Computer Vision and Pattern Recognition Techniques
Share This Topical Collection
Editor
Topical Collection Information
Dear Colleagues,
Recently, AI, machine learning, pattern recognition, and deep learning have been attracting attention in various fields of applications, such as autonomous driving, IoT, robot, drone, smart mobility, etc. These applications acquire data from the surrounding environment through sensing; they then analyze the acquired data, making decisions and actions based on the analysis. Vision sensors are mainly used to acquire data, thus, computer vision technology that analyzes and utilizes visual information is of great importance. The aims of this Topical Collection are to provide a venue to publish various research about computer vision technologies based on AI, machine learning, pattern recognition, and deep learning. Specifically, our scope includes recognition tasks (including image classification, object detection, and segmentation), low-level vision tasks (including super resolution and image denoising), and tasks related to video and 3D vision.
Dr. Donghyeon Cho
Collection Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Electronics is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- computer vision
- image processing
- deep learning
- recognition
- object detection
- segmentation
- convolutional neural network
- video processing
- 3d vision
- low-level vision
Published Papers (36 papers)
Open AccessArticle
3D Human Motion Prediction via the Decoupled Spatiotemporal Clue
by
Mingrui Xu, Zheming Gu and Erping Li
Viewed by 1309
Abstract
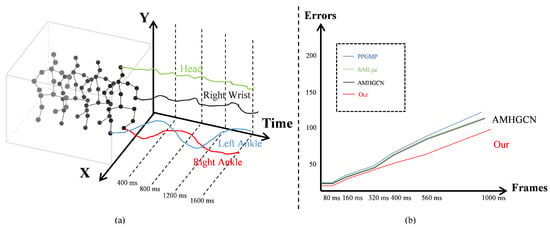
Human motion exhibits high-dimensional and stochastic characteristics, posing significant challenges for modeling and prediction. Existing approaches typically employ coupled spatiotemporal frameworks to generate future poses. However, the intrinsic nonlinearity of joint interactions over time, compounded by high-dimensional noise, often obscures meaningful motion features.
[...] Read more.
Human motion exhibits high-dimensional and stochastic characteristics, posing significant challenges for modeling and prediction. Existing approaches typically employ coupled spatiotemporal frameworks to generate future poses. However, the intrinsic nonlinearity of joint interactions over time, compounded by high-dimensional noise, often obscures meaningful motion features. Notably, while adjacent joints demonstrate strong spatial correlations, their temporal trajectories frequently remain independent, adding further complexity to modeling efforts. To address these issues, we propose a novel framework for human motion prediction via the
decoupled spatiotemporal clue (DSC), which explicitly disentangles and models spatial and temporal dependencies. Specifically, DSC comprises two core components: (i) a
spatiotemporal decoupling module that dynamically identifies critical joints and their hierarchical relationships using graph attention combined with separable convolutions for efficient motion decomposition; and (ii) a
pose generation module that integrates local motion denoising with global dynamics modeling through a spatiotemporal transformer that independently processes spatial and temporal correlations. Experiments on the widely used human motion datasets H3.6M and AMASS demonstrate the superiority of DSC, which achieves 13% average improvement in long-term prediction over state-of-the-art methods.
Full article
►▼
Show Figures
Open AccessEditor’s ChoiceArticle
Human-Centric Depth Estimation: A Hybrid Approach with Minimal Data
by
Yuhyun Kim, Heejin Ahn, Taeseop Kim, Byungtae Ahn and Dong-Geol Choi
Cited by 1 | Viewed by 2206
Abstract
This study presents a novel system for accurate camera-to-person distance estimation in CCTV environments. To address the limitations of existing approaches—which often require extensive training data and lack object-level precision—we propose a hybrid framework that integrates SAM’s zero-shot segmentation with monocular depth estimation.
[...] Read more.
This study presents a novel system for accurate camera-to-person distance estimation in CCTV environments. To address the limitations of existing approaches—which often require extensive training data and lack object-level precision—we propose a hybrid framework that integrates SAM’s zero-shot segmentation with monocular depth estimation. Our method isolates human subjects from complex backgrounds and incorporates Kernel Density Estimation (KDE), log-space learning, and linear residual blocks to improve prediction accuracy. This approach is designed to resolve the non-linear mapping between visual features and metric distances. Evaluations on a custom dataset demonstrate a mean absolute error (MAE) of 0.65 m on 1612 test images, using only 30 training samples. Notably, the use of SAM for fine-grained segmentation significantly outperforms conventional bounding box methods, reducing the MAE from 0.82 m to 0.65 m. The proposed system offers immediate applicability to security surveillance and disaster response scenarios, with its minimal data requirements enhancing its practical deployability.
Full article
►▼
Show Figures
Open AccessEditor’s ChoiceArticle
A Study on the Features for Multi-Target Dual-Camera Tracking and Re-Identification in a Comparatively Small Environment
by
Jong-Chen Chen, Po-Sheng Chang and Yu-Ming Huang
Viewed by 1973
Abstract
Tracking across multiple cameras is a complex problem in computer vision. Its main challenges include camera calibration, occlusion handling, camera overlap and field of view, person re-identification, and data association. In this study, we designed a laboratory as a research environment that facilitates
[...] Read more.
Tracking across multiple cameras is a complex problem in computer vision. Its main challenges include camera calibration, occlusion handling, camera overlap and field of view, person re-identification, and data association. In this study, we designed a laboratory as a research environment that facilitates our exploration of some of the above challenging issues. This study uses stereo camera calibration and key point detection to reconstruct the three-dimensional key points of the person being tracked, thereby performing person-tracking tasks. The results show that the dual cameras’ 3D spatial tracking method can have a relatively better continuous monitoring effect than a single camera alone. This study adopts four ways to evaluate person similarity, which can effectively reduce the unnecessary identity generation of persons. However, using all four methods simultaneously may not produce better results than a specific assessment method alone due to differences in people’s activity situations.
Full article
►▼
Show Figures
Open AccessArticle
Clean Collector Algorithm for Satellite Image Pre-Processing of SAR-to-EO Translation
by
Min-Woo Kim, Se-Kil Park, Jin-Gi Ju, Hyeon-Cheol Noh and Dong-Geol Choi
Cited by 2 | Viewed by 2285
Abstract
In applications such as environmental monitoring, algorithms and deep learning-based methods using synthetic aperture radar (SAR) and electro-optical (EO) data have been proposed with promising results. These results have been achieved using already cleaned datasets for training data. However, in real-world data collection,
[...] Read more.
In applications such as environmental monitoring, algorithms and deep learning-based methods using synthetic aperture radar (SAR) and electro-optical (EO) data have been proposed with promising results. These results have been achieved using already cleaned datasets for training data. However, in real-world data collection, data are often collected regardless of environmental noises (clouds, night, missing data, etc.). Without cleaning the data with these noises, the trained model has a critical problem of poor performance. To address these issues, we propose the Clean Collector Algorithm (CCA). First, we use a pixel-based approach to clean the QA60 mask and outliers. Secondly, we remove missing data and night-time data that can act as noise in the training process. Finally, we use a feature-based refinement method to clean the cloud images using FID. We demonstrate its effectiveness by winning first place in the SAR-to-EO translation track of the MultiEarth 2023 challenge. We also highlight the performance and robustness of the CCA on other cloud datasets, SEN12MS-CR-TS and Scotland&India.
Full article
►▼
Show Figures
Open AccessArticle
Stage-by-Stage Adaptive Alignment Mechanism for Object Detection in Aerial Images
by
Jiangang Zhu, Donglin Jing and Dapeng Gao
Cited by 2 | Viewed by 2173
Abstract
Object detection in aerial images has had a broader range of applications in the past few years. Unlike the targets in the images of horizontal shooting, targets in aerial photos generally have arbitrary orientation, multi-scale, and a high aspect ratio. Existing methods often
[...] Read more.
Object detection in aerial images has had a broader range of applications in the past few years. Unlike the targets in the images of horizontal shooting, targets in aerial photos generally have arbitrary orientation, multi-scale, and a high aspect ratio. Existing methods often employ a classification backbone network to extract translation-equivariant features (TEFs) and utilize many predefined anchors to handle objects with diverse appearance variations. However, they encounter misalignment at three levels, spatial, feature, and task, during different detection stages. In this study, we propose a model called the Staged Adaptive Alignment Detector (SAADet) to solve these challenges. This method utilizes a Spatial Selection Adaptive Network (SSANet) to achieve spatial alignment of the convolution receptive field to the scale of the object by using a convolution sequence with an increasing dilation rate to capture the spatial context information of different ranges and evaluating this information through model dynamic weighting. After correcting the preset horizontal anchor to an oriented anchor, feature alignment is achieved through the alignment convolution guided by oriented anchor to align the backbone features with the object’s orientation. The decoupling of features using the Active Rotating Filter is performed to mitigate inconsistencies due to the sharing of backbone features in regression and classification tasks to accomplish task alignment. The experimental results show that SAADet achieves equilibrium in speed and accuracy on two aerial image datasets, HRSC2016 and UCAS-AOD.
Full article
►▼
Show Figures
Open AccessReview
Deep Learning for Abnormal Human Behavior Detection in Surveillance Videos—A Survey
by
Leonard Matheus Wastupranata, Seong G. Kong and Lipo Wang
Cited by 36 | Viewed by 16782
Abstract
Detecting abnormal human behaviors in surveillance videos is crucial for various domains, including security and public safety. Many successful detection techniques based on deep learning models have been introduced. However, the scarcity of labeled abnormal behavior data poses significant challenges for developing effective
[...] Read more.
Detecting abnormal human behaviors in surveillance videos is crucial for various domains, including security and public safety. Many successful detection techniques based on deep learning models have been introduced. However, the scarcity of labeled abnormal behavior data poses significant challenges for developing effective detection systems. This paper presents a comprehensive survey of deep learning techniques for detecting abnormal human behaviors in surveillance video streams. We categorize the existing techniques into three approaches: unsupervised, partially supervised, and fully supervised. Each approach is examined in terms of its underlying conceptual framework, strengths, and drawbacks. Additionally, we provide an extensive comparison of these approaches using popular datasets frequently used in the prior research, highlighting their performance across different scenarios. We summarize the advantages and disadvantages of each approach for abnormal human behavior detection. We also discuss open research issues identified through our survey, including enhancing robustness to environmental variations through diverse datasets, formulating strategies for contextual abnormal behavior detection. Finally, we outline potential directions for future development to pave the way for more effective abnormal behavior detection systems.
Full article
►▼
Show Figures
Open AccessArticle
SRFAD-Net: Scale-Robust Feature Aggregation and Diffusion Network for Object Detection in Remote Sensing Images
by
Jing Liu, Donglin Jing, Haijing Zhang and Chunyu Dong
Cited by 17 | Viewed by 2680
Abstract
The significant differences in target scales of remote sensing images lead to remarkable variations in visual features, posing significant challenges for feature extraction, fusion, regression, and classification. For example, models frequently struggle to capture features of targets across all scales, inadequately consider the
[...] Read more.
The significant differences in target scales of remote sensing images lead to remarkable variations in visual features, posing significant challenges for feature extraction, fusion, regression, and classification. For example, models frequently struggle to capture features of targets across all scales, inadequately consider the weights and importance of features at different scales during fusion, and encounter accuracy limitations when detecting targets of varying scales. To tackle these challenges, we proposes a Scale-Robust Feature Aggregation and Diffusion Network (SRFAD-Net) for remote sensing target detection. This model includes a Scale-Robust Feature Network (SRFN), an Adaptive Feature Aggregation and Diffusion (AFAD) module, and a Focaler-GIoU Loss. SRFN extracts scale-robust features by constructing a multi-scale pyramid. It includes a downsampling (ADown) module that combines the advantages of average pooling and max pooling, effectively preserving background information and salient features. This further enhances the network’s ability to handle targets of varying scales and shapes. The introduced Deformable Attention(DAttention) mechanism captures target features effectively through adaptive adjustment of the receptive field’s shape and size, reducing background clutter and substantially enhancing the model’s performance in detecting distant objects. In the feature fusion stage, we propose the AFAD module, which utilizes a dimension-adaptive perceptual selection mechanism and parallel depthwise convolutional operations to precisely aggregate multi-channel information. It then employs a diffusion mechanism to spread contextual information across various scales, greatly improving the network’s ability to extract and fuse features across multiple scales. For the detection head, we adopt the Focaler-GIoU Loss, leveraging its advantages in handling non-overlapping bounding boxes, effectively alleviating the difficulty of localization caused by scale variations. We have undertaken experiments on two widely utilized aerial target datasets: the Remote Sensing Scene Object Detection Dataset (RSOD) and NWPU VHR-10, which is a high-resolution object detection dataset from Northwestern Polytechnical University. The findings of these experiments clearly illustrate that SRFAD-Net surpasses the performances of mainstream detectors.
Full article
►▼
Show Figures
Open AccessArticle
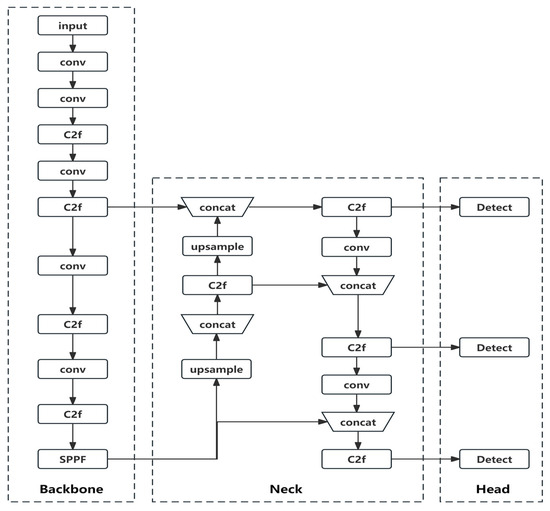
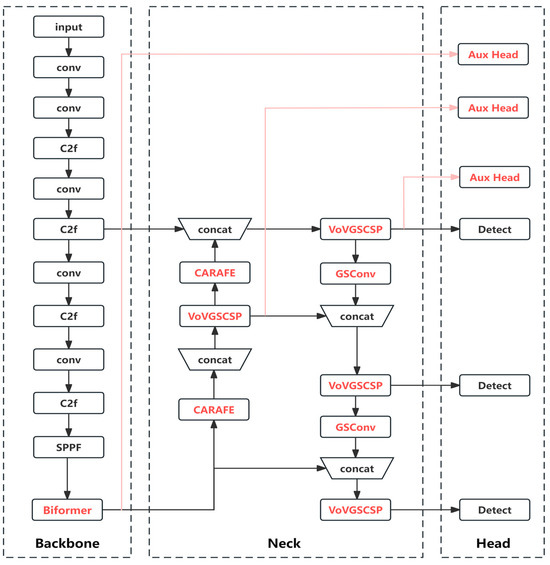
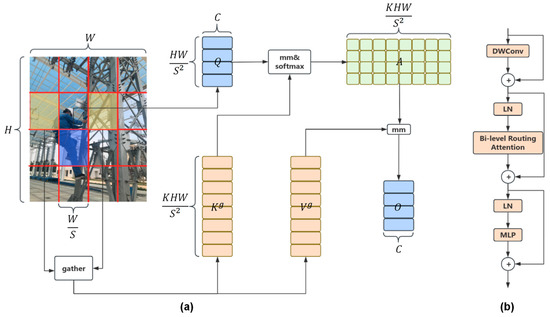
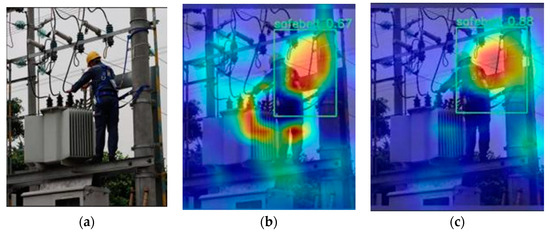
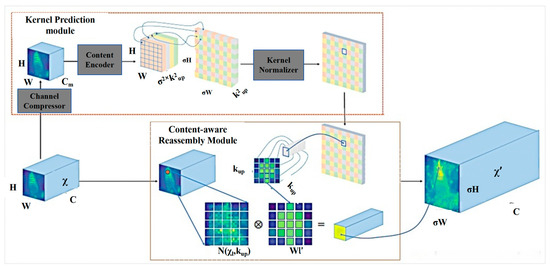
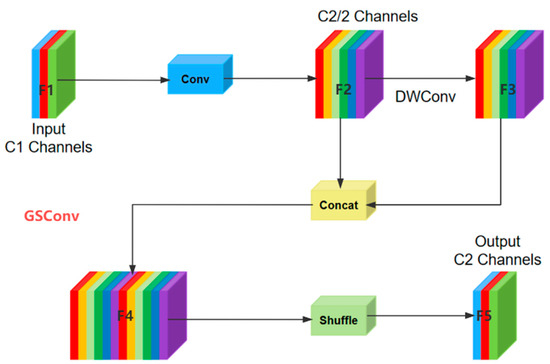
An Improved Safety Belt Detection Algorithm for High-Altitude Work Based on YOLOv8
by
Tingyao Jiang, Zhao Li, Jian Zhao, Chaoguang An, Hao Tan and Chunliang Wang
Cited by 9 | Viewed by 3653
Abstract
High-altitude work poses significant safety risks, and wearing safety belts is crucial to prevent falls and ensure worker safety. However, manual monitoring of safety belt usage is time consuming and prone to errors. In this paper, we propose an improved high-altitude safety belt
[...] Read more.
High-altitude work poses significant safety risks, and wearing safety belts is crucial to prevent falls and ensure worker safety. However, manual monitoring of safety belt usage is time consuming and prone to errors. In this paper, we propose an improved high-altitude safety belt detection algorithm based on the YOLOv8 model to address these challenges. Our paper introduces several improvements to enhance its performance in detecting safety belts. First, to enhance the feature extraction capability, we introduce a BiFormer attention mechanism. Moreover, we used a lightweight upsampling operator instead of the original upsampling layer to better preserve and recover detailed information without adding an excessive computational burden. Meanwhile, Slim-neck was introduced into the neck layer. Additionally, extra auxiliary training heads were incorporated into the head layer to enhance the detection capability. Lastly, to optimize the prediction of bounding box position and size, we replaced the original loss function with MPDIOU. We evaluated our algorithm using a dataset collected from high-altitude work scenarios and demonstrated its effectiveness in detecting safety belts with high accuracy. Compared to the original YOLOv8 model, the improved model achieves P (precision), R (recall), and mAP (mean average precision) values of 98%, 91.4%, and 97.3%, respectively. These values represent an improvement of 5.1%, 0.5%, and 1.2%, respectively, compared to the original model. The proposed algorithm has the potential to improve workplace safety and reduce the risk of accidents in high-altitude work environments.
Full article
►▼
Show Figures
Open AccessArticle
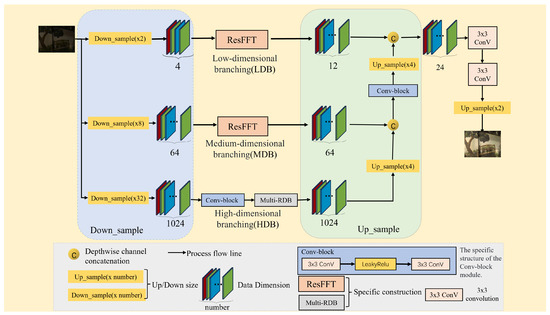
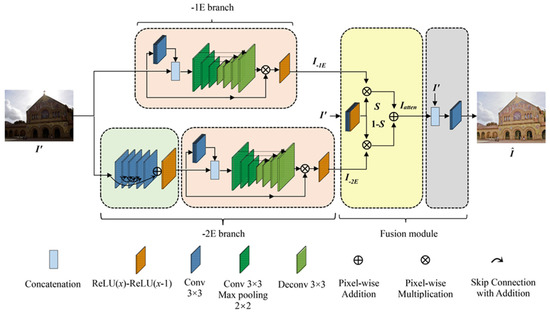
Real-Time Low-Light Imaging in Space Based on the Fusion of Spatial and Frequency Domains
by
Jiaxin Wu, Haifeng Zhang, Biao Li, Jiaxin Duan, Qianxi Li, Zeyu He, Jianzhong Cao and Hao Wang
Viewed by 2090
Abstract
Due to the low photon count in space imaging and the performance bottlenecks of edge computing devices, there is a need for a practical low-light imaging solution that maintains satisfactory recovery while offering lower network latency, reduced memory usage, fewer model parameters, and
[...] Read more.
Due to the low photon count in space imaging and the performance bottlenecks of edge computing devices, there is a need for a practical low-light imaging solution that maintains satisfactory recovery while offering lower network latency, reduced memory usage, fewer model parameters, and fewer operation counts. Therefore, we propose a real-time deep learning framework for low-light imaging. Leveraging the parallel processing capabilities of the hardware, we perform the parallel processing of the image data from the original sensor across branches with different dimensionalities. The high-dimensional branch conducts high-dimensional feature learning in the spatial domain, while the mid-dimensional and low-dimensional branches perform pixel-level and global feature learning through the fusion of the spatial and frequency domains. This approach ensures a lightweight network model while significantly improving the quality and speed of image recovery. To adaptively adjust the image based on brightness and avoid the loss of detailed pixel feature information, we introduce an adaptive balancing module, thereby greatly enhancing the effectiveness of the model. Finally, through validation on the SID dataset and our own low-light satellite dataset, we demonstrate that this method can significantly improve image recovery speed while ensuring image recovery quality.
Full article
►▼
Show Figures
Open AccessArticle
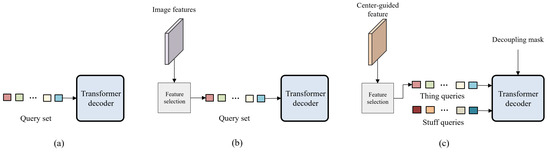
Center-Guided Transformer for Panoptic Segmentation
by
Jong-Hyeon Baek, Hee Kyung Lee, Hyon-Gon Choo, Soon-heung Jung and Yeong Jun Koh
Cited by 3 | Viewed by 2581
Abstract
A panoptic segmentation network to predict masks and classes for things and stuff in images is proposed in this work. Recently, panoptic segmentation has been advanced through the combination of the query-based learning and end-to-end learning approaches. Current research focuses on learning queries
[...] Read more.
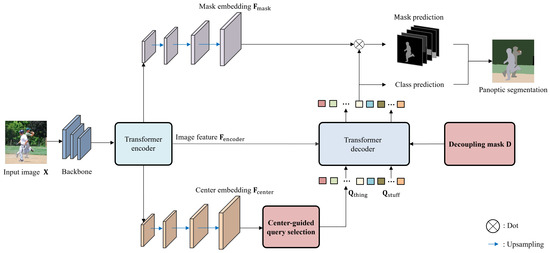
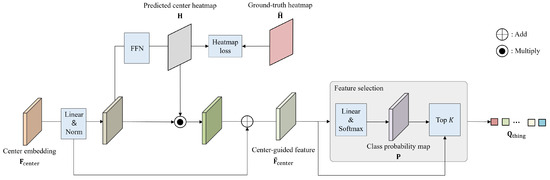
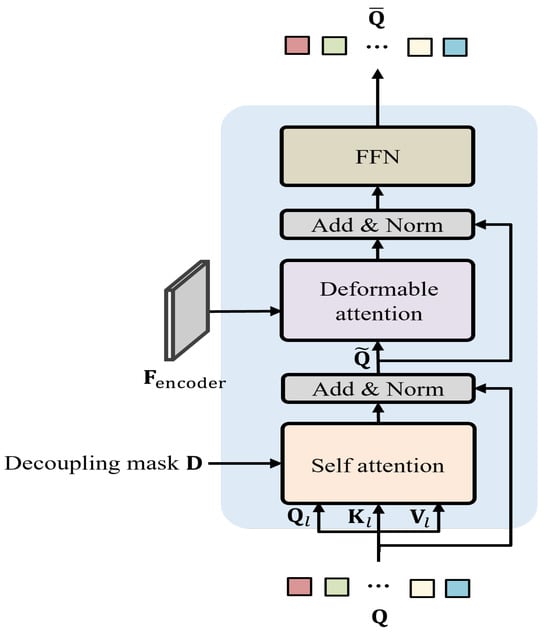
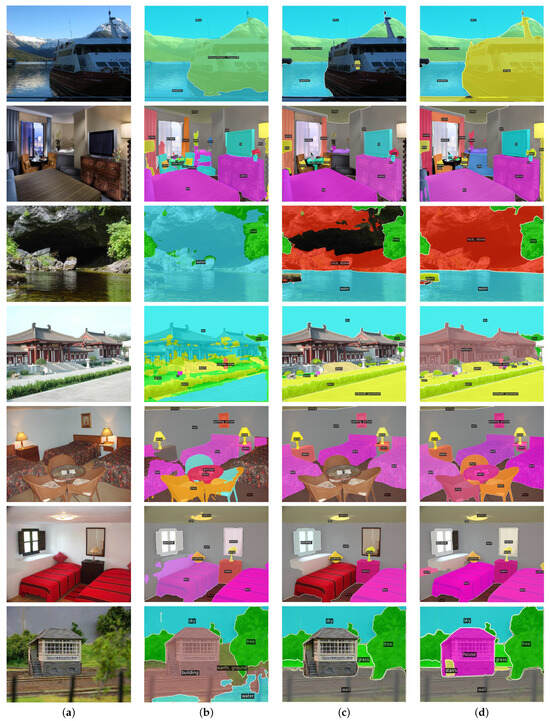
A panoptic segmentation network to predict masks and classes for things and stuff in images is proposed in this work. Recently, panoptic segmentation has been advanced through the combination of the query-based learning and end-to-end learning approaches. Current research focuses on learning queries without distinguishing between thing and stuff classes. We present decoupling query learning to generate effective thing and stuff queries for panoptic segmentation. For this purpose, we adopt different workflows for thing and stuff queries. We design center-guided query selection for thing queries, which focuses on the center regions of individual instances in images, while we set stuff queries as randomly initialized embeddings. Also, we apply a decoupling mask to the self-attention of query features to prevent interactions between things and stuff. In the query selection process, we generate a center heatmap that guides thing query selection. Experimental results demonstrate that the proposed panoptic segmentation network outperforms the state of the art on two panoptic segmentation datasets.
Full article
►▼
Show Figures
Open AccessArticle
Non-Uniform Motion Aggregation with Graph Convolutional Networks for Skeleton-Based Human Action Recognition
by
Chengwu Liang, Jie Yang, Ruolin Du, Wei Hu and Yun Tie
Cited by 7 | Viewed by 2718
Abstract
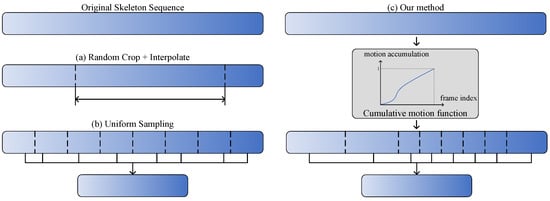
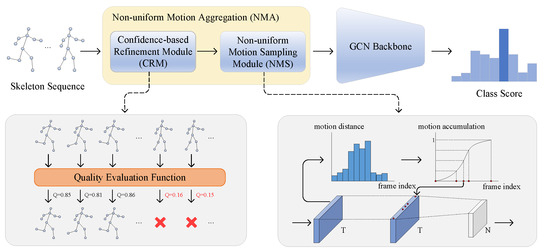
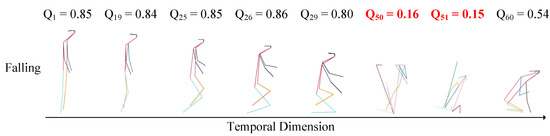
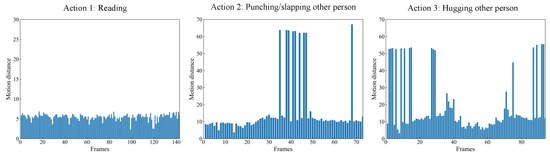
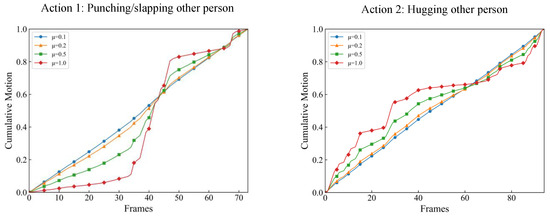
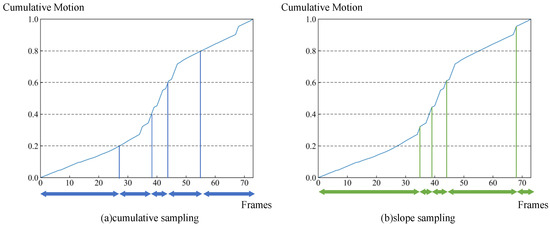
Skeleton-based human action recognition aims to recognize human actions from given skeleton sequences. The literature utilizes fixed-stride sampling and uniform aggregations, which are independent of the input data and do not focus on representative motion frames. In this paper, to overcome the challenge
[...] Read more.
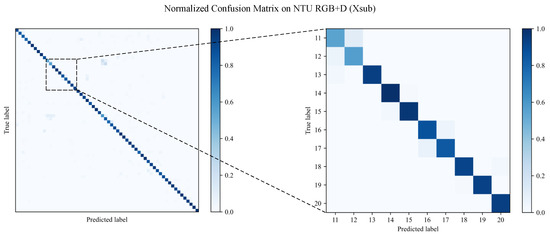
Skeleton-based human action recognition aims to recognize human actions from given skeleton sequences. The literature utilizes fixed-stride sampling and uniform aggregations, which are independent of the input data and do not focus on representative motion frames. In this paper, to overcome the challenge of the fixed uniform aggregation strategy being unable to focus on discriminative motion information, a novel non-uniform motion aggregation embedded with a graph convolutional network (NMA-GCN) is proposed for skeleton-based human action recognition. Based on the skeleton quality and motion-salient regions, NMA is able to focus on the discriminative motion information of human motion-salient regions. Finally, the aggregated skeleton sequences are embedded with the GCN backbone for skeleton-based human action recognition. Experiments were conducted on three large benchmarks: NTU RGB+D, NTU RGB+D 120, and FineGym. The results show that our method achieves 93.4% (Xsub) and 98.2% (Xview) on NTU RGB+D dataset, 87.0% (Xsub) and 90.0% (Xset) on the NTU RGB+D 120 dataset, and 90.3% on FineGym dataset. Ablation studies and evaluations across various GCN-based backbones further support the effectiveness and generalization of NMA-GCN.
Full article
►▼
Show Figures
Open AccessArticle
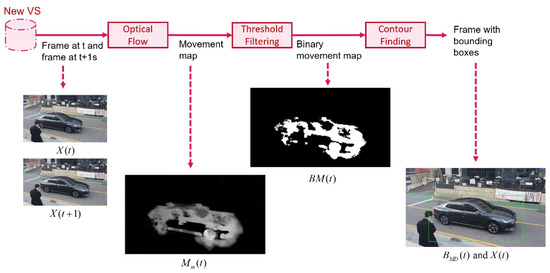
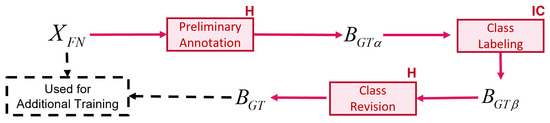
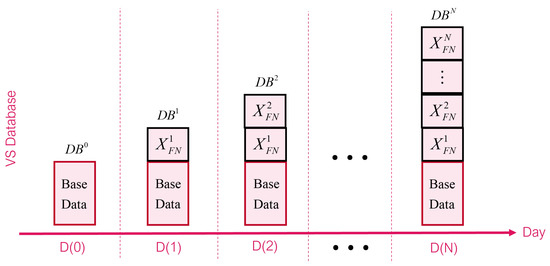
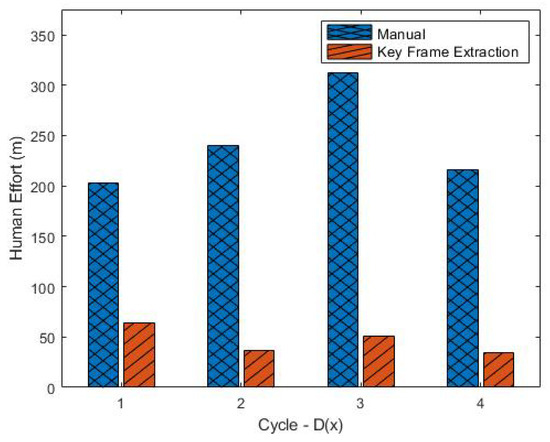
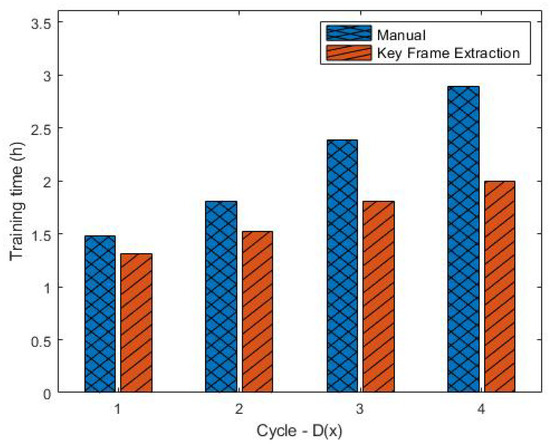
Key-Frame Extraction for Reducing Human Effort in Object Detection Training for Video Surveillance
by
Hagai R. Sinulingga and Seong G. Kong
Cited by 5 | Viewed by 5630
Abstract
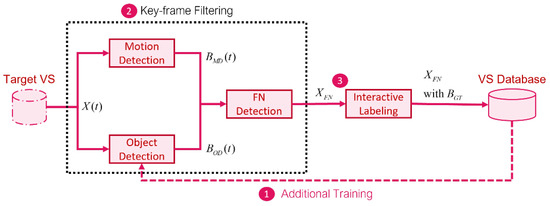
This paper presents a supervised learning scheme that employs key-frame extraction to enhance the performance of pre-trained deep learning models for object detection in surveillance videos. Developing supervised deep learning models requires a significant amount of annotated video frames as training data, which
[...] Read more.
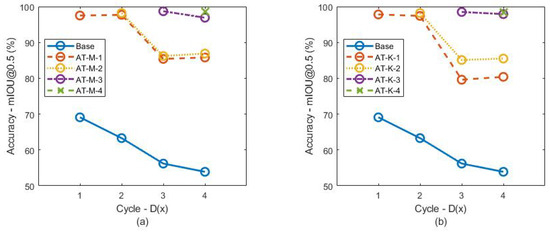
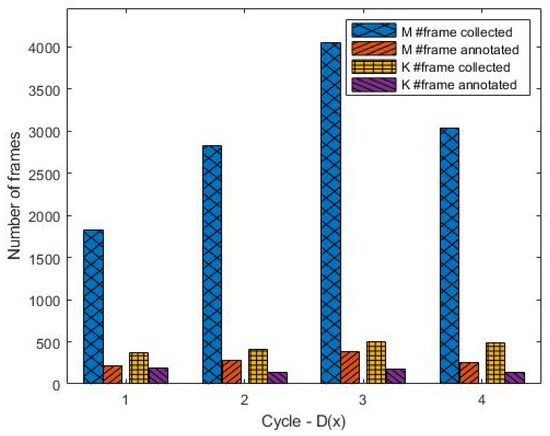
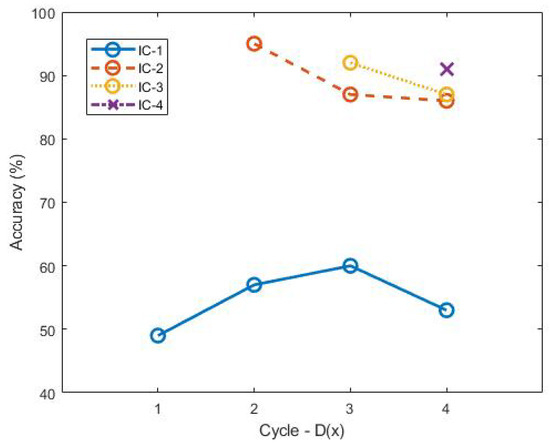
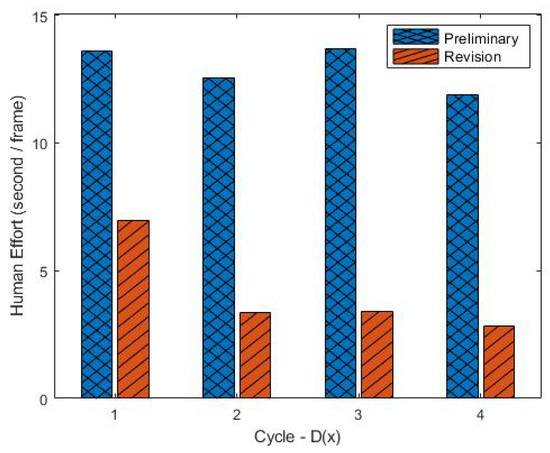
This paper presents a supervised learning scheme that employs key-frame extraction to enhance the performance of pre-trained deep learning models for object detection in surveillance videos. Developing supervised deep learning models requires a significant amount of annotated video frames as training data, which demands substantial human effort for preparation. Key frames, which encompass frames containing false negative or false positive objects, can introduce diversity into the training data and contribute to model improvements. Our proposed approach focuses on detecting false negatives by leveraging the motion information within video frames that contain the detected object region. Key-frame extraction significantly reduces the human effort involved in video frame extraction. We employ interactive labeling to annotate false negative video frames with accurate bounding boxes and labels. These annotated frames are then integrated with the existing training data to create a comprehensive training dataset for subsequent training cycles. Repeating the training cycles gradually improves the object detection performance of deep learning models to monitor a new environment. Experiment results demonstrate that the proposed learning approach improves the performance of the object detection model in a new operating environment, increasing the mean average precision (mAP@0.5) from 54% to 98%. Manual annotation of key frames is reduced by 81% through the proposed key-frame extraction method.
Full article
►▼
Show Figures
Open AccessArticle
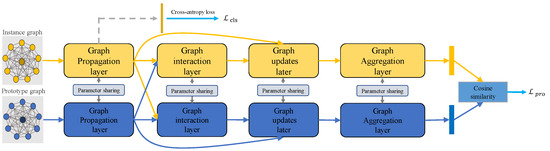
Webly Supervised Fine-Grained Image Recognition with Graph Representation and Metric Learning
by
Jianman Lin, Jiantao Lin, Yuefang Gao, Zhijing Yang and Tianshui Chen
Cited by 2 | Viewed by 2620
Abstract
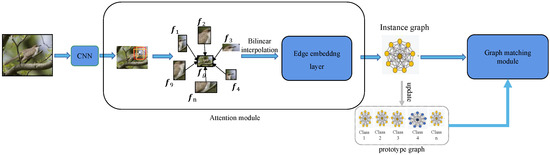
The aim of webly supervised fine-grained image recognition (FGIR) is to distinguish sub-ordinate categories based on data retrieved from the Internet, which can significantly mitigate the dependence of deep learning on manually annotated labels. Most current fine-grained image recognition algorithms use a large-scale
[...] Read more.
The aim of webly supervised fine-grained image recognition (FGIR) is to distinguish sub-ordinate categories based on data retrieved from the Internet, which can significantly mitigate the dependence of deep learning on manually annotated labels. Most current fine-grained image recognition algorithms use a large-scale data-driven deep learning paradigm, which relies heavily on manually annotated labels. However, there is a large amount of weakly labeled free data on the Internet. To utilize fine-grained web data effectively, this paper proposes a Graph Representation and Metric Learning (GRML) framework to learn discriminative and effective holistic–local features by graph representation for web fine-grained images and to handle noisy labels simultaneously, thus effectively using webly supervised data for training. Specifically, we first design an attention-focused module to locate the most discriminative region with different spatial aspects and sizes. Next, a structured instance graph is constructed to correlate holistic and local features to model the holistic–local information interaction, while a graph prototype that contains both holistic and local information for each category is introduced to learn category-level graph representation to assist in processing the noisy labels. Finally, a graph matching module is further employed to explore the holistic–local information interaction through intra-graph node information propagation as well as to evaluate the similarity score between each instance graph and its corresponding category-level graph prototype through inter-graph node information propagation. Extensive experiments were conducted on three webly supervised FGIR benchmark datasets, Web-Bird, Web-Aircraft and Web-Car, with classification accuracy of 76.62%, 85.79% and 82.99%, respectively. In comparison with Peer-learning, the classification accuracies of the three datasets separately improved 2.47%, 4.72% and 1.59%.
Full article
►▼
Show Figures
Open AccessArticle
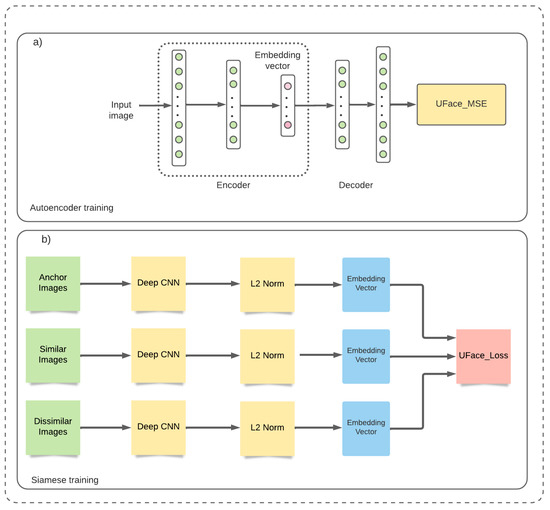
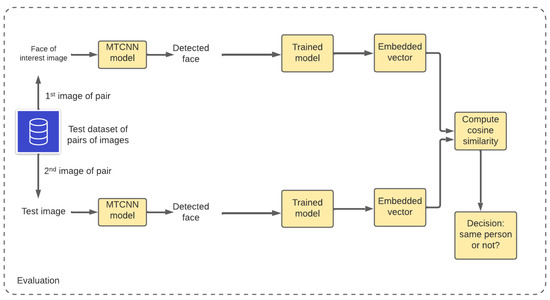
UFace: An Unsupervised Deep Learning Face Verification System
by
Enoch Solomon, Abraham Woubie and Krzysztof J. Cios
Cited by 19 | Viewed by 5155
Abstract
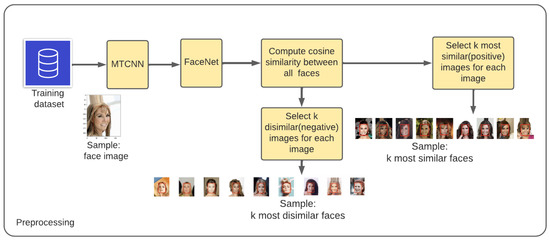
Deep convolutional neural networks are often used for image verification but require large amounts of labeled training data, which are not always available. To address this problem, an unsupervised deep learning face verification system, called UFace, is proposed here. It starts by selecting
[...] Read more.
Deep convolutional neural networks are often used for image verification but require large amounts of labeled training data, which are not always available. To address this problem, an unsupervised deep learning face verification system, called UFace, is proposed here. It starts by selecting from large unlabeled data the k most similar and k most dissimilar images to a given face image and uses them for training. UFace is implemented using methods of the autoencoder and Siamese network; the latter is used in all comparisons as its performance is better. Unlike in typical deep neural network training, UFace computes the loss function k times for similar images and k times for dissimilar images for each input image. UFace’s performance is evaluated using four benchmark face verification datasets: Labeled Faces in the Wild (LFW), YouTube Faces (YTF), Cross-age LFW (CALFW) and Celebrities in Frontal Profile in the Wild (CFP-FP). UFace with the Siamese network achieved accuracies of 99.40%, 96.04%, 95.12% and 97.89%, respectively, on the four datasets. These results are comparable with the state-of-the-art methods, such as ArcFace, GroupFace and MegaFace. The biggest advantage of UFace is that it uses much less training data and does not require labeled data.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
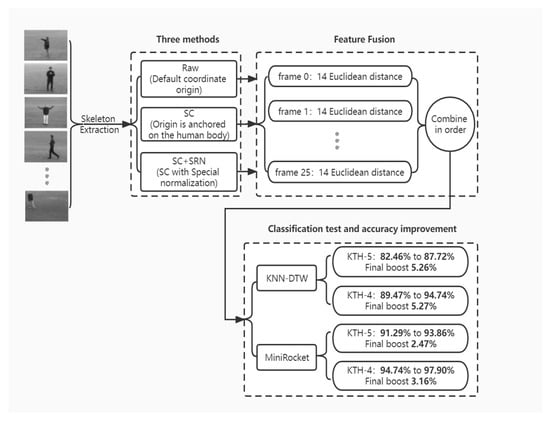
An Efficient Motion Registration Method Based on Self-Coordination and Self-Referential Normalization
by
Yuhao Ren, Bochao Zhang, Jing Chen, Liquan Guo and Jiping Wang
Viewed by 2369
Abstract
Action quality assessment (AQA) is an important problem in computer vision applications. During human AQA, differences in body size or changes in position relative to the sensor may cause unwanted effects. We propose a motion registration method based on self-coordination (SC) and self-referential
[...] Read more.
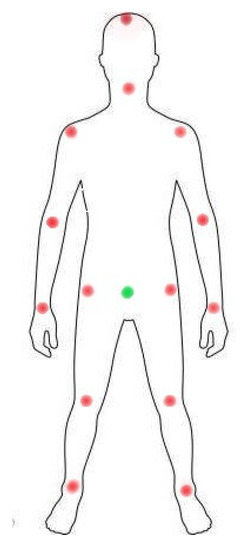
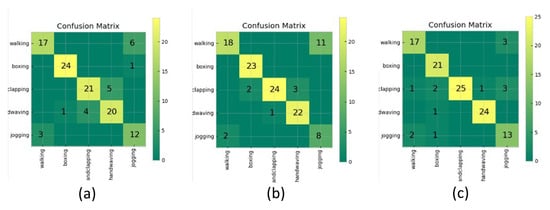
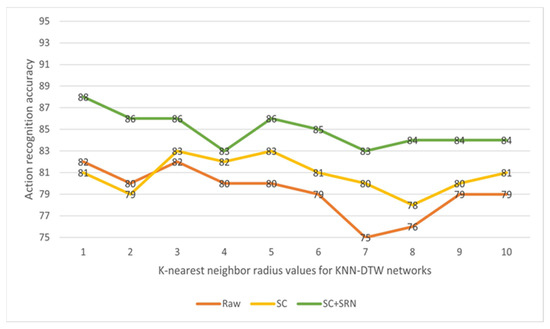
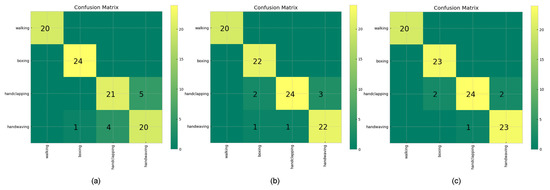
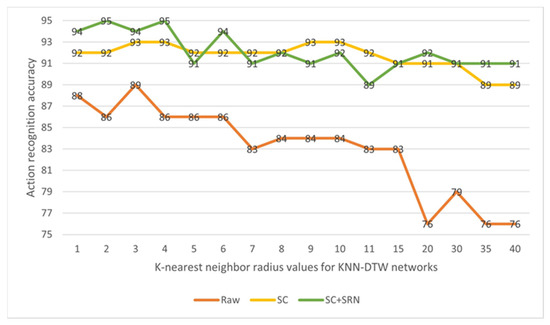
Action quality assessment (AQA) is an important problem in computer vision applications. During human AQA, differences in body size or changes in position relative to the sensor may cause unwanted effects. We propose a motion registration method based on self-coordination (SC) and self-referential normalization (SRN). By establishing a coordinate system on the human body and using a part of the human body as a normalized reference standard to process the raw data, the standardization and distinguishability of the raw data are improved. To demonstrate the effectiveness of our method, we conducted experiments on KTH datasets. The experimental results show that the method improved the classification accuracy of the KNN-DTW network for KTH-5 from 82.46% to 87.72% and for KTH-4 from 89.47% to 94.74%, and it improved the classification accuracy of the tsai-MiniRocket network for KTH-5 from 91.29% to 93.86% and for KTH-4 from 94.74% to 97.90%. The results show that our method can reduce the above effects and improve the action classification accuracy of the action classification network. This study provides a new method and idea for improving the accuracy of AQA-related algorithms.
Full article
►▼
Show Figures
Open AccessArticle
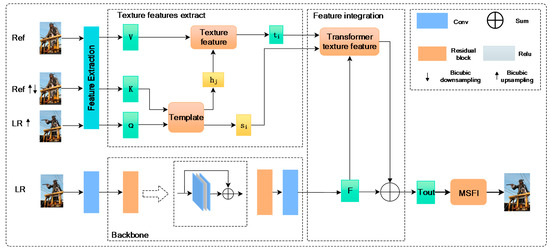
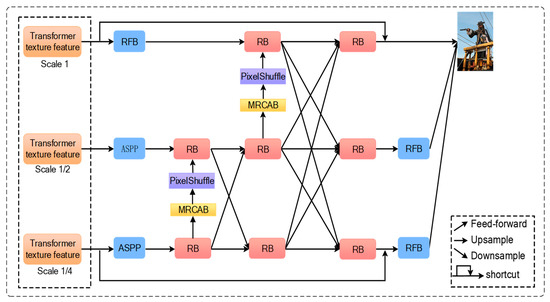
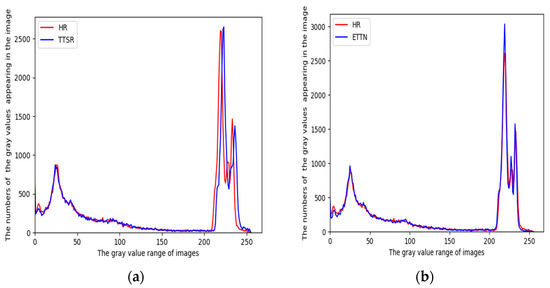
A Novel Deep-Learning-Based Enhanced Texture Transformer Network for Reference Image Super-Resolution
by
Changhong Liu, Hongyin Li, Zhongwei Liang, Yongjun Zhang, Yier Yan, Ray Y. Zhong and Shaohu Peng
Cited by 4 | Viewed by 3394
Abstract
The study explored a deep learning image super-resolution approach which is commonly used in face recognition, video perception and other fields. These generative adversarial networks usually have high-frequency texture details. The relevant textures of high-resolution images could be transferred as reference images to
[...] Read more.
The study explored a deep learning image super-resolution approach which is commonly used in face recognition, video perception and other fields. These generative adversarial networks usually have high-frequency texture details. The relevant textures of high-resolution images could be transferred as reference images to low-resolution images. The latest existing methods use transformer ideas to transfer related textures to low-resolution images, but there are still some problems with channel learning and detailed textures. Therefore, the study proposed an enhanced texture transformer network (ETTN) to improve the channel learning ability and details of the texture. It could learn the corresponding structural information of high-resolution texture images and convert it into low-resolution texture images. Through this, finding the feature map can change the exact feature of images and improve the learning ability between channels. We then used multi-scale feature integration (MSFI) to further enhance the effect of fusion and achieved different degrees of texture restoration. The experimental results show that the model has a good resolution enhancement effect on texture transformers. In different datasets, the peak signal to noise ratio (PSNR) and structural similarity (SSIM) were improved by 0.1–0.5 dB and 0.02, respectively.
