

Unraveling COVID-19 Dynamics via Machine Learning and XAI: Investigating Variant Influence and Prognostic Classification




Abstract
:1. Introduction
2. Related Work
2.1. Related Work on Machine Learning Algorithms
2.2. Related Work on Identified COVID-19 Risk Factors
3. Methodology and Experiments
3.1. Business Understanding
3.2. Data Understanding
3.2.1. Datasets from 2020
3.2.2. Datasets from 2021 and 2022
3.2.3. COVID-19 Variants Dataset
3.3. Data Preparation
3.4. Modeling
3.4.1. Predicting the Target Class “dead”
3.4.2. Predicting the Target Class “icu”
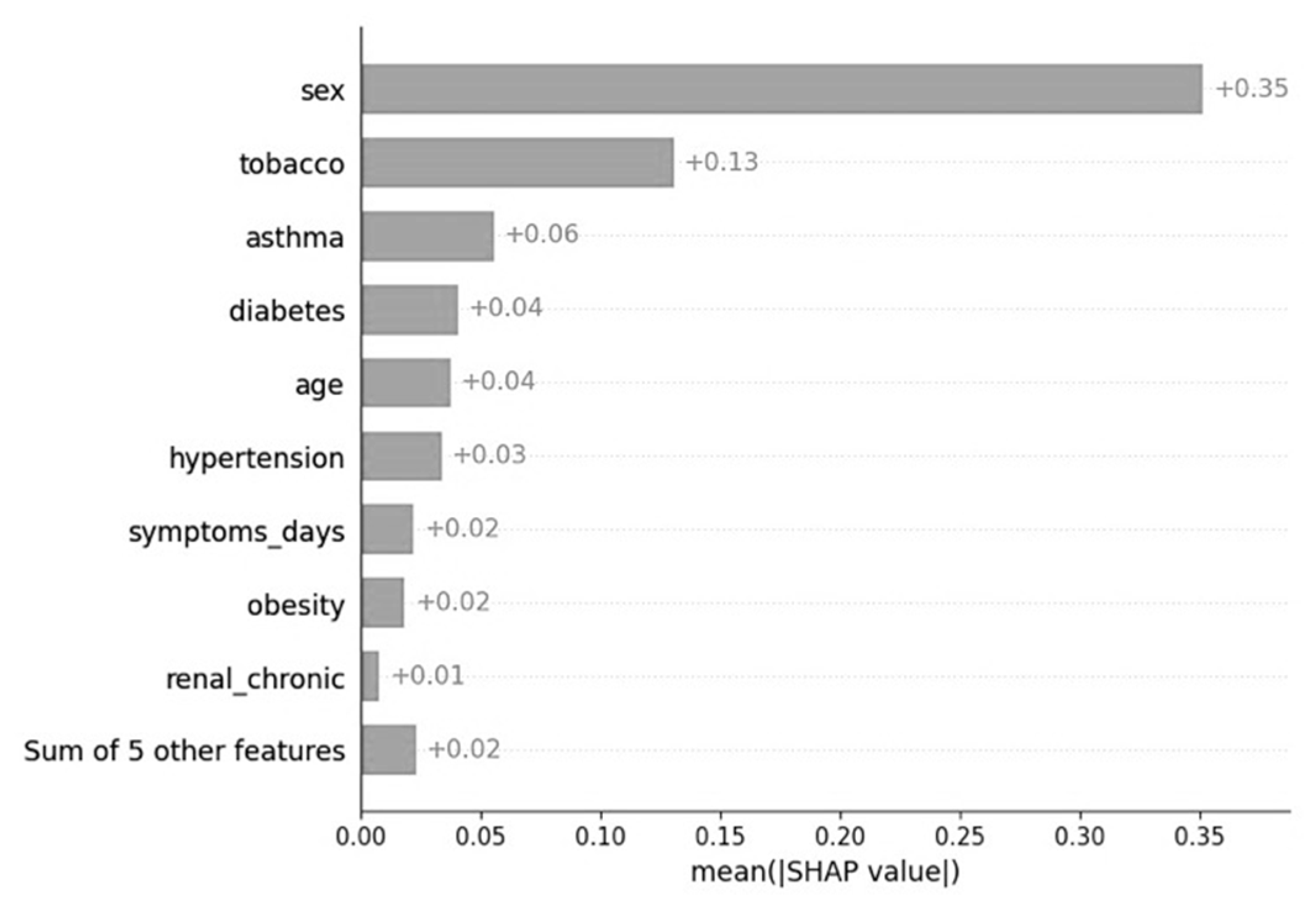
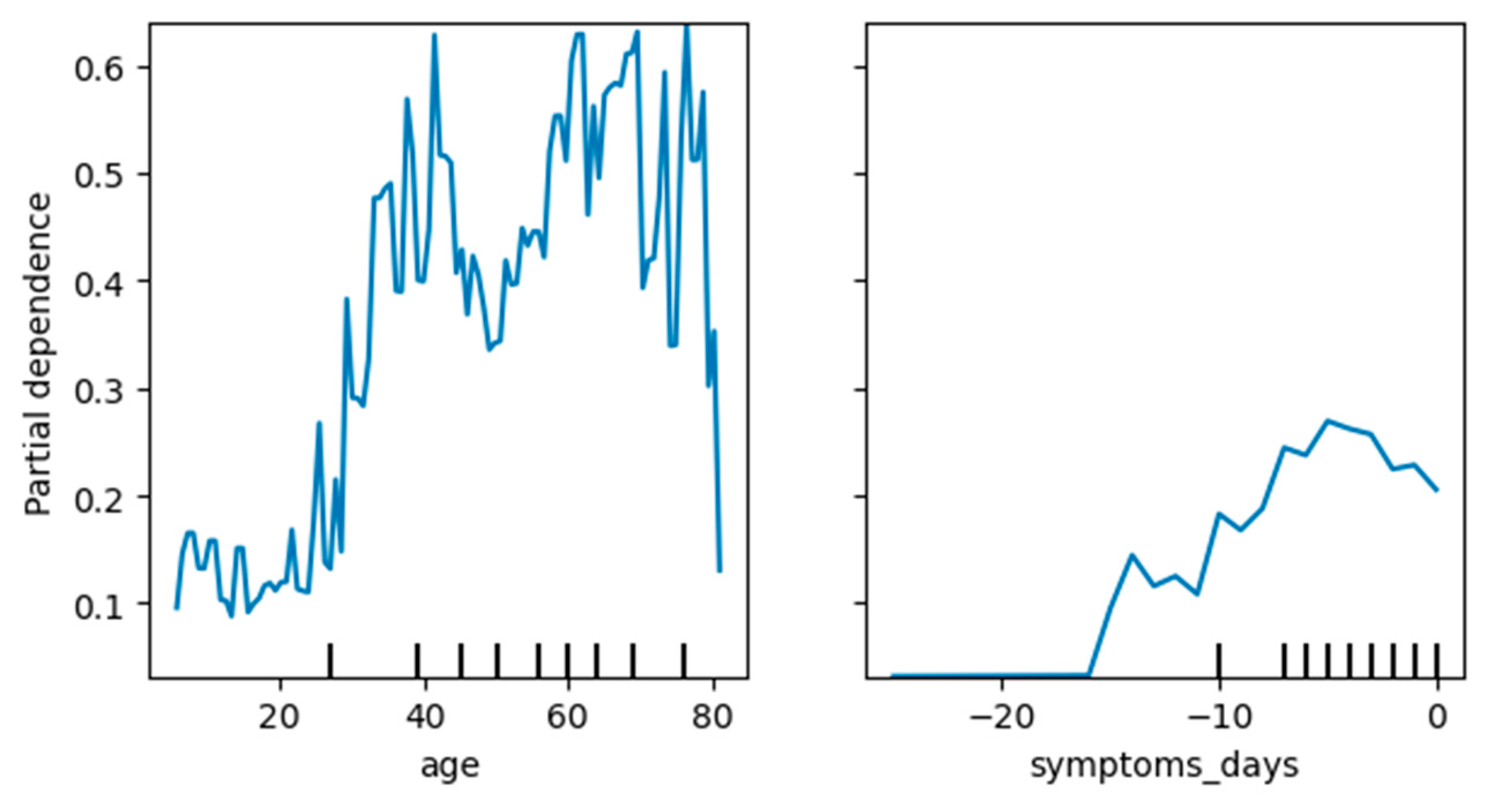
3.4.3. Knowledge Extraction—Important COVID-19 Attributes
3.5. Evaluation
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cascella, M.; Rajnik, M.; Aleem, A.; Dulebohn, S.C.; Di Napoli, R. Features, Evaluation, and Treatment of Coronavirus (COVID-19); StatPearls Publishing: Treasure Island, FL, USA, 2023. Available online: https://www.ncbi.nlm.nih.gov/books/NBK554776/ (accessed on 21 January 2023).
- An, C.; Lim, H.; Kim, D.-W.; Chang, J.H.; Choi, Y.J.; Kim, S.W. Machine learning prediction for mortality of patients diagnosed with COVID-19: A nationwide Korean cohort study. Sci. Rep. 2020, 10, 18716. [Google Scholar] [CrossRef] [PubMed]
