3.3.1. Features
In this section, we describe the nine features we used for state representation, which are summarized in
Table 3.
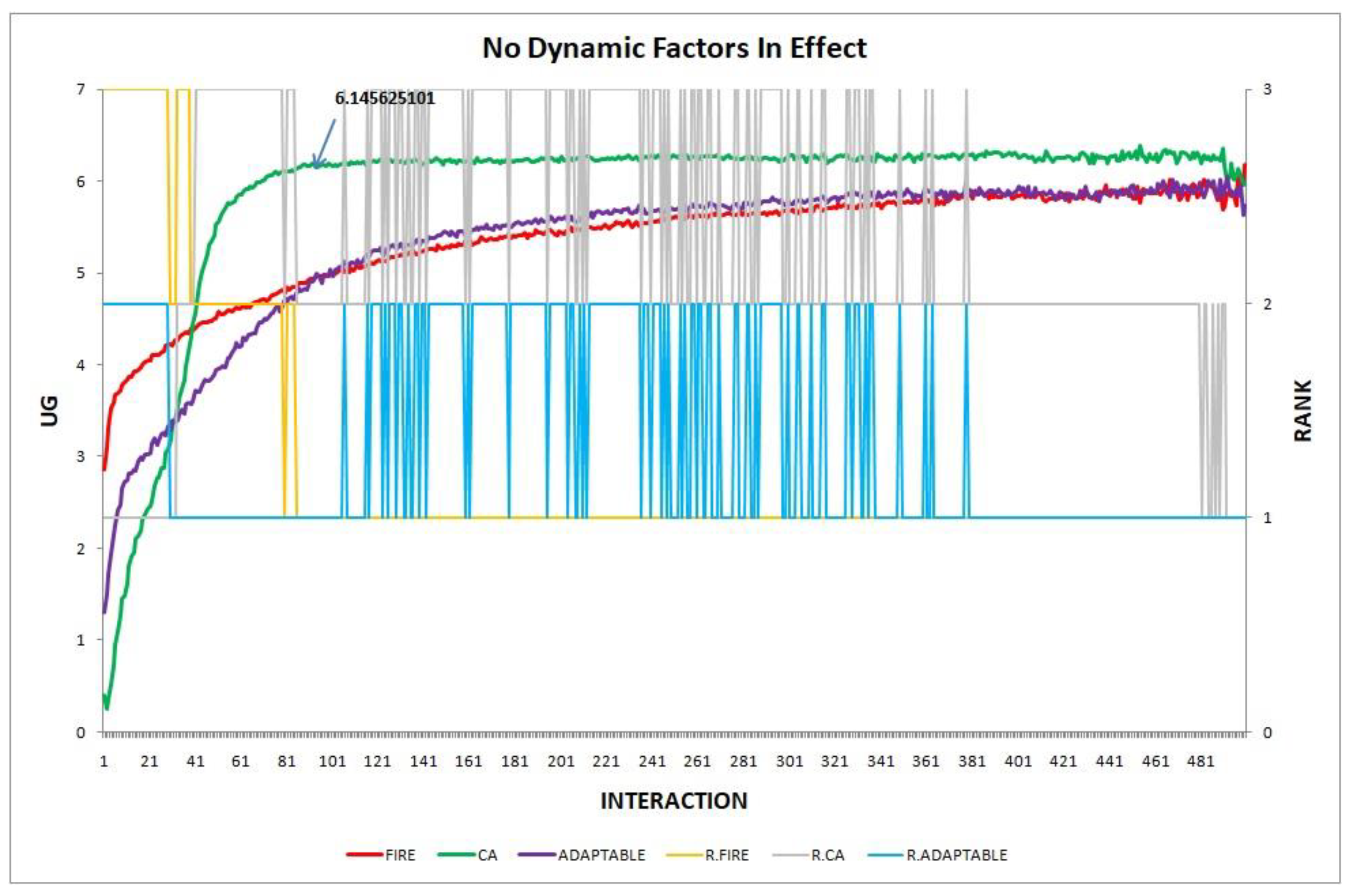
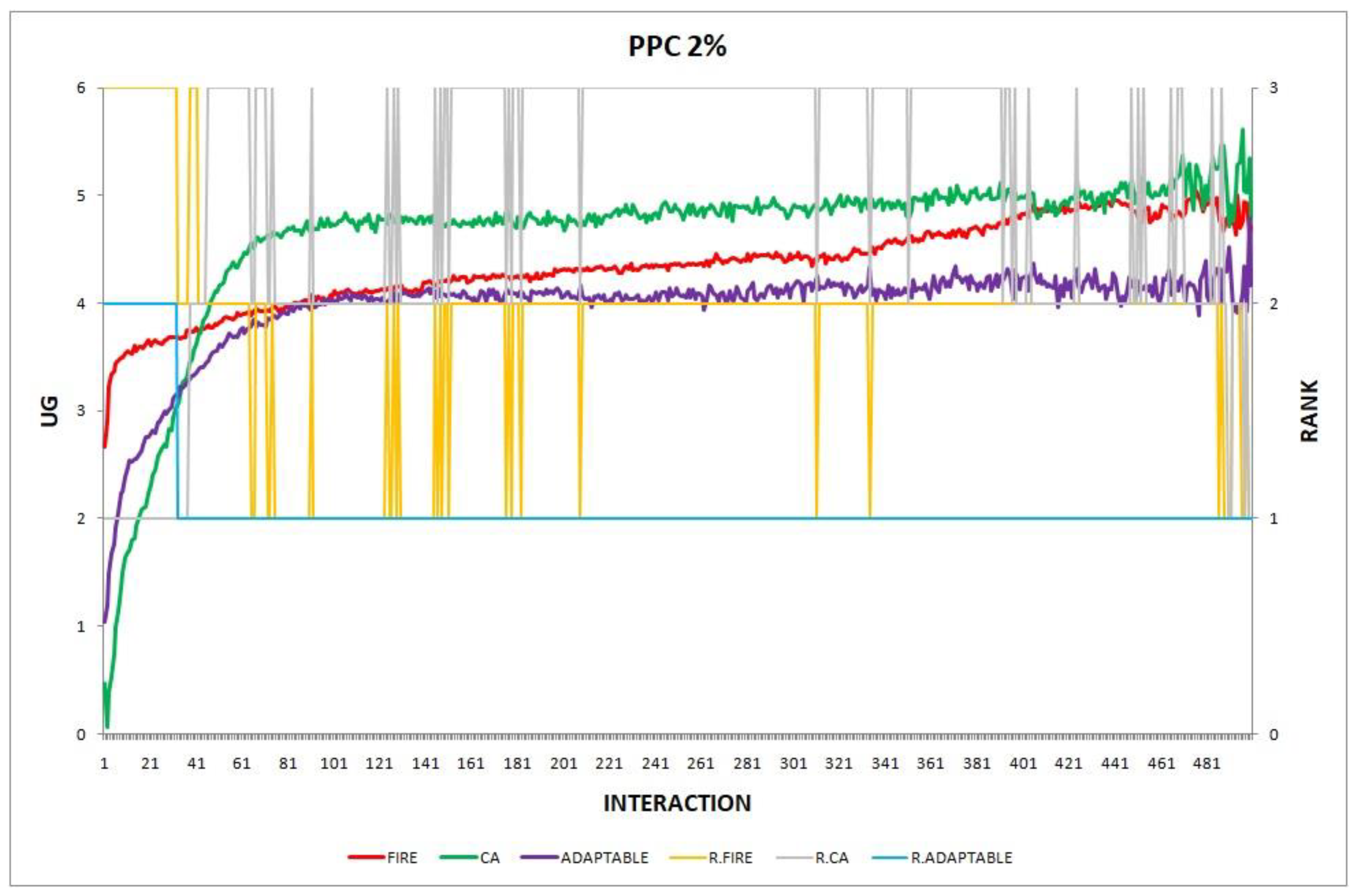
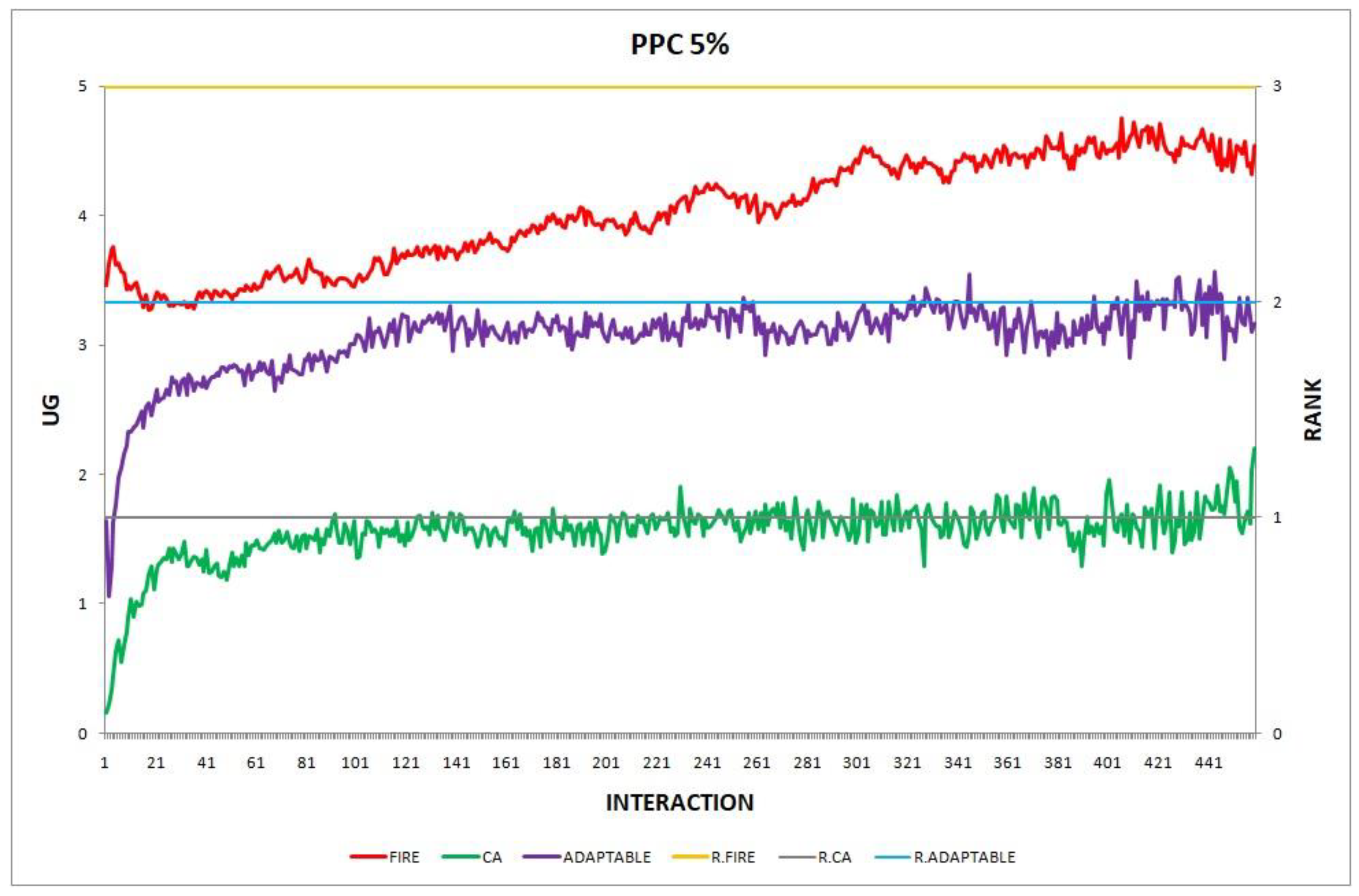
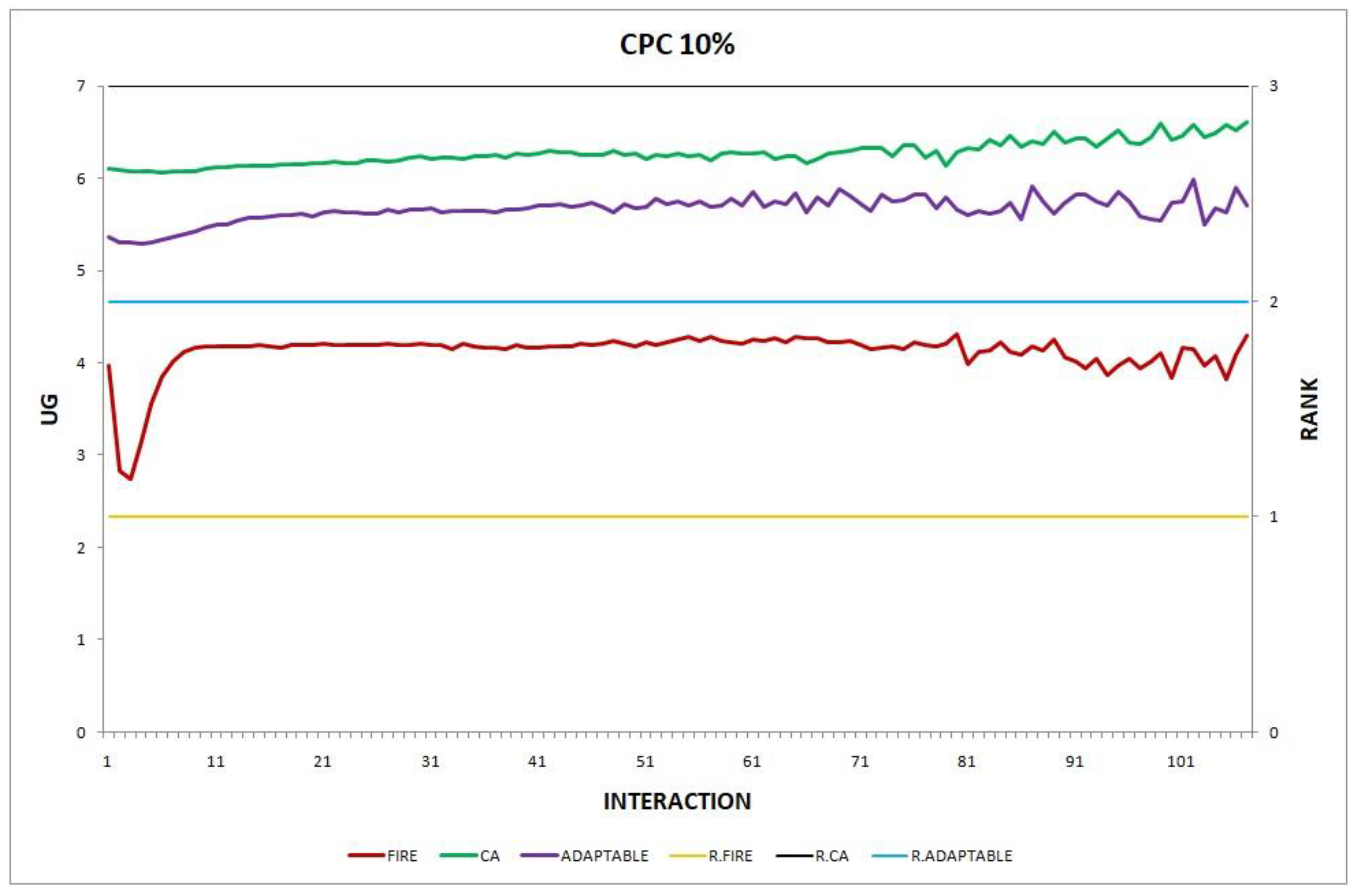
The trustor’s decision on which model is most appropriate at any given time is based on the accuracy of its assessment about the environment’s current state, which is determined by the presence of the following factors:
The provider population change.
The consumer population change.
The provider’s average level of performance change.
The provider’s change into a different performance profile.
The provider’s move to a new location on the spherical world.
The consumer’s move to a new location on the spherical world.
Since we assume a partially observable environment, meaning that the trustor has no knowledge of the aforementioned factors, the trustor can only utilize the following available data:
A local ratings database. After each interaction, the trustor rates the provided service and each rating is stored in its local ratings database.
The trustor’s acquaintances: the agents situated in the trustor’s radius of operation.
The trustor’s nearby provider agents: the providers situated in the trustor’s radius of operation.
The trustor is able to evaluate the trustworthiness of all nearby providers using the FIRE model. Providers whose trustworthiness cannot be determined (for any reason) are placed in the set NoTrustValue. The rest, whose trustworthiness can be determined, are placed in the set HasTrustValue.
The trustor’s location on the spherical world, i.e., its polar coordinates .
The acquaintances’ ratings or referrals, according to the process of witness reputation (WR): When consumer agent a evaluates agent ’s WR, it sends a request for ratings to acquaintances that are likely to have ratings for agent b. Upon receiving the query, each acquaintance will attempt to match it to its own ratings database and return any relative ratings. In case an acquaintance cannot find the requested ratings (because it has had no interactions with b), it will only return referrals identifying its acquaintances.
