
Real-Time Low-Light Imaging in Space Based on the Fusion of Spatial and Frequency Domains

Abstract
:1. Introduction
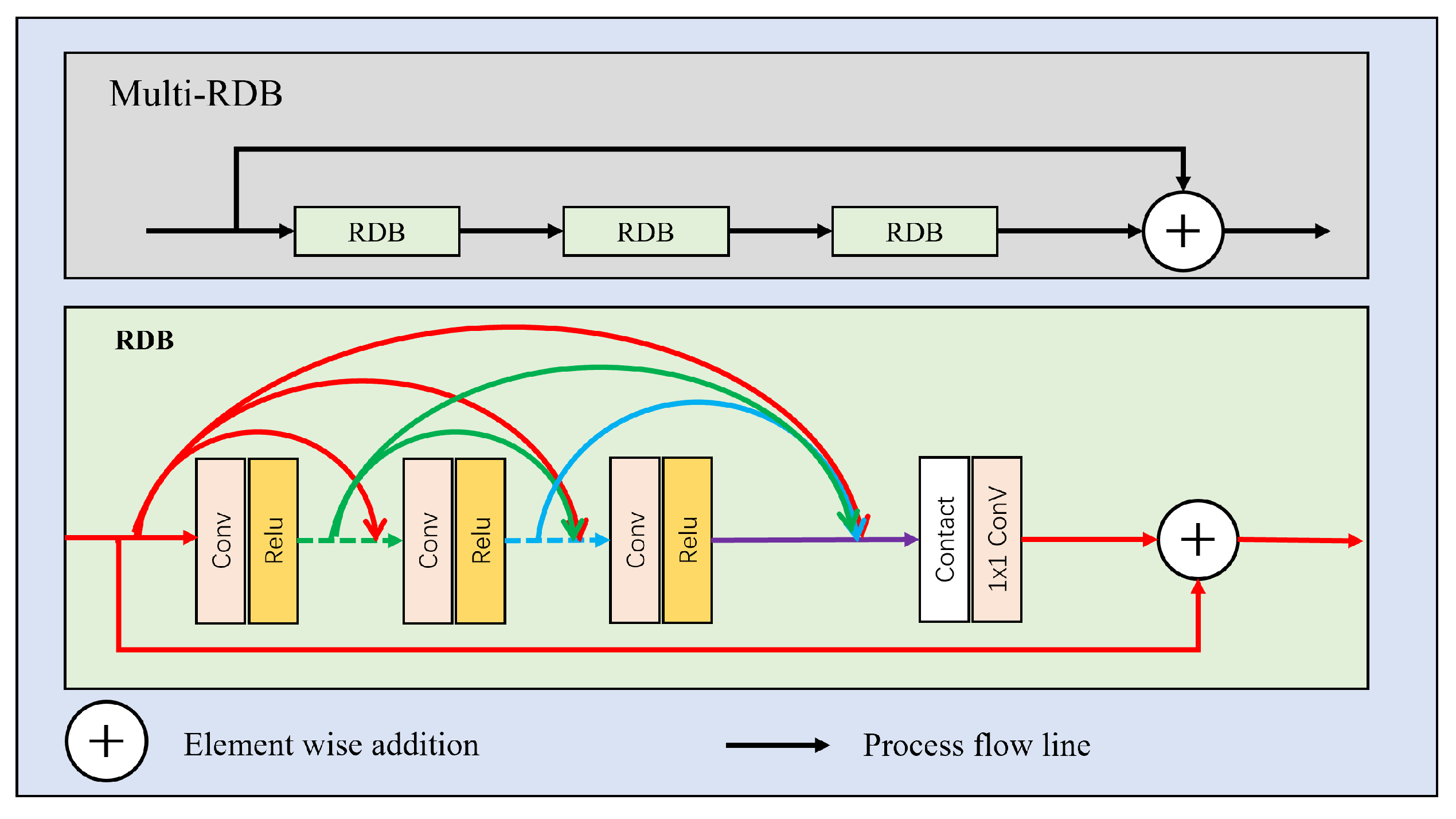
- We constructed a lightweight end-to-end network that processes image data obtained from the original sensor through multi-scale parallel processing, greatly reducing the image acquisition time;
- The multi-scale image processing branch incorporates both spatial- and frequency-domain fusion networks, reducing the network parameters and computational complexity while ensuring image restoration quality;
- We introduced an adaptive balancing mechanism as a pre-processing step to enhance the effectiveness of lightweight application models.
2. Related Work
2.1. Lightweight Models
2.2. Low-Light Image Enhancement
2.3. Frequency-Domain Processing of Images
3. Methods
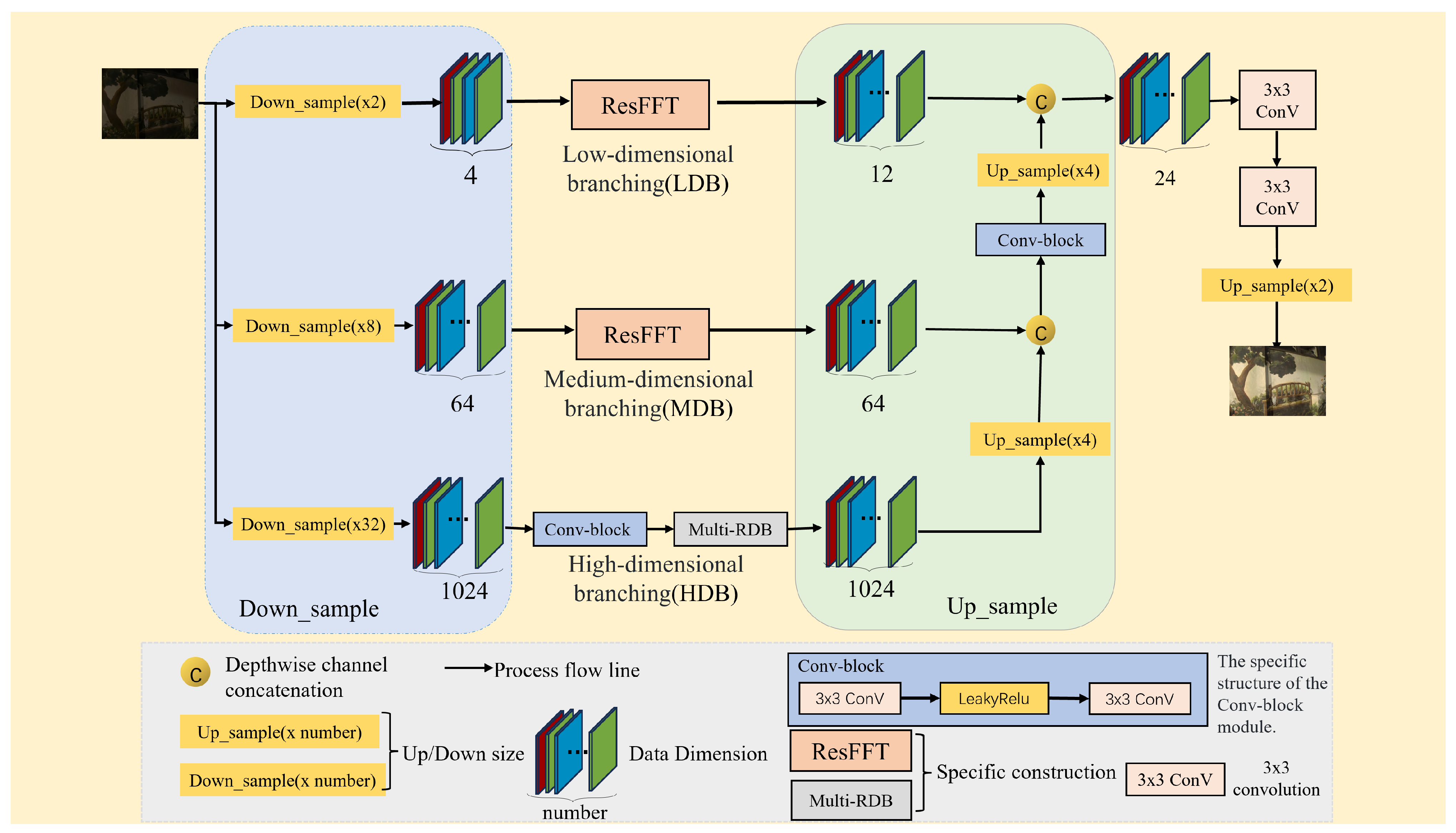
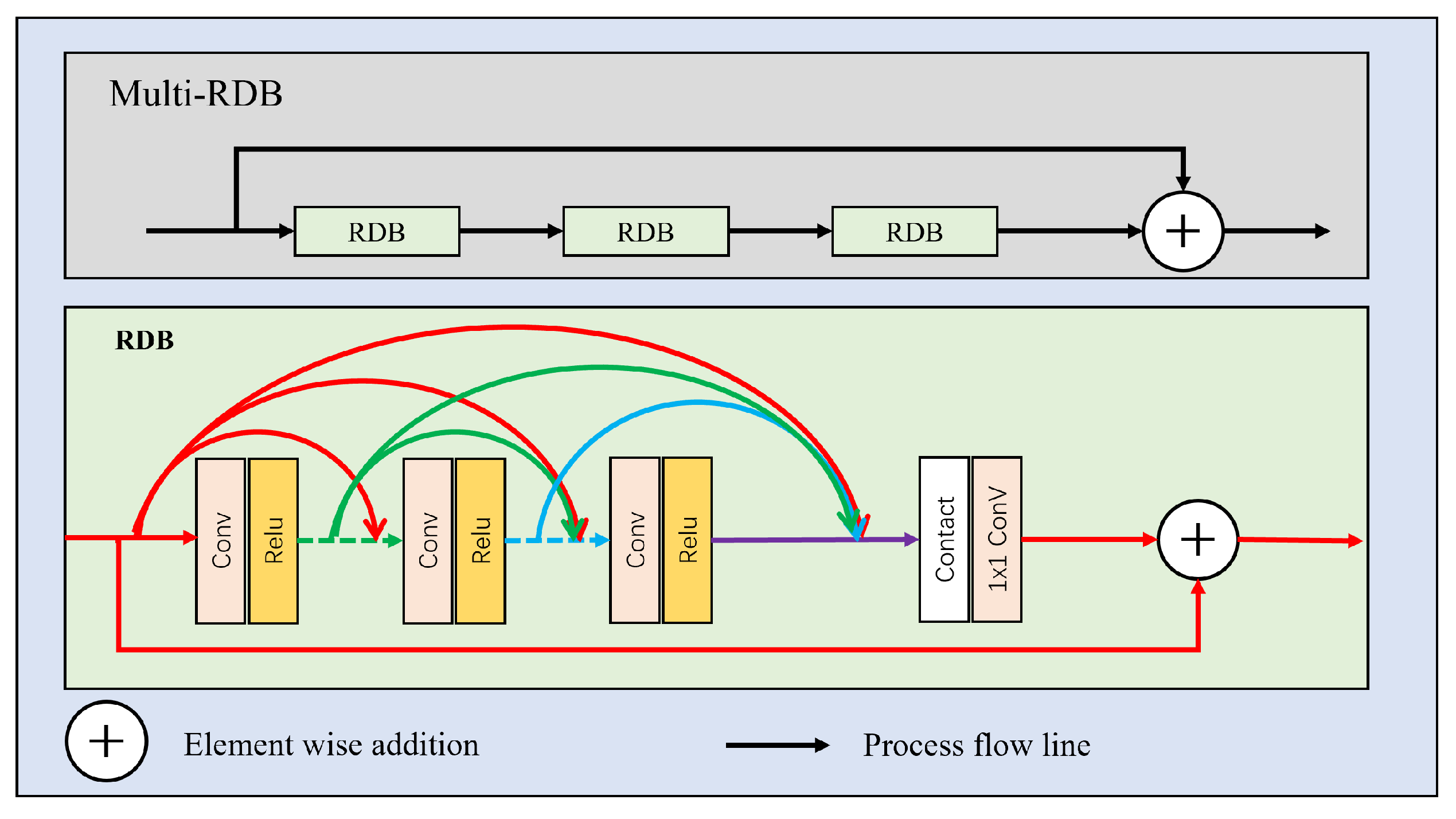
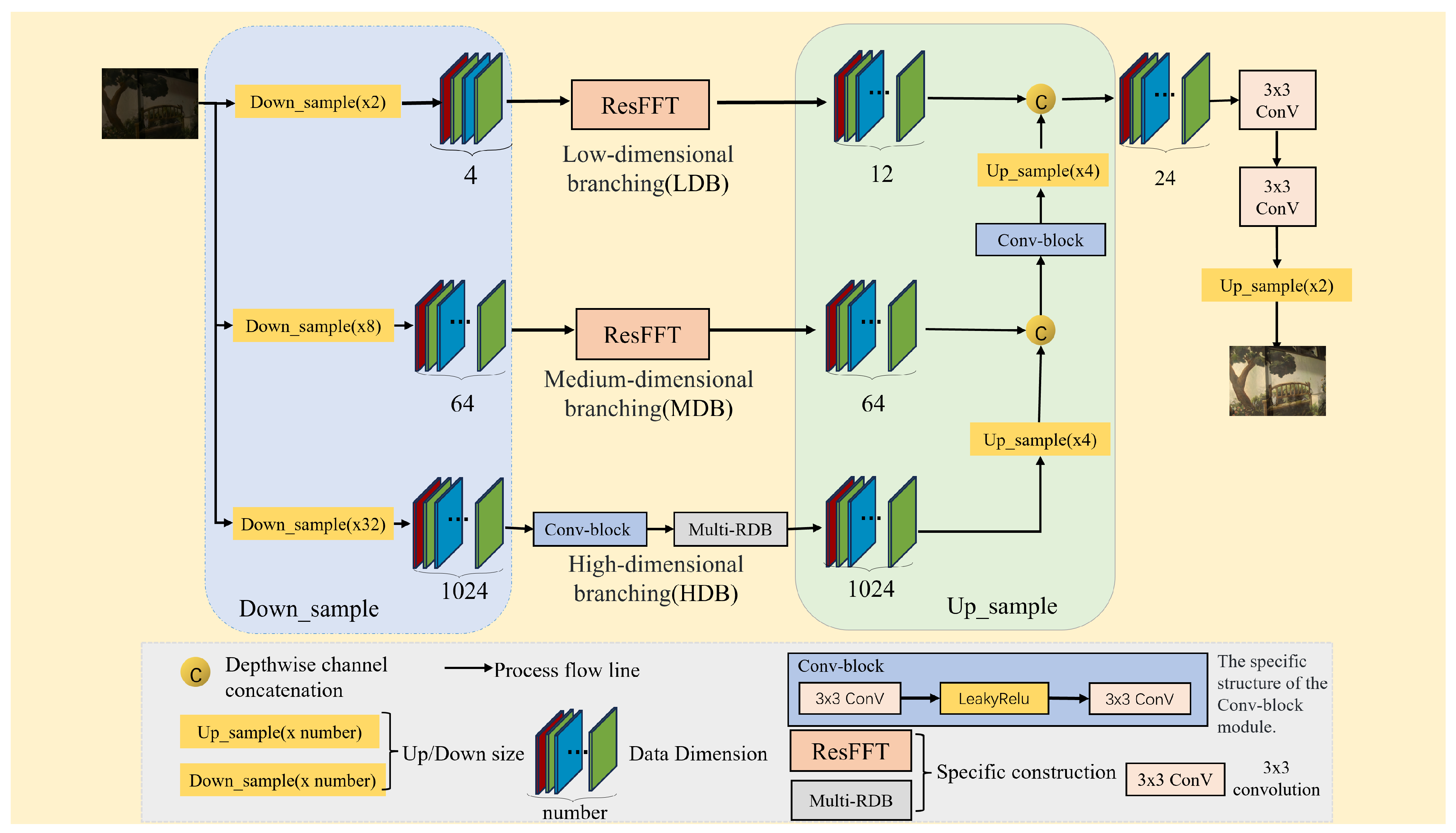
3.1. Network Architecture
3.2. Frequency-Domain Processing
3.3. Adaptive Balance
4. Experimental Results
4.1. Experimental Settings
4.2. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Shen, P.; Luo, L.; Zhang, L.; Song, J. Enhancement and noise reduction of very low light level images. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2034–2037. [Google Scholar]
- Gu, S.; Li, Y.; Van Gool, L.; Timofte, R. Self-Guided Network for Fast Image Denoising. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 2511–2520. [Google Scholar] [CrossRef]
- Xu, K.; Yang, X.; Yin, B.; Lau, R.W. Learning to Restore Low-Light Images via Decomposition-and-Enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2278–2287. [Google Scholar] [CrossRef]
- Atoum, Y.; Ye, M.; Ren, L.; Tai, Y.; Liu, X. Color-wise Attention Network for Low-light Image Enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2130–2139. [Google Scholar] [CrossRef]
- Ai, S.; Kwon, J. Extreme Low-Light Image Enhancement for Surveillance Cameras Using Attention U-Net. Sensors 2020, 20, 495. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to See in the Dark. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar] [CrossRef]
- Remez, T.; Litany, O.; Giryes, R.; Bronstein, A.M. Deep Convolutional Denoising of Low-Light Images. arXiv 2017, arXiv:1701.01687. [Google Scholar]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted Nuclear Norm Minimization with Application to Image Denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar] [CrossRef]
- Maharjan, P.; Li, L.; Li, Z.; Xu, N.; Ma, C.; Li, Y. Improving Extreme Low-Light Image Denoising via Residual Learning. In Proceedings of the IEEE International Conference on Multimedia and Expo, ICME 2019, Shanghai, China, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 916–921. [Google Scholar] [CrossRef]
- Lamba, M.; Mitra, K. Restoring Extremely Dark Images in Real Time. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3486–3496. [Google Scholar] [CrossRef]
- Huang, Q. Towards Indoor Suctionable Object Classification and Recycling: Developing a Lightweight AI Model for Robot Vacuum Cleaners. Appl. Sci. 2023, 13, 10031. [Google Scholar] [CrossRef]
- Hsia, C.H.; Lee, Y.H.; Lai, C.F. An Explainable and Lightweight Deep Convolutional Neural Network for Quality Detection of Green Coffee Beans. Appl. Sci. 2022, 12, 10966. [Google Scholar] [CrossRef]
- Huang, Q. Weight-Quantized SqueezeNet for Resource-Constrained Robot Vacuums for Indoor Obstacle Classification. AI 2022, 3, 180–193. [Google Scholar] [CrossRef]
- Tang, Z.; Luo, L.; Xie, B.; Zhu, Y.; Zhao, R.; Bi, L.; Lu, C. Automatic Sparse Connectivity Learning for Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 7350–7364. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Che, Z.; Liu, N.; Li, M.; Tang, J.; Zhang, C.; Wang, J. CATRO: Channel Pruning via Class-Aware Trace Ratio Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Ibrahim, H.; Pik Kong, N.S. Brightness Preserving Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.M.; Gu, J.; Loy, C.C. Low-Light Image and Video Enhancement Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9396–9416. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-light Image/Video Enhancement Using CNNs. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet. Pattern Recogn. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Cai, J.; Gu, S.; Zhang, L. Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Yu, R.; Liu, W.; Zhang, Y.; Qu, Z.; Zhao, D.; Zhang, B. DeepExposure: Learning to Expose Photos with Asynchronously Reinforced Adversarial Learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, Montreal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 2153–2163. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Chi, L.; Tian, G.; Mu, Y.; Xie, L.; Tian, Q. Fast Non-Local Neural Networks with Spectral Residual Learning. In Proceedings of the 27th ACM International Conference on Multimedia, MM ’19, Nice, France, 21–25 October 2019; ACM: New York, NY, USA, 2019; pp. 2142–2151. [Google Scholar] [CrossRef]
- Wei, K.; Fu, Y.; Yang, J.; Huang, H. A Physics-Based Noise Formation Model for Extreme Low-Light Raw Denoising. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2755–2764. [Google Scholar] [CrossRef]
- Yang, Y.; Soatto, S. FDA: Fourier Domain Adaptation for Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4084–4094. [Google Scholar] [CrossRef]
- Suvorov, R.; Logacheva, E.; Mashikhin, A.; Remizova, A.; Ashukha, A.; Silvestrov, A.; Kong, N.; Goka, H.; Park, K.; Lempitsky, V. Resolution-robust Large Mask Inpainting with Fourier Convolutions. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3172–3182. [Google Scholar] [CrossRef]
- Rao, Y.; Zhao, W.; Zhu, Z.; Lu, J.; Zhou, J. Global Filter Networks for Image Classification. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Brooklyn, NY, USA, 2021; Volume 34, pp. 980–993. [Google Scholar]
- Zou, W.; Jiang, M.; Zhang, Y.; Chen, L.; Lu, Z.; Wu, Y. SDWNet: A Straight Dilated Network with Wavelet Transformation for image Deblurring. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1895–1904. [Google Scholar] [CrossRef]
- Mao, X.; Liu, Y.; Shen, W.; Li, Q.; Wang, Y. Deep Residual Fourier Transformation for Single Image Deblurring. arXiv 2021, arXiv:2111.11745. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar] [CrossRef]
- Cuda c++ Best Practices Guide. Available online: https://docs.nvidia.com/cuda/pdf/CUDA_C_Best_Practices_Guide.pdf (accessed on 30 November 2020).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SID | LDC | SGN | Ours | ||
|---|---|---|---|---|---|
| Parameters (million) | 7.78 | 8.6 | 3.5 | 0.891 | |
| GMACs | Sony | 562.06 | >2000 | >2000 | 60.5 |
| Fuji | 1273.64 | >2000 | >2000 | 121.07 | |
| CPU inference times (s) | Sony | 4.21 | >50 | 20.52 | 0.96 |
| Fuji | 8.11 | >50 | >50 | 1.78 | |
| GPU inference times (ms) | Sony | 197.66 | >1500 | 1113.85 | 57.92 |
| Fuji | 384.87 | >1500 | >1500 | 106.26 | |
| PSNR (dB)/SSIM | Sony | 28.88/0.787 | 29.56/0.799 | 28.91/0.789 | 28.85/0.794 |
| Fuji | 26.61/0.680 | 26.70/0.681 | 26.90/0.683 | 26.62/0.681 | |
| LLPackNet | RETNet | Ours | ||
|---|---|---|---|---|
| Parameters (million) | 1.16 | 0.785 | 0.891 | |
| GMACs | Sony | 83.46 | 59.8 | 60.5 |
| Fuji | 166.12 | 119.66 | 121.07 | |
| CPU inference times (s) | Sony | 1.73 | 0.76 | 0.96 |
| Fuji | 3.25 | 1.4 | 1.78 | |
| GPU inference times (ms) | Sony | 70.96 | 46.24 | 57.92 |
| Fuji | 138.34 | 93.83 | 106.26 | |
| PSNR (dB)/SSIM | Sony | 27.83/0.75 | 28.66/0.790 | 28.85/0.794 |
| Fuji | 24.13/0.59 | 26.60/0.682 | 26.62/0.681 | |
| SID | LDC | SGN | LLPackNet | RETNet | Ours | ||
|---|---|---|---|---|---|---|---|
| CPU inference times (s) | 4.21 | >50 | 20.52 | 1.73 | 0.76 | 0.96 | |
| PSNR (dB)/SSIM | Satellite | 26.53/0.677 | 26.95/0.679 | 26.75/0.672 | 25.35/0.632 | 26.13/0.653 | 26.72/0.674 |
| Macbeth | 28.48/0.736 | 28.97/0.763 | 28.78/0.738 | 27.12/0.657 | 28.13/0.729 | 28.79/0.765 | |
| PSNR (dB)/SSIM | Decreasing Value | |
|---|---|---|
| Original network architecture | 28.85/0.794 | 0/0 |
| Removing the frequency-domain modules | 28.13/0.772 | 0.72/0.22 |
| Removing the adaptive balancing module | 28.31/0.785 | 0.54/0.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Zhang, H.; Li, B.; Duan, J.; Li, Q.; He, Z.; Cao, J.; Wang, H. Real-Time Low-Light Imaging in Space Based on the Fusion of Spatial and Frequency Domains. Electronics 2023, 12, 5022. https://doi.org/10.3390/electronics12245022
Wu J, Zhang H, Li B, Duan J, Li Q, He Z, Cao J, Wang H. Real-Time Low-Light Imaging in Space Based on the Fusion of Spatial and Frequency Domains. Electronics. 2023; 12(24):5022. https://doi.org/10.3390/electronics12245022
Chicago/Turabian StyleWu, Jiaxin, Haifeng Zhang, Biao Li, Jiaxin Duan, Qianxi Li, Zeyu He, Jianzhong Cao, and Hao Wang. 2023. "Real-Time Low-Light Imaging in Space Based on the Fusion of Spatial and Frequency Domains" Electronics 12, no. 24: 5022. https://doi.org/10.3390/electronics12245022
APA StyleWu, J., Zhang, H., Li, B., Duan, J., Li, Q., He, Z., Cao, J., & Wang, H. (2023). Real-Time Low-Light Imaging in Space Based on the Fusion of Spatial and Frequency Domains. Electronics, 12(24), 5022. https://doi.org/10.3390/electronics12245022