- Drefahl, S.; Wallace, M.; Mussino, E.; Aradhya, S.; Kolk, M.; Brandén, M.; Malmberg, B.; Andersson, G. A population-based cohort study of socio-demographic risk factors for COVID-19 deaths in Sweden. Nat. Commun. 2020, 11, 5097. [Google Scholar] [CrossRef] [PubMed]
- Guan, X.; Zhang, B.; Fu, M.; Li, M.; Xu, Y.; Zhu, Y.; Peng, J.; Guo, H.; Lu, Y. Clinical and inflammatory features based machine learning model for fatal risk prediction of hospitalized COVID-19 patients: Results from a retrospective cohort study. Ann. Med. 2021, 53, 257–266. [Google Scholar] [CrossRef] [PubMed]
- Wong, K.C.Y.; Xiang, Y.; Yin, J.; So, H.-C. Uncovering Clinical Risk Factors and Predicting Severe COVID-19 Cases Using UK Biobank Data: Machine Learning Approach. JMIR Public Health Surveill. 2021, 7, e29544. [Google Scholar] [CrossRef] [PubMed]
- Krajah, A.; Almadani, Y.F.; Saadeh, H.; Sleit, A. Analyzing COVID-19 Data Using Various Algorithms. In Proceedings of the 2021 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 16–18 November 2021; pp. 66–71. [Google Scholar]
- Mukherjee, T. COVID-19 Patient Pre-Condition Dataset. 2020. Available online: https://Kaggle.com (accessed on 1 March 2023).
