1. Introduction
Automatic speech recognition (ASR) technology marks a transformative advancement in human–computer interaction, reshaping our digital engagements and enhancing accessibility. It has widespread applications, from streamlining workflows with speech-to-text to supporting individuals with diverse access needs, such as those with difficulty typing. The integration of ASR into daily life exemplifies technological innovation and heralds a new era of intuitive and inclusive computing. Thus, improving ASR accuracy while ensuring the process remains fast and lightweight is essential.
ASR error correction is a crucial component of modern speech recognition systems, with various models developed to effectively reduce errors. From integrated systems like DeepSpeech2 [
1], which merges error correction with ASR training, to ranking-based techniques like N-best reranking [
2,
3,
4,
5]. In addition, large language models (LLMs), such as GPT-3.5 [
6], represent a significant leap forward, demonstrating their potential in contextual error identification and correction.
Much of the work on ASR error correction is tightly integrated within specific ASR systems, posing challenges for integration with different ASR frameworks. The goal of this research is to develop a lightweight, ad hoc error correction system that is compatible with various ASR platforms. In particular, the focus is to harness the capabilities of modern, pre-trained large language models to effectively reduce errors in ASR outputs.
In this project, the LibriSpeech dataset is used as a testbed [
7]. Instructional learning is applied to the Phoenix LLM for error correction [
8]. The overall system developed in this paper is named Lexical Error Guard (LEG). For the baseline ASR models, the small, medium, and large variants of the Whisper ASR models [
9] are utilized, a leading ASR system. The findings from the LibriSpeech dataset indicate that LEG significantly improves the Whisper models’ performance with both greedy and beam search decoding baselines. This performance is achieved using zero-shot error correction, outperforming benchmark models in the task of ASR such as the work by Ma et al. [
10], which uses one-shot error correction.
2. Related Work
In this section, a literature review is presented to compare related work in three interconnected domains: Automatic speech recognition (ASR) techniques, error correction methods for ASR systems, and large language models (LLMs) with instructional learning.
2.1. Automatic Speech Recognition (ASR)
Recent advances in automatic speech recognition (ASR) systems have seen significant improvements through the integration of deep learning models and large-scale datasets. Google’s WaveNet [
11] leverages a deep generative model for raw audio waveforms, resulting in high-quality speech synthesis and recognition. Facebook’s wav2vec 2.0 [
12] introduces a self-supervised learning approach, significantly improving ASR performance, especially in low-resource languages. DeepSpeech [
13] employs end-to-end deep learning techniques, which streamline the ASR pipeline by learning directly from audio data to text transcription, bypassing traditional hand-engineered features. DeepSpeech2 [
1] extends the original DeepSpeech by incorporating convolutional and recurrent layers, achieving notable accuracy improvements across various languages and noisy environments, effectively reducing error rates in both English and Mandarin.
OpenAI’s Whisper is one of the leading models in the realm of ASR tasks [
9]. Trained on 680,000 h of multilingual labeled speech data from various datasets, it exemplifies effectiveness in transcribing speech audio samples. By looking at the phonetic components of the input speech, it compares it to the information it knows to determine the next sequence of words. Its framework consists of an encoder–decoder transformer using two convolutional layers for the encoder and learned position embeddings for the decoder. Whisper is a versatile model that performs well on languages it has not been trained on, allowing it to generalize to any domain in zero shots. Three different checkpoints of the Whisper model are used in this research, with each configured with a different amount of parameters: Small, Medium, and Large-v2 [
9]. Each of these model sizes is a configuration with a different amount of parameters: 244 M, 769 M, and 1550 M, respectively. The word error rates (WERs) of each Whisper model on LibriSpeech are 2.89%, 2.91%, 2.97% for “Test Clean” and 6.73%, 5.77%, and 4.93% for “Test Other” for the models Small, Medium, and Large, respectively.
2.2. ASR Error Correction
ASR error correction employs diverse strategies. Techniques like PATCorrect integrate error correction within ASR systems for enhanced performance [
14]. PATCorrect achieves low latency and higher error reduction by using both text and phoneme representations of transcriptions. Alternative approaches, such as training with lattice-free maximum mutual information, use different loss functions to reduce overfitting and generate more accurate transcripts [
15]. The Conformer model, meanwhile, enhances accuracy by accounting for both local and global dependencies in acoustic signals [
16].
N-best reranking is a method that utilizes the top N hypotheses from an ASR model, ranking them based on an accuracy score derived from the speech audio clip. Although the top-ranking hypothesis is typically returned, the accuracy of this ranking can often be enhanced with alternate ranking functions. HypR introduces three scoring methods, sentence-level, token-level, and comparison-based, leveraging models like BERT and its derivatives for reranking [
2,
3,
4,
5]. However, a limitation of this approach is its reliance on the initial set of hypotheses, preventing the generation of new, corrected results. In this study, N-best reranking is synergized with unconstrained decoding through large language models (LLMs) to enhance ASR accuracy.
2.3. LLMs in ASR Error Correction
Exploring the use of large language models (LLMs) for correcting ASR transcript errors is a new and promising direction.
LLMs have been employed for generative error correction (GER) in ASR systems, where they generate corrected transcriptions from erroneous ASR outputs. This approach has shown significant improvements in word error rates (WERs), particularly in noisy conditions. For instance, the RobustGER approach demonstrated an up to 53.9% improvement in WER on the RobustHP test sets, even with limited training data [
17].
A multi-stage approach has been proposed, which utilizes uncertainty estimation of ASR outputs and the reasoning capabilities of LLMs. This method involves two stages: the first stage estimates ASR uncertainty using N-best list hypotheses to identify unreliable transcriptions, and the second stage performs LLM-based corrections on these identified transcriptions. This approach has shown a 10% to 20% relative improvement in WER across multiple test domains [
18].
LLMs’ in-context learning capabilities have been explored to enhance ASR performance. Different prompting schemes, including zero-shot and few-shot learning, as well as a novel “task activation” prompting method, have been evaluated. These techniques allow LLMs to perform rescoring and error correction without fine-tuning, achieving competitive results with domain-tuned LMs [
19].
Several benchmarks and datasets have been introduced to evaluate the performance of LLMs in ASR error correction. The ‘Robust HyPoradise’ dataset, featuring 113K hypotheses–transcription pairs from various noisy ASR scenarios [
17], and the ’HyPoradise’ dataset, encompassing over 316,000 pairs of N-best hypotheses and accurate transcriptions, are notable examples [
20].
Wenyi et al. conducted a comparative analysis of model adaptation, evaluating the efficacy of fully connected layers, multihead cross-attention, and Q-Former architectures linked with Vicuna LLMs in reducing word error rates (WERs) [
21].
LLMs have also been applied to domain-specific ASR error correction tasks. For instance, in medical transcription, LLMs have been used to improve general WERs, medical concept WERs (MC-WERs), and speaker diarization accuracy. Chain-of-thought (CoT) prompting has been particularly effective in achieving state-of-the-art performance in this domain [
22].
Most relevant to this research, Higuchi et al. integrate the instruction-tuned Llama 2 model as a decoder, utilizing its zero-shot capabilities for grammatical corrections [
23]. Ma et al.’s study, combines the ASR N-best list with ChatGPT, exploring both constrained and unconstrained correction methods [
10]. Drawing inspiration from these works, our methodology also inputs the ASR N-best list into an LLM. However, this research methodology diverges by employing instruction training with unconstrained decoding to further refine performance.
3. Methodology
The LibriSpeech dataset is used as the testbed [
7]. LibriSpeech is a speech dataset of approximately 1000 h of read audiobooks derived from the LibriVox project [
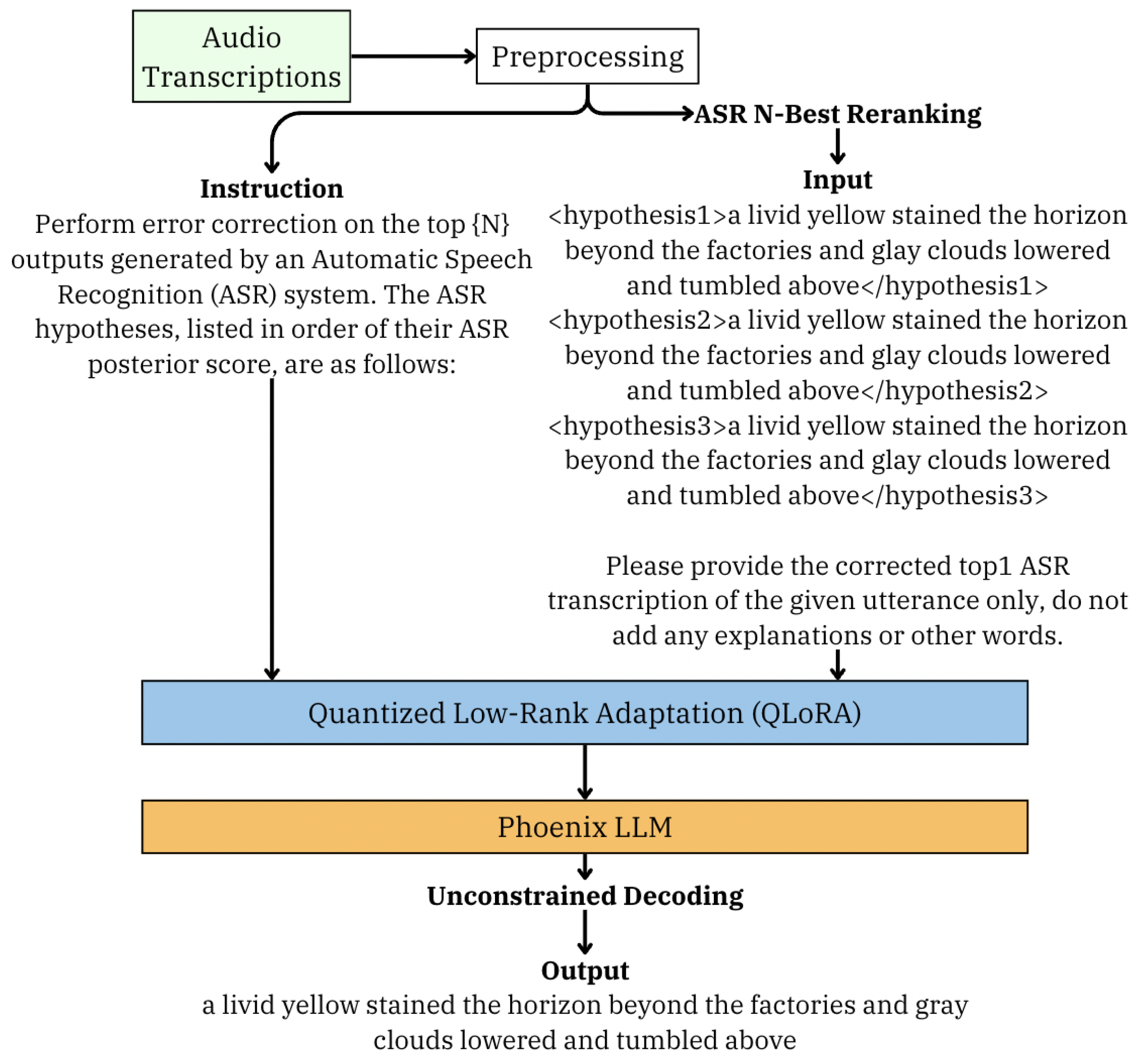
7]. It contains over 803M tokens and 977K unique words and is split into a quiet “clean” and a more difficult, noisier “other” split of the dataset. The training sets contained 40K audio snippets total. The proposed Lexical Error Guard (LEG) model is detailed in
Figure 1. LEG starts by processing transcribed audio and generating training prompts from a template. These encoded prompts are subsequently input into the fine-tuned Phoenix LLM [
8], which performs the final corrections via unconstrained decoding. Quantized low-rank adaptation (QLoRA) [
24] was used for optimizing the training process.
3.1. Training Data Preparation
There are 40k data points used for training. The data were sampled given in the format seen in
Figure 2, which was adopted from Ma et al. [
10]. The data points were chosen in order, retrieving the first 40k instances by using all of the 28,539 data points from “train-clean-100” and the remaining from “train-clean-360”. All data points from the test sets were used, with “test-clean” containing 2620 data points and “test-other” having 2939 that were used for model evaluation.
In our LEG framework, the variable N is set to 3, indicating the selection of the top three beam search options from the ASR model for consideration. Our chosen base ASR model is Whisper. By feeding the top N outputs from the Whisper ASR model into LEG, it creates a list of possible corrections that is referred to as the ASR N-best list, a strategy that frequently enhances performance by acknowledging that the correct transcript might not always be the most likely one produced by the ASR system [
10,
25].
3.2. Unconstrained Decoding
LEG’s approach transcends merely selecting from among these top N transcripts. It employs unconstrained decoding, effectively exploiting the generative power of LLMs to produce the correct transcript. This process is guided by appending the instruction “Please provide the corrected top1 ASR transcription of the given utterance only, do not add any explanations or other words”, to the prompt fed into LEG. While the correction generated by LEG is often one of the top N hypotheses, the model retains the flexibility to generate the most accurate transcript as it sees fit, not limited to the pre-selected options. The general prompt template is depicted in
Figure 2.
3.3. Model Parameters
Two epochs with batch sizes of 80 were run for each of the Whisper models: Small, Medium and Large-v2 for fine-tuning. Because of limitations in computing, every epoch was saved at a checkpoint and ran non-consecutively, continuing from the most recent checkpoint, until all 2 epochs for each model were completed. The cutoff length for the transcriptions was set to 3225. Lastly, this was the LoRA configuration set within the model parameters [lora_r: int = 8, lora_alpha: int = 16, lora_dropout: float = 0.05, lora_target_modules: List[str] = [“query_key_value”, “dense_h_to_4h”, “dense_4h_to_h”, “dense”]]. This configuration tunes the query, key, and value matrices used in attention and the dense neural layers while the other layers are not affected. This focuses on finding the optimal layers for performance.
3.4. Training with Quantized Low-Rank Adaptation
The base LLM model for error correction is Phoenix. It is an open-source alternative LLM to ChatGPT created by Freedom Intelligence with the mission of making machine learning freely available [
8]. The model has 7 billion parameters and operates at roughly 87% of the performance level of ChatGPT3.5. Despite its smaller size, Phoenix is optimized to deliver high contextual understanding and generative capabilities, making it a suitable choice for tasks such as ASR error correction. Its relatively lightweight nature allows it to be fine-tuned more efficiently using techniques such as low-rank adaptation (LoRA).
Training was performed with eight NVIDIA V100 GPUs and an Intel Xeon Gold processor. To make the training process more memory efficient, the model was loaded in 8 bits by taking advantage of the library BitsandBytes [
26]. Trusov et al. found that using 8-bit quantization leads to 95.4% of the original network accuracy with a 39% speedup [
24]. In this research, it was decided to trade a bit of performance for a lower training cost, allowing us to train the model more quickly and with more data. Then, it was trained using low-rank adaptation (LoRA) as available from Huggingface’s Parameter-Efficient Fine-Tuning (PEFT) library [
27]. All of the linear modules were targeted for training using LoRA with the following configuration: r = 8, target modules = [query_key_value, dense_h_to_4h, dense_4h_to_h, dense], dropout = 0.05, bias = none, and task type = CASUAL_LM. The time to train on average was 3 h for each model using this configuration.
The parameter
r refers to the rank of the decomposition rank,
alpha refers to the scaling factor, and
bias specifies if the bias parameters should be trained or not [
28]. Reducing these hyperparameters leads to a reduction in the total number of trainable parameters. The final model tunes less than 32 million trainable parameters, less than 1% of the original size of Phoenix [
8].
3.5. Mathematical Framework for Instructional Fine-Tuning for ASR Error Correction
Instructional fine-tuning of LLMs involves refining the pre-trained model’s ability to follow task-specific instructions. In the context of ASR error correction, instructional fine-tuning allows the model to learn how to correct transcription errors based on instructions provided during training. The process can be mathematically described as an optimization problem aimed at minimizing a task-specific loss function.
3.5.1. Objective and Loss Function
Let be the LLM, parameterized by , that generates a corrected ASR transcript given an input utterance x and an instruction I. The instruction here might be: “Please provide the corrected ASR transcription of the given utterance only”. The objective is to fine-tune the model so that closely matches the true transcription y.
The loss function can be expressed as
where
is a suitable loss function (e.g., cross-entropy loss) that measures the distance between the model’s output and the correct transcription, and
N is the number of training examples.
3.5.2. Low-Rank Adaptation (LoRA) and Model Compression
Fine-tuning with LoRA allows efficient training by modifying only a subset of model parameters. In this method, the weight matrices
and
of the LLM’s attention layers are decomposed into low-rank matrices:
where
,
,
, and
have low ranks, reducing the number of trainable parameters. This significantly lowers the memory requirements for training, allowing fine-tuning to occur even with large models.
The number of parameters trained is proportional to the rank
r, making the total number of trainable parameters
where
and
are the dimensions of the input and output layers of the attention module.
In the case of Phoenix, a model with 7 billion parameters, LoRA enables fine-tuning with fewer than 32 million parameters—less than 1% of the total model size.
3.5.3. Unconstrained Decoding
Instructional fine-tuning also supports unconstrained decoding. Rather than limiting itself to pre-selected top N hypotheses generated by the ASR system, the model is allowed to generate the most accurate transcript directly, based on the instruction. This process can be mathematically described by decoding from the model’s probability distribution:
where
is the conditional probability of the correct transcription given the input utterance
x and instruction
I.
3.6. Evaluation Metrics
Word error rate (WER) and character error rate (CER) were the evaluation metrics used throughout this project [
29]. Word error rate (WER) and character error rate (CER) are metrics used to measure the accuracy of text transcriptions or corrections. WER compares the number of word-level errors (insertions, deletions, substitutions) needed to match the transcribed sequence with the reference sequence, divided by the total number of words in the reference. CER works similarly but at the character level, dividing the number of character-level errors by the total number of characters in the reference. Both metrics indicate accuracy, with lower values representing fewer errors and higher accuracy.
4. Results and Discussion
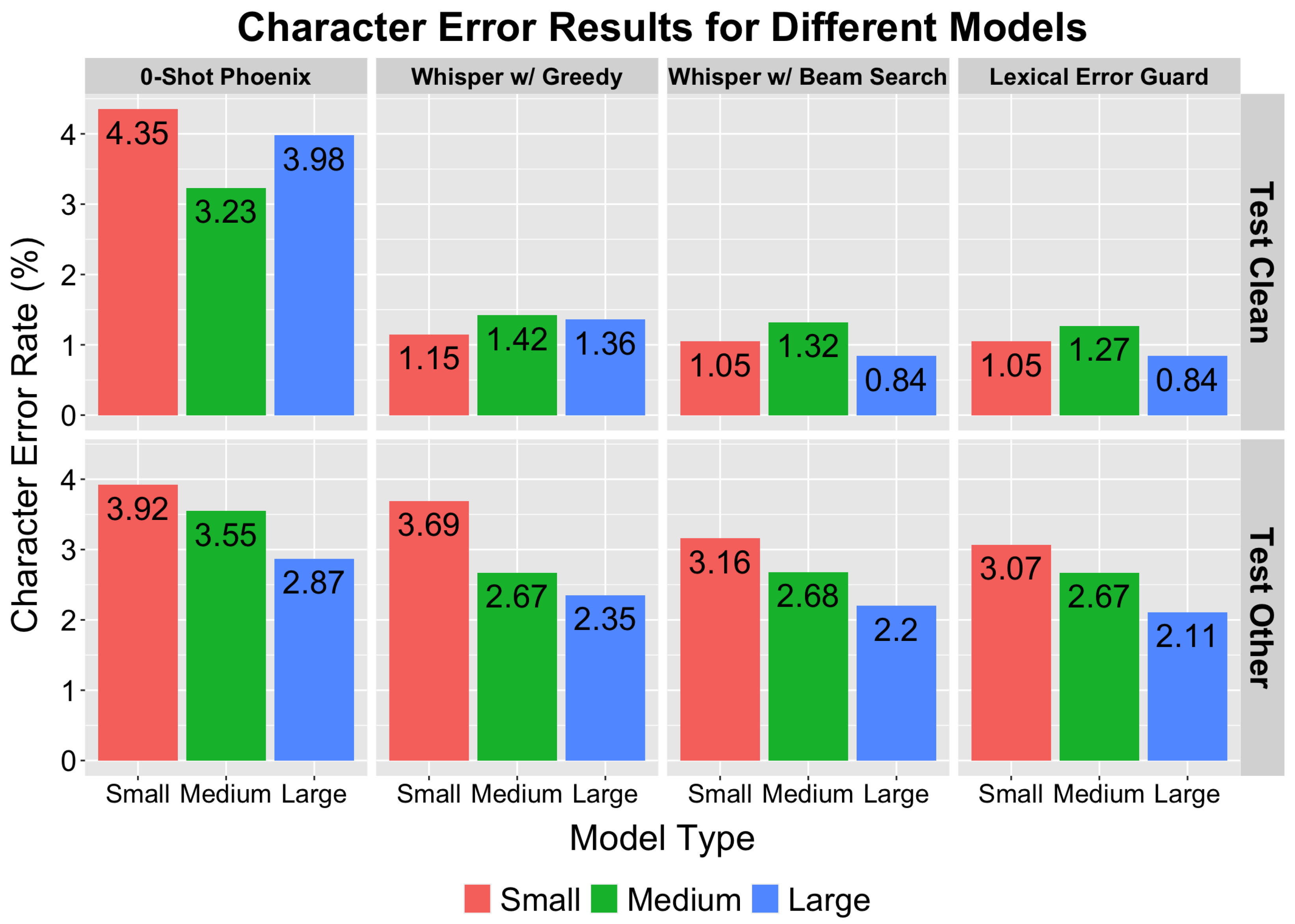
Figure 3 and
Figure 4 present a comparison of the performance outcomes of the Lexical Error Guard (LEG) model against multiple baselines. Our objective in developing LEG was to achieve a lower word error rate (WER) and character error rate (CER) compared to the following baseline models:
Zero-shot Phoenix with ASR N-best list;
Whisper with greedy decoder;
Whisper with beam search (N = 3).
Performance improvements with the Lexical Error Guard (LEG) model were consistent across all Whisper model variants (Small, Medium, and Large) and on both LibriSpeech test splits (“Other” and “Clean”). Our model consistently outperformed baselines, and in a few instances, its performance matched the base model, but importantly, it never degraded the results.
Significant improvements were seen with LEG over Whisper with greedy decoding; for example, LEG reduced the WER on LibriSpeech “Test Clean” for Whisper Large from 2.87% to 2.21%. Additionally, LEG showed significant, though smaller, improvements over Whisper with beam search (N = 3), underlining the effectiveness of our approach.
It is also observed that the LEG model significantly enhances transcript accuracy using the generative power and knowledge of large language models (LLMs). It achieves this by introducing corrections not originally present in the ASR N-best list. For instance, LEG can expand “etc.” to “etcetera”, demonstrating its ability to elaborate abbreviations. It also adeptly handles compound words, correctly splitting “tonight” into “to night” and “today” into “to day”, showcasing its precision in modifying transcripts beyond the suggestions from the Whisper models.
Moreover, LEG excels at correcting misspellings and making contextually appropriate corrections. An example includes changing “mister hell” to “mister hale”, a correction that significantly alters the meaning and appropriateness of the phrase based on contextual clues. Such adjustments indicate LEG’s deep understanding of context and its ability to apply this understanding to improve the accuracy and coherence of ASR-generated transcripts.
Using zero-shot Phoenix, however, increased the WER and CER compared to Whisper with greedy decoding, suggesting that bypassing an error correction model might be preferable in some cases, contrasting with outcomes from ChatGPT3.5 due to Phoenix’s lower performance [
10].
Table 1 reports the results with various sizes of Whisper models for ASR and compares LEG with two recent works that employed large language models (LLMs) for ASR error correction. The table specifies the model used in each row with various results from testing on the LibriSpeech test sets ’Other’ and ’Clean’. The results reported include the word error rate (WER), character error rate (CER), and WER of the corrections to word-level errors including insertions (Ins), deletions (Del) and substitution (Subs). The table includes the models used for testing including the Small, Medium and Large Whisper models along with two baseline models for comparison. Specifically, using the Whisper Large model, LEG outperformed [
23], which integrated a CTC model with Llama 2. Moreover, using Whisper Small as the base ASR model, our approach surpassed the performance of combining Whisper Small with ChatGPT [
10], which is a significantly larger and more advanced model than our base LLM Phoenix. This comparison highlights the effectiveness of LEG in reducing error rates in ASR applications. Interestingly, LEG had higher substitution errors when paired with Whisper Small compared to the ChatGPT3.5 integration, while it significantly reduced insertion and deletion errors. This outcome suggests that the differences between ChatGPT and Phoenix can impact error types, warranting further exploration in future work.
5. Challenges and Future Work
Fine-tuning large language models (LLMs) for automatic speech recognition (ASR) presents several challenges that stem from the fundamental differences between text and audio data. First, LLMs are typically pre-trained on vast text corpora, which do not inherently contain phonetic or acoustic information. This creates a mismatch when adapting LLMs for ASR tasks, as they struggle to capture the nuances of spoken language without explicit training on audio features. As a result, fine-tuning these models to bridge the gap between text-based training and audio-domain tasks can lead to suboptimal performance. Furthermore, ASR systems must handle phonetic variations, accents, and dialects, but LLMs, which are primarily trained on written language, often lack the inherent understanding required to process these differences accurately. This limitation is particularly problematic when trying to achieve high accuracy in diverse linguistic environments.
In addition to domain mismatches, real-time processing poses another significant challenge when fine-tuning LLMs for ASR tasks. LLMs are computationally heavy, and this often results in increased latency, especially for real-time applications. Even when fine-tuned, these models may introduce delays in transcription, making them less efficient than specialized, lightweight ASR models that are designed for speed and responsiveness.
Future work should focus on addressing these limitations through several approaches. One promising direction is improving domain adaptation by incorporating multi-modal training data that includes both text and corresponding audio features. This would allow the model to better handle the intricacies of spoken language, leading to more accurate transcriptions. Additionally, expanding the training dataset to include phonetic variations, regional accents, and audio from different periods can help the model generalize better across diverse linguistic contexts. Collecting diverse speech data from various accents, regions, and time periods would improve the model’s ability to adapt to different phonetic structures and dialects, resulting in more accurate ASR performance.
Using a large LLM, such as Llama 3, may achieve better ASR correction results due to its ability to capture complex linguistic patterns and nuances. These models, with their expanded parameter bases and enhanced fine-tuning capabilities, are better equipped to handle the diverse and intricate nature of spoken language. As a result, they have the potential to significantly improve transcription accuracy in ASR systems. However, larger models also come with increased computational demands, which can lead to higher latency and slower responses, particularly in real-time applications.
To address this, techniques like model distillation and quantization can be applied to reduce the size and computational complexity of these models while preserving most of their performance benefits. By distilling larger models into smaller, more efficient versions, it becomes possible to achieve both high accuracy and low latency, making them more suitable for real-time ASR tasks. This approach ensures that the strengths of large LLMs can be leveraged without sacrificing responsiveness, enabling more practical deployment in real-world scenarios.
Lastly, the adaptability of the model across various ASR systems and domains needs to be refined. Fine-tuning efforts should also focus on improving the model’s ability to recognize temporal and geographical variations in language, such as evolving speech patterns and regional spelling differences. This would allow the model to maintain contextual accuracy across different linguistic regions and time periods, further enhancing its ASR capabilities. By addressing these challenges through targeted improvements, fine-tuning LLMs for ASR tasks can become more efficient and effective across a broader range of real-world applications.
6. Conclusions
Our research underscores the significant impact of large language models (LLMs) on ASR error correction, achieving promising results even with the smaller Phoenix model and QLoRA training, which are known to potentially reduce performance. This demonstrates the LLMs’ deep contextual understanding and generative abilities as key to enhancing ASR system accuracy and reliability, marking a significant advancement in employing LLMs for complex error correction tasks.
Looking ahead, future work will focus on leveraging larger models like Llama 3 to further improve ASR correction. Additionally, efforts will involve reducing computational complexity through techniques like model distillation and quantization, optimizing these large models for real-time applications while maintaining high performance. Expanding the model’s adaptability to different accents, dialects, and temporal language variations will also be a priority to enhance contextual understanding across diverse ASR systems.






{kind=link}
{kind=link}
{kind=link}
{kind=link}