


Evaluation of AI ChatBots for the Creation of Patient-Informed Consent Sheets
 ,
,
Abstract
1. Introduction
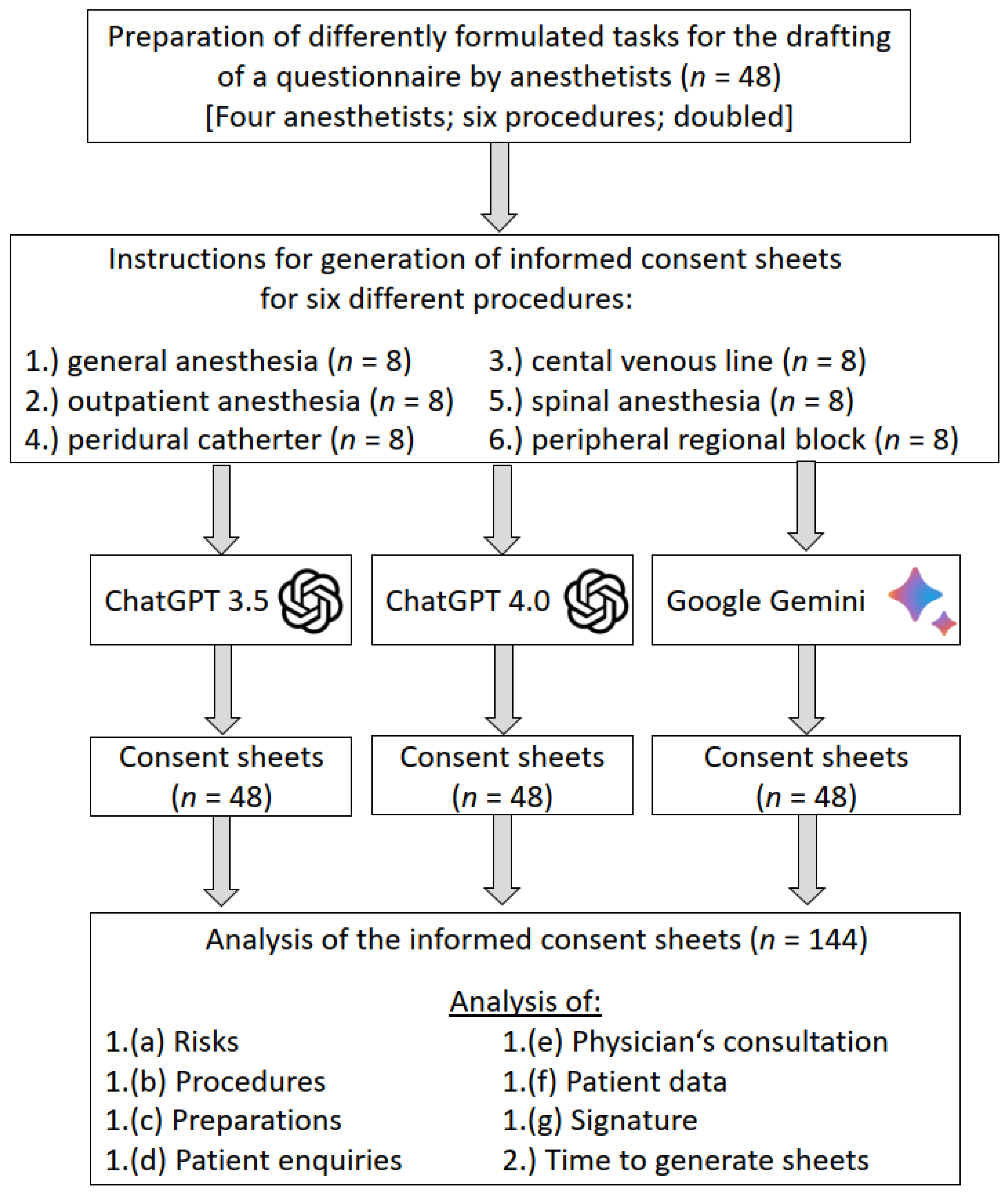
2. Materials and Methods
2.1. Preparation of the Prompts for LLM and Generation
2.2. Evaluation
2.3. Statistics
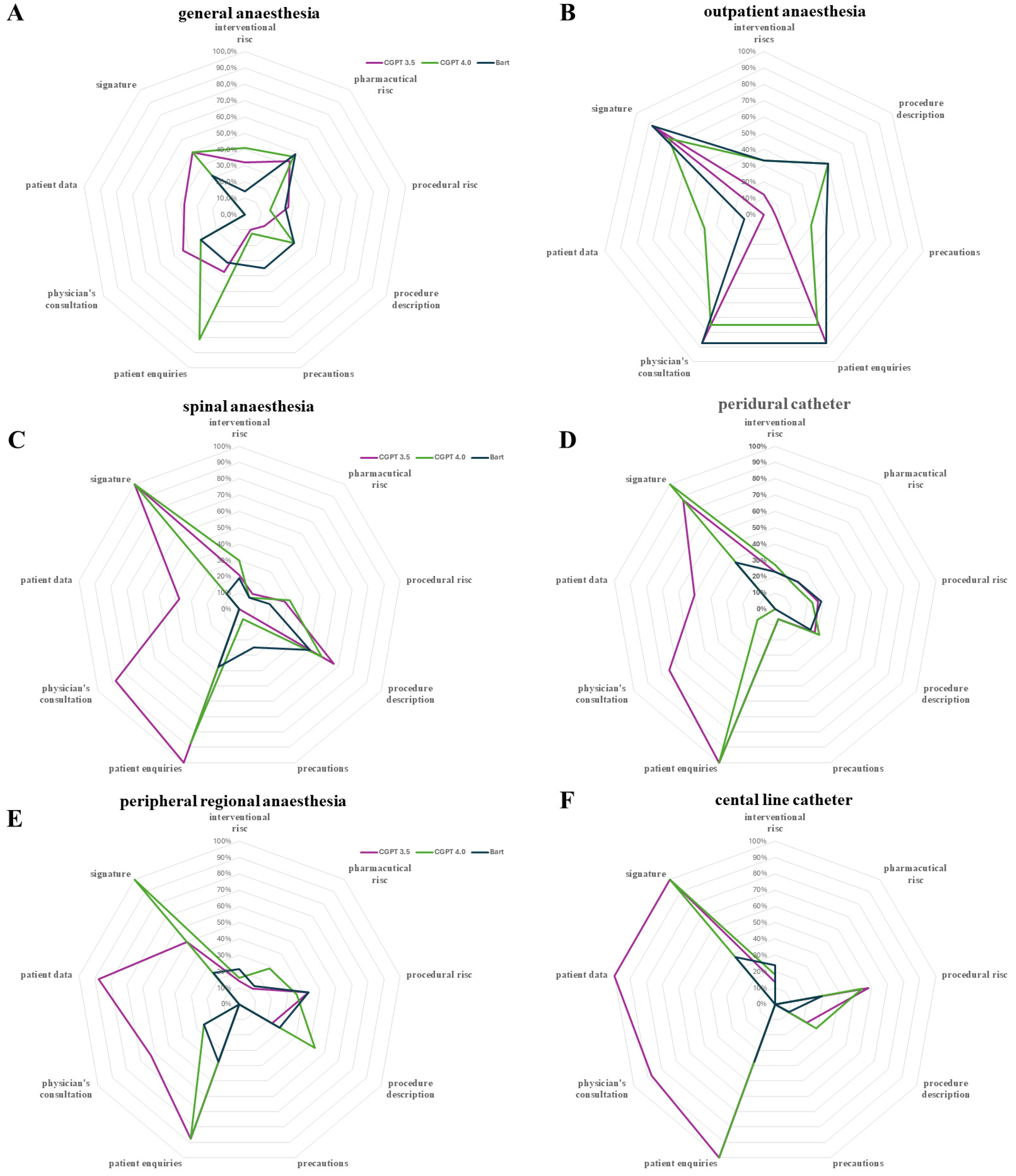
3. Results
4. Discussion
5. Limitations
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Verma, P.; De Vynck, G. ChatGPT Took Their Jobs. Now They Walk Dogs and Fix Air Conditioners. The Washington Post. Available online: https://www.washingtonpost.com/technology/2023/06/02/ai-taking-jobs/ (accessed on 4 March 2024).
- Cerullo, M. Here’s How Many U.S. Workers ChatGPT Says It Could Replace. 2023. Available online: https://www.cbsnews.com/news/chatgpt-artificial-intelligence-jobs/ (accessed on 26 June 2023).
- Tangalakis-Lippert, K. IBM Halts Hiring for 7,800 Jobs That Could Be Replaced by AI, Bloomberg Reports. 2023. Available online: https://www.businessinsider.com/ibm-halts-hiring-for-7800-jobs-that-could-be-replaced-by-ai-report-2023-5 (accessed on 26 June 2023).
