1. Introduction
With the accelerating digitization of urban infrastructure, closed-circuit television (CCTV) systems have emerged as indispensable components of contemporary urban safety and management frameworks. In particular, the precise measurement of planar distances between CCTV cameras and human subjects represents a critical capability across diverse application domains, including security monitoring, surveillance systems, spatial analysis, and emergency response coordination. Such distance measurement systems possess extensive applications, spanning from security zone delineation and threat level assessment in intrusion detection systems to real-time evacuation route optimization and rescue priority determination in disaster scenarios such as fires or earthquakes, as well as monitoring safe distances for facilities within public spaces.
The ’human-centric depth estimation’ methodology proposed in this research aims to detect human subjects, extract depth information exclusively for human regions, and quantify the planar distance between these subjects and the camera in metric units, thereby distinguishing itself from conventional scene-wide depth estimation approaches. Existing depth estimation systems typically require expensive equipment such as Light Detection and Ranging (LiDAR) sensors, and while capable of identifying relative depth relationships, they exhibit significant limitations in measuring absolute distances. Particularly, due to the inherently non-linear relationship between pixel-based representations and actual physical distances, measurement accuracy deteriorates substantially as objects move farther from the camera. Furthermore, while existing systems necessitate large-scale training datasets, our proposed methodology enables effective human-centric depth estimation utilizing merely 10–30 training images labeled with bounding boxes and corresponding distance values. Consequently, human-centric depth estimation represents a crucial technological advancement for human-centered applications, including rescue priority determination in disaster situations and social distancing monitoring for public safety.
However, current distance estimation systems demonstrate significant limitations when deployed in practical applications. Firstly, most existing systems focus on estimating depth for entire scenes, lacking specialization in accurate planar distance measurement between specific objects, particularly human subjects and cameras. This limitation constrains rapid and accurate location-based decision-making capabilities in emergency situations such as disasters or security threats. Secondly, contemporary systems require extensive training data to accommodate the various environmental variables that occur in real CCTV environments, including changes in illumination conditions, weather variations, and differences in camera installation angles. This substantial data requirement imposes considerable cost and temporal burdens in actual system implementation and operation.
A fundamental challenge in developing practical distance estimation systems with minimal data lies in the inherent complexity of visual scenes captured by CCTV cameras. Environmental factors such as varying illumination conditions, object occlusions, and perspective distortions significantly complicate accurate distance estimation without extensive training data. Moreover, traditional approaches that rely exclusively on either object detection or depth estimation methodologies often fail to provide the specificity and accuracy required for human-centric distance measurement. Object detection methods can effectively localize human subjects but lack essential depth information, while general-purpose depth estimation models may struggle with distinguishing between target objects and background elements.
The challenge is further compounded by the non-linear relationship between pixel-based representations and actual metric distances. As objects move progressively farther from the camera, their visual dimensions decrease in a non-linear fashion, making accurate distance estimation increasingly challenging. This non-linearity is particularly pronounced in surveillance settings where accurate distance measurements across extensive ranges (e.g., 5–30 m) are essential for effective operation.
To address these substantial challenges, this study proposes an innovative system capable of reliable distance estimation with minimal training data requirements. The proposed system effectively combines the sophisticated object segmentation capabilities of the Segment Anything Model (SAM) [
1] with advanced depth perception technology from monocular depth estimation methodologies [
2,
3,
4]. A particularly noteworthy aspect is the system’s ability to effectively overcome the constraints of large-scale training data that previous approaches required by utilizing the complementary characteristics of SAM’s precise human object segmentation and the global depth mapping provided by monocular depth estimation.
The core technical innovation of this research lies in the strategic introduction of Kernel Density Estimation (KDE) [
5] and log-space learning methodologies. This approach ensures robustness against overfitting and noise inherent in limited training data while guaranteeing stable performance against various environmental variables that may occur in real CCTV environments. Unlike conventional smoothing techniques, KDE provides a sophisticated probabilistic framework for handling depth uncertainties by modeling the density distribution of depth values, which proves particularly effective when working with noisy depth maps. Similarly, log-space learning addresses the inherent non-linearity in depth perception by transforming the representation space, resulting in more stable learning across different distance ranges.
The key contributions of this research are as follows:
Proposal of an innovative framework enabling reliable planar distance estimation between cameras and human subjects using minimal training data (30 images).
Achievement of enhanced noise robustness in real-world environments through the strategic implementation of Kernel Density Estimation and log-space learning.
Comprehensive verification of system practicality through the construction and rigorous testing of datasets that accurately reflect actual CCTV environments.
Demonstration of the proposed system’s effectiveness through extensive experimental validation.
2. Related Work
This section reviews key studies that have informed the development of our human-centric depth estimation framework. Particular attention is given to the underlying technical principles and methodological paradigms that enable effective performance under limited supervision or constrained training data conditions.
2.1. Depth Estimation Paradigms
Depth estimation research primarily follows two paradigms: stereo vision-based and monocular approaches. Traditional stereo methods [
6,
7,
8] compute depth by triangulating disparities between multiple calibrated viewpoints, yielding geometrically accurate results rooted in well-established physical principles. However, these methods face substantial deployment challenges in real-world scenarios due to hardware dependencies and calibration complexity, which limit their scalability—particularly in CCTV-based surveillance systems.
The emergence of deep learning has significantly advanced monocular depth estimation [
9,
10], which circumvents many limitations inherent to stereo setups. Supervised methods such as DPT [
11] leverage Vision Transformers [
12] for dense prediction, while AdaBins [
13] introduces an adaptive discretization strategy that improves depth resolution across scenes. Despite their accuracy, these models require large-scale ground-truth annotations, which are often difficult to acquire.
To mitigate data annotation constraints, self-supervised approaches have gained traction. Models such as MonoDepth2 [
14] and MonoViT [
15] eliminate the reliance on labeled depth maps by leveraging view synthesis and photometric consistency objectives. These strategies have proven effective in training from raw video sequences, offering a more scalable path for real-world deployment.
Of particular relevance to human-centric scenarios are recent zero-shot depth estimation methods [
16,
17,
18,
19]. Metric3Dv2 [
16,
17] introduces a camera-space normalization technique that resolves metric ambiguities across varying camera intrinsics and incorporates surface normal estimation to enforce geometric consistency. Trained on diverse datasets covering indoor and outdoor environments, varying lighting conditions, and a wide range of camera models, Metric3Dv2 demonstrates strong generalization, especially in scenes containing humans. Similarly, DepthPro [
18] employs dual ViT encoders to capture multi-scale features and produces high-resolution depth maps with crisp boundaries, enabling precise reconstruction of fine human-centric details such as hair, fur, and limbs.
While these foundational models showcase the promise of transferable depth estimation in diverse environments, they remain insufficiently specialized for human-centric applications and typically rely on extensive training data, which limits their effectiveness in resource-constrained settings.
2.2. Object-Aware Visual Understanding
Object segmentation provides the critical capability to isolate and analyze specific elements within visual scenes—a prerequisite for human-centric depth estimation approaches.
SegFormer [
20] employs a hierarchical transformer encoder to output multi-scale features, offering the advantage of minimal performance degradation even when test and training resolutions differ due to its lack of need for position encoding. It also efficiently integrates information from various layers using a simple MLP decoder. MaskFormer [
21] further advances this approach by progressively enhancing object segmentation capabilities through a mask classification method that more clearly distinguishes object instances.
The recent introduction of SAM(Segment Anything Model) [
1] by Meta AI represents a paradigm shift in segmentation capabilities, offering unprecedented zero-shot performance and adaptability across diverse visual contexts. The prompt-based interface of SAM and its robust generalization to untrained object categories make it particularly suitable for human segmentation in varied CCTV environments. While its performance is excellent, efficiency improvements are needed for real-time processing. Several lightweight models have been proposed to address this. MobileSAM [
22] utilizes Decoupled Distillation techniques [
23] to reduce model size while preserving segmentation quality, achieving up to 50× acceleration compared to the original model while being 60 times smaller with similar performance. Similarly, FastSAM [
24] introduces an efficient CNN-based architecture that achieves comparable segmentation performance at substantially higher inference speeds. These enhancements directly address computational constraints in CCTV systems, enabling real-time human-centric analysis without sacrificing segmentation precision. In particular, the FusionVision [
25] pipeline employs FastSAM to generate refined segmentation masks for holistic interpretation of RGB-D data and to improve post-processing tasks such as accurate 3D dataset extraction.
However, we find that MobileSAM and FastSAM generate some noise in complex environments, resulting in slightly degraded accuracy. Therefore, in this research, we decide to use the original SAM for the best segmentation accuracy. We expect that performance with MobileSAM and FastSAM will improve with enhanced noise removal modules in future work. Our approach leverages the powerful combination of zero-shot segmentation with monocular depth estimation to build a system for human-centric distance measurement that generates high-quality segmentation masks necessary for accurate depth estimation while ensuring practical viability in resource-constrained environments. This approach presents an effective technical direction that addresses practical limitations in real deployment scenarios.
2.3. Integrated Object-Depth Frameworks
The integration of object understanding and depth estimation represents a critical research direction for human-centric applications. The pioneering work by Masoumian et al. [
26] combines YOLOv5-based [
27,
28,
29,
30] detection with ResNet [
31] autoencoders for depth estimation, introducing GCN [
32] for multi-scale depth refinement. More specialized frameworks like MonoScene [
33] have demonstrated the advantages of incorporating instance-level reasoning into depth estimation processes, confirming the fundamental premise that object-aware depth estimation outperforms generic scene-level approaches.
One family of integrated approaches uses a shared CNN backbone with multiple heads for different tasks. Eigen and Fergus’s single multi-scale architecture [
34] was an early attempt, simultaneously predicting depth, surface normals, and semantic labels. More recently, PADNet by Xu et al. [
35] introduced an explicit multi-task framework: they guided a depth network with intermediate predictions from a segmentation network through a feature distillation module. This integration of “scene parsing” (object segmentation) and depth allowed each task to inject knowledge into the other—for example, segmentation features helped depth prediction differentiate objects from background, and depth cues helped the segmentation branch recognize object extents [
36,
37].
These integrated approaches, however, typically require extensive training data and lack optimization for specific measurement tasks like human-camera distance estimation in CCTV environments. Our research specifically addresses these limitations through a novel combination of the precise human segmentation capabilities of SAM with state-of-the-art monocular depth estimation, enhanced by statistical techniques for noise robustness and log-space learning for measurement consistency, including polynomial regression models to systematically analyze the effects of log-space learning.
2.4. Statistical Methods for Limited Data Scenarios
A key challenge in practical computer vision applications is achieving robust performance with minimal training data. While few-shot learning approaches have shown promise in domains like segmentation and recognition, their application to metric depth estimation remains limited. Kernel Density Estimation (KDE) techniques, historically applied in object tracking and background modeling, offer valuable statistical frameworks for handling uncertainty in limited-data scenarios.
Our research uniquely combines these statistical approaches with modern deep learning architectures to address the specific challenges of human-centric depth estimation under minimal training data constraints.
When data are limited, it also becomes important to inject prior knowledge or constraints—effectively informing the model about the expected structure of the depth prediction task. Researchers have incorporated priors ranging from planarity (for man-made environments with flat surfaces) to object size and ground contact constraints (in driving scenes, for example) to guide depth estimation in data-sparse regimes. Some works leverage classical probabilistic models: by formulating depth estimation in a Bayesian framework, one can encode confidence in predictions. Kendall et al. [
38], for instance, not only tackled multi-task learning but also modeled prediction uncertainty; by learning a pixel-wise uncertainty map, their method can identify which depth estimates are reliable.
The fundamental limitation of existing approaches—which our work directly addresses—is their dependence on extensive training data and their lack of specialization for human-centric distance measurement. By integrating state-of-the-art segmentation, monocular depth estimation, and statistical modeling, our method achieves high accuracy using only 30 training images. This demonstrates a substantial advancement in practical applicability, particularly for CCTV-based human distance measurement systems operating under data-scarce conditions.
3. Method
This section explains the overall structure and technical details of the proposed person-centric distance estimation system. The proposed system presents a new methodology that can achieve high accuracy with minimal training data by combining precise object segmentation based on SAM [
1] with monocular depth estimation.
3.1. System Overview
As depicted in
Figure 1, the processing pipeline of the proposed method is structured as follows.
Initially, the input image is processed using a pre-trained human detection network to identify bounding boxes corresponding to human instances within the scene. These bounding boxes are subsequently provided as prompts to the Segment Anything Model (SAM), which produces high-precision segmentation masks for each detected human object.
Meanwhile, the same input image is processed by a monocular depth estimation module to generate a global depth map. The segmentation masks obtained from SAM are utilized to isolate depth information corresponding exclusively to human regions within the image, thereby effectively filtering out background noise. The extracted person-centric depth values are then smoothed, and residual noise is mitigated through the application of Kernel Density Estimation (KDE).
Finally, a logarithmic transformation is applied to the KDE-processed depth values. This transformation serves to normalize the data distribution and render them suitable as input for the subsequent regression model. The normalized data are then fed into the regression model to predict absolute distance values. The model’s predictions are evaluated against ground truth annotations using the L1 loss function during training.
This methodology enables accurate estimation of the human-centric depth information and its reliable conversion into metric distance values, thereby enhancing the precision and applicability of the proposed system in real-world scenarios.
3.2. Monocular Depth Estimation
This research adopts a zero-shot monocular depth estimation model to overcome the limitations of having only 30 training images. While conventional monocular depth estimation models require retraining with thousands of images, our approach directly performs depth prediction using pre-trained Metric3Dv2 [
16,
17] and DepthPro [
18] models without additional training.
These two models are evaluated independently, not as an ensemble, to leverage their distinct strengths. Metric3Dv2 excels with its camera-space normalization technique that resolves metric ambiguities across varying camera intrinsics and demonstrates strong generalization capabilities in diverse environments containing humans. In contrast, DepthPro employs dual ViT encoders to capture multi-scale features and produces high-resolution depth maps with crisp boundaries, enabling the precise reconstruction of fine human-centric details such as hair and body contours.
This zero-shot approach differentiates itself from conventional monocular depth estimation models in that pre-trained models can be utilized in new environments without separate retraining. While conventional approaches require retraining with large-scale datasets in new environments, the zero-shot approach offers practical value, as it can be efficiently utilized even in limited data environments.
However, while zero-shot monocular depth estimation models can effectively predict relative depths within an image, they show limitations in absolute distance measurement due to different viewing angles and focal lengths across cameras. To overcome these limitations, our research improves the absolute distance measurement accuracy by combining new methodologies.
As shown in
Figure 2, the model effectively delineates human silhouettes and accurately captures relative depth relationships among individuals at varying distances, all without requiring any further training.
3.3. Person-Centric Depth Extraction with SAM
The zero-shot capability in object segmentation of SAM plays a crucial role in accurately segmenting human objects in various situations without additional training. This ensures stable performance against variables that occur in real CCTV environments, such as diverse poses, lighting conditions, and occlusions, while providing flexibility to accept various forms of prompts such as bounding boxes and points.
Figure 3 shows the core processing steps of our system. It illustrates the process where SAM generates accurate human segmentation masks using bounding boxes produced by a pre-trained person detector as prompts. The generated segmentation masks are combined with depth maps from monocular depth estimation, which contain relative depth information for all pixels in the image.
To achieve our goal of accurately estimating the planar distance between human objects and the camera, we use SAM-generated segmentation masks to extract only the depth values corresponding to human regions. This approach is effective because background depth information can introduce noise in distance estimation, and the use of segmentation masks provides a means to retain the spatially central and structurally reliable parts of the human body, while effectively discarding uncertain peripheral areas.
3.4. Kernel Density Estimation
Kernel Density Estimation (KDE) is applied to obtain a continuous depth distribution and select N points with the highest density. The rationale for choosing KDE is that it provides a continuous probability density function unlike histograms, enabling a more natural depth distribution and offering resistance to noise by smoothly distributing the influence of individual data points. Additionally, by selecting points from high-density regions, we can utilize only the most reliable depth information.
The core basis for introducing KDE lies in the statistical characteristics of noise in depth maps. While monocular depth estimation provides pixel-level predictions, these predictions contain inherent uncertainties due to camera angles, lighting conditions, and object occlusion phenomena. KDE models these uncertainties as probability distributions, enabling more reliable depth estimation than simple averages or median values.
Mathematically, for a set of depth values
extracted from the human region, the KDE at a point d is given by
where
K is the kernel function (typically a Gaussian function), and
h is the bandwidth parameter that controls the smoothness of the density estimate. The optimal value of
h is critical for balancing between overfitting (too small
h) and oversmoothing (too large
h).
KDE performance heavily depends on kernel bandwidth selection. Therefore, we conduct experiments applying both widely used Silverman’s rule and Scott’s rule to determine the optimal bandwidth.
Silverman’s rule is defined as
where
h is the bandwidth,
is the standard deviation estimate, and
n is the sample size.
Particularly, is selected as the smaller of the following:
Scott’s rule is defined for multidimensional data as
where
is the bandwidth for the
i-th dimension,
n is the sample size,
d is the number of dimensions, and
is the standard deviation of the
i-th dimension.
3.5. Log-Space Learning and Inference
To enhance the depth regression accuracy, we perform learning and inference by transforming depth values into log space. This provides the following advantages.
First, depth values observed from CCTV cameras show non-linear increases with distance. For example, while the differences between points 5 m and 6 m apart (1 m) and points 45 m and 46 m apart (1 m) represent the same actual distance, they appear at very different scales in the image. Through log transformation, we can effectively linearize this non-linearity.
The log transformation can be expressed as
where
d is the original depth value,
is the transformed value, and
is a small constant (typically 1 × 10
−6) to prevent numerical issues when
d approaches zero.
Second, errors in depth estimation tend to increase as distance increases. Learning in log space naturally normalizes the scale of these errors. Specifically, it maintains high precision at close distances and relatively lower precision at far distances, allowing us to maintain a consistent error ratio according to distance. The relative error after log transformation becomes
which shows that the relative error remains approximately constant across different depth ranges.
Finally, learning in log space makes the loss function’s gradient more uniform across distances. This ensures balanced learning across all distance ranges during the training process and particularly mitigates sharp gradient changes at far distances, improving learning stability. The gradient of the loss function
L with respect to
d becomes
which naturally assigns smaller gradients to larger depths, preventing optimization instability.
However, these characteristics of log transformation have a duality. While the aforementioned gradient reduction at far distances helps optimization stability, it may simultaneously limit the learning of subtle depth differences between distant objects. At far distances, actual spatial differences can become overly compressed in log space, potentially reducing the model’s discriminative power, and the transformation effect may vary depending on the choice of measurement units. We deliberately choose log transformation for four primary reasons: (1) to effectively linearize the inherent non-linearity of depth values in CCTV footage, (2) to enhance model stability by preventing overfitting even with high-degree polynomial models, (3) to create more uniform learning gradients across all distance ranges, and (4) to improve optimization safety through balanced gradient distribution.
As demonstrated in
Figure 4, these advantages of log transformation result in higher prediction accuracy than using only KDE. Predictions (red dots) after applying log transformation remain consistently closer to the ground truth (GT) than those (blue markers) obtained without it.
3.6. Distance Regression Model
Figure 5 shows the detailed architecture of the proposed regression model. This model serves as the final stage of the entire system, processing integrated information from segmentation masks obtained through SAM and depth maps generated by the monocular depth estimation module. Specifically, the input to the Distance Regression Model is an N-dimensional vector of log-transformed depth values after applying KDE to human regions extracted through the SAM segmentation masks. The output is a value that converts the normalized depth information into actual meter-unit distances. Through this process, the relative depth information obtained from the monocular depth estimation module can be accurately converted into actual physical distance values. The model consists of a basic block for extracting initial features, two residual blocks, and a final linear layer for output. The basic block sequentially applies linear layer → batch normalization [
39] → PReLU activation function [
40], performing the role of converting
N-dimensional log-transformed depth values into
M-dimensional hidden channels.
The residual block is structured as linear layer → batch normalization → PReLU activation function → dropout → linear layer → batch normalization. Dropout [
41] existing within the residual block serves to suppress overfitting, and a skip connection is implemented by adding each block’s input to its output, enabling stable learning even in deeper networks. Notably, all layers are composed of lightweight linear operations, enabling fast inference while effectively increasing model expressiveness and suppressing overfitting through these structures.
The mathematical formulation of the residual block can be expressed as
where
x is the input to the residual block and
y is the output. This residual learning formulation helps address the degradation problem in deep networks and enables effective feature extraction even with limited training data.
4. Experiments
This section details the experimental settings and results for evaluating the proposed system’s performance. We systematically conduct experiments on the effects of each component proposed in
Section 3, sequentially testing log-space learning, object segmentation methods, and density estimation methods.
4.1. Dataset Construction
In this research, we constructed a dataset reflecting actual CCTV environments for system performance evaluation. The camera was installed at 2 m height and maintained a 90-degree angle with the ground to replicate actual CCTV conditions (refer to
Figure 6). Filming was conducted in outdoor environments to include various environmental variables, with distance measurements taken at 5 m intervals from 5 m to 30 m.
To reflect the complexity of real CCTV camera installation environments, we included multiple object scenarios, and to simulate person-to-person occlusion scenes that frequently occur in real environments, we filmed situations where test subjects were partially occluded or overlapping with each other. To ensure data accuracy, test subjects were instructed to walk along pre-drawn baseline markers on the ground, enabling precise distance measurements to each subject in every image. This approach guaranteed accurate data labeling while realistically evaluating system performance in actual surveillance environments.
To ensure uniformity in data distribution, we collected similar numbers of samples for each distance interval. Each image was labeled with human bounding boxes and actual distance (m) information. The final dataset comprised 1642 images in total, with 30 allocated for training and 1612 for testing.
4.2. Experimental Setup
The proposed system’s performance evaluation was conducted using mean absolute error (MAE) as the primary evaluation metric. The experiments were conducted in three aspects: (1) analysis of log-space learning effects, (2) performance comparison by object segmentation methods, and (3) performance comparison by density estimation methods. Model training was designed to achieve effective results with minimal data (30 images). Key training parameters included a learning rate of 0.005, batch size of 32, AdamW optimizer [
42], dropout rate of 0.1, and 750 training epochs. The regression model’s input (
N) mentioned in
Section 3.6 was set to 750 through experiments, with hidden layer channels set to 256.
4.3. Log Space Learning Analysis
To systematically analyze the effect of log-space learning, we first conducted experiments with easily interpretable polynomial regression models before applying it to deep learning models.
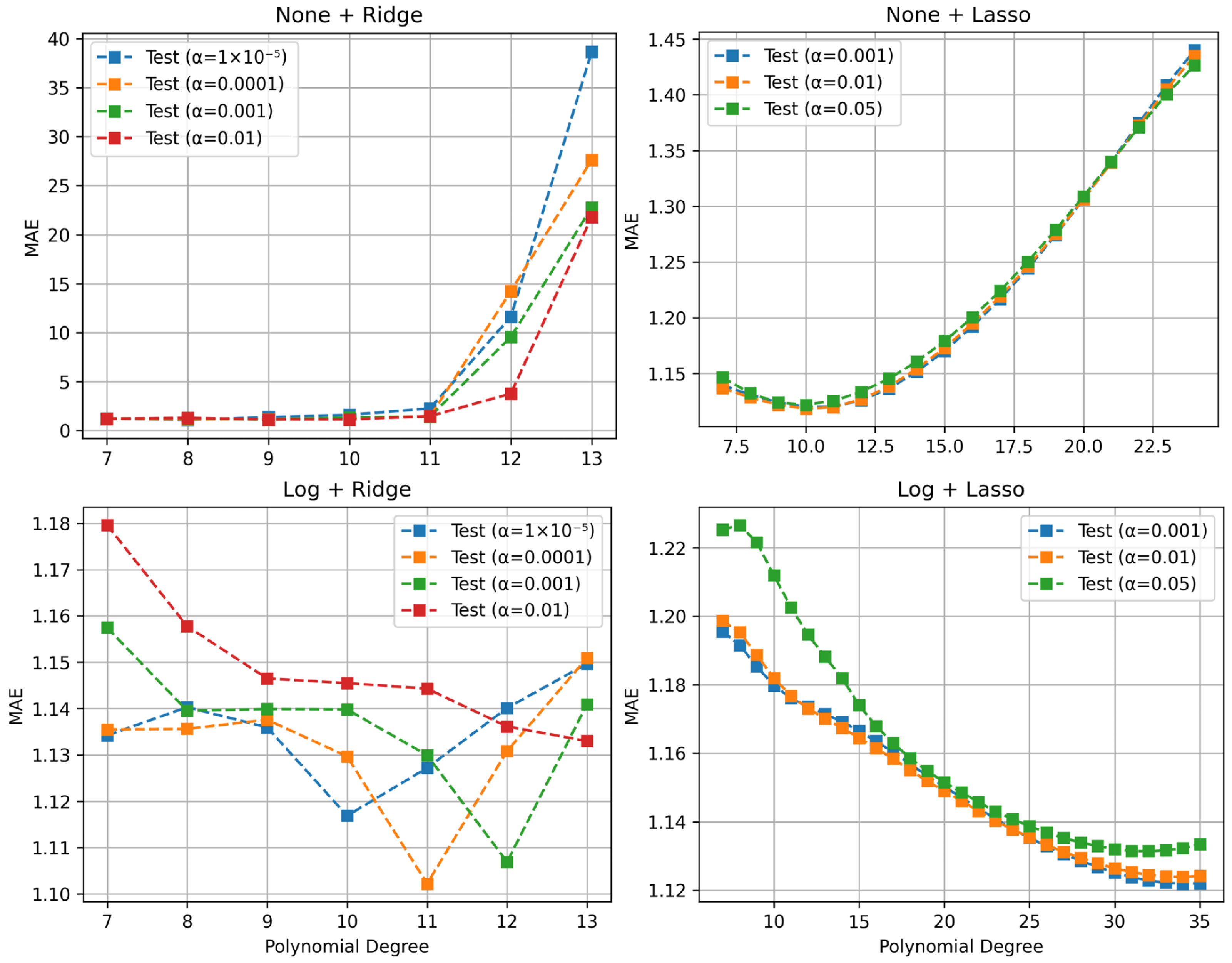
Figure 7 shows the performance of polynomial regression models with Ridge and Lasso regularization in both original and log space. Each graph shows MAE changes according to increasing polynomial degrees for various regularization coefficients (
).
Analysis of polynomial regression with Ridge regularization revealed that in original space (None + Ridge), MAE increased dramatically when polynomial degree exceeded 11, indicating severe overfitting. In contrast, in log space (Log + Ridge), stable learning was achieved at the same degree, achieving optimal performance with MAE of 1.02 at 12th-degree polynomials when .
Similar results were observed in experiments with Lasso regularization. In original space (None + Lasso), MAE continuously increased with degrees, while in log space (Log + Lasso), stable performance improvements were maintained up to the 35th degree. Particularly at , it showed the best performance, demonstrating desirable learning patterns where MAE gradually decreased with increasing degrees.
These results from polynomial regression models suggest that log-space learning reduces the intrinsic complexity of the distance estimation problem, clearly demonstrated by the fact that stable learning is possible even with high-degree polynomials without overfitting.
To validate these findings in neural network models, we conducted experiments comparing baseline approaches with log-space learning for both Metric3D v2 [
16,
17] and DepthPro [
18] models. As shown in
Table 1, log-space learning consistently improved performance, reducing MAE from 0.75879 m to 0.74905 m for Metric3D v2 and from 0.83525 m to 0.82067 m for DepthPro.
4.4. Segmentation Method Analysis
To verify whether the precise object segmentation capability of SAM [
1] described in
Section 3.2 leads to actual performance improvement, we analyzed performance according to object segmentation methods with log-space learning applied.
Table 2 shows the comparison results between various crop ratios applied to bounding boxes and SAM-based segmentation.
According to the experimental results, for the Metric3D model, applying crops to bounding boxes actually degraded performance. The original bounding box (Crop 0%) showed the best performance with an MAE of 0.74905 m, while Crop 30%, 50%, and 70% resulted in decreased performance with MAEs of 0.77006 m, 0.78596 m, and 0.76993 m respectively. This indicates that the Metric3D model works more effectively when utilizing the entire contextual information of the object.
More notable results appeared in the DepthPro model. The original bounding box (Crop 0%) recorded an MAE of 0.82067 m, and as the crop ratio increased, performance progressively improved, showing optimal results at Crop 50% with an MAE of 0.68838 m. However, when the crop ratio further increased to 70%, the MAE slightly increased again to 0.70722 m. This demonstrates that for the DepthPro model, an appropriate level of bounding box cropping can effectively remove background noise and improve performance.
Interestingly, the SAM segmentation method achieved the lowest MAE of 0.65280 m, outperforming even the best cropping method (Crop 50%) for the DepthPro model. This proves that integrating SAM into the DepthPro framework yields significant performance improvement (reducing error by 0.16787 m compared to the original bounding box). This enhancement shows that SAM captures object boundaries more accurately than simple rectangular crops, enabling effective background removal and improving depth prediction, particularly in scenes with multiple subjects at varying distances.
4.5. Density Estimation Analysis
To investigate the impact of kernel bandwidth selection in KDE, we analyzed the performance of different kernel bandwidths in KDE for the model combining DepthPro and SAM with log transformation.
Table 3 shows the performance comparison between various kernel settings. Experimental results revealed an MAE of 0.69061 m with Silverman’s rule and 0.67576 m with Scott’s rule. Experimental results showed an MAE of 0.69061 m when applying Silverman’s rule, while using Scott’s rule as the baseline achieved slightly improved results with an MAE of 0.67576 m.
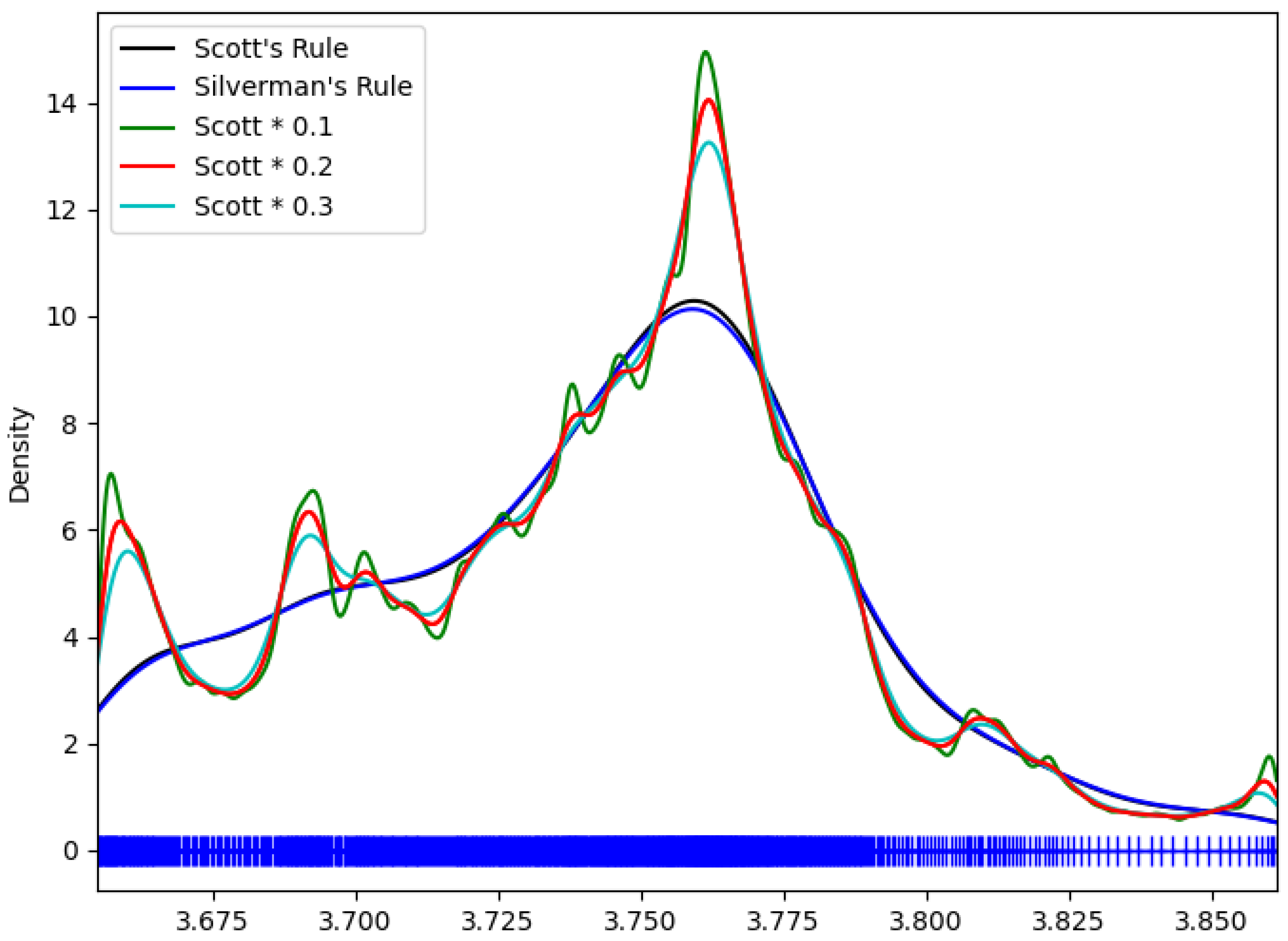
Figure 8 provides a visual representation of KDE results across various kernel sizes. When multiplying Scott’s rule by 0.1, the distribution changes very sensitively and captures minor variations, but this led to increased MAE due to overfitting. In contrast, Scott’s rule and Silverman’s rule show generally smooth distributions and effectively capture overall data trends.
Particularly noteworthy is the case of multiplying Scott’s rule by 0.2, which achieved the best performance with an MAE of 0.65280 m. As seen in
Figure 8, this setting provides balanced estimation by maintaining the overall distribution shape while clearly distinguishing major peaks. When increasing the scale factor to 0.3, MAE slightly increased to 0.65490 m, which can be interpreted as the loss of some important features due to excessive smoothing of the distribution as is visible in the graph.
These results demonstrate that kernel size selection in KDE has a decisive impact on performance. Too-small kernel sizes lead to overfitted estimation sensitive to noise, while too-large kernel sizes can result in excessive smoothing that misses important features. The setting of multiplying Scott’s rule by 0.2 proved to provide the optimal balance point in this trade-off relationship.
We also conducted experiments to analyze the effect of training data size on system performance using the optimal KDE setting (Scott’s rule × 0.2).
Table 4 shows the performance variations when using 10, 20, and 30 training images. Notably, even when the number of training images was significantly reduced from 30 to 10, the MAE increased only minimally from 0.65280 m to 0.66416 m, representing a mere 1.7% performance degradation. These results demonstrate that the proposed system can maintain robust performance even with highly limited training data, further strengthening its practical applicability in real CCTV environments. Beyond functioning reliably with an already small set of 30 training images, the fact that accurate distance measurement is possible with as few as 10 images validates the data efficiency of the system. Given this trend of decreasing dependency on training data, future research could potentially evolve this methodology into a complete zero-shot approach, enabling accurate distance measurement without any training data whatsoever.
5. Absolute Study
In this section, we conduct comprehensive analyses of the proposed system’s performance and robustness. We examine the impact of KDE input size (N) on model accuracy, analyze error rates by distance class, and verify system robustness under varying lighting conditions by comparing daytime and nighttime performance.
5.1. KDE Input Size Analysis
To analyze the impact of KDE input size (N) on model performance, we conducted experiments with various N values. As shown in
Table 5, we measured the changes in MAE according to N values in models where Depth Pro, SAM, and log transformation were applied. Experimental results showed the best performance with an MAE of 0.65280 m when N = 750. For N = 300 and N = 500, MAE values of 0.71457 m and 0.76456 m were recorded respectively, which was analyzed to be due to the insufficient input size that failed to fully represent the depth distribution. Conversely, when increased to N = 1000, performance slightly degraded to an MAE of 0.69750 m, which we attribute to excessive input size increasing noise. These results demonstrate that the selection of KDE input size significantly affects model performance, and the accuracy of depth estimation can be improved by selecting the optimal N value. Therefore, in this study, we selected N = 750 for optimal performance and conducted all subsequent experiments with this value.
5.2. Distance-Based Error Analysis
To evaluate system performance across various distance ranges, we conducted an error rate analysis by distance class. As shown in
Figure 9, the error rate exhibited a non-linear increasing trend with distance. At the closest distance of 5 m, we observed the lowest error rate of 1.15%, which gradually increased with distance, recording 2.27% at 10 m and 2.94% at 15 m. At 20 m, the error rate increased significantly to 4.65%, but slightly decreased to 4.24% at 25 m, then marginally increased to 4.46% at 30 m. These results demonstrate that despite the application of log-space learning, the trend of increasing errors with distance still exists. However, the system maintains relatively stable error rates (4.24–4.65%) at long distances (20–30 m), consistently achieving error rates below 5% across the wide range from 5 m to 30 m. This proves that the proposed system can provide practical and reliable distance measurements across various distance ranges in real CCTV environments.
5.3. Robustness Analysis Under Varying Lighting Conditions
To evaluate the robustness of the system in various environmental conditions, we analyzed performance differences between daytime and nighttime. Based on the existing test data, we generated synthetic nighttime images by applying brightness reduction, color adjustment, and blur effects. As shown in
Table 6, the optimal configuration (DepthPro + SAM + log) showed performance degradation of approximately 38.3%, from a daytime MAE of 0.65280 m to a nighttime MAE of 0.90308 m. This is primarily due to the decreased person detection accuracy in low-light conditions, which results in lower quality bounding boxes provided to SAM. Nevertheless, maintaining an MAE of less than 1 m even in nighttime conditions demonstrates the robustness of the proposed methodology. We anticipate that using detection models optimized for low-light environments could further improve nighttime performance. These results suggest that log-space learning and KDE-based noise reduction provide robustness against variations that occur in diverse environmental conditions.
6. Conclusions
The importance of accurate distance measurement in CCTV environments has recently been highlighted. Existing solutions have been limited by either requiring large-scale training data or lacking specialization in precise distance measurement for specific objects. Therefore, this research proposed an innovative system that can accurately measure planar distance between cameras and people in CCTV environments with minimal data. To achieve this, we presented a new methodology that effectively combines the sophisticated object segmentation capabilities of SAM with zero-shot monocular depth estimation technology.
The primary conceptual contribution of this research is the presentation of a novel methodological framework for ’human-centric depth estimation’. The sophisticated object segmentation capabilities of SAM enhance depth estimation accuracy by eliminating background noise, while KDE probabilistically models uncertainties in depth values, and log-space learning addresses the non-linearity problem in depth perception. This organic integration of technical approaches transcends the mere combination of techniques, establishing a new paradigm for high-precision measurement in minimal-data environments.
The core technical innovations of this research are as follows. First, we minimized background noise using the precise object segmentation capabilities of SAM. Experimental results validated that SAM-based precise segmentation significantly improved performance compared to the conventional bounding box method by removing background noise, confirming that sophisticated object segmentation beyond simple detection is crucial for improving distance estimation accuracy.
Second, we resolved the non-linearity problem through log-space learning. The application of log transformation in both Metric3D v2 and DepthPro showed improved performance, particularly demonstrating more stable results in long-distance measurements. This improvement effect was theoretically validated through polynomial regression analysis.
Third, we processed optimal depth information using KDE and Scott’s rule. Through the analysis of various density estimation methods, we achieved optimal performance. This succeeded in securing robustness against noise while minimizing the loss of important depth information.
Fourth, the regression learning structure utilizing linear-based residual blocks achieved fast inference speed suitable for real-time processing, being composed of only simple linear transformations. Additionally, it demonstrated stable regression performance without overfitting, even with the limited dataset used in our experiment.
Particularly noteworthy is that the excellent performance of MAE 0.65 m was achieved on 1612 test images with only 30 training images.
The outcomes of this research can be utilized in various real-world application areas such as security surveillance, disaster response, and public space monitoring. Furthermore, the minimal training data requirement greatly enhances the practicality of system construction and operation.
The human-centric depth estimation methodology developed in this research has the potential for application across various computer vision tasks. By integrating our precise object segmentation and depth estimation techniques with Wang et al.’s [
43] occluded person re-identification research and Pang et al.’s [
44] tissue image analysis study, our approach could be utilized for generating accurate pedestrian representations and performing fine-grained structural analysis tasks. These extension possibilities further broaden the impact of our research.
However, the currently proposed model still has room for improvement. Future research should focus on the following:
Model lightweighting for real-time processing on edge devices;
Performance verification in extreme environmental conditions (night, rain, fog);
Extension to distance estimation for non-human objects;
Exploration of self-supervised approaches to further reduce the need for labeled data.
While our current model has achieved excellent performance with limited training data, several practical challenges remain. Experiments were conducted using an NVIDIA GeForce RTX 3090 Ti graphics processing unit (NVIDIA Corporation, Santa Clara, CA, USA), which demonstrated a processing speed of approximately 11.26 FPS. This computational efficiency, while promising, necessitates further optimization for CCTV applications requiring real-time monitoring capabilities.
Additionally, domain differences present challenges for real-world deployment, as each CCTV camera possesses unique visual characteristics (lighting, angle, installation height, etc.). This variability makes it difficult to guarantee consistent performance across diverse CCTV environments. In the future, we can further enhance the practicality of the system by developing domain adaptation techniques that can adapt to new camera environments with minimal or no target domain data or labels.
Through these improvements, it is expected to develop into an even more practical and effective system, and this research holds significance in expanding the practical application possibilities of computer vision technology.
Author Contributions
Conceptualization, Y.K., B.A. and D.-G.C.; methodology, Y.K.; software, Y.K., H.A. and T.K.; validation, Y.K., H.A. and T.K.; formal analysis, Y.K., H.A. and T.K.; investigation, Y.K., H.A. and T.K.; resources, B.A. and D.-G.C.; writing—original draft preparation, Y.K., H.A. and T.K.; writing—review and editing, Y.K., B.A. and D.-G.C.; visualization, Y.K., H.A. and T.K.; supervision, B.A. and D.-G.C.; project administration, B.A. and D.-G.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Korea Agency for Infrastructure Technology Advancement (KAIA) grant funded by the Ministry of Land, Infrastructure and Transport (No. RS-2023-00238018), and partially supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2023-NR076879).
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Institutional Review Board (or Ethics Committee) of Ministry of Health and Welfare Designated Public Institutional Review Board (protocol code P01-202505-01-067 and date of approval 27 May 2025).
Informed Consent Statement
Written informed consent has been obtained from the patient(s) to publish this paper.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Ganj, A.; Su, H.; Guo, T. HybridDepth: Robust Metric Depth Fusion by Leveraging Depth from Focus and Single-Image Priors. arXiv 2024, arXiv:2407.18443. [Google Scholar]
- Lavreniuk, M. SPIdepth: Strengthened Pose Information for Self-supervised Monocular Depth Estimation. arXiv 2024, arXiv:2404.12501. [Google Scholar]
- He, X.; Guo, D.; Li, H.; Li, R.; Cui, Y.; Zhang, C. Distill Any Depth: Distillation Creates a Stronger Monocular Depth Estimator. arXiv 2025, arXiv:2502.19204. [Google Scholar]
- Liu, K.; Wang, W.; Wang, J. Pedestrian detection with lidar point clouds based on single template matching. Electronics 2019, 8, 780. [Google Scholar] [CrossRef]
- Xu, G.; Wang, X.; Zhang, Z.; Cheng, J.; Liao, C.; Yang, X. IGEV++: Iterative Multi-Range Geometry Encoding Volumes for Stereo Matching. arXiv 2024, arXiv:2409.00638. [Google Scholar] [CrossRef]
- Bartolomei, L.; Tosi, F.; Poggi, M.; Mattoccia, S. Stereo Anywhere: Robust Zero-Shot Deep Stereo Matching Even Where Either Stereo or Mono Fail. arXiv 2024, arXiv:2412.04472. [Google Scholar]
- Jiang, H.; Lou, Z.; Ding, L.; Xu, R.; Tan, M.; Jiang, W.; Huang, R. DEFOM-Stereo: Depth Foundation Model Based Stereo Matching. arXiv 2025, arXiv:2501.09466. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 27, 2366–2374. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12179–12188. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bhat, S.F.; Alhashim, I.; Wonka, P. AdaBins: Depth Estimation Using Adaptive Bins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 4009–4018. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into Self-Supervised Monocular Depth Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 3828–3838. [Google Scholar]
- Zhao, C.; Zhang, Y.; Poggi, M.; Tosi, F.; Guo, X.; Zhu, Z.; Huang, G.; Tang, Y.; Mattoccia, S. Monovit: Self-Supervised Monocular Depth Estimation with a Vision Transformer. In Proceedings of the International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–15 September 2022; pp. 668–678. [Google Scholar]
- Yin, W.; Zhang, C.; Chen, H.; Cai, Z.; Yu, G.; Wang, K.; Chen, X.; Shen, C. Metric3D: Towards Zero-Shot Metric 3D Prediction from a Single Image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 9043–9053. [Google Scholar]
- Hu, M.; Yin, W.; Zhang, C.; Cai, Z.; Long, X.; Chen, H.; Wang, K.; Yu, G.; Shen, C.; Shen, S. Metric3D v2: A Versatile Monocular Geometric Foundation Model for Zero-Shot Metric Depth and Surface Normal Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10579–10596. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskii, A.; Delaunoy, A.; Germain, H.; Santos, M.; Zhou, Y.; Richter, S.R.; Koltun, V. Depth Pro: Sharp Monocular Metric Depth in Less Than a Second. arXiv 2024, arXiv:2410.02073. [Google Scholar]
- Bhat, S.F.; Birkl, R.; Wofk, D.; Wonka, P.; Müller, M. ZoeDepth: Zero-Shot Transfer by Combining Relative and Metric Depth. arXiv 2023, arXiv:2302.12288. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-Pixel Classification Is Not All You Need for Semantic Segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Zhang, C.; Han, D.; Qiao, Y.; Kim, J.U.; Bae, S.-H.; Lee, S.; Hong, C.S. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications. arXiv 2023, arXiv:2306.14289. [Google Scholar]
- Zhao, B.; Cui, Q.; Song, R.; Qiu, Y.; Liang, J. Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11953–11962. [Google Scholar]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast Segment Anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- El Ghazouali, S.; Mhirit, Y.; Oukhrid, A.; Michelucci, U.; Nouira, H. FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything. Sensors 2024, 24, 2889. [Google Scholar] [CrossRef] [PubMed]
- Masoumian, A.; Marei, D.G.F.; Abdulwahab, S.; Cristiano, J.; Puig, D.; Rashwan, H.A. Absolute Distance Prediction Based on Deep Learning Object Detection and Monocular Depth Estimation Models. In Artificial Intelligence Research and Development; IOS Press: Amsterdam, The Netherlands, 2021; pp. 325–334. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Cao, A.-Q.; De Charette, R. MonoScene: Monocular 3D Semantic Scene Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3991–4001. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. PAD-Net: Multi-Tasks Guided Prediction-and-Distillation Network for Simultaneous Depth Estimation and Scene Parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 675–684. [Google Scholar]
- He, L.; Lu, J.; Wang, G.; Song, S.; Zhou, J. Sosd-net: Joint semantic object segmentation and depth estimation from monocular images. Neurocomputing 2021, 440, 251–263. [Google Scholar] [CrossRef]
- Kim, J.H.; Lee, D.S.; Kwon, S.K. Volume Estimation Method for Irregular Object Using RGB-D Deep Learning. Electronics 2025, 14, 919. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Adv. Neural Inf. Process. Syst. 2017, 30, 5574–5584. [Google Scholar]
- Ioffe, S. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Wang, C.; He, S.; Wu, M.; Lam, S.-K.; Tiwari, P.; Gao, X. Looking Clearer with Text: A Hierarchical Context Blending Network for Occluded Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2025, 20, 4296–4307. [Google Scholar] [CrossRef]
- Pang, M.; Roy, T.K.; Wu, X.; Tan, K. CelloType: A unified model for segmentation and classification of tissue images. Nat. Methods 2025, 22, 348–357. [Google Scholar] [CrossRef]
Figure 1.
Overview of the proposed pipeline: This is a framework that estimates planar distance between CCTV and people using CCTV footage. The proposed system consists of three main modules: (1) human detection and segmentation module for generating segmentation masks of human regions, (2) depth estimation module for generating depth maps of the entire image, and (3) distance regression module for noise removal and actual distance conversion.
Figure 1.
Overview of the proposed pipeline: This is a framework that estimates planar distance between CCTV and people using CCTV footage. The proposed system consists of three main modules: (1) human detection and segmentation module for generating segmentation masks of human regions, (2) depth estimation module for generating depth maps of the entire image, and (3) distance regression module for noise removal and actual distance conversion.
Figure 2.
The left column shows CCTV footage used as input for our pipeline. The right column shows the depth map, which is the result of zero-shot monocular depth estimation (DepthPro). As can be observed in the depth map, even without training, it can clearly distinguish human silhouettes and verify the relative depth relationships among people from near to far distances.
Figure 2.
The left column shows CCTV footage used as input for our pipeline. The right column shows the depth map, which is the result of zero-shot monocular depth estimation (DepthPro). As can be observed in the depth map, even without training, it can clearly distinguish human silhouettes and verify the relative depth relationships among people from near to far distances.
Figure 3.
CCTV footage input to the detection network detects human locations, and the detected bounding box information is used as the prompt for SAM to generate segmentation masks. Simultaneously, zero-shot monocular depth estimation generates a complete depth map from the same footage. Background noise is removed by projecting the segmentation mask generated by SAM onto the depth map.
Figure 3.
CCTV footage input to the detection network detects human locations, and the detected bounding box information is used as the prompt for SAM to generate segmentation masks. Simultaneously, zero-shot monocular depth estimation generates a complete depth map from the same footage. Background noise is removed by projecting the segmentation mask generated by SAM onto the depth map.
Figure 4.
Effect of log transformation on KDE: The blue markers represent model predictions using only KDE, while red dots show predictions using both log transformation and KDE. The green cross markers represent original KDE values. The results confirm that red markers (KDE + Log) achieve predictions closer to GT than blue markers, verifying that log transformation improves model prediction accuracy.
Figure 4.
Effect of log transformation on KDE: The blue markers represent model predictions using only KDE, while red dots show predictions using both log transformation and KDE. The green cross markers represent original KDE values. The results confirm that red markers (KDE + Log) achieve predictions closer to GT than blue markers, verifying that log transformation improves model prediction accuracy.
Figure 5.
Overview of the proposed regression pipeline: the model consists of one basic block, two residual blocks, and a final linear layer. The basic block is sequentially structured with a linear layer, batch normalization, and PReLU activation function. The residual block comprises linear layer, batch normalization, PReLU, dropout for preventing overfitting, linear layer, and batch normalization, with this residual block repeated twice. A distance-estimating linear layer is positioned at the model’s final stage.
Figure 5.
Overview of the proposed regression pipeline: the model consists of one basic block, two residual blocks, and a final linear layer. The basic block is sequentially structured with a linear layer, batch normalization, and PReLU activation function. The residual block comprises linear layer, batch normalization, PReLU, dropout for preventing overfitting, linear layer, and batch normalization, with this residual block repeated twice. A distance-estimating linear layer is positioned at the model’s final stage.
Figure 6.