Full article
►▼
Show Figures
Open AccessArticle
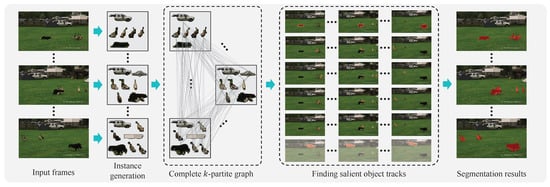
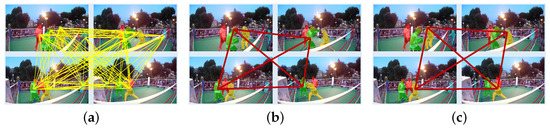
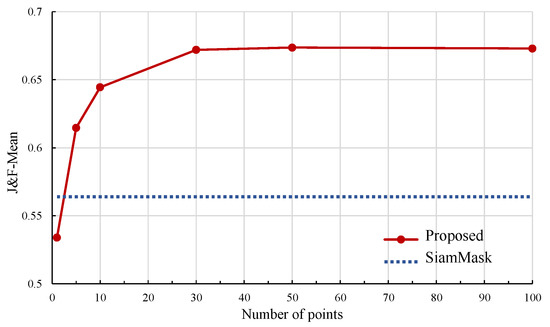
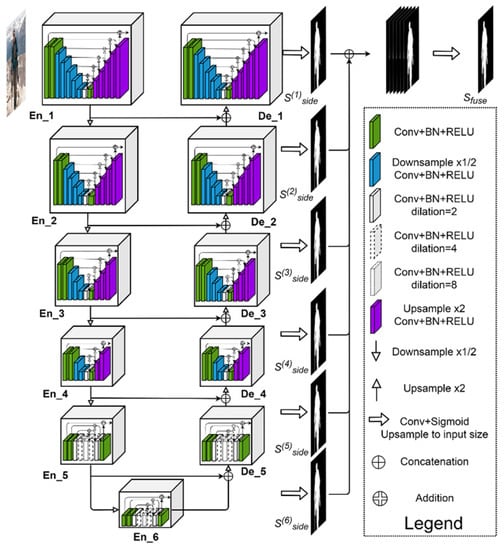
Sequential Clique Optimization for Unsupervised and Weakly Supervised Video Object Segmentation
by
Yeong Jun Koh, Yuk Heo and Chang-Su Kim
Cited by 1 | Viewed by 2213
Abstract
A novel video object segmentation algorithm, which segments out multiple objects in a video sequence in unsupervised or weakly supervised manners, is proposed in this work. First, we match visually important object instances to construct salient object tracks through a video sequence without
[...] Read more.
A novel video object segmentation algorithm, which segments out multiple objects in a video sequence in unsupervised or weakly supervised manners, is proposed in this work. First, we match visually important object instances to construct salient object tracks through a video sequence without any user supervision. We formulate this matching process as the problem to find maximal weight cliques in a complete
k-partite graph and develop the sequential clique optimization algorithm to determine the cliques efficiently. Then, we convert the resultant salient object tracks into object segmentation results and refine them based on Markov random field optimization. Second, we adapt the sequential clique optimization algorithm to perform weakly supervised video object segmentation. To this end, we develop a sparse-to-dense network to convert the point cliques into segmentation results. The experimental results demonstrate that the proposed algorithm provides comparable or better performances than recent state-of-the-art VOS algorithms.
Full article
►▼
Show Figures
Open AccessArticle
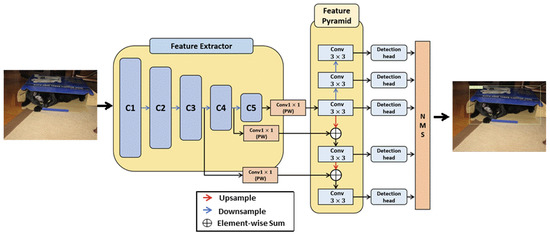
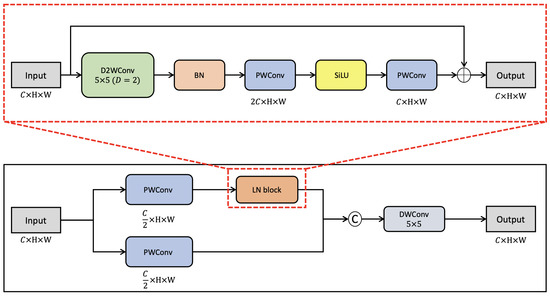
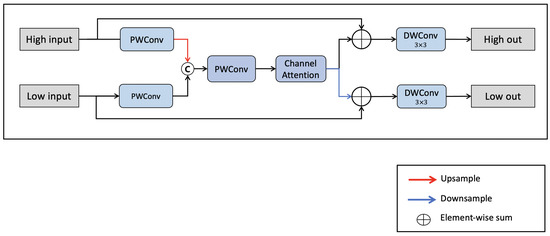
LNFCOS: Efficient Object Detection through Deep Learning Based on LNblock
by
Beomyeon Hwang, Sanghun Lee and Hyunho Han
Cited by 11 | Viewed by 3361
Abstract
In recent deep-learning-based real-time object detection methods, the trade-off between accuracy and computational cost is an important consideration. Therefore, based on the fully convolutional one-stage detector (FCOS), which is a one-stage object detection method, we propose a light next FCOS (LNFCOS) that achieves
[...] Read more.
In recent deep-learning-based real-time object detection methods, the trade-off between accuracy and computational cost is an important consideration. Therefore, based on the fully convolutional one-stage detector (FCOS), which is a one-stage object detection method, we propose a light next FCOS (LNFCOS) that achieves an optimal trade-off between computational cost and accuracy. In LNFCOS, the loss of low- and high-level information is minimized by combining the features of different scales through the proposed feature fusion module. Moreover, the light next block (LNblock) is proposed for efficient feature extraction. LNblock performs feature extraction with a low computational cost compared with standard convolutions, through sequential operation on a small amount of spatial and channel information. To define the optimal parameters of LNFCOS suggested through experiments and for a fair comparison, experiments and evaluations were conducted on the publicly available benchmark datasets MSCOCO and PASCAL VOC. Additionally, the average precision (AP) was used as an evaluation index for quantitative evaluation. LNFCOS achieved an optimal trade-off between computational cost and accuracy by achieving a detection accuracy of 79.3 AP and 37.2 AP on the MS COCO and PASCAL VOC datasets, respectively, with 36% lower computational cost than the FCOS.
Full article
►▼
Show Figures
Open AccessArticle
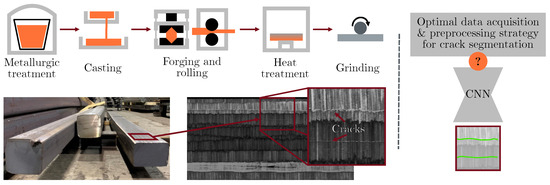
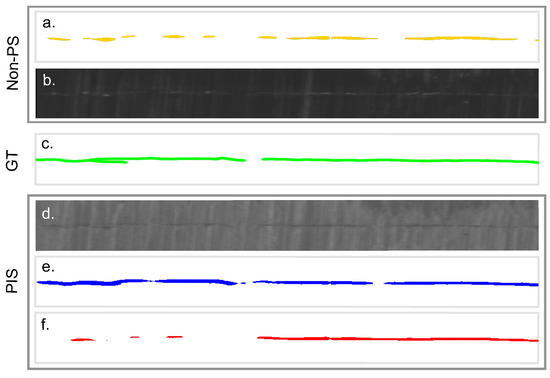
Industry-Fit AI Usage for Crack Detection in Ground Steel
by
Daniel Soukup, Christian Kapeller, Bernhard Raml and Johannes Ruisz
Cited by 2 | Viewed by 3115
Abstract
We investigated optimal implementation strategies for industrial inspection systems aiming to detect cracks on ground steel billets’ surfaces by combining state-of-the-art AI-based methods and classical computational imaging techniques. In 2D texture images, the interesting patterns of surface irregularities are often surrounded by visual
[...] Read more.
We investigated optimal implementation strategies for industrial inspection systems aiming to detect cracks on ground steel billets’ surfaces by combining state-of-the-art AI-based methods and classical computational imaging techniques. In 2D texture images, the interesting patterns of surface irregularities are often surrounded by visual clutter, which is to be ignored, e.g., grinding patterns. Even neural networks struggle to reliably distinguish between actual surface disruptions and irrelevant background patterns. Consequently, the image acquisition procedure already has to be optimised to the specific application. In our case, we use photometric stereo (PS) imaging to generate 3D surface models of steel billets using multiple illumination units. However, we demonstrate that the neural networks, especially in high-speed scenarios, still suffer from recognition deficiencies when using raw photometric stereo camera data, and are unable to generalise to new billets and image acquisition conditions. Only the additional application of adequate state-of-the-art image processing algorithms guarantees the best results in both aspects. The neural networks benefit when appropriate image acquisition methods together with image processing algorithms emphasise relevant surface structures and reduce overall pattern variation. Our proposed combined strategy shows a 9.25% better detection rate on validation data and is 14.7% better on test data, displaying the best generalisation.
Full article
►▼
Show Figures
Open AccessArticle
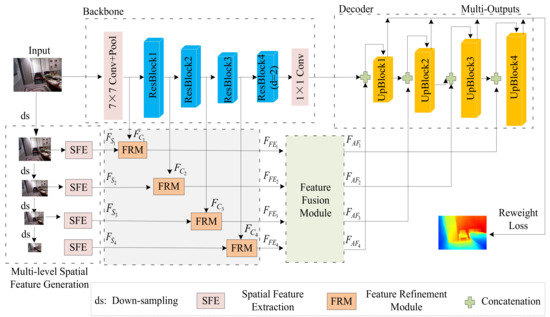
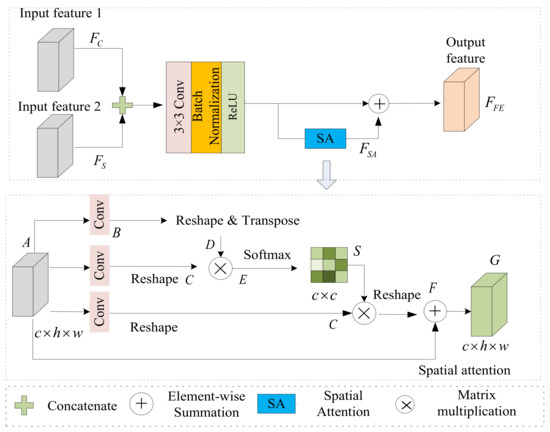
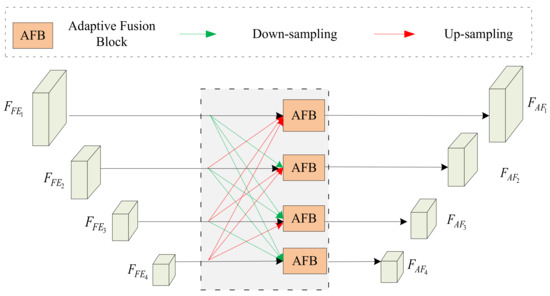
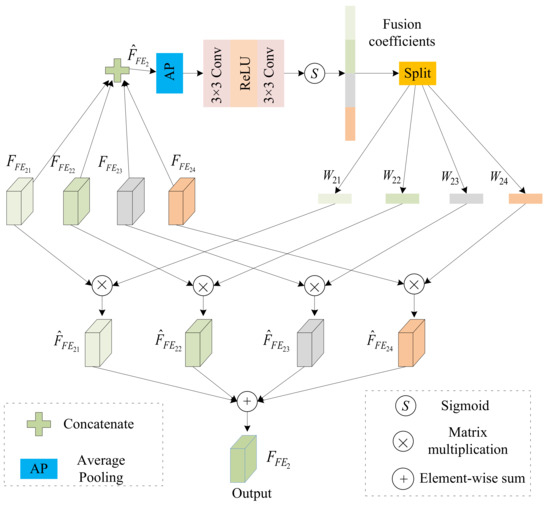
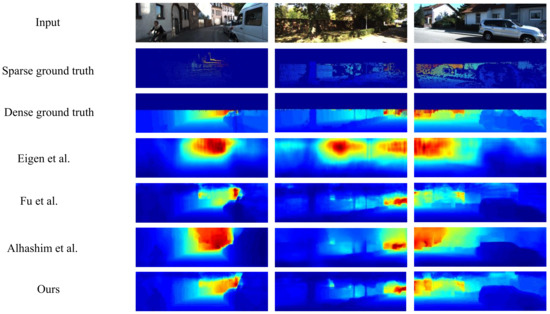
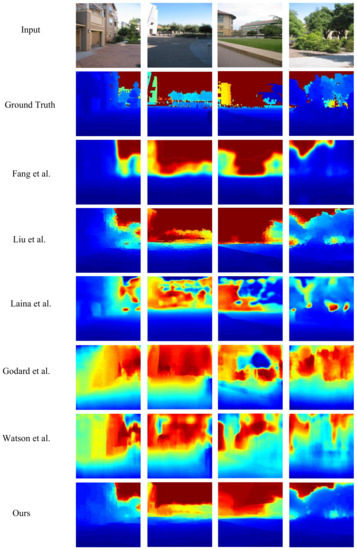
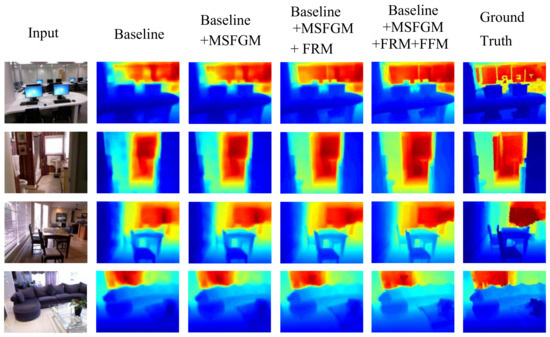
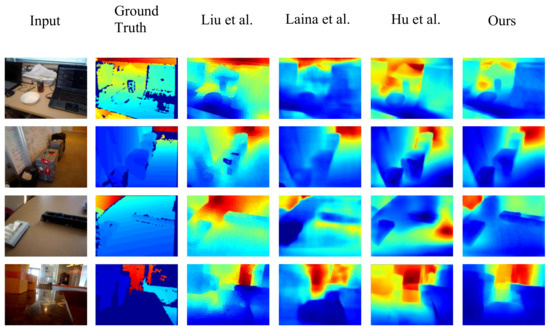
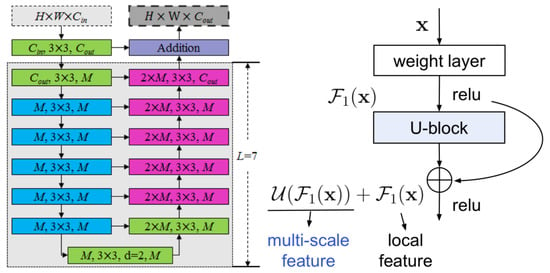
Multilevel Pyramid Network for Monocular Depth Estimation Based on Feature Refinement and Adaptive Fusion
by
Huihui Xu and Fei Li
Cited by 4 | Viewed by 3155
Abstract
As a traditional computer vision task, monocular depth estimation plays an essential role in novel view 3D reconstruction and augmented reality. Convolutional neural network (CNN)-based models have achieved good performance for this task. However, in the depth map recovered by some existing deep
[...] Read more.
As a traditional computer vision task, monocular depth estimation plays an essential role in novel view 3D reconstruction and augmented reality. Convolutional neural network (CNN)-based models have achieved good performance for this task. However, in the depth map recovered by some existing deep learning-based methods, local details are still lost. To generate convincing depth maps with rich local details, this study proposes an efficient multilevel pyramid network for monocular depth estimation based on feature refinement and adaptive fusion. Specifically, a multilevel spatial feature generation scheme is developed to extract rich features from the spatial branch. Then, a feature refinement module that combines and enhances these multilevel contextual and spatial information is designed to derive detailed information. In addition, we design an adaptive fusion block for improving the capability of fully connected features. The performance evaluation results on public RGBD datasets indicate that the proposed approach can recover reasonable depth outputs with better details and outperform several depth recovery algorithms from a qualitative and quantitative perspective.
Full article
►▼
Show Figures
Open AccessArticle
Online Learning for Reference-Based Super-Resolution
by
Byungjoo Chae, Jinsun Park, Tae-Hyun Kim and Donghyeon Cho
Cited by 3 | Viewed by 3576
Abstract
Online learning is a method for exploiting input data to update deep networks in the test stage to derive potential performance improvement. Existing online learning methods for single-image super-resolution (SISR) utilize an input low-resolution (LR) image for the online adaptation of deep networks.
[...] Read more.
Online learning is a method for exploiting input data to update deep networks in the test stage to derive potential performance improvement. Existing online learning methods for single-image super-resolution (SISR) utilize an input low-resolution (LR) image for the online adaptation of deep networks. Unlike SISR approaches, reference-based super-resolution (RefSR) algorithms benefit from an additional high-resolution (HR) reference image containing plenty of useful features for enhancing the input LR image. Therefore, we introduce a new online learning algorithm, using several reference images, which is applicable to not only RefSR but also SISR networks. Experimental results show that our online learning method is seamlessly applicable to many existing RefSR and SISR models, and that improves performance. We further present the robustness of our method to non-bicubic degradation kernels with in-depth analyses.