- Andriola, C.; Ellis, R.P.; Siracuse, J.J.; Hoagland, A.; Kuo, T.C.; Hsu, H.E.; Walkey, A.; Lasser, K.E.; Ash, A.S. A Novel Machine Learning Algorithm for Creating Risk-Adjusted Payment Formulas. JAMA Health Forum 2024, 5, e240625. [Google Scholar] [CrossRef] [PubMed]
- Newman-Toker, D.E.; Sharfstein, J.M. The Role for Policy in AI-Assisted Medical Diagnosis. JAMA Health Forum 2024, 5, e241339. [Google Scholar] [CrossRef] [PubMed]
- Tai-Seale, M.; Baxter, S.L.; Vaida, F.; Walker, A.; Sitapati, A.M.; Osborne, C.; Diaz, J.; Desai, N.; Webb, S.; Polston, G.; et al. AI-Generated Draft Replies Integrated Into Health Records and Physicians’ Electronic Communication. JAMA Netw. Open 2024, 7, e246565. [Google Scholar] [CrossRef] [PubMed]
- Mello, M.M.; Guha, N. ChatGPT and Physicians’ Malpractice Risk. JAMA Health Forum 2023, 4, e231938. [Google Scholar] [CrossRef] [PubMed]
- Hswen, Y.; Abbasi, J. AI Will—And Should—Change Medical School, Says Harvard’s Dean for Medical Education. JAMA 2023, 330, 1820–1823. [Google Scholar] [CrossRef] [PubMed]
- Medicine NEJo. Prescribing Large Language Models for Medicine: What’s The Right Dose? NEJM Group. 2023. Available online: https://events.nejm.org/events/617 (accessed on 2 November 2023).
- Odom-Forren, J. The Role of ChatGPT in Perianesthesia Nursing. J. PeriAnesthesia Nurs. 2023, 38, 176–177. [Google Scholar] [CrossRef] [PubMed]
- Neff, A.S.; Philipp, S. KI-Anwendungen: Konkrete Beispiele für den ärztlichen Alltag. Deutsches Ärzteblatt 2023, 120, A-236/B-207. [Google Scholar]
- Anderer, S.; Hswen, Y. Will Generative AI Tools Improve Access to Reliable Health Information? JAMA 2024, 331, 1347–1349. [Google Scholar] [CrossRef] [PubMed]
- Obradovich, N.; Johnson, T.; Paulus, M.P. Managerial and Organizational Challenges in the Age of AI. JAMA Psychiatry 2024, 81, 219–220. [Google Scholar] [CrossRef] [PubMed]
- Sonntagbauer, M.; Haar, M.; Kluge, S. Künstliche Intelligenz: Wie werden ChatGPT und andere KI-Anwendungen unseren ärztlichen Alltag verändern? Med. Klin.—Intensivmed. Notfallmedizin 2023, 118, 366–371. [Google Scholar] [CrossRef]
- Menz, B.D.; Modi, N.D.; Sorich, M.J.; Hopkins, A.M. Health Disinformation Use Case Highlighting the Urgent Need for Artificial Intelligence Vigilance: Weapons of Mass Disinformation. JAMA Intern. Med. 2024, 184, 92–96. [Google Scholar] [CrossRef] [PubMed]
- dpa. Weltgesundheits Organisation Warnt vor Risiken durch Künstliche Intelligenz im Gesundheitssektor. 2023. Available online: https://www.aerzteblatt.de/treffer?mode=s&wo=1041&typ=1&nid=143259&s=ChatGPT (accessed on 26 June 2023).
