

Multimodal Technol. Interact. 2026, 10(6), 58; https://doi.org/10.3390/mti10060058 - 22 May 2026
Abstract
►
Show Figures
This study presents a comprehensive review of more than 100 research papers on sign language recognition (SLR) published between 2020 and 2026. The analysis focuses on deep learning approaches applied to video-based SLR, including spatiotemporal feature extraction, temporal modeling, attention mechanisms, motion-based representations,
[...] Read more.
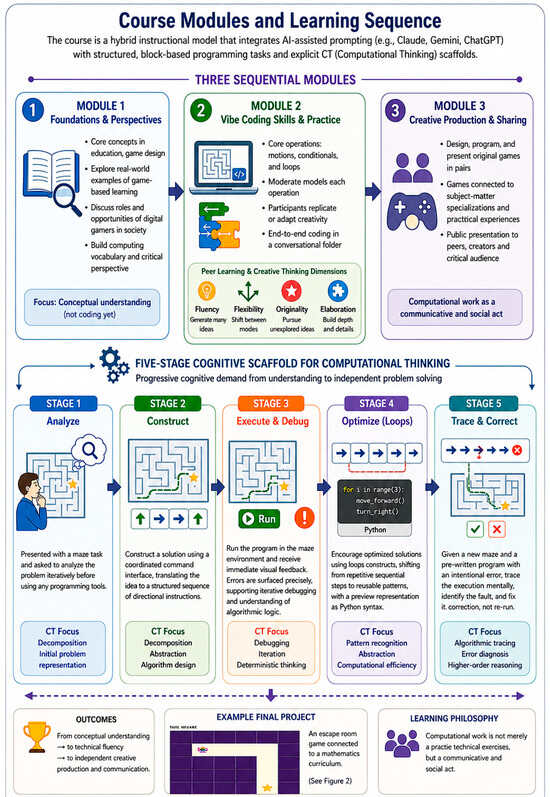
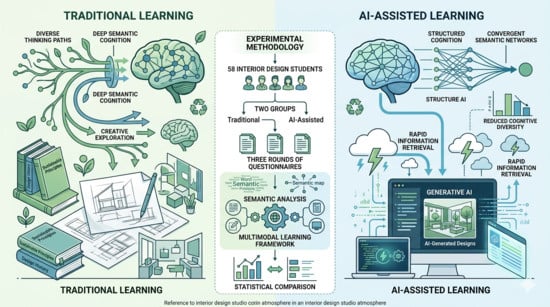
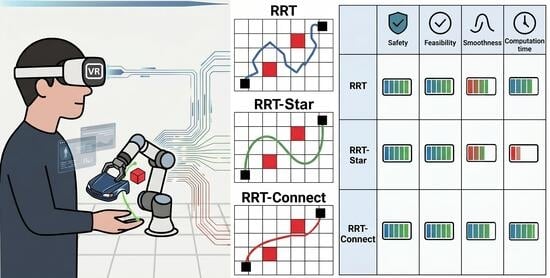
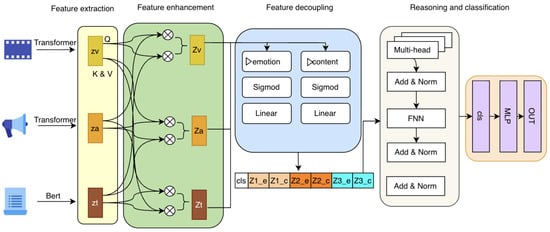
This study presents a comprehensive review of more than 100 research papers on sign language recognition (SLR) published between 2020 and 2026. The analysis focuses on deep learning approaches applied to video-based SLR, including spatiotemporal feature extraction, temporal modeling, attention mechanisms, motion-based representations, hybrid frameworks, transfer learning methods and other methods. Particular attention is given to how these methods model spatiotemporal dynamics and capture subtle gesture characteristics in sign language communication. The review highlights several recent developments, such as the introduction of specialized datasets, the emergence of real-time recognition systems, and the integration of multimodal fusion strategies. At the same time, persistent challenges remain, including data scarcity in low-resource sign languages, limited linguistic standardization of datasets, and insufficient model interpretability. The findings underline the importance of developing scalable and generalizable models capable of handling diverse datasets and user variability. The distinct contributions of this review are fourfold: (1) a comprehensive synthesis of over 100 studies published between 2020 and 2026, covering the full spectrum of deep learning architectures for video-based SLR; (2) a structured six-category taxonomy enabling systematic cross-architectural comparison; (3) a comprehensive focus on low-resource sign languages, which remain underrepresented in the existing literature; and (4) a critical analysis of the current benchmark landscape for low-resource sign languages, identifying key gaps and outlining strategic directions for future dataset development. These contributions are intended to guide further research toward more robust, inclusive, and universally applicable SLR systems.
Full article

Figure 1



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}