1. Introduction
What is it that we mean when we ask if a system possesses free will? In most discussions of free will, the nature of what freedom entails is often taken for granted; if we ask if a given choice is free, we are assuming that it is a well-formed question to begin with. Rather than asking if a given choice is free, we might instead ask what, in general, a free choice is. In other words, a more formal and rigorous definition of freedom of choice ought to be a prerequisite to any deeper understanding of free will.
This is not merely academic. In EPR tests in quantum mechanics, it is often assumed that the experimenters have free will (see [
1] for an overview). On the other hand, as Bell suggested, one could replace the experimenters with a pair of machines capable of making suitably random measurements [
2]. The variables measured by the machine are the same as the variables measured by the experimenters, but do machines carrying out pre-programmed algorithms to produce random measurements count as having free will? While they might produce measurements that are provably more randomly chosen than those chosen by experimenters, it is hard to say if a presumably non-conscious entity can possess free will. Therein lies the problem. Does it even make sense to refer to the machine’s actions, which are guided by a pre-programmed algorithm, as making a choice? As Nozick has rightly pointed out, “[a]n action’s being non-determined is not sufficient for it to be free–it might just be a random act” [
3]. A random act is no more free than a fully determined one.
Thus, it is that freedom of choice has a bearing on the nature of consciousness. Does our conception of consciousness drive our definition of free will or is it the other way around? Explicating the relationship between consciousness and volition has moved well beyond the theoretical. Famously, the Libet experiments suggest to some that volition can be an unconscious act [
4]. Additional experiments have built on Libet’s work [
5,
6]. On the other hand, our judgment of what this means appears to be driven by the outcomes. Specifically, experimental work by Shepherd suggests that the conscious causation of behavior tends to be judged as being free even when the causation is explicitly deterministic [
7].
The question of whether free will is compatible or incompatible with (causal) determinism has long been central to the nature of free will, at least in the Western perspective [
8]. However, the indeterminacy of quantum systems raises similar issues for seemingly opposite reasons [
9,
10]. In other words, one could argue that both causal determinism as well as quantum indeterminacy are incompatible with free will. On the one hand, one can deny the existence of free will on the grounds that all choices are pre-determined in some way. On the other hand, one can deny the existence of free will on the grounds that all choices are simply macro-manifestations of random quantum processes, i.e., the universe is nothing but a collection of randomly fluctuating quantum fields. However, this misses a deeper point captured succinctly by O’Connor when he notes that “though freedom of will requires a baseline capacity of choice …the
freedom this capacity makes possible is, nevertheless, a property that comes in
degrees and can vary over time within an individual” [
11] p. 183 (original emphasis). The usual debate over the existence of free will is thus really a debate over the capacity of choice. Less attention is paid to the nature of the freedom that this capacity makes possible. It is this freedom that is the motivation for the model described in this article.
In order to build a model of the freedom engendered by the existence of a capacity of choice, it is necessary to assume that such a capacity exists. As such, the model that follows sidesteps the question of whether or not free will actually exists. Rather, it proceeds from the assumption that capacity of choice exists for some systems and develops a measure for the freedom that follows from this assumption. The model is based on a process ontology in which a
free choice is a process that takes a system from one macrostate to another. I lay the groundwork for this by first describing the self-evident characteristics of what I will call
adaptive free choices. This very roughly corresponds to what O’Connor calls “willing” or the “conscious forming of an intention to act” (see [
11], p. 178) though it does not explicitly presume an agent or system is conscious. I then develop the process ontology on which the formal model is constructed where I show that both determinism and indeterminism have a role to play in the nature of free choices. The formal model is then quantified by the
-function as a measure of free choice and the
Z-function as a corresponding measure of free will which is taken to be an aggregation of free choices. Free will in this model, then, is not taken to be the capacity of choice, but rather is viewed as an aggregation of the freedoms that a capacity of choice, if it exists, would make possible. Finally, I discuss methods for assessing certain aspects of the model and for assigning values to certain variables within the model.