- Fransiska, A.; Holy, C.; Prima Rosa, P.H. Classification of COVID-19 Patients Requiring Intensive Care Unit. In Proceedings of the 25th International Computer Science and Engineering Conference, Chiang Rai, Thailand, 18–20 November 2021; pp. 469–472. [Google Scholar]
- Shi, Y.; Wang, Y.; Shao, C.; Huang, J.; Gan, J.; Huang, X.; Bucci, E.; Piacentini, M.; Ippolito, G.; Melino, G. COVID-19 infection: The perspectives on immune responses. Cell Death Differ. 2020, 27, 1451–1454. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Yu, T.; Du, R.; Fan, G.; Liu, Y.; Liu, Z.; Xiang, J.; Wang, Y.; Song, B.; Gu, X.; et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: A retrospective cohort study. Lancet 2020, 395, 1054–1062. [Google Scholar] [CrossRef] [PubMed]
- Majnarić, L.T.; Babič, F.; O’Sullivan, S.; Holzinger, A. AI and Big Data in Healthcare: Towards a More Comprehensive Research Framework for Multimorbidity. J. Clin. Med. 2021, 10, 766. [Google Scholar] [CrossRef]
- Bhargava, A.; Fukushima, E.A.; Levine, M.; Zhao, W.; Tanveer, F.; Szpunar, S.M.; Saravolatz, L. Predictors for Severe COVID-19 Infection. Clin. Infect. Dis. 2020, 71, 1962–1968. [Google Scholar] [CrossRef]
- Aziz, M.; Haghbin, H.; Lee-Smith, W.; Goyal, H.; Nawras, A.; Adler, D.G. Gastrointestinal predictors of severe COVID-19: Systematic review and meta-analysis. Ann. Gastroenterol. 2020, 33, 615–630. [Google Scholar] [CrossRef]
- Mostaza, J.M.; Garcia-Iglesias, F.; Gonzalez-Alegre, T.; Blanco, F.; Varas, M.; Hernandez-Blanco, C.; Hontañón, V.; Jaras-Hernández, M.J.; Martínez-Prieto, M.; Negreiros, A.Z.; et al. Clinical course and prognostic factors of COVID-19 infection in an elderly hospitalized population. Arch. Gerontol. Geriatr. 2020, 91, 104204. [Google Scholar] [CrossRef] [PubMed]
- Albitar, O.; Ballouze, R.; Ooi, J.P.; Ghadzi, S.M.S. Risk factors for mortality among COVID-19 patients. Diabetes Res. Clin. Pr. 2020, 166, 108293. [Google Scholar] [CrossRef] [PubMed]
- Xu, E.; Xie, Y.; Al-Aly, Z. Long-term neurologic outcomes of COVID-19. Nat. Med. 2022, 28, 2406–2415. [Google Scholar] [CrossRef] [PubMed]
- Schröer, C.; Kruse, F.; Marx Gómez, J. A Systematic Literature Review on Applying CRISP-DM Process Model. Procedia Comput. Sci. 2021, 181, 526–534. [Google Scholar] [CrossRef]
- Alsharif, M.H.; Alsharif, Y.H.; Chaudhry, S.A.; Albreem, M.A.; Jahid, A.; Hwang, E. Artificial intelligence technology for diagnosing COVID-19 cases: A review of substantial issues. Eur. Rev. Med. Pharmacol. Sci. 2020, 24, 9226–9233. [Google Scholar] [CrossRef] [PubMed]
- Alsharif, M.H.; Alsharif, Y.H.; Yahya, K.; Alomari, O.A.; Albreem, M.A.; Jahid, A. Deep learning applications to combat the dissemination of COVID-19 disease: A review. Eur. Rev. Med. Pharmacol. Sci. 2020, 24, 11455–11460. [Google Scholar] [CrossRef] [PubMed]
- Gobierno de Mexico. Datos Abiertos. 2021. Available online: https://www.gob.mx/salud/documentos/datos-abiertos-152127 (accessed on 1 March 2023).