Nearby providers’ certified ratings, according to the process of certified reputation (CR): After each interaction, provider requests from its partner consumer to provide certified ratings for its performance. Then, selects the best ratings to be saved in its local ratings database. When expresses its interest for ’s services, it asks to give references about its previous performance. Then, agent receives ’s certified ratings set and uses it to calculate ’s CR.
Next, we elaborate on how the trustor can approximate the real environment’s conditions. We enumerate indicative changes in the environment and analyze on how the trustor could sense this particular change and measure the extent of the change.
Given that
is the list of nearby providers in round
, and
is the list of nearby providers in round
, the consumer can calculate the list of the newcomer nearby provider agents,
, as the providers that exist in
, but not in
(
. Then, the following feature can be calculated by the consumer agent as an index of the provider population change in each round:
where the meaning of
is cardinality of. Intuitively, this ratio expresses how changes in the total provider population can be reflected in changes in the provider population situated in the consumer’s radius of operation. However, in any given round, newcomer providers may not be located within a specific consumer’s radius of operation, even if new providers have entered the system. In this case, the total change of the providers’ population in the system can be better assessed in a window of consecutive rounds.
Given that a window of rounds
is defined as a set of
consecutive rounds,
, the consumer can calculate the feature
for each round
, as follows.
Then, a more accurate index of the provider population change in each round can be calculated as the following mean:
Note that can include providers that are not really newcomers but they previously existed in the system and appear as new agents in , either due to their own movement in the world, due to the consumer’s movement, or both. In other words, agents’ movements in the world introduce noise in the measurement of .
Each newcomer provider agent has not yet interacted with other agents in the system and therefore its trustworthiness cannot be determined using the interaction trust and witness reputation modules. If the newcomer provider does not have any certified ratings from its interactions with agents in other systems, then its trustworthiness cannot be determined using the certified reputation module either. This agent belongs to the set, which is a subset of .
We can distinguish another category of newcomer provider agents, those whose trustworthiness can be determined solely by CR, because they own certified ratings from their interactions with agents in other systems. Let
denote the subset of
whose trustworthiness can be determined using only the CR module. The consumer can then calculate the following feature as an alternative index for the provider population change in a round.
As previously stated, in any given round, newcomer providers may not be located within a specific consumer’s radius of operation, even if they have entered the system. Thus, a more accurate estimate of
can be calculated in a window of
n consecutive rounds, with the following mean:
- 2.
The consumer population changes at maximum X% in each round.
If the consumer population has changed, it is possible that the consumer itself is a newcomer. In this case, the consumer is not expected to have ratings for any of its nearby providers in its local ratings database, and the IT module of FIRE cannot work. Thus, estimating whether it is a newcomer consumer probably helps the agent to decide about which trust model to employ for maximum benefits. The consumer can calculate the feature
as follows. It sets
, if there are no available ratings in its local ratings database for any of the nearby providers, otherwise it sets
. More formally:
According to the WR process, when consumer
assesses the WR of a nearby provider
, it sends out a query for ratings to
consumer acquaintances that are likely to have relative ratings on agent b. Each newcomer consumer acquaintance will try to match the query to its own (local) ratings database, but it will find no matching ratings because of no previous interactions with b. Thus, the acquaintance will return no ratings. In this case, the consumer can reasonably infer that an acquaintance that returns no ratings is very likely to be a newcomer agent. So, consumer agent
a, in order to approximate the consumer population change, can calculate the following feature:
where
is the set of consumer acquaintances of
to which consumer
sends queries (for ratings), one for each of its nearby providers, at round
, and
is the subset of
consumer acquaintances that returned no ratings (for any query) to
at round
.
As previously stated, in any given round, newcomer consumer acquaintances may not be located within a specific consumer’s radius of operation, even if newcomer consumers have entered the system. Thus, a more accurate estimate of
can be calculated in a window of
consecutive rounds, with the following mean:
- 3.
The provider alters its average level of performance at maximum X UG units with a probability of p in each round.
A consumer using FIRE selects the provider with the highest trust value in the HasTrustValue set. The quantity
is an estimate of the average performance of the selected provider whose actual performance can be different. The difference
expresses the change of the average performance level of a specific provider. Yet not all providers alter their average level of performance in each round. Thus, the consumer can calculate the following feature as an estimate of a provider’s average level of performance, by using the differences
of the last
interactions with this provider.
- 4.
The providers switch into a different (performance) profile with a probability of in each round.
A consumer can use as an estimate of a provider’s profile change, as well.
- 5.
Consumers move to a new location on the spherical world with a probability in each round.
The list can include providers that appear as new because of the consumer’s movement on the world. Thus, can also be used as an estimate of consumer’s movement.
Nevertheless, in order to make a more accurate estimate, a consumer can use its polar coordinates. Given that
are its polar coordinates in round
and
are its polar coordinates in round
, a consumer is able to calculate the following feature:
The consumer estimates that its location has changed, by setting , if at least one of its polar coordinates have changed compared to the previous round.
- 6.
Providers move to a new location on the spherical world with a probability in each round.
The list can include providers that appear as new because of their movement in the world. Thus, also serves as an estimate of the providers’ movement.
Note that since a provider does not know other agents’ polar coordinates, it cannot calculate a feature similar to .








