Extravaganza Feature Papers on Hot Topics in Machine Learning and Knowledge Extraction
Share This Topical Collection
Editor
 Prof. Dr. Andreas Holzinger
Prof. Dr. Andreas Holzinger
Prof. Dr. Andreas Holzinger
E-Mail
Website
Collection Editor
1. Human-Centered AI Lab, Institute of Forest Engineering, Department of Forest and Soil Sciences, University of Natural Resources and Life Sciences, 1190 Vienna, Austria
2. xAI Lab, Alberta Machine Intelligence Institute, University of Alberta, Edmonton, AB T5J 3B1, Canada
Interests: human-centered AI; explainable AI; interactive machine-learning; decision support; trustworthy AI
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
As Editors-in-Chief of MAKE, we are pleased to announce a call for papers for the upcoming Feature Papers Topical Collection. This is a collection of high-quality open access papers written by Editorial Board Members or those invited by the editorial office and the Editor-in-Chief. Submitted work should take the form of long research papers (or survey or review papers) with a full and detailed summary of the author’s own work carried out so far.
Papers accepted for this Special Issue will be published free of charge in open access format. You are welcome to send short proposals for submissions of feature papers to our Editorial Office (make@mdpi.com).
Prof. Dr. Andreas Holzinger
Collection Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Machine Learning and Knowledge Extraction is an international peer-reviewed open access monthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1800 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Published Papers (47 papers)
Open AccessArticle
Bregman–Hausdorff Divergence: Strengthening the Connections Between Computational Geometry and Machine Learning
by
Tuyen Pham, Hana Dal Poz Kouřimská and Hubert Wagner
Cited by 2 | Viewed by 2514
Abstract
The purpose of this paper is twofold. On a technical side, we propose an extension of the Hausdorff distance from metric spaces to spaces equipped with asymmetric distance measures. Specifically, we focus on extending it to the family of Bregman divergences, which includes
[...] Read more.
The purpose of this paper is twofold. On a technical side, we propose an extension of the Hausdorff distance from metric spaces to spaces equipped with asymmetric distance measures. Specifically, we focus on extending it to the family of Bregman divergences, which includes the popular Kullback–Leibler divergence (also known as relative entropy). The resulting dissimilarity measure is called a Bregman–Hausdorff divergence and compares two collections of vectors—without assuming any pairing or alignment between their elements. We propose new algorithms for computing Bregman–Hausdorff divergences based on a recently developed Kd-tree data structure for nearest neighbor search with respect to Bregman divergences. The algorithms are surprisingly efficient even for large inputs with hundreds of dimensions. As a benchmark, we use the new divergence to compare two collections of probabilistic predictions produced by different machine learning models trained using the relative entropy loss. In addition to the introduction of this technical concept, we provide a survey. It outlines the basics of Bregman geometry, and motivated the Kullback–Leibler divergence using concepts from information theory. We also describe computational geometric algorithms that have been extended to this geometry, focusing on algorithms relevant for machine learning.
Full article
►▼
Show Figures
Open AccessArticle
Multimodal Deep Learning for Android Malware Classification
by
James Arrowsmith, Teo Susnjak and Julian Jang-Jaccard
Cited by 7 | Viewed by 6747
Abstract
This study investigates the integration of diverse data modalities within deep learning ensembles for Android malware classification. Android applications can be represented as binary images and function call graphs, each offering complementary perspectives on the executable. We synthesise these modalities by combining predictions
[...] Read more.
This study investigates the integration of diverse data modalities within deep learning ensembles for Android malware classification. Android applications can be represented as binary images and function call graphs, each offering complementary perspectives on the executable. We synthesise these modalities by combining predictions from convolutional and graph neural networks with a multilayer perceptron. Empirical results demonstrate that multimodal models outperform their unimodal counterparts while remaining highly efficient. For instance, integrating a plain CNN with 83.1% accuracy and a GCN with 80.6% accuracy boosts overall accuracy to 88.3%. DenseNet-GIN achieves 90.6% accuracy, with no further improvement obtained by expanding this ensemble to four models. Based on our findings, we advocate for the flexible development of modalities to capture distinct aspects of applications and for the design of algorithms that effectively integrate this information.
Full article
►▼
Show Figures
Open AccessArticle
Investigating the Performance of Retrieval-Augmented Generation and Domain-Specific Fine-Tuning for the Development of AI-Driven Knowledge-Based Systems
by
Róbert Lakatos, Péter Pollner, András Hajdu and Tamás Joó
Cited by 25 | Viewed by 9846
Abstract
Generative large language models (LLMs) have revolutionized the development of knowledge-based systems, enabling new possibilities in applications like ChatGPT, Bing, and Gemini. Two key strategies for domain adaptation in these systems are Domain-Specific Fine-Tuning (DFT) and Retrieval-Augmented Generation (RAG). In this study, we
[...] Read more.
Generative large language models (LLMs) have revolutionized the development of knowledge-based systems, enabling new possibilities in applications like ChatGPT, Bing, and Gemini. Two key strategies for domain adaptation in these systems are Domain-Specific Fine-Tuning (DFT) and Retrieval-Augmented Generation (RAG). In this study, we evaluate the performance of RAG and DFT on several LLM architectures, including GPT-J-6B, OPT-6.7B, LLaMA, and LLaMA-2. We use the ROUGE, BLEU, and METEOR scores to evaluate the performance of the models. We also measure the performance of the models with our own designed cosine similarity-based Coverage Score (CS). Our results, based on experiments across multiple datasets, show that RAG-based systems consistently outperform those fine-tuned with DFT. Specifically, RAG models outperform DFT by an average of 17% in ROUGE, 13% in BLEU, and 36% in CS. At the same time, DFT achieves only a modest advantage in METEOR, suggesting slightly better creative capabilities. We also highlight the challenges of integrating RAG with DFT, as such integration can lead to performance degradation. Furthermore, we propose a simplified RAG-based architecture that maximizes efficiency and reduces hallucination, underscoring the advantages of RAG in building reliable, domain-adapted knowledge systems.
Full article
►▼
Show Figures
Open AccessArticle
Triple Down on Robustness: Understanding the Impact of Adversarial Triplet Compositions on Adversarial Robustness
by
Sander Joos, Tim Van hamme, Willem Verheyen, Davy Preuveneers and Wouter Joosen
Viewed by 1529
Abstract
Adversarial training, a widely used technique for fortifying the robustness of machine learning models, has seen its effectiveness further bolstered by modifying loss functions or incorporating additional terms into the training objective. While these adaptations are validated through empirical studies, they lack a
[...] Read more.
Adversarial training, a widely used technique for fortifying the robustness of machine learning models, has seen its effectiveness further bolstered by modifying loss functions or incorporating additional terms into the training objective. While these adaptations are validated through empirical studies, they lack a solid theoretical basis to explain the models’ secure and robust behavior. In this paper, we investigate the integration of adversarial triplets within the adversarial training framework, a method previously shown to enhance robustness. However, the reasons behind this increased robustness are poorly understood, and the impact of different adversarial triplet configurations remains unclear. To address this gap, we utilize the robust and non-robust features framework to analyze how various adversarial triplet compositions influence robustness, providing deeper insights into the robustness guarantees of this approach. Specifically, we introduce a novel framework that explains how different compositions of adversarial triplets lead to distinct training dynamics, thereby affecting the model’s adversarial robustness. We validate our theoretical findings through empirical analysis, demonstrating that our framework accurately characterizes the effects of adversarial triplets on the training process. Our results offer a comprehensive explanation of how adversarial triplets influence the security and robustness of models, providing a theoretical foundation for methods that employ adversarial triplets to improve robustness. This research not only enhances our theoretical understanding but also has practical implications for developing more robust machine learning models.
Full article
►▼
Show Figures
Open AccessArticle
Unsupervised Word Sense Disambiguation Using Transformer’s Attention Mechanism
by
Radu Ion, Vasile Păiș, Verginica Barbu Mititelu, Elena Irimia, Maria Mitrofan, Valentin Badea and Dan Tufiș
Cited by 4 | Viewed by 3856
Abstract
Transformer models produce advanced text representations that have been used to break through the hard challenge of natural language understanding. Using the Transformer’s attention mechanism, which acts as a language learning memory, trained on tens of billions of words, a word sense disambiguation
[...] Read more.
Transformer models produce advanced text representations that have been used to break through the hard challenge of natural language understanding. Using the Transformer’s attention mechanism, which acts as a language learning memory, trained on tens of billions of words, a word sense disambiguation (WSD) algorithm can now construct a more faithful vectorial representation of the context of a word to be disambiguated. Working with a set of 34 lemmas of nouns, verbs, adjectives and adverbs selected from the National Reference Corpus of Romanian (CoRoLa), we show that using BERT’s attention heads at all hidden layers, we can devise contextual vectors of the target lemma that produce better clusters of lemma’s senses than the ones obtained with standard BERT embeddings. If we automatically translate the Romanian example sentences of the target lemma into English, we show that we can reliably infer the number of senses with which the target lemma appears in the CoRoLa. We also describe an unsupervised WSD algorithm that, using a Romanian BERT model and a few example sentences of the target lemma’s senses, can label the Romanian induced sense clusters with the appropriate sense labels, with an average accuracy of 64%.
Full article
Open AccessArticle
Reliable and Faithful Generative Explainers for Graph Neural Networks
by
Yiqiao Li, Jianlong Zhou, Boyuan Zheng, Niusha Shafiabady and Fang Chen
Cited by 6 | Viewed by 3571
Abstract
Graph neural networks (GNNs) have been effectively implemented in a variety of real-world applications, although their underlying work mechanisms remain a mystery. To unveil this mystery and advocate for trustworthy decision-making, many GNN explainers have been proposed. However, existing explainers often face significant
[...] Read more.
Graph neural networks (GNNs) have been effectively implemented in a variety of real-world applications, although their underlying work mechanisms remain a mystery. To unveil this mystery and advocate for trustworthy decision-making, many GNN explainers have been proposed. However, existing explainers often face significant challenges, such as the following: (1) explanations being tied to specific instances; (2) limited generalisability to unseen graphs; (3) potential generation of invalid graph structures; and (4) restrictions to particular tasks (e.g., node classification, graph classification). To address these challenges, we propose a novel explainer, GAN-GNNExplainer, which employs a generator to produce explanations and a discriminator to oversee the generation process, enhancing the reliability of the outputs. Despite its advantages, GAN-GNNExplainer still struggles with generating faithful explanations and underperforms on real-world datasets. To overcome these shortcomings, we introduce ACGAN-GNNExplainer, an approach that improves upon GAN-GNNExplainer by using a more robust discriminator that consistently monitors the generation process, thereby producing explanations that are both reliable and faithful. Extensive experiments on both synthetic and real-world graph datasets demonstrate the superiority of our proposed methods over existing GNN explainers.
Full article
►▼
Show Figures
Open AccessArticle
Prediction of Drivers’ Red-Light Running Behaviour in Connected Vehicle Environments Using Deep Recurrent Neural Networks
by
Md Mostafizur Rahman Komol, Mohammed Elhenawy, Jack Pinnow, Mahmoud Masoud, Andry Rakotonirainy, Sebastien Glaser, Merle Wood and David Alderson
Cited by 2 | Viewed by 3887
Abstract
Red-light running at signalised intersections poses a significant safety risk, necessitating advanced predictive technologies to predict red-light violation behaviour, especially for advanced red-light warning (ARLW) systems. This research leverages Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) models to forecast the red-light
[...] Read more.
Red-light running at signalised intersections poses a significant safety risk, necessitating advanced predictive technologies to predict red-light violation behaviour, especially for advanced red-light warning (ARLW) systems. This research leverages Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) models to forecast the red-light running and stopping behaviours of drivers in connected vehicles. We utilised data from the Ipswich Connected Vehicle Pilot (ICVP) in Queensland, Australia, which gathered naturalistic driving data from 355 connected vehicles at 29 signalised intersections. These vehicles broadcast Cooperative Awareness Messages (CAM) within the Cooperative Intelligent Transport Systems (C-ITS), providing kinematic inputs such as vehicle speed, speed limits, longitudinal and lateral accelerations, and yaw rate. These variables were monitored at 100-millisecond intervals for durations from 1 to 4 s before reaching various distances from the stop line. Our results indicate that the LSTM model outperforms the GRU in predicting both red-light running and stopping behaviours with high accuracy. However, the pre-trained GRU model performs better in predicting red-light running specifically, making it valuable in applications requiring early violation prediction. Implementing these models can enhance red-light violation countermeasures, such as dynamic all-red extension (DARE), decreasing the likelihood of severe collisions and enhancing road users’ safety.
Full article
►▼
Show Figures
Open AccessArticle
Continual Semi-Supervised Malware Detection
by
Matthew Chin and Roberto Corizzo
Cited by 3 | Viewed by 3592
Abstract
Detecting malware has become extremely important with the increasing exposure of computational systems and mobile devices to online services. However, the rapidly evolving nature of malicious software makes this task particularly challenging. Despite the significant number of machine learning works for malware detection
[...] Read more.
Detecting malware has become extremely important with the increasing exposure of computational systems and mobile devices to online services. However, the rapidly evolving nature of malicious software makes this task particularly challenging. Despite the significant number of machine learning works for malware detection proposed in the last few years, limited interest has been devoted to continual learning approaches, which could allow models to showcase effective performance in challenging and dynamic scenarios while being computationally efficient. Moreover, most of the research works proposed thus far adopt a fully supervised setting, which relies on fully labelled data and appears to be impractical in a rapidly evolving malware landscape. In this paper, we address malware detection from a continual semi-supervised one-class learning perspective, which only requires normal/benign data and empowers models with a greater degree of flexibility, allowing them to detect multiple malware types with different morphology. Specifically, we assess the effectiveness of two replay strategies on anomaly detection models and analyze their performance in continual learning scenarios with three popular malware detection datasets (CIC-AndMal2017, CIC-MalMem-2022, and CIC-Evasive-PDFMal2022). Our evaluation shows that replay-based strategies can achieve competitive performance in terms of continual ROC-AUC with respect to the considered baselines and bring new perspectives and insights on this topic.
Full article
►▼
Show Figures
Open AccessArticle
Node-Centric Pruning: A Novel Graph Reduction Approach
by
Hossein Shokouhinejad, Roozbeh Razavi-Far, Griffin Higgins and Ali A. Ghorbani
Cited by 6 | Viewed by 4880
Abstract
In the era of rapidly expanding graph-based applications, efficiently managing large-scale graphs has become a critical challenge. This paper introduces an innovative graph reduction technique, Node-Centric Pruning (NCP), designed to simplify complex graphs while preserving their essential structural properties, thereby enhancing the scalability
[...] Read more.
In the era of rapidly expanding graph-based applications, efficiently managing large-scale graphs has become a critical challenge. This paper introduces an innovative graph reduction technique, Node-Centric Pruning (NCP), designed to simplify complex graphs while preserving their essential structural properties, thereby enhancing the scalability and maintaining performance of downstream Graph Neural Networks (GNNs). Our proposed approach strategically prunes less significant nodes and refines the graph structure, ensuring that critical topological properties are maintained. By carefully evaluating node significance based on advanced connectivity metrics, our method preserves the topology and ensures high performance in downstream machine learning tasks. Extensive experimentation demonstrates that our proposed method not only maintains the integrity and functionality of the original graph but also significantly improves the computational efficiency and preserves the classification performance of GNNs. These enhancements in computational efficiency and resource management make our technique particularly valuable for deploying GNNs in real-world applications, where handling large, complex datasets effectively is crucial. This advancement represents a significant step toward making GNNs more practical and effective for a wide range of applications in both industry and academia.
Full article
►▼
Show Figures
Open AccessArticle
A Study on Text Classification in the Age of Large Language Models
by
Paul Trust and Rosane Minghim
Cited by 9 | Viewed by 9893
Abstract
Large language models (LLMs) have recently made significant advances, excelling in tasks like question answering, summarization, and machine translation. However, their enormous size and hardware requirements make them less accessible to many in the machine learning community. To address this, techniques such as
[...] Read more.
Large language models (LLMs) have recently made significant advances, excelling in tasks like question answering, summarization, and machine translation. However, their enormous size and hardware requirements make them less accessible to many in the machine learning community. To address this, techniques such as quantization, prefix tuning, weak supervision, low-rank adaptation, and prompting have been developed to customize these models for specific applications. While these methods have mainly improved text generation, their implications for the text classification task are not thoroughly studied. Our research intends to bridge this gap by investigating how variations like model size, pre-training objectives, quantization, low-rank adaptation, prompting, and various hyperparameters influence text classification tasks. Our overall conclusions show the following: 1—even with synthetic labels, fine-tuning works better than prompting techniques, and increasing model size does not always improve classification performance; 2—discriminatively trained models generally perform better than generatively pre-trained models; and 3—fine-tuning models at 16-bit precision works much better than using 8-bit or 4-bit models, but the performance drop from 8-bit to 4-bit is smaller than from 16-bit to 8-bit. In another scale of our study, we conducted experiments with different settings for low-rank adaptation (LoRA) and quantization, finding that increasing LoRA dropout negatively affects classification performance. We did not find a clear link between the LoRA attention dimension (rank) and performance, observing only small differences between standard LoRA and its variants like rank-stabilized LoRA and weight-decomposed LoRA. Additional observations to support model setup for classification tasks are presented in our analyses.
Full article
►▼
Show Figures
Open AccessArticle
Lexical Error Guard: Leveraging Large Language Models for Enhanced ASR Error Correction
by
Mei Si, Omar Cobas and Michael Fababeir
Cited by 4 | Viewed by 7120
Abstract
Error correction is a vital element in modern automatic speech recognition (ASR) systems. A significant portion of ASR error correction work is closely integrated within specific ASR systems, which creates challenges for adapting these solutions to different ASR frameworks. This research introduces Lexical
[...] Read more.
Error correction is a vital element in modern automatic speech recognition (ASR) systems. A significant portion of ASR error correction work is closely integrated within specific ASR systems, which creates challenges for adapting these solutions to different ASR frameworks. This research introduces Lexical Error Guard (LEG), which leverages the extensive pre-trained knowledge of large language models (LLMs) and employs instructional learning to create an adaptable error correction system compatible with various ASR platforms. Additionally, a parameter-efficient fine-tuning method is utilized using quantized low-rank adaptation (QLoRA) to facilitate fast training of the system. Tested on the LibriSpeech data corpus, the results indicate that LEG improves ASR results when used with various Whisper model sizes. Improvements in WER are made, with a decrease from 2.27% to 2.21% on the “Test Clean” dataset for Whisper Large with beam search. Improvements on the “Test Other” dataset for Whisper Large with beam search are also made, from 4.93% to 4.72%.
Full article
►▼
Show Figures
Open AccessArticle
Towards Self-Conscious AI Using Deep ImageNet Models: Application for Blood Cell Classification
by
Mohamad Abou Ali, Fadi Dornaika and Ignacio Arganda-Carreras
Cited by 1 | Viewed by 4864
Abstract
The exceptional performance of ImageNet competition winners in image classification has led AI researchers to repurpose these models for a whole range of tasks using transfer learning (TL). TL has been hailed for boosting performance, shortening learning time and reducing computational effort. Despite
[...] Read more.
