




Algorithms 2025, 18(12), 789; https://doi.org/10.3390/a18120789 - 12 Dec 2025
Abstract
This study tested the impacts of large language model (LLM) addiction on the mental health of university students, employing gender as a moderator. Data was collected from 750 university students from multiple fields of study (i.e., business, medical, education, and social sciences) using
[...] Read more.
This study tested the impacts of large language model (LLM) addiction on the mental health of university students, employing gender as a moderator. Data was collected from 750 university students from multiple fields of study (i.e., business, medical, education, and social sciences) using a self-administered questionnaire. Partial Least Squares Structural Equation Modeling (PLS-SEM) was employed to analyze the collected data; this study tested the impacts of three LLM addiction dimensions—withdrawal and health problems (W&HPs), time management and performance (TM&P), and social comfort (SC)—on stress, depression, and anxiety as dimensions of mental health disorders. Findings indicate that TM&P and SC had a significant positive impact on stress, depression, and anxiety, implying that overdependence (as an early-stage precursor and behavioral antecedent of LLM addiction) on LLMs for academic achievements and emotional reassurance contributed to higher levels of psychological distress. On the contrary, W&HP showed a weak but significant negative correlation with stress, signaling a probable self-regulatory coping approach. Furthermore, gender was found to successfully moderate several of the tested relationships, where male university students showed stronger relationships between LLM addiction dimensions and adverse mental health consequences, whereas female university students proved greater emotional constancy and resilience. Theoretically, this paper extends the digital addiction frameworks into the AI setting, highlighting gendered models of emotional exposure. Practically, this study highlights the urgent need for gender-sensitive digital well-being intervention programs that address the overuse of LLMs, a prominent category of generative AI. These outcomes emphasize the significance of balancing technological involvement with mental health protection, determining how LLM usage can specifically contribute to digital addiction and related psychological consequences among university students.
Full article
(This article belongs to the Special Issue Artificial Intelligence Algorithms and Generative AI in Education (2nd Edition))
►
Show Figures
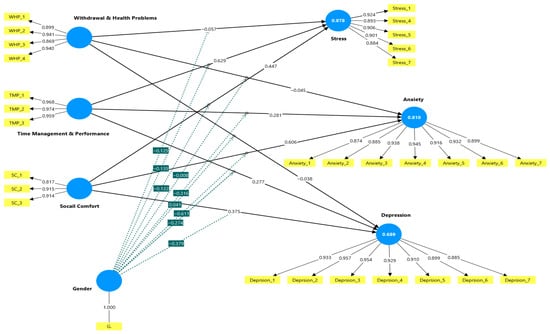
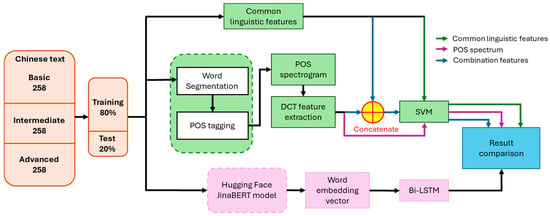
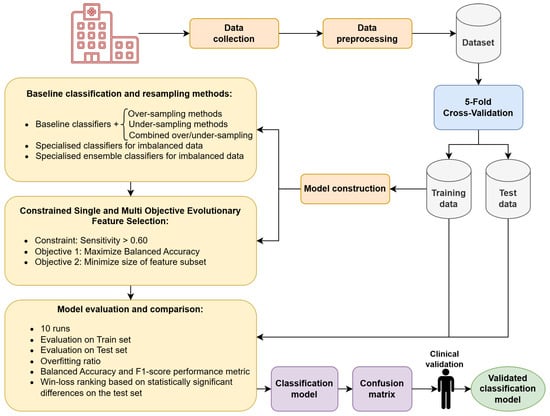
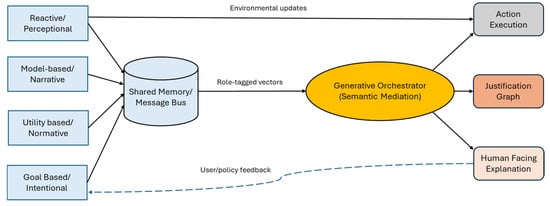
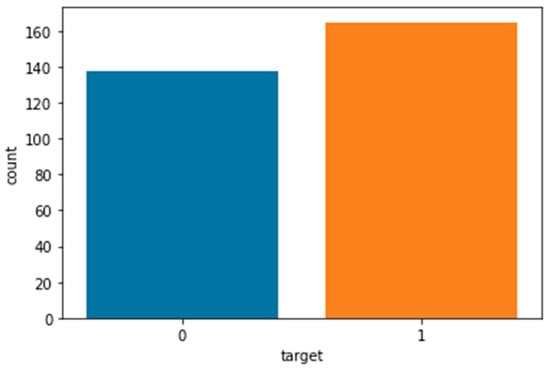
Figure 1









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}