1. Introduction
The normalized least-mean-square (NLMS) algorithm is the workhorse in many practical applications of adaptive filtering [
1,
2,
3]. The main reasons behind its popularity consist of its simple and efficient implementation, together with fairly reasonable performance, in terms of the convergence rate, tracking, and accuracy of the solution. Nevertheless, there is always a need to improve the performance features of the NLMS algorithm, especially in challenging scenarios, e.g., when using highly correlated input signals and/or dealing with long-length adaptive filters. In this framework, a very important application is acoustic echo cancellation (AEC) [
4,
5,
6], where the input signal is mainly speech (i.e., a nonstationary and highly correlated sequence), while the impulse response of the acoustic echo path is usually of the order of hundreds or even thousands of coefficients.
There are several strategies to improve the performance of the NLMS algorithm in AEC scenarios. Among them, proportionate NLMS algorithms exploit the sparseness nature of the echo paths to increase the convergence rate and tracking of the adaptive filter [
7,
8,
9,
10,
11,
12,
13]. Besides, variable step size NLMS (VSS-NLMS) algorithms are designed to achieve a proper compromise between the convergence rate and misadjustment (i.e., accuracy of the estimate) [
14,
15,
16,
17,
18]. Moreover, the data reuse approach consists of performing more than one filter update for the same set of data (i.e., the input and reference signals), thus targeting a higher convergence rate [
19,
20,
21,
22,
23,
24,
25].
In this short communication, we focused on the data reuse NLMS algorithm from a different perspective, showing how it can be exploited in order to develop an improved NLMS version with variable step sizes. As compared to other previous works related to the data reuse approach, the proposed VSS-NLMS algorithm uses a sequence of scheduled step size parameters. These values are a priori computed by exploiting the convergence modes of the data reuse NLMS algorithm. On the contrary, in [
24], the variable step size (VSS) from [
14] was used in conjunction with the data reuse NLMS algorithm from [
21], thus resulting in a new version that was similar to an affine projection algorithm with VSS parameter. Furthermore, in [
25], the data reuse approach was applied to an optimized least-mean-square algorithm, which behaves similar to a VSS version. In these previous works, the VSS parameter was evaluated within each iteration of the algorithm, which is fundamentally different as compared to the current proposed approach, where the step size parameters were a priori computed and scheduled within the algorithm.
Our main application framework was AEC [
4], where the main goal was to estimate the impulse response between the loudspeaker and microphone of a hands-free communication device. Basically, we dealt with a system identification problem, which can be solved by using an adaptive filter. Currently, hands-free communication devices are involved in many popular applications, such as mobile telephony and teleconferencing systems. Due to their specific features, they can be used in a wide range of environments with different acoustic characteristics. In this context, an important issue that has to be addressed when dealing with such devices is the acoustic coupling between the loudspeaker and microphone. In other words, besides the voice of the near-end speaker and the background noise, the microphone of the hands-free equipment captures another signal (coming from its own loudspeaker), known as the acoustic echo. Depending on the environments’ characteristics, this phenomenon can be very disturbing for the far-end speaker, which hears a replica of her/his own voice. From this point of view, there is a need to enhance the quality of the microphone signal by canceling the unwanted acoustic echo. The most reliable solution to this problem is the use of an adaptive filter that generates at its output a replica of the echo, which is further subtracted from the microphone signal [
4,
5,
6]. Consequently, the adaptive filter has to model an unknown system, i.e., the acoustic echo path between the loudspeaker and microphone.
Even if the problem formulation is straightforward, the specific features of AEC represent a challenge for any adaptive algorithm. First, the acoustic echo paths have excessive lengths in time (up to hundreds of milliseconds), due to the slow speed of sound in the air, together with multiple reflections caused by the environment; therefore, long-length adaptive filters are required (hundreds or even thousands of coefficients), influencing the convergence rate of the algorithm. Second, the acoustic echo paths are time-variant systems (depending on the temperature, pressure, humidity, and movement of objects or bodies), requiring good tracking capabilities for the echo canceler. Third, the input of the adaptive filter (i.e., the far-end signal) is mainly speech, which is a nonstationary and highly correlated signal that can influence the overall performance of the adaptive algorithm.
Since the conventional NLMS algorithm uses a constant step size parameter to control its performances, a compromise should be made when choosing this value. It is known that a large value implies a fast convergence rate and tracking, while a small value leads to low misadjustment and good robustness features. Since in AEC, there is a need for all these performance criteria, the step size should be controlled; therefore, a VSS version represents a more reliable choice. In addition, for real-world AEC applications, it is highly desirable to use nonparametric algorithms, in the sense that no information about the acoustic environment is required. Nevertheless, we should note that the applications of the VSS-NLMS algorithms are not limited only to the framework of AEC. Different other application areas can be explored in the field of communication systems, such as the carrier phase recovery, e.g., see [
26,
27] and the references therein.
Following this Introduction, in
Section 2, we present the data reuse NLMS algorithm, but using a computationally efficient method to exploit the data reuse process, thus keeping almost the same complexity as the conventional version. Then, in
Section 3, we develop a VSS-NLMS algorithm based on the data reuse approach. Simulation results in the context of AEC are provided in
Section 4 in order to support the performance of the proposed VSS-NLMS algorithm. Finally, several conclusions are summarized in
Section 5. The acronyms used in this paper are provided in
Table A1 in
Appendix A, while the notation and symbols are summarized in
Table A2 from the same section.
2. Data Reuse NLMS Algorithm
The conventional NLMS algorithm [
1,
3] is defined by two main equations, which provide the error signal and the filter update, respectively, as follows:
where
is the a priori error signal at the discrete-time index
n,
is the desired (or reference) signal,
is a vector containing the most recent
L time samples of the zero-mean input signal
, the superscript
denotes the transpose operator,
is the adaptive filter (of length
L) at the discrete-time index
n, which is an estimate of the unknown impulse response, and
is the normalized step size parameter of the NLMS algorithm. Theoretically, the range for this parameter is
, but practically, the recommended choice is
[
2]. For the sake of simplicity, we omitted in the developments the regularization parameter
[
28], which is usually added to the denominator in (
2).
Based on the adaptive filter coefficients at the discrete-time index
n, we may also define the a posteriori error signal as:
Using (
1) and (
2) in (
3), we can further develop the previous expression of the a posteriori error, which results in:
It can be noticed that the a posteriori error is canceled for (assuming that ).
Now, let us consider that we perform multiple iterations for the NLMS algorithm using the same input data
and reference signal
, i.e., performing the data reuse process [
19,
20,
21,
22,
23,
24,
25]. Hence, in the first step (using (
1), (
2), and (
4)), we have:
Then, by repeating the process, we obtain:
and so on.
Using mathematical induction, it results that the
kth-order a posteriori error is:
and the
kth-order update is given by:
which is similar to the original update (
2), but using the normalized step size:
In other words, performing multiple iterations for the same set of data is equivalent to increasing the value of the normalized step size, thus leading to a faster convergence mode [
1,
2,
3].
A few remarks can be outlined based on the previous results, as follows:
(1) If , then and for any value of k. This supports the well-known fact that the value of the normalized step size provides the fastest convergence mode;
(2) For any , ;
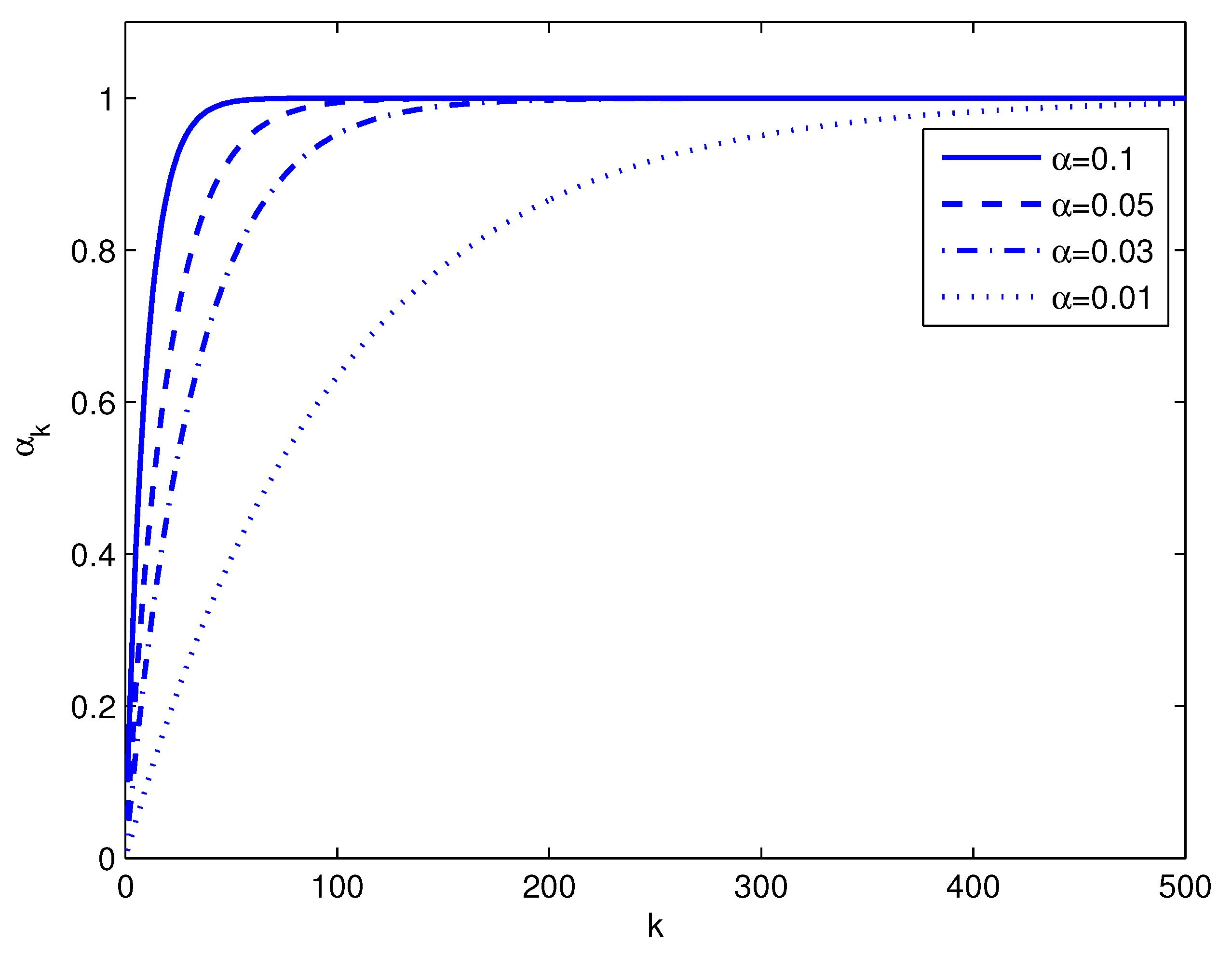
(3) For any
,
. This is shown in
Figure 1, where the parameter
is plotted for different values of
. These curves can be interpreted as the data reuse convergence modes of the NLMS algorithm, for a certain value of
.
In addition, based on (
10), we can easily evaluate the number of data reuse iterations,
, required to attain a certain (maximum) value of the normalized step size,
, starting from a given value of
. Thus, we can write:
which results in:
where
denotes the ceiling function and
stands for the natural logarithm.
3. Variable Step Size NLMS Algorithm
Based on the previous considerations, we can design a simple VSS-NLMS algorithm, by implementing the previous approach in a “reverse” manner, using scheduled normalized step sizes. Thus, given the lower and the upper bounds for the normalized step size parameter, i.e.,
and
, respectively, the update equation that defines the proposed VSS-NLMS algorithm is:
where the variable step size parameter
is evaluated as follows (using (
10) and (
12)):
Step 1: , for and (with );
Step 2: , for ;
Step 3: if (with ) for , then go to Step 1;
where
denotes the variance of the a priori error signal,
is the power of the system noise (i.e., the external noise that usually corrupts the reference signal), and
results based on (
12), according to the values of
and
.
In other words, in Step 1, the algorithm uses the normalized step sizes in the following order:
,
,
,
…,
. Each value is used for
iterations, with
. For tracking purposes, in order to not stall the algorithm in Step 2 (i.e., when the lower bound of the normalized step size parameter
is used), the condition from Step 3 is introduced. The power estimates required in Step 3 can be recursively evaluated as:
where
and
, with
and
[
29]. The power estimate of the system noise can be roughly estimated from the error signal by using a larger smoothing parameter
. By checking the condition from Step 3, we can identify the change of the system (in a system identification scenario) and reset the step size of the algorithm. Of course, more complex/performant detectors can be used in Step 3 [
15], but this is beyond the scope of this paper.
The main parameters to be set are
and
l. The first parameter,
, is related to the maximum value of the normalized step size,
, as shown in (
12). For example, if we consider
(which is high enough and very close to the fastest convergence mode) and the lower bound
(so that
), according to (
12) we obtain:
The second parameter,
l (with
), determines how many iterations (i.e.,
) the algorithm will use a certain value of the step size (see Step 1). As we can notice from Step 2, the algorithm will reach the lower bound of the normalized step size
after
iterations; from this point of view, it is not recommended to set a very low value of
(e.g.,
), which leads to a high value of
, according to (
16). Since the convergence rate of the NLMS-based algorithms depends on the character of the input signal [
1,
2,
3] (in terms of the condition number of the correlation matrix), the value of
l should be chosen accordingly. For example, for white Gaussian inputs, we can choose a smaller value of
l, e.g.,
. For more correlated inputs (such as autoregressive processes), the value of
l should be increased, e.g.,
. Furthermore, for more challenging signals such as speech (i.e., highly correlated and nonstationary), the value of
l could be even higher, e.g.,
.
The computational complexity of the proposed VSS-NLMS algorithm is similar to the complexity of the conventional NLMS benchmark, since the values of the step size parameters of the VSS-NLMS algorithm are a priori computed and scheduled based on (
10) and (
12); thus, these values can be used directly in Steps 1 and 2 of the algorithm, as describe before. The only extra computational amount is required in Step 3 of the VSS-NLMS algorithm, which is mainly related to the power estimates from (
14) and (
15). Nevertheless, this step requires only 5 multiplications, 2 additions, and 1 comparison, which represents a negligible computational effort as compared to the overall complexity of the conventional NLMS algorithm that is proportional to
, especially for very large values of
L as in the context of AEC.
In addition, the proposed VSS-NLMS does not require additional parameters from the environment, so it can be considered a nonparametric algorithm [
14]. Of course, it would be very useful to find more practical ways to set (or adjust) the parameter
l within the algorithm, based on the convergence status of the adaptive filter, but this will be the subject for future works.
4. Simulation Results
Simulations were performed in the context of AEC, in a single-talk scenario [
4,
5,
6]. In this case, the microphone (reference/desired) signal results in:
where
contains the coefficients of the acoustic impulse response (of length
L),
contains the last
L time samples of the far-end signal (i.e., the input signal),
is the background noise, and
represents the echo signal. In this framework, the main goal is to identify the acoustic echo path,
, with an adaptive filter,
.
In our experiments, it was considered that
is a white Gaussian noise, so that the echo-to-noise ratio (ENR) was 20 dB. The ENR is defined as
, where
denotes the variance of the echo signal. The acoustic echo path
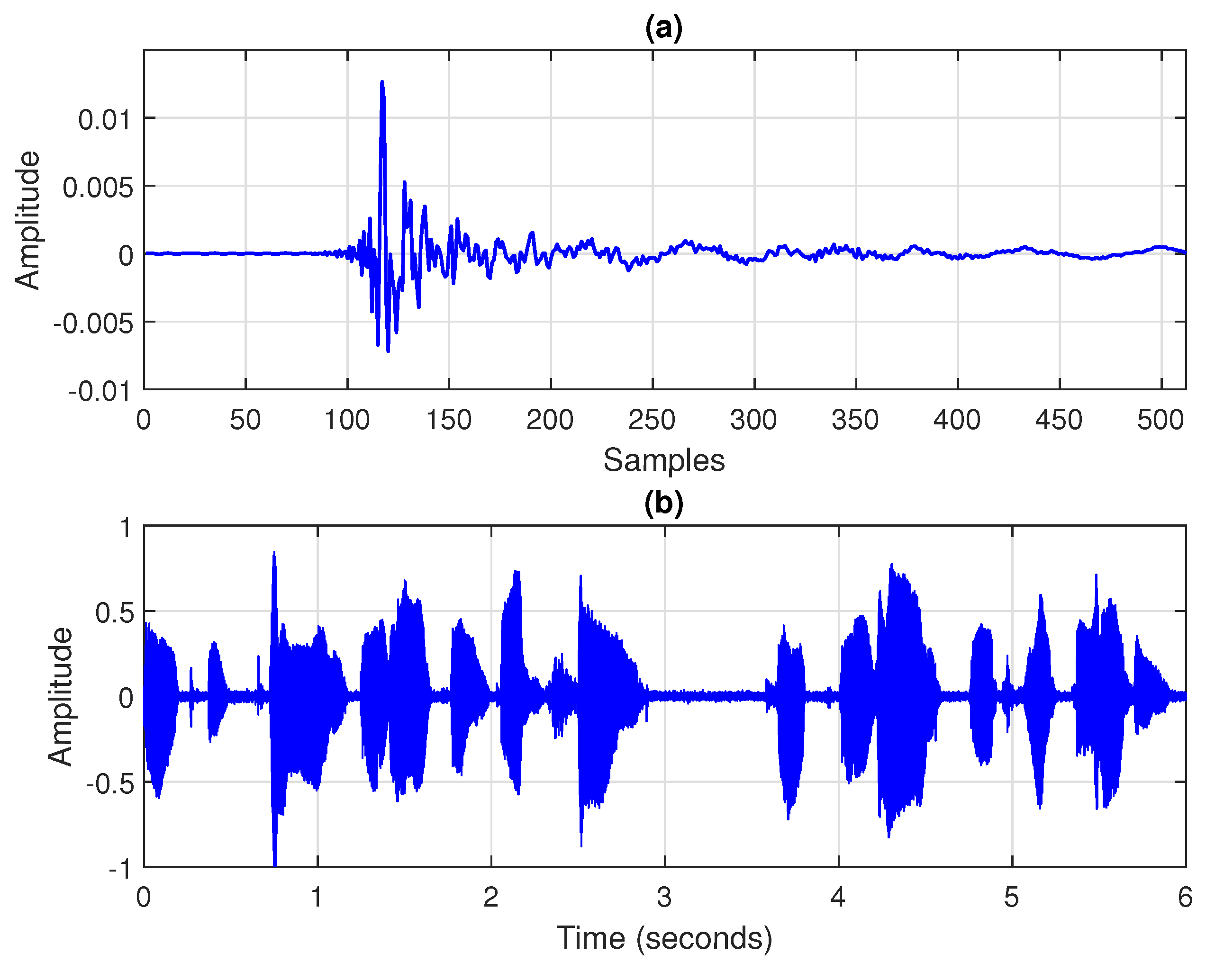
was obtained from a measured acoustic impulse response using
coefficients (depicted in
Figure 2a and available at
www.comm.pub.ro/plant, accessed on 24 February 2022), and the same length was used for the adaptive filter, using a sampling rate of 8 kHz. Three types of input signals were considered: (i) a white Gaussian noise, (ii) a first-order autoregressive process, referred to as AR(1), which was obtained by filtering a white Gaussian noise through a first-order autoregressive model with a pole at
, and (iii) a recorded speech sequence (depicted in
Figure 2b); for a longer simulation time (as needed in some experiments), this voice signal can be simply repeated several times. The experimental framework is summarized in
Table A3 in
Appendix A. In the middle of some simulations, an echo path change scenario was simulated by shifting the acoustic impulse response to the right by 12 samples, in order to assess the tracking capabilities of the algorithms. The performance measure used in all the experiments was the normalized misalignment (in dB), which is evaluated as:
where
denotes the Euclidean norm.
The parameters of the proposed VSS-NLMS algorithm were set as follows. Based on (
16), we set
, using different values for the lower bound of the normalized step size parameter
. The power estimates from (
14) and (
15) were computed using
for the white Gaussian input and
for the AR(1) process or speech sequence [
14]; also, we used
and
[
29]. The main parameters of the algorithms used in comparisons are provided in
Table A4 in
Appendix A, while their main values are summarized in
Table A5 from the same section.
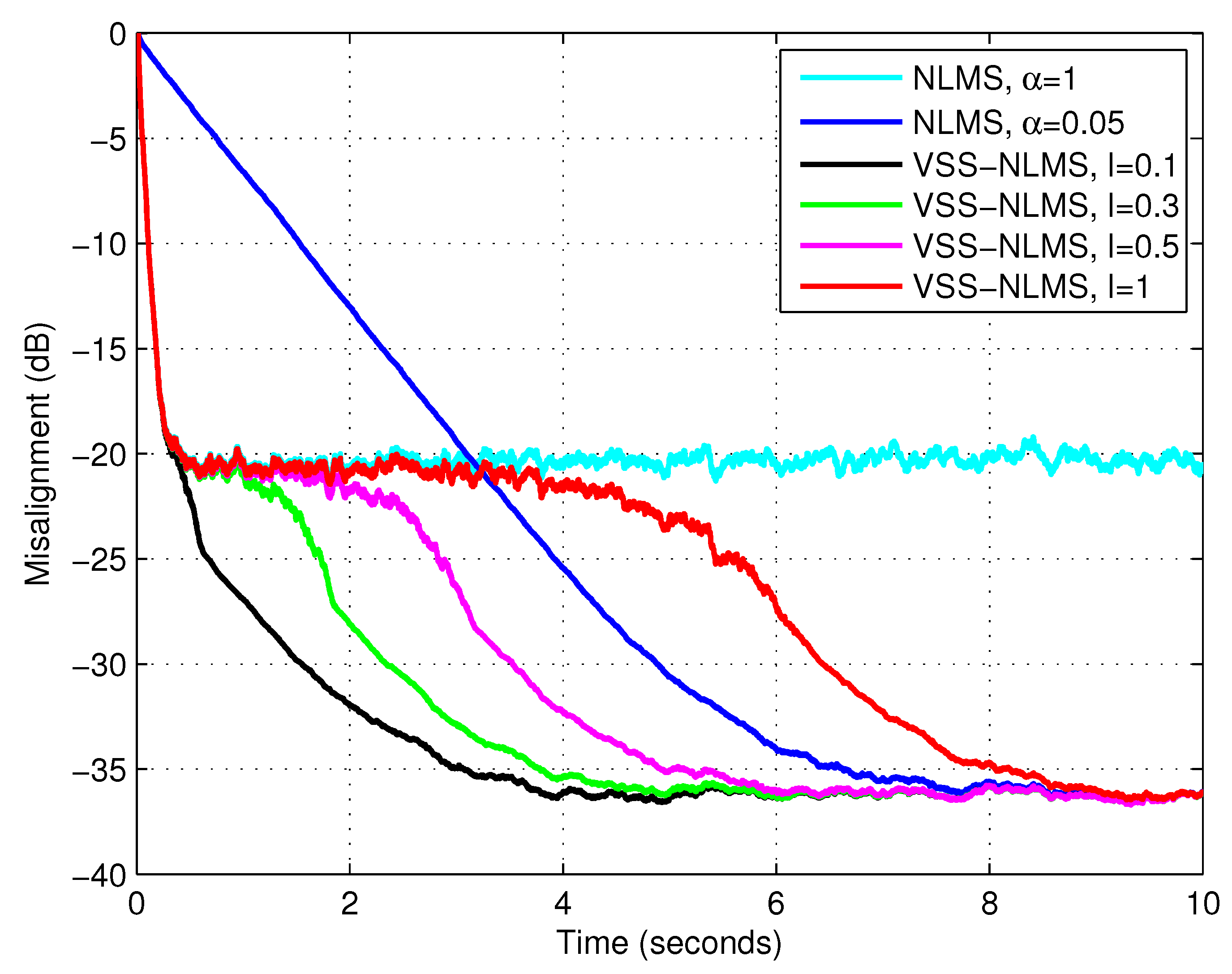
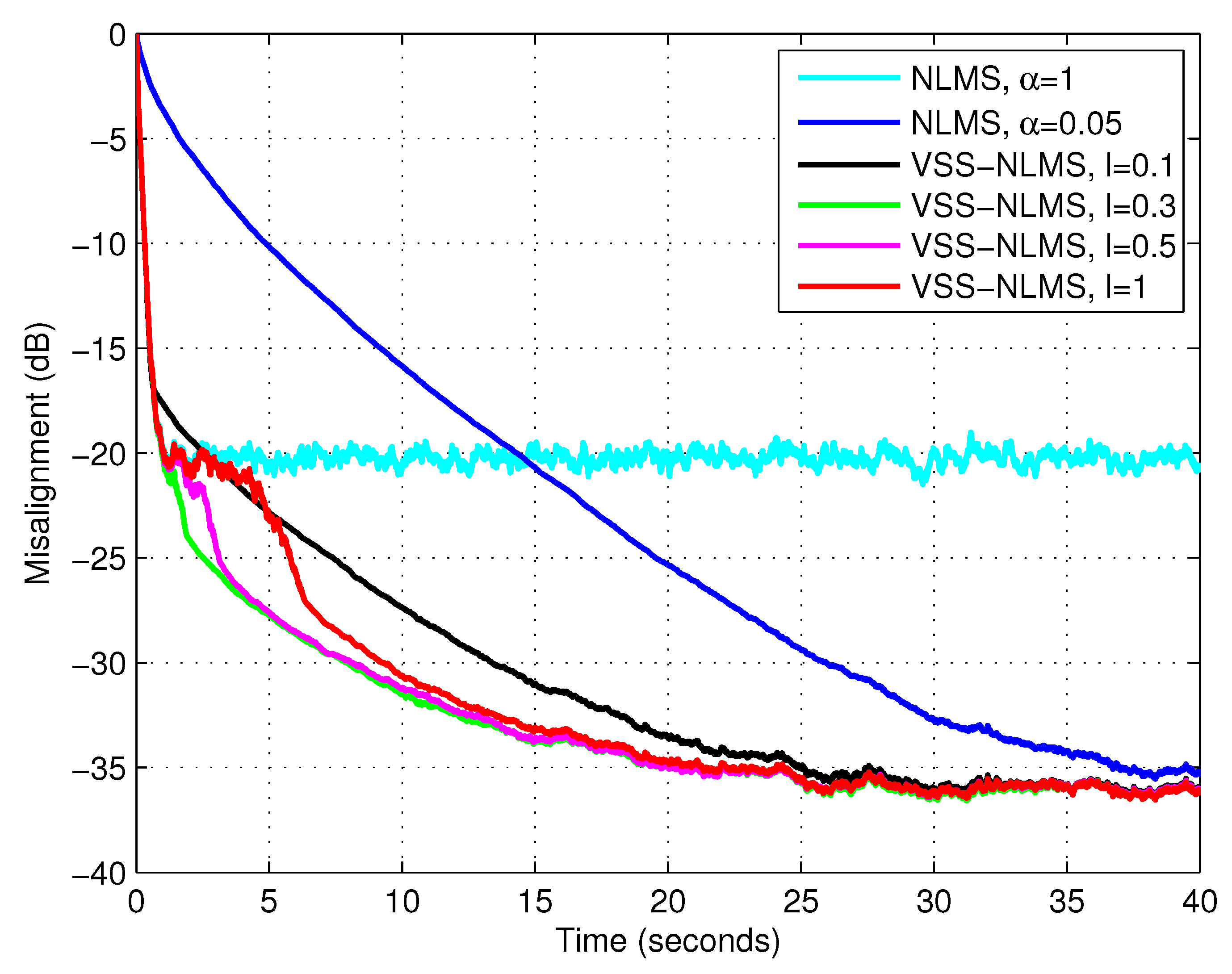
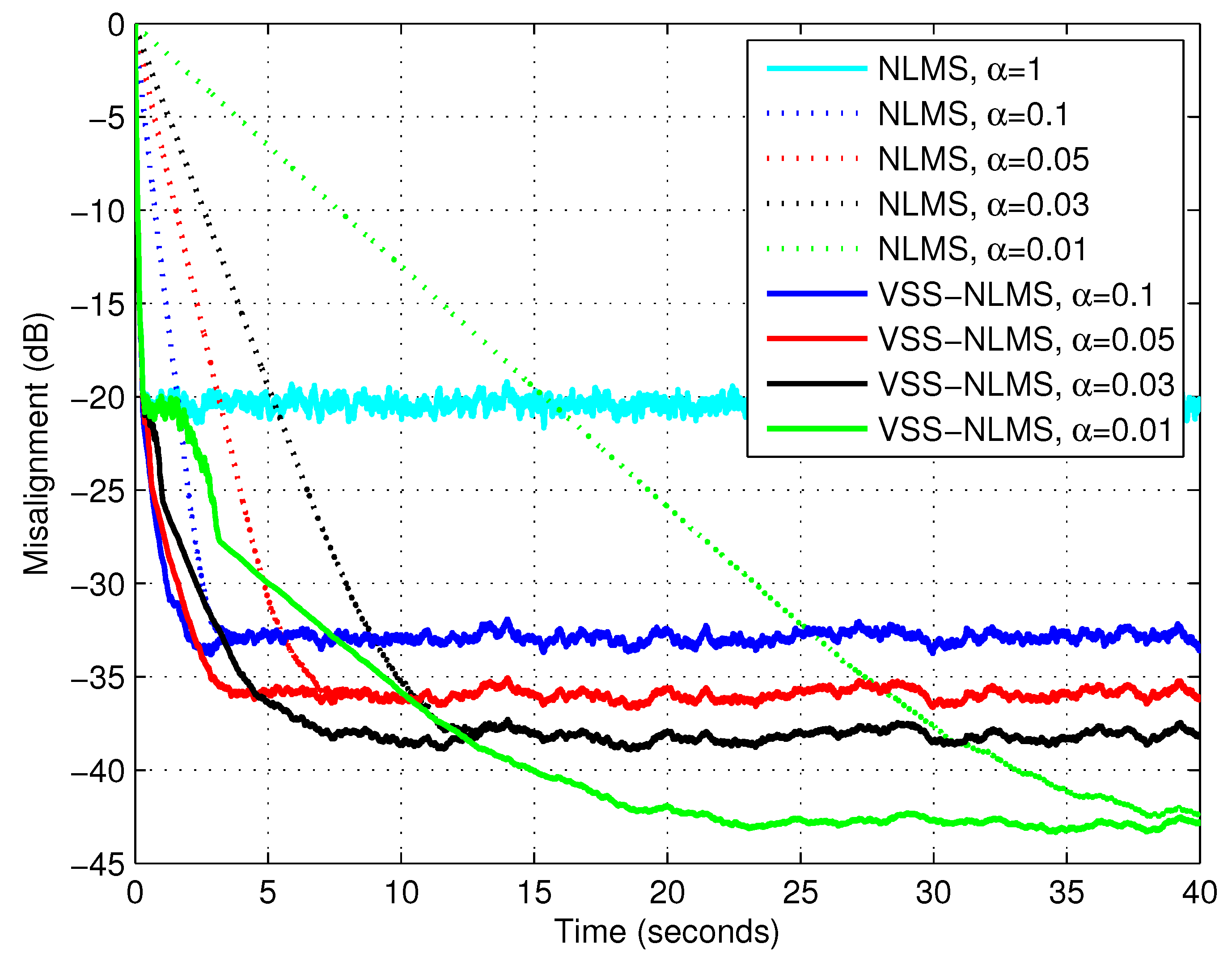
First, we evaluated the influence of the parameter
l on the performance of the proposed algorithm (using the lower bound
), for different types of input signals. The results are given in
Figure 3,
Figure 4 and
Figure 5, using white Gaussian noise, the AR(1) process, and the speech signal, respectively. These results supported the discussion from
Section 3, concerning the influence of the parameter
l (and the recommended choices). Consequently, in the following simulations, we use
for white Gaussian inputs,
for the AR(1) process, and
for the speech signal.
Next, the performance of the VSS-NLMS algorithm was evaluated for different values of the lower bound of the normalized step size parameter, i.e.,
, and
. The results are given in
Figure 6, using a white Gaussian noise as the input. It can be noticed that the algorithm was efficient for different values of
. However, as was explained in
Section 3, it is not recommended to choose a very small value of this lower bound.
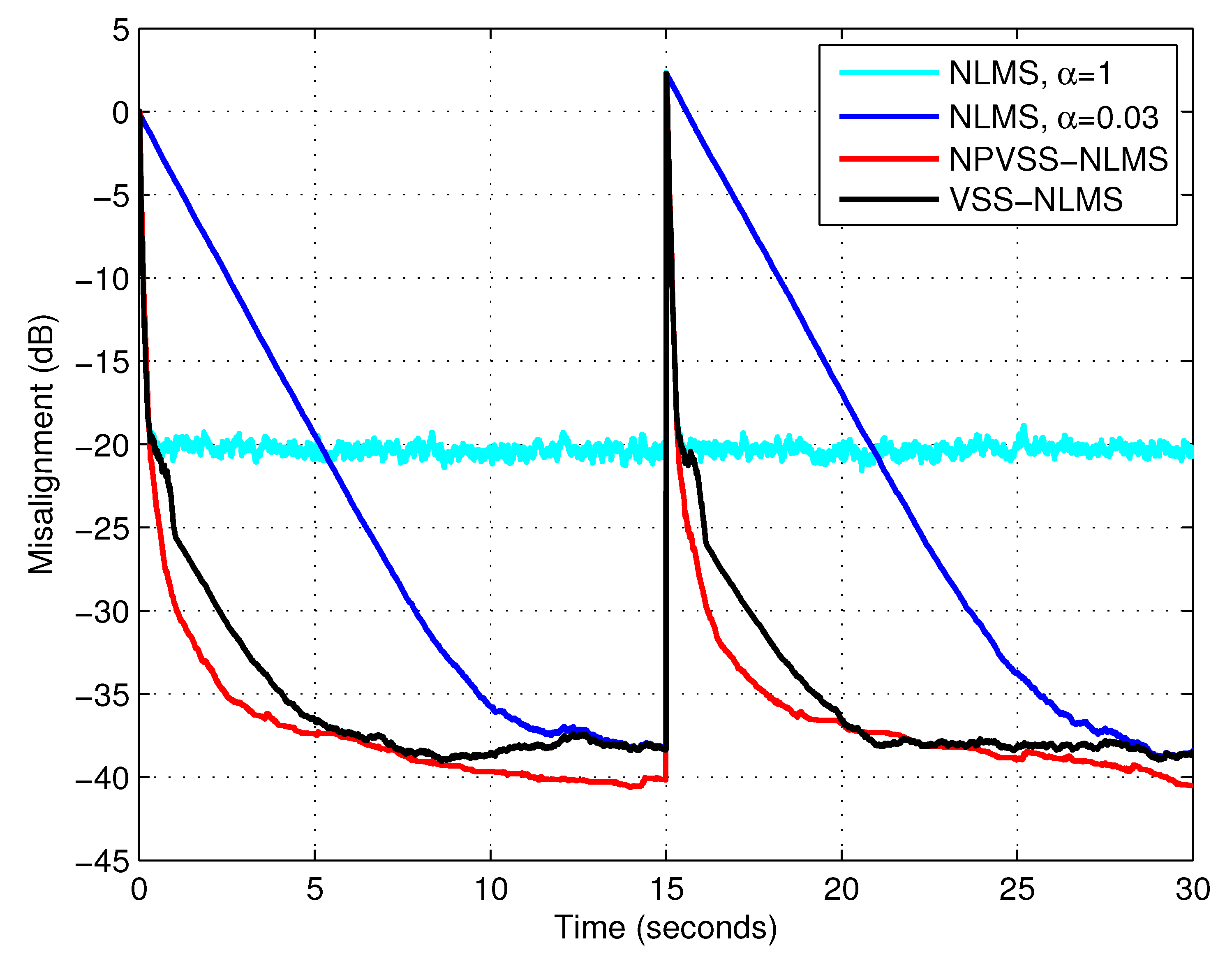
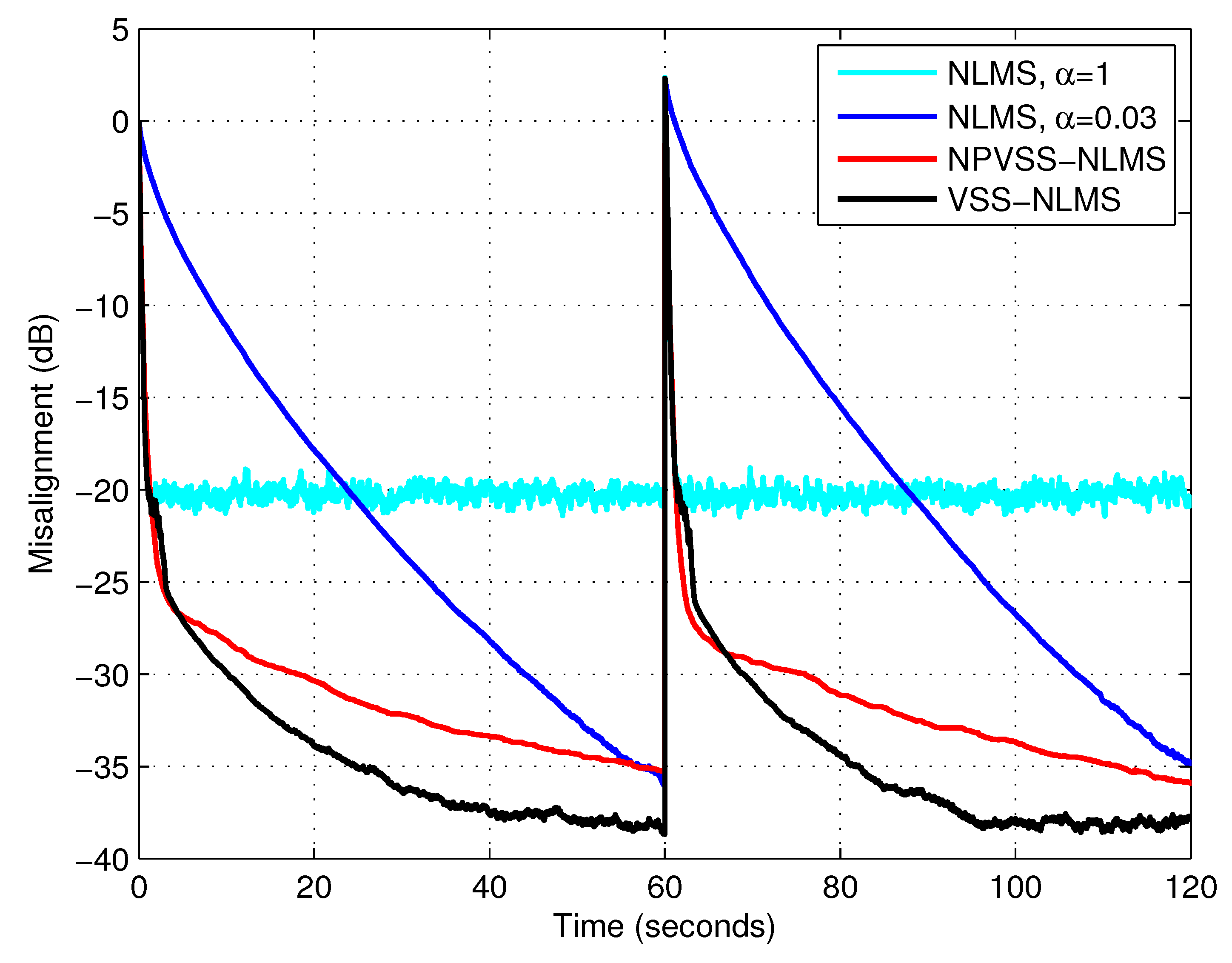
In the following experiments, the nonparametric VSS-NLMS (NPVSS-NLMS) algorithm proposed in [
14] is introduced for comparison, assuming that the true power of the system noise,
, is available for this algorithm. The update of the NPVSS-NLMS algorithm is:
where:
and
was evaluated similar to (
14). Furthermore, a very small positive constant should be added to the denominator of
, in order to avoid any potential division by zero related to the estimation of
. It should be outlined that the NPVSS-NLMS algorithm is usually considered as a benchmark (for many VSS-NLMS algorithms), due to its good performance and practical features. In the following experiments, the proposed VSS-NLMS algorithm uses the lower bound value
. In order to test the tracking capabilities of the algorithms, an echo path change scenario was considered. All three types of input signals were used, i.e., white Gaussian noise, the AR(1) process, and speech; the results are provided in
Figure 7,
Figure 8 and
Figure 9, respectively. It can be noticed that the NPVSS-NLMS algorithm outperformed the proposed VSS-NLMS algorithm in the case of the white Gaussian input. However, the proposed algorithm performed better for the AR(1) process and speech inputs.
Finally, a variation of the ENR was considered, in order to assess the robustness of the algorithms. In
Figure 10, the ENR decreased from 20 dB to 10 dB after 120 s. In this experiment, the input signal was speech. Here, we considered that the initial value of
was available for the NPVSS-NLMS algorithm, but not the new one (i.e., after the decrease of the ENR). As expected, the proposed VSS-NLMS algorithm reacted similar to the NLMS algorithm with the smaller normalized step size, outperforming the NPVSS-NLMS algorithm.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}