The exceptional performance of ImageNet competition winners in image classification has led AI researchers to repurpose these models for a whole range of tasks using transfer learning (TL). TL has been hailed for boosting performance, shortening learning time and reducing computational effort. Despite these benefits, issues such as data sparsity and the misrepresentation of classes can diminish these gains, occasionally leading to misleading TL accuracy scores. This research explores the innovative concept of endowing ImageNet models with a self-awareness that enables them to recognize their own accumulated knowledge and experience. Such self-awareness is expected to improve their adaptability in various domains. We conduct a case study using two different datasets, PBC and BCCD, which focus on blood cell classification. The PBC dataset provides high-resolution images with abundant data, while the BCCD dataset is hindered by limited data and inferior image quality. To compensate for these discrepancies, we use data augmentation for BCCD and undersampling for both datasets to achieve balance. Subsequent pre-processing generates datasets of different size and quality, all geared towards blood cell classification. We extend conventional evaluation tools with novel metrics—“accuracy difference” and “loss difference”—to detect overfitting or underfitting and evaluate their utility as potential indicators for learning behavior and promoting the self-confidence of ImageNet models. Our results show that these metrics effectively track learning progress and improve the reliability and overall performance of ImageNet models in new applications. This study highlights the transformative potential of turning ImageNet models into self-aware entities that significantly improve their robustness and efficiency in various AI tasks. This groundbreaking approach opens new perspectives for increasing the effectiveness of transfer learning in real-world AI implementations.
Full article
►▼
Show Figures
Open AccessArticle
Systematic Analysis of Retrieval-Augmented Generation-Based LLMs for Medical Chatbot Applications
by
Arunabh Bora and Heriberto Cuayáhuitl
Cited by 41 | Viewed by 17629
Abstract
Artificial Intelligence (AI) has the potential to revolutionise the medical and healthcare sectors. AI and related technologies could significantly address some supply-and-demand challenges in the healthcare system, such as medical AI assistants, chatbots and robots. This paper focuses on tailoring LLMs to medical
[...] Read more.
Artificial Intelligence (AI) has the potential to revolutionise the medical and healthcare sectors. AI and related technologies could significantly address some supply-and-demand challenges in the healthcare system, such as medical AI assistants, chatbots and robots. This paper focuses on tailoring LLMs to medical data utilising a Retrieval-Augmented Generation (RAG) database to evaluate their performance in a computationally resource-constrained environment. Existing studies primarily focus on fine-tuning LLMs on medical data, but this paper combines RAG and fine-tuned models and compares them against base models using RAG or only fine-tuning. Open-source LLMs (Flan-T5-Large, LLaMA-2-7B, and Mistral-7B) are fine-tuned using the medical datasets Meadow-MedQA and MedMCQA. Experiments are reported for response generation and multiple-choice question answering. The latter uses two distinct methodologies: Type A, as standard question answering via direct choice selection; and Type B, as language generation and probability confidence score generation of choices available. Results in the medical domain revealed that Fine-tuning and RAG are crucial for improved performance, and that methodology Type A outperforms Type B.
Full article
►▼
Show Figures
Open AccessArticle
Bayesian Optimization Using Simulation-Based Multiple Information Sources over Combinatorial Structures
by
Antonio Sabbatella, Andrea Ponti, Antonio Candelieri and Francesco Archetti
Cited by 4 | Viewed by 4724
Abstract
Bayesian optimization due to its flexibility and sample efficiency has become a standard approach for simulation optimization. To reduce this problem, one can resort to cheaper surrogates of the objective function. Examples are ubiquitous, from protein engineering or material science to tuning machine
[...] Read more.
Bayesian optimization due to its flexibility and sample efficiency has become a standard approach for simulation optimization. To reduce this problem, one can resort to cheaper surrogates of the objective function. Examples are ubiquitous, from protein engineering or material science to tuning machine learning algorithms, where one could use a subset of the full training set or even a smaller related dataset. Cheap information sources in the optimization scheme have been studied in the literature as the multi-fidelity optimization problem. Of course, cheaper sources may hold some promise toward tractability, but cheaper models offer an incomplete model inducing unknown bias and epistemic uncertainty. In this manuscript, we are concerned with the discrete case, where
is the value of the performance measure associated with the environmental condition
and
represents the relevance of the condition
(i.e., the probability of occurrence or the fraction of time this condition occurs). The main contribution of this paper is the proposal of a Gaussian-based framework, called augmented Gaussian process (AGP), based on sparsification, originally proposed for continuous functions and its generalization in this paper to stochastic optimization using different risk profiles for combinatorial optimization. The AGP leverages sample and cost-efficient Bayesian optimization (BO) of multiple information sources and supports a new acquisition function to select the new source–location pair considering the cost of the source and the (location-dependent) model discrepancy. An extensive set of computational results supports risk-aware optimization based on CVaR (conditional value-at-risk). Computational experiments confirm the actual performance of the MISO-AGP method and the hyperparameter optimization on benchmark functions and real-world problems.
Full article
►▼
Show Figures
Open AccessReview
Not in My Face: Challenges and Ethical Considerations in Automatic Face Emotion Recognition Technology
by
Martina Mattioli and Federico Cabitza
Cited by 28 | Viewed by 16936
Abstract
Automatic Face Emotion Recognition (FER) technologies have become widespread in various applications, including surveillance, human–computer interaction, and health care. However, these systems are built on the basis of controversial psychological models that claim facial expressions are universally linked to specific emotions—a concept often
[...] Read more.
Automatic Face Emotion Recognition (FER) technologies have become widespread in various applications, including surveillance, human–computer interaction, and health care. However, these systems are built on the basis of controversial psychological models that claim facial expressions are universally linked to specific emotions—a concept often referred to as the “universality hypothesis”. Recent research highlights significant variability in how emotions are expressed and perceived across different cultures and contexts. This paper identifies a gap in evaluating the reliability and ethical implications of these systems, given their potential biases and privacy concerns. Here, we report a comprehensive review of the current debates surrounding FER, with a focus on cultural and social biases, the ethical implications of their application, and their technical reliability. Moreover, we propose a classification that organizes these perspectives into a three-part taxonomy. Key findings show that FER systems are built with limited datasets with potential annotation biases, in addition to lacking cultural context and exhibiting significant unreliability, with misclassification rates influenced by race and background. In some cases, the systems’ errors lead to significant ethical concerns, particularly in sensitive settings such as law enforcement and surveillance. This study calls for more rigorous evaluation frameworks and regulatory oversight, ensuring that the deployment of FER systems does not infringe on individual rights or perpetuate biases.
Full article
►▼
Show Figures
Open AccessArticle
A Multi-Objective Framework for Balancing Fairness and Accuracy in Debiasing Machine Learning Models
by
Rashmi Nagpal, Ariba Khan, Mihir Borkar and Amar Gupta
Cited by 9 | Viewed by 7641
Abstract
Machine learning algorithms significantly impact decision-making in high-stakes domains, necessitating a balance between fairness and accuracy. This study introduces an in-processing, multi-objective framework that leverages the Reject Option Classification (ROC) algorithm to simultaneously optimize fairness and accuracy while safeguarding protected attributes such as
[...] Read more.
Machine learning algorithms significantly impact decision-making in high-stakes domains, necessitating a balance between fairness and accuracy. This study introduces an in-processing, multi-objective framework that leverages the Reject Option Classification (ROC) algorithm to simultaneously optimize fairness and accuracy while safeguarding protected attributes such as age and gender. Our approach seeks a multi-objective optimization solution that balances accuracy, group fairness loss, and individual fairness loss. The framework integrates fairness objectives without relying on a weighted summation method, instead focusing on directly optimizing the trade-offs. Empirical evaluations on publicly available datasets, including German Credit, Adult Income, and COMPAS, reveal several significant findings: the ROC-based approach demonstrates superior performance, achieving an accuracy of 94.29%, an individual fairness loss of 0.04, and a group fairness loss of 0.06 on the German Credit dataset. These results underscore the effectiveness of our framework, particularly the ROC component, in enhancing both the fairness and performance of machine learning models.
Full article
►▼
Show Figures
Open AccessArticle
A Data Science and Sports Analytics Approach to Decode Clutch Dynamics in the Last Minutes of NBA Games
by
Vangelis Sarlis, Dimitrios Gerakas and Christos Tjortjis
Cited by 23 | Viewed by 13838
Abstract
This research investigates clutch performance in the National Basketball Association (NBA) with a focus on the final minutes of contested games. By employing advanced data science techniques, we aim to identify key factors that enhance winning probabilities during these critical moments. The study
[...] Read more.
This research investigates clutch performance in the National Basketball Association (NBA) with a focus on the final minutes of contested games. By employing advanced data science techniques, we aim to identify key factors that enhance winning probabilities during these critical moments. The study introduces the Estimation of Clutch Competency (EoCC) metric, which is a novel formula designed to evaluate players’ impact under pressure. Examining player performance statistics over twenty seasons, this research addresses a significant gap in the literature regarding the quantification of clutch moments and challenges conventional wisdom in basketball analytics. Our findings deal valuable insights into player efficiency during the final minutes and its impact on the probabilities of a positive outcome. The EoCC metric’s validation through comparison with the NBA Clutch Player of the Year voting results demonstrates its effectiveness in identifying top performers in high-pressure situations. Leveraging state-of-the-art data science techniques and algorithms, this study analyzes play data to uncover key factors contributing to a team’s success in pivotal moments. This research not only enhances the theoretical understanding of clutch dynamics but also provides practical insights for coaches, analysts, and the broader sports community. It contributes to more informed decision making in high-stakes basketball environments, advancing the field of sports analytics.
Full article
►▼
Show Figures
Open AccessArticle
Assessing Fine-Tuned NER Models with Limited Data in French: Automating Detection of New Technologies, Technological Domains, and Startup Names in Renewable Energy
by
Connor MacLean and Denis Cavallucci
Cited by 4 | Viewed by 8288
Abstract
Achieving carbon neutrality by 2050 requires unprecedented technological, economic, and sociological changes. With time as a scarce resource, it is crucial to base decisions on relevant facts and information to avoid misdirection. This study aims to help decision makers quickly find relevant information
[...] Read more.
Achieving carbon neutrality by 2050 requires unprecedented technological, economic, and sociological changes. With time as a scarce resource, it is crucial to base decisions on relevant facts and information to avoid misdirection. This study aims to help decision makers quickly find relevant information related to companies and organizations in the renewable energy sector. In this study, we propose fine-tuning five RNN and transformer models trained for French on a new category, “TECH”. This category is used to classify technological domains and new products. In addition, as the model is fine-tuned on news related to startups, we note an improvement in the detection of startup and company names in the “ORG” category. We further explore the capacities of the most effective model to accurately predict entities using a small amount of training data. We show the progression of the model from being trained on several hundred to several thousand annotations. This analysis allows us to demonstrate the potential of these models to extract insights without large corpora, allowing us to reduce the long process of annotating custom training data. This approach is used to automatically extract new company mentions as well as to extract technologies and technology domains that are currently being discussed in the news in order to better analyze industry trends. This approach further allows to group together mentions of specific energy domains with the companies that are actively developing new technologies in the field.
Full article
►▼
Show Figures
Open AccessArticle
Optimal Knowledge Distillation through Non-Heuristic Control of Dark Knowledge
by
Darian Onchis, Codruta Istin and Ioan Samuila
Cited by 1 | Viewed by 3534
Abstract
In this paper, a method is introduced to control the dark knowledge values also known as soft targets, with the purpose of improving the training by knowledge distillation for multi-class classification tasks. Knowledge distillation effectively transfers knowledge from a larger model to a
[...] Read more.
In this paper, a method is introduced to control the dark knowledge values also known as soft targets, with the purpose of improving the training by knowledge distillation for multi-class classification tasks. Knowledge distillation effectively transfers knowledge from a larger model to a smaller model to achieve efficient, fast, and generalizable performance while retaining much of the original accuracy. The majority of deep neural models used for classification tasks append a SoftMax layer to generate output probabilities and it is usual to take the highest score and consider it the inference of the model, while the rest of the probability values are generally ignored. The focus is on those probabilities as carriers of dark knowledge and our aim is to quantify the relevance of dark knowledge, not heuristically as provided in the literature so far, but with an inductive proof on the SoftMax operational limits. These limits are further pushed by using an incremental decision tree with information gain split. The user can set a desired precision and an accuracy level to obtain a maximal temperature setting for a continual classification process. Moreover, by fitting both the hard targets and the soft targets, one obtains an optimal knowledge distillation effect that mitigates better catastrophic forgetting. The strengths of our method come from the possibility of controlling the amount of distillation transferred non-heuristically and the agnostic application of this model-independent study.
Full article
►▼
Show Figures
Open AccessArticle
Visual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges
by
Mohammed Elhenawy, Ahmad Abutahoun, Taqwa I. Alhadidi, Ahmed Jaber, Huthaifa I. Ashqar, Shadi Jaradat, Ahmed Abdelhay, Sebastien Glaser and Andry Rakotonirainy
Cited by 23 | Viewed by 4556
Abstract
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray
[...] Read more.
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray point distributions on a two-dimensional plane. We introduce a novel approach employing multiple specialized agents within the MLLM framework, each dedicated to optimizing solutions for these combinatorial challenges. We benchmarked our multi-agent model solutions against the Google OR tools, which served as the baseline for comparison. The results demonstrated that both multi-agent models—Multi-Agent 1, which includes the initializer, critic, and scorer agents, and Multi-Agent 2, which comprises only the initializer and critic agents—significantly improved the solution quality for TSP and mTSP problems. Multi-Agent 1 excelled in environments requiring detailed route refinement and evaluation, providing a robust framework for sophisticated optimizations. In contrast, Multi-Agent 2, focusing on iterative refinements by the initializer and critic, proved effective for rapid decision-making scenarios. These experiments yield promising outcomes, showcasing the robust visual reasoning capabilities of MLLMs in addressing diverse combinatorial problems. The findings underscore the potential of MLLMs as powerful tools in computational optimization, offering insights that could inspire further advancements in this promising field.
Full article
►▼
Show Figures
Open AccessArticle
Enhanced Graph Representation Convolution: Effective Inferring Gene Regulatory Network Using Graph Convolution Network with Self-Attention Graph Pooling Layer
by
Duaa Mohammad Alawad, Ataur Katebi and Md Tamjidul Hoque
Cited by 4 | Viewed by 3322
Abstract
Studying gene regulatory networks (GRNs) is paramount for unraveling the complexities of biological processes and their associated disorders, such as diabetes, cancer, and Alzheimer’s disease. Recent advancements in computational biology have aimed to enhance the inference of GRNs from gene expression data, a
[...] Read more.
Studying gene regulatory networks (GRNs) is paramount for unraveling the complexities of biological processes and their associated disorders, such as diabetes, cancer, and Alzheimer’s disease. Recent advancements in computational biology have aimed to enhance the inference of GRNs from gene expression data, a non-trivial task given the networks’ intricate nature. The challenge lies in accurately identifying the myriad interactions among transcription factors and target genes, which govern cellular functions. This research introduces a cutting-edge technique, EGRC (Effective GRN Inference applying Graph Convolution with Self-Attention Graph Pooling), which innovatively conceptualizes GRN reconstruction as a graph classification problem, where the task is to discern the links within subgraphs that encapsulate pairs of nodes. By leveraging Spearman’s correlation, we generate potential subgraphs that bring nonlinear associations between transcription factors and their targets to light. We use mutual information to enhance this, capturing a broader spectrum of gene interactions. Our methodology bifurcates these subgraphs into ‘Positive’ and ‘Negative’ categories. ‘Positive’ subgraphs are those where a transcription factor and its target gene are connected, including interactions among their neighbors. ‘Negative’ subgraphs, conversely, denote pairs without a direct connection. EGRC utilizes dual graph convolution network (GCN) models that exploit node attributes from gene expression profiles and graph embedding techniques to classify these. The performance of EGRC is substantiated by comprehensive evaluations using the DREAM5 datasets. Notably, EGRC attained an AUROC of 0.856 and an AUPR of 0.841 on the
E. coli dataset. In contrast, the in silico dataset achieved an AUROC of 0.5058 and an AUPR of 0.958. Furthermore, on the
S. cerevisiae dataset, EGRC recorded an AUROC of 0.823 and an AUPR of 0.822. These results underscore the robustness of EGRC in accurately inferring GRNs across various organisms. The advanced performance of EGRC represents a substantial advancement in the field, promising to deepen our comprehension of the intricate biological processes and their implications in both health and disease.
Full article
►▼
Show Figures
Open AccessArticle
Diverse Machine Learning for Forecasting Goal-Scoring Likelihood in Elite Football Leagues
by
Christina Markopoulou, George Papageorgiou and Christos Tjortjis
Cited by 9 | Viewed by 12037
Abstract
The field of sports analytics has grown rapidly, with a primary focus on performance forecasting, enhancing the understanding of player capabilities, and indirectly benefiting team strategies and player development. This work aims to forecast and comparatively evaluate players’ goal-scoring likelihood in four elite
[...] Read more.
The field of sports analytics has grown rapidly, with a primary focus on performance forecasting, enhancing the understanding of player capabilities, and indirectly benefiting team strategies and player development. This work aims to forecast and comparatively evaluate players’ goal-scoring likelihood in four elite football leagues (Premier League, Bundesliga, La Liga, and Serie A) by mining advanced statistics from 2017 to 2023. Six types of machine learning (ML) models were developed and tested individually through experiments on the comprehensive datasets collected for these leagues. We also tested the upper 30th percentile of the best-performing players based on their performance in the last season, with varied features evaluated to enhance prediction accuracy in distinct scenarios. The results offer insights into the forecasting abilities of those leagues, identifying the best forecasting methodologies and the factors that most significantly contribute to the prediction of players’ goal-scoring. XGBoost consistently outperformed other models in most experiments, yielding the most accurate results and leading to a well-generalized model. Notably, when applied to Serie A, it achieved a mean absolute error (MAE) of 1.29. This study provides insights into ML-based performance prediction, advancing the field of player performance forecasting.
Full article
►▼
Show Figures
Open AccessArticle
Learning Effective Good Variables from Physical Data
by
Giulio Barletta, Giovanni Trezza and Eliodoro Chiavazzo
Cited by 2 | Viewed by 2264
Abstract
We assume that a sufficiently large database is available, where a physical property of interest and a number of associated ruling primitive variables or observables are stored. We introduce and test two machine learning approaches to discover possible groups or combinations of primitive
[...] Read more.
We assume that a sufficiently large database is available, where a physical property of interest and a number of associated ruling primitive variables or observables are stored. We introduce and test two machine learning approaches to discover possible groups or combinations of primitive variables, regardless of data origin, being it numerical or experimental: the first approach is based on regression models, whereas the second on classification models. The variable group (here referred to as the new effective good variable) can be considered as successfully found when the physical property of interest is characterized by the following effective invariant behavior: in the first method, invariance of the group implies invariance of the property up to a given accuracy; in the other method, upon partition of the physical property values into two or more classes, invariance of the group implies invariance of the class. For the sake of illustration, the two methods are successfully applied to two popular empirical correlations describing the convective heat transfer phenomenon and to the Newton’s law of universal gravitation.
Full article
►▼
Show Figures
Open AccessSystematic Review
Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures
by
Maisha Binte Rashid, Md Shahidur Rahaman and Pablo Rivas
Cited by 10 | Viewed by 6157
Abstract
Images and text have become essential parts of the multimodal machine learning (MMML) framework in today’s world because data are always available, and technological breakthroughs bring disparate forms together, and while text adds semantic richness and narrative to images, images capture visual subtleties
[...] Read more.
Images and text have become essential parts of the multimodal machine learning (MMML) framework in today’s world because data are always available, and technological breakthroughs bring disparate forms together, and while text adds semantic richness and narrative to images, images capture visual subtleties and emotions. Together, these two media improve knowledge beyond what would be possible with just one revolutionary application. This paper investigates feature extraction and advancement from text and image data using pre-trained models in MMML. It offers a thorough analysis of fusion architectures, outlining text and image data integration and evaluating their overall advantages and effects. Furthermore, it draws attention to the shortcomings and difficulties that MMML currently faces and guides areas that need more research and development. We have gathered 341 research articles from five digital library databases to accomplish this. Following a thorough assessment procedure, we have 88 research papers that enable us to evaluate MMML in detail. Our findings demonstrate that pre-trained models, such as BERT for text and ResNet for images, are predominantly employed for feature extraction due to their robust performance in diverse applications. Fusion techniques, ranging from simple concatenation to advanced attention mechanisms, are extensively adopted to enhance the representation of multimodal data. Despite these advancements, MMML models face significant challenges, including handling noisy data, optimizing dataset size, and ensuring robustness against adversarial attacks. Our findings highlight the necessity for further research to address these challenges, particularly in developing methods to improve the robustness of MMML models.
Full article
►▼
Show Figures
Open AccessArticle
Using Deep Q-Learning to Dynamically Toggle between Push/Pull Actions in Computational Trust Mechanisms
by
Zoi Lygizou and Dimitris Kalles
Cited by 2 | Viewed by 1752
Abstract
Recent work on decentralized computational trust models for open multi-agent systems has resulted in the development of CA, a biologically inspired model which focuses on the trustee’s perspective. This new model addresses a serious unresolved problem in existing trust and reputation models, namely
[...] Read more.
Recent work on decentralized computational trust models for open multi-agent systems has resulted in the development of CA, a biologically inspired model which focuses on the trustee’s perspective. This new model addresses a serious unresolved problem in existing trust and reputation models, namely the inability to handle constantly changing behaviors and agents’ continuous entry and exit from the system. In previous work, we compared CA to FIRE, a well-known trust and reputation model, and found that CA is superior when the trustor population changes, whereas FIRE is more resilient to the trustee population changes. Thus, in this paper, we investigate how the trustors can detect the presence of several dynamic factors in their environment and then decide which trust model to employ in order to maximize utility. We frame this problem as a machine learning problem in a partially observable environment, where the presence of several dynamic factors is not known to the trustor, and we describe how an adaptable trustor can rely on a few measurable features so as to assess the current state of the environment and then use Deep Q-Learning (DQL), in a single-agent reinforcement learning setting, to learn how to adapt to a changing environment. We ran a series of simulation experiments to compare the performance of the adaptable trustor with the performance of trustors using only one model (FIRE or CA) and we show that an adaptable agent is indeed capable of learning when to use each model and, thus, perform consistently in dynamic environments.
Full article
►▼
Show Figures
Open AccessReview
Machine Learning in Geosciences: A Review of Complex Environmental Monitoring Applications
by
Maria Silvia Binetti, Carmine Massarelli and Vito Felice Uricchio
Cited by 40 | Viewed by 12576
Abstract
This is a systematic literature review of the application of machine learning (ML) algorithms in geosciences, with a focus on environmental monitoring applications. ML algorithms, with their ability to analyze vast quantities of data, decipher complex relationships, and predict future events, and they
[...] Read more.
This is a systematic literature review of the application of machine learning (ML) algorithms in geosciences, with a focus on environmental monitoring applications. ML algorithms, with their ability to analyze vast quantities of data, decipher complex relationships, and predict future events, and they offer promising capabilities to implement technologies based on more precise and reliable data processing. This review considers several vulnerable and particularly at-risk themes as landfills, mining activities, the protection of coastal dunes, illegal discharges into water bodies, and the pollution and degradation of soil and water matrices in large industrial complexes. These case studies about environmental monitoring provide an opportunity to better examine the impact of human activities on the environment, with a specific focus on water and soil matrices. The recent literature underscores the increasing importance of ML in these contexts, highlighting a preference for adapted classic models: random forest (RF) (the most widely used), decision trees (DTs), support vector machines (SVMs), artificial neural networks (ANNs), convolutional neural networks (CNNs), principal component analysis (PCA), and much more. In the field of environmental management, the following methodologies offer invaluable insights that can steer strategic planning and decision-making based on more accurate image classification, prediction models, object detection and recognition, map classification, data classification, and environmental variable predictions.
Full article
►▼
Show Figures
Open AccessReview
Bayesian Networks for the Diagnosis and Prognosis of Diseases: A Scoping Review
by
Kristina Polotskaya, Carlos S. Muñoz-Valencia, Alejandro Rabasa, Jose A. Quesada-Rico, Domingo Orozco-Beltrán and Xavier Barber
Cited by 32 | Viewed by 19071
Abstract
Bayesian networks (BNs) are probabilistic graphical models that leverage Bayes’ theorem to portray dependencies and cause-and-effect relationships between variables. These networks have gained prominence in the field of health sciences, particularly in diagnostic processes, by allowing the integration of medical knowledge into models
[...] Read more.
Bayesian networks (BNs) are probabilistic graphical models that leverage Bayes’ theorem to portray dependencies and cause-and-effect relationships between variables. These networks have gained prominence in the field of health sciences, particularly in diagnostic processes, by allowing the integration of medical knowledge into models and addressing uncertainty in a probabilistic manner. Objectives: This review aims to provide an exhaustive overview of the current state of Bayesian networks in disease diagnosis and prognosis. Additionally, it seeks to introduce readers to the fundamental methodology of BNs, emphasising their versatility and applicability across varied medical domains. Employing a meticulous search strategy with MeSH descriptors in diverse scientific databases, we identified 190 relevant references. These were subjected to a rigorous analysis, resulting in the retention of 60 papers for in-depth review. The robustness of our approach minimised the risk of selection bias. Results: The selected studies encompass a wide range of medical areas, providing insights into the statistical methodology, implementation feasibility, and predictive accuracy of BNs, as evidenced by an average area under the curve (AUC) exceeding 75%. The comprehensive analysis underscores the adaptability and efficacy of Bayesian networks in diverse clinical scenarios. The majority of the examined studies demonstrate the potential of BNs as reliable adjuncts to clinical decision-making. The findings of this review affirm the role of Bayesian networks as accessible and versatile artificial intelligence tools in healthcare. They offer a viable solution to address complex medical challenges, facilitating timely and informed decision-making under conditions of uncertainty. The extensive exploration of Bayesian networks presented in this review highlights their significance and growing impact in the realm of disease diagnosis and prognosis. It underscores the need for further research and development to optimise their capabilities and broaden their applicability in addressing diverse and intricate healthcare challenges.
Full article
►▼
Show Figures
Open AccessArticle
Evaluation of AI ChatBots for the Creation of Patient-Informed Consent Sheets
by
Florian Jürgen Raimann, Vanessa Neef, Marie Charlotte Hennighausen, Kai Zacharowski and Armin Niklas Flinspach
Cited by 8 | Viewed by 3928
Abstract
Introduction: Large language models (LLMs), such as ChatGPT, are a topic of major public interest, and their potential benefits and threats are a subject of discussion. The potential contribution of these models to health care is widely discussed. However, few studies to date
[...] Read more.
Introduction: Large language models (LLMs), such as ChatGPT, are a topic of major public interest, and their potential benefits and threats are a subject of discussion. The potential contribution of these models to health care is widely discussed. However, few studies to date have examined LLMs. For example, the potential use of LLMs in (individualized) informed consent remains unclear.
Methods: We analyzed the performance of the LLMs ChatGPT 3.5, ChatGPT 4.0, and Gemini with regard to their ability to create an information sheet for six basic anesthesiologic procedures in response to corresponding questions. We performed multiple attempts to create forms for anesthesia and analyzed the results checklists based on existing standard sheets.
Results: None of the LLMs tested were able to create a legally compliant information sheet for any basic anesthesiologic procedure. Overall, fewer than one-third of the risks, procedural descriptions, and preparations listed were covered by the LLMs.
Conclusions: There are clear limitations of current LLMs in terms of practical application. Advantages in the generation of patient-adapted risk stratification within individual informed consent forms are not available at the moment, although the potential for further development is difficult to predict.
Full article
►▼
Show Figures
Open AccessArticle
EyeXNet: Enhancing Abnormality Detection and Diagnosis via Eye-Tracking and X-ray Fusion
by
Chihcheng Hsieh, André Luís, José Neves, Isabel Blanco Nobre, Sandra Costa Sousa, Chun Ouyang, Joaquim Jorge and Catarina Moreira
Cited by 4 | Viewed by 3999
Abstract
Integrating eye gaze data with chest X-ray images in deep learning (DL) has led to contradictory conclusions in the literature. Some authors assert that eye gaze data can enhance prediction accuracy, while others consider eye tracking irrelevant for predictive tasks. We argue that
[...] Read more.
Integrating eye gaze data with chest X-ray images in deep learning (DL) has led to contradictory conclusions in the literature. Some authors assert that eye gaze data can enhance prediction accuracy, while others consider eye tracking irrelevant for predictive tasks. We argue that this disagreement lies in how researchers process eye-tracking data as most remain agnostic to the human component and apply the data directly to DL models without proper preprocessing. We present EyeXNet, a multimodal DL architecture that combines images and radiologists’ fixation masks to predict abnormality locations in chest X-rays. We focus on fixation maps during reporting moments as radiologists are more likely to focus on regions with abnormalities and provide more targeted regions to the predictive models. Our analysis compares radiologist fixations in both silent and reporting moments, revealing that more targeted and focused fixations occur during reporting. Our results show that integrating the fixation masks in a multimodal DL architecture outperformed the baseline model in five out of eight experiments regarding average Recall and six out of eight regarding average Precision. Incorporating fixation masks representing radiologists’ classification patterns in a multimodal DL architecture benefits lesion detection in chest X-ray (CXR) images, particularly when there is a strong correlation between fixation masks and generated proposal regions. This highlights the potential of leveraging fixation masks to enhance multimodal DL architectures for CXR image analysis. This work represents a first step towards human-centered DL, moving away from traditional data-driven and human-agnostic approaches.
Full article
►▼
Show Figures
Open AccessArticle
VOD: Vision-Based Building Energy Data Outlier Detection
by
Jinzhao Tian, Tianya Zhao, Zhuorui Li, Tian Li, Haipei Bie and Vivian Loftness
Cited by 9 | Viewed by 3863
Abstract
Outlier detection plays a critical role in building operation optimization and data quality maintenance. However, existing methods often struggle with the complexity and variability of building energy data, leading to poorly generalized and explainable results. To address the gap, this study introduces a
[...] Read more.
Outlier detection plays a critical role in building operation optimization and data quality maintenance. However, existing methods often struggle with the complexity and variability of building energy data, leading to poorly generalized and explainable results. To address the gap, this study introduces a novel Vision-based Outlier Detection (VOD) approach, leveraging computer vision models to spot outliers in the building energy records. The models are trained to identify outliers by analyzing the load shapes in 2D time series plots derived from the energy data. The VOD approach is tested on four years of workday time-series electricity consumption data from 290 commercial buildings in the United States. Two distinct models are developed for different usage purposes, namely a classification model for broad-level outlier detection and an object detection model for the demands of precise pinpointing of outliers. The classification model is also interpreted via Grad-CAM to enhance its usage reliability. The classification model achieves an F1 score of 0.88, and the object detection model achieves an Average Precision (AP) of 0.84. VOD is a very efficient path to identifying energy consumption outliers in building operations, paving the way for the enhancement of building energy data quality, operation efficiency, and energy savings.
Full article
►▼
Show Figures
Open AccessArticle
Quantum-Enhanced Representation Learning: A Quanvolutional Autoencoder Approach against DDoS Threats
by
Pablo Rivas, Javier Orduz, Tonni Das Jui, Casimer DeCusatis and Bikram Khanal
Cited by 8 | Viewed by 5143
Abstract
Motivated by the growing threat of distributed denial-of-service (DDoS) attacks and the emergence of quantum computing, this study introduces a novel “quanvolutional autoencoder” architecture for learning representations. The architecture leverages the computational advantages of quantum mechanics to improve upon traditional machine learning techniques.
[...] Read more.
Motivated by the growing threat of distributed denial-of-service (DDoS) attacks and the emergence of quantum computing, this study introduces a novel “quanvolutional autoencoder” architecture for learning representations. The architecture leverages the computational advantages of quantum mechanics to improve upon traditional machine learning techniques. Specifically, the quanvolutional autoencoder employs randomized quantum circuits to analyze time-series data from DDoS attacks, offering a robust alternative to classical convolutional neural networks. Experimental results suggest that the quanvolutional autoencoder performs similarly to classical models in visualizing and learning from DDoS hive plots and leads to faster convergence and learning stability. These findings suggest that quantum machine learning holds significant promise for advancing data analysis and visualization in cybersecurity. The study highlights the need for further research in this fast-growing field, particularly for unsupervised anomaly detection.
Full article
►▼
Show Figures
Open AccessArticle
Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models
by
Fouad Trad and Ali Chehab
Cited by 95 | Viewed by 18656
Abstract
Large Language Models (LLMs) are reshaping the landscape of Machine Learning (ML) application development. The emergence of versatile LLMs capable of undertaking a wide array of tasks has reduced the necessity for intensive human involvement in training and maintaining ML models. Despite these
[...] Read more.
Large Language Models (LLMs) are reshaping the landscape of Machine Learning (ML) application development. The emergence of versatile LLMs capable of undertaking a wide array of tasks has reduced the necessity for intensive human involvement in training and maintaining ML models. Despite these advancements, a pivotal question emerges: can these generalized models negate the need for task-specific models? This study addresses this question by comparing the effectiveness of LLMs in detecting phishing URLs when utilized with prompt-engineering techniques versus when fine-tuned. Notably, we explore multiple prompt-engineering strategies for phishing URL detection and apply them to two chat models, GPT-3.5-turbo and Claude 2. In this context, the maximum result achieved was an F1-score of 92.74% by using a test set of 1000 samples. Following this, we fine-tune a range of base LLMs, including GPT-2, Bloom, Baby LLaMA, and DistilGPT-2—all primarily developed for text generation—exclusively for phishing URL detection. The fine-tuning approach culminated in a peak performance, achieving an F1-score of 97.29% and an AUC of 99.56% on the same test set, thereby outperforming existing state-of-the-art methods. These results highlight that while LLMs harnessed through prompt engineering can expedite application development processes, achieving a decent performance, they are not as effective as dedicated, task-specific LLMs.
Full article
►▼
Show Figures
Open AccessArticle
Transforming Simulated Data into Experimental Data Using Deep Learning for Vibration-Based Structural Health Monitoring
by
Abhijeet Kumar, Anirban Guha and Sauvik Banerjee
Cited by 8 | Viewed by 4542
Abstract
While machine learning (ML) has been quite successful in the field of structural health monitoring (SHM), its practical implementation has been limited. This is because ML model training requires data containing a variety of distinct instances of damage captured from a real structure
[...] Read more.
While machine learning (ML) has been quite successful in the field of structural health monitoring (SHM), its practical implementation has been limited. This is because ML model training requires data containing a variety of distinct instances of damage captured from a real structure and the experimental generation of such data is challenging. One way to tackle this issue is by generating training data through numerical simulations. However, simulated data cannot capture the bias and variance of experimental uncertainty. To overcome this problem, this work proposes a deep-learning-based domain transformation method for transforming simulated data to the experimental domain. Use of this technique has been demonstrated for debonding location and size predictions of stiffened panels using a vibration-based method. The results are satisfactory for both debonding location and size prediction. This domain transformation method can be used in any field in which experimental data for training machine-learning models is scarce.
Full article
►▼
Show Figures
Open AccessArticle
Detecting Adversarial Examples Using Surrogate Models
by
Borna Feldsar, Rudolf Mayer and Andreas Rauber
Cited by 6 | Viewed by 5448
Abstract
Deep Learning has enabled significant progress towards more accurate predictions and is increasingly integrated into our everyday lives in real-world applications; this is true especially for Convolutional Neural Networks (CNNs) in the field of image analysis. Nevertheless, it has been shown that Deep
[...] Read more.
Deep Learning has enabled significant progress towards more accurate predictions and is increasingly integrated into our everyday lives in real-world applications; this is true especially for Convolutional Neural Networks (CNNs) in the field of image analysis. Nevertheless, it has been shown that Deep Learning is vulnerable against well-crafted, small perturbations to the input, i.e.,
adversarial examples. Defending against such attacks is therefore crucial to ensure the proper functioning of these models—especially when autonomous decisions are taken in safety-critical applications, such as autonomous vehicles. In this work, shallow machine learning models, such as Logistic Regression and Support Vector Machine, are utilised as
surrogates of a CNN based on the assumption that they would be differently affected by the minute modifications crafted for CNNs. We develop three detection strategies for adversarial examples by analysing differences in the prediction of the surrogate and the CNN model: namely, deviation in (i) the prediction, (ii) the distance of the predictions, and (iii) the confidence of the predictions. We consider three different feature spaces: raw images, extracted features, and the activations of the CNN model. Our evaluation shows that our methods achieve state-of-the-art performance compared to other approaches, such as Feature Squeezing, MagNet, PixelDefend, and Subset Scanning, on the MNIST, Fashion-MNIST, and CIFAR-10 datasets while being robust in the sense that they do not entirely fail against selected single attacks. Further, we evaluate our defence against an adaptive attacker in a grey-box setting.
Full article
►▼
Show Figures
Open AccessArticle
Unraveling COVID-19 Dynamics via Machine Learning and XAI: Investigating Variant Influence and Prognostic Classification
by
Oliver Lohaj, Ján Paralič, Peter Bednár, Zuzana Paraličová and Matúš Huba
Cited by 7 | Viewed by 3723
Abstract
Machine learning (ML) has been used in different ways in the fight against COVID-19 disease. ML models have been developed, e.g., for diagnostic or prognostic purposes and using various modalities of data (e.g., textual, visual, or structured). Due to the many specific aspects
[...] Read more.
Machine learning (ML) has been used in different ways in the fight against COVID-19 disease. ML models have been developed, e.g., for diagnostic or prognostic purposes and using various modalities of data (e.g., textual, visual, or structured). Due to the many specific aspects of this disease and its evolution over time, there is still not enough understanding of all relevant factors influencing the course of COVID-19 in particular patients. In all aspects of our work, there was a strong involvement of a medical expert following the human-in-the-loop principle. This is a very important but usually neglected part of the ML and knowledge extraction (KE) process. Our research shows that explainable artificial intelligence (XAI) may significantly support this part of ML and KE. Our research focused on using ML for knowledge extraction in two specific scenarios. In the first scenario, we aimed to discover whether adding information about the predominant COVID-19 variant impacts the performance of the ML models. In the second scenario, we focused on prognostic classification models concerning the need for an intensive care unit for a given patient in connection with different explainability AI (XAI) methods. We have used nine ML algorithms, namely XGBoost, CatBoost, LightGBM, logistic regression, Naive Bayes, random forest, SGD, SVM-linear, and SVM-RBF. We measured the performance of the resulting models using precision, accuracy, and AUC metrics. Subsequently, we focused on knowledge extraction from the best-performing models using two different approaches as follows: (a) features extracted automatically by forward stepwise selection (FSS); (b) attributes and their interactions discovered by model explainability methods. Both were compared with the attributes selected by the medical experts in advance based on the domain expertise. Our experiments showed that adding information about the COVID-19 variant did not influence the performance of the resulting ML models. It also turned out that medical experts were much more precise in the identification of significant attributes than FSS. Explainability methods identified almost the same attributes as a medical expert and interesting interactions among them, which the expert discussed from a medical point of view. The results of our research and their consequences are discussed.
Full article
►▼
Show Figures
Open AccessArticle
Improving Spiking Neural Network Performance with Auxiliary Learning
by
Paolo G. Cachi, Sebastián Ventura and Krzysztof J. Cios
Cited by 1 | Viewed by 4176
Abstract
The use of back propagation through the time learning rule enabled the supervised training of deep spiking neural networks to process temporal neuromorphic data. However, their performance is still below non-spiking neural networks. Previous work pointed out that one of the main causes
[...] Read more.
The use of back propagation through the time learning rule enabled the supervised training of deep spiking neural networks to process temporal neuromorphic data. However, their performance is still below non-spiking neural networks. Previous work pointed out that one of the main causes is the limited number of neuromorphic data currently available, which are also difficult to generate. With the goal of overcoming this problem, we explore the usage of auxiliary learning as a means of helping spiking neural networks to identify more general features. Tests are performed on neuromorphic DVS-CIFAR10 and DVS128-Gesture datasets. The results indicate that training with auxiliary learning tasks improves their accuracy, albeit slightly. Different scenarios, including manual and automatic combination losses using implicit differentiation, are explored to analyze the usage of auxiliary tasks.
Full article
►▼
Show Figures
Open AccessArticle
Classification Confidence in Exploratory Learning: A User’s Guide
by
Peter Salamon, David Salamon, V. Adrian Cantu, Michelle An, Tyler Perry, Robert A. Edwards and Anca M. Segall
Cited by 1 | Viewed by 3824
Abstract
This paper investigates the post-hoc calibration of confidence for “exploratory” machine learning classification problems. The difficulty in these problems stems from the continuing desire to push the boundaries of which categories have enough examples to generalize from when curating datasets, and confusion regarding
[...] Read more.
This paper investigates the post-hoc calibration of confidence for “exploratory” machine learning classification problems. The difficulty in these problems stems from the continuing desire to push the boundaries of which categories have enough examples to generalize from when curating datasets, and confusion regarding the validity of those categories. We argue that for such problems the “one-versus-all” approach (top-label calibration) must be used rather than the “calibrate-the-full-response-matrix” approach advocated elsewhere in the literature. We introduce and test four new algorithms designed to handle the idiosyncrasies of category-specific confidence estimation using only the test set and the final model. Chief among these methods is the use of kernel density ratios for confidence calibration including a novel algorithm for choosing the bandwidth. We test our claims and explore the limits of calibration on a bioinformatics application (PhANNs) as well as the classic MNIST benchmark. Finally, our analysis argues that post-hoc calibration should always be performed, may be performed using only the test dataset, and should be sanity-checked visually.
Full article
►▼
Show Figures
Open AccessArticle
The Value of Numbers in Clinical Text Classification
by
Kristian Miok, Padraig Corcoran and Irena Spasić
Cited by 3 | Viewed by 4177
Abstract
Clinical text often includes numbers of various types and formats. However, most current text classification approaches do not take advantage of these numbers. This study aims to demonstrate that using numbers as features can significantly improve the performance of text classification models. This
[...] Read more.
Clinical text often includes numbers of various types and formats. However, most current text classification approaches do not take advantage of these numbers. This study aims to demonstrate that using numbers as features can significantly improve the performance of text classification models. This study also demonstrates the feasibility of extracting such features from clinical text. Unsupervised learning was used to identify patterns of number usage in clinical text. These patterns were analyzed manually and converted into pattern-matching rules. Information extraction was used to incorporate numbers as features into a document representation model. We evaluated text classification models trained on such representation. Our experiments were performed with two document representation models (vector space model and word embedding model) and two classification models (support vector machines and neural networks). The results showed that even a handful of numerical features can significantly improve text classification performance. We conclude that commonly used document representations do not represent numbers in a way that machine learning algorithms can effectively utilize them as features. Although we demonstrated that traditional information extraction can be effective in converting numbers into features, further community-wide research is required to systematically incorporate number representation into the word embedding process.
Full article
►▼
Show Figures
Open AccessArticle
Using Machine Learning with Eye-Tracking Data to Predict if a Recruiter Will Approve a Resume
by
Angel Pina, Corbin Petersheim, Josh Cherian, Joanna Nicole Lahey, Gerianne Alexander and Tracy Hammond
Cited by 8 | Viewed by 7033
Abstract
When job seekers are unsuccessful in getting a position, they often do not get feedback to inform them on how to develop a better application in the future. Therefore, there is a critical need to understand what qualifications recruiters value in order to
[...] Read more.
When job seekers are unsuccessful in getting a position, they often do not get feedback to inform them on how to develop a better application in the future. Therefore, there is a critical need to understand what qualifications recruiters value in order to help applicants. To address this need, we utilized eye-trackers to measure and record visual data of recruiters screening resumes to gain insight into which Areas of Interest (AOIs) influenced recruiters’ decisions the most. Using just this eye-tracking data, we trained a machine learning classifier to predict whether or not a recruiter would move a resume on to the next level of the hiring process with an AUC of 0.767. We found that features associated with recruiters looking outside the content of a resume were most predictive of their decision as well as total time viewing the resume and time spent on the Experience and Education sections. We hypothesize that this behavior is indicative of the recruiter reflecting on the content of the resume. These initial results show that applicants should focus on designing clear and concise resumes that are easy for recruiters to absorb and think about, with additional attention given to the Experience and Education sections.
Full article
►▼
Show Figures
Open AccessArticle
A Mathematical Framework for Enriching Human–Machine Interactions
by
Andrée C. Ehresmann, Mathias Béjean and Jean-Paul Vanbremeersch
Cited by 4 | Viewed by 3538
Abstract
This paper presents a conceptual mathematical framework for developing rich human–machine interactions in order to improve decision-making in a social organisation, S. The idea is to model how S can create a “multi-level artificial cognitive system”, called a data analyser (DA), to collaborate
[...] Read more.
This paper presents a conceptual mathematical framework for developing rich human–machine interactions in order to improve decision-making in a social organisation, S. The idea is to model how S can create a “multi-level artificial cognitive system”, called a data analyser (DA), to collaborate with humans in collecting and learning how to analyse data, to anticipate situations, and to develop new responses, thus improving decision-making. In this model, the DA is “processed” to not only gather data and extend existing knowledge, but also to learn how to act autonomously with its own specific procedures or even to create new ones. An application is given in cases where such rich human–machine interactions are expected to allow the DA+S partnership to acquire deep anticipation capabilities for possible future changes, e.g., to prevent risks or seize opportunities. The way the social organization S operates over time, including the construction of DA, is described using the conceptual framework comprising “memory evolutive systems” (MES), a mathematical theoretical approach introduced by Ehresmann and Vanbremeersch for evolutionary multi-scale, multi-agent and multi-temporality systems. This leads to the definition of a “data analyser–MES”.
Full article
►▼
Show Figures
Open AccessArticle
Multimodal AutoML via Representation Evolution
by
Blaž Škrlj, Matej Bevec and Nada Lavrač
Cited by 4 | Viewed by 4114
Abstract
With the increasing amounts of available data, learning simultaneously from different types of inputs is becoming necessary to obtain robust and well-performing models. With the advent of representation learning in recent years, lower-dimensional vector-based representations have become available for both images and texts,
[...] Read more.
With the increasing amounts of available data, learning simultaneously from different types of inputs is becoming necessary to obtain robust and well-performing models. With the advent of representation learning in recent years, lower-dimensional vector-based representations have become available for both images and texts, while automating simultaneous learning from multiple modalities remains a challenging problem. This paper presents an AutoML (automated machine learning) approach to automated machine learning model configuration identification for data composed of two modalities: texts and images. The approach is based on the idea of representation evolution, the process of automatically amplifying heterogeneous representations across several modalities, optimized jointly with a collection of fast, well-regularized linear models. The proposed approach is benchmarked against 11 unimodal and multimodal (texts and images) approaches on four real-life benchmark datasets from different domains. It achieves competitive performance with minimal human effort and low computing requirements, enabling learning from multiple modalities in automated manner for a wider community of researchers.
Full article
►▼
Show Figures
Open AccessArticle
Ontology Completion with Graph-Based Machine Learning: A Comprehensive Evaluation
by
Sebastian Mežnar, Matej Bevec, Nada Lavrač and Blaž Škrlj
Cited by 8 | Viewed by 8332
Abstract
Increasing quantities of semantic resources offer a wealth of human knowledge, but their growth also increases the probability of wrong knowledge base entries. The development of approaches that identify potentially spurious parts of a given knowledge base is therefore highly relevant. We propose
[...] Read more.
Increasing quantities of semantic resources offer a wealth of human knowledge, but their growth also increases the probability of wrong knowledge base entries. The development of approaches that identify potentially spurious parts of a given knowledge base is therefore highly relevant. We propose an approach for ontology completion that transforms an ontology into a graph and recommends missing edges using structure-only link analysis methods. By systematically evaluating thirteen methods (some for knowledge graphs) on eight different semantic resources, including Gene Ontology, Food Ontology, Marine Ontology, and similar ontologies, we demonstrate that a structure-only link analysis can offer a scalable and computationally efficient ontology completion approach for a subset of analyzed data sets. To the best of our knowledge, this is currently the most extensive systematic study of the applicability of different types of link analysis methods across semantic resources from different domains. It demonstrates that by considering symbolic node embeddings, explanations of the predictions (links) can be obtained, making this branch of methods potentially more valuable than black-box methods.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
Semantic Interactive Learning for Text Classification: A Constructive Approach for Contextual Interactions
by
Sebastian Kiefer, Mareike Hoffmann and Ute Schmid
Cited by 2 | Viewed by 3698
Abstract
Interactive Machine Learning (IML) can enable intelligent systems to interactively learn from their end-users, and is quickly becoming more and more relevant to many application domains. Although it places the human in the loop, interactions are mostly performed via mutual explanations that miss
[...] Read more.
Interactive Machine Learning (IML) can enable intelligent systems to interactively learn from their end-users, and is quickly becoming more and more relevant to many application domains. Although it places the human in the loop, interactions are mostly performed via mutual explanations that miss contextual information. Furthermore, current model-agnostic IML strategies such as CAIPI are limited to ’destructive’ feedback, meaning that they solely allow an expert to prevent a learner from using irrelevant features. In this work, we propose a novel interaction framework called
Semantic Interactive Learning for the domain of document classification, located at the intersection between Natural Language Processing (NLP) and Machine Learning (ML). We frame the problem of incorporating constructive and contextual feedback into the learner as a task involving finding an architecture that enables more semantic alignment between humans and machines while at the same time helping to maintain the statistical characteristics of the input domain when generating user-defined counterexamples based on meaningful corrections. Therefore, we introduce a technique called SemanticPush that is effective for translating conceptual corrections of humans to non-extrapolating training examples such that the learner’s reasoning is pushed towards the desired behavior. Through several experiments we show how our method compares to CAIPI, a state of the art IML strategy, in terms of Predictive Performance and Local Explanation Quality in downstream multi-class classification tasks. Especially in the early stages of interactions, our proposed method clearly outperforms CAIPI while allowing for contextual interpretation and intervention. Overall, SemanticPush stands out with regard to data efficiency, as it requires fewer queries from the pool dataset to achieve high accuracy.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
Actionable Explainable AI (AxAI): A Practical Example with Aggregation Functions for Adaptive Classification and Textual Explanations for Interpretable Machine Learning
by
Anna Saranti, Miroslav Hudec, Erika Mináriková, Zdenko Takáč, Udo Großschedl, Christoph Koch, Bastian Pfeifer, Alessa Angerschmid and Andreas Holzinger
Cited by 23 | Viewed by 6345
Abstract
In many domains of our daily life (e.g., agriculture, forestry, health, etc.), both laymen and experts need to classify entities into two binary classes (yes/no, good/bad, sufficient/insufficient, benign/malign, etc.). For many entities, this decision is difficult and we need another class called “maybe”,
[...] Read more.
In many domains of our daily life (e.g., agriculture, forestry, health, etc.), both laymen and experts need to classify entities into two binary classes (yes/no, good/bad, sufficient/insufficient, benign/malign, etc.). For many entities, this decision is difficult and we need another class called “maybe”, which contains a corresponding quantifiable tendency toward one of these two opposites. Human domain experts are often able to mark any entity, place it in a different class and adjust the position of the slope in the class. Moreover, they can often explain the classification space linguistically—depending on their individual domain experience and previous knowledge. We consider this human-in-the-loop extremely important and call our approach actionable explainable AI. Consequently, the parameters of the functions are adapted to these requirements and the solution is explained to the domain experts accordingly. Specifically, this paper contains three novelties going beyond the state-of-the-art: (1) A novel method for detecting the appropriate parameter range for the averaging function to treat the slope in the “maybe” class, along with a proposal for a better generalisation than the existing solution. (2) the insight that for a given problem, the family of t-norms and t-conorms covering the whole range of nilpotency is suitable because we need a clear “no” or “yes” not only for the borderline cases. Consequently, we adopted the Schweizer–Sklar family of t-norms or t-conorms in ordinal sums. (3) A new fuzzy quasi-dissimilarity function for classification into three classes: Main difference, irrelevant difference and partial difference. We conducted all of our experiments with real-world datasets.
Full article
►▼
Show Figures
Open AccessReview
Artificial Intelligence Methods for Identifying and Localizing Abnormal Parathyroid Glands: A Review Study
by
Ioannis D. Apostolopoulos, Nikolaos I. Papandrianos, Elpiniki I. Papageorgiou and Dimitris J. Apostolopoulos
Cited by 10 | Viewed by 4823
Abstract
Background: Recent advances in Artificial Intelligence (AI) algorithms, and specifically Deep Learning (DL) methods, demonstrate substantial performance in detecting and classifying medical images. Recent clinical studies have reported novel optical technologies which enhance the localization or assess the viability of Parathyroid Glands (PG)
[...] Read more.
Background: Recent advances in Artificial Intelligence (AI) algorithms, and specifically Deep Learning (DL) methods, demonstrate substantial performance in detecting and classifying medical images. Recent clinical studies have reported novel optical technologies which enhance the localization or assess the viability of Parathyroid Glands (PG) during surgery, or preoperatively. These technologies could become complementary to the surgeon’s eyes and may improve surgical outcomes in thyroidectomy and parathyroidectomy. Methods: The study explores and reports the use of AI methods for identifying and localizing PGs, Primary Hyperparathyroidism (PHPT), Parathyroid Adenoma (PTA), and Multiglandular Disease (MGD). Results: The review identified 13 publications that employ Machine Learning and DL methods for preoperative and operative implementations. Conclusions: AI can aid in PG, PHPT, PTA, and MGD detection, as well as PG abnormality discrimination, both during surgery and non-invasively.
Full article
►▼
Show Figures
Open AccessArticle
Benefits from Variational Regularization in Language Models
by
Cornelia Ferner and Stefan Wegenkittl
Cited by 4 | Viewed by 4111
Abstract
Representations from common pre-trained language models have been shown to suffer from the degeneration problem, i.e., they occupy a narrow cone in latent space. This problem can be addressed by enforcing isotropy in latent space. In analogy with variational autoencoders, we suggest applying
[...] Read more.
Representations from common pre-trained language models have been shown to suffer from the degeneration problem, i.e., they occupy a narrow cone in latent space. This problem can be addressed by enforcing isotropy in latent space. In analogy with variational autoencoders, we suggest applying a token-level variational loss to a Transformer architecture and optimizing the standard deviation of the prior distribution in the loss function as the model parameter to increase isotropy. The resulting latent space is complete and interpretable: any given point is a valid embedding and can be decoded into text again. This allows for text manipulations such as paraphrase generation directly in latent space. Surprisingly, features extracted at the sentence level also show competitive results on benchmark classification tasks.
Full article
►▼
Show Figures
Open AccessArticle
The Case of Aspect in Sentiment Analysis: Seeking Attention or Co-Dependency?
by
Anastazia Žunić, Padraig Corcoran and Irena Spasić
Cited by 2 | Viewed by 4140
Abstract
(1) Background: Aspect-based sentiment analysis (SA) is a natural language processing task, the aim of which is to classify the sentiment associated with a specific aspect of a written text. The performance of SA methods applied to texts related to health and well-being
[...] Read more.
(1) Background: Aspect-based sentiment analysis (SA) is a natural language processing task, the aim of which is to classify the sentiment associated with a specific aspect of a written text. The performance of SA methods applied to texts related to health and well-being lags behind that of other domains. (2) Methods: In this study, we present an approach to aspect-based SA of drug reviews. Specifically, we analysed signs and symptoms, which were extracted automatically using the Unified Medical Language System. This information was then passed onto the BERT language model, which was extended by two layers to fine-tune the model for aspect-based SA. The interpretability of the model was analysed using an axiomatic attribution method. We performed a correlation analysis between the attribution scores and syntactic dependencies. (3) Results: Our fine-tuned model achieved accuracy of approximately
on a well-balanced test set. It outperformed our previous approach, which used syntactic information to guide the operation of a neural network and achieved an accuracy of approximately
. (4) Conclusions: We demonstrated that a BERT-based model of SA overcomes the negative bias associated with health-related aspects and closes the performance gap against the state-of-the-art in other domains.