2. Adaptive Free Choice
What do we generally think of when we think of free will? O’Connor claims that systems that possess free will should generally be possessed of three capacities: (1) an awareness and sensitivity to reasons for actions; (2) an ability to weigh and critically probe desires and intentions, and possibly to reevaluate goals; and (3) the ability to choose, based on reasons, which action to take on a given occasion [
11]. While O’Connor claims that those are necessary for a system to possess free will, are they sufficient?
Suppose that I open my refrigerator with the intent of having something to eat and am presented with a variety of options. It is immediately obvious that, if my refrigerator only contained one thing, then I wouldn’t have much of a choice. It seems clear, then, that, aside from any internal capacities that I might possess, one very clear external factor in assessing the freedom of a choice is the number of options that are available to choose from. By its very nature, the word “choice” implies that there must be a minimum of two options to choose from. However, it is also necessary that I be able to read those options (or a certain subset of them) into my memory and then process them, all in a finite amount of time (it wouldn’t really be much of a choice if it took me an infinite amount of time to read in all the options). As such, there is a computational aspect to free choice. Indeed, several computational models of free will exist [
12,
13]. However, we also assume that, for free will to exist, the system or agent experiencing it must have enough time to assign meaning or a value judgment (i.e., a weight) to each possible choice. In other words, if the possible choices are read into the system’s memory too quickly, one could easily attribute any subsequent choice to mere instinct. O’Connor identifies three types of “will” or “desire”: (1) minimally voluntary action, (2) willing or the conscious formation of an intention to act (briefly mentioned above) and (3) an urge or want [
11]. It seems clear, then, that the capacity to weigh and probe desires and intentions, i.e., to assign meaning or a value judgment to each possible choice, is linked to the distinction between a minimally voluntary action and a “willing”. What I refer to as an
adaptive free choice, then, includes the capacity to weigh and probe desires, the formation of an intention to act based on the action of weighing and probing desires, and finally the carrying out of the action whose intention was formed. That is, I assume that it is not merely sufficient to possess the capacity of choice. Some action representing the choice being made must also take place. This is not a trivial point.
Returning to the refrigerator, for the sake of simplicity, let’s suppose that I only have two options—carrots and peppers. With only two choices, there is no real concern about the reading and processing time being too lengthy and we can assume, for the moment, that neither is it too short, i.e., I am free to stand in front of the refrigerator and ponder these two possibilities, assigning meaning to them in the form of weights. Let us suppose that I then make a choice—carrots, for the sake of argument. There is an often overlooked assumption in discussions of free will having to do with the nature of actually
enacting a choice. That is, we assume (usually implicitly) that, to a generally high degree of probability, enacting the choice results in the desired outcome. To put it another way, in choosing carrots, I am relying on the fact that there is a very high probability that, at some point between choosing carrots and actually removing them from the refrigerator and ingesting them, they
remain carrots and do not spontaneously turn into peppers. That is, we rely on the fact that the universe is a relatively stable place. Consider what would happen if we could
not be confident that our choices lead to their expected outcomes the vast majority of the time. If this were the case, we would likely give up on choosing since the outcomes would be closer to random and thus the act of making a choice would be pointless. As Nozick pointed out, a random act is not a free act [
3]. Thus, there must be some level of determinism involved in free choices in the sense that the chosen action itself is nearly deterministic. The crucial point, however, is that each possible choice
is a different action. Thus, it is that we are choosing between different
processes rather than labeling each choice as a different outcome of the
same process [
14]. In other words, in order for the choice to be truly free, we have to have a high degree of confidence that the state that we finally choose actually occurs. Otherwise, there is no point in making a choice in the first place. However, this means that, when presented with a set of possible choices, each choice must represent a fundamentally different process, e.g., the actual process of reaching into my refrigerator for a carrot is not the same as the actual process of reaching into my refrigerator for a pepper (at the very least, they are not in the exact same location and thus the processes involve different spatial coordinates).
These characteristics of free choices are partially behavioral since they are based on the system’s actions and its reaction to those actions. We weigh our choices based partly on past experience. If I have eaten both carrots and peppers before, I will know what they taste like and can use that information to place weights on each option. The fact that previous behavior can inform future behavior is a characteristic of many downwardly causal processes. This makes the weighting of the choices and the existence of a memory key differentiators, and motivates the use of the term
adaptive (see [
15]). This distinguishes them from O’Connor’s minimally voluntary actions which I interpret as upwardly causal. A minimally voluntary action is distinguished from a purely instinctual one by the fact that it still leads to a desired outcome (see [
11] for a fuller discussion).
If we expect the outcomes of chosen actions to be nearly deterministic in most instances, how can we reconcile this with the fact that the quantum fields of which the universe is constructed, display a certain level of indeterminacy? Is it possible to obtain deterministic outcomes from sets of random processes? This, in fact, is exactly what happens in the thermodynamic limit of statistical physics. I use similar methods to construct the process ontology that is at the heart of this model.
3. Process Ontology
In order to reconcile a seemingly deterministic macroworld with a fundamentally random microworld, I introduce a process ontology in which we may classify choices. The fundamental entities of this ontology are systems, states, and processes. However, I refer to this as a process ontology in order to emphasize the fact that the aim is to model both the internal reasoning about possible actions as well as the fulfillment of a chosen action.
A system in this ontology can be anything one chooses it to be. We define states as follows.
Definition 1 (State).
A state is a unique vector configuration of the fundamental components of a system as specified by some variable or set of variables λ.
The states of systems are thus functions of variables which allow us to specify the state. Processes, then, take states from one configuration to another by changing .
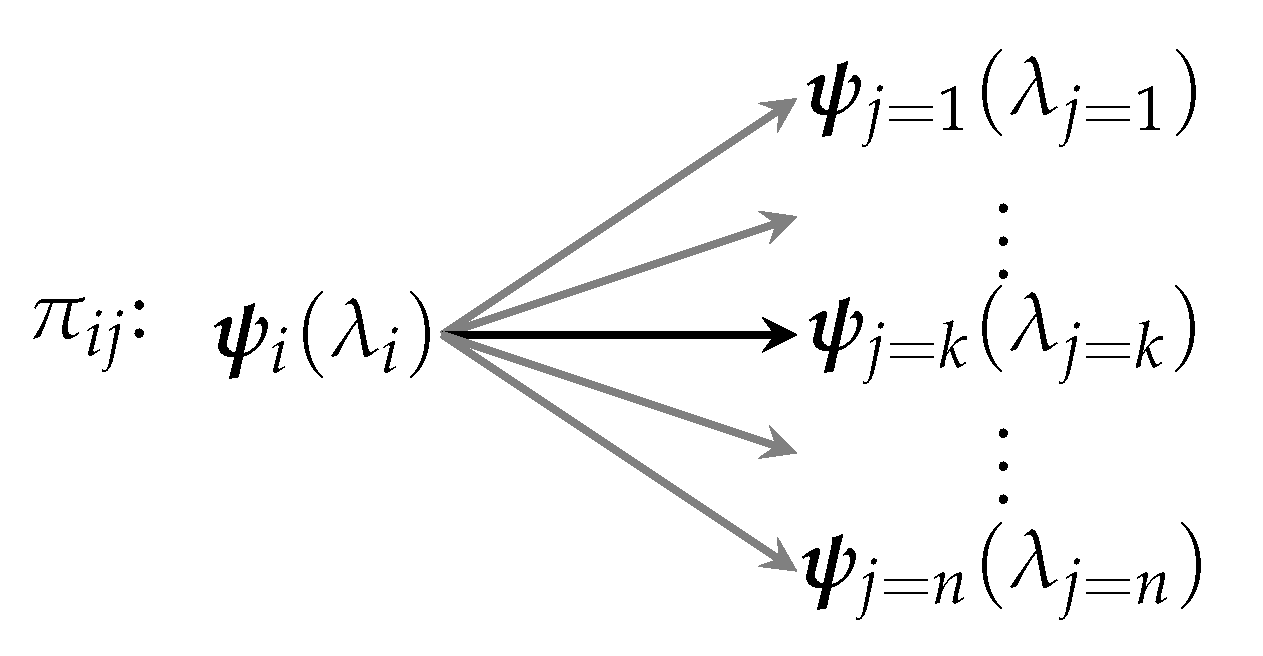
Definition2 (Process)
. A process π is a means by which a system may transition between some fixed state and one (and only one) of n possible states .
That is, though a process always ends in a single definite state, it may probabilistically end up in one of a possible collection of states. We assume that the outcome state is definite (i.e., is not a superposition). A graphical representation of a process is shown in
Figure 1.
The multiplicity for process is then defined to be the number of possible outcomes, i.e., .
These definitions now allow us to describe a spectrum of processes. It might be true, for instance, that, for a given process , the multiplicity is . That is, there might be only one possible outcome for the process. Such a process is thus fully deterministic. Conversely, it may be true that and that all outcomes have an equal likelihood of occurring, i.e., the probability distribution for the process is flat. Such a process would naturally be fully random since no single outcome is favored over any other.
It is important to distinguish here the difference between determinism and causality. In this model, all processes are causal in that they follow from other processes. This includes “spontaneous” processes which are understood to follow from conditions produced by other processes. For example, spontaneous particle creation can only occur because of the presence of the underlying fields. This model would assume that the existence of those fields came about from some process, even if the nature of that process is not known. Thus, though this model is causal, it is not fully deterministic. The distinction between causality and determinism has been rigorously delineated by D’Ariano, Manessi, and Perinotti, and we refer the reader to [
16] for details.
I note that all these definitions can be broken into two possible categories—micro or macro—depending on the level of the system under consideration. This has the usual meaning from statistics and statistical mechanics. Thus, for instance, we can speak of a pair of (fair) dice as having 36 different microstates and 11 different macrostates. In this case, the microstates are the various configurations that produce a given macrostate. A pair of (fair) dice is a fairly simple system in which we assume the fundamental constituents (the dice) do not interact. In more complex systems, interactions may occur between the various parts of the system. It is not necessary for interactions to occur, however, in order to obtain a deterministic macrostate from a collection of equally likely microstates.
Consider a simple two-state system
in a state
. Since it is a two-state system, any potential process only has two possible outcomes: either the existing state evolves to itself or to the other state. Let us assume that each of these states is equally likely to occur in the long run. Examples of such systems include two-state paramagnets, fair coins (being flipped), etc. Thus, the process
for the evolution of a simple two-state system is
The multiplicity for this process is . If we assume that each of the two possible outcomes is equally likely, the probability distribution is quite simple.
Now, consider a more complex system that is composed of smaller sub-systems. The more complex system will be referred to as a macrosystem and its states and processes will be referred to as macrostates and macroprocesses. I will distinguish these from the component microsystems, microstates, and microprocesses by using capital letters. Thus, for example, if is a microprocess taking a microsystem from some fixed microstate to one (and only one) of n possible microstates , then is a macroprocess taking a macrosystem from some fixed macrostate to one (and only one) of N possible macrostates .
As an example, consider a macrosystem
that consists of two
non-interacting two-state microsystems
and
that is in a state
. The possible outcome states and the associated probability distribution are shown in
Figure 2:
The probability of any given macrostate is given by the multiplicity of that macrostate divided by the total multiplicity. In this situation, there is only one microstate for each macrostate and so
where
is the number of microstates that correspond to macrostate
and where
follows from the fact that multiplicities are multiplicative. Once again, the probability distribution is flat.
Now, consider an even more complex macrosystem composed of
N non-interacting two-state microsystems and let us ask how many of the subsystems will be in the state
after the process
occurs. The answer is given by the multiplicity, which is
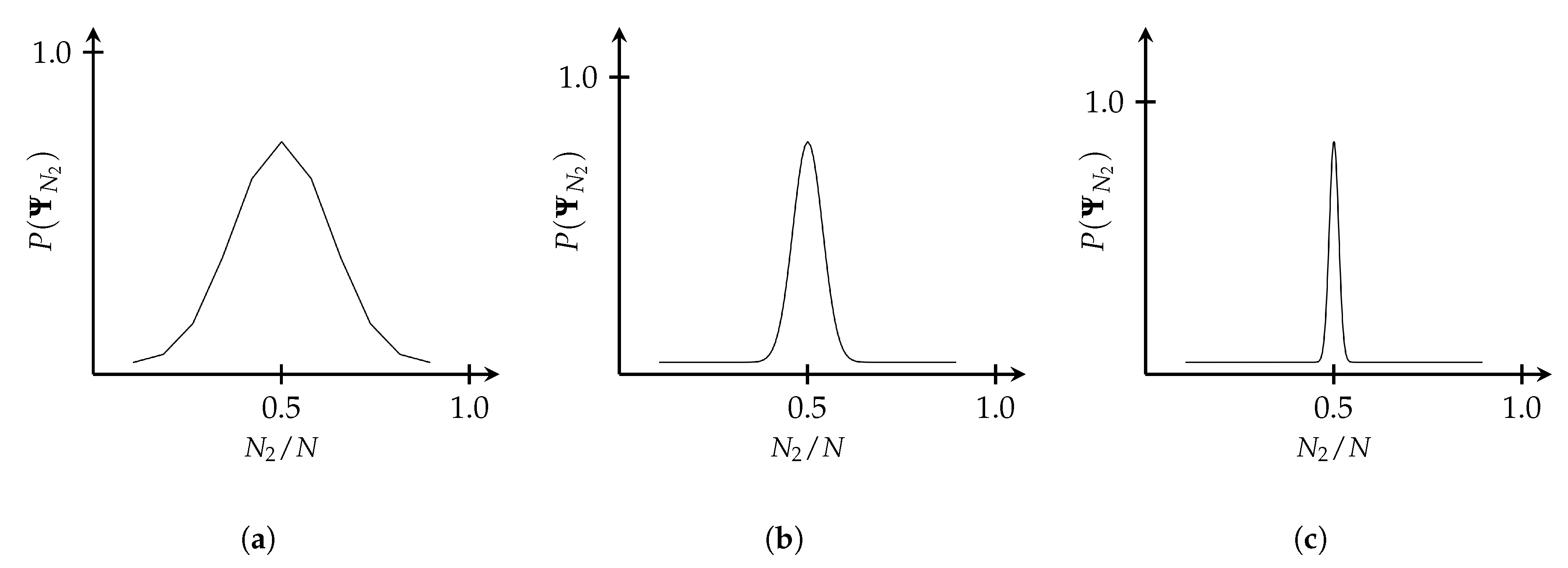
If
N is very large, we can use Stirling’s approximation,
, which gives
where
. The probability
of a state
occurring is plotted as a function of
for three different values of
N in
Figure 3 where I have normalized each distribution (see [
17] Ch. 2).
We can see from this that, as the size of the system increases, despite the underlying processes being entirely random, the system tends to cluster in a small number of macrostates. As , the system tends toward a single macrostate. That is, the transition between state 1 and some state J becomes deterministic. From this we can see that sets of random microprocesses can lead to deterministic macroprocesses.
The processes considered in the above example were non-interacting. The real world, of course, includes interactions. An interaction between two systems is also a process that in some way changes the variables of each system. As such, each subsystem is undergoing a process that is influenced by the other subsystems’ processes. The details of the process ontology for such situations is beyond the scope of the current work, which is intended as an introduction to the model. However, subsequent works will elaborate on the underlying process ontology and discuss how it affects the distributions. For the purposes of explicating the basic model of free will, the nature of the actual distributions is not important. The distributions become important when assessing the actual choices that are fed into the model.
4. The Model
I will refer to any system that possesses the capacity of choice, as introduced in
Section 2, as an ‘agent’. A choice can only be said to be free if the agent can make some judgment about all possible choices in order to weigh them against one another, i.e., they must mean something to the agent. Otherwise, the choice is random (and thus meaningless). In addition, the agent has to have a high degree of confidence that the choice they finally make will actually be realized. Crucially, different choices represent different processes. I thus
define choice in the following manner.
Definition 3 (Choice)
. A choice is a (possible) macroprocess that is a means by which a system may transition between some fixed state I and one (and only one) of n possible states J.
Note that the lower-case n is deliberate and the reason will become evident in a moment.
For a particular choice to be free, the total number of choices presented to the agent at a given time, which I will call the ‘choice ensemble’
, must be read into the system’s memory and then processed in a finite amount of time. Otherwise, the possibility of making a choice is undecidable. Likewise, stability is assumed, as described in
Section 2, in that the outcomes of the actions associated with each choice do not change subsequent to the decision, i.e., carrots don’t spontaneously turn into peppers.
Given the above definition, I add the following axioms:
Axiom 1.The most fundamental systems are irreducible to other systems, i.e., they contain no interactions and cannot be partitioned.
Axiom 2. All possible configurations, i.e., microstates, of fundamental systems are equally likely in the long run.
Axiom 3. A system’s macrostates are formed via interacting (micro)processes.
Axiom 4. The probability that a choice will lead to its macrostate is arbitrarily high if the choice is free, i.e., a free choice inevitably leads to a nearly deterministic outcome.
Axiom 5. The number N of possible choices that a system has must be small enough to be read into the system’s memory in a finite time.
Axiom 6. The choices do not change at any time during the agent’s processing of the choices nor during the agent’s enactment of the choice.
Axiom 7. The choices must be distinct.
These are the formal axioms of the model. There are certain assumptions and definitions that fully describe the model that will be introduced in the next section. However, from the formal standpoint, we restrict ourselves to these axioms. It is worth noting that I do not require that the interactions of Axiom 3 be classical. This is intentional. It is entirely possible that such an assumption will lead to unusual results that require a refinement of the model, but that is an area for future work.
Now, suppose that some macrosystem
composed of
k microsystems
is presented with an ensemble
of
N possible choices
. Each choice in the ensemble has
possible outcomes (hence the choice of a lower-case
n in Definition 3). The probability distributions associated with the choices in the ensemble are
where
is the mean and
is the variance for the given distribution. The ensemble of choices may be represented as a mixed distribution,
with weights
and where
is a convex function.
A particularly useful analysis of multimodal distributions is based on the distribution’s overall topology. Ray and Lindsay give a method that utilizes what they refer to as the “ridgeline” function which describes the shape of
as
where
a belongs to the
dimensional unit simplex
. Here,
,
for a
D-dimensional space and
and
correspond to the covariance and mean of the
ith component, respectively. This function can be used to identify the locations of the peaks in the distributions if they are not clearly known [
18]. Here, I will assume that the peaks are reasonably distinct in that their individual means and variances, and thus their locations in the overall distribution, are known.
Axiom 7 above captures the assumption that choices can only be said to be free if they are reasonably distinct. If an agent is presented with two essentially identical choices, then there are fewer criteria by which the agent can distinguish them and thus their distributions will have a certain amount of overlap. If spatial information is included in their distributions, then they won’t overlap perfectly since the two choices will, at the very least, represent different spatial locations. For example, in choosing between two identical carrots, one is choosing between two objects that, though perhaps otherwise identical, are in different spatial locations. In any case, one expects that the more distinct the choices, the more free the ability to choose; if the choices are identical, the ability to choose is closer to a random process, e.g., the choice between two nearly identical carrots is not as free as the choice between a carrot and a pepper. A convenient measure of the distinctness of the choices in this case is given by the Mahalanobis distance [
18,
19] between any pair of constituent distributions
i and
j in the mixed distribution
given by
where
and
are the respective means and
is the covariance matrix. When the covariance matrix is diagonal, this reduces to the standardized Euclidean distance. The Mahalanobis distance is preserved under full-rank linear transformations of the space that is spanned by the data comprising the distributions. Intuitively, then, the larger the value of
, the more distinct choices
i and
j will be. Within the full ensemble of choices
, the freedom of choice
i depends on the
minimum distance
between
i and each other choice in the ensemble
.
Capturing Axiom 5 proves to be a bit tricky. We could quite simply define a time function
T that depends on the total number of choices
N and require that it be finite. However, one might suppose that different values for
or even
will affect the time required to read in and process the choices. For instance, if two neighboring choices are not particularly distinct in that they have considerable overlap in their individual distributions, this might lead to the agent spending more time processing and assigning weights to these two choices. Thus, I will assume that the time it takes for the agent to read in and process the choices is some function of their number
N as well as the general topology
of the distribution, i.e.,
. The crucial requirement is that
where
is some minimum time below which the choice becomes either minimally voluntary or purely instinctual. This ensures that the information can be read into memory and processed in a finite amount of time.
It is debatable whether, aside from requiring that
T be finite, we also need to require that it be minimized but greater than
. Obviously if
T is too small, the system is not extracting meaning from the process and thus the choice is minimally voluntary or instinctual. Hence the lower bound on
T. On the other hand, one could argue that a shorter time means the system is more efficient. Greater efficiency does not necessarily mean less freedom. Thus it is that we also might require that
T be as close to
as possible without dropping below it. I will leave this point unanswered in this initial version of the model. However, I discuss some related points in
Section 5.
The covariance, time function, and minimum Mahalanobis distance, then, provide a means of measuring Axioms 4, 5, and 7, respectively. This leads us naturally to a measure of the “freedom” of any particular choice in the ensemble.
Definition4 (Free choice)
. Given a finite number of possible choices N from ensemble , the “freedom” of choice i is given by the functionwhere is a constant of proportionality with units of inverse time. I have assumed that maximizing the freedom of the choice entails minimizing its covariance since this increases the “sharpness” of the probability distribution within the ensemble. The larger the value of the -function, then, the more free the choice.
This, of course, is only a measure of the freedom of a single choice. It is entirely possible that an agent could have many free choices and many non-free choices. One would assume that a majority of choices for any agent said to possess free will would have a high measure of freedom. The question is whether freedom in this sense is additive or multiplicative. We can answer this by returning to the statistical arguments that underpin the first few axioms.
In a certain sense, the freedom of a given choice is related to how easy it is to actually make that choice. Roughly speaking, then, the more ways in which one can make a specific choice, the greater the freedom of that choice. In that sense, freedom is similar to the outcomes of a process. The number of outcomes for a given macrostate of a process is measured by the multiplicity which is multiplicative. Thus, we can, by analogy, take freedom to be multiplicative in this particular model. As such, we can take a measure of free will to be the following.
Definition5 (Free will)
. Given some number of processes that result in choices, an agent’s free will is given by a partition functioni.e., the level of free will that a system possesses over N choices is dependent in a multiplicative way on the level of freedom in each of those choices. 5. Weighting the Choices
A crucial component of the model is the set of weights given in Equation (
5). It is within these weights that the action of choosing can either be entirely random (if the weights are all equal), entirely deterministic (if there is only a single constituent distribution), or something in between. Freedom is a spectrum between entirely random and entirely deterministic and it is this spectrum that
and
Z measure.
There are two basic methods for assigning the weights in the function from a physical standpoint. In the one case, the weights can be derived from the internal dynamics of the agent. That is, we could begin with a set of k fundamental subsystems each with some state . These subsystems could be allowed to evolve naturally through various processes such that the agent itself evolves by some macroprocess between two macrostates and , where lowercase labels represent microstates and uppercase labels represent macrostates. It is entirely possible that the agent could have evolved via an entirely different macroprocess to macrostate under the same internal conditions since the outcomes of the individual microprocesses are assumed to be random in accordance with Axiom 2. Each of these possible macrostates may have an associated probability distribution. Over a large number of evolutions of the agent to these macrostates, the weights can be established statistically and an ensemble can be formed.
Establishing the weights in this instance relies solely on the internal dynamics of the agent and is an entirely upwardly causal process. It would be easy to dismiss this as a free choice either on the grounds that, as a closed system, the agent is causally deterministic or on the grounds that it is simply reacting to underlying random processes. It is important to note that this does not mean the system is free from external interactions. It simply means that the internal dynamics are what drives the state evolution. The external constraints may be what sets the initial conditions in the form of the initial state but plays no role in the determination of the actual weights.
However, no system is truly closed and so it is more accurate to assume that environmental and contextual factors also drive the evolution of the processes that the agent undergoes. In actuality, the agent interacts with its environment
during the macroprocesses such that the dynamics are influenced by the environment in
addition to internal factors. Axiom 2 is still satisfied since the underlying microstates of both the agent and its environment remain equally likely in the long run, but conditions are now contextual such that the
macrostates are now partially constrained by external factors. These external factors can be construed as assigning a form of
meaning to the weights. This is a form of downward causation as discussed by Ellis and others (see, for example, [
20]). Specifically, this can be viewed as a form of decoupling similar to dynamic or symbolic decoupling that has been argued as a possible driver for free will [
21]. However, there is still something missing.
Let’s return to the choice between carrots and peppers in my refrigerator. If I choose carrots, did I do so because my genetics and specific worldline in spacetime predisposed me to do so? If so, it was hardly a free choice. Indeed, this is a typical feature of arguments
against free will (see, for example, [
22]). On the other hand, perhaps I chose the carrot because I consciously weighed my past experience against how I “felt” at the time. The difference between the two is that the second involves accessing
memory in the broad sense (i.e., including both stored practical information as well as potentially qualia). One might argue that both instances involve memory, but that really isn’t the case. Accessing memory is a necessarily downwardly causal process whereby a system in a higher-level state actively accesses stored information about lower-level states. Specifically, the process of choosing from a set of choices, which necessarily includes assigning them weights and accessing memory, is precisely a form of adaptive selection [
23]. Adaptive selection involves a process of variation (the process ontology in this model) that generates an ensemble of states (here these are the macrostates) from which an outcome is selected according to some kind of selection criteria. Indeed, the selection criteria themselves can be chosen through a form of adaptive selection [
15]. The presence of memory is fundamental to any adaptive process. Thus, it makes sense to require that the determination of the weights in this model be through a process of adaptive selection involving environmental and contextual factors, and the accessing of the agent’s memory.
6. Conclusions
As I emphasized earlier, the model assumes that at least some complex systems possess a capacity of choice. That may or may not be a valid assumption. However, it should be clear that human behavior is at least partly guided by the assumption that we
do have free will. Indeed, most legal systems are built on the basis of that assumption. As O’Connor pointed out, then, the freedom that this assumed capacity of choice makes possible should come in degrees and can vary in time with individual agents [
11]. Freedom, in this context, is an action taken by an agent and it is this action that the model presented here aims to capture. Given the increasing importance of artificial intelligence and autonomous systems, it also seems worthwhile to compare such actionable freedom across systems. Could a machine make choices as freely as a human? Might there be a way to measure any difference?
In that sense, this model is one of behavior. It considers a system as being contained within an environment that helps constrain that behavior. To a certain extent, there is a similarity here to the cause and effect repertoires of integrated information theory (IIT) [
24] and, indeed, the relationship is part of a larger research project that is in the early stages. Additional work is required to determine the form of the constant of proportionality in Equation (
9) and determining the exact form for the time function
T. I suspect both may need to be determined through experiment. In addition, the model presented here employs simple Gaussian distributions, but it would be interesting to see if Fermi–Dirac, Bose-Einstein, or other such distributions give substantially different predictions.
Clearly, the problem of free will is deeply tied to the problem of consciousness. As such, any model will include some of the same baggage as models of consciousness including, for instance, how to deal with qualia which appear to play a role in weighting the choices. More likely than not, the model will need considerable revision and alteration in order to truly capture what we think of when we think of free will, but it at least provides a basic framework for thinking about the problem.


{kind=link}
{kind=link}
{kind=link}