- Swana, E.F.; Doorsamy, W.; Bokoro, P. Tomek Link and SMOTE Approaches for Machine Fault Classification with an Imbalanced Dataset. Sensors 2022, 22, 3246. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J.F.; Korevaar, D.A.; Matczak, S.; Chalumeau, M.; Allali, S.; Toubiana, J. COVID-19-Related Fatalities and Intensive-Care-Unit Admissions by Age Groups in Europe: A Meta-Analysis. Front. Med. 2021, 7, 560685. [Google Scholar] [CrossRef] [PubMed]
- Kämpe, J.; Bohlin, O.; Jonsson, M.; Hofmann, R.; Hollenberg, J.; Wahlin, R.R.; Svensson, P.; Nordberg, P. Risk factors for severe COVID-19 in the young—Before and after ICU admission. Ann. Intensiv. Care 2023, 13, 31. [Google Scholar] [CrossRef] [PubMed]
- Falcone, M.; Suardi, L.R.; Tiseo, G.; Barbieri, C.; Giusti, L.; Galfo, V.; Forniti, A.; Caroselli, C.; Della Sala, L.; Tempini, S.; et al. Early Use of Remdesivir and Risk of Disease Progression in Hospitalized Patients with Mild to Moderate COVID-19. Clin. Ther. 2022, 44, 364–373. [Google Scholar] [CrossRef]
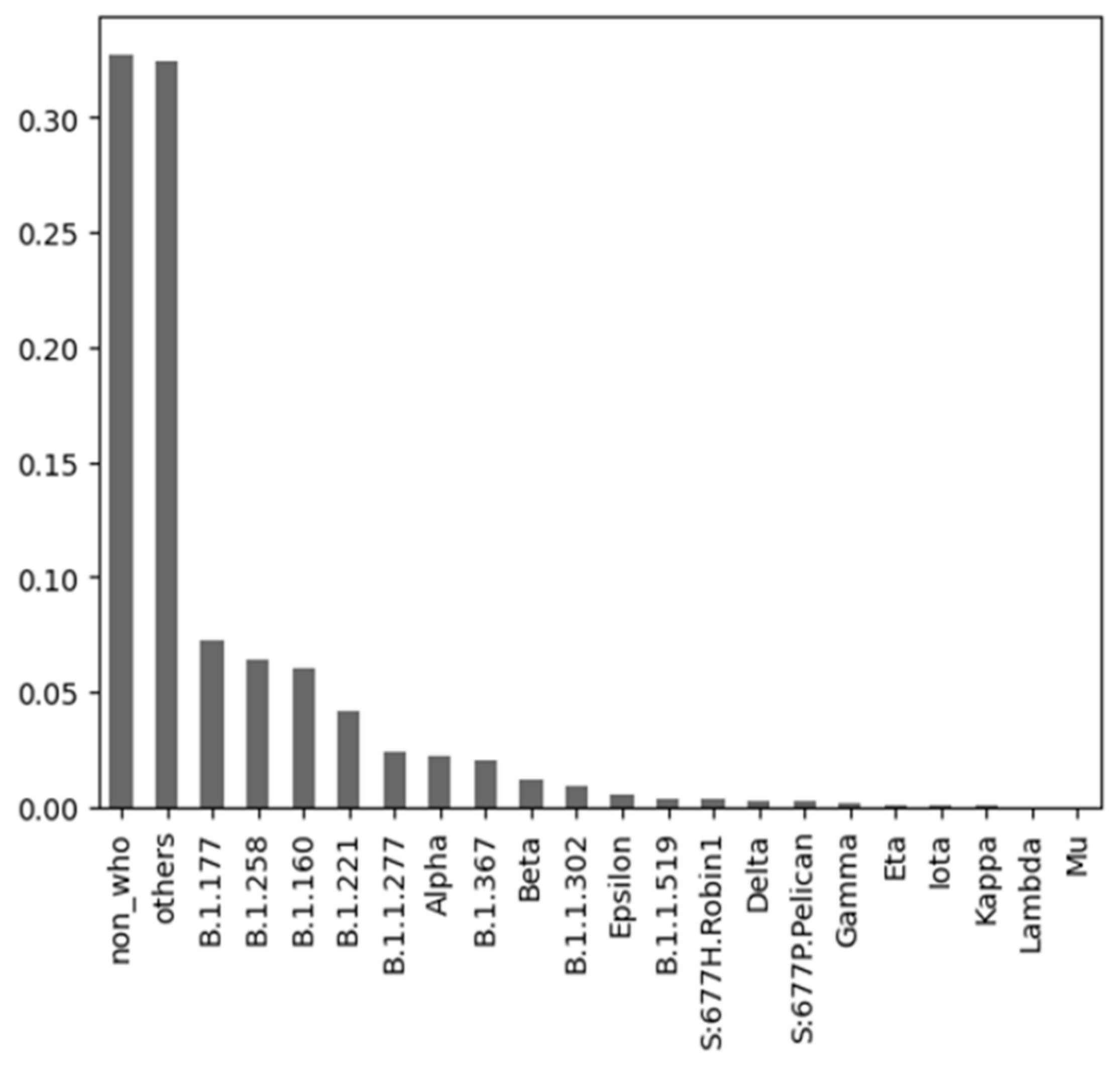
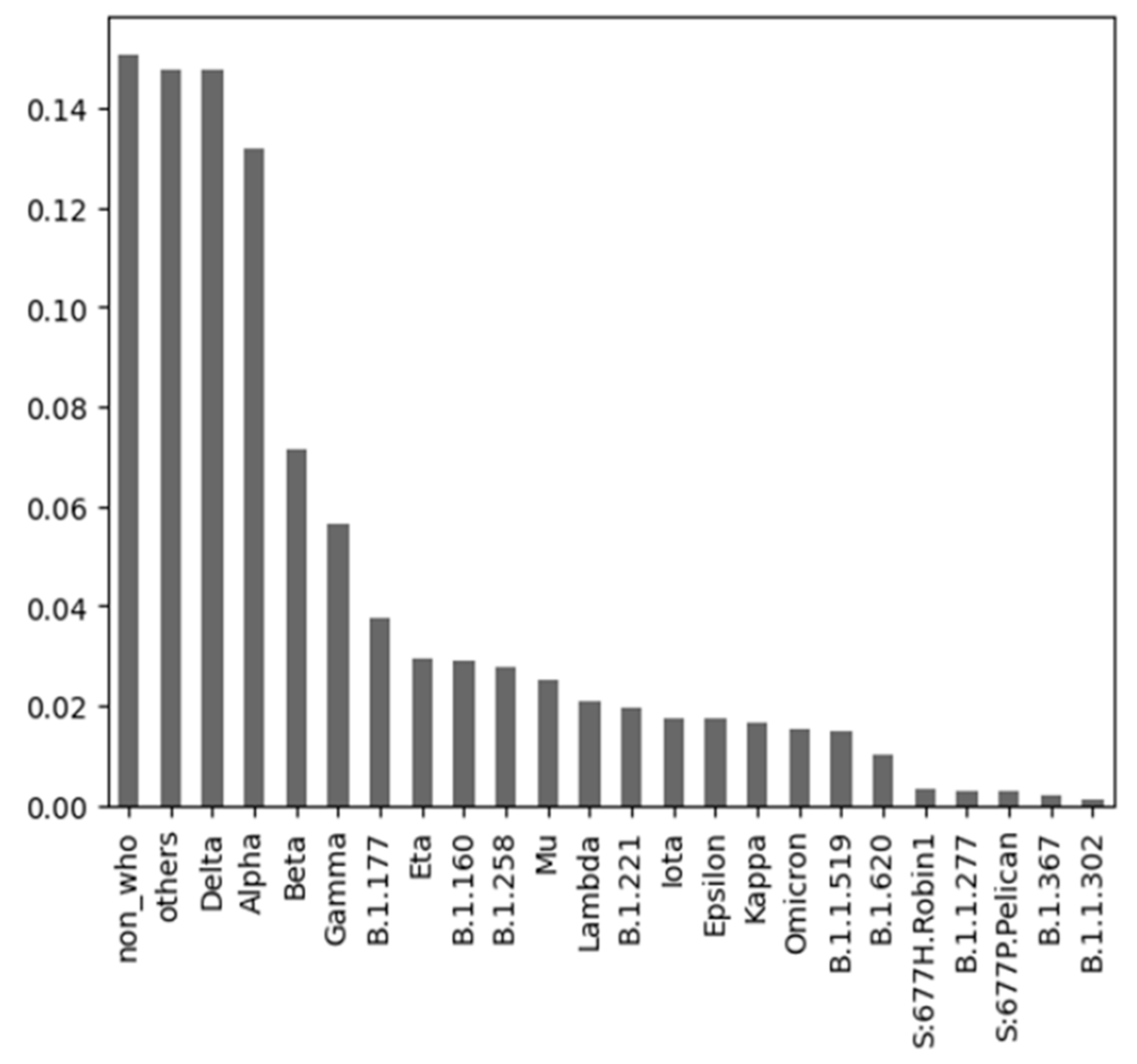

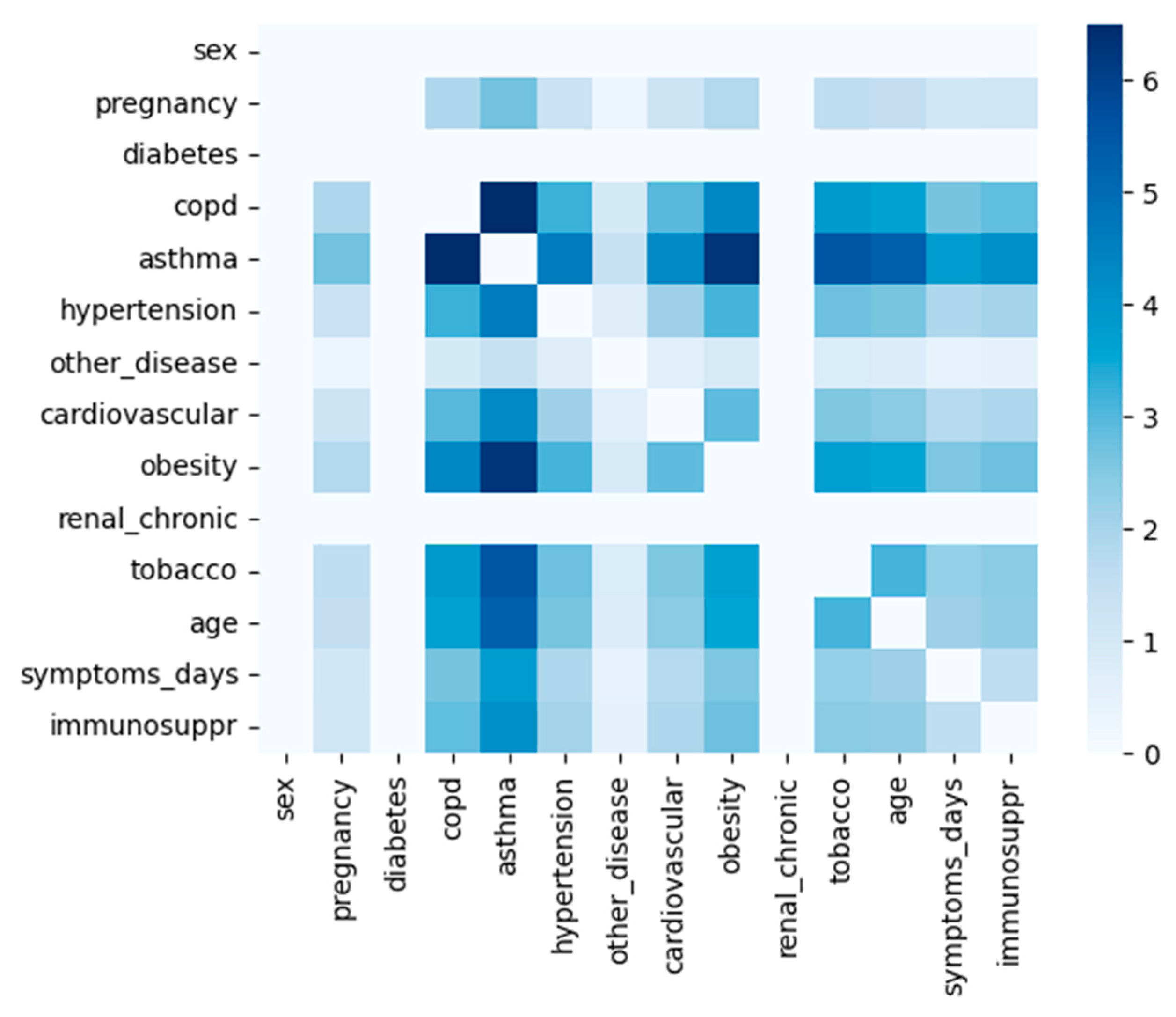
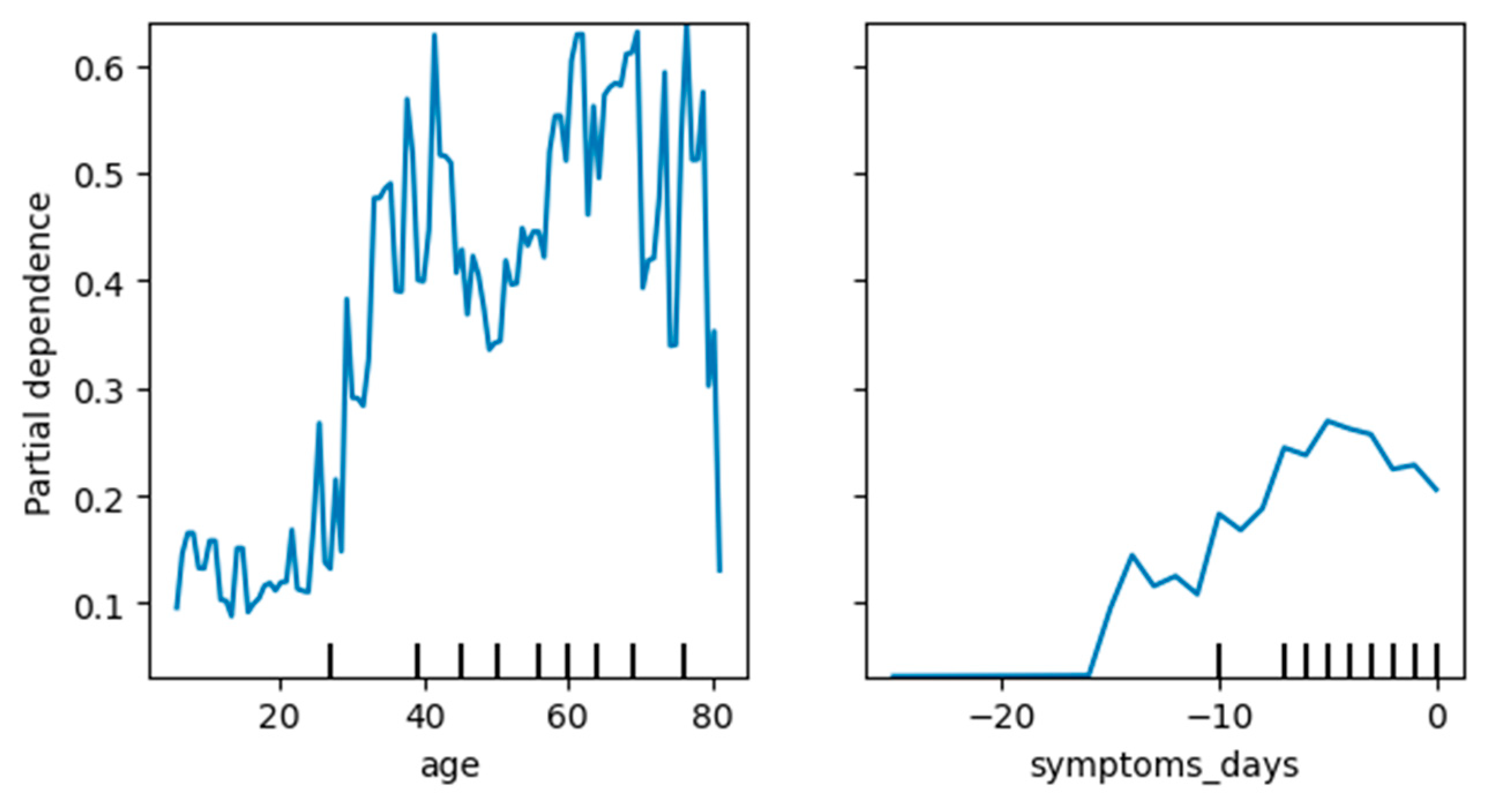

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Predicted Class | Used Algorithms | Resulting Statistics |
|---|---|---|---|