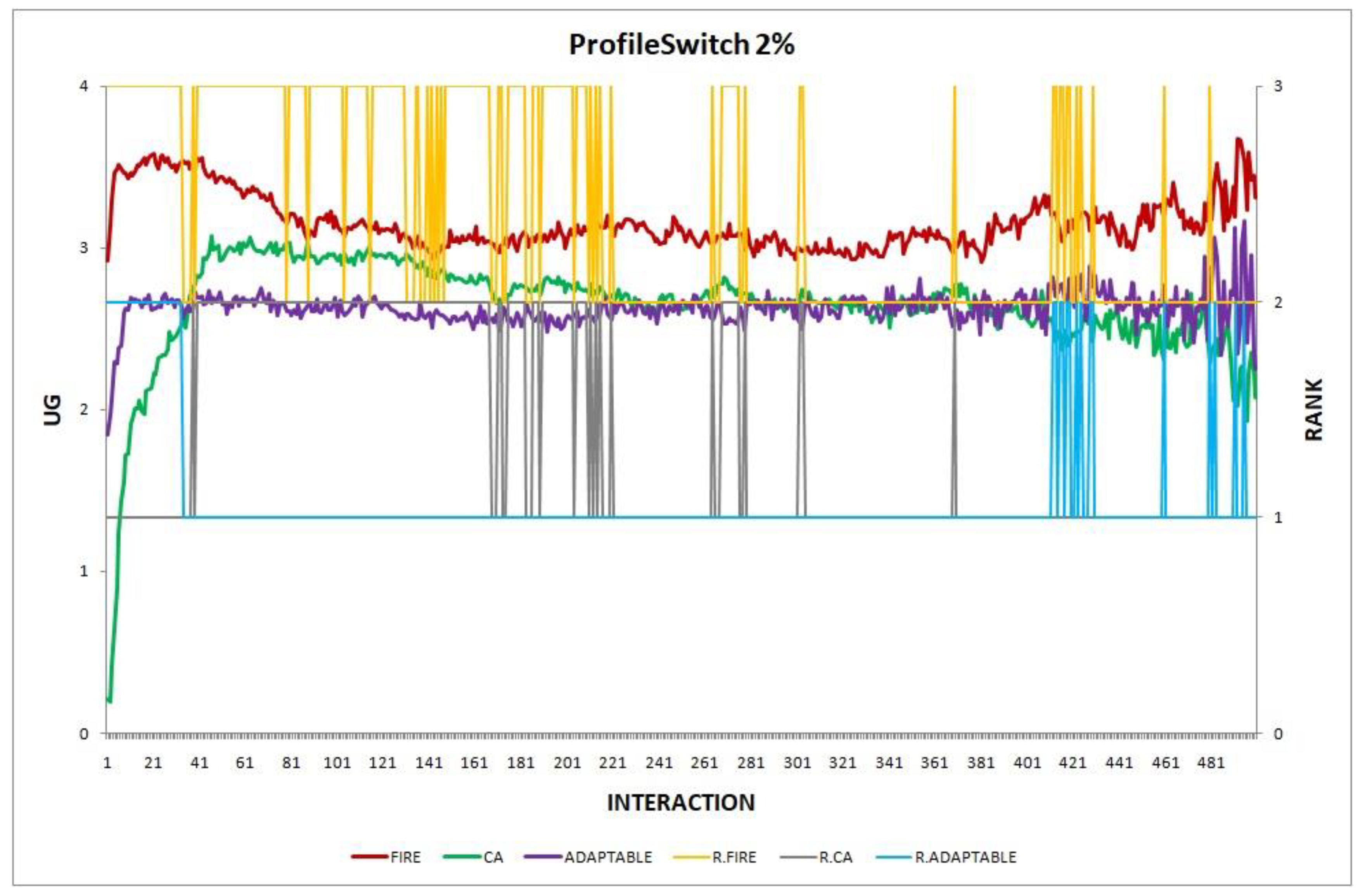


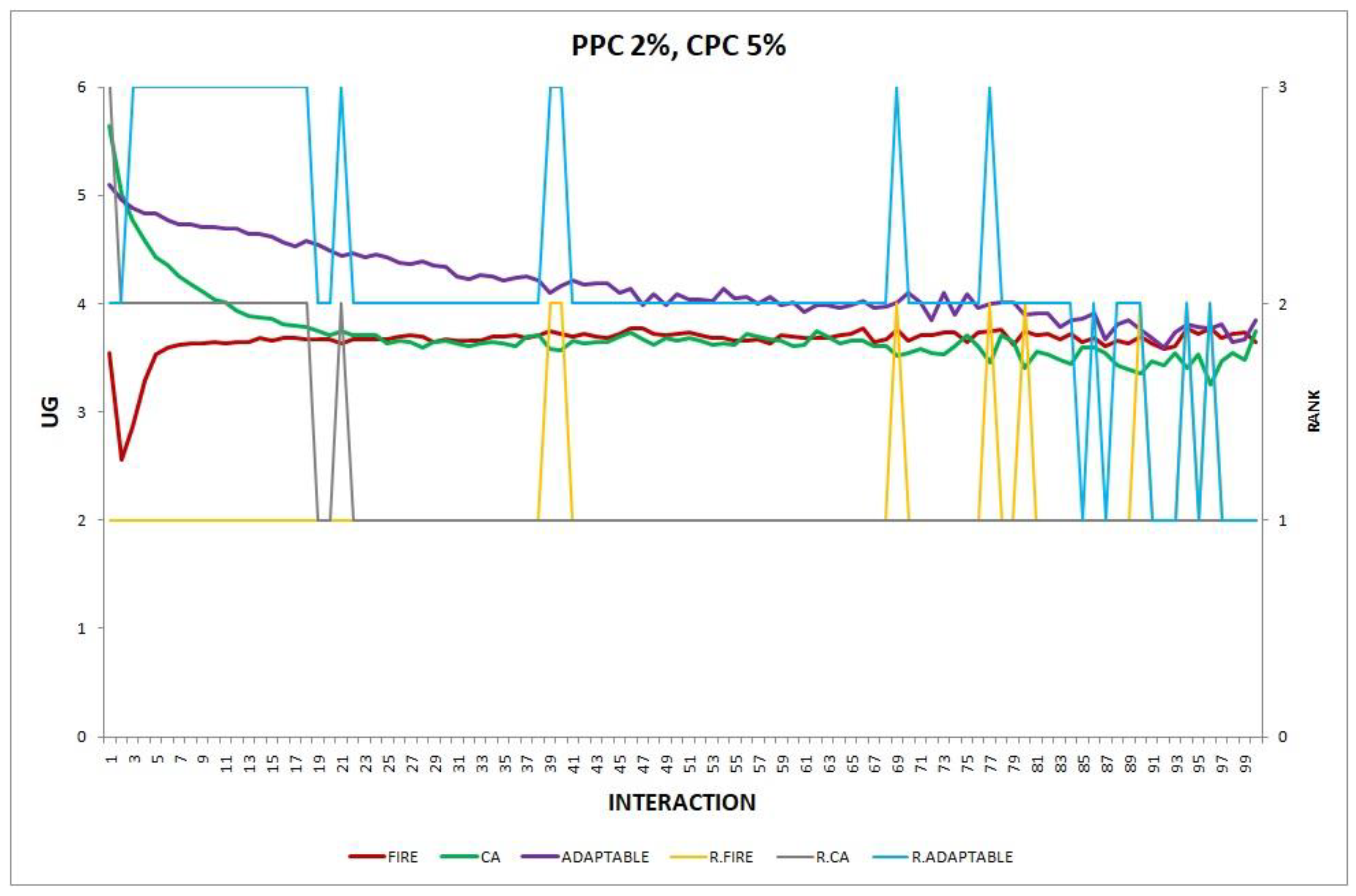