Full article
►▼
Show Figures
Open AccessArticle
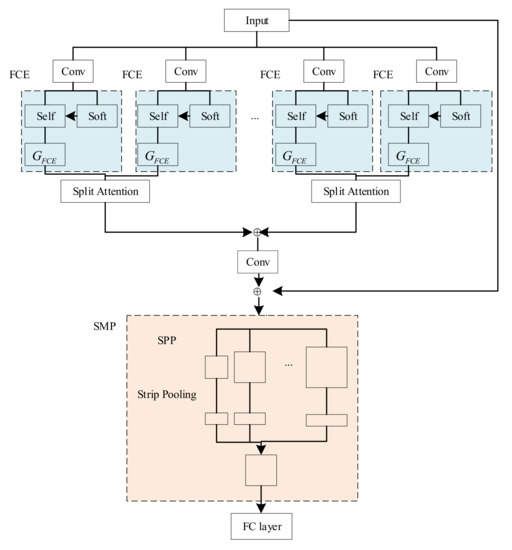
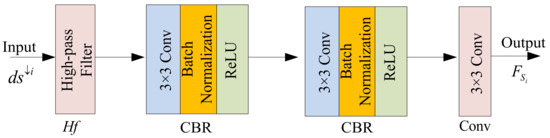
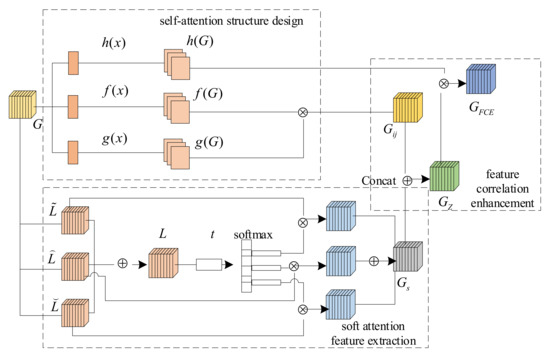
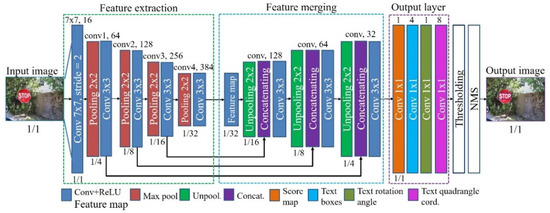
Mathematical Formula Image Screening Based on Feature Correlation Enhancement
by
Hongyuan Liu, Fang Yang, Xue Wang and Jianhui Si
Cited by 2 | Viewed by 4405
Abstract
There are mathematical formula images or other images in scientific and technical documents or on web pages, and mathematical formula images are classified as either containing only mathematical formulas or formulas interspersed with other elements, such as text and coordinate diagrams. To screen
[...] Read more.
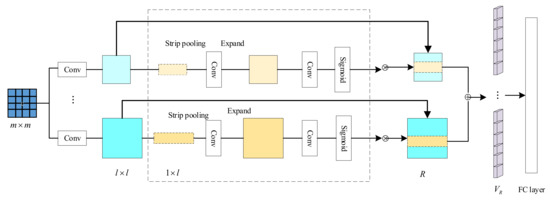
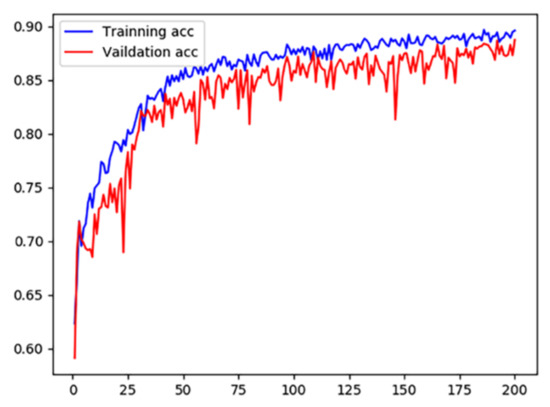
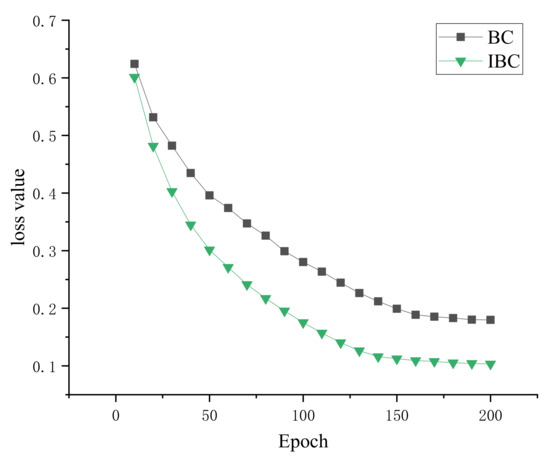
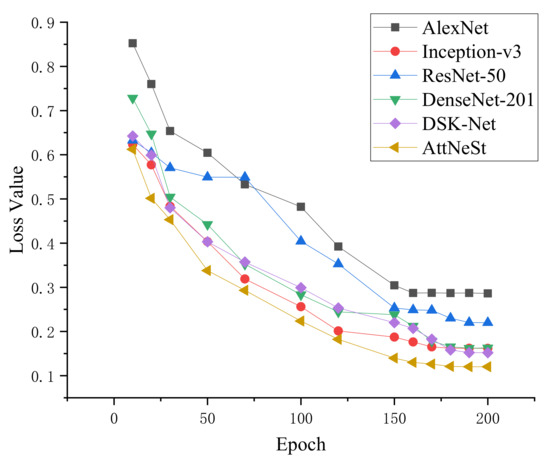
There are mathematical formula images or other images in scientific and technical documents or on web pages, and mathematical formula images are classified as either containing only mathematical formulas or formulas interspersed with other elements, such as text and coordinate diagrams. To screen and collect images containing mathematical formulas for others to study or for further research, a model for screening images of mathematical formulas based on feature correlation enhancement is proposed. First, the Feature Correlation Enhancement (FCE) module was designed to improve the correlation degree of mathematical formula features and weaken other features. Then, the strip multi-scale pooling (SMP) module was designed to solve the problem of non-uniform image size, while enhancing the focus on horizontal formula features. Finally, the loss function was improved to balance the dataset. The accuracy of the experiment was 89.50%, which outperformed the existing model. Using the model to screen images enables the user to screen out images containing mathematical formulas. The screening of images containing mathematical formulas helps to speed up the creation of a database of mathematical formula images.
Full article
►▼
Show Figures
Open AccessArticle
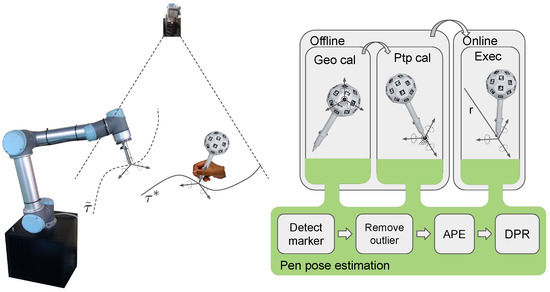
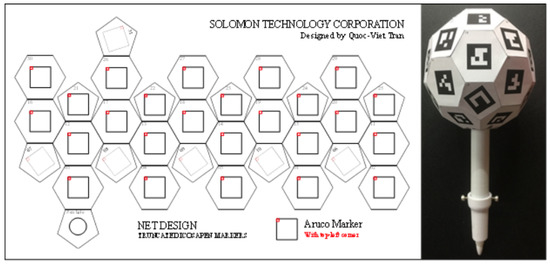
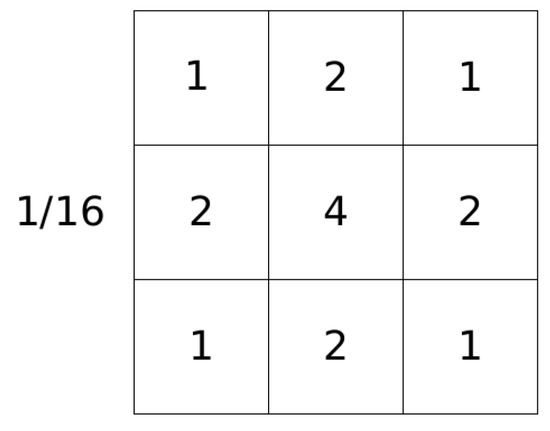
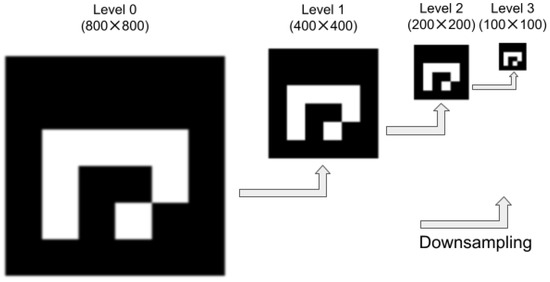
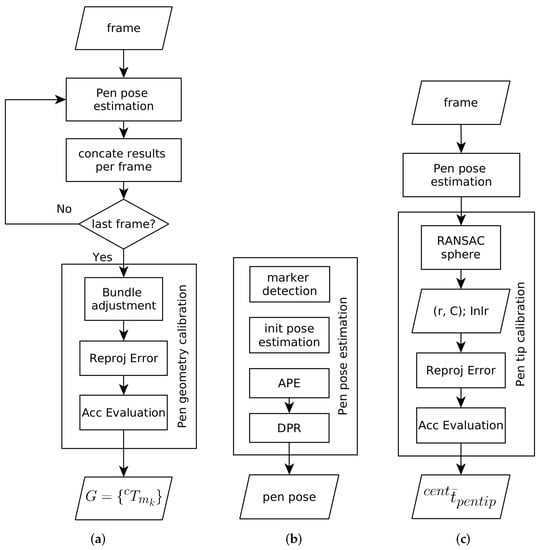
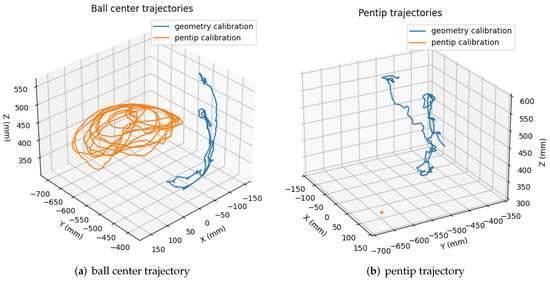
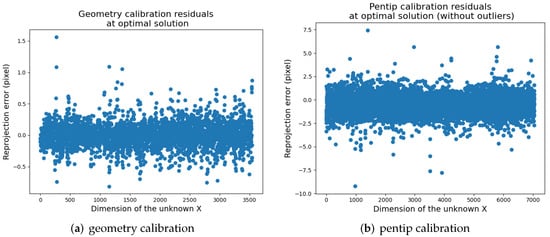
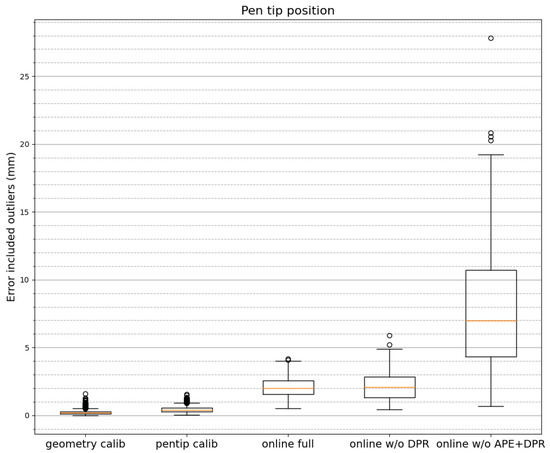
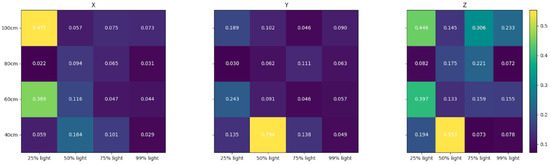
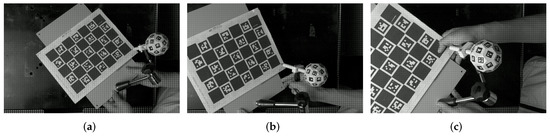
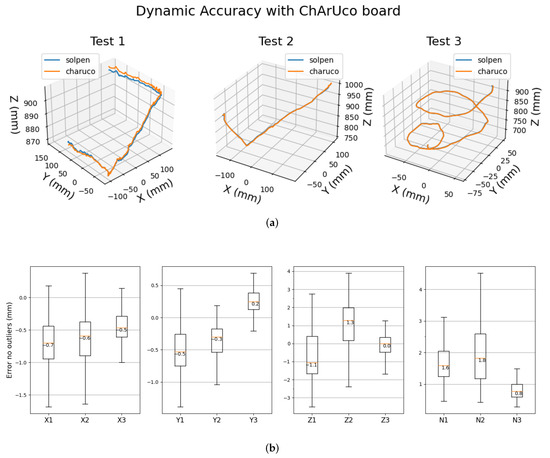
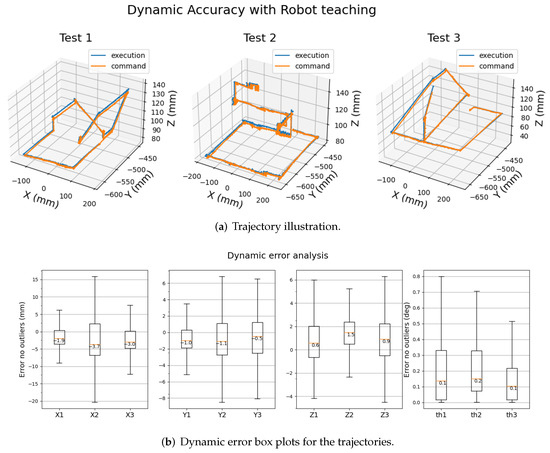
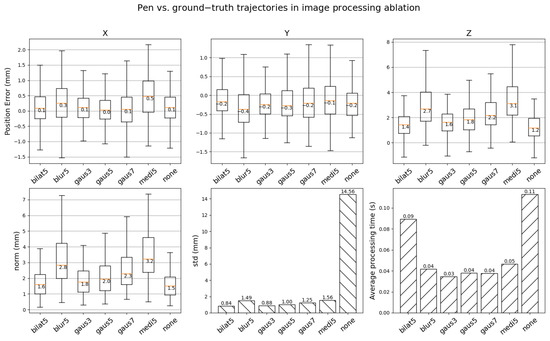
Solpen: An Accurate 6-DOF Positioning Tool for Vision-Guided Robotics
by
Trung-Son Le, Quoc-Viet Tran, Xuan-Loc Nguyen and Chyi-Yeu Lin
Cited by 10 | Viewed by 6908
Abstract
A robot trajectory teaching system with a vision-based positioning pen, which we called Solpen, is developed to generate pose paths of six degrees of freedom (6-DoF) for vision-guided robotics applications such as welding, cutting, painting, or polishing, which can achieve a millimeter dynamic
[...] Read more.
A robot trajectory teaching system with a vision-based positioning pen, which we called Solpen, is developed to generate pose paths of six degrees of freedom (6-DoF) for vision-guided robotics applications such as welding, cutting, painting, or polishing, which can achieve a millimeter dynamic accuracy within a meter working distance from the camera. The system is simple and requires only a 2D camera and the printed ArUco markers which are hand-glued on 31 surfaces of the designed 3D-printed Solpen. Image processing techniques are implemented to remove noise and sharpen the edge of the ArUco images and also enhance the contrast of the ArUco edge intensity generated by the pyramid reconstruction. In addition, the least squares method is implemented to optimize parameters for the center pose of the truncated Icosahedron center, and the vector of the Solpen-tip. From dynamic experiments conducted with ChArUco board to verify exclusively the pen performance, the developed system is robust within its working range, and achieves a minimum axis-accuracy at approximately 0.8 mm.
Full article
►▼
Show Figures
Open AccessArticle
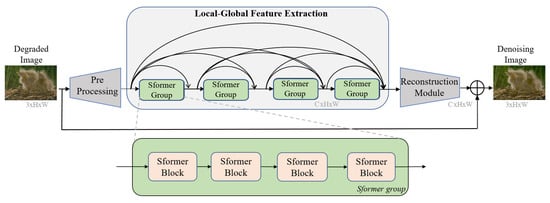
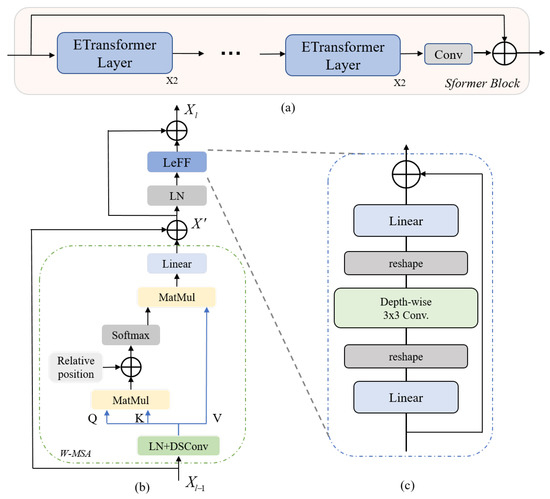
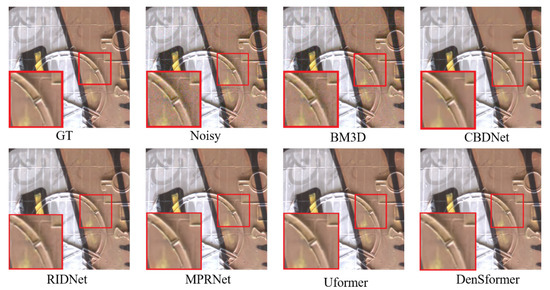
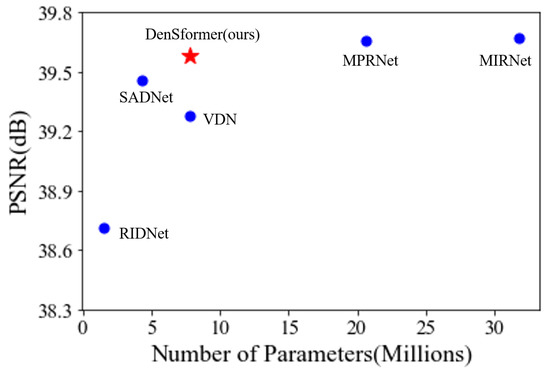
Dense Residual Transformer for Image Denoising
by
Chao Yao, Shuo Jin, Meiqin Liu and Xiaojuan Ban
Cited by 36 | Viewed by 7135
Abstract
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising,
[...] Read more.
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. In synthetic noise removal, DenSformer outperforms other state-of-the-art methods by up to 0.06–0.28 dB in gray-scale images and 0.57–1.19 dB in color images. In real noise removal, DenSformer can achieve comparable performance, while the number of parameters can be reduced by up to 40%. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.
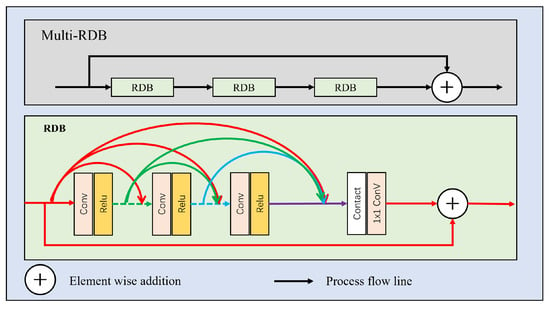
Full article
►▼
Show Figures
Open AccessArticle
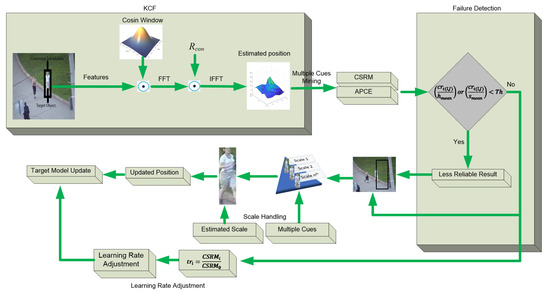
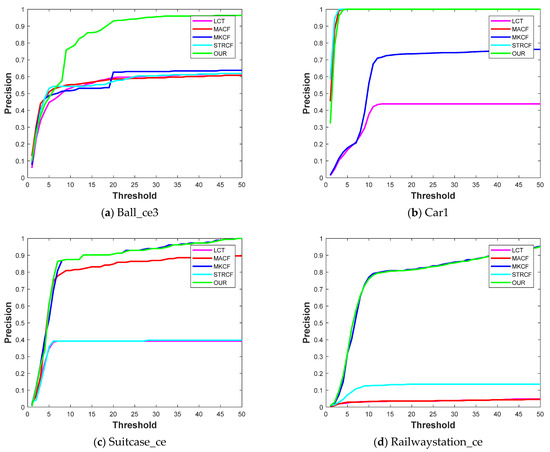
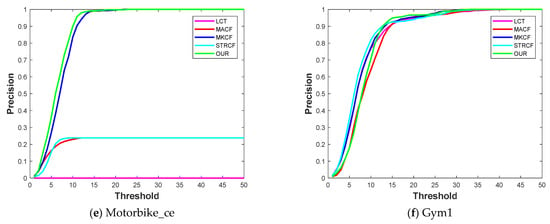
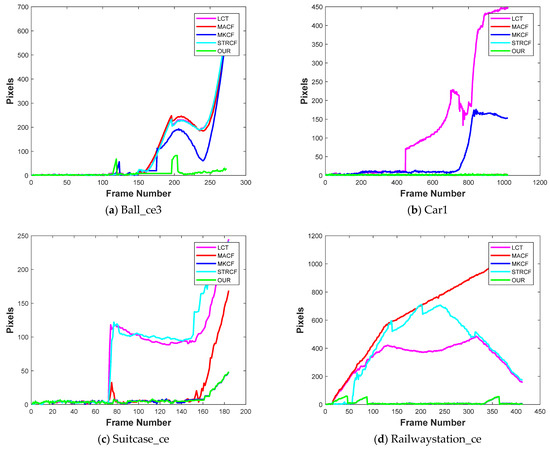
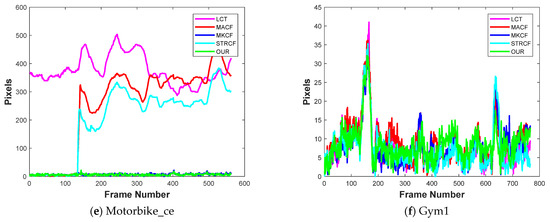
Multiple Cues-Based Robust Visual Object Tracking Method
by
Baber Khan, Abdul Jalil, Ahmad Ali, Khaled Alkhaledi, Khizer Mehmood, Khalid Mehmood Cheema, Maria Murad, Hanan Tariq and Ahmed M. El-Sherbeeny
Cited by 7 | Viewed by 4001
Abstract
Visual object tracking is still considered a challenging task in computer vision research society. The object of interest undergoes significant appearance changes because of illumination variation, deformation, motion blur, background clutter, and occlusion. Kernelized correlation filter- (KCF) based tracking schemes have shown good
[...] Read more.
Visual object tracking is still considered a challenging task in computer vision research society. The object of interest undergoes significant appearance changes because of illumination variation, deformation, motion blur, background clutter, and occlusion. Kernelized correlation filter- (KCF) based tracking schemes have shown good performance in recent years. The accuracy and robustness of these trackers can be further enhanced by incorporating multiple cues from the response map. Response map computation is the complementary step in KCF-based tracking schemes, and it contains a bundle of information. The majority of the tracking methods based on KCF estimate the target location by fetching a single cue-like peak correlation value from the response map. This paper proposes to mine the response map in-depth to fetch multiple cues about the target model. Furthermore, a new criterion based on the hybridization of multiple cues i.e., average peak correlation energy (APCE) and confidence of squared response map (CSRM), is presented to enhance the tracking efficiency. We update the following tracking modules based on hybridized criterion: (i) occlusion detection, (ii) adaptive learning rate adjustment, (iii) drift handling using adaptive learning rate, (iv) handling, and (v) scale estimation. We integrate all these modules to propose a new tracking scheme. The proposed tracker is evaluated on challenging videos selected from three standard datasets, i.e., OTB-50, OTB-100, and TC-128. A comparison of the proposed tracking scheme with other state-of-the-art methods is also presented in this paper. Our method improved considerably by achieving a center location error of 16.06, distance precision of 0.889, and overlap success rate of 0.824.
Full article
►▼
Show Figures
Open AccessArticle
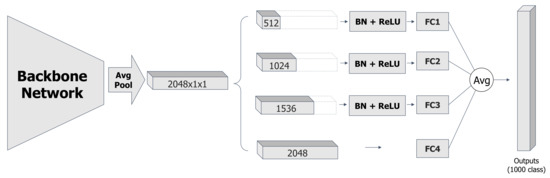
Exploiting Features with Split-and-Share Module
by
Jae-Min Lee, Min-Seok Seo, Dae-Han Kim, Sang-Woo Lee, Jong-Chan Park and Dong-Geol Choi
Viewed by 2489
Abstract
Deep convolutional neural networks (CNNs) have shown state-of-the-art performances in various computer vision tasks. Advances on CNN architectures have focused mainly on designing convolutional blocks of the feature extractors, but less on the classifiers that exploit extracted features. In this work, we propose
[...] Read more.
Deep convolutional neural networks (CNNs) have shown state-of-the-art performances in various computer vision tasks. Advances on CNN architectures have focused mainly on designing convolutional blocks of the feature extractors, but less on the classifiers that exploit extracted features. In this work, we propose Split-and-Share Module (SSM), a classifier that splits a given feature into parts, which are partially shared by multiple sub-classifiers. Our intuition is that the more the features are shared, the more common they will become, and SSM can encourage such structural characteristics in the split features. SSM can be easily integrated into any architecture without bells and whistles. We have extensively validated the efficacy of SSM on ImageNet-1K classification task, and SSM has shown consistent and significant improvements over baseline architectures. In addition, we analyze the effect of SSM using the Grad-CAM visualization.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
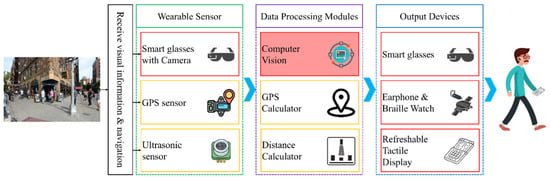
Smart Glass System Using Deep Learning for the Blind and Visually Impaired
by
Mukhriddin Mukhiddinov and Jinsoo Cho
Cited by 118 | Viewed by 37959
Abstract
Individuals suffering from visual impairments and blindness encounter difficulties in moving independently and overcoming various problems in their routine lives. As a solution, artificial intelligence and computer vision approaches facilitate blind and visually impaired (BVI) people in fulfilling their primary activities without much
[...] Read more.
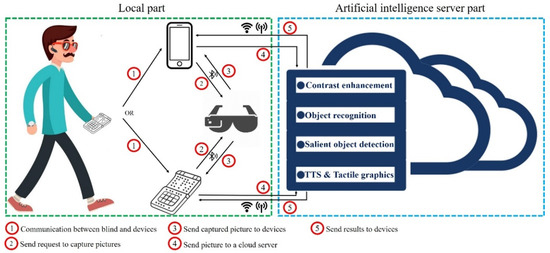
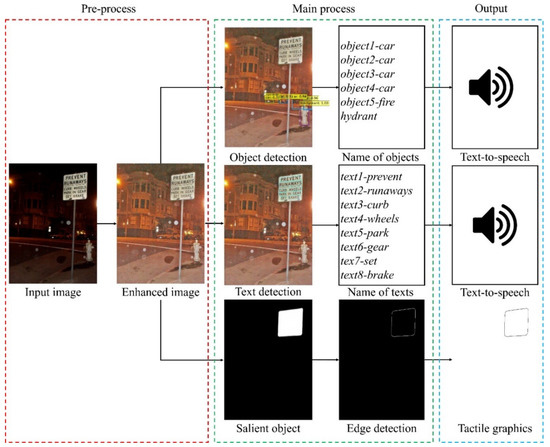
Individuals suffering from visual impairments and blindness encounter difficulties in moving independently and overcoming various problems in their routine lives. As a solution, artificial intelligence and computer vision approaches facilitate blind and visually impaired (BVI) people in fulfilling their primary activities without much dependency on other people. Smart glasses are a potential assistive technology for BVI people to aid in individual travel and provide social comfort and safety. However, practically, the BVI are unable move alone, particularly in dark scenes and at night. In this study we propose a smart glass system for BVI people, employing computer vision techniques and deep learning models, audio feedback, and tactile graphics to facilitate independent movement in a night-time environment. The system is divided into four models: a low-light image enhancement model, an object recognition and audio feedback model, a salient object detection model, and a text-to-speech and tactile graphics generation model. Thus, this system was developed to assist in the following manner: (1) enhancing the contrast of images under low-light conditions employing a two-branch exposure-fusion network; (2) guiding users with audio feedback using a transformer encoder–decoder object detection model that can recognize 133 categories of sound, such as people, animals, cars, etc., and (3) accessing visual information using salient object extraction, text recognition, and refreshable tactile display. We evaluated the performance of the system and achieved competitive performance on the challenging Low-Light and ExDark datasets.
Full article
►▼
Show Figures
Open AccessArticle
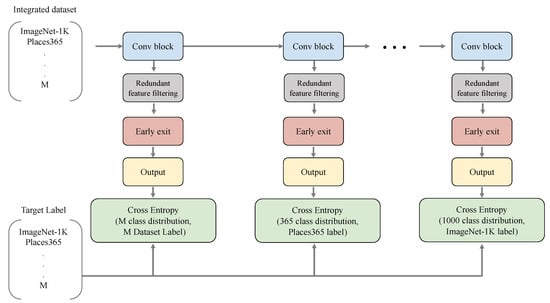
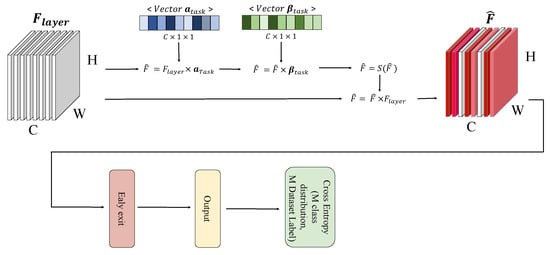
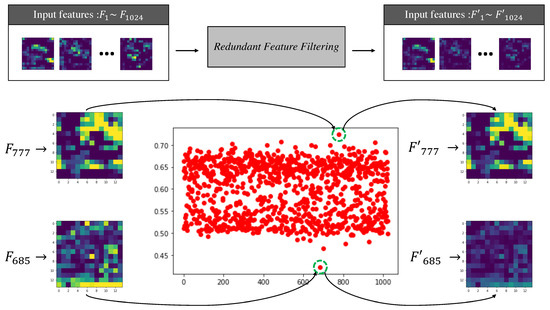
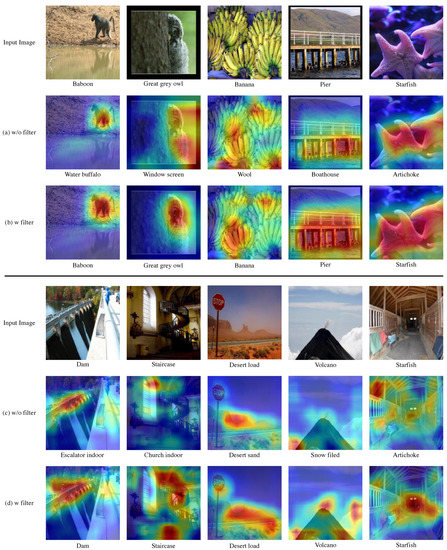
Multi-Task Learning with Task-Specific Feature Filtering in Low-Data Condition
by
Sang-woo Lee, Ryong Lee, Min-seok Seo, Jong-chan Park, Hyeon-cheol Noh, Jin-gi Ju, Rae-young Jang, Gun-woo Lee, Myung-seok Choi and Dong-geol Choi
Cited by 5 | Viewed by 4424
Abstract
Multi-task learning is a computationally efficient method to solve multiple tasks in one multi-task model, instead of multiple single-task models. MTL is expected to learn both diverse and shareable visual features from multiple datasets. However, MTL performances usually do not outperform single-task learning.
[...] Read more.
Multi-task learning is a computationally efficient method to solve multiple tasks in one multi-task model, instead of multiple single-task models. MTL is expected to learn both diverse and shareable visual features from multiple datasets. However, MTL performances usually do not outperform single-task learning. Recent MTL methods tend to use heavy task-specific heads with large overheads to generate task-specific features. In this work, we (1) validate the efficacy of MTL in low-data conditions with early-exit architectures, and (2) propose a simple feature filtering module with minimal overheads to generate task-specific features. We assume that, in low-data conditions, the model cannot learn useful low-level features due to the limited amount of data. We empirically show that MTL can significantly improve performances in all tasks under low-data conditions. We further optimize the early-exit architecture by a sweep search on the optimal feature for each task. Furthermore, we propose a feature filtering module that selects features for each task. Using the optimized early-exit architecture with the feature filtering module, we improve the 15.937% in ImageNet and 4.847% in Places365 under the low-data condition where only 5% of the original datasets are available. Our method is empirically validated in various backbones and various MTL settings.
Full article
►▼
Show Figures
Open AccessArticle
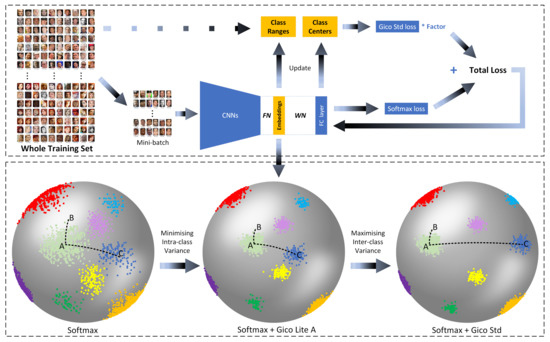
GicoFace: A Deep Face Recognition Model Based on Global-Information Loss Function
by
Xin Wei, Wei Du, Xiaoping Hu, Jie Huang and Weidong Min
Viewed by 3615
Abstract
As CNNs have a strong capacity to learn discriminative facial features, CNNs have greatly promoted the development of face recognition, where the loss function plays a key role in this process. Nonetheless, most of the existing loss functions do not simultaneously apply weight
[...] Read more.
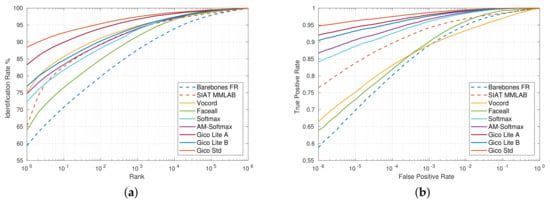
As CNNs have a strong capacity to learn discriminative facial features, CNNs have greatly promoted the development of face recognition, where the loss function plays a key role in this process. Nonetheless, most of the existing loss functions do not simultaneously apply weight normalization, apply feature normalization and follow the two goals of enhancing the discriminative capacity (optimizing intra-class/inter-class variance). In addition, they are updated by only considering the feedback information of each mini-batch, but ignore the information from the entire training set. This paper presents a new loss function called Gico loss. The deep model trained with Gico loss in this paper is then called GicoFace. Gico loss satisfies the four aforementioned key points, and is calculated with the global information extracted from the entire training set. The experiments are carried out on five benchmark datasets including LFW, SLLFW, YTF, MegaFace and FaceScrub. Experimental results confirm the efficacy of the proposed method and show the state-of-the-art performance of the method.
Full article
►▼
Show Figures
Open AccessArticle
Aircraft Type Recognition in Remote Sensing Images: Bilinear Discriminative Extreme Learning Machine Framework
by
Baojun Zhao, Wei Tang, Yu Pan, Yuqi Han and Wenzheng Wang
Cited by 15 | Viewed by 4352
Abstract
Small inter-class and massive intra-class changes are important challenges in aircraft model recognition in the field of remote sensing. Although the aircraft model recognition algorithm based on the convolutional neural network (CNN) has excellent recognition performance, it is limited by sample sets and
[...] Read more.
Small inter-class and massive intra-class changes are important challenges in aircraft model recognition in the field of remote sensing. Although the aircraft model recognition algorithm based on the convolutional neural network (CNN) has excellent recognition performance, it is limited by sample sets and computing resources. To solve the above problems, we propose the bilinear discriminative extreme learning machine (ELM) network (BD-ELMNet), which integrates the advantages of the CNN, autoencoder (AE), and ELM. Specifically, the BD-ELMNet first executes the convolution and pooling operations to form a convolutional ELM (ELMConvNet) to extract shallow features. Furthermore, the manifold regularized ELM-AE (MRELM-AE), which can simultaneously consider the geometrical structure and discriminative information of aircraft data, is developed to extract discriminative features. The bilinear pooling model uses the feature association information for feature fusion to enhance the substantial distinction of features. Compared with the backpropagation (BP) optimization method, BD-ELMNet adopts a layer-by-layer training method without repeated adjustments to effectively learn discriminant features. Experiments involving the application of several methods, including the proposed method, to the MTARSI benchmark demonstrate that the proposed aircraft type recognition method outperforms the state-of-the-art methods.
Full article
►▼
Show Figures
Open AccessArticle
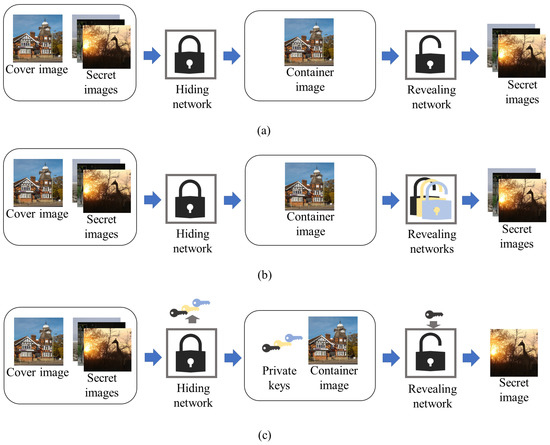
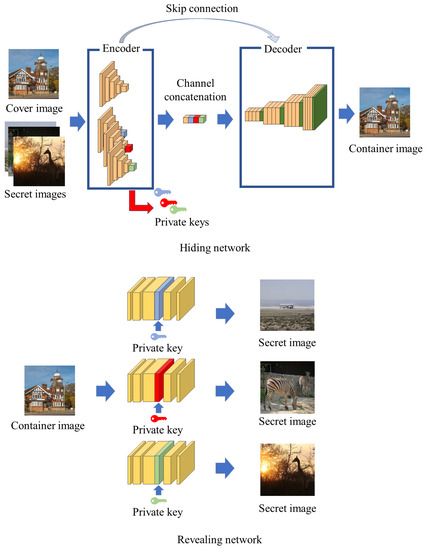
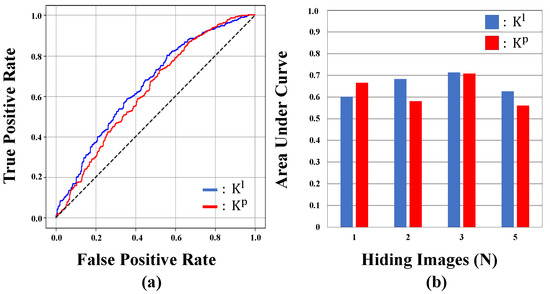
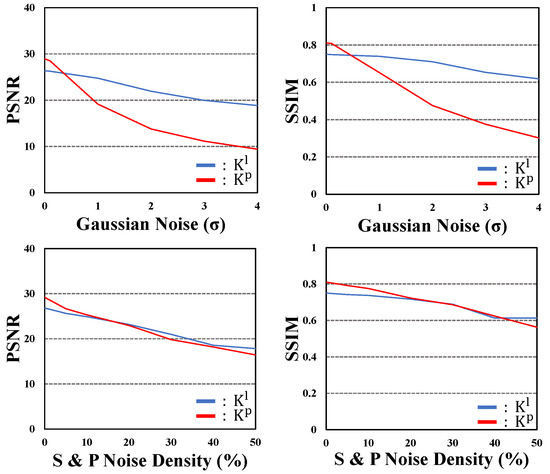
Deep Multi-Image Steganography with Private Keys
by
Hyeokjoon Kweon, Jinsun Park, Sanghyun Woo and Donghyeon Cho
Cited by 12 | Viewed by 6127
Abstract
In this paper, we propose deep multi-image steganography with private keys. Recently, several deep CNN-based algorithms have been proposed to hide multiple secret images in a single cover image. However, conventional methods are prone to the leakage of secret information because they do
[...] Read more.
In this paper, we propose deep multi-image steganography with private keys. Recently, several deep CNN-based algorithms have been proposed to hide multiple secret images in a single cover image. However, conventional methods are prone to the leakage of secret information because they do not provide access to an individual secret image and often decrypt the entire hidden information all at once. To tackle the problem, we introduce the concept of private keys for secret images. Our method conceals multiple secret images in a single cover image and generates a visually similar container image containing encrypted secret information inside. In addition, private keys corresponding to each secret image are generated simultaneously. Each private key provides access to only a single secret image while keeping the other hidden images and private keys unrevealed. In specific, our model consists of deep hiding and revealing networks. The hiding network takes a cover image and secret images as inputs and extracts high-level features of the cover image and generates private keys. After that, the extracted features and private keys are concatenated and used to generate a container image. On the other hand, the revealing network extracts high-level features of the container image and decrypts a secret image using the extracted feature and a corresponding private key. Experimental results demonstrate that the proposed algorithm effectively hides and reveals multiple secret images while achieving high security.
Full article
►▼
Show Figures
Open AccessArticle
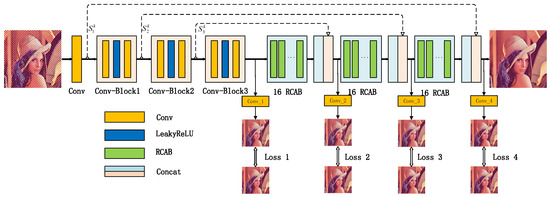
An Efficient Convolutional Neural Network Model Combined with Attention Mechanism for Inverse Halftoning
by
Linhao Shao, Erhu Zhang and Mei Li
Cited by 14 | Viewed by 3579
Abstract
Inverse halftoning acting as a special image restoration problem is an ill-posed problem. Although it has been studied in the last several decades, the existing solutions can’t restore fine details and texture accurately from halftone images. Recently, the attention mechanism has shown its
[...] Read more.
Inverse halftoning acting as a special image restoration problem is an ill-posed problem. Although it has been studied in the last several decades, the existing solutions can’t restore fine details and texture accurately from halftone images. Recently, the attention mechanism has shown its powerful effects in many fields, such as image processing, pattern recognition and computer vision. However, it has not yet been used in inverse halftoning. To better solve the problem of detail restoration of inverse halftoning, this paper proposes a simple yet effective deep learning model combined with the attention mechanism, which can better guide the network to remove noise dot-patterns and restore image details, and improve the network adaptation ability. The whole model is designed in an end-to-end manner, including feature extraction stage and reconstruction stage. In the feature extraction stage, halftone image features are extracted and halftone noises are removed. The reconstruction stage is employed to restore continuous-tone images by fusing the feature information extracted in the first stage and the output of the residual channel attention block. In this stage, the attention block is firstly introduced to the field of inverse halftoning, which can make the network focus on informative features and further enhance the discriminative ability of the network. In addition, a multi-stage loss function is proposed to accelerate the network optimization, which is conducive to better reconstruction of the global image. To demonstrate the generalization performance of the network for different types of halftone images, the experiment results confirm that the network can restore six different types of halftone image well. Furthermore, experimental results show that our method outperforms the state-of-the-art methods, especially in the restoration of details and textures.
Full article
►▼
Show Figures
Open AccessArticle
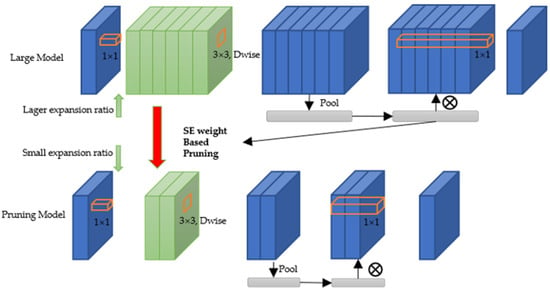
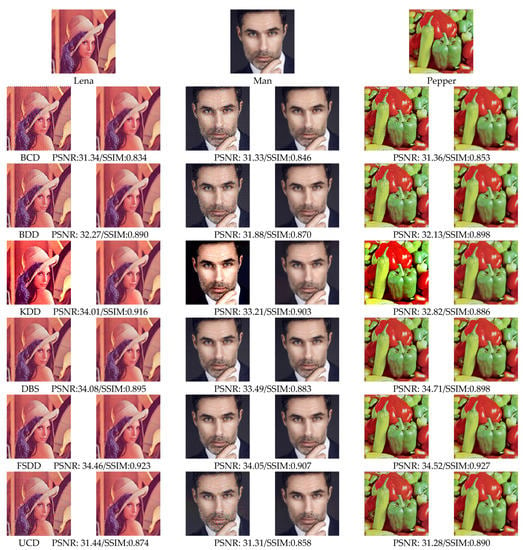
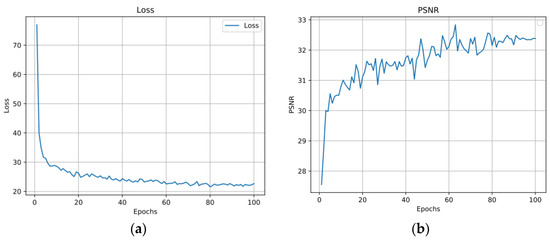
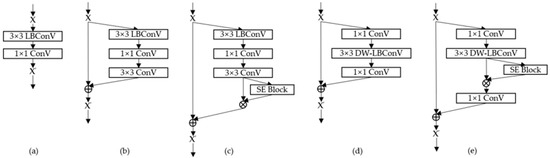
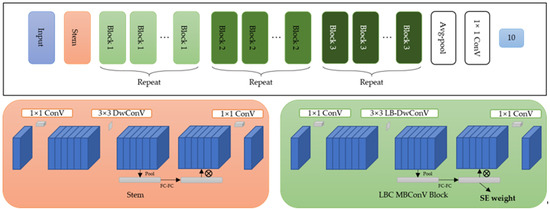
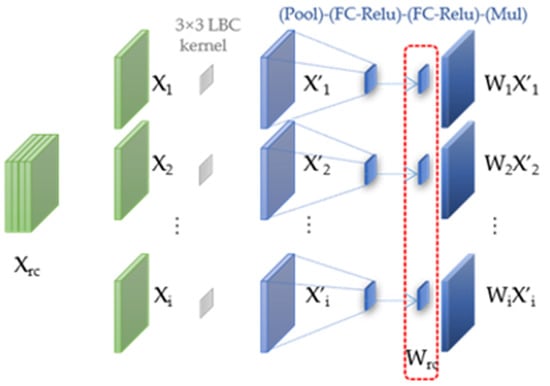
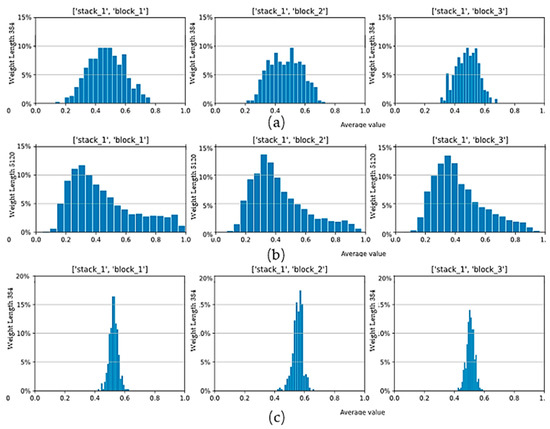
Data-Driven Channel Pruning towards Local Binary Convolution Inverse Bottleneck Network Based on Squeeze-and-Excitation Optimization Weights
by
Duo Feng and Fuji Ren
Cited by 2 | Viewed by 3536
Abstract
This paper proposed a model pruning method based on local binary convolution (LBC) and squeeze-and-excitation (SE) optimization weights. We first proposed an efficient deep separation convolution model based on the LBC kernel. By expanding the number of LBC kernels in the model, we
[...] Read more.
This paper proposed a model pruning method based on local binary convolution (LBC) and squeeze-and-excitation (SE) optimization weights. We first proposed an efficient deep separation convolution model based on the LBC kernel. By expanding the number of LBC kernels in the model, we have trained a larger model with better results, but more parameters and slower calculation speed. Then, we extract the SE optimization weight value of each SE module according to the data samples and score the LBC kernel accordingly. Based on the score of each LBC kernel corresponding to the convolution channel, we performed channel-based model pruning, which greatly reduced the number of model parameters and accelerated the calculation speed. The model pruning method proposed in this paper is verified in the image classification database. Experiments show that, in the model using the LBC kernel, as the number of LBC kernels increases, the recognition accuracy will increase. At the same time, the experiment also proved that the recognition accuracy is maintained at a similar level in the small parameter model after channel-based model pruning by the SE optimization weight value.