| Kenneth Chi-Yin Wong et al. [5] | Severity of COVID-19 cases | XGBoost prediction model | AUC ROC: 69.6% to 82.5%; recall: 0.5% to 74.8%; sensitivity: 55.7% to 83%; specificity: 66.6% to 71.9%; accuracy: 66.5% to 68.6%. Best analysis: 72% accuracy for fatal cases vs. outpatient cases. |
| Krajah et al. [6] | Patient Survival (Death or Survival) | Logistic regression, LDA, CART, SVM, NB, k-NN | Logistic regression: average accuracy 84%; SVM: average accuracy 85%; overall success rates: logistic regression 83% and SVM 82%. |
| Holy and Rosa [8] | Placement in ICU | SVM (linear, polynomial, and RBF) | Accuracies obtained with 5-fold cross-validation using 16 predictors: Linear SVM: 77.16%; Polynomial SVM: 80.44%; RBF SVM: 81.27%. |
| Study and Reference | Kind of Data Used | Methodology for Risk Factor Identification | Identified Risk Factors |
|---|---|---|---|
| Wuhan Cohort Study [14] | Demographics, laboratory data, clinical information, and treatment records | Univariate and multivariate logistic regression | Diabetes, coronary heart disease, older age, lymphopenia, leukocytosis, higher SOFA score, and d-dimer > 1 μg/mL |
| Global Analysis by Orwa Albitar et al. [15] | Demographics, comorbidities, and key dates (hospital admission, test results, symptom onset, discharge, or death) | Comprehensive analysis based on open databases | Older age, male gender, hypertension, diabetes, and differences in risk by nationality (American vs. Asian). The following risk factors are associated but not significant: Chronic lung disease, chronic kidney disease, and cardiovascular diseases |
| Sociodemographic Study by Sven Drefahl et al. [3] | Data on recorded COVID-19 deaths in Sweden | Survival analysis | Men, low or no income, only primary education, unmarried, and born in a low or middle-income county |
| Feature | Coefficient | p-Value |
|---|---|---|
| sex | 0.2531 | 0 |
| tobacco | 0.1967 | 0 |
| asthma | 0.1698 | 0 |
| age | 0.0673 | 1.3263 × 10−69 |
| diabetes | 0.0477 | 5.2488 × 10−54 |
| hypertension | 0.0536 | 2.0673 × 10−53 |
| renal_chronic | 0.0277 | 2.0746 × 10−28 |
| other_disease | 0.0241 | 3.7978 × 10−19 |
| pregnancy | 0.0279 | 3.3495 × 10−16 |
| copd | 0.0178 | 1.221 × 10−12 |
| immunosuppressed | 0.0136 | 1.566 × 10−8 |
| cardiovascular | 0.0023 | 0.34459 |
| Correct ICU Predictions | Incorrect ICU Predictions | ||
|---|---|---|---|
| not asthma | 0.2290 | False negative | |
| not copd | 0.1555 | symptoms_days <= −7 | −0.0608 |
| not cardiovascular | 0.1466 | age <= 38 | −0.0416 |
| not renal_chronic | 0.1306 | tobacco | −0.0126 |
| not tobaco | 0.1195 | cardiovascular | −0.0106 |
| not other_disease | 0.1008 | False positive | |
| −4 < symptoms_days <= −2 | 0.0190 | not asthma | 0.2164 |
| age > 64 | 0.0253 | not copd | 0.1522 |
| 51 < age <= 64 | 0.0032 | not cardiovascular | 0.1452 |
| not renal_chronic | 0.1315 | ||
| not tobacco | 0.1109 | ||
| not immunosuppr | 0.1095 |
| MEX Data—Model Comparison—Target Class “DEAD” (Accuracy) | ||||
|---|---|---|---|---|
| Reference Model 2020 by [6] | Model 2020 | Model 2021 | Model 2021 + Variants | |
| LR accuracy—predictors by [6] | 0.828 | 0.842 | 0.7683 | 0.7688 |
| RF accuracy—predictors by [6] | 0.82 | 0.803 | 0.7506 | 0.75 |
| LR accuracy—own predictors | 0.828 | 0.71 | 0.73 | 0.73 |
| RF accuracy—own predictors | 0.82 | 0.71 | 0.73 | 0.73 |
| MEX Data—Model Comparison—Target Class “icu” (Accuracy) | ||||
|---|---|---|---|---|
| Reference Model 2020 by [8] | Model 2020 | Model 2021 | Model 2021 + Variants | |
| SVM-linear | 0.7715 | 0.4101 | 0.9662 | 0.9662 |
| SVM-RBF | 0.8154 | 0.5631 | 0.9662 | 0.9662 |
| Model | Precision Class 0 | Precision Class 1 | Accuracy | AUC |
|---|---|---|---|---|
| XGBoost | 0.9 | 0.35 | 0.87 | 0.57 |
| CatBoost | 0.9 | 0.83 | 0.9 | 0.57 |
| LightGBM | 0.91 | 0.5 | 0.89 | 0.59 |
| Random Forest | 0.89 | 0.4 | 0.88 | 0.52 |
| Logistic Regression | 0.9 | 0.6 | 0.89 | 0.54 |
| Naive Bayes | 0.91 | 0.24 | 0.82 | 0.59 |
| SGD | 0.89 | 0 | 0.89 | 0.5 |
| SVM-linear | 0.89 | 0 | 0.89 | 0.5 |
| SVM-RBF | 0.89 | 0 | 0.89 | 0.5 |
| Model | Precision Class 0 | Precision Class 1 | Accuracy | AUC |
|---|---|---|---|---|
| XGBoost | 0.93 | 0.83 | 0.93 | 0.71 |
| CatBoost | 0.93 | 0.87 | 0.92 | 0.68 |
| LightGBM | 0.93 | 0.83 | 0.93 | 0.71 |
| Random Forest | 0.91 | 0.9 | 0.91 | 0.63 |
| Logistic Regression | 0.92 | 0.92 | 0.92 | 0.66 |
| Naive Bayes | 0.93 | 0.44 | 0.88 | 0.68 |
| SGD | 0.89 | 0.29 | 0.88 | 0.51 |
| SVM-linear | 0.93 | 0.76 | 0.92 | 0.68 |
| SVM-RBF | 0.89 | 0 | 0.89 | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lohaj, O.; Paralič, J.; Bednár, P.; Paraličová, Z.; Huba, M. Unraveling COVID-19 Dynamics via Machine Learning and XAI: Investigating Variant Influence and Prognostic Classification. Mach. Learn. Knowl. Extr. 2023, 5, 1266-1281. https://doi.org/10.3390/make5040064
Lohaj O, Paralič J, Bednár P, Paraličová Z, Huba M. Unraveling COVID-19 Dynamics via Machine Learning and XAI: Investigating Variant Influence and Prognostic Classification. Machine Learning and Knowledge Extraction. 2023; 5(4):1266-1281. https://doi.org/10.3390/make5040064
Chicago/Turabian StyleLohaj, Oliver, Ján Paralič, Peter Bednár, Zuzana Paraličová, and Matúš Huba. 2023. "Unraveling COVID-19 Dynamics via Machine Learning and XAI: Investigating Variant Influence and Prognostic Classification" Machine Learning and Knowledge Extraction 5, no. 4: 1266-1281. https://doi.org/10.3390/make5040064
APA StyleLohaj, O., Paralič, J., Bednár, P., Paraličová, Z., & Huba, M. (2023). Unraveling COVID-19 Dynamics via Machine Learning and XAI: Investigating Variant Influence and Prognostic Classification. Machine Learning and Knowledge Extraction, 5(4), 1266-1281. https://doi.org/10.3390/make5040064