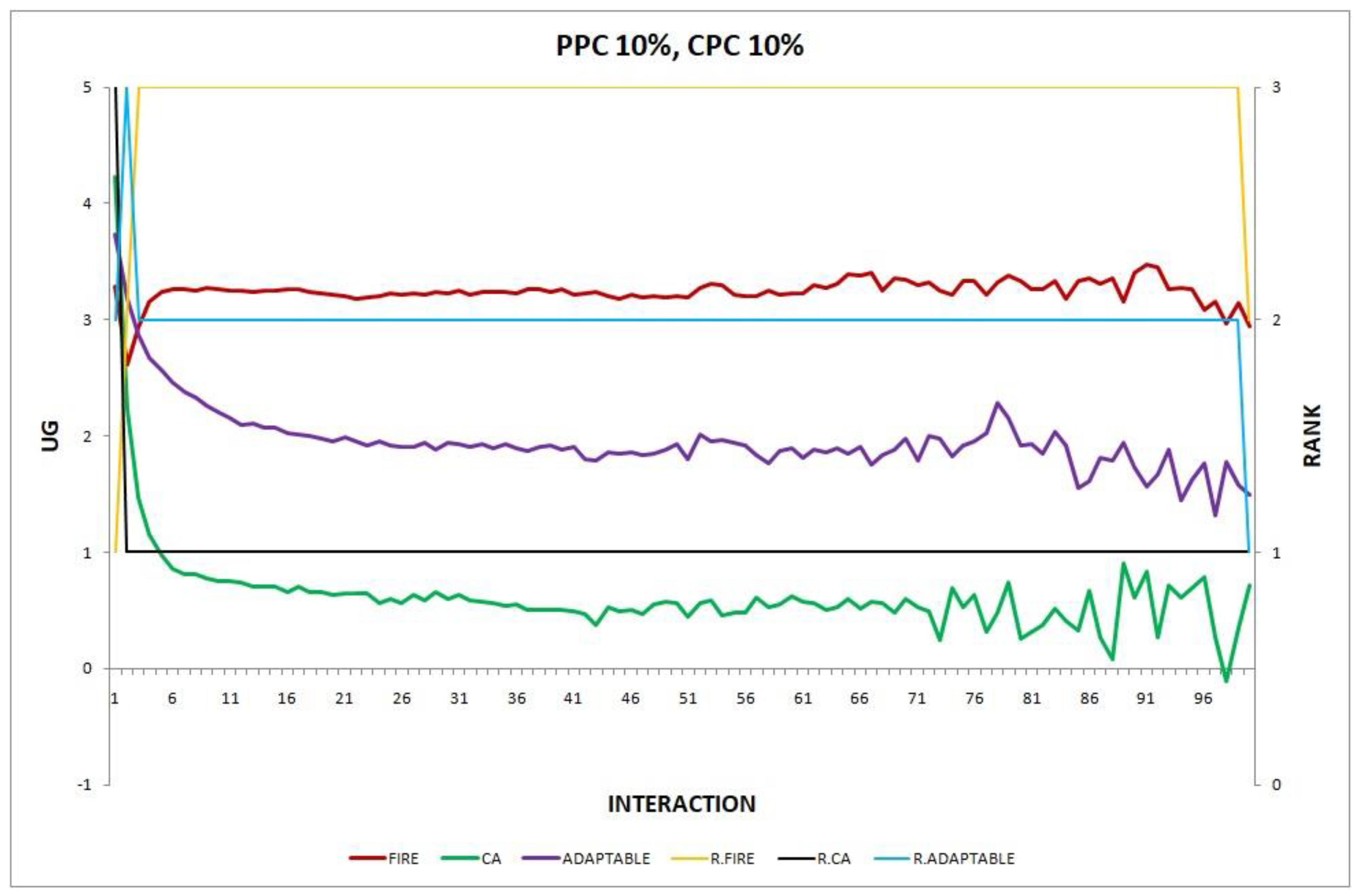

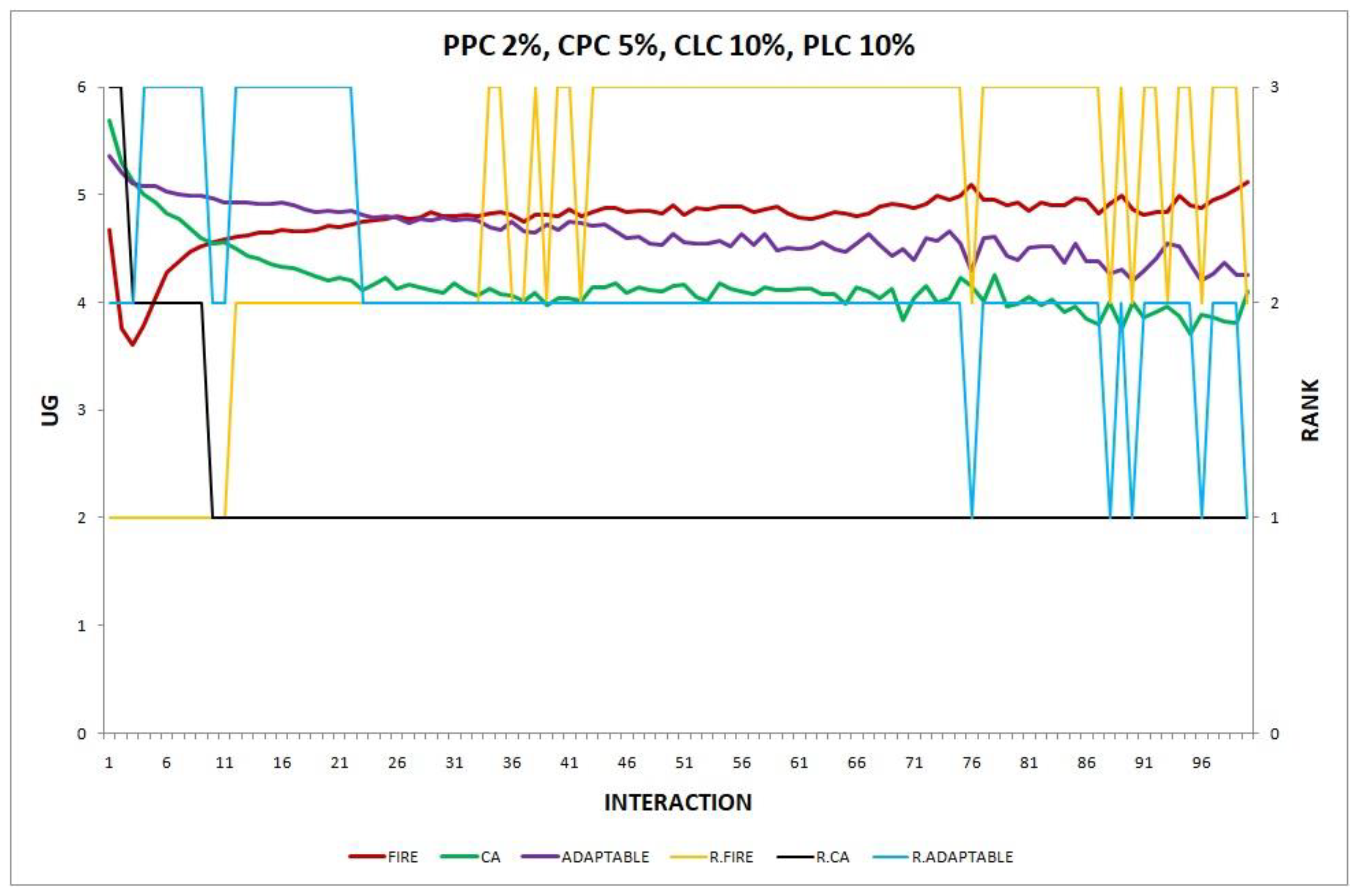
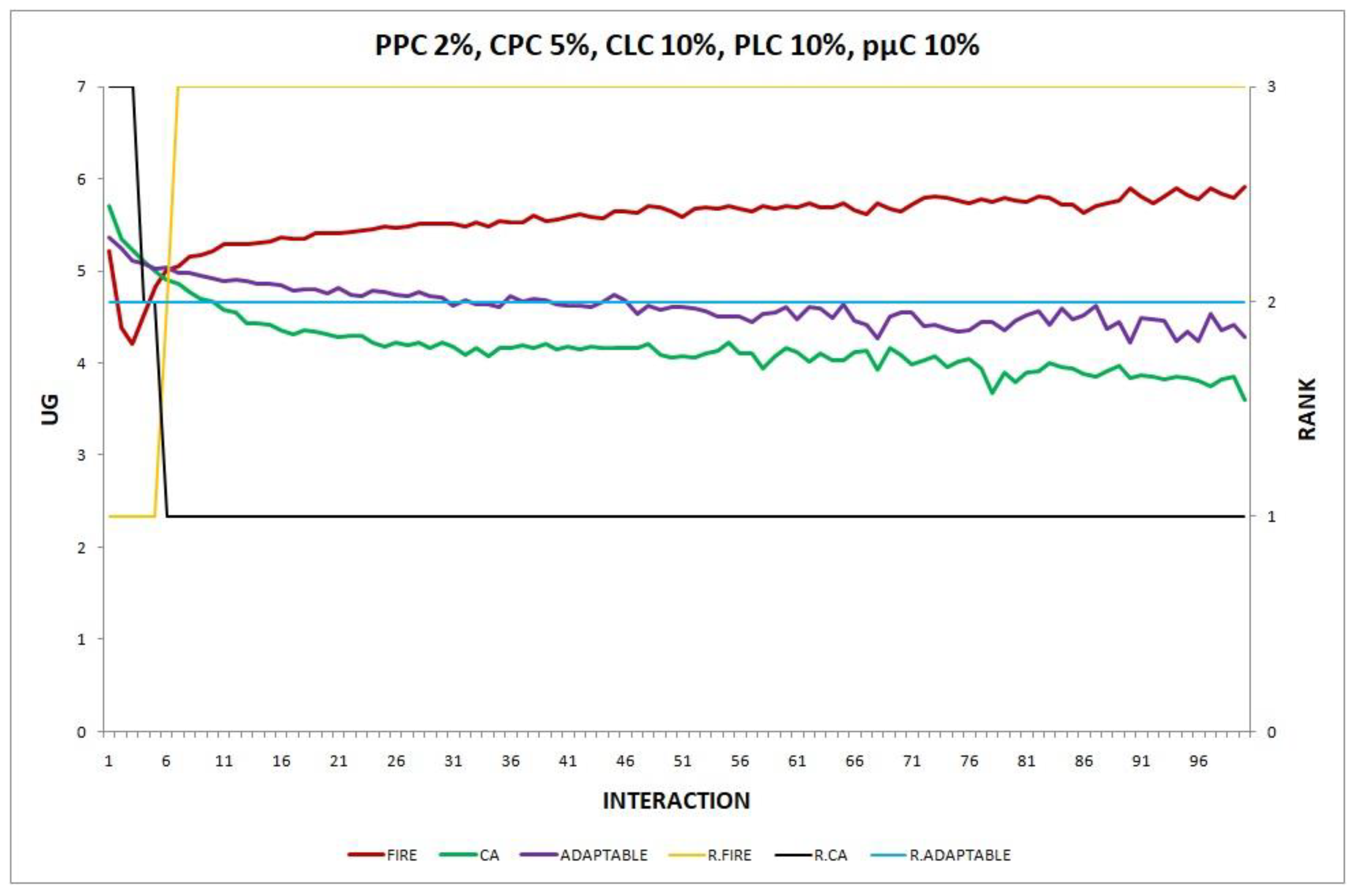
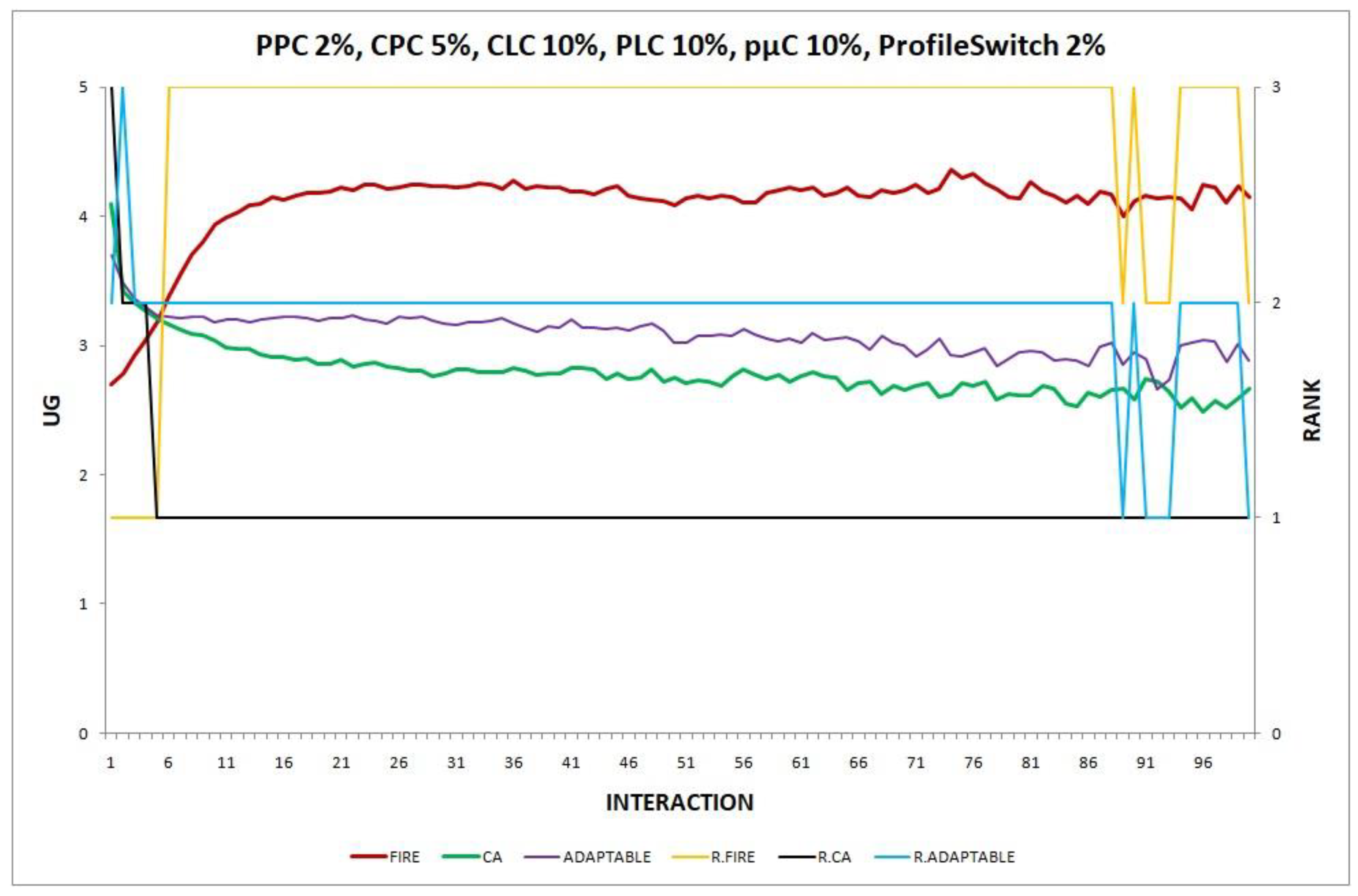


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}