1. Introduction
With the development of social networks, the speed of information dissemination is increasing rapidly, which not only facilitates people to socialize but also facilitates the spread of false information [
1,
2]. False information seriously damages the credibility of the media, infringes the public’s right to know, hinders the public’s right to participate and supervise, and in severe cases can disrupt social order, cause people’s property damage, cause public panic, disrupt social order and have serious adverse effects on society. For example, in 2011, the rumor that iodized salt would prevent nuclear radiation caused by the Fukushima nuclear accident in Japan caused everyone to frantically buy salt, which not only caused a waste of resources but also disturbed social stability. Therefore, how to detect false information at an early stage has become a recent research hotspot. Early information is in the form of plain text, so the early methods mainly detect false information by extracting text features from text content or extracting corresponding single-modality features from other single-modality data [
3,
4]. With the development of social media, the form of information has changed from the form of plain text to the form of multimedia [
5,
6,
7]. Most of the existing information is in the form of multimedia. At the same time, research found that the fusion of features of different modalities can effectively improve the performance of the model. Therefore, the recent research in the field of false information detection is mainly based on multimodal methods. However, the existing multimodal methods have shortcomings. First, most of the existing multimodal methods use early fusion methods or late fusion methods. However, there are many limitations in using only one method to fuse multimodal information, and it is difficult to fully fuse the information of different modalities. Second, for text feature extraction, most of them rely on the concatenated output of bi-gated recurrent unit (Bi-GRU) at each time step. However, the feature extraction process lacks the participation of corresponding factual knowledge. Such methods have limited ability to understand named entities in the text, and thus, it is difficult to fully capture the clues at the semantic level of false information [
8]. The extraction of image features mostly relies on VGG19 [
9] to obtain features. This method requires a large number of parameters and computing resources during training. The quality of features extracted by these two models is lower than that of some existing models. Finally, the problem of original information loss is not considered when performing information fusion between modalities.
In this paper, the above-mentioned issues are investigated separately:
- (1)
This paper studies the problem of how to mitigate the influence of irrelevant features and how to enhance fusion between multimodalities. In this paper, the deep autoencoder is used to fuse the information of different modalities early, and the noise removal function of the deep autoencoder is used to reduce the impact of noise on the model performance. The multi-classifier hybrid prediction method is used to fuse the multimodal information in the later stage to enhance the fusion effect between different modalities.
- (2)
For the problem of low quality of single-modality features, this paper uses bidirectional encoder representations for transformers (BERT) [
10] to replace Bi-GRU in the text feature extraction. BERT has proven its effectiveness in many fields. Shifted window transformer (SWTR) [
11] is used to replace VGG19 in image feature extraction. SWTR has achieved good performance in multiple tasks, such as object detection, instance segmentation and semantic segmentation since its release. In this paper, SWTR is applied to multimodal false information detection tasks as an image feature extraction module. The experimental results show that SWTR also has a good performance in the field of false information detection.
- (3)
For the problem that the deep autoencoder will lose some information while removing noise, after the joint feature is obtained by the deep autoencoder, the text feature and image feature are spliced with the feature to reduce the loss of original information.
- (4)
Comparative experiments and ablation experiments are performed on the Chinese and English datasets, which prove the effectiveness of the model and its various modules in false information detection.
3. False Information Detection Method
Problem Definition: Suppose is a dataset of multimodal posts in social networks where is the ith post. is the text set, is the text content in the ith post. is an image set, is the image included in the ith post. is the tag set, is the tag of the ith post. , The task of false information detection can be described as learning a function , , is the predicted label value of the ith post, , 0 represents true information, and 1 represents false information.
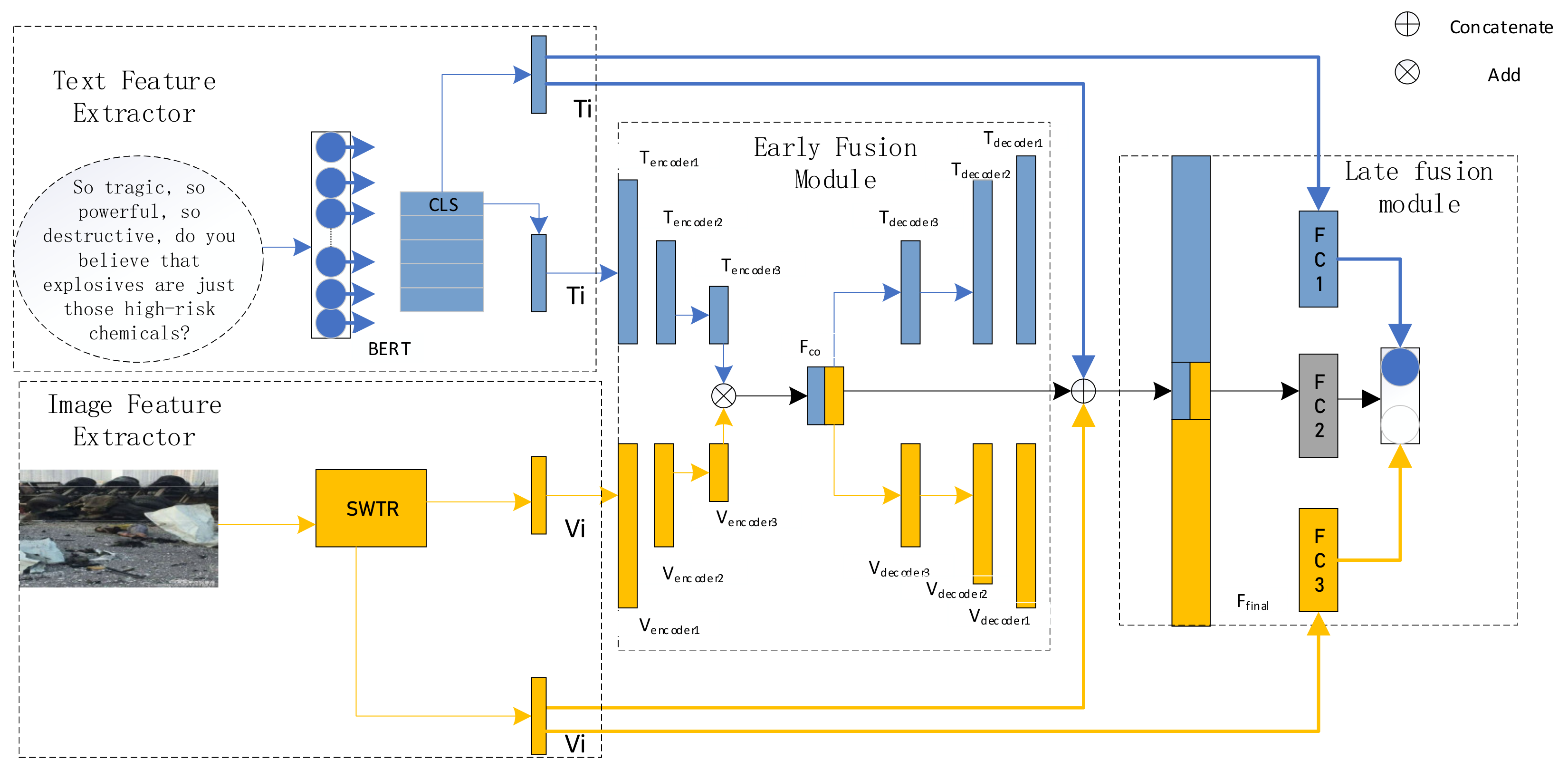
The model in this paper is mainly composed of four parts: text feature extractor, image feature extractor, early fusion module and late fusion module.
Figure 1 shows our proposed false information detection method based on multimodal feature fusion and multi-classifier hybrid prediction.
The model first uses the text feature extractor and the image feature extractor to extract the text and image features, and then input the two obtained features into the early fusion module to obtain joint features, and the text features, image features and joint features are concatenated to strengthen the joint features. Finally, the text features, the image features and the enhanced joint features are used to obtain the prediction results through the later fusion module. The early fusion module realizes early fusion between different modal features through the deep autoencoder, and the late fusion module uses the method of multi-classifier mixed prediction to fuse the prediction probabilities of different modalities, The pseudocode is shown in
Table 1.
3.1. Text Feature Extraction
The text is the main part of the post. It contains the main information that the publisher wants to express, and it can also show the publisher’s emotions and other information. We adopt the BERT pre-training model with strong modeling ability to deal with this important part.
BERT is a pre-training model based on Transformer [
28]. Its special unsupervised task enables it to learn contextual information, and it only uses self-attention mechanism instead of RNNs so that it can be parallelized to speed up the training process, and because it has enough parameters, the model can learn more knowledge through learning on large-scale pre-training corpus. It learns some syntactic knowledge and common sense. In some recent similar tasks, usually, BERT-based models will perform better than other networks built on RNNs and CNNs. These experiments show that higher-quality text features can be extracted using BERT. Therefore, this paper uses BERT to extract text features. BERT is used to input text in the form of ‘[CLS]’ + sentence + ’[SEP]’, and the output is an embedded representation of a set of words. The text features are calculated as follows:
where
is a collection of text,
is the feature vector of the text,
is the dimension of the feature vector.
Since BERT uses the self-attention mechanism internally, if a word with a specific meaning is used to represent the entire sentence, the word vector will be affected by the word itself, and it is difficult to objectively represent the characteristics of the entire sentence. Since the [CLS] vector is a marker bit and does not have semantic information, it will not be affected by itself, so it can be better used as a feature of the entire text. Therefore, this paper selects the [CLS] vector of each sentence to represent the features of the entire text.
3.2. Image Feature Extraction
Picture can supplement the text information and increase the credibility of the content. Processing image parts can better understand the semantics of multimodal posts and thus better detect false information. We use SWTR to process the image part.
SWTR is also an image feature extraction model based on Transformer. This model expands the applicability of Transformer, transfers the high performance of Transformer to the visual neighborhood, solves the shortage of CNN for global information feature extraction, and at the same time, with its unique window mechanism, it greatly reduces the computational complexity of self-attention and solves the problem of fixed token scale, which has become the general backbone of computer vision. Since it was proposed, it has achieved relatively good results in tasks, such as image classification and segmentation tasks. Therefore, this paper uses SWTR as the image feature extractor. The input of
SWTR is a picture, and the output is the feature vector of the picture. The specific calculation process is as follows:
where
is a picture contained in the ith post,
is the feature vector of the picture, and
is the dimension of the feature vector.
3.3. Early Fusion
We obtained text features
and image features
. In order to obtain the interactive relationship between the text and the image, this paper uses a deep autoencoder to interact with text and image features to obtain multimodal joint features. The deep autoencoder will convert the high-dimensional feature vector into a low-dimensional feature vector through a function. The low-dimensional feature vector will contain most of the main features of the data, and some tiny features may be lost, so as to eliminate irrelevant features in the features. This module firstly inputs the features of text and images into the encoder for encoding. After the features of text and images enter the encoder, they will be compressed into low-dimensional feature vectors through two linear layers, and then add the encoded two feature vectors by dimension. Finally, the added feature vector is input into the two decoders to obtain two outputs. The specific calculation process is as follows:
is a linear transformation function, which transforms the dimension of the feature vector, and is an addition operation, which adds the two input feature vectors according to the corresponding dimensions. is the feature of the text feature processed by the encoder, and is the feature of the image feature Vi processed by the encoder. , is the dimension of the feature vector processed by the encoder. is the feature vector decoded by the , and , di is the dimension of the feature vector.
The and are only used when training this module. This module obtains the prediction error by comparing the output of the decoder with the input of the encoder, and then backpropagation is performed to train the deep autoencoder and gradually improve the accuracy of autoencoding, and finally, the trained model is used as the early fusion module of the model in this paper. In this paper, the after the addition of and is taken as the joint features of multimodality.
3.4. Late Fusion
Because the deep autoencoder changes the feature vector from high dimensional to low dimensional, it not only removes some irrelevant features but also loses some original information of text and images. Therefore, this paper does not use the joint features
extracted from the early fusion module to train classifier 2 but uses the joint features
enhanced by the original information to train it. The enhanced joint features
is obtained by concatenating the text features
and image feature
with the multimodal joint feature
.
is the concatenating operation, .
The three classifiers,
,
and
, are all fully connected layers with activation function
.
classifies the true and false information through text information,
classifies the true and false information through the fusion information of text and images, and
classifies the true and false information through image information. The text feature
, the enhanced joint features
and the image feature
are projected to the binary target space to obtain the probability distributions
,
and
.
where
,
and
represent weight parameters, and
,
and
represent bias terms.
Then, the obtained three probability distributions are fused in proportion to obtain the final predicted probability.
where
,
and
, respectively, represent the degree of influence of different parts of the model on the final detection results.
3.5. False Information Detection
After normalizing the probability distribution of the later fusion by the function, take out the one with the highest probability as the final result.
is the predicted tag value of our model for ith post.
The loss function is defined as the cross-entropy loss function between the predicted probability distribution and the true label:
where
m is the number of posts, which
is the true label value, 1 represents false information, 0 represents true information, and
represents the probability of being predicted to be false information.
5. Conclusions
The detection model proposed in this paper has the following advantages: (1) It can interact with the data of different modalities in the early stage to exploit its correlation; (2) It can remove the influence of noise during the fusion process; (3) It can reduce the loss of information in the fusion process; (4) The post-fusion module enables the model to handle the asynchrony of the data, allowing different modalities to use their most appropriate analysis method. At the same time, it contains several disadvantages: (1) The remaining information, other than text and images, cannot be used; (2) The extraction of features is difficult. The features of different modalities must have the same format. It is difficult to express the time synchronization between multimodal features, and it is difficult to obtain the cross-correlation between features as the number of features increases; (3) The model structure is complex and the training is difficult; (4) Only the overall fusion is performed on the data of different modalities, and the local fusion is not performed.
This paper proposes a model for false information detection using multimodal information. The model uses a hybrid fusion method to fuse multimodal information, firstly using a deep autoencoder as an early fusion model to obtain multimodal joint features, and the loss of original information in the fusion process is reduced by concatenating text features and image features on the joint features. Finally, the multimodal data are further fused by the late fusion method. The experimental results on Weibo dataset and Twitter dataset show that the detection accuracy of our model is better than the baseline model. At the same time, the model proposed in this paper has limitations: (1) For a post containing multiple pictures, only one of the pictures can be used to detect it, and all the pictures cannot be used at the same time; (2) The complex structure of the model has a large number of parameters and cannot be run on small devices. The following issues should be addressed in future work: (1) Reduce the complexity of the model so that it can be applied to small devices; (2) Use all the information in the post to detect it; (3) Detect false information that has begun to spread on social platforms.




{kind=link}