- Lühnen, J.; Mühlhauser, I.; Steckelberg, A. The Quality of Informed Consent Forms. Dtsch. Ärzteblatt Int. 2018, 115, 377–383. [Google Scholar] [CrossRef]
- Ali, R.; Connolly, I.D.; Tang, O.Y.; Mirza, F.N.; Johnston, B.; Abdulrazeq, H.F.; Galamaga, P.F.; Libby, T.J.; Sodha, N.R.; Groff, M.W.; et al. Bridging the literacy gap for surgical consents: An AI-human expert collaborative approach. NPJ Digit. Med. 2024, 7, 63. [Google Scholar] [CrossRef]
- Mirza, F.N.; Tang, O.Y.; Connolly, I.D.; Abdulrazeq, H.A.; Lim, R.K.; Roye, G.D.; Priebe, C.; Chandler, C.; Libby, T.J.; Groff, M.W.; et al. Using ChatGPT to Facilitate Truly Informed Medical Consent. NEJM AI 2024, 1, AIcs2300145. [Google Scholar] [CrossRef]
- PPR Human Experimentation. Code of ethics of the world medical association. Declaration of Helsinki. Br. Med. J. 1964, 2, 177. [Google Scholar] [CrossRef] [PubMed]
- Schulz, K.F.; Altman, D.G.; Moher, D.; the CONSORT Group. CONSORT 2010 statement: Updated guidelines for reporting parallel group randomised trials. Trials 2010, 11, 32. [Google Scholar] [CrossRef] [PubMed]
- Duffourc, M.; Gerke, S. Generative AI in Health Care and Liability Risks for Physicians and Safety Concerns for Patients. JAMA 2023, 330, 313. [Google Scholar] [CrossRef] [PubMed]
- Kanter, G.P.; Packel, E.A. Health Care Privacy Risks of AI Chatbots. JAMA 2023, 330, 311–312. [Google Scholar] [CrossRef] [PubMed]
- Minssen, T.; Vayena, E.; Cohen, I.G. The Challenges for Regulating Medical Use of ChatGPT and Other Large Language Models. JAMA 2023, 330, 315–316. [Google Scholar] [CrossRef] [PubMed]
- Gomes, B.; Ashley, E.A. Artificial Intelligence in Molecular Medicine. N. Engl. J. Med. 2023, 388, 2456–2465. [Google Scholar] [CrossRef] [PubMed]
- Hunter, D.J.; Holmes, C. Where Medical Statistics Meets Artificial Intelligence. N. Engl. J. Med. 2023, 389, 1211–1219. [Google Scholar] [CrossRef] [PubMed]
- Wachter, R.M.; Brynjolfsson, E. Will Generative Artificial Intelligence Deliver on Its Promise in Health Care? JAMA 2024, 331, 65–69. [Google Scholar] [CrossRef] [PubMed]
- Yalamanchili, A.; Sengupta, B.; Song, J.; Lim, S.; Thomas, T.O.; Mittal, B.B.; Abazeed, M.E.; Teo, P.T. Quality of Large Language Model Responses to Radiation Oncology Patient Care Questions. JAMA Netw. Open 2024, 7, e244630. [Google Scholar] [CrossRef] [PubMed]
- Roccetti, M.; Delnevo, G.; Casini, L.; Salomoni, P. A Cautionary Tale for Machine Learning Design: Why We Still Need Human-Assisted Big Data Analysis. Mob. Netw. Appl. 2020, 25, 1075–1083. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| General Anesthesia | Ambulant Anesthesia | Spinal Anesthesia | Epidural Catheter | Peripheral Nerve Block | Central Venous Line | |
|---|---|---|---|---|---|---|
| Risks | 25 | 3 | 25 | 28 | 21 | 24 |
| Procedures | 9 | 2 | 3 | 4 | 7 | 9 |
| Preparations | 5 | 8 | 2 | 4 | 3 | 1 |
| Patient enquiries | 1 | 1 | 1 | 1 | 1 | 1 |
| Physicians’ consultation | 1 | 1 | 1 | 1 | 1 | 1 |
| Patient data | 1 | 1 | 1 | 1 | 1 | 1 |
| Signature | 1 | 1 | 1 | 1 | 1 | 1 |
| Total | 43 | 17 | 43 | 40 | 35 | 38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raimann, F.J.; Neef, V.; Hennighausen, M.C.; Zacharowski, K.; Flinspach, A.N. Evaluation of AI ChatBots for the Creation of Patient-Informed Consent Sheets. Mach. Learn. Knowl. Extr. 2024, 6, 1145-1153. https://doi.org/10.3390/make6020053
Raimann FJ, Neef V, Hennighausen MC, Zacharowski K, Flinspach AN. Evaluation of AI ChatBots for the Creation of Patient-Informed Consent Sheets. Machine Learning and Knowledge Extraction. 2024; 6(2):1145-1153. https://doi.org/10.3390/make6020053
Chicago/Turabian StyleRaimann, Florian Jürgen, Vanessa Neef, Marie Charlotte Hennighausen, Kai Zacharowski, and Armin Niklas Flinspach. 2024. "Evaluation of AI ChatBots for the Creation of Patient-Informed Consent Sheets" Machine Learning and Knowledge Extraction 6, no. 2: 1145-1153. https://doi.org/10.3390/make6020053
APA StyleRaimann, F. J., Neef, V., Hennighausen, M. C., Zacharowski, K., & Flinspach, A. N. (2024). Evaluation of AI ChatBots for the Creation of Patient-Informed Consent Sheets. Machine Learning and Knowledge Extraction, 6(2), 1145-1153. https://doi.org/10.3390/make6020053