Full article
►▼
Show Figures































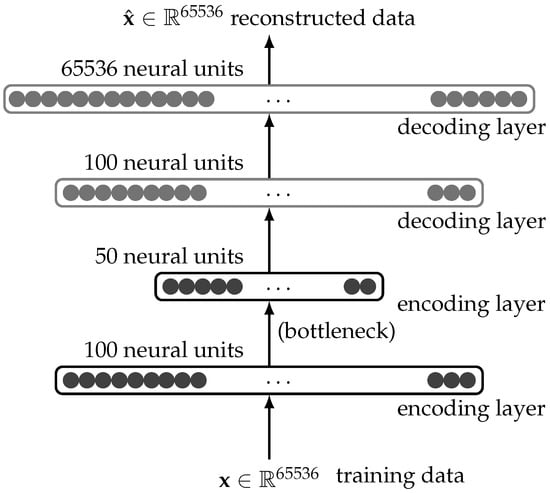
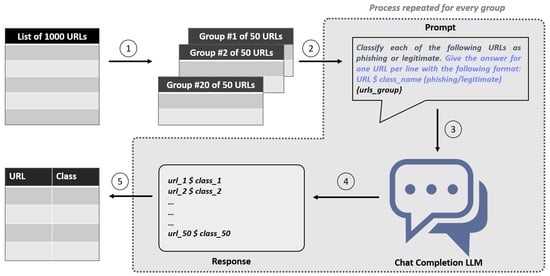
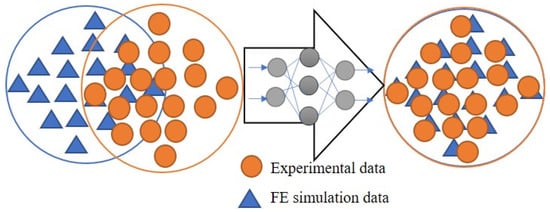
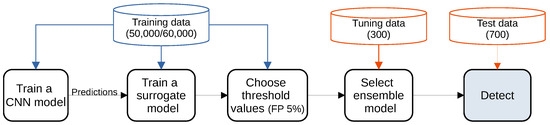
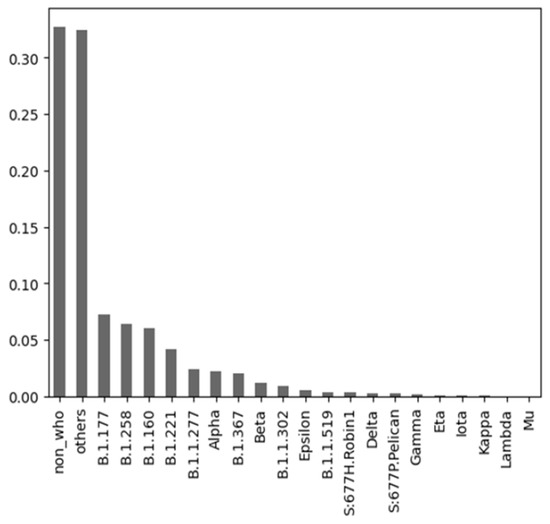
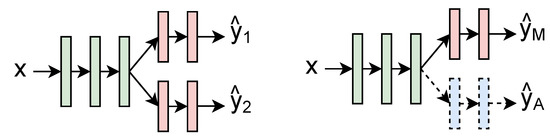
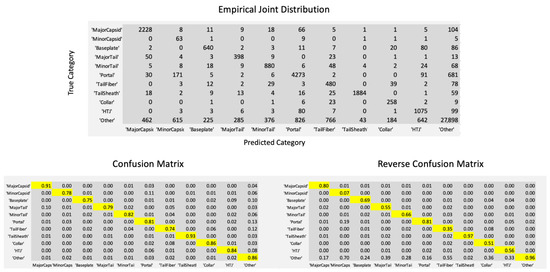


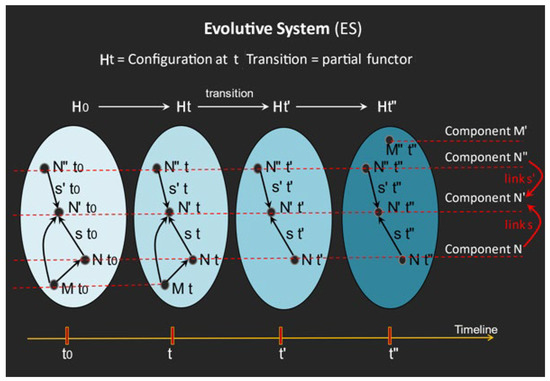
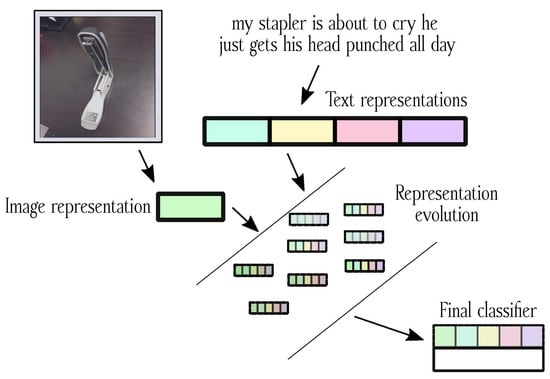
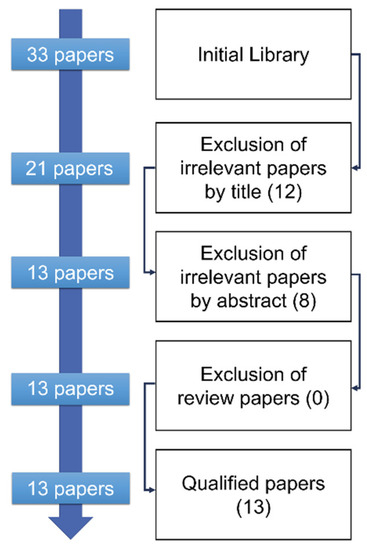


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
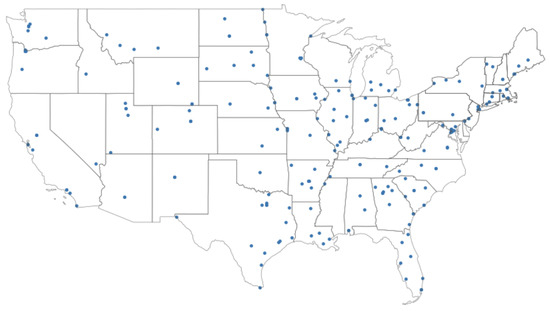{kind=link}
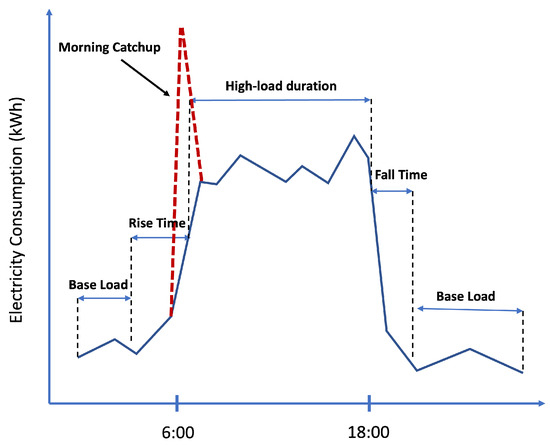{kind=link}
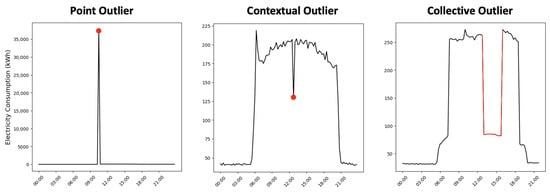{kind=link}
{kind=link}
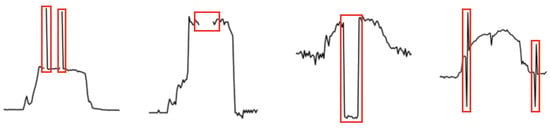{kind=link}
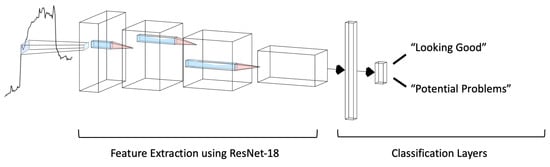{kind=link}
{kind=link}
{kind=link}
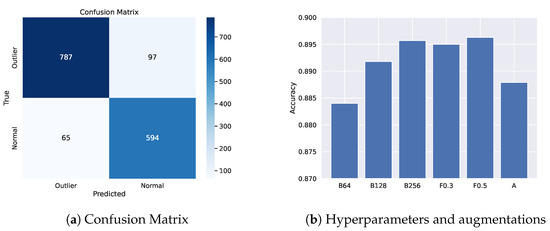{kind=link}
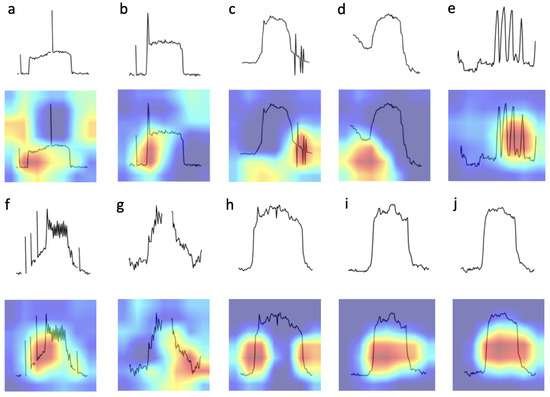{kind=link}
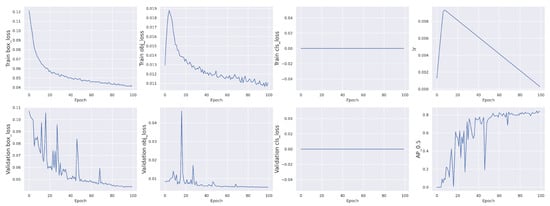{kind=link}
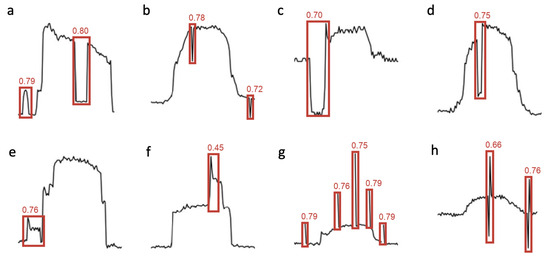{kind=link}
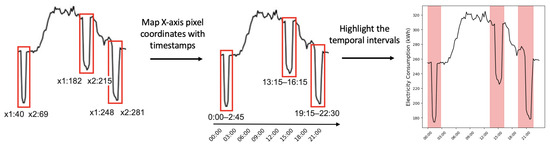{kind=link}
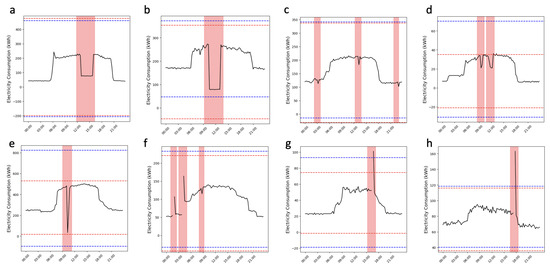{kind=link}
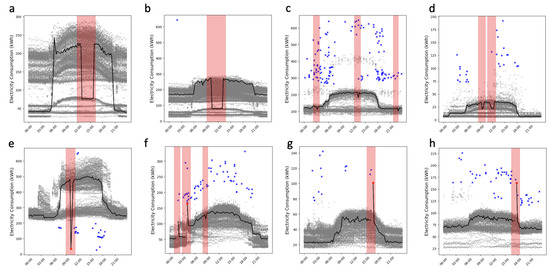{kind=link}
{kind=link}
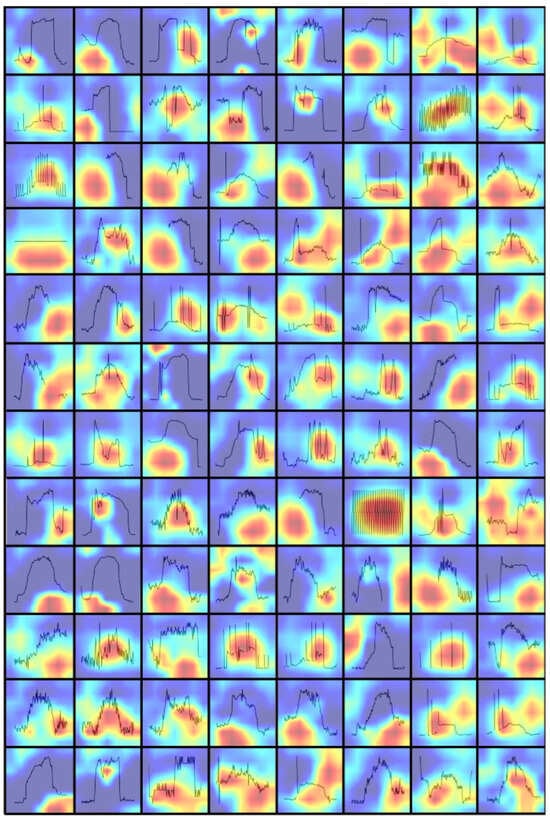{kind=link}
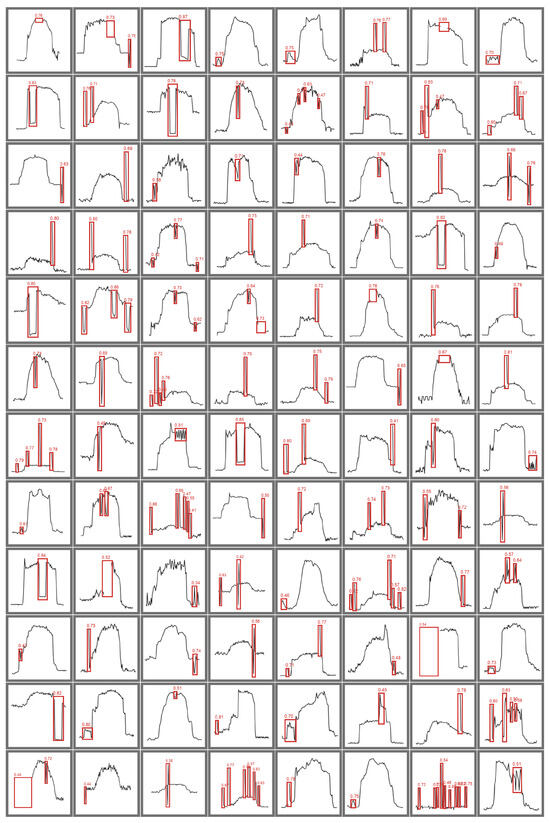{kind=link}
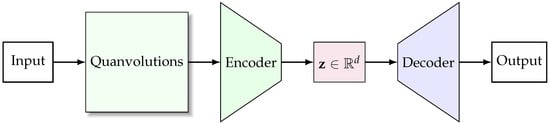{kind=link}
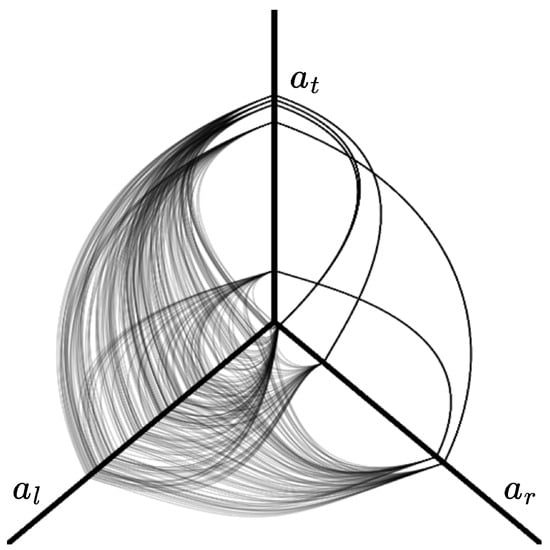{kind=link}
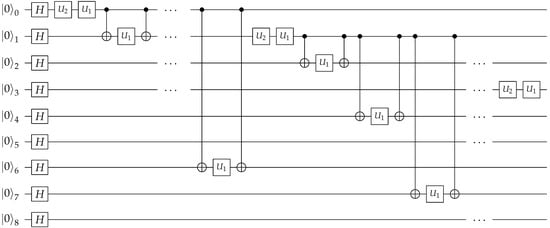{kind=link}
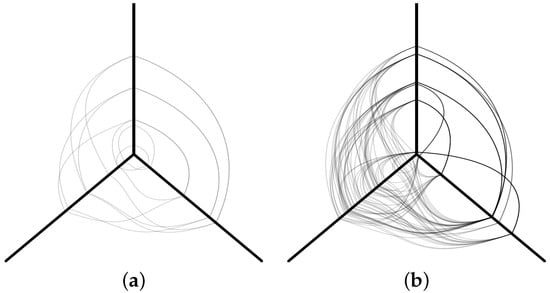{kind=link}
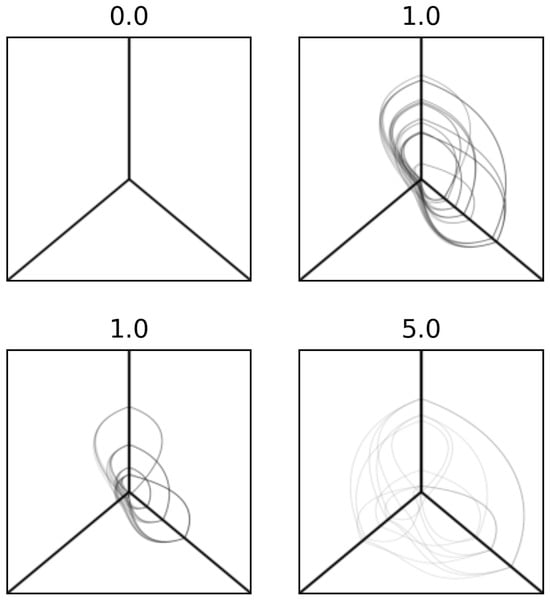{kind=link}
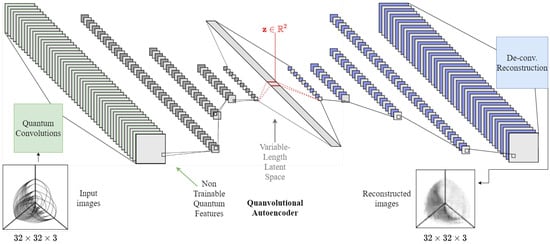{kind=link}
