

Algorithms, Volume 15, Issue 4 (April 2022) – 33 articles
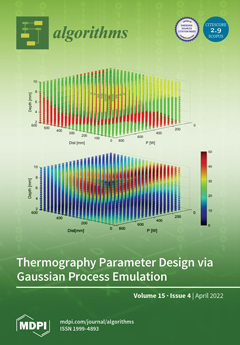
Cover Story (view full-size image):
We address the challenge of determining a valid set of parameters for a dynamic line scan thermography setup. Via Gaussian process emulation, we are able to predict the behavior of dynamic line scan thermography without performing a large number of simulations or experiments. Applications depending on many input parameters are hard to optimize and even harder to develop an intuition for. Using Gaussian process emulation, we are able to identify regions of parameter combinations that should be avoided. At the same time, the emulation algorithm provides an insight in the most suitable regions of parameter sets for a desired outcome. We demonstrate that a trained emulator can be queried to find solutions for design questions relevant in a real-world engineering design challenge. View this paper
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue