- Review

What Distinguishes AI-Generated from Human Writing? A Rapid Review of the Literature
- Georgios P. Georgiou
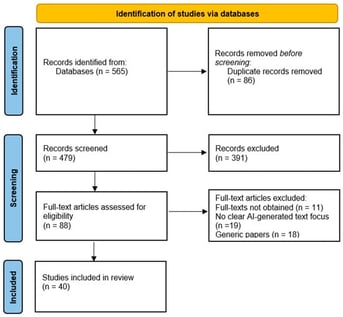
Large language models (LLMs) are now routine writing tools across various domains, intensifying questions about when text should be treated as human-authored, artificial intelligence (AI)-generated, or collaboratively produced. This rapid review aims to identify cue families reported in empirical studies as distinguishing AI from human-authored text and to assess how stable these cues are across genres/tasks, text lengths, and revision conditions. Following the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) guidelines, we searched four online databases for peer-reviewed empirical articles (1 January 2022–1 January 2026). After deduplication and screening, 40 studies were included. Evidence converged on five cue families: surface, discourse/pragmatic, epistemic/content, predictability/probabilistic, and provenance. Surface cues dominated the literature and were the most consistently operationalized. Discourse/pragmatic cues followed, particularly in discipline-bound academic genres where stance and metadiscourse differentiated AI from human writing. Predictability/probabilistic cues were central in detector-focused studies, while epistemic/content cues emerged primarily in tasks where grounding and authenticity were salient. Provenance cues were concentrated in watermarking research. Across studies, cue stability was consistently conditional rather than universal. Specifically, surface and discourse cues often remained discriminative within constrained genres, but shifted with register and discipline; probabilistic cues were powerful yet fragile under paraphrasing, post-editing, and evasion; and provenance signals required robustness to editing, mixing, and span localization. Overall, the literature indicates that AI–human distinction emerges from layered and context-dependent cue profiles rather than from any single reliable marker. High-stakes decisions, therefore, require condition-aware interpretation, triangulation across multiple cue families, and human oversight rather than automated classification in isolation.
8 February 2026