

Center-Guided Transformer for Panoptic Segmentation


Abstract
:1. Introduction
2. Related Works
3. Proposed Methods
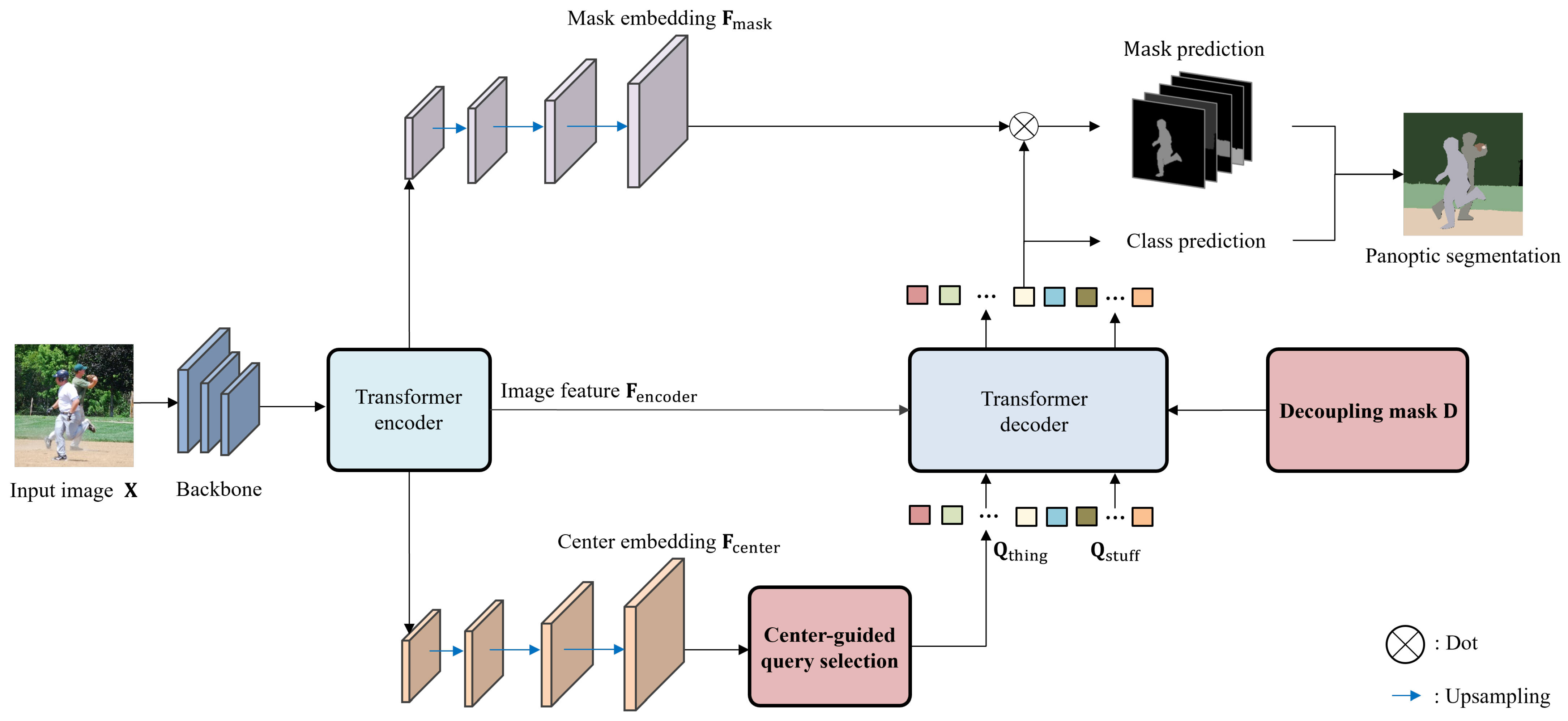
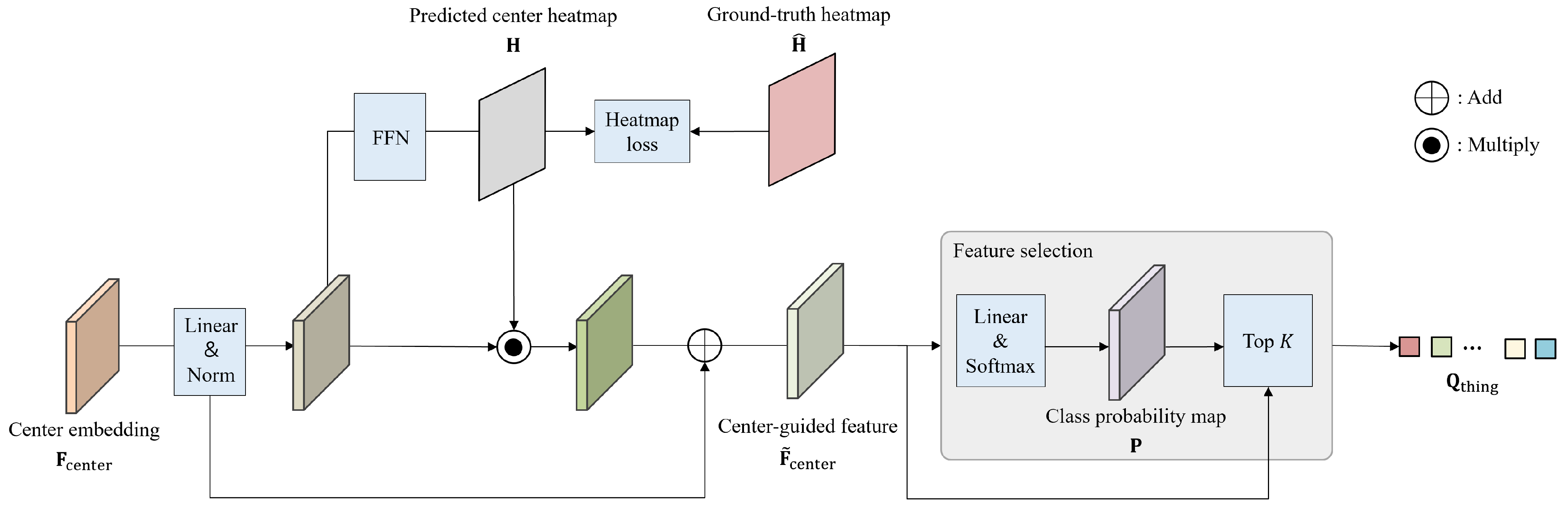
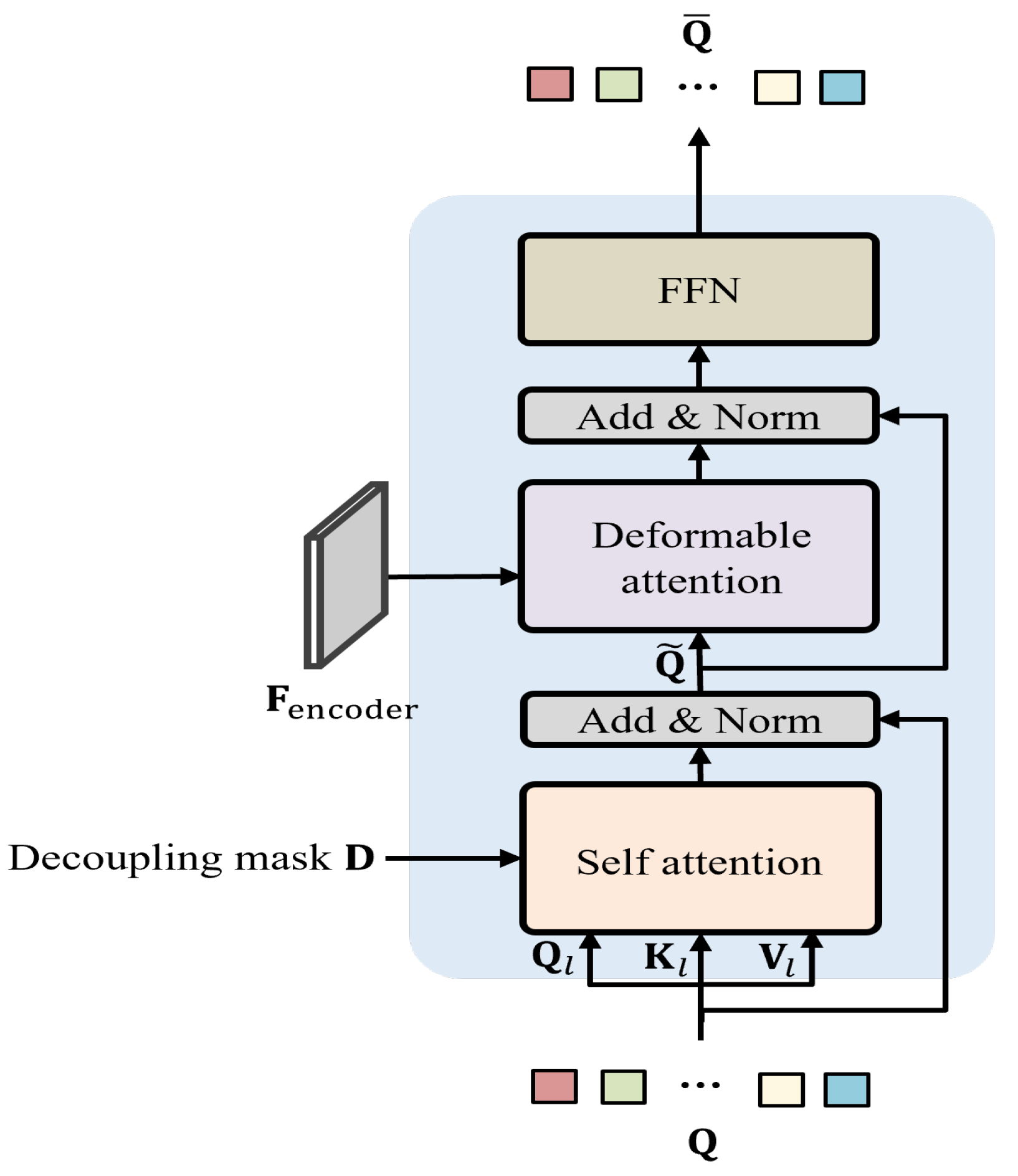
3.1. Architecture
3.2. Loss
4. Experiments
4.1. Setting
4.2. Comparison with Other Methods
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9404–9413. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. Upsnet: A unified panoptic segmentation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8818–8826. [Google Scholar]
- Li, Y.; Zhao, H.; Qi, X.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Fully convolutional networks for panoptic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 214–223. [Google Scholar]
- Li, Y.; Chen, X.; Zhu, Z.; Xie, L.; Huang, G.; Du, D.; Wang, X. Attention-guided unified network for panoptic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7026–7035. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang T., S.; Adam, H.; Chen, L.C. Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 12475–12485. [Google Scholar]
- Li, Z.; Wang, W.; Xie, E.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Lu, T. Panoptic segformer: Delving deeper into panoptic segmentation with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1280–1289. [Google Scholar]
- Nicolas, C.; Francisco, M.; Gabriel, S.; Nicolas, U.; Alexander, K.; Sergey, Z. End-to end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Bowen, C.; Alexander, G.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 7–10 December 2021. [Google Scholar]
- Bowen, C.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1290–1299. [Google Scholar]
- Zhu, W.; Xizhou, S. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ADE20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Lin, G.; Li, S.; Chen, Y.; Li, X. IDNet: Information Decomposition Network for Fast Panoptic Segmentation. IEEE Trans. Image Process. 2023. early access. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Huang, L.; Ren, T.; Zhang, S.; Ji, R.; Cao, L. You Only Segment Once: Towards Real-Time Panoptic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17819–17829. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6569–6578. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Probabilistic two-stage detection. arXiv 2021, arXiv:2103.07461. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9627–9636. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 13906–13915. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Stewart, R.J.; Andriluka, M.; Ng, A.Y. End-to-end people detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2325–2333. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D vision, Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Yuxin, W.; Alexander, K.; Francisco, M.; Wan-Yen, L.; Ross, G. Detectron2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 8 September 2023).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Mao, L.; Ren, F.; Yang, D.; Zhang, R. ChaInNet: Deep Chain Instance Segmentation Network for Panoptic Segmentation. Neural Process. Lett. 2023, 55, 615–630. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | PQ | FLOPs | Params | |||
|---|---|---|---|---|---|---|---|
| Panoptic DeepLab [5] | Xception71 [28] | 41.4 | 45.1 | 35.9 | - | - | - |
| ChaInNet [27] | ResNet50 | 43.0 | 49.8 | 33.8 | - | - | - |
| DETR [7] | ResNet50 | 43.2 | 48.2 | 36.1 | 31.1 | 248 G | 43 M |
| Panoptic FCN [3] | ResNet50 | 43.6 | 49.3 | 35.0 | 36.6 | 244 G | 37 M |
| IDNet [14] | ResNet50 | 43.8 | 49.6 | 35.0 | - | - | - |
| MaskFormer [8] | ResNet50 | 46.5 | 51.0 | 39.8 | 33.0 | 181 G | 45 M |
| Panoptic Segformer [6] | ResNet50 | 49.6 | 54.4 | 42.4 | 39.5 | 214 G | 51 M |
| Mask2Former [9] | ResNet50 | 51.9 | 57.7 | 43.0 | 41.7 | 226 G | 44 M |
| Ours | ResNet50 | 52.2 | 58.4 | 42.6 | 44.1 | 276 G | 51 M |
| Model | Backbone | PQ | |||
|---|---|---|---|---|---|
| IDNet [14] | ResNet50 | 30.2 | 33.2 | 24.3 | - |
| MaskFormer [8] | ResNet50 | 34.7 | 32.2 | 39.7 | - |
| Panoptic Segformer [6] | ResNet50 | 36.4 | 35.3 | 38.6 | - |
| YOSO [15] | ResNet50 | 38.0 | 37.3 | 39.4 | - |
| Mask2Former [9] | ResNet50 | 39.7 | 38.8 | 40.5 | 26.2 |
| Ours | ResNet50 | 41.5 | 41.1 | 42.2 | 28.9 |
| Model | PQ | FLOPs | Params | |||
|---|---|---|---|---|---|---|
| Ours | 52.2 | 58.4 | 42.6 | 44.1 | 276 G | 51 M |
| −Center-guided query selection | 51.6 | 57.2 | 42.3 | 42.0 | 273 G | 50 M |
| −Decoupling mask | 51.8 | 57.6 | 42.1 | 42.6 | 273 G | 50 M |
| −2 components above | 50.4 | 56.2 | 41.3 | 41.4 | 270 G | 50 M |
| Model | PQ | |||
|---|---|---|---|---|
| Ours | 41.5 | 41.1 | 42.2 | 28.9 |
| −Center-guided query selection | 40.2 | 39.4 | 41.1 | 26.1 |
| −Decoupling mask | 40.5 | 39.9 | 41.3 | 26.9 |
| −2 components above | 39.4 | 39.3 | 40.1 | 25.2 |
| Center-Guided | Feature | Random | PQ | ||||
|---|---|---|---|---|---|---|---|
| Query Selection | Selection | Initialization | |||||
| Things | ✓ | 52.2 | 58.4 | 42.6 | 44.1 | ||
| Stuff | ✓ | ||||||
| Things | ✓ | 51.8 | 58.2 | 42.1 | 43.6 | ||
| Stuff | ✓ | ||||||
| Things | ✓ | 51.6 | 57.6 | 42.3 | 42.9 | ||
| Stuff | ✓ |
| Backbone | PQ | FLOPs | Params | |||
|---|---|---|---|---|---|---|
| ResNet50 | 52.2 | 58.4 | 42.6 | 44.1 | 276 G | 51 M |
| ResNet101 | 52.7 | 58.9 | 43.3 | 44.7 | 342 G | 69 M |
| Swin-T | 53.6 | 59.8 | 43.6 | 45.2 | 280 G | 48 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baek, J.-H.; Lee, H.K.; Choo, H.-G.; Jung, S.-h.; Koh, Y.J. Center-Guided Transformer for Panoptic Segmentation. Electronics 2023, 12, 4801. https://doi.org/10.3390/electronics12234801
Baek J-H, Lee HK, Choo H-G, Jung S-h, Koh YJ. Center-Guided Transformer for Panoptic Segmentation. Electronics. 2023; 12(23):4801. https://doi.org/10.3390/electronics12234801
Chicago/Turabian StyleBaek, Jong-Hyeon, Hee Kyung Lee, Hyon-Gon Choo, Soon-heung Jung, and Yeong Jun Koh. 2023. "Center-Guided Transformer for Panoptic Segmentation" Electronics 12, no. 23: 4801. https://doi.org/10.3390/electronics12234801
APA StyleBaek, J.-H., Lee, H. K., Choo, H.-G., Jung, S.-h., & Koh, Y. J. (2023). Center-Guided Transformer for Panoptic Segmentation. Electronics, 12(23), 4801. https://doi.org/10.3390/electronics12234801