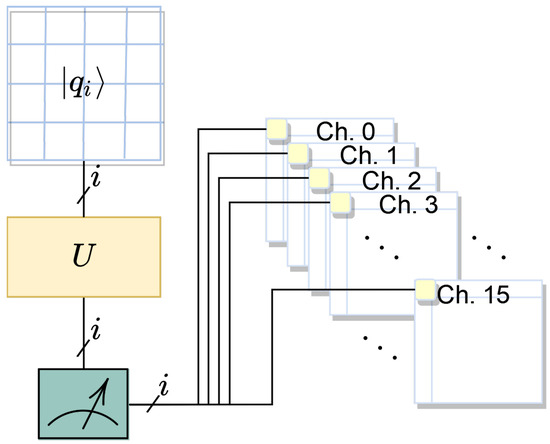{kind=link}
{kind=link}
{kind=link}
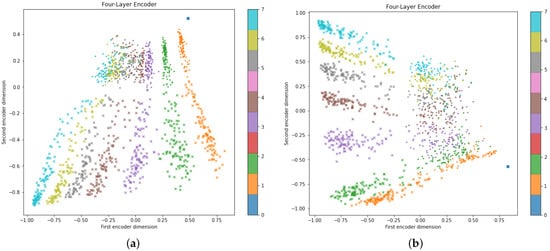{kind=link}
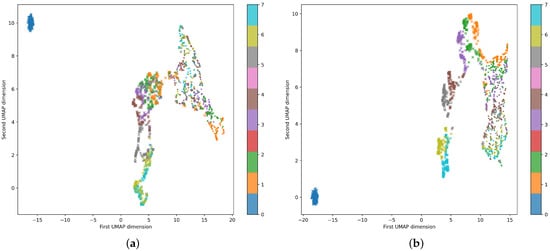{kind=link}
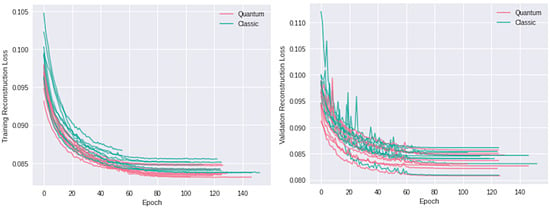{kind=link}
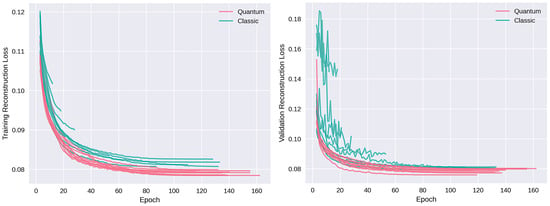{kind=link}
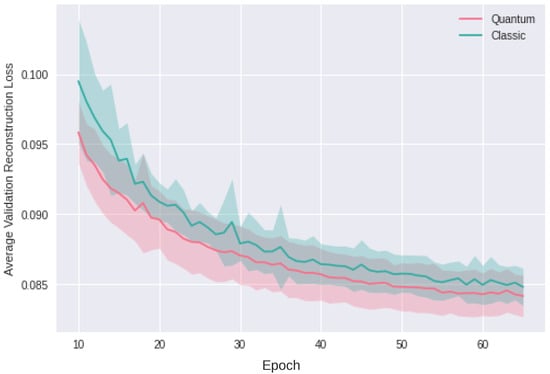{kind=link}
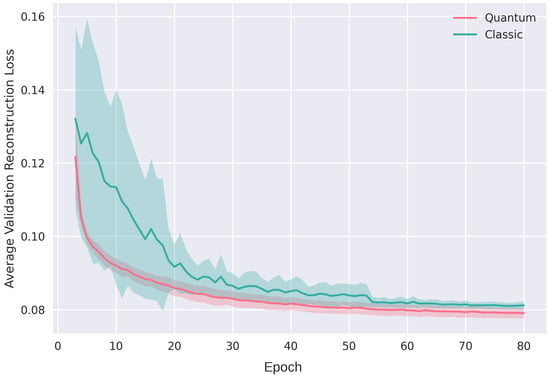{kind=link}
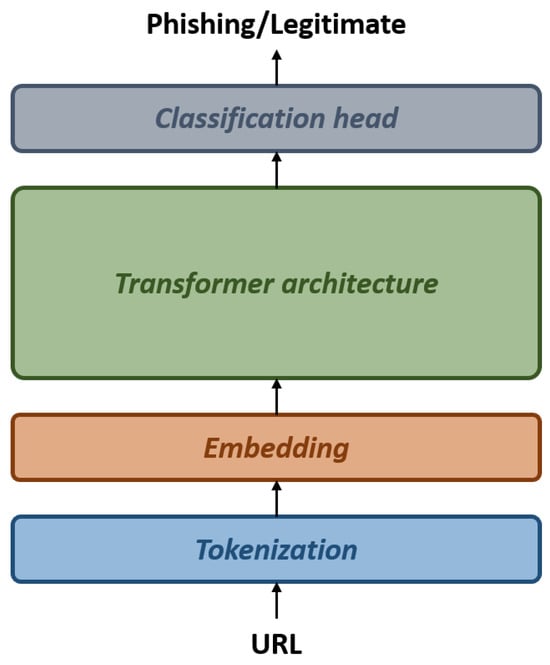{kind=link}
{kind=link}
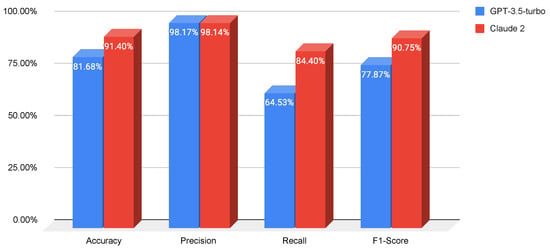{kind=link}
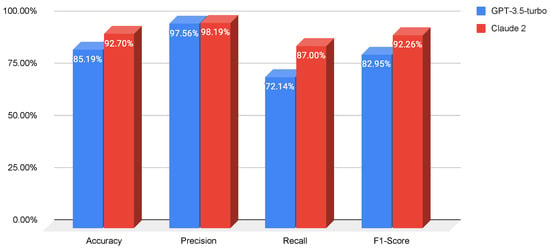{kind=link}
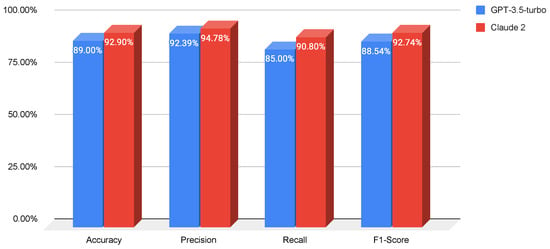{kind=link}
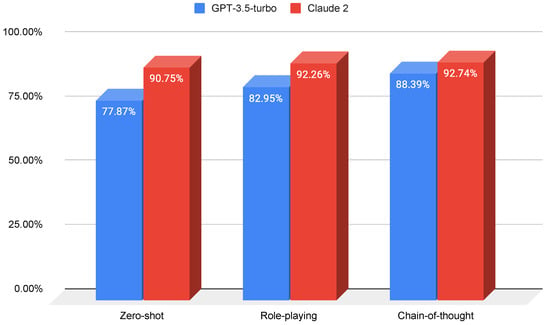{kind=link}
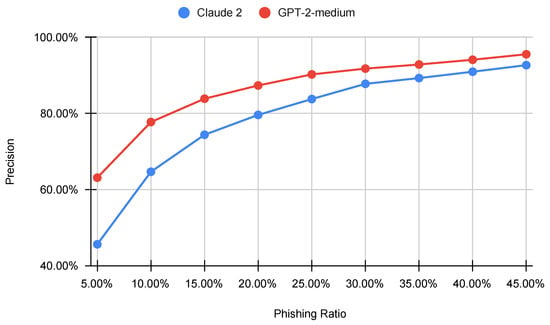{kind=link}
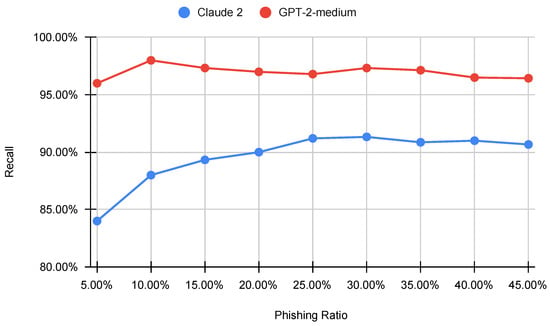{kind=link}
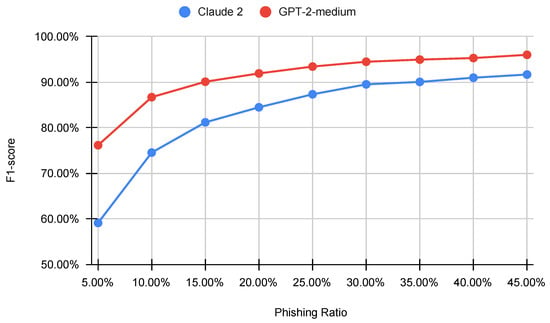{kind=link}
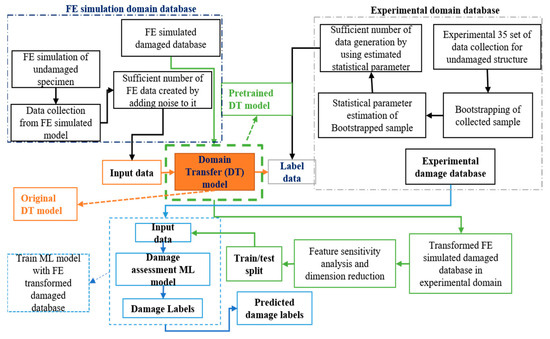{kind=link}
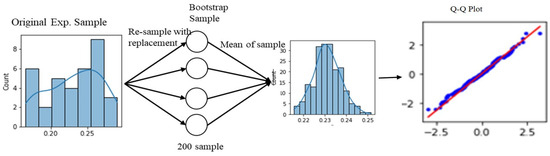{kind=link}
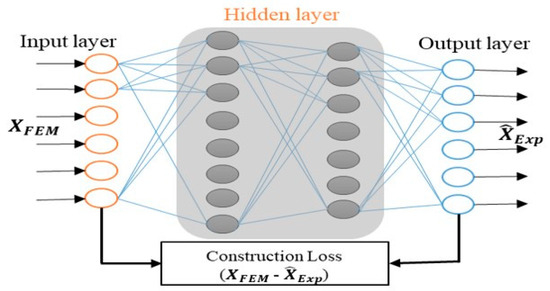{kind=link}
{kind=link}
{kind=link}
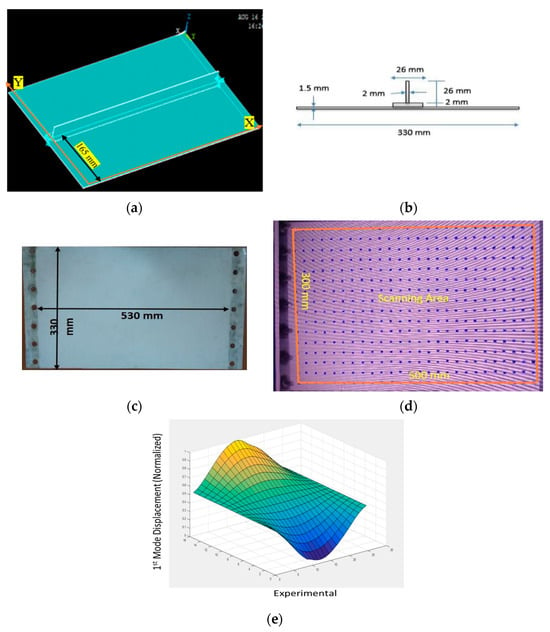{kind=link}
{kind=link}
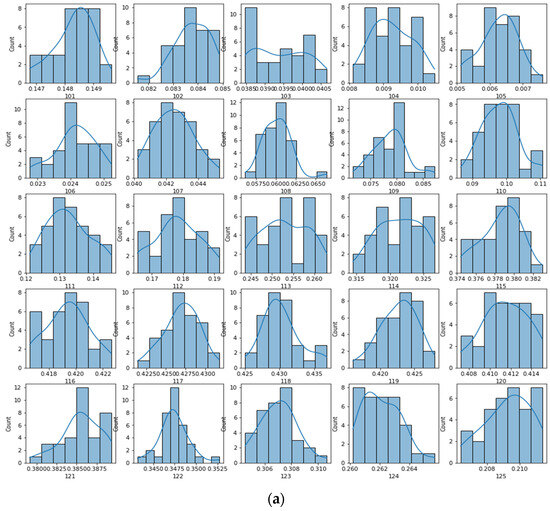{kind=link}
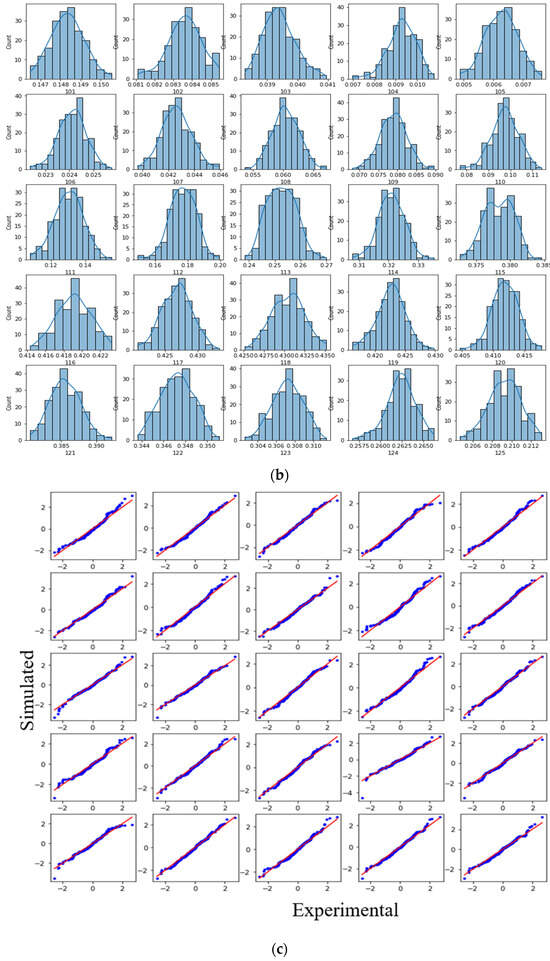{kind=link}
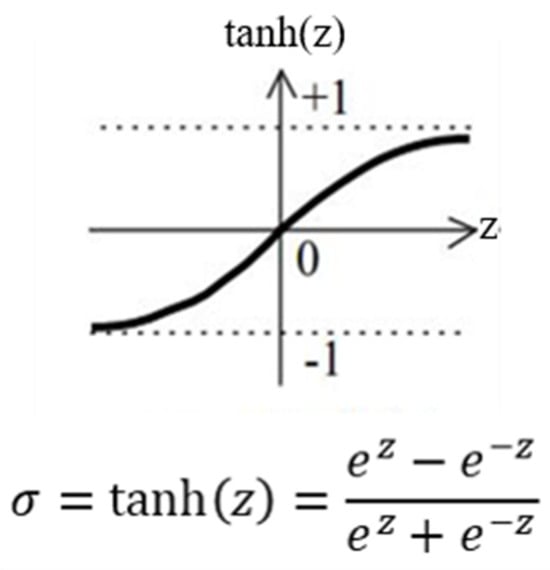{kind=link}
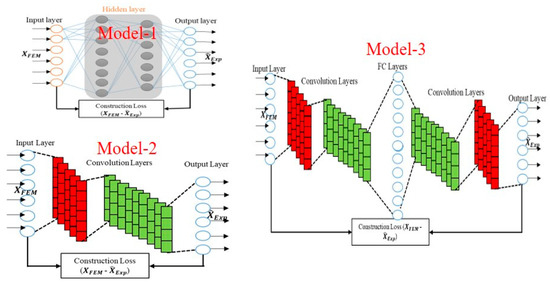{kind=link}
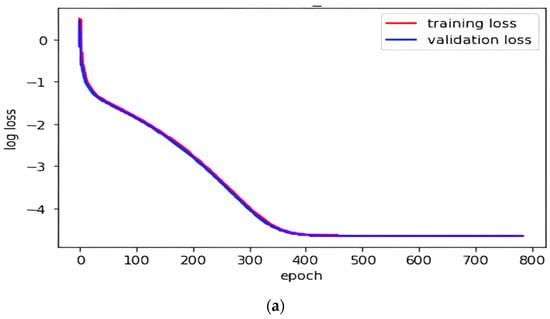{kind=link}
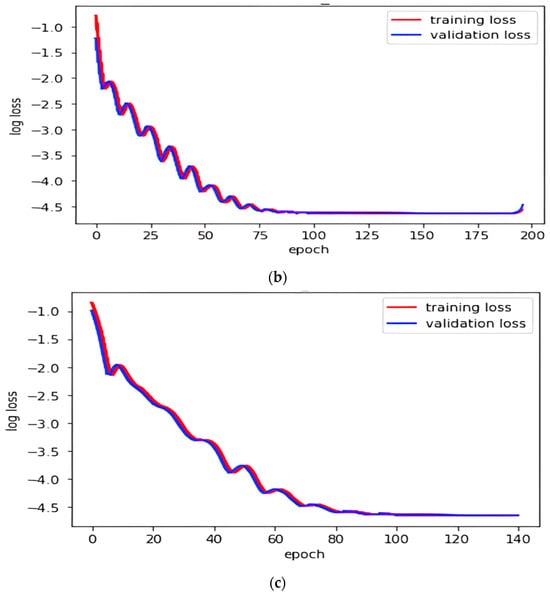{kind=link}
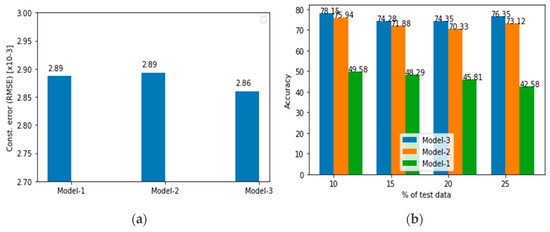{kind=link}
{kind=link}
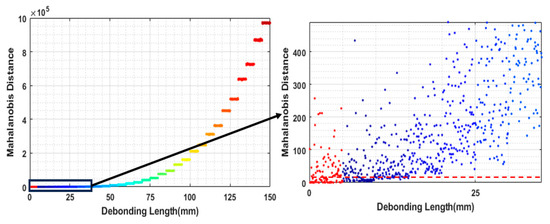{kind=link}
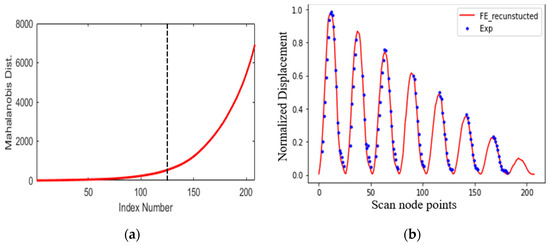{kind=link}
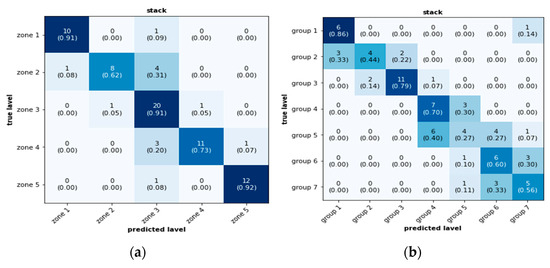{kind=link}
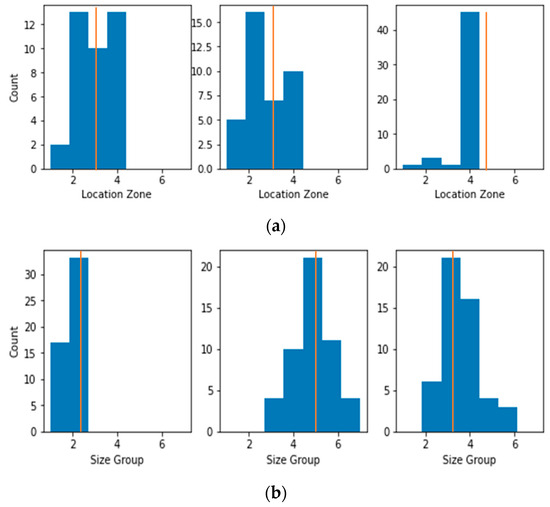{kind=link}
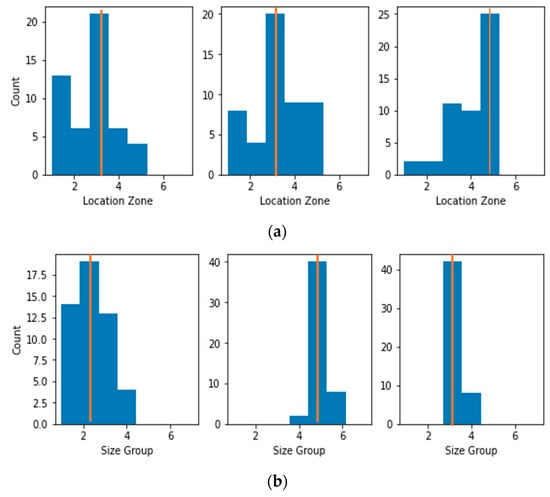{kind=link}
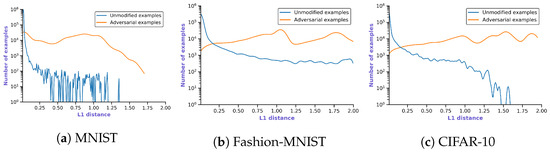{kind=link}
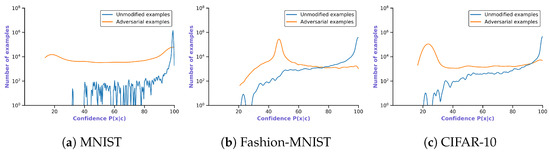{kind=link}
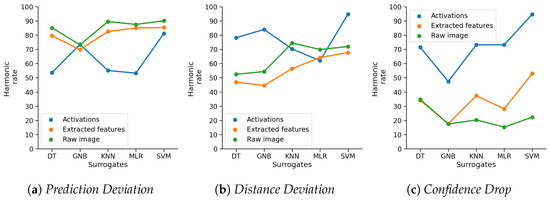{kind=link}
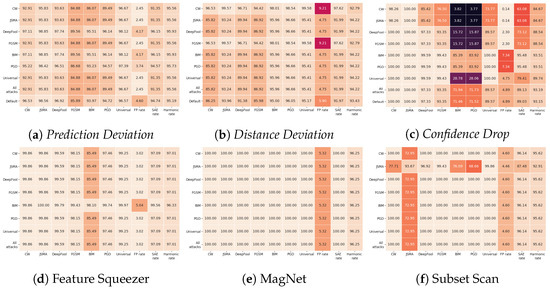{kind=link}
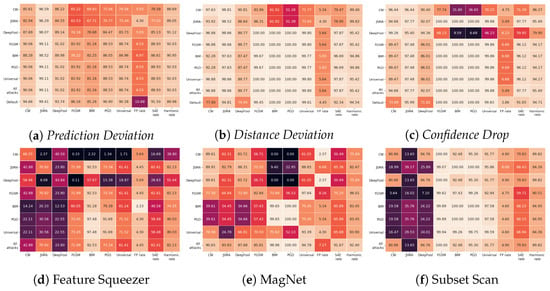{kind=link}
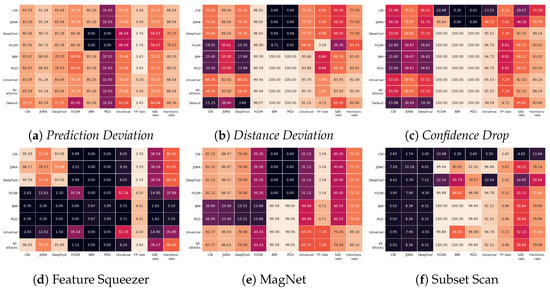{kind=link}
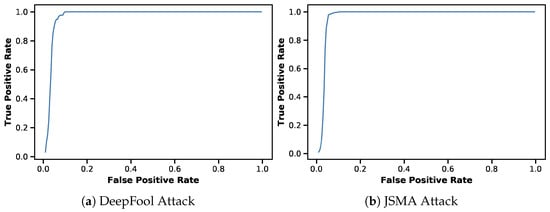{kind=link}
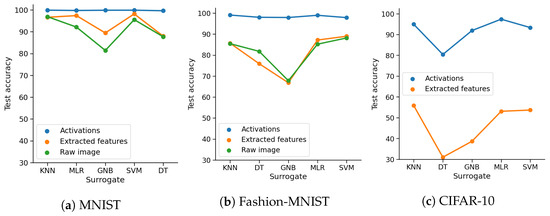{kind=link}
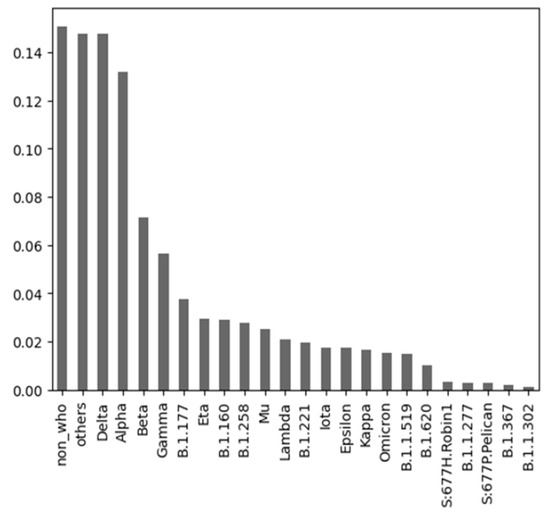{kind=link}
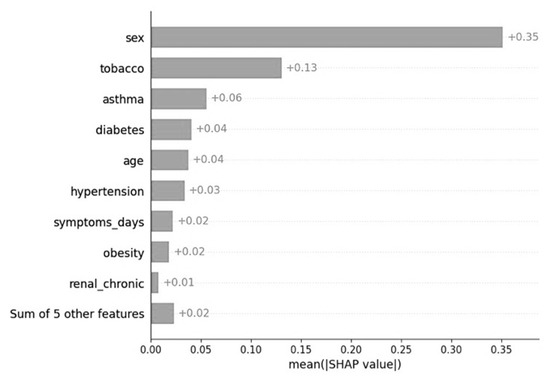{kind=link}
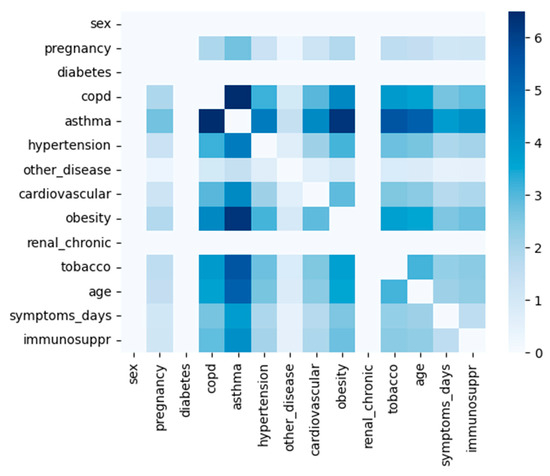{kind=link}
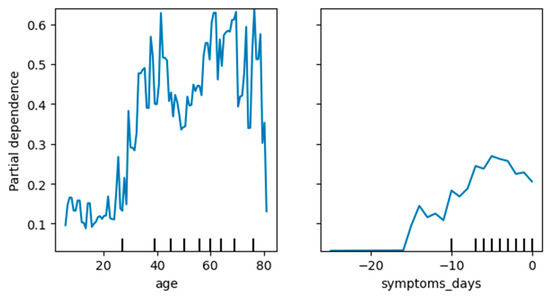{kind=link}
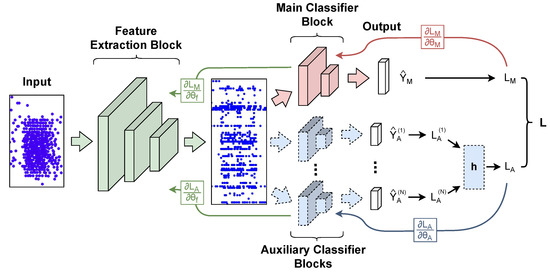{kind=link}
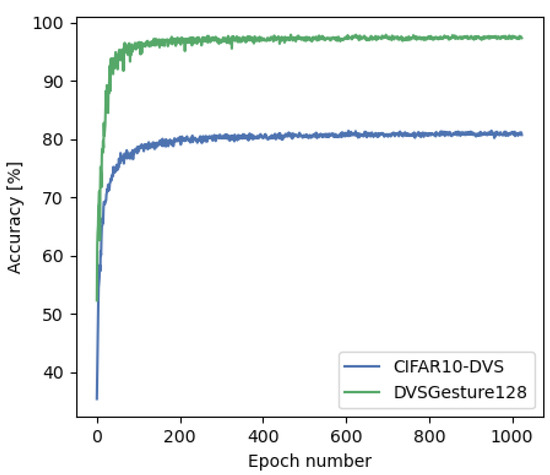{kind=link}
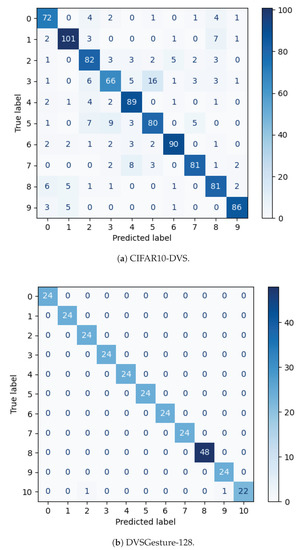{kind=link}
{kind=link}
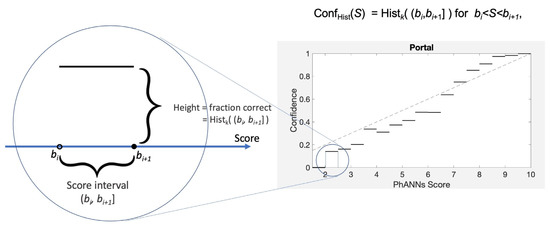{kind=link}
{kind=link}
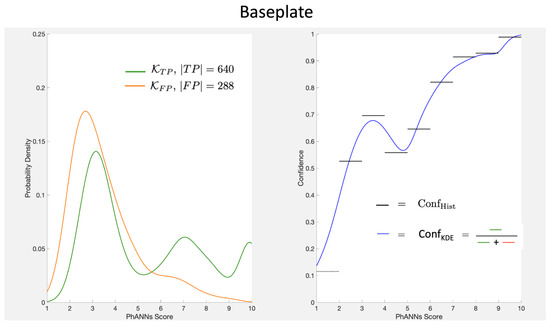{kind=link}
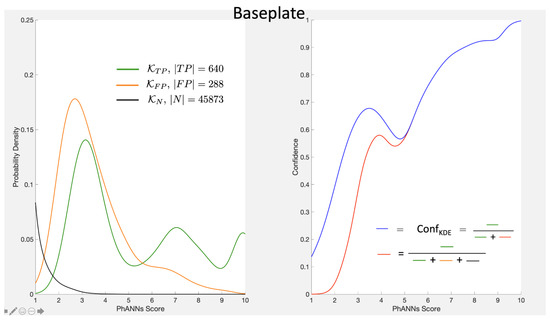{kind=link}
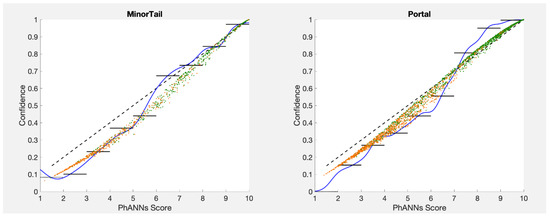{kind=link}
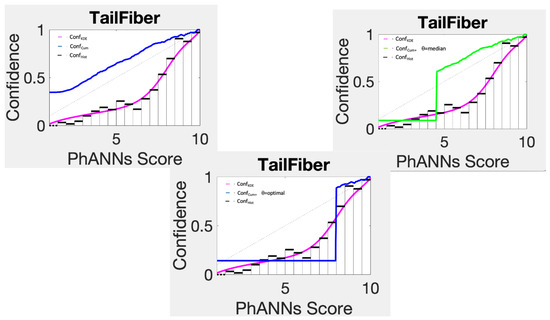{kind=link}
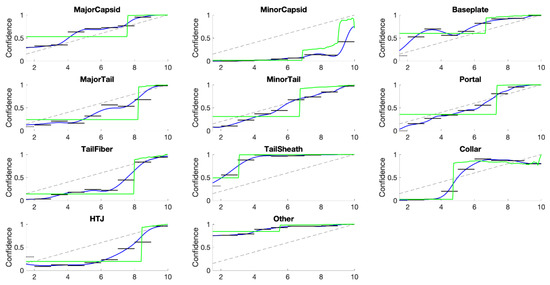{kind=link}
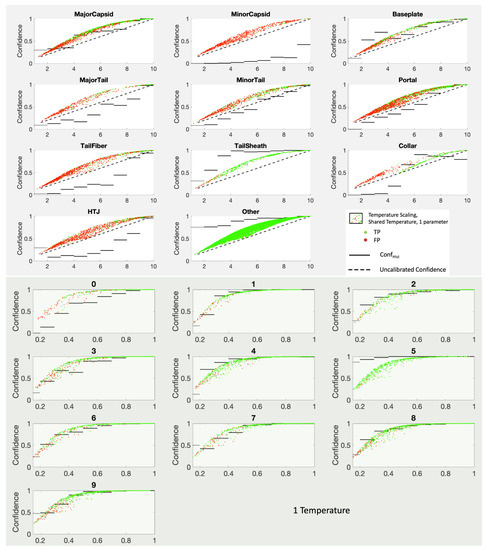{kind=link}
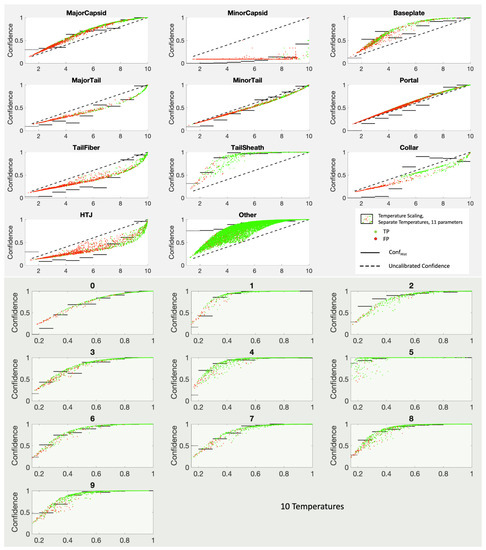{kind=link}
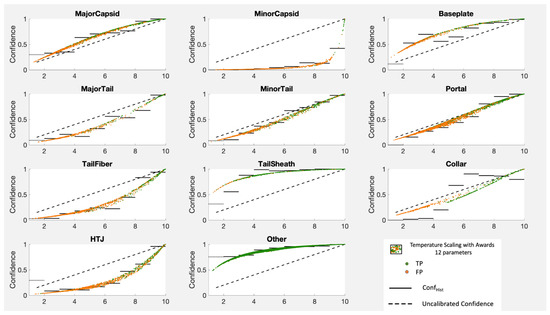{kind=link}
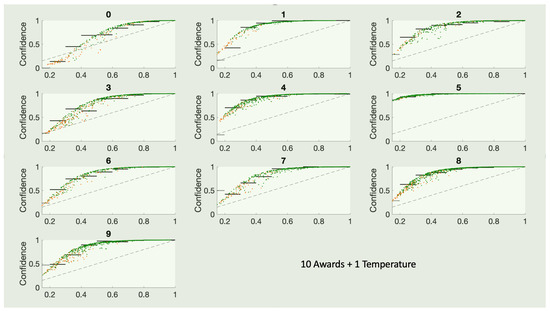{kind=link}
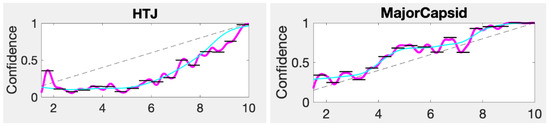{kind=link}
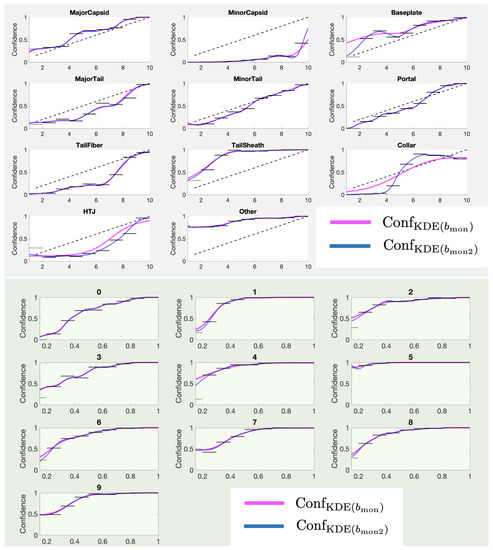{kind=link}
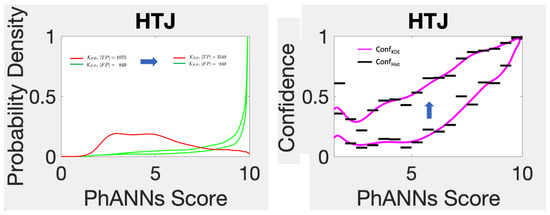{kind=link}
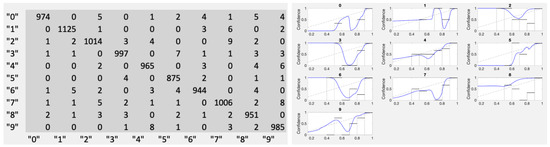{kind=link}
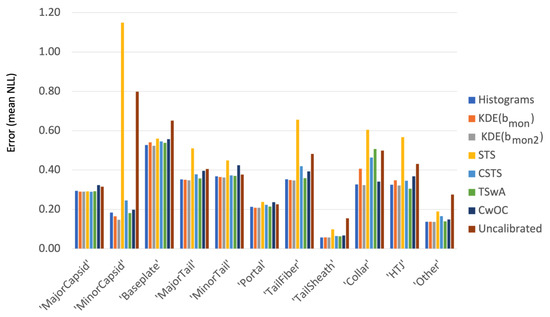{kind=link}
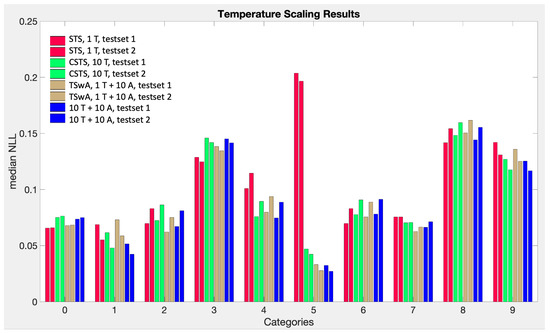{kind=link}
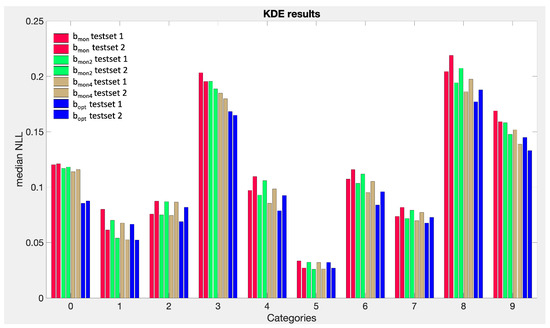{kind=link}
{kind=link}
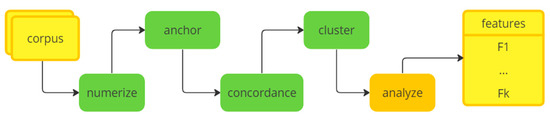{kind=link}
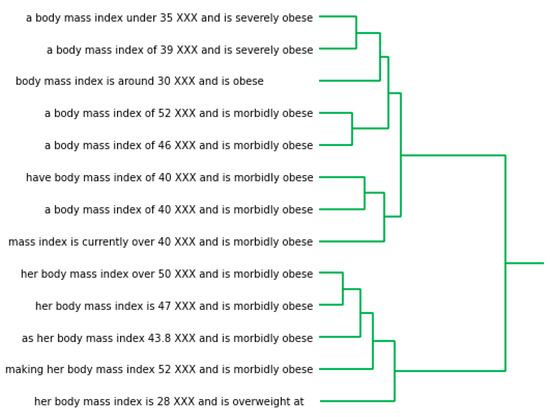{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
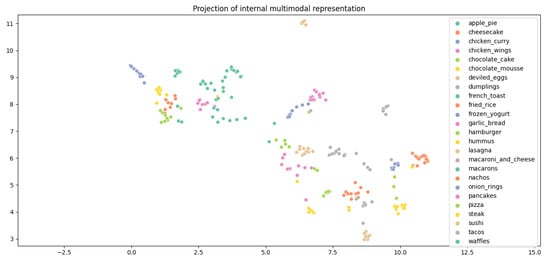{kind=link}
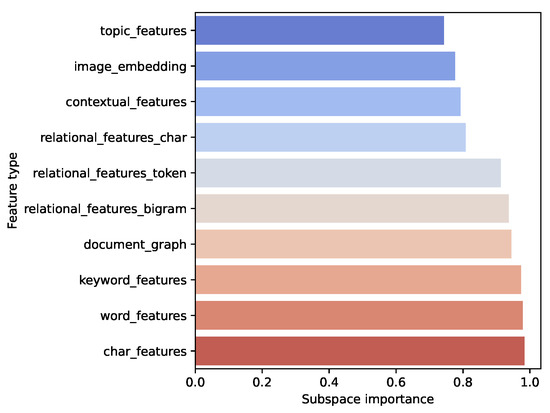{kind=link}
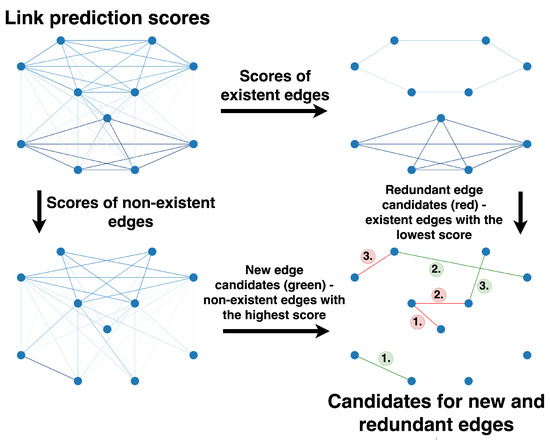{kind=link}
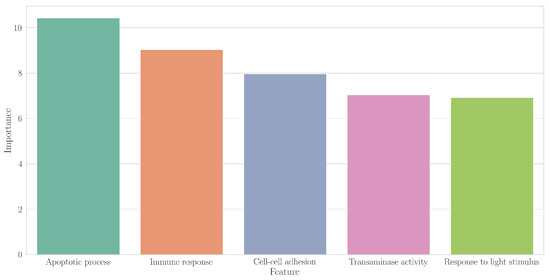{kind=link}
{kind=link}
{kind=link}
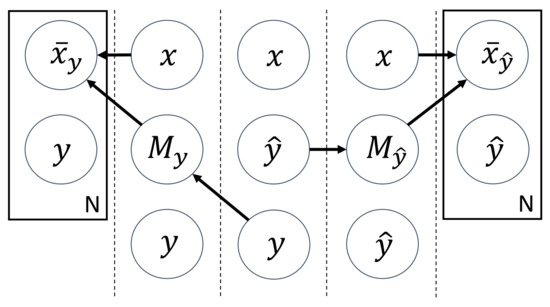{kind=link}
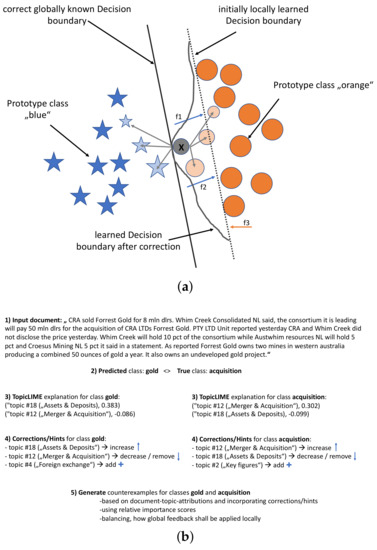{kind=link}
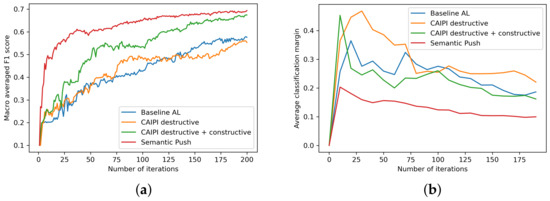{kind=link}
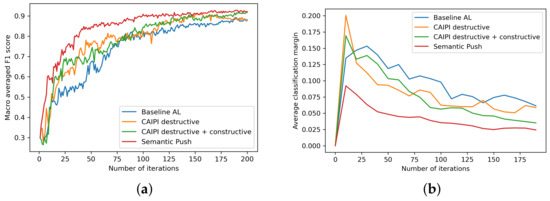{kind=link}
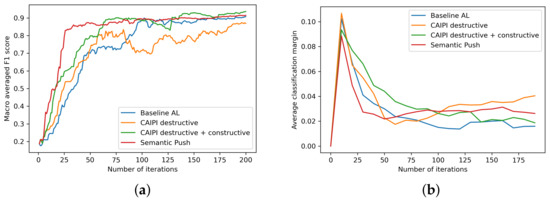{kind=link}
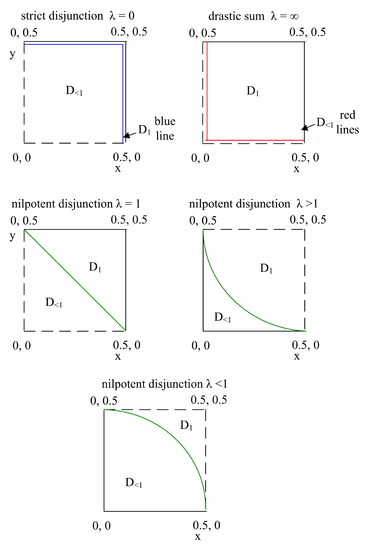{kind=link}
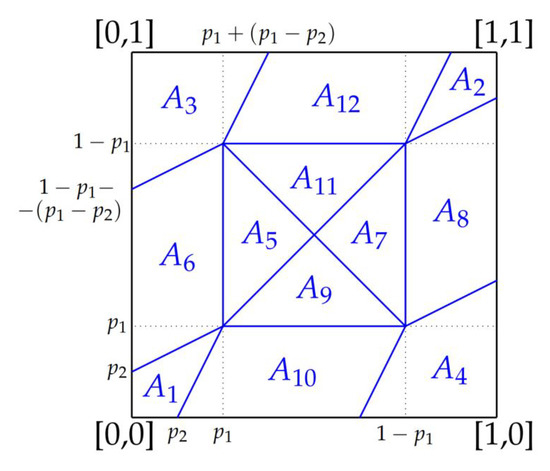{kind=link}
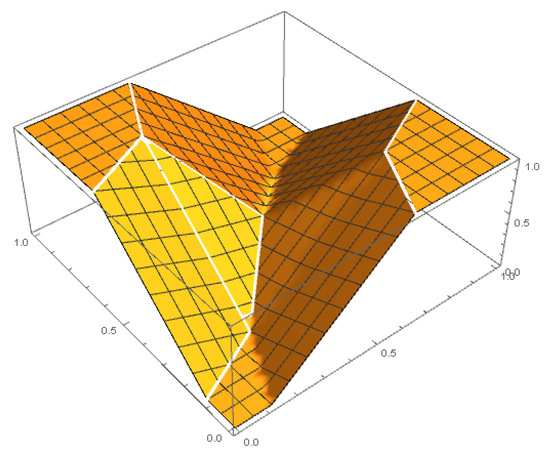{kind=link}
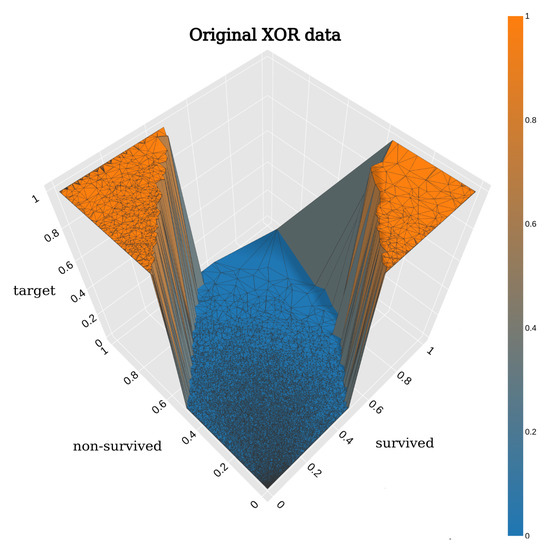{kind=link}
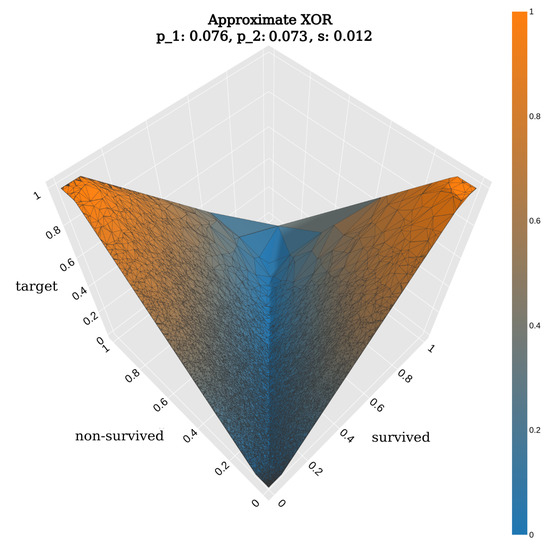{kind=link}
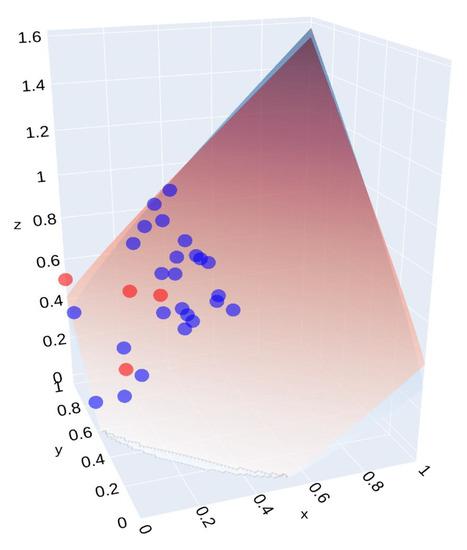{kind=link}
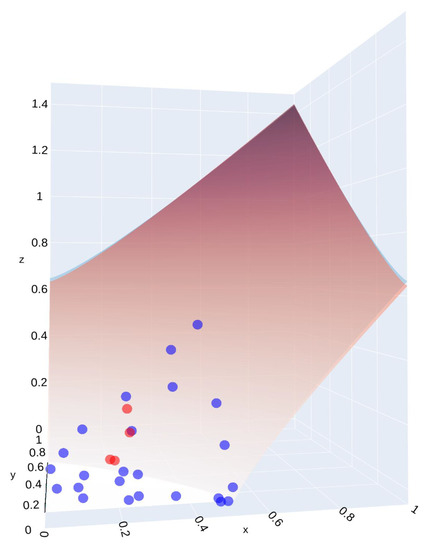{kind=link}
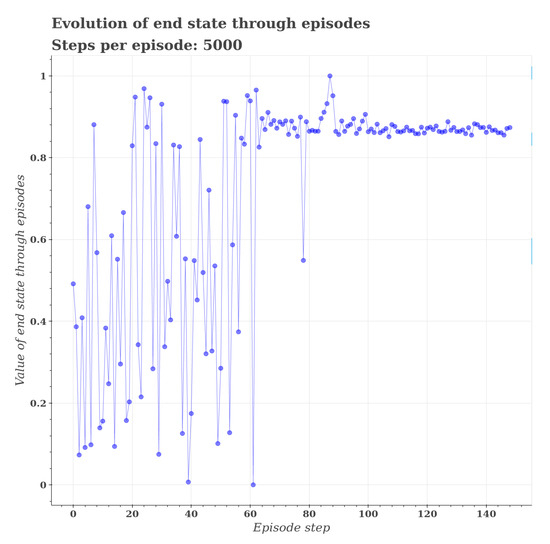{kind=link}
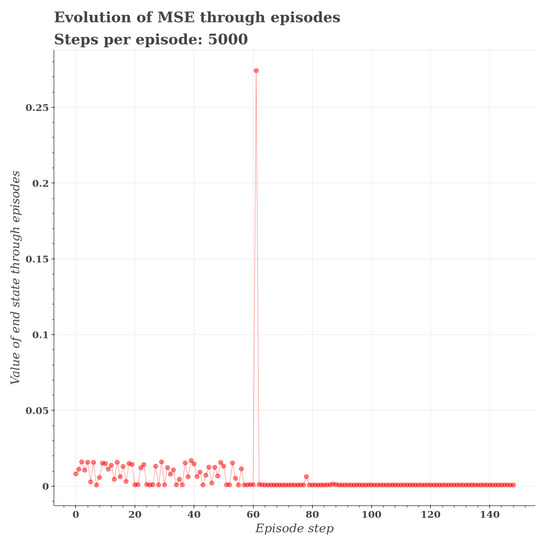{kind=link}
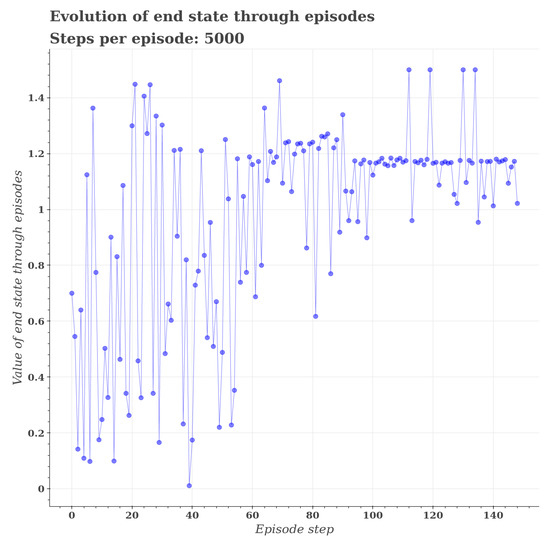{kind=link}
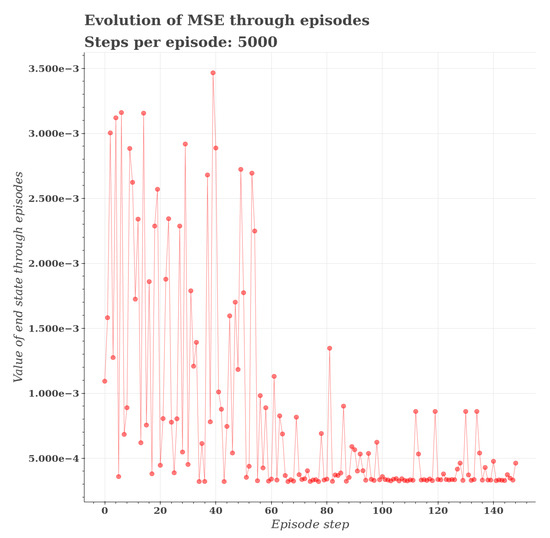{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
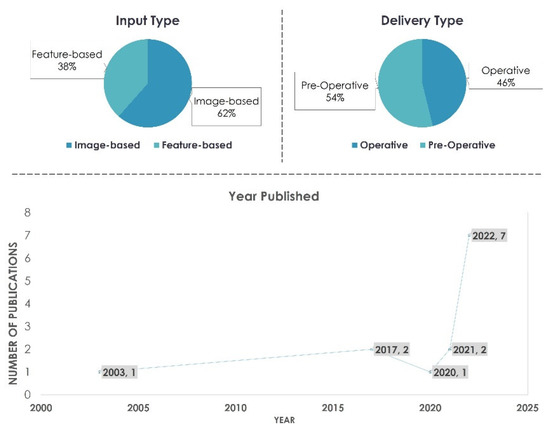{kind=link}
{kind=link}
{kind=link}
{kind=link}
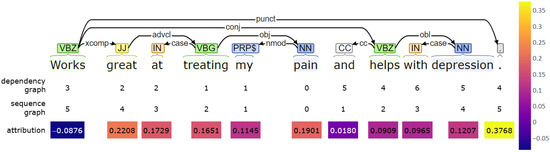{kind=link}
{kind=link}
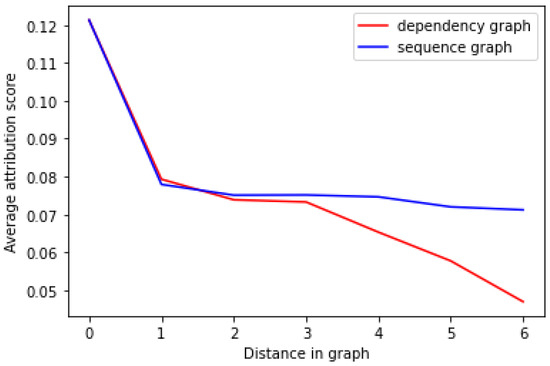{kind=link}