1. Introduction
Active thermography is widely recognized as a fast, reliable and contactless non-destructive inspection technique [
1]. It can be performed in a stationary manner in which the sample to be inspected remains at the same location. This way, the object is easily heated using a heating source, and the cooling of the sample is registered using a thermal camera. This method limits the size of the object since the sample has to fit in the field of view of the camera. It is possible to examine larger samples by placing the thermal camera at a greater distance from the sample. The downside of placing the camera further away from the sample is the resolution reduction in a specified region. In order to detect a defect with sufficient certainty, the defect has to have an area of at least 3 × 3 pixels [
2]. Larger samples can be inspected using dynamic line scan thermography (DLST). This technique uses a heat source and a thermal camera in tandem, which moves relative to the sample to be inspected. This can be achieved in two ways: either the camera and heating source are moved above the object using a robotic arm, or the specimen can translate on a conveyor belt underneath the heating source and the camera [
3,
4]. Since dynamic line scan thermography is a relatively new technique, it is less widely spread in comparison to other nondestructive testing methods.
An expert skilled in the art has to define the DLST measurement parameters in order to prevent time-intensive trial and error attempts to find a workable parameter set. In this work, we focus on the movement velocity, the distance between the heat source and the camera, the heating power, the start depth of the defect, the diameter of the defect, the height of the camera and the ambient temperature.
Several studies have been performed in order to simplify the search for these DLST measurement parameters. Finite element simulations have been used in order to update the parameters according to measurements [
5]. Response surfaces are used as approximation in order to find the best parameters based on the characteristics of the defect (depth, dimension) and the thermal properties of the material [
2]. Using the response surface and some fixed parameters provided by the inspector of a specimen, the best matching set of parameters is predicted. A response surface can be generated using data from multiple measurements. However, in order to create such a response surface, a large amount of measurements are needed. Generally, this is a time-consuming and costly endeavor. Therefore, a response surface is often built from data gathered in multiple finite element simulations. The amount of simulations matches the amount of needed measurements; nonetheless, performing simulations is cheaper, cost wise and time wise. The simulation performed for this manuscript consists of a flat bottom hole plate heated by a line heater moving above the sample. The simulated object is a flat bottom hole plate since this is widely used in scientific research on thermography. The thermal behavior of flat bottom holes best resembles the response expected by most defects, whereby active thermography is used as an inspection method. Such defects are delaminations, lateral cracks, areas of porosity, etc. Attempts are made to create a standard for thermal imaging based on the use of flat bottom hole plates [
6,
7]. Therefore, this research is limited to flat bottom hole plates.
A different approach to predict an optimal parameter set is to use artificial intelligence. For instance, it is possible to train a reinforcement agent to search for the best parameters to detect multiple defects in a flat bottom hole plate. However, training the reinforcement learning algorithm requires more simulations than generating the response surface and, therefore, is less interesting.
Computer simulations are used in a wide range of scientific and engineering challenges [
8]. In this work, we follow their definition of a simulation, stating that it is any computer program that imitates a real-world system or process. Being able to simulate an experiment instead of actually conducting it in the real world greatly reduces the required time, cost and other practical implications, such as possible health risks or consequences for the environment.
However, since simulators are programmed to a specific task, they are not insensitive to bias. Moreover, for more complex simulators, the amount of time needed to run the simulations can become cumbersome. In order to overcome these drawbacks, the simulation itself can be modeled by a machine learning algorithm, which predicts the outcome of the simulator. Popular choices for these models are Gaussian processes [
9], random forests [
10] and neural networks [
11]. In this sense, the emulator is a ’model of a model’. The gain stems from the fact that a complex simulation is much more computationally expensive than a computationally cheap emulation. Over the past years, emulation has found its way in several domains. In [
12], a Gaussian process was implemented to emulate a mechanical model of the left ventricle, which allowed for a more rapid discovery of the optimal parameter set for the design. The authors of [
13] built an emulator to model the calibration of an engine. The spread of an infectious disease was modeled in [
10].
For machine learning models that are probabilistic by nature, they serve as a statistical surrogate model. This allows for the quantification of uncertainty of their predictions, which plays an important role in decision making or risk assessment. For this reason, we focus on Gaussian processes in this work. By following the Bayesian paradigm, their predictions consist of both a mean and a variance, which is interpretable as a measure of uncertainty. A more detailed description is given in
Section 2.
The rest of this paper is structured as follows. In the next section, we explain how we generated the data and give some theoretical background on Gaussian processes and uncertainty sampling. The
Section 3 describes our results. In
Section 4, we discuss these findings. Finally, the conclusions are provided.
3. Results
The purpose of this manuscript is to investigate the feasibility to use emulation for dynamic line scan thermography. Predicting the optimal parameter set is difficult and highly dependent on the defect characteristics. Generating a sufficient detailed response surface requires a large number of data points. The incentive of using Gaussian Process emulation for parameter prediction is based on the idea that it takes fewer data points to learn the effect of the different design parameters in comparison to generating a response surface.
We evaluate the benefits of dynamic line scan thermography emulation by means of a Gaussian process in two ways. First, we assess the ability of the model to capture the underlying physical truth. Second, we formulate several design specific queries that arise in a practical setting and investigate to which extend the emulation can be utilized to answer these.
3.1. Model Performance
In order to assess the accuracy of the model, we need a ground truth. We ran the simulator, as described in [
2], 45,000 times. However, the movement velocity, height of the camera and the ambient temperature were kept constant at 10 mm/s, 450 mm, and 20 °C, respectively. The remaining input variables were as follows:
Distance between the heat source and the camera, range 50 to 600 mm;
Heating power, range 50 to 800 W;
Start depth of the defect, range 2 to 9.8 mm;
Diameter of the defect, range 12 to 24 mm.
These four tuples are the inputs of our dataset. The reason we limited the dataset to four variables is that composing a dataset of seven input variables with enough resolution to assess the accuracy of the model would take a lot more data points and thus time to simulate. Moreover, in an industrial context, one does not always have full control over the parameters we fixed in this demonstration, as they are dictated by the production process and installation itself.
For each of those four tuples, the temperature difference between a position on the surface above a defect and a position that is not above a defect is calculated. This temperature difference is the output of our dataset.
Via active learning, as described in
Section 2, we iteratively picked data points from the dataset and moved them to the training set of the Gaussian process. The remaining data points in the dataset served as test points. After the Gaussian process was trained, two calculations on the test points were performed:
The root mean square error between the posterior mean in each test point and the actual values from the simulations. This number serves as a measurement for the deviation of the model from the underlying truth.
The average posterior standard deviation for all remaining test points. This is a measurement for how much uncertainty there still is in the system. The point with the highest variance, i.e., the highest uncertainty, becomes the point that is moved from the test set to the training set of the Gaussian process in the next iteration.
When both of these numbers flatline, then there is little to be gained in running more simulations. In that case, the Gaussian process is able to approximate the ground truth.
We performed the active learning process for 500 iterations. We started with 25 training points randomly chosen from the dataset. This makes for a total of 525 data points in the Gaussian process of the last iteration. In
Figure 3, the learning curves of the Gaussian process are visualized. The exact curves of the iterations depend on the initial random points that are drawn from the dataset described aboveblack. Therefore, we repeated the experiment five times.
The hyperparameters for the covariance functions, as described in Equation (
4), of the trained Gaussian processes, can be found in
Table 1.
3.2. Parameter Design
Generating a response surface is a technique used in the design of experiments (DOF) often with the idea of investigating the interference between several factors in a process. It is possible to determine which factors have an influence on the output effect and in what way the output responds to a change in one or a collection of input parameters. Afterwards, the insight in the process and the response surface itself can be used to optimize the parameters in order to minimize/maximize the output effect of the process. In industrial applications, one is generally not interested in the influence of the different input parameters on the output effect. There, focus lies on how to optimize the efficiency of the inspection process itself, or in other words, how to reduce its economical impact on the overall production process.
Once a Gaussian process is trained to emulate the simulations up to an adequate level, we can query the model with real-world engineering design questions. Below, we give a few examples. We picked the threshold values in these examples in an arbitrary way. Here, they only serve demonstrating purposes. They are, of course, application specific. In a practical setup, they depend on the type of the camera used, the ambient temperature in the production facility, the material of the sample under inspection, etc.
Example 1. From a practical and economical point of view, the most crucial input parameter is the heating power. The reduction in the energy needed to heat a sample under inspection results in a drastic reduction in the inspection cost. To accommodate this, we can ask the following question: what parameter combination should be used to be able to detect a predefined defect with a certain start depth and diameter, with a minimal of amount of heating energy needed? For instance, we want to be able to detect a defect with a diameter of 14 mm, which is situated 6 mm below the surface. We query the GP posterior prediction for all test and training points by filtering on the input variables’ start depth and diameter. Then, we filter the temperature difference on a range from 5 to 10 °C. A temperature difference that is lower might make it hard to detect with a given camera. A temperature difference that is higher means the sample under inspection is heated to a value that is too high, resulting in a waste of energy of an even and undesirable effect on the material itself. From all the remaining possible inputs, we choose the ones with the lowest heat load. In our case this is 50 W. We end up with a range for the distance between the camera and the heat source of 335 to 420 mm. All these values yield a temperature difference between 5 and 10 °C for the given defect. On the other hand, when the distance between the heat source and the camera is below this range, we can observe that the heat load has to be increased to 75 W to still yield a temperature difference between 5 and 10 °C.
Example 2. In some practical scenarios, it is possible that the distance between the heat source and the camera has to be a fixed value, for instance, due to constraints on the physical setup in the production environment. We can ask the trained model, what parameter combination should be used to be able to detect a range of defects with only adjusting the heating power? Again, we filter the temperature difference on a range from 5 to 10 °C. We fix the distance between the heat source and the camera to 100 mm. We observe that we need a minimum of 500 W to be able to detect all defects from our dataset. When the heat load is below 500 W, we can no longer detect defects that are lower than 9.8 mm below the surface.
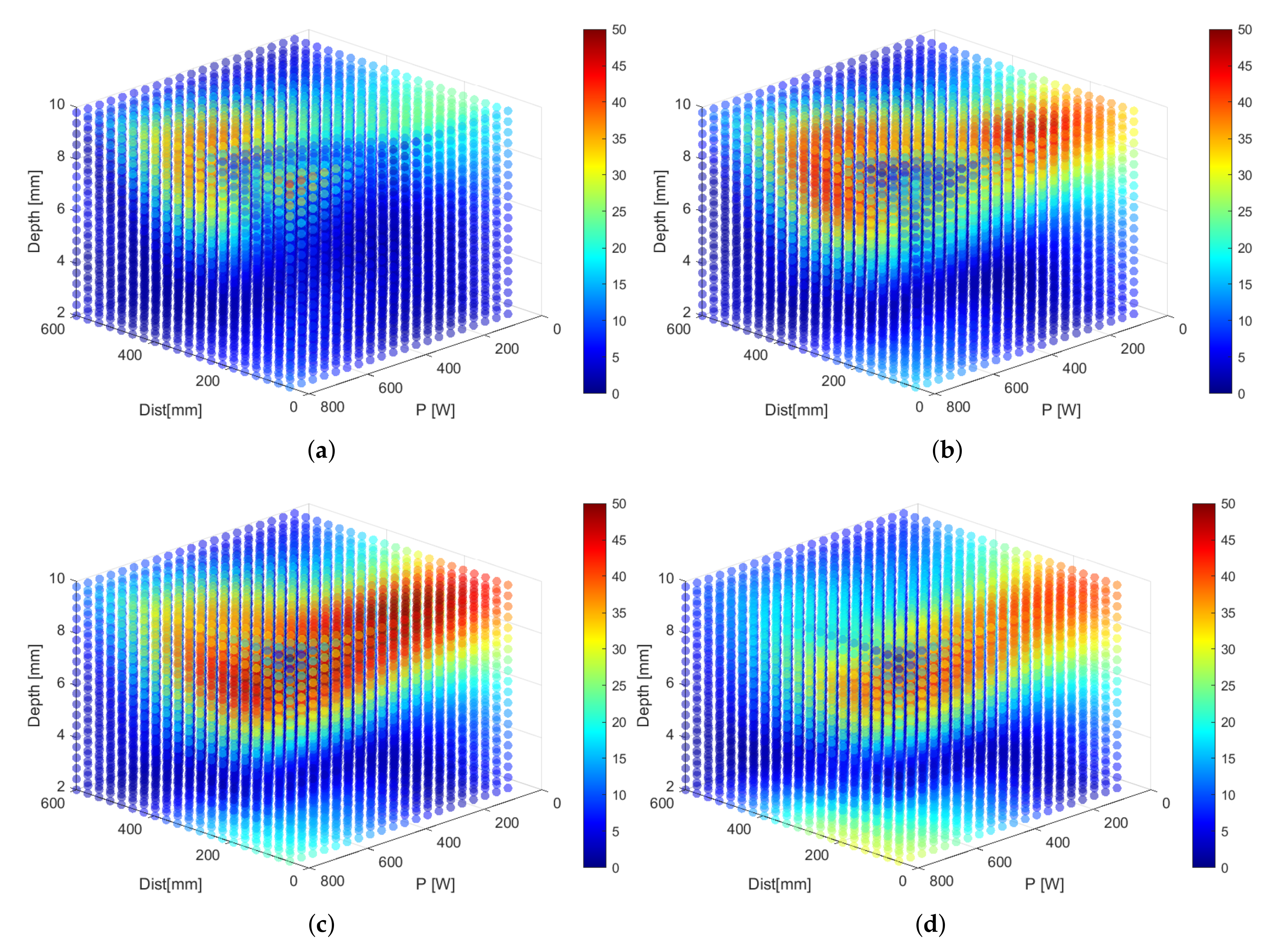
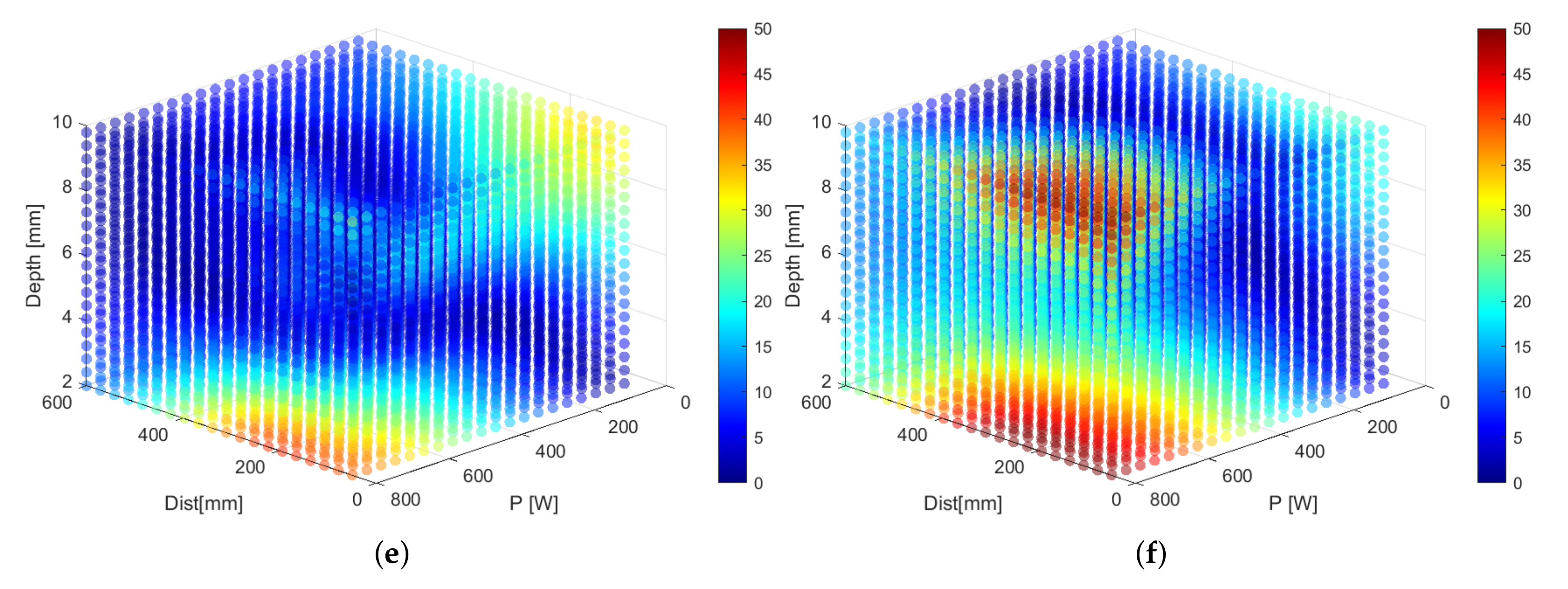
Example 3. The model can also be used to visualize regions in the input space that result in undesirable temperatures for the sample. For instance, we can highlight regions where the temperature of the sample would become too high. This serves as a warning, as temperatures that are too high might cause damage to the sample under inspection. In Figure 4, we provide an overview of the predicted temperature differences per defect diameter. Regions that are colored are to be avoided when designing the dynamic line scan thermography setup. These plots also reveal that some regions of the input space are workable for some defects, but not for others. The full benefit of these plots comes into its own when using software that allows the end user to rotate the generated cubes, which is trivial to set up in Matlab or any Python environment equipped with a graphing library, such as Matplotlib. Example 4. In this last example, we visualize the plots from Example 3 in a different way to highlight regions of the input space that correspond to appropriate temperature differences. In Figure 5, we color regions that result in hard-to-detect (or even undetectable) temperature differences red. For this example, we set the threshold to an arbitrary value of 5 °C. Regions that result in temperature differences above 25 °C are colored yellow. Ideal regions lie in between those values and are given the color green (see Table 2).
Figure 4.
Visualization of the temperature difference for six different defect diameters. (a) 12 mm, (b) 14 mm, (c) 16 mm, (d) 18 mm, (e) 20 mm and (f) 22 mm. Red indicates temperature differences that might result in damaging the sample under inspection. These plots serve as a warning when designing a setup.
Figure 4.
Visualization of the temperature difference for six different defect diameters. (a) 12 mm, (b) 14 mm, (c) 16 mm, (d) 18 mm, (e) 20 mm and (f) 22 mm. Red indicates temperature differences that might result in damaging the sample under inspection. These plots serve as a warning when designing a setup.
Figure 5.
Visualization of the temperature difference for six different defect diameters. (a) 12 mm, (b) 14 mm, (c) 16 mm, (d) 18 mm, (e) 20 mm and (f) 22 mm. Red are temperature differences below 5 °C, yellow above 25 °C and green in between. Only the green regions are of practical value in real-world applications.
Figure 5.
Visualization of the temperature difference for six different defect diameters. (a) 12 mm, (b) 14 mm, (c) 16 mm, (d) 18 mm, (e) 20 mm and (f) 22 mm. Red are temperature differences below 5 °C, yellow above 25 °C and green in between. Only the green regions are of practical value in real-world applications.
Table 2.
Optimal parameter sets found for the examples explained above.
Table 2.
Optimal parameter sets found for the examples explained above.
| Parameter | Example 1 | Example 2 | Example 3 | Example 4 |
|---|
| Ambient Temperature [°C] | 20 | 20 | 20 | 20 |
| Velocity [mm/s] | 10 | 10 | 10 | 10 |
| Camera Height [mm] | 450 | 450 | 450 | 450 |
| Diameter Hole [mm] | 14 | 12–24 | 22 | 12 |
| Startdepth Hole [mm] | 6 | 2–9.8 | 2–9.8 | 2–9.8 |
| Heating Power [W] | 50 | 500 | 200–400 | 600–800 |
| Distance cam.–heat [mm] | 335–420 | 100 | 500–600 | 50–200 |
4. Discussion
Both the RMSE and the average standard deviation show an initial steep decline that gradually flatlines. All our experiments have shown to converge to the same values after enough iterations. These curves support the decision making process whether or not to continue to add more data points (costly simulations). For our application, one could conclude that after 350 iterations the RMSE and the standard deviation are sufficiently low enough and do not change significantly anymore. The total amount of iterations needed to train the Gaussian process such that it can approximate the simulations up to an adequate level, depends on the application itself. It is a function of the available computational budget and the amount of uncertainty that can be tolerated. Similarly, generating a response surface is also subjective in the sense of deciding when a surrogate has a sufficient resolution and accuracy for the specified application. Therefore this manuscript does not focus on the exact numbers or percentage of data points needed to approximate the response surface.
Simulators and emulators are models of an underlying truth and as such nothing more than an approximation. This means that one has to be prudent about the outcomes of such models. For instance, it is possible for the model to predict values that do not correspond with reality or, even worse, that do not have any physical meaning. For instance, we noticed that for some test points (points were we make predictions) far away from the data, it is possible to obtain negative values for the temperature difference, even though the data only contained positive values. This issue can be dealt with in two ways. First, one could implement constraints on the model. In our case we could alter the covariance function, such that only positive values can be predicted by the model. This is an approach thoroughly explained in [
23]. Second, in this research, we chose the Gaussian process for the underlying machine learning model. By following the Bayesian paradigm [
9], this stochastic model makes predictions that are not just numerical values (in our case for the temperature difference). They are also accompanied by a variance. As such, each prediction for every test point is in fact a normal distribution. The variance can be interpreted as a measurement of uncertainty about the prediction. This extra information should be taken into account when evaluating the predictions.
As mentioned throughout the text, several optimisations could further improve the performance of the model. They were not investigated in this work, because we wanted to restrict ourselves to a basic implementation of the core idea of approximating dynamic line scan thermography parameter design via emulation. We consider these to be future work. First, the initial sampled points were drawn uniformly from the input space. Several alternatives are described in the literature [
12,
16,
17]. As the total number of sampled points increases, the influence of the initial points becomes less important. Still, on very tight computational budgets, this could become a factor of interest. Second, the Uncertainty Sampling method sometimes favours points on the boundary of the input space. This is due to the fact that the density of data points is lower in those regions and thus the uncertainty is higher (there are no data points beyond the boundary). Integrated Variance Reduction takes this drawback into account and calculates the total amount of uncertainty reduction a new data point yields. It does so for each point in the test set. This reduces the score of points in the vicinity of the boundary. It is to be expected that Integrated Variance Reduction would reduce the number of time consuming sampled input points, but at a higher computational cost. This is also stated in [
18]. The effect of this remains an open question. Third, as also stated above, the Gaussian process used in this study can be further developed to incorporate prior knowledge in the form of constraints.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}