
Multilevel Pyramid Network for Monocular Depth Estimation Based on Feature Refinement and Adaptive Fusion


Abstract
:1. Introduction
- In addition to extracting contextual features, we also developed a multilevel spatial feature generation module to extract rich spatial features containing better details.
- We designed a spatial attention-based feature refinement module that enhances multilevel information to derive detailed information.
- We utilized fully connected fusion to enrich the representation of each level feature. Moreover, an adaptive fusion block is designed to fuse fully connected features according to the reliability of features.
- An efficient hybrid loss function and loss terms reweighted scheme are explored for multilevel outputs to provide depth details.
2. Related Work
2.1. Supervised Learning
2.2. Self-Supervised Learning
3. Proposed Method
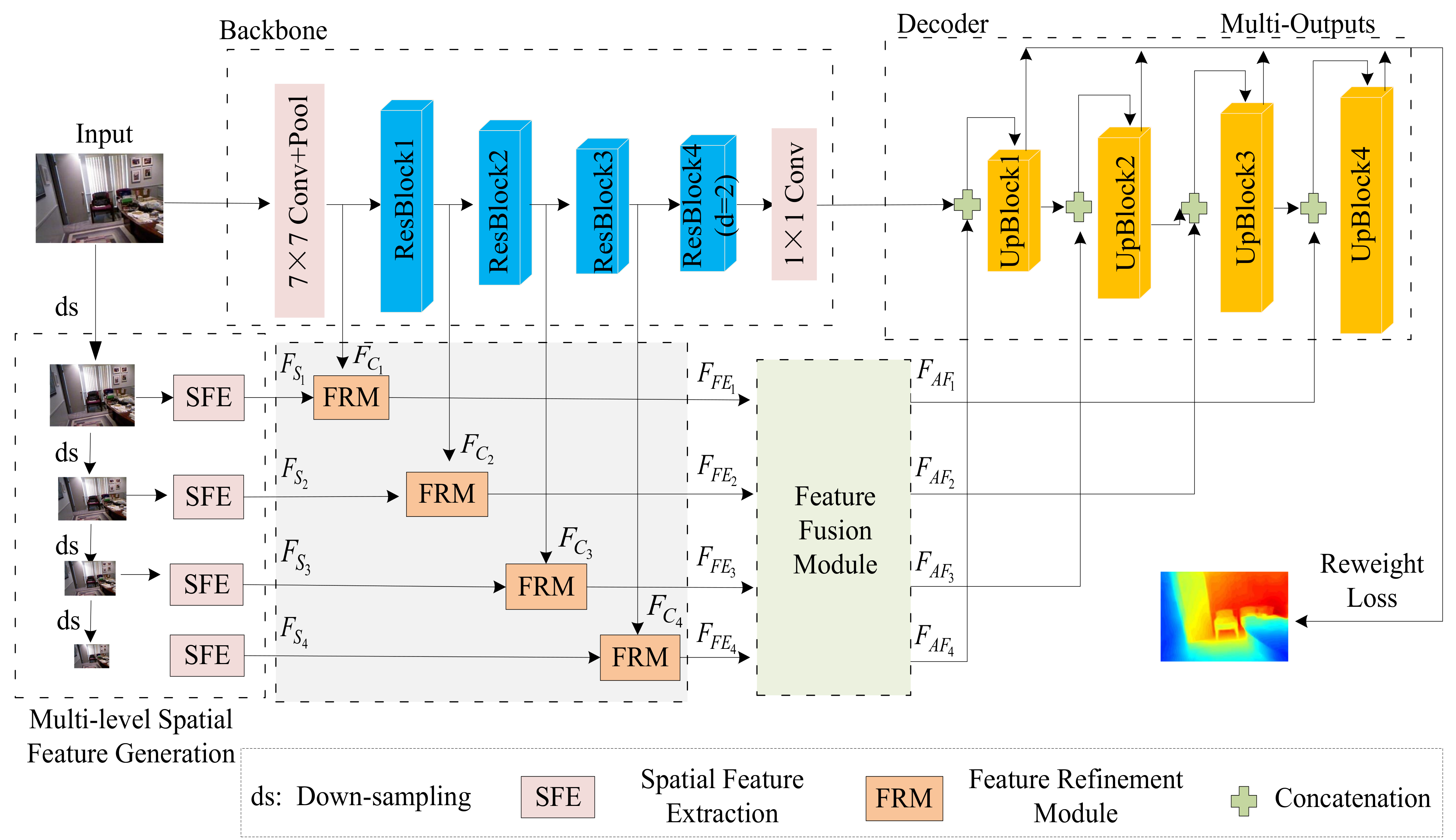
3.1. Network Architecture
3.2. Multi-Level Spatial Feature Generation Module (MSFGM)
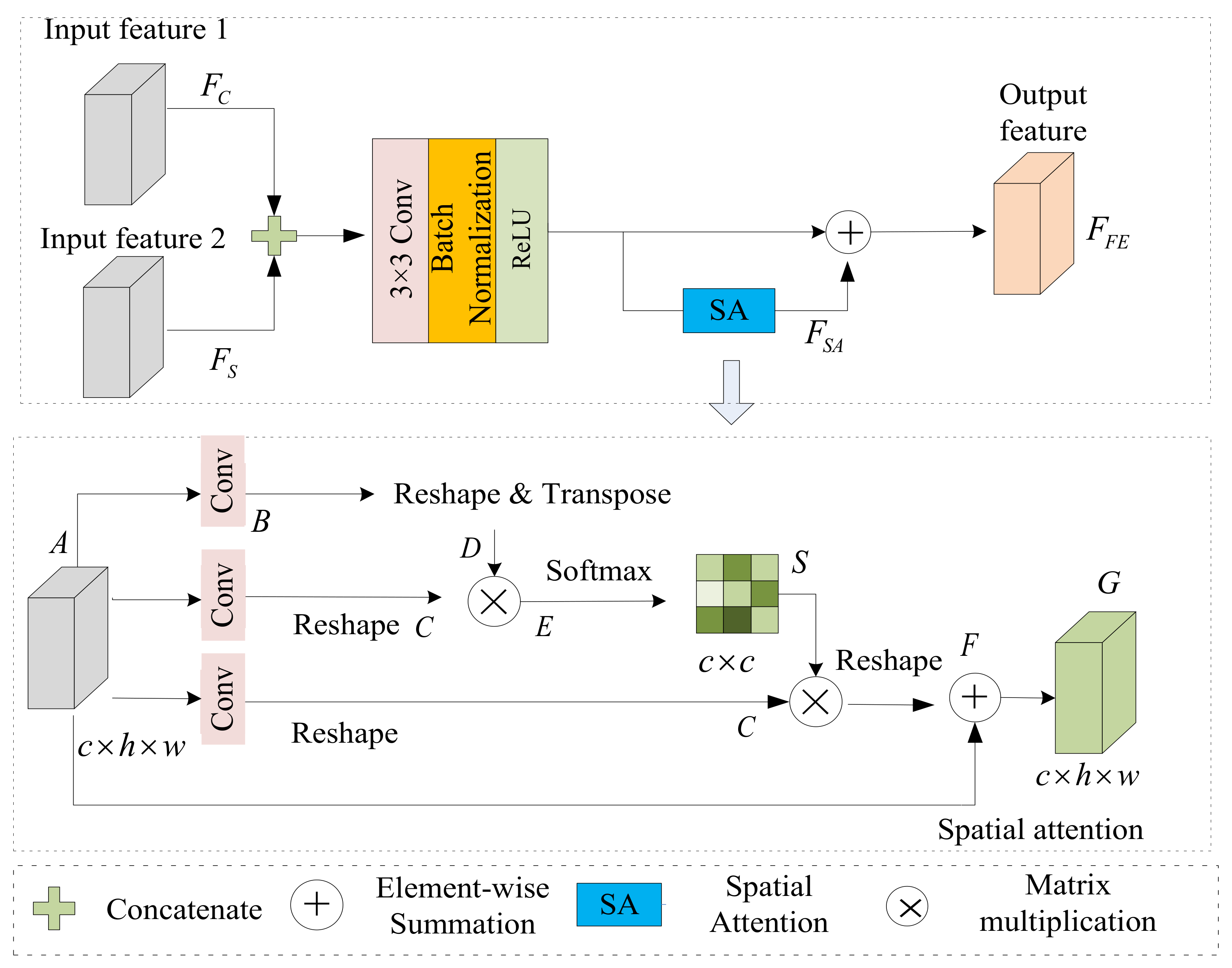
3.3. Feature Refinement Module (FRM)
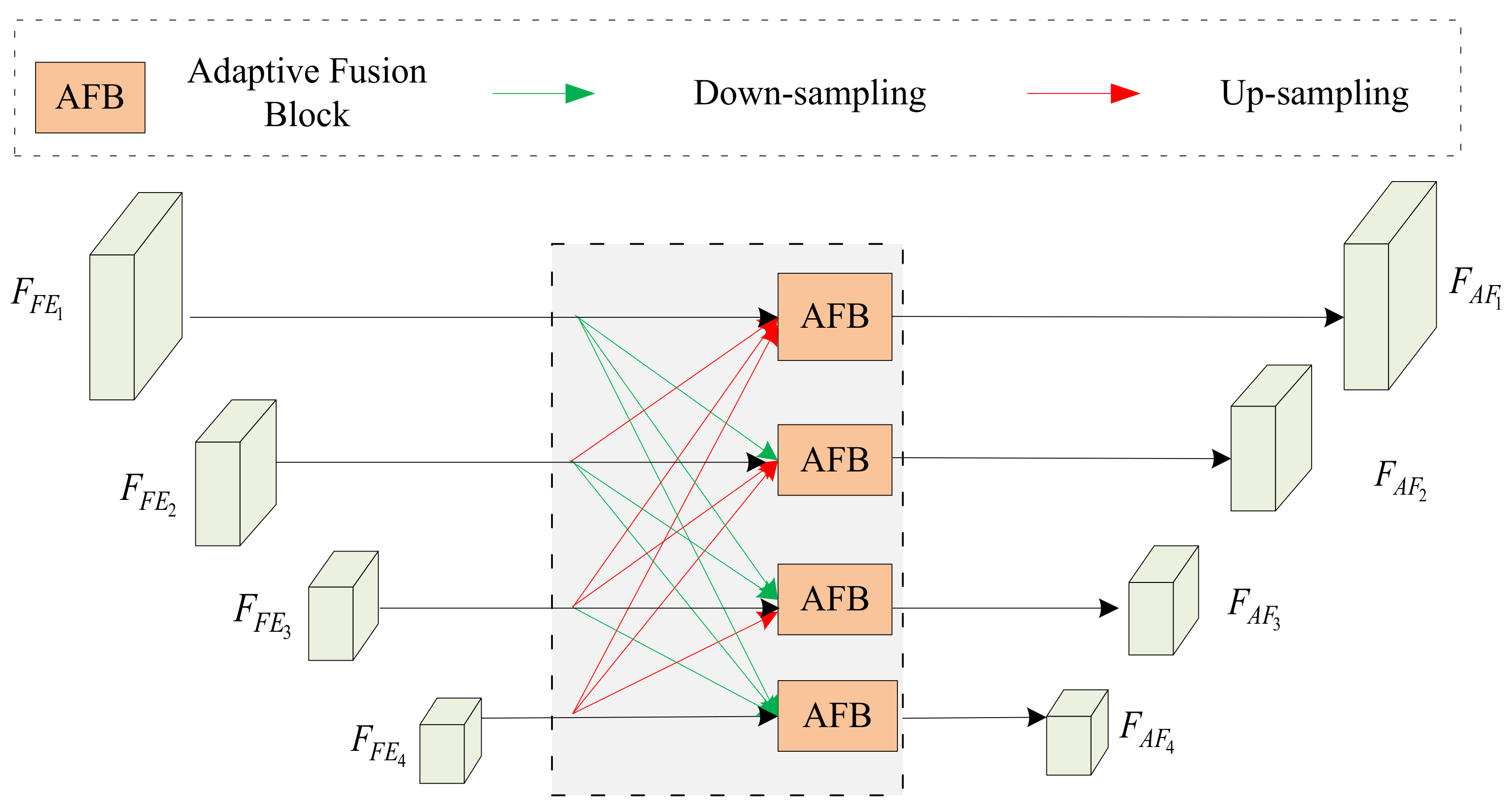
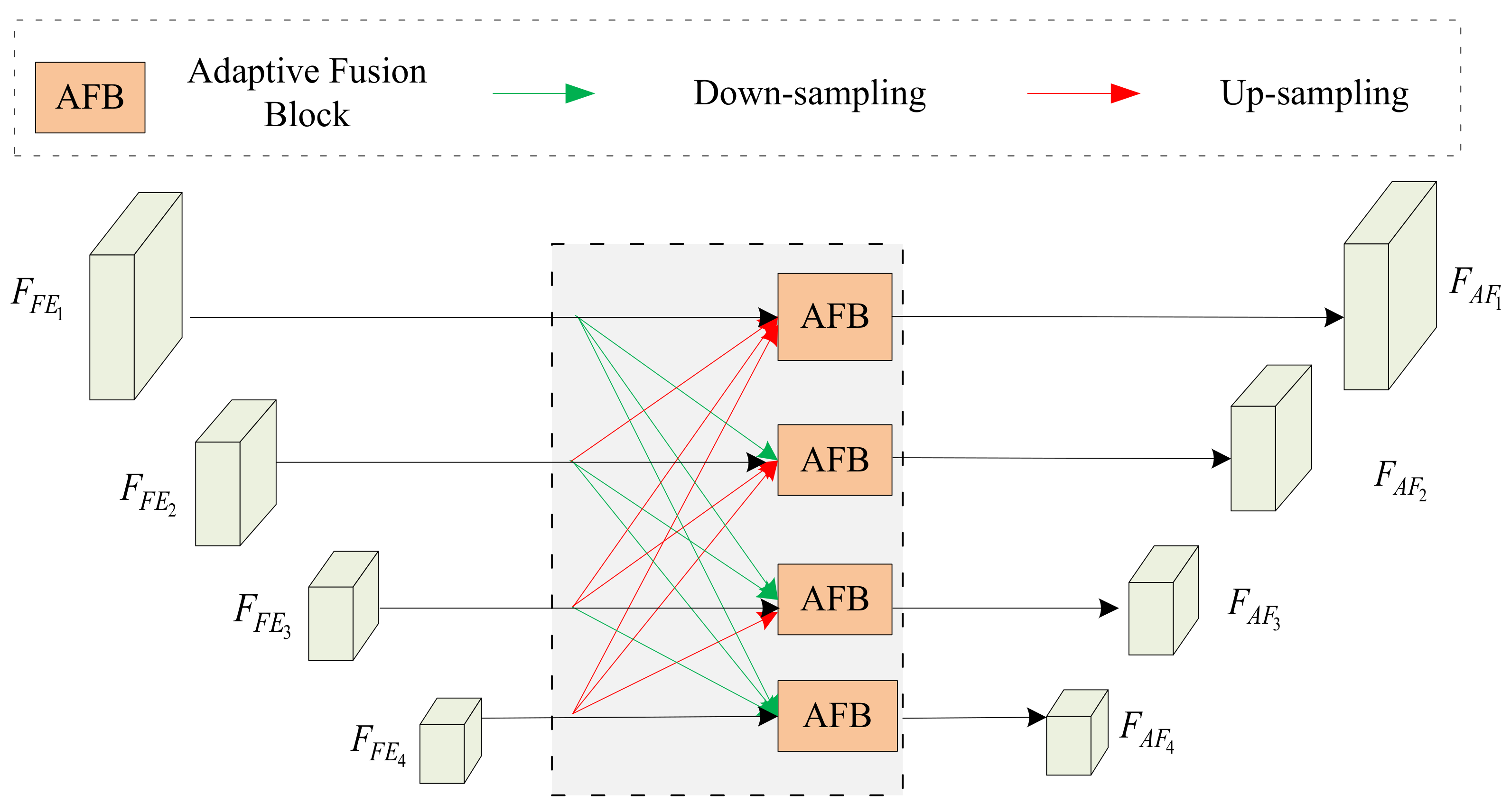
3.4. Feature Fusion Module (FFM)
3.5. Loss Function
4. Experimental Results
- (1)
- Root-mean-squared error (RMSE(lin)): ;
- (2)
- Root-mean-squared error (RMSE(log)): ;
- (3)
- Mean log10 error (log10): ;
- (4)
- Mean relative error (Rel): ;
- (5)
- Threshold (): percentage of , i.e., .
4.1. Qualitative Comparison
4.2. Quantitative Comparison
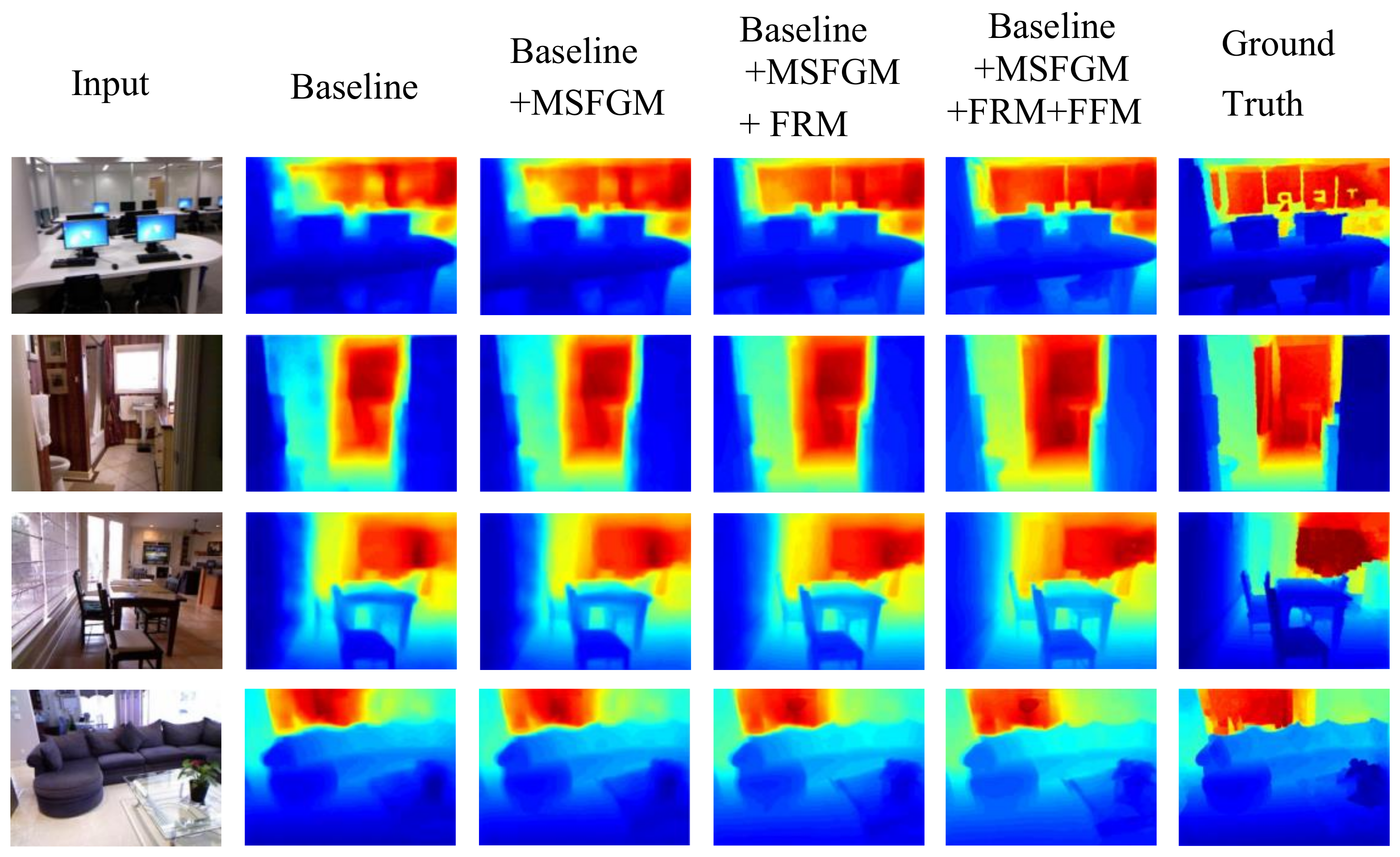
4.3. Ablation Study
4.4. Generalization
4.5. Application: 3D Reconstruction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, S.; Sun, S.; Yan, W.; Liu, G.; Li, X. A Method Based on Curvature and Hierarchical Strategy for Dynamic Point Cloud Compression in Augmented and Virtual Reality System. Sensors 2022, 22, 1262. [Google Scholar] [CrossRef] [PubMed]
- Bertels, M.; Jutzi, B.; Ulrich, M. Automatic Real-Time Pose Estimation of Machinery from Images. Sensors 2022, 22, 2627. [Google Scholar] [CrossRef] [PubMed]
- Nie, X.; Min, C.; Pan, Y.; Li, K.; Li, Z. Deep-neural-network-based modelling of longitudinal-lateral dynamics to predict the vehicle states for autonomous driving. Sensors 2022, 22, 2013. [Google Scholar] [CrossRef]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2650–2658. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Hu, J.; Ozay, M.; Zhang, Y.; Okatani, T. Revisiting single image depth estimation: Toward higher resolution maps with accurate object boundaries. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1043–1051. [Google Scholar]
- Su, W.; Zhang, H.; Su, Y. Monocular depth estimation with spatially coherent sliced network. Image Vis. Comput. 2022, 124, 104487. [Google Scholar] [CrossRef]
- Tao, B.; Chen, X.; Tong, X. Self-Supervised Monocular Depth Estimation Based on Channel Attention. Photonics 2022, 9, 434. [Google Scholar] [CrossRef]
- Kim, D.; Ga, W.; Ahn, P. Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth. arXiv 2022, arXiv:2201.07436. [Google Scholar]
- Swami, K.; Muduli, A.; Gurram, U. Do What You Can, with What You Have: Scale-Aware and High Quality Monocular Depth Estimation without Real World Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 988–997. [Google Scholar]
- Ma, H.; Ding, Y.; Wang, L. Depth Estimation from Monocular Images Using Dilated Convolution and Uncertainty Learning. In Proceedings of the Pacific Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; pp. 13–23. [Google Scholar]
- Petrovai, A.; Nedevschi, S. Exploiting Pseudo Labels in a Self-Supervised Learning Framework for Improved Monocular Depth Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1578–1588. [Google Scholar]
- Wang, X.; Fu, X.; Dong, Q. Image Depth Estimation Model Based on Fully Convolutional U-Net. Comput. Sci. Appl. 2019, 9, 250–255. [Google Scholar]
- Xu, H.; Li, F.; Feng, Z. MLFFNet: Multilevel feature fusion network for monocular depth estimation from aerial images. J. Appl. Remote Sens. 2022, 16, 026506. [Google Scholar] [CrossRef]
- Sagar, A. Monocular depth estimation using multi scale neural network and feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 4–8 January 2022; pp. 656–662. [Google Scholar]
- Agarwal, A.; Arora, C. Depthformer: Multiscale Vision Transformer for Monocular Depth Estimation with Local Global Information Fusion. arXiv 2022, arXiv:2207.04535. [Google Scholar]
- Ye, X.; Chen, S.; Xu, R. DPNet: Detail-preserving network for high-quality monocular depth estimation. Pattern Recognit. 2021, 109, 107578. [Google Scholar] [CrossRef]
- Pei, M. MSFNet: Multi-scale features network for monocular depth estimation. arXiv 2021, arXiv:2107.06445. [Google Scholar]
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-based context aggregation network for monocular depth estimation. Int. J. Mach. Learn. Cybern. 2021, 12, 1583–1596. [Google Scholar] [CrossRef]
- Wei, J.; Pan, S.; Gao, W. Triaxial Squeeze Attention Module and Mutual-Exclusion Loss Based Unsupervised Monocular Depth Estimation. Neural Process. Lett. 2022, 1–16. [Google Scholar] [CrossRef]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [Green Version]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2002–2011. [Google Scholar]
- Song, M.; Lim, S.; Kim, W. Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4381–4393. [Google Scholar] [CrossRef]
- Wu, J.; Ji, R.; Wang, Q. Fast Monocular Depth Estimation via Side Prediction Aggregation with Continuous Spatial Refinement. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Gao, T.; Wei, W.; Cai, Z. CI-Net: A joint depth estimation and semantic segmentation network using contextual information. Appl. Intell. 2022, 1–20. [Google Scholar] [CrossRef]
- Zhao, X.; Pang, Y.; Zhang, L. Joint Learning of Salient Object Detection, Depth Estimation and Contour Extraction. arXiv 2022, arXiv:2203.04895. [Google Scholar]
- Wang, Y.; Zhu, H.; Liu, M. CNNapsule: A Lightweight Network with Fusion Features for Monocular Depth Estimation. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021; pp. 507–518. [Google Scholar]
- Liu, S.; Yang, L.T.; Tu, X. Lightweight Monocular Depth Estimation on Edge Devices. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Firman, M. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Watson, J.; Firman, M.; Brostow, G.J. Self-supervised monocular depth hints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2162–2171. [Google Scholar]
- Wong, A.; Soatto, S. Bilateral cyclic constraint and adaptive regularization for unsupervised monocular depth prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5644–5653. [Google Scholar]
- Tosi, F.; Aleotti, F.; Poggi, M.; Mattoccia, S. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9799–9809. [Google Scholar]
- Ling, C.; Zhang, X.; Chen, H. Unsupervised Monocular Depth Estimation using Attention and Multi-Warp Reconstruction. IEEE Trans. Multimed. 2021, 24, 2938–2949. [Google Scholar] [CrossRef]
- Ye, X.; Fan, X.; Zhang, M.; Xu, R.; Zhong, W. Unsupervised Monocular Depth Estimation via Recursive Stereo Distillation. IEEE Trans. Image Process. 2021, 30, 4492–4504. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q.; Tang, Y.; Zhang, C.; Zhao, C.; Qian, F.; Kurths, J. Unsupervised Estimation of Monocular Depth and VO in Dynamic Environments via Hybrid Masks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2023–2033. [Google Scholar] [CrossRef] [PubMed]
- Chiu, M.-J.; Chiu, W.C.; Chen, H.T.; Chuang, J.H. Real-time Monocular Depth Estimation with Extremely Light-Weight Neural Network. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Varma, A.; Chawla, H.; Zonooz, B.; Arani, E. Transformers in Self-Supervised Monocular Depth Estimation with Unknown Camera Intrinsics. arXiv 2022, arXiv:2202.03131. [Google Scholar]
- Yang, J.; An, L.; Dixit, A. Depth Estimation with Simplified Transformer. arXiv 2022, arXiv:2204.13791. [Google Scholar]
- Mendoza, J.; Pedrini, H. Self-distilled Self-supervised Depth Estimation in Monocular Videos. In Proceedings of the International Conference on Pattern Recognition and Artificial Intelligence, Chengdu, China, 19–21 August 2022; pp. 423–434. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; An, S.; Zhang, Y.; Ma, C.; Wang, H.; Guo, X.; Zheng, W. Improving monocular depth estimation by leveraging structural awareness and complementary datasets. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 90–108. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, M.; Le Saux, B.; Trouvé-Peloux, P.; Almansa, A.; Champagnat, F. On regression losses for deep depth estimation. In Proceedings of the 2018 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 2915–2919. [Google Scholar]
- Moukari, M.; Picard, S.; Simon, L.; Jurie, F. Deep multi-scale architectures for monocular depth estimation. In Proceedings of the 2018 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 2940–2944. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale continuous crfs as sequential deep networks for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5354–5362. [Google Scholar]
- Jiang, H.; Huang, R. High quality monocular depth estimation via a multi-scale network and a detail-preserving objective. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Wang, L.; Zhang, J.; Wang, O.; Lin, Z.; Lu, H. Sdc-depth: Semantic divide-and-conquer network for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 541–550. [Google Scholar]
- Lee, J.H.; Kim, C.S. Monocular depth estimation using relative depth maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9729–9738. [Google Scholar]
- Ramamonjisoa, M.; Lepetit, V. Sharpnet: Fast and accurate recovery of occluding contours in monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Liu, P.; Zhang, Z.H.; Meng, H.; Gao, N. Joint attention mechanisms for monocular depth estimation with multi-scale convolutions and adaptive weight adjustment. IEEE Access 2020, 8, 184437–184450. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Y.; Cui, J.; Feng, Y.; Pang, L. Fully convolutional multi-scale dense networks for monocular depth estimation. IET Comput. Vis. 2019, 13, 515–522. [Google Scholar] [CrossRef]
- Fang, Z.; Chen, X.; Chen, Y.; Gool, L.V. Towards good practice for CNN-based monocular depth estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 2–5 March 2020; pp. 1091–1100. [Google Scholar]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Chen, S.; Fan, X.; Pu, Z.; Ouyang, J.; Zou, B. Single image depth estimation based on sculpture strategy. Knowl. Based Syst. 2022, 250, 109067. [Google Scholar] [CrossRef]
- Gan, Y.; Xu, X.; Sun, W.; Lin, L. Monocular depth estimation with affinity, vertical pooling, and label enhancement. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 232–247. [Google Scholar]
- Fang, S.; Jin, R.; Cao, Y. Fast depth estimation from single image using structured forest. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4022–4026. [Google Scholar]
- Kim, Y.; Jung, H.; Min, D.; Sohn, K. Deep monocular depth estimation via integration of global and local predictions. IEEE Trans. Image Process. 2018, 27, 4131–4144. [Google Scholar] [CrossRef] [PubMed]
- Kuznietsov, Y.; Stuckler, J.; Leibe, B. Semisupervised deep learning for monocular depth map prediction. In Proceedings of the IEEE Conference on Computer Vision Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2215–2223. [Google Scholar]
- Chakrabarti, S.A.; Shakhnarovich, J.G. Depth from a single image by harmonizing overcomplete local network predictions. arXiv 2016, arXiv:1605.0708. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view rgb-d object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | RMSE(lin) | log10 | Rel | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|
| Eigen et al. [4] | 0.907 | NR | 0.215 | 0.611 | 0.887 | 0.971 |
| Carvalho et al. [45] | 0.600 | 0.059 | 0.135 | 0.819 | 0.957 | 0.987 |
| Moukari et al. [46] | 0.569 | 0.057 | 0.133 | 0.830 | 0.966 | 0.993 |
| Xu et al. [47] | 0.586 | 0.052 | 0.121 | 0.811 | 0.954 | 0.987 |
| Liu et al. [21] | 0.824 | 0.095 | 0.230 | 0.614 | 0.883 | 0.971 |
| Laina et al. [5] | 0.573 | 0.055 | 0.127 | 0.811 | 0.953 | 0.988 |
| Jiang et al. [48] | 0.468 | 0.054 | 0.127 | 0.841 | 0.966 | 0.993 |
| Wang et al. [49] | 0.497 | NR | 0.128 | 0.845 | 0.966 | 0.990 |
| Lee et al. [50] | 0.538 | NR | NR | 0.837 | 0.971 | 0.994 |
| Fu et al. [22] | 0.509 | 0.051 | 0.115 | 0.828 | 0.965 | 0.992 |
| Ye et al. [17] | 0.474 | 0.063 | NR | 0.784 | 0.948 | 0.986 |
| Pei et al. [18] | 0.531 | 0.051 | 0.118 | 0.865 | 0.975 | 0.993 |
| SharpNet [51] | 0.502 | NR | 0.139 | 0.836 | 0.966 | 0.990 |
| Liu et al. [52] | 0.523 | 0.049 | 0.113 | 0.872 | 0.975 | 0.993 |
| Our method | 0.463 | 0.049 | 0.115 | 0.868 | 0.977 | 0.993 |
| Methods | Type | RMSE(lin) | Rel | RMSE(log) | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|---|
| Godard et al. [29] | Stereo | 4.863 | 0.115 | 0.193 | 0.877 | 0.959 | 0.981 |
| Watson et al. [30] | Stereo | 4.695 | 0.106 | 0.193 | 0.875 | 0.958 | 0.980 |
| Wong et al. [31] | Stereo | 4.172 | 0.126 | 0.217 | 0.840 | 0.941 | 0.973 |
| Tosi et al. [32] | Stereo | 4.714 | 0.111 | 0.199 | 0.864 | 0.954 | 0.979 |
| Ling et al. [33] | Stereo | 5.206 | 0.121 | 0.214 | 0.843 | 0.944 | 0.975 |
| Ye et al. [34] | Stereo | 4.810 | 0.105 | 0.196 | 0.861 | 0.947 | 0.978 |
| Eigen et al. [5] | Depth | 7.156 | 0.190 | 0.246 | 0.692 | 0.899 | 0.967 |
| Liu et al. [53] | Depth | 4.977 | 0.127 | NR | 0.838 | 0.948 | 0.980 |
| Fang et al. [54] | Depth | 4.075 | 0.098 | 0.174 | 0.889 | 0.963 | 0.985 |
| Ye et al. [17] | Depth | 4.978 | 0.112 | 0.210 | 0.842 | 0.947 | 0.973 |
| Pei et al. [18] | Depth | 4.054 | 0.098 | NR | 0.893 | 0.968 | 0.987 |
| Alhashim et al. [55] | Depth | 4.170 | 0.093 | NR | 0.886 | 0.963 | 0.986 |
| Chen et al. [56] | Depth | 3.597 | 0.095 | 0.159 | 0.893 | 0.970 | 0.989 |
| Gan et al. [57] | Depth | 3.933 | 0.098 | 0.173 | 0.890 | 0.964 | 0.985 |
| Our method | Depth | 3.842 | 0.092 | 0.185 | 0.895 | 0.974 | 0.990 |
| Methods | RMSE(lin) | log10 | Rel |
|---|---|---|---|
| Fang et al. [58] | 7.39 | 0.117 | 0.334 |
| Liu et al. [21] | 8.6 | 0.119 | 0.314 |
| Laina et al. [5] | 4.46 | 0.072 | 0.176 |
| Liu et al. [52] | 13.8 | 0.138 | 0.346 |
| Xu et al. [47] | 4.38 | 0.065 | 0.184 |
| Kim et al. [59] | 4.85 | 0.058 | 0.141 |
| Ye et al. [17] | 4.17 | 0.062 | 0.171 |
| Godard et al. [29] | 7.417 | 0.163 | 0.322 |
| Ling et al. [33] | 7.745 | NR | 0.352 |
| Kuznietsov et al. [60] | NR | 0.190 | 0.421 |
| Our method | 4.10 | 0.056 | 0.162 |
| Methods | RMSE(lin) | log10 | Rel | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|
| Baseline | 0.561 | 0.073 | 0.163 | 0.737 | 0.928 | 0.990 |
| Baseline + MSFGM | 0.552 | 0.069 | 0.138 | 0.743 | 0.933 | 0.991 |
| Baseline + MSFGM + FRM | 0.498 | 0.059 | 0.125 | 0.806 | 0.953 | 0.992 |
| Baseline + MSFGM + FRM + FFM | 0.463 | 0.049 | 0.115 | 0.868 | 0.977 | 0.993 |
| Loss Terms | RMSE(lin) | log10 | Rel | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|
| Lberhu + Lgra | 0.483 | 0.060 | 0.115 | 0.853 | 0.969 | 0.992 |
| Lberhu + Lgra + Lrel | 0.480 | 0.060 | 0.116 | 0.856 | 0.970 | 0.993 |
| Lberhu + Lgra + Lrel + RW | 0.463 | 0.049 | 0.115 | 0.868 | 0.977 | 0.993 |
| Backbone | RMSE(lin) | log10 | Rel | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|
| VGG19 | 0.615 | 0.073 | 0.756 | 0.936 | 0.980 | VGG19 |
| ResNet50 | 0.556 | 0.064 | 0.809 | 0.954 | 0.983 | ResNet50 |
| Ours | 0.463 | 0.049 | 0.868 | 0.977 | 0.993 | Ours |
| Methods | Time (ms) |
|---|---|
| Eigen [4] | 201.3 |
| Liu et al. [21] | 175.2 |
| Laina et al. [5] | 72.4 |
| Chakrabarti et al. [61] | 150.3 |
| Ours (Resnet50) | 70.5 |
| Ours | 81.3 |
| Methods | RMSE(lin) | log10 | Rel | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|
| Hu et al. [6] | 1.551 | 0.196 | 0.340 | 0.179 | 0.547 | 0.849 |
| Liu et al. [21] | 2.254 | 0.205 | 0.356 | 0.162 | 0.497 | 0.816 |
| Laina et al. [5] | 1.896 | 0.200 | 0.344 | 0.168 | 0.531 | 0.827 |
| Our method | 1.449 | 0.199 | 0.337 | 0.173 | 0.601 | 0.855 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Li, F. Multilevel Pyramid Network for Monocular Depth Estimation Based on Feature Refinement and Adaptive Fusion. Electronics 2022, 11, 2615. https://doi.org/10.3390/electronics11162615
Xu H, Li F. Multilevel Pyramid Network for Monocular Depth Estimation Based on Feature Refinement and Adaptive Fusion. Electronics. 2022; 11(16):2615. https://doi.org/10.3390/electronics11162615
Chicago/Turabian StyleXu, Huihui, and Fei Li. 2022. "Multilevel Pyramid Network for Monocular Depth Estimation Based on Feature Refinement and Adaptive Fusion" Electronics 11, no. 16: 2615. https://doi.org/10.3390/electronics11162615
APA StyleXu, H., & Li, F. (2022). Multilevel Pyramid Network for Monocular Depth Estimation Based on Feature Refinement and Adaptive Fusion. Electronics, 11(16), 2615. https://doi.org/10.3390/electronics11162615