Examples from our dataset constructed by installing cameras at 2 m height to simulate CCTV environments. Six test subjects were positioned at 5 m intervals from 5 m to 30 m, and their walking motions were recorded at each distance. To ensure data diversity, the subjects’ positions were randomly assigned. Each image was labeled with actual distance information, and the final dataset consists of 30 training images and 1612 test images.
Figure 6.
Examples from our dataset constructed by installing cameras at 2 m height to simulate CCTV environments. Six test subjects were positioned at 5 m intervals from 5 m to 30 m, and their walking motions were recorded at each distance. To ensure data diversity, the subjects’ positions were randomly assigned. Each image was labeled with actual distance information, and the final dataset consists of 30 training images and 1612 test images.
Figure 7.
Polynomial regression performance comparison: MAE of polynomial regression models in original space (None + Ridge, None + Lasso) and log space (Log + Ridge, Log + Lasso). represents the regularization coefficient. The upper-left graph (None + Ridge) shows low MAE at the 7th-degree polynomials, while the lower-left graph (Log + Ridge) shows low MAE at the 12th-degree polynomials. The upper-right (None + Lasso) shows low MAE at the 10th-degree polynomials, while the lower-right (Log + Lasso) shows low MAE at the 35th-degree polynomials. Overall, models applying log transformation demonstrate lower MAE and maintain stable performance particularly in high-degree polynomials.
Figure 7.
Polynomial regression performance comparison: MAE of polynomial regression models in original space (None + Ridge, None + Lasso) and log space (Log + Ridge, Log + Lasso). represents the regularization coefficient. The upper-left graph (None + Ridge) shows low MAE at the 7th-degree polynomials, while the lower-left graph (Log + Ridge) shows low MAE at the 12th-degree polynomials. The upper-right (None + Lasso) shows low MAE at the 10th-degree polynomials, while the lower-right (Log + Lasso) shows low MAE at the 35th-degree polynomials. Overall, models applying log transformation demonstrate lower MAE and maintain stable performance particularly in high-degree polynomials.
Figure 8.
KDE results for various kernel sizes. The black line shows results applying Scott’s rule, the blue line shows results applying Silverman’s rule, and the green, red, and sky-blue lines show the results of multiplying Scott’s rule by 0.1, 0.2, and 0.3, respectively.
Figure 8.
KDE results for various kernel sizes. The black line shows results applying Scott’s rule, the blue line shows results applying Silverman’s rule, and the green, red, and sky-blue lines show the results of multiplying Scott’s rule by 0.1, 0.2, and 0.3, respectively.
Figure 9.
Error rate analysis by distance class. The graph demonstrates the relationship between distance from camera and Mean Absolute Error (MAE) percentage. The error rate exhibits a non-linear increase from 1.15% at 5 m to 4.65% at 20 m, followed by a slight stabilization at longer distances (4.24% at 25 m and 4.46% at 30 m). This pattern validates that while error increases with distance, the proposed system maintains consistent performance below 5% error across the entire measurement range.
Figure 9.
Error rate analysis by distance class. The graph demonstrates the relationship between distance from camera and Mean Absolute Error (MAE) percentage. The error rate exhibits a non-linear increase from 1.15% at 5 m to 4.65% at 20 m, followed by a slight stabilization at longer distances (4.24% at 25 m and 4.46% at 30 m). This pattern validates that while error increases with distance, the proposed system maintains consistent performance below 5% error across the entire measurement range.
Table 1.
Effect of log-space learning in deep learning models: MAE for baseline and log-space learning methods applied to Metric3D v2 and DepthPro models. Here, the baseline refers to models using only object detection results (bounding box) with KDE (Kernel Density Estimation). The downward arrow (↓) indicates that lower MAE values represent better performance. All results were obtained under identical conditions.
Table 1.
Effect of log-space learning in deep learning models: MAE for baseline and log-space learning methods applied to Metric3D v2 and DepthPro models. Here, the baseline refers to models using only object detection results (bounding box) with KDE (Kernel Density Estimation). The downward arrow (↓) indicates that lower MAE values represent better performance. All results were obtained under identical conditions.
| Model | Method | MAE (m) ↓ |
|---|
| Metric3D v2 | Baseline (bbox + KDE) | 0.75879 |
| + Log Space | 0.74905 |
| DepthPro | Baseline | 0.83525 |
| + Log Space | 0.82067 |
Table 2.
Comparison of object localization strategies: MAE comparison for Metric3Dv2 and DepthPro models with log-space learning applied. The downward arrow (↓) indicates that lower MAE values represent better performance.
Table 2.
Comparison of object localization strategies: MAE comparison for Metric3Dv2 and DepthPro models with log-space learning applied. The downward arrow (↓) indicates that lower MAE values represent better performance.
| Model | Localization Method | Approach | MAE (m) ↓ |
|---|
| Metric3D v2 + log | Detection | Crop 0% | 0.74905 |
| Crop 30% | 0.77006 |
| Crop 50% | 0.78596 |
| Crop 70% | 0.76993 |
| Segmentation | SAM | 0.72007 |
| DepthPro + log | Detection | Crop 0% | 0.82067 |
| Crop 30% | 0.77179 |
| Crop 50% | 0.68838 |
| Crop 70% | 0.70722 |
| Segmentation | SAM | 0.65280 |
Table 3.
Comparison of density estimation methods: Performance comparison of KDE with various kernel sizes in models where DepthPro, SAM, and log-space learning are applied. The downward arrow (↓) indicates that lower MAE values represent better performance.
Table 3.
Comparison of density estimation methods: Performance comparison of KDE with various kernel sizes in models where DepthPro, SAM, and log-space learning are applied. The downward arrow (↓) indicates that lower MAE values represent better performance.
| Model | Method | Kernel Size | MAE (m) ↓ |
|---|
| DepthPro + SAM + log | KDE | Silverman’s | 0.69061 |
| Scott’s | 0.67576 |
| Scott’s × 0.1 | 0.73996 |
| Scott’s × 0.2 | 0.65280 |
| Scott’s × 0.3 | 0.65490 |
Table 4.
Effect of training data size using the best kernel configuration (Scott’s × 0.2). The downward arrow (↓) indicates that lower MAE values represent better performance.
Table 4.
Effect of training data size using the best kernel configuration (Scott’s × 0.2). The downward arrow (↓) indicates that lower MAE values represent better performance.
| Model | Method | Training Images | MAE (m) ↓ |
|---|
| DepthPro + SAM + log | KDE (Scott’s × 0.2) | 10 | 0.66416 |
| 20 | 0.66120 |
| 30 | 0.65280 |
Table 5.
Performance comparison analysis based on KDE input size (N). The downward arrow (↓) indicates that lower MAE values represent better performance.
Table 5.
Performance comparison analysis based on KDE input size (N). The downward arrow (↓) indicates that lower MAE values represent better performance.
| Model | KDE (N) | MAE (m) ↓ |
|---|
| Depth Pro + SAM + log | 300 | 0.68959 |
| 500 | 0.68433 |
| 750 | 0.65280 |
| 1000 | 0.66429 |
| 1200 | 0.68450 |
Table 6.
Performance comparison analysis between daytime and nighttime conditions. The downward arrow (↓) indicates that lower MAE values represent better performance.
Table 6.
Performance comparison analysis between daytime and nighttime conditions. The downward arrow (↓) indicates that lower MAE values represent better performance.
| Model | Condition | MAE (m) ↓ |
|---|
| DepthPro + SAM + log | Daytime | 0.65280 |
| Nighttime | 0.90308 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}