

Mach. Learn. Knowl. Extr. 2026, 8(6), 166; https://doi.org/10.3390/make8060166 (registering DOI) - 16 Jun 2026
Abstract
The increasing convergence of Operational Technology (OT) and Information Technology (IT) within the Industrial Internet of Things (IIoT) brings about remarkable improvements in monitoring and automation. However, it also exposes industrial systems to large-scale Distributed Denial of Service (DDoS) attacks. Edge-based defences are
[...] Read more.
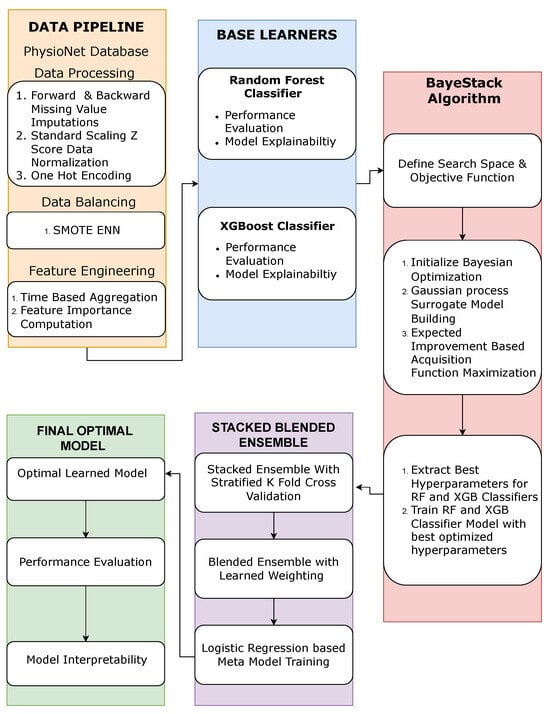
The increasing convergence of Operational Technology (OT) and Information Technology (IT) within the Industrial Internet of Things (IIoT) brings about remarkable improvements in monitoring and automation. However, it also exposes industrial systems to large-scale Distributed Denial of Service (DDoS) attacks. Edge-based defences are essential in satisfying low-latency demands and data sovereignty rules, yet they must function under severe resource limitations and adapt to shifting traffic characteristics without cloud assistance. In this work, we introduce a lightweight hybrid deep learning architecture that fuses a Convolutional Neural Network (CNN) with a Convolutional Block Attention Module (CBAM) and a Multi-Layer Perceptron (MLP) in a single detector. A sequential transfer learning scheme is adopted, including a feature projection layer that handles differences in input dimensionality. The model is pre-trained on the CIC-DDoS2019 dataset, then adapted to the more recent CICIoT23 dataset. Evaluations are performed on both datasets while preserving their natural class imbalance. We provide extensive ablation and variance analysis under identical experimental conditions. The proposed method achieves 99.52% accuracy on CICIoT23 while maintaining 99.65% recall, which is a crucial property for critical systems. Real-time measurements on a CPU-only testbed show an average inference latency of 0.013 ms, inference-only throughput exceeding 93,000 packets/s, and end-to-end batch throughput of approximately 38,000 packets/s. The solution demonstrates effective domain adaptation, sub-millisecond latency, and suitability for resource-constrained IIoT edge gateways.
Full article
(This article belongs to the Section Safety, Security, Privacy, and Cyber Resilience)
►
Show Figures

Figure 1






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}