






Big Data Cogn. Comput. 2026, 10(6), 173; https://doi.org/10.3390/bdcc10060173 - 29 May 2026
Abstract
Open fiscal data in Ecuador remains largely unexplored beyond basic descriptive reporting, despite its potential for territorial intelligence and fiscal planning. This study examines how taxpayers are distributed across Ecuador’s provinces and economic sectors by applying a Big Data pipeline built on Apache
[...] Read more.
Open fiscal data in Ecuador remains largely unexplored beyond basic descriptive reporting, despite its potential for territorial intelligence and fiscal planning. This study examines how taxpayers are distributed across Ecuador’s provinces and economic sectors by applying a Big Data pipeline built on Apache Spark 3.5, PostgreSQL 14/PostGIS 3.2, and Python 3.11 spatial libraries to the SRI Tax Registry, comprising approximately 2.5 million records. The analysis combined K-Means and DBSCAN clustering with spatial autocorrelation methods, including Moran’s Index and LISA, to identify concentration patterns and territorial dependencies. The findings show that 68% of taxpayers are located in three provinces, namely Pichincha (34%), Guayas (24%), and Azuay (10%), with a spatial Gini coefficient of 0.61 reflecting considerable fiscal inequality across the country. A Global Moran’s Index of 0.49 (p < 0.001) confirms that neighboring provinces tend to share similar taxpayer densities, while LISA revealed five High–High clusters in major urban centers and six Low–Low clusters in the Amazon region and northern border. DBSCAN identified 27 spatial groupings, including secondary economic nuclei in cities like Ambato, Riobamba, and Machala that autocorrelation models alone do not capture. The methodology is replicable and offers a practical basis for designing place-based fiscal policies in similar contexts. These results provide tax authorities and regional planners with an empirically grounded, scalable framework for identifying territories with fiscal formalization gaps and designing geographically targeted interventions to reduce territorial inequality in Ecuador and in comparable developing-country contexts.
Full article
(This article belongs to the Special Issue Advanced Software and Machine Learning Techniques for System Architectures and Big Data)






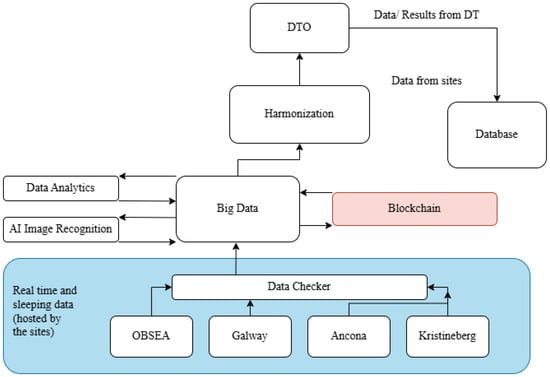

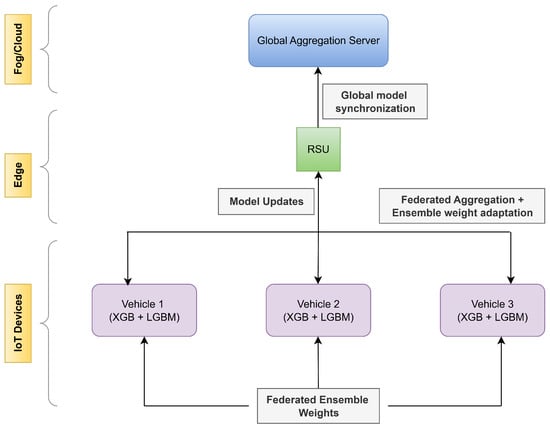



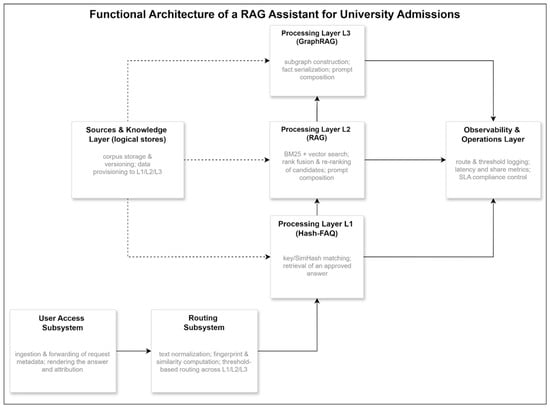

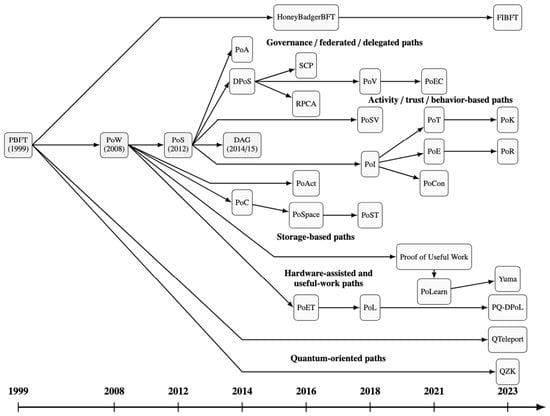






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}