Full article
►▼
Show Figures
Open AccessArticle
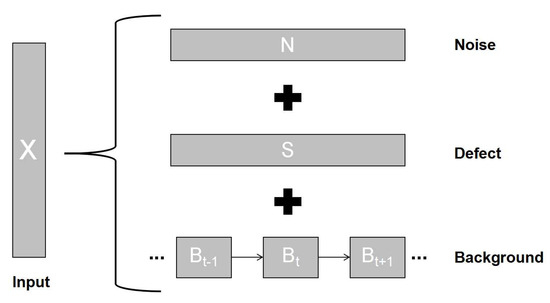
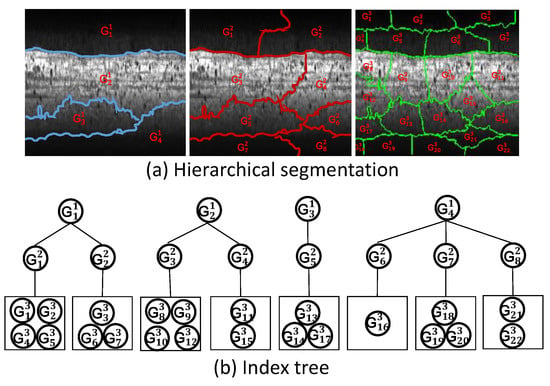
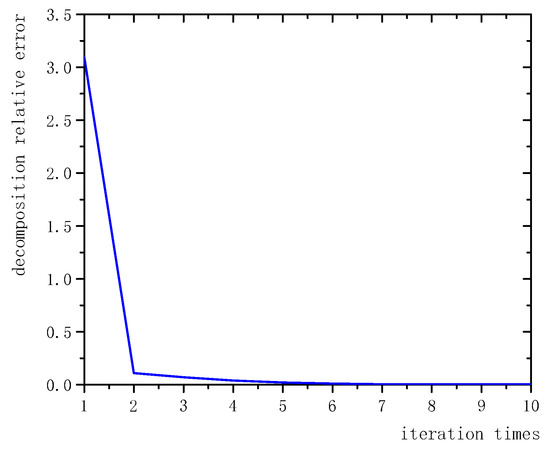
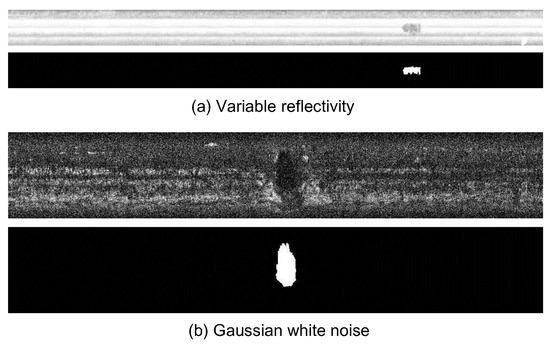
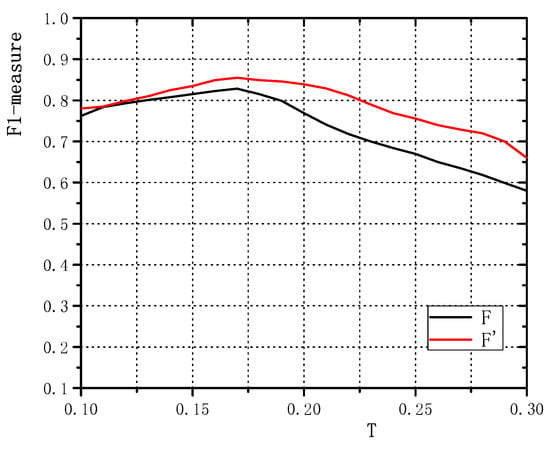
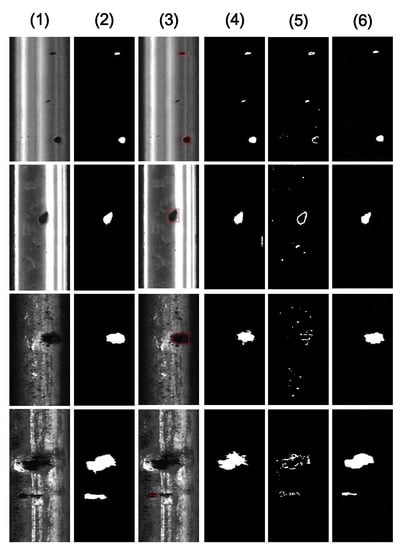
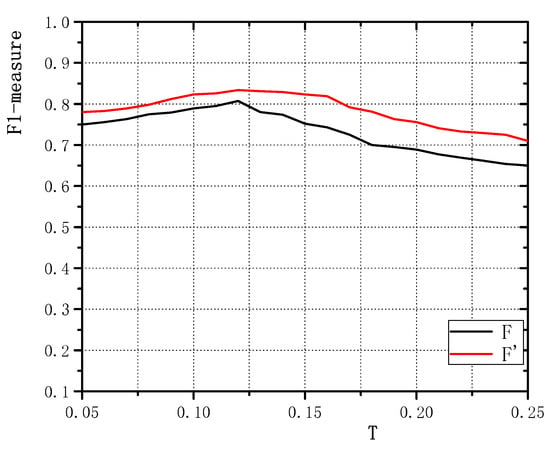
A Novel Decomposition Model for Visual Rail Surface Inspection
by
Ziwen Zhang, Mangui Liang and Zhiyu Liu
Cited by 7 | Viewed by 3421
Abstract
Rail surface inspection plays a pivotal role in large-scale railway construction and development. However, accurately identifying possible defects involving a large variety of visual appearances and their dynamic illuminations remains challenging. In this paper, we fully explore and use the essential attributes of
[...] Read more.
Rail surface inspection plays a pivotal role in large-scale railway construction and development. However, accurately identifying possible defects involving a large variety of visual appearances and their dynamic illuminations remains challenging. In this paper, we fully explore and use the essential attributes of our defect structure data and the inherent temporal and spatial characteristics of the track to establish a general theoretical framework for practical applications. As such, our framework can overcome the bottleneck associated with machine vision inspection technology in complex rail environments. In particular, we consider a differential regular term for background rather than a traditional low-rank constraint to ensure that the model can tolerate dynamic background changes without losing sensitivity when detecting defects. To better capture the compactness and completeness of a defect, we introduce a tree-shaped hierarchical structure of sparse induction norms to encode the spatial structure of the defect area. The proposed model is evaluated with respect to two newly released Type-I/II rail surfaces discrete defects (RSDD) data sets and a practical rail line. Qualitative and quantitative evaluations show that the decomposition model can handle the dynamics of the track surface well and that the model can be used for structural detection of the defect area.
Full article
►▼
Show Figures
Open AccessArticle
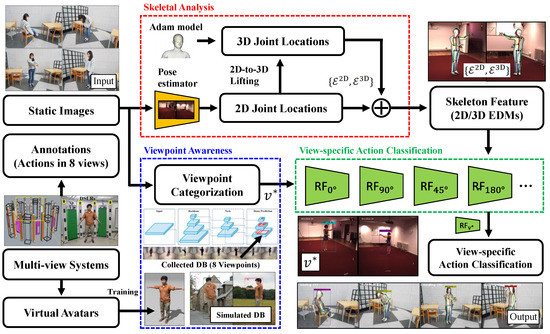
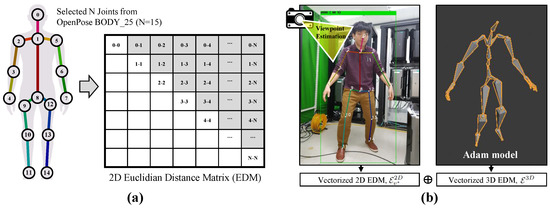
Viewpoint-Aware Action Recognition Using Skeleton-Based Features from Still Images
by
Seong-heum Kim and Donghyeon Cho
Cited by 8 | Viewed by 4845
Abstract
In this paper, we propose a viewpoint-aware action recognition method using skeleton-based features from static images. Our method consists of three main steps. First, we categorize the viewpoint from an input static image. Second, we extract 2D/3D joints using state-of-the-art convolutional neural networks
[...] Read more.
In this paper, we propose a viewpoint-aware action recognition method using skeleton-based features from static images. Our method consists of three main steps. First, we categorize the viewpoint from an input static image. Second, we extract 2D/3D joints using state-of-the-art convolutional neural networks and analyze the geometric relationships of the joints for computing 2D and 3D skeleton features. Finally, we perform view-specific action classification per person, based on viewpoint categorization and the extracted 2D and 3D skeleton features. We implement two multi-view data acquisition systems and create a new action recognition dataset containing the viewpoint labels, in order to train and validate our method. The robustness of the proposed method to viewpoint changes was quantitatively confirmed using two multi-view datasets. A real-world application for recognizing various actions was also qualitatively demonstrated.
Full article
►▼
Show Figures
Open AccessArticle
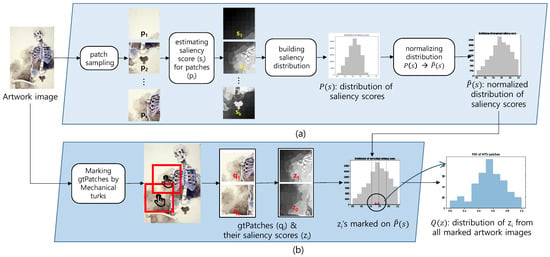
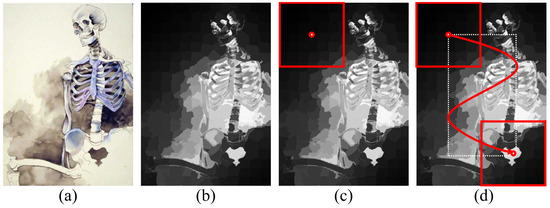
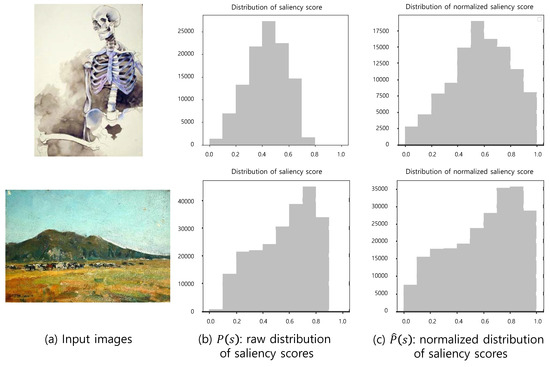
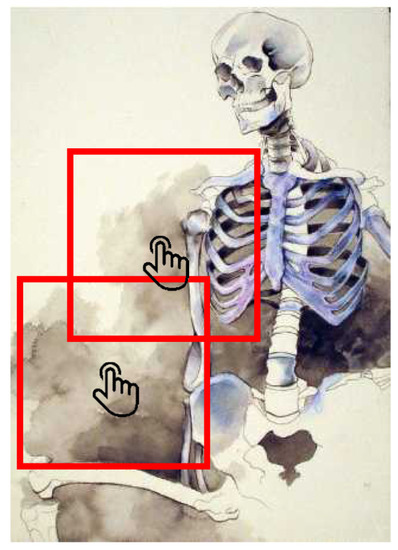
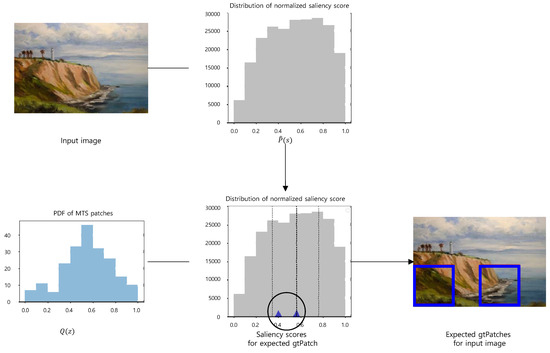
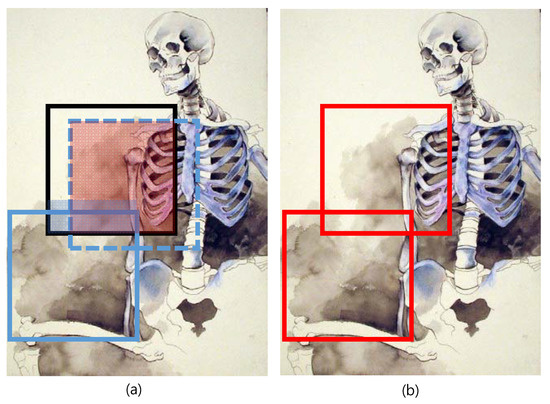
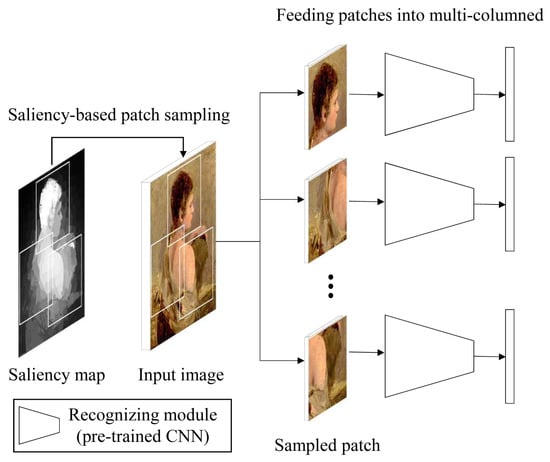
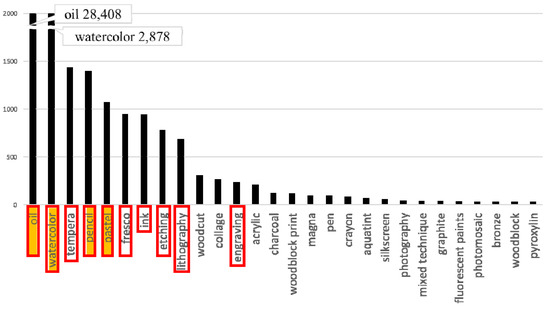
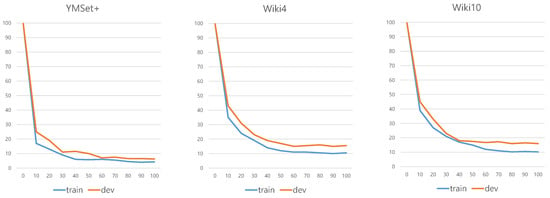
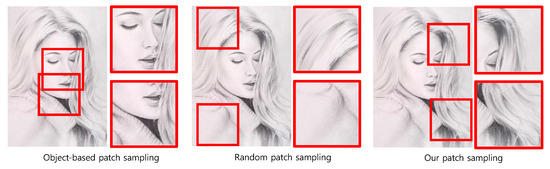
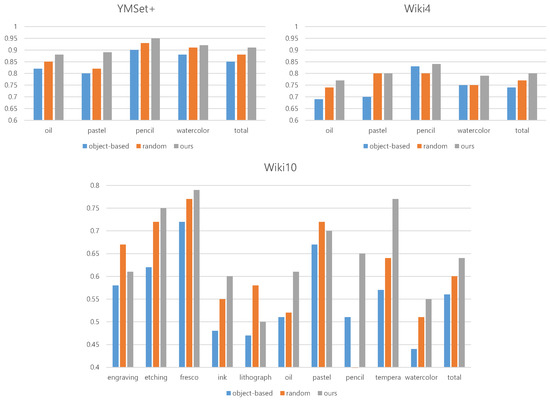
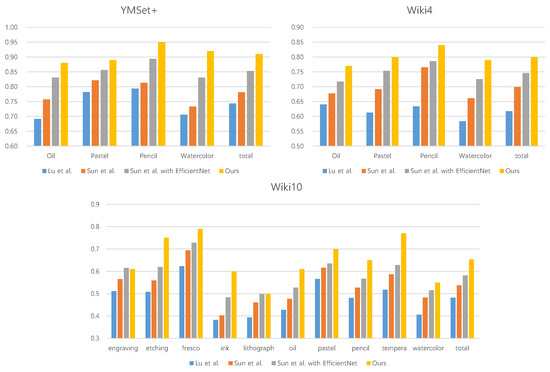
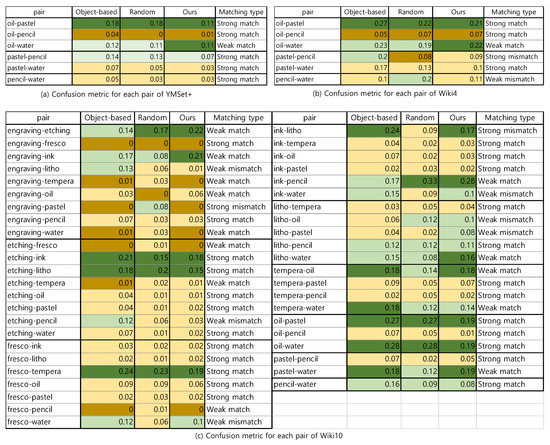
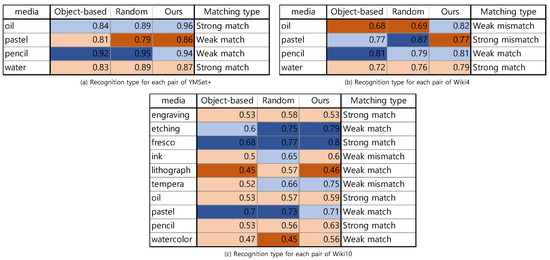
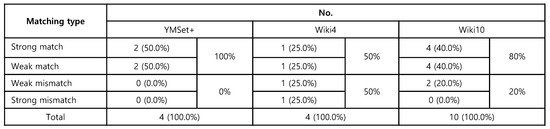
A Saliency-Based Patch Sampling Approach for Deep Artistic Media Recognition
by
Heekyung Yang and Kyungha Min
Cited by 2 | Viewed by 2788
Abstract
We present a saliency-based patch sampling strategy for recognizing artistic media from artwork images using a deep media recognition model, which is composed of several deep convolutional neural network-based recognition modules. The decisions from the individual modules are merged into the final decision
[...] Read more.
We present a saliency-based patch sampling strategy for recognizing artistic media from artwork images using a deep media recognition model, which is composed of several deep convolutional neural network-based recognition modules. The decisions from the individual modules are merged into the final decision of the model. To sample a suitable patch for the input of the module, we devise a strategy that samples patches with high probabilities of containing distinctive media stroke patterns for artistic media without distortion, as media stroke patterns are key for media recognition. We design this strategy by collecting human-selected ground truth patches and analyzing the distribution of the saliency values of the patches. From this analysis, we build a strategy that samples patches that have a high probability of containing media stroke patterns. We prove that our strategy shows best performance among the existing patch sampling strategies and that our strategy shows a consistent recognition and confusion pattern with the existing strategies.
Full article
►▼
Show Figures












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
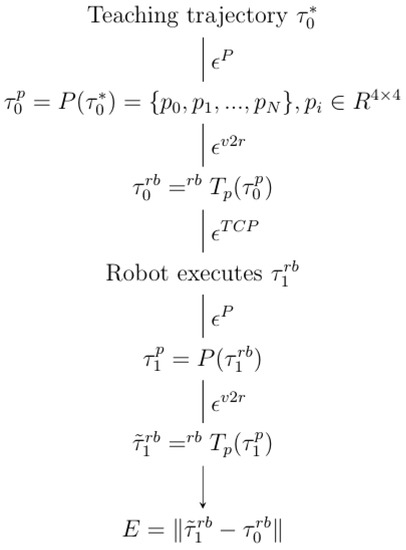{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}