


Entropy, Volume 22, Issue 5 (May 2020) – 99 articles
Cover Story (view full-size image):
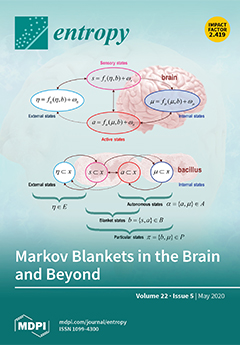
This schematic illustrates the partition of a system’s states into internal states (blue) and hidden or external states (cyan) that are separated by a Markov blanket, comprising sensory (magenta) and active states (red). The upper panel shows this partition as it would be applied to action and perception in the brain. The ensuing self-organization of internal states then corresponds to perception, while action couples brain states back to external states. The lower panel shows the same dependencies but rearranged so that the internal states are associated with the intracellular states of a Bacillus, while the sensory states become the surface states or cell membrane overlying active states (e.g., the actin filaments of the cytoskeleton). View this paper
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue