
Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures


Abstract
1. Introduction
- Exploration of how MMML leverages pre-trained models to extract features from both textual and visual data, highlighting methods that enhance data representation.
- A comprehensive review of fusion techniques, detailing approaches for integrating text and image data, along with an analysis of their benefits and impacts.
- Discussion of the limitations and challenges encountered in MMML.
- Examination of the resilience of MMML models against noisy and adversarial data to determine their adaptability and practicality in real-world scenarios.
2. Methodology
2.1. Research Questions
- RQ1: Are well-established, pre-existing architectures utilized in multimodal machine learning models?
- –
- RQ1.1 Which pre-trained models are predominantly employed for the processing and learning of image and text data?
- –
- RQ1.2 Which datasets are commonly utilized for benchmarking these models?
- RQ2: Which fusion techniques are prevalently adopted in MMML?
- RQ3: What limitations or obstacles are encountered when using these architectures?
- RQ4: In what way can MMML models be robust against noise and adversarial data?
2.2. Searching Methodology
- Scopus;
- IEEE Xplore;
- SpringerLink;
- ACM Digital Library;
- Semantic Scholar.
- Scopus
- –
- Query executed: (ABS(machine AND learning) AND TITLE (multimodal) AND ABS(image) AND ABS (text) AND (TITLE-ABS (deep AND learning) OR TITLE-ABS (neural AND network))).
- –
- Filter criteria: no filters were applied.
- IEEE Xplore
- –
- Query executed: ((((“Document Title”:multimodal) AND ((“Document Title”: “deep”) OR (“Document Title”:“machine learning”) OR (“Abstract”:“deep”) OR (“Abstract”: “machine learning”) OR (“Abstract”:“neural network”)) AND (“Abstract”:text) AND (“Abstract”:image)) NOT (“Document Title”:“audiovisual”) NOT (“Document Title”:“video”))).
- –
- Filter criteria: no filters were applied.
- SpringerLink
- –
- Query executed: where the title contains multimodal; query: text AND image AND (“deep learning” OR “machine learning” OR “neural network”); sort by relevance.
- –
- Filter criteria: the top 32 most pertinent entries were selected.
- ACM Digital Library
- –
- Abstract: (neural) AND Title: (multimodal) AND Abstract: (deep learning) AND NOT Title: (video) AND NOT Title: (audio) AND E-Publication Date: (27 June 2018 TO 27 June 2023).
- –
- Filter criteria: sorted by relevance.
- Semantic Scholar
- –
- Query executed: keywords: multimodal machine learning deep learning image text. Dates: (1 January 2018 To 31 April 2023). Sort by relevance.
- –
- Filter criteria: the top 30 entries by relevance, including a ‘TL;DR’ visual summary, were chosen.
2.3. Selection Criteria
2.3.1. Inclusion Criteria
- Papers that worked with both text and image data.
- Papers that discussed multimodal machine learning model based on neural networks.
- Papers that discussed the performance of multimodal machine learning models.
- Papers that are in English.
2.3.2. Exclusion Criteria
- Papers that have a length less than four pages.
- Papers that are not in English.
- Papers that are not peer-reviewed.
- Papers that are not published in any conference/journal.
- Articles with full text not available in the specified database.
- Opinion papers.
- Papers that worked with data other than image and text.
2.4. Data Extraction and Synthesis
3. RQ1: Are Well-Established, Pre-Existing Architectures Utilized in Multimodal Machine Learning Models?
3.1. RQ1.1 Which Pre-Trained Models Are Predominantly Employed for the Processing and Learning Image and Text Data?
3.1.1. Text Feature Extractor

{kind=link}
{kind=link}
| Architecture Name | Article | Total Articles |
|---|---|---|
| BERT | [21,22,23,24,25,26,27,28,34,35,36,37,38,39,40,41,42,43,44,45,46] | 21 |
| LSTM | [22,30,32,33,38,41,47,48,49,50] | 10 |
| Bi-LSTM | [45,51,52,53,54] | 5 |
| Residual Bi-LSTM | [55] | 1 |
| TF-IDF | [56] | 1 |
| GRU | [41,57,58] | 3 |
| GREEK BERT | [59] | 1 |
| RoBERTa | [26,29] | 2 |
| Text CNN | [31,45,60,61] | 4 |
| CLIP ViT-L/14 | [62] | 1 |
| Bi-GRU | [63] | 1 |
| VADER | [64] | 1 |
| Doc2Vec | [65] | 1 |
| RNN | [40,41] | 2 |
| LinearSVC | [65] | 1 |
| LSTM-RNN | [66] | 1 |
| GloVe | [67,68] | 2 |
| VD-CNN | [69] | 1 |
| Not Applicable | 29 |
3.1.2. Image Feature Extractor
3.1.3. Description of Language and Image Architectures
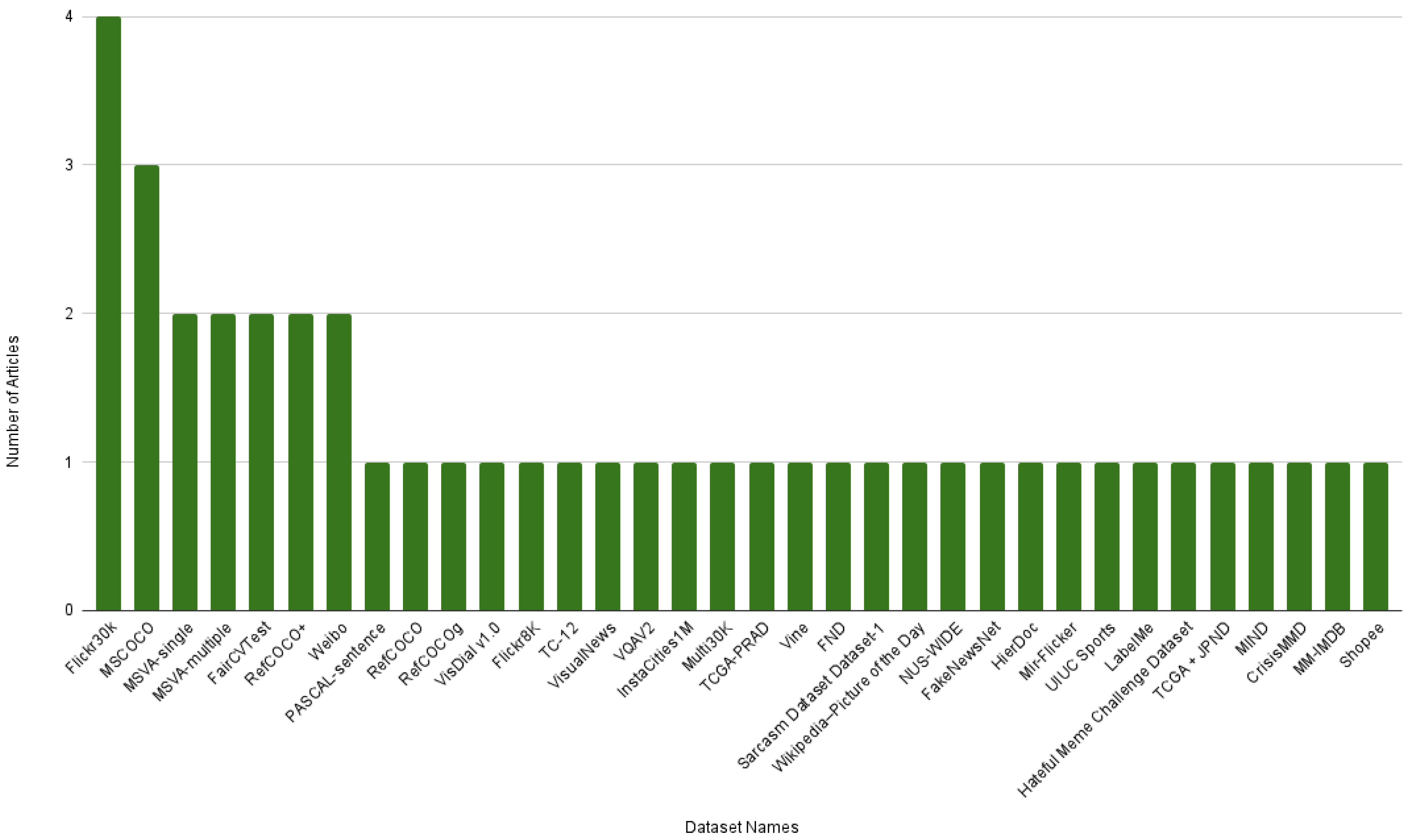
3.2. RQ1.2 Which Datasets Are Commonly Utilized for Benchmarking These Models?
4. RQ2: Which Fusion Techniques Are Prevalently Adopted in MMML?
- Concatenation Technique: This method involves the straightforward combination of textual and visual vectors to create a unified representation, facilitating the simultaneous processing of both data types. For instance, Palani et al. [21] concatenated text and image feature vectors to generate multimodal feature vectors, thereby harnessing the strengths of both text and visual information. The authors performed the concatenation by averaging the vector values in each vector position. Similarly, Paraskevopoulos et al. [59] applied the concatenation technique to merge text and visual encoders, assembling them into a classifier model to enhance the model’s interpretative power.
- Attention Technique: This approach utilizes the attention mechanism to focus on specific parts of the text and image features, enhancing the model’s ability to discern relevant information from both modalities for improved decision-making. Ghosal et al. [52] utilized an attention mechanism as a fusion technique for detecting appropriateness in scholarly submissions, acknowledging that not all modalities are equally important. By introducing an attention layer and computing attention scores, the model could prioritize modalities with higher relevance, as demonstrated by Zhang et al. [35] who employed a multi-head attention mechanism for the joint representation of image and text features, calculating attention scores to weight the importance of images for source words. Xu et al. [45] further explored this technique by using the attention mechanism to discern relationships between words in a sentence and corresponding image regions, thereby ensuring a meaningful association between text and image features.
- Weight-based Technique: This category includes Early Fusion, Late Fusion, and Intermediate Fusion techniques, each applying different weightage strategies to the integration process, allowing for a nuanced amalgamation of modalities at various stages of the model’s architecture. Hossain et al. [54] utilized Early Fusion for disaster identification by merging image and text features, ensuring equal representation from each modality by taking the same number of nodes from the last hidden layer of each modality. This technique was also applied by Hangloo and Arora [22] for detecting fake news in social media posts. Late Fusion, on the other hand, is applied after feature computation, as seen in the work of Thuseethan et al. [69] for sentiment analysis, where it directly integrates features computed for attention-heavy words and salient image regions, showcasing the versatility of weight-based fusion in constructing multimodal frameworks.
- Deep Learning Architectures: In the field of multimodal deep learning architectures, the development and application of diverse deep learning models have significantly advanced the area of multimodal feature representation. These architectures facilitate enhanced fusion and interpretation of information across different data modalities. A notable example is using Bi-LSTM by Asgari-Chenaghlu et al. [34] for integrating image and text features, showcasing the model’s ability to handle sequential data effectively. Additionally, Yue et al. [24] introduced a knowledge-based network, ConceptNet, to fuse data. This network employs the calculation of pointwise mutual information for matrix entries, further refined by smoothing with the contextual distribution, illustrating an innovative approach to integrating multimodal data.
5. RQ3: What Limitations or Obstacles Are Encountered When Using These Architectures?
- Dataset Size: One of the primary challenges in MMML models is determining the optimal size for datasets, as these models require large datasets due to data integration from multiple modalities. Data preprocessing for such vast amounts of data is costly and computationally intensive [9]. Furthermore, the disparity in size and complexity between image and text datasets complicate their simultaneous training [82].
- Data Annotation: Most publicly available datasets for text and images are tailored for specific tasks, necessitating the creation of custom datasets for new applications. This process involves data annotation, which, on a large scale, is often not readily accessible [83].
- Noisy Data: The presence of noisy data within multimodal contexts can lead to misclassification [26]. The accuracy of outcomes diminishes if one of the modalities contains noisy data, underscoring the importance of data quality in MMML models.
6. RQ4: In What Way MMML Models Can Be Robust against Noise and Adversarial Data?
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Talukder, S.; Barnum, G.; Yue, Y. On the benefits of early fusion in multimodal representation learning. arXiv 2020, arXiv:2011.07191. [Google Scholar] [CrossRef]
- Gao, J.; Li, P.; Chen, Z.; Zhang, J. A survey on deep learning for multimodal data fusion. Neural Comput. 2020, 32, 829–864. [Google Scholar] [CrossRef] [PubMed]
- Siriwardhana, S.; Kaluarachchi, T.; Billinghurst, M.; Nanayakkara, S. Multimodal emotion recognition with transformer-based self supervised feature fusion. IEEE Access 2020, 8, 176274–176285. [Google Scholar] [CrossRef]
- Chai, W.; Wang, G. Deep vision multimodal learning: Methodology, benchmark, and trend. Appl. Sci. 2022, 12, 6588. [Google Scholar] [CrossRef]
- Choi, J.; Lee, J. Embracenet: A robust deep learning architecture for multimodal classification. Inf. Fusion 2019, 51, 259–270. [Google Scholar] [CrossRef]
- Kline, A.; Wang, H.; Li, Y.; Dennis, S.; Hutch, M.; Xu, Z.; Wang, F.; Cheng, F.; Luo, Y. Multimodal machine learning in precision health: A scoping review. npj Digit. Med. 2022, 5, 171. [Google Scholar] [CrossRef]
- Bayoudh, K.; Knani, R.; Hamdaoui, F.; Mtibaa, A. A survey on deep multimodal learning for computer vision: Advances, trends, applications, and datasets. Vis. Comput. 2021, 38, 2939–2970. [Google Scholar] [CrossRef]
- Aggarwal, A.; Srivastava, A.; Agarwal, A.; Chahal, N.; Singh, D.; Alnuaim, A.; Alhadlaq, A.; Lee, H. Two-way feature extraction for speech emotion recognition using deep learning. Sensors 2022, 22, 2378. [Google Scholar] [CrossRef]
- Barua, P.; Chan, W.; Dogan, S.; Baygin, M.; Tuncer, T.; Ciaccio, E.; Islam, M.; Cheong, K.; Shahid, Z.; Acharya, U. Multilevel deep feature generation framework for automated detection of retinal abnormalities using oct images. Entropy 2021, 23, 1651. [Google Scholar] [CrossRef] [PubMed]
- Lv, D.; Wang, H.; Che, C. Fault diagnosis of rolling bearing based on multimodal data fusion and deep belief network. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2021, 235, 6577–6585. [Google Scholar] [CrossRef]
- Kumaresan, S.; Aultrin, K.; Kumar, S.; Anand, M. Transfer learning with cnn for classification of weld defect. IEEE Access 2021, 9, 95097–95108. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; He, X.; Deng, L. Multimodal intelligence: Representation learning, information fusion, and applications. IEEE J. Sel. Top. Signal Process. 2020, 14, 478–493. [Google Scholar] [CrossRef]
- Li, J.; Yao, X.; Wang, X.; Yu, Q.; Zhang, Y. Multiscale local features learning based on bp neural network for rolling bearing intelligent fault diagnosis. Measurement 2020, 153, 107419. [Google Scholar] [CrossRef]
- Zhu, Q.; Xu, X.; Yuan, N.; Zhang, Z.; Guan, D.; Huang, S.; Zhang, D. Latent correlation embedded discriminative multi-modal data fusion. Signal Process. 2020, 171, 107466. [Google Scholar] [CrossRef]
- Singh, J.; Azamfar, M.; Li, F.; Lee, J. A systematic review of machine learning algorithms for prognostics and health management of rolling element bearings: Fundamentals, concepts and applications. Meas. Sci. Technol. 2020, 32, 012001. [Google Scholar] [CrossRef]
- Cai, H.; Qu, Z.; Li, Z.; Zhang, Y.; Hu, X.; Hu, B. Feature-level fusion approaches based on multimodal eeg data for depression recognition. Inf. Fusion 2020, 59, 127–138. [Google Scholar] [CrossRef]
- Schillaci, G.; Villalpando, A.; Hafner, V.; Hanappe, P.; Colliaux, D.; Wintz, T. Intrinsic motivation and episodic memories for robot exploration of high-dimensional sensory spaces. Adapt. Behav. 2020, 29, 549–566. [Google Scholar] [CrossRef]
- Guo, R.; Wei, J.; Sun, L.; Yu, B.; Chang, G.; Liu, D.; Zhang, S.; Yao, Z.; Xu, M.; Bu, L. A Survey on Image-text Multimodal Models. arXiv 2023, arXiv:2309.15857. [Google Scholar]
- Palani, B.; Elango, S.; Viswanathan K, V. CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT. Multimed. Tools Appl. 2022, 81, 5587–5620. [Google Scholar] [CrossRef] [PubMed]
- Hangloo, S.; Arora, B. Combating multimodal fake news on social media: Methods, datasets, and future perspective. Multimed. Syst. 2022, 28, 2391–2422. [Google Scholar] [CrossRef] [PubMed]
- Gao, L.; Gao, Y.; Yuan, J.; Li, X. Rumor detection model based on multimodal machine learning. In Proceedings of the Second International Conference on Algorithms, Microchips, and Network Applications (AMNA 2023), Zhengzhou, China, 13–15 January 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12635, pp. 359–366. [Google Scholar]
- Yue, T.; Mao, R.; Wang, H.; Hu, Z.; Cambria, E. KnowleNet: Knowledge fusion network for multimodal sarcasm detection. Inf. Fusion 2023, 100, 101921. [Google Scholar] [CrossRef]
- Lucas, L.; Tomás, D.; Garcia-Rodriguez, J. Detecting and locating trending places using multimodal social network data. Multimed. Tools Appl. 2023, 82, 38097–38116. [Google Scholar] [CrossRef]
- Chandra, M.; Pailla, D.; Bhatia, H.; Sanchawala, A.; Gupta, M.; Shrivastava, M.; Kumaraguru, P. “Subverting the Jewtocracy”: Online antisemitism detection using multimodal deep learning. In Proceedings of the 13th ACM Web Science Conference 2021, Virtual Event, 21–25 June 2021; pp. 148–157. [Google Scholar]
- Xiao, S.; Chen, G.; Zhang, C.; Li, X. Complementary or substitutive? A novel deep learning method to leverage text-image interactions for multimodal review helpfulness prediction. Expert Syst. Appl. 2022, 208, 118138. [Google Scholar] [CrossRef]
- Li, M. Research on extraction of useful tourism online reviews based on multimodal feature fusion. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–16. [Google Scholar] [CrossRef]
- Bhat, A.; Chauhan, A. A Deep Learning based approach for MultiModal Sarcasm Detection. In Proceedings of the 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 16–17 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2523–2528. [Google Scholar]
- Yadav, A.; Vishwakarma, D.K. A deep multi-level attentive network for multimodal sentiment analysis. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–19. [Google Scholar] [CrossRef]
- Chen, X.; Lao, S.; Duan, T. Multimodal fusion of visual dialog: A survey. In Proceedings of the 2020 2nd International Conference on Robotics, Intelligent Control and Artificial Intelligence, Shanghai, China, 17–19 October 2020; pp. 302–308. [Google Scholar]
- Alsan, H.F.; Yıldız, E.; Safdil, E.B.; Arslan, F.; Arsan, T. Multimodal retrieval with contrastive pretraining. In Proceedings of the 2021 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Kocaeli, Turkey, 25–27 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Ange, T.; Roger, N.; Aude, D.; Claude, F. Semi-supervised multimodal deep learning model for polarity detection in arguments. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Asgari-Chenaghlu, M.; Feizi-Derakhshi, M.R.; Farzinvash, L.; Balafar, M.; Motamed, C. CWI: A multimodal deep learning approach for named entity recognition from social media using character, word and image features. Neural Comput. Appl. 2022, 34, 1905–1922. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, K.; Wang, R.; Utiyama, M.; Sumita, E.; Li, Z.; Zhao, H. Universal Multimodal Representation for Language Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9169–9185. [Google Scholar] [CrossRef]
- Guo, Q.; Yao, K.; Chu, W. Switch-BERT: Learning to Model Multimodal Interactions by Switching Attention and Input. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 330–346. [Google Scholar]
- Hu, P.; Zhang, Z.; Zhang, J.; Du, J.; Wu, J. Multimodal Tree Decoder for Table of Contents Extraction in Document Images. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1756–1762. [Google Scholar]
- Ahmed, M.R.; Bhadani, N.; Chakraborty, I. Hateful Meme Prediction Model Using Multimodal Deep Learning. In Proceedings of the 2021 International Conference on Computing, Communication and Green Engineering (CCGE), Pune, India, 23–25 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Agarwal, S. A Multimodal Machine Learning Approach to Diagnosis, Prognosis, and Treatment Prediction for Neurodegenerative Diseases and Cancer. In Proceedings of the 2022 IEEE 13th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 26–29 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 0475–0479. [Google Scholar]
- Huang, P.C.; Shakya, E.; Song, M.; Subramaniam, M. BioMDSE: A Multimodal Deep Learning-Based Search Engine Framework for Biofilm Documents Classifications. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3608–3612. [Google Scholar]
- Ban, M.; Zong, L.; Zhou, J.; Xiao, Z. Multimodal Aspect-Level Sentiment Analysis based on Deep Neural Networks. In Proceedings of the 2022 8th International Symposium on System Security, Safety, and Reliability (ISSSR), Chongqing, China, 27–28 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 184–188. [Google Scholar]
- Liang, T.; Lin, G.; Wan, M.; Li, T.; Ma, G.; Lv, F. Expanding large pre-trained unimodal models with multimodal information injection for image-text multimodal classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15492–15501. [Google Scholar]
- Sahoo, C.C.; Tomar, D.S.; Bharti, J. Transformer based multimodal similarity search method for E-Commerce platforms. In Proceedings of the 2023 IEEE Guwahati Subsection Conference (GCON), Guwahati, India, 23–25 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Yu, Z.; Lu, M.; Li, R. Multimodal Co-Attention Mechanism for One-stage Visual Grounding. In Proceedings of the 2022 IEEE 8th International Conference on Cloud Computing and Intelligent Systems (CCIS), Chengdu, China, 26–28 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 288–292. [Google Scholar]
- Xu, J.; Zhao, H.; Liu, W.; Ding, X. Research on False Information Detection Based on Multimodal Event Memory Network. In Proceedings of the 2023 3rd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 6–8 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 566–570. [Google Scholar]
- Dou, Z.Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Yuan, L.; Peng, N.; et al. An empirical study of training end-to-end vision-and-language transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18166–18176. [Google Scholar]
- Jácome-Galarza, L.R. Multimodal Deep Learning for Crop Yield Prediction. In Proceedings of the Doctoral Symposium on Information and Communication Technologies, Manta, Ecuador, 12–14 October 2022; Springer: Cham, Switzerland, 2022; pp. 106–117. [Google Scholar]
- Kraidia, I.; Ghenai, A.; Zeghib, N. HST-Detector: A Multimodal Deep Learning System for Twitter Spam Detection. In Proceedings of the International Conference on Computing, Intelligence and Data Analytics, Kocaeli, Turkey, 16–17 September 2022; Springer: Cham, Switzerland, 2022; pp. 91–103. [Google Scholar]
- Kaliyar, R.K.; Mohnot, A.; Raghhul, R.; Prathyushaa, V.; Goswami, A.; Singh, N.; Dash, P. MultiDeepFake: Improving Fake News Detection with a Deep Convolutional Neural Network Using a Multimodal Dataset. In Proceedings of the Advanced Computing: 10th International Conference, IACC 2020, Panaji, Goa, India, 5–6 December 2020; Springer: Singapore, 2021; pp. 267–279. [Google Scholar]
- Malhotra, A.; Jindal, R. Multimodal deep learning architecture for identifying victims of online death games. In Data Analytics and Management, Proceedings of ICDAM, Jaipur, India, 26 June 2021; Springer: Singapore, 2021; pp. 827–841. [Google Scholar]
- Peña, A.; Serna, I.; Morales, A.; Fierrez, J.; Ortega, A.; Herrarte, A.; Alcantara, M.; Ortega-Garcia, J. Human-centric multimodal machine learning: Recent advances and testbed on AI-based recruitment. SN Comput. Sci. 2023, 4, 434. [Google Scholar] [CrossRef]
- Ghosal, T.; Raj, A.; Ekbal, A.; Saha, S.; Bhattacharyya, P. A deep multimodal investigation to determine the appropriateness of scholarly submissions. In Proceedings of the 2019 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Champaign, IL, USA, 2–6 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 227–236. [Google Scholar]
- Miao, H.; Zhang, Y.; Wang, D.; Feng, S. Multimodal Emotion Recognition with Factorized Bilinear Pooling and Adversarial Learning. In Proceedings of the 5th International Conference on Computer Science and Application Engineering, Sanya, China, 19–21 October 2021; pp. 1–6. [Google Scholar]
- Hossain, E.; Hoque, M.M.; Hoque, E.; Islam, M.S. A Deep Attentive Multimodal Learning Approach for Disaster Identification From Social Media Posts. IEEE Access 2022, 10, 46538–46551. [Google Scholar] [CrossRef]
- Paul, S.; Saha, S.; Hasanuzzaman, M. Identification of cyberbullying: A deep learning based multimodal approach. Multimed. Tools Appl. 2022, 81, 26989–27008. [Google Scholar] [CrossRef]
- Ha, Y.; Park, K.; Kim, S.J.; Joo, J.; Cha, M. Automatically detecting image–text mismatch on Instagram with deep learning. J. Advert. 2020, 50, 52–62. [Google Scholar] [CrossRef]
- Rivas, R.; Paul, S.; Hristidis, V.; Papalexakis, E.E.; Roy-Chowdhury, A.K. Task-agnostic representation learning of multimodal twitter data for downstream applications. J. Big Data 2022, 9, 18. [Google Scholar] [CrossRef]
- Babu, G.T.V.M.; Kavila, S.D.; Bandaru, R. Multimodal Framework Using CNN Architectures and GRU for Generating Image Description. In Proceedings of the 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 28–29 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2116–2121. [Google Scholar]
- Paraskevopoulos, G.; Pistofidis, P.; Banoutsos, G.; Georgiou, E.; Katsouros, V. Multimodal Classification of Safety-Report Observations. Appl. Sci. 2022, 12, 5781. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, F.; Wang, H.; Jha, K.; Gao, J. Multimodal emergent fake news detection via meta neural process networks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3708–3716. [Google Scholar]
- Xu, N.; Mao, W. A residual merged neutral network for multimodal sentiment analysis. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6–10. [Google Scholar]
- Papadopoulos, S.I.; Koutlis, C.; Papadopoulos, S.; Petrantonakis, P. Synthetic Misinformers: Generating and Combating Multimodal Misinformation. In Proceedings of the 2nd ACM International Workshop on Multimedia AI against Disinformation, Thessaloniki, Greece, 12–15 June 2023; pp. 36–44. [Google Scholar]
- Karimvand, A.N.; Chegeni, R.S.; Basiri, M.E.; Nemati, S. Sentiment analysis of persian instagram post: A multimodal deep learning approach. In Proceedings of the 2021 7th International Conference on Web Research (ICWR), Tehran, Iran, 19–20 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 137–141. [Google Scholar]
- Shirzad, A.; Zare, H.; Teimouri, M. Deep Learning approach for text, image, and GIF multimodal sentiment analysis. In Proceedings of the 2020 10th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 29–30 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 419–424. [Google Scholar]
- Yu, Y.; Tang, S.; Aizawa, K.; Aizawa, A. Category-based deep CCA for fine-grained venue discovery from multimodal data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1250–1258. [Google Scholar] [CrossRef]
- Barveen, A.; Geetha, S.; Faizal, M.M. Meme Expressive Classification in Multimodal State with Feature Extraction in Deep Learning. In Proceedings of the 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichirappalli, India, 5–7 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–10. [Google Scholar]
- Chen, D.; Zhang, R. Building Multimodal Knowledge Bases with Multimodal Computational Sequences and Generative Adversarial Networks. IEEE Trans. Multimed. 2023, 26, 2027–2040. [Google Scholar] [CrossRef]
- Kim, E.; Onweller, C.; McCoy, K.F. Information graphic summarization using a collection of multimodal deep neural networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 10188–10195. [Google Scholar]
- Thuseethan, S.; Janarthan, S.; Rajasegarar, S.; Kumari, P.; Yearwood, J. Multimodal deep learning framework for sentiment analysis from text-image web Data. In Proceedings of the 2020 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Melbourne, Australia, 14–17 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 267–274. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Huang, Z.; Zeng, Z.; Liu, B.; Fu, D.; Fu, J. Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. arXiv 2020, arXiv:2004.00849. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Fatichah, C.; Wiyadi, P.D.S.; Navastara, D.A.; Suciati, N.; Munif, A. Incident detection based on multimodal data from social media using deep learning methods. In Proceedings of the 2020 International conference on ICT for smart society (ICISS), Bandung, Indonesia, 19–20 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Guo, N.; Fu, Z.; Zhao, Q. Multimodal News Recommendation Based on Deep Reinforcement Learning. In Proceedings of the 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 15–17 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 279–284. [Google Scholar]
- Guo, L. Art teaching interaction based on multimodal information fusion under the background of deep learning. Soft Comput. 2023, 1–9. [Google Scholar] [CrossRef]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5579–5588. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lu, J.; Goswami, V.; Rohrbach, M.; Parikh, D.; Lee, S. 12-in-1: Multi-task vision and language representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10437–10446. [Google Scholar]
- Rahate, A.; Walambe, R.; Ramanna, S.; Kotecha, K. Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions. Inf. Fusion 2022, 81, 203–239. [Google Scholar] [CrossRef]
- Liu, J. Multimodal Machine Translation. IEEE Access, 2021; early access. [Google Scholar] [CrossRef]
- Li, L.; Gan, Z.; Liu, J. A closer look at the robustness of vision-and-language pre-trained models. arXiv 2020, arXiv:2012.08673. [Google Scholar]
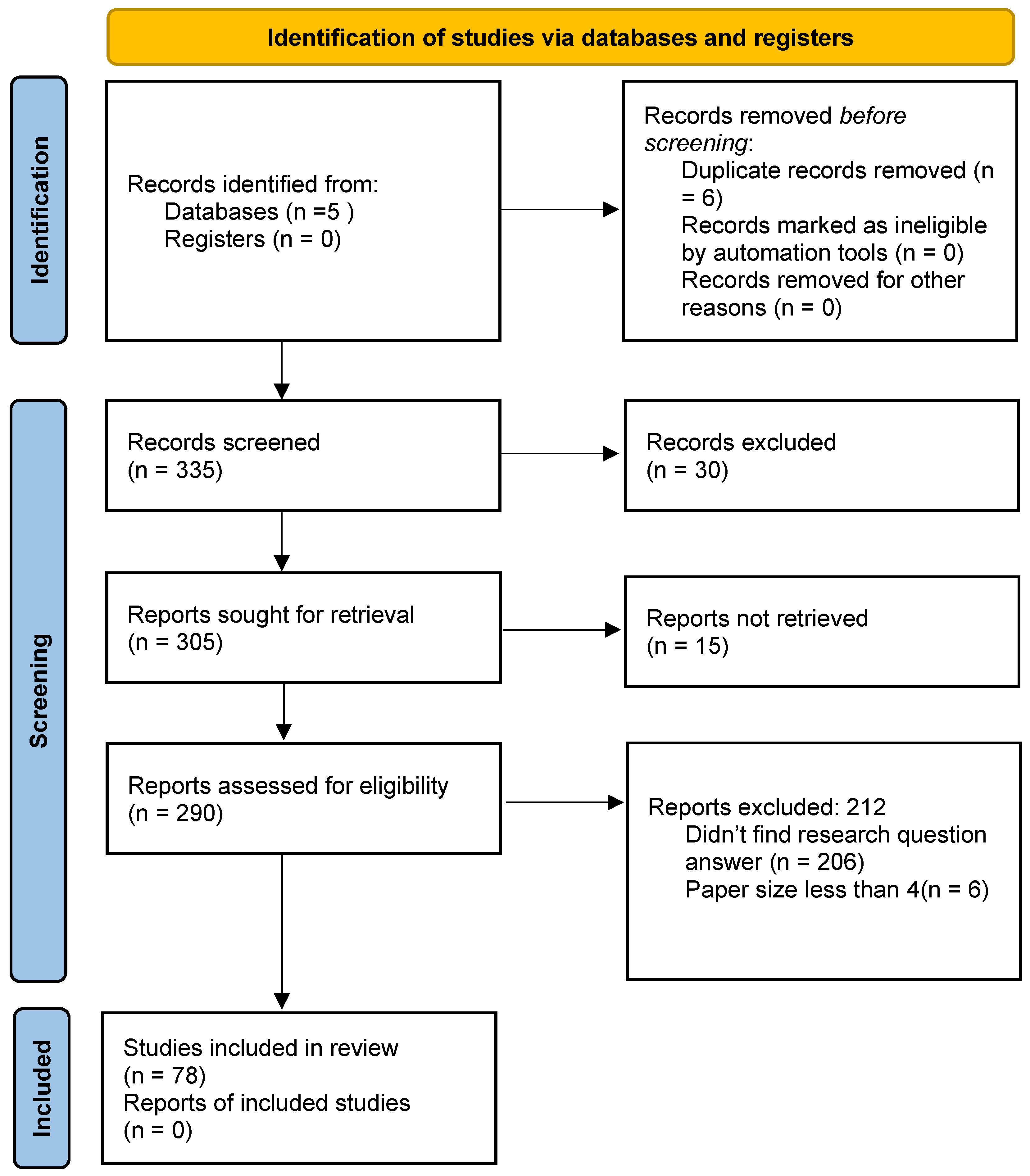
| Database Name | Before Exclusion | After Exclusion |
|---|---|---|
| Scopus | 57 | 14 |
| IEEE Explorer | 114 | 29 |
| Springer Link | 32 | 12 |
| ACM Digital Library | 108 | 14 |
| Semantic Scholar | 30 | 9 |
| Others | - | 10 |
| Research Question | Preferred Section |
|---|---|
| RQ1, RQ2 | Methodology/Model Description/Dataset/Results |
| RQ3 | Limitations/Future Work/Research Gap |
| RQ4 | Limitations/Dataset/Data Pre-processing |
| Architecture Name | Article | Total Articles |
|---|---|---|
| VGG-16 | [27,38,40,52,58,64,65,68,69,74,75] | 12 |
| VGG-19 | [60,67] | 2 |
| ResNet-50 | [23,51,54] | 3 |
| ResNet-101 | [76] | 1 |
| ResNet-152 | [26,41,57] | 3 |
| ResNet-18 | [25,59] | 2 |
| AlexNet | [22,56,74] | 3 |
| SqueezeNet | [28,74] | 2 |
| DenseNet-161 | [26] | 1 |
| MobileNet | [43] | 1 |
| InceptionV3 | [34] | 1 |
| Faster RCNN | [31,36] | 2 |
| Recurrent CNN | [55] | 1 |
| Image-CNN | [61] | 1 |
| Visual Transformer | [59] | 1 |
| Xception | [58] | 1 |
| Not Applicable | 51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Binte Rashid, M.; Rahaman, M.S.; Rivas, P. Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures. Mach. Learn. Knowl. Extr. 2024, 6, 1545-1563. https://doi.org/10.3390/make6030074
Binte Rashid M, Rahaman MS, Rivas P. Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures. Machine Learning and Knowledge Extraction. 2024; 6(3):1545-1563. https://doi.org/10.3390/make6030074
Chicago/Turabian StyleBinte Rashid, Maisha, Md Shahidur Rahaman, and Pablo Rivas. 2024. "Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures" Machine Learning and Knowledge Extraction 6, no. 3: 1545-1563. https://doi.org/10.3390/make6030074
APA StyleBinte Rashid, M., Rahaman, M. S., & Rivas, P. (2024). Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures. Machine Learning and Knowledge Extraction, 6(3), 1545-1563. https://doi.org/10.3390/make6030074