
Boosting Iris Recognition by Margin-Based Loss Functions




Abstract
:1. Introduction
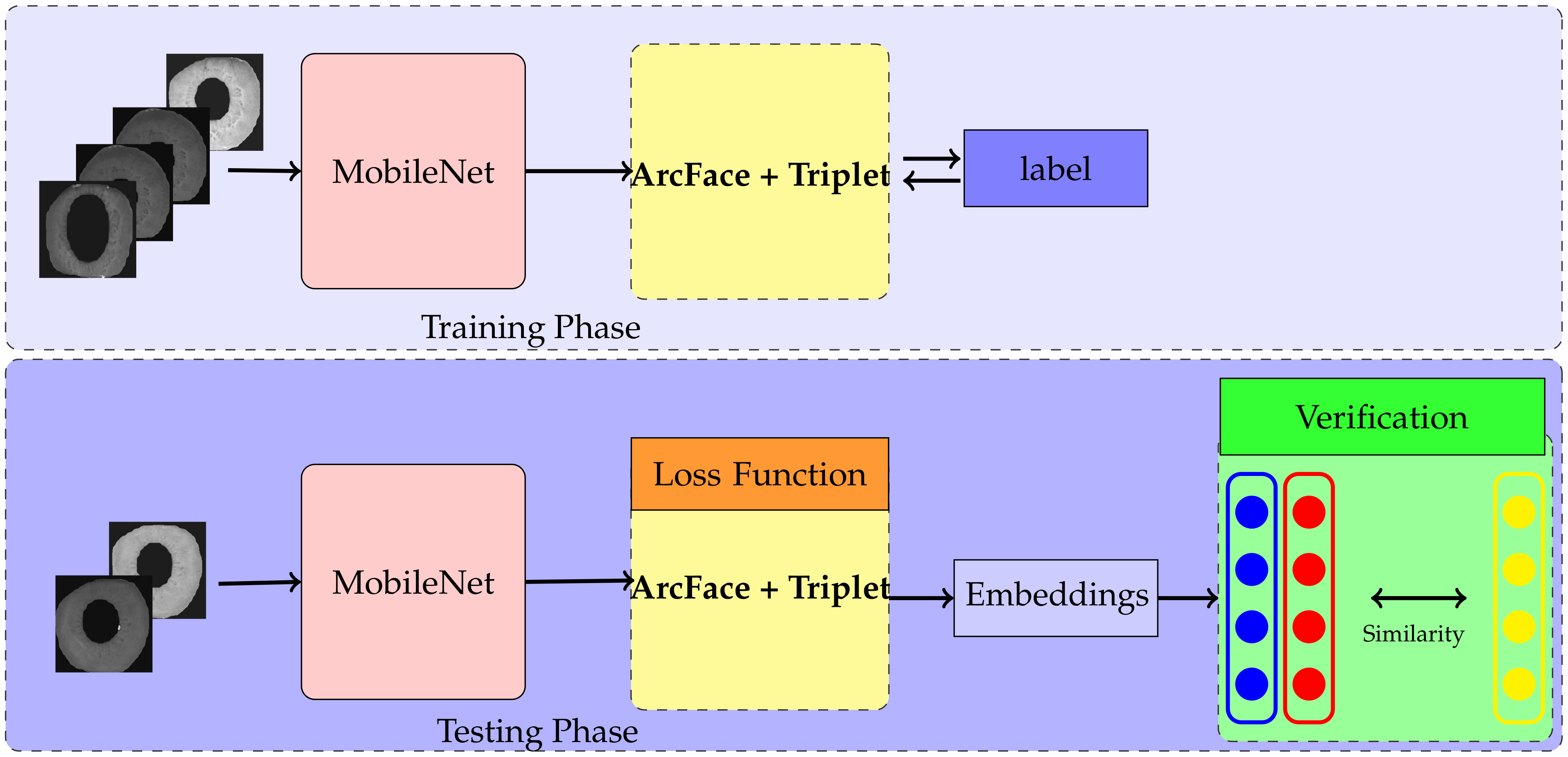
- To extract discriminative iris features, our study focuses on implementing state-of-the-art loss functions, especially a combination of ArcFace and Triplet loss with a light-weight MobileNet architecture for the training approach;
2. Related Work
3. Proposed Approach
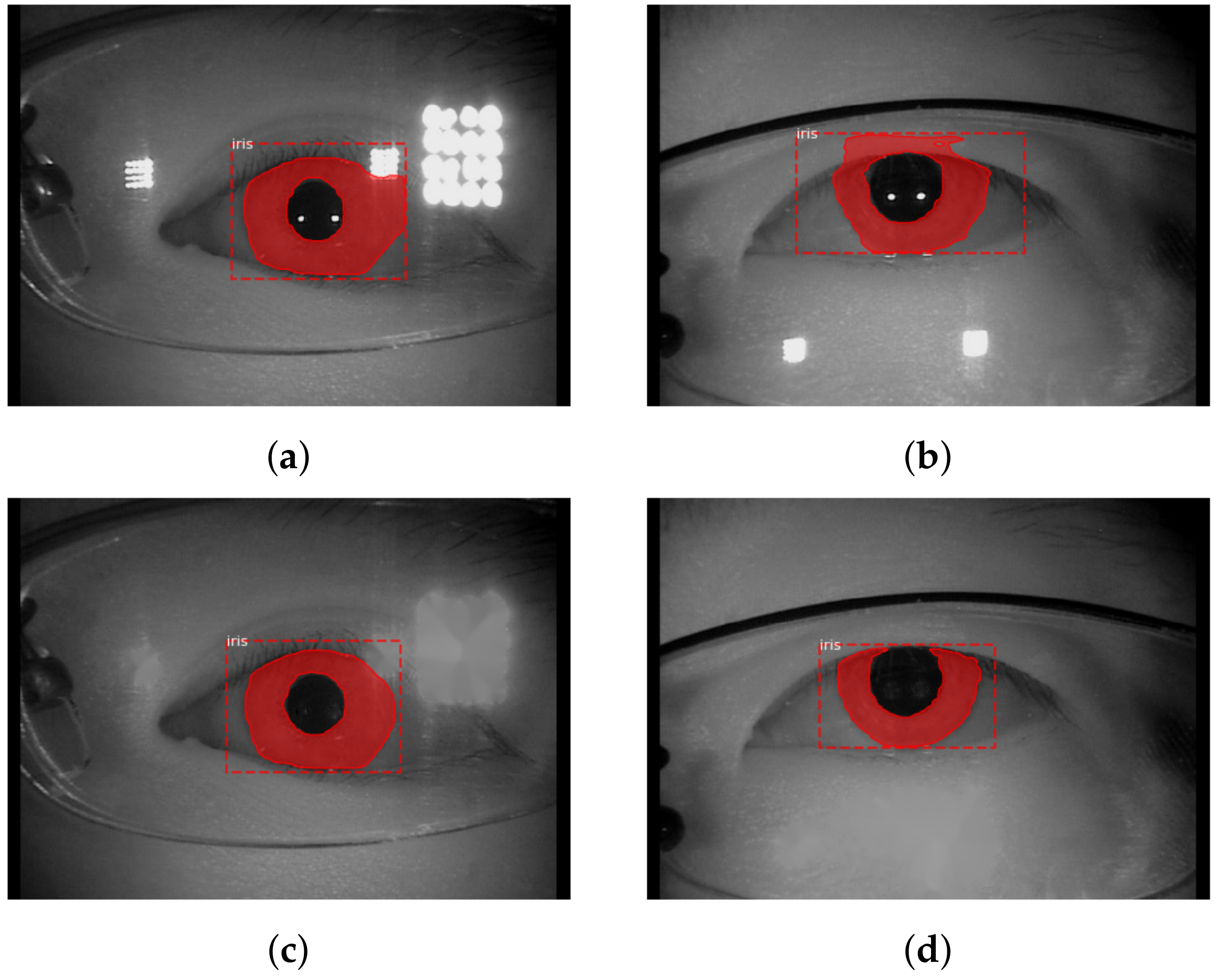
3.1. Preprocessing and Segmentation
3.2. Combined Loss of ArcFace and Triplet
3.3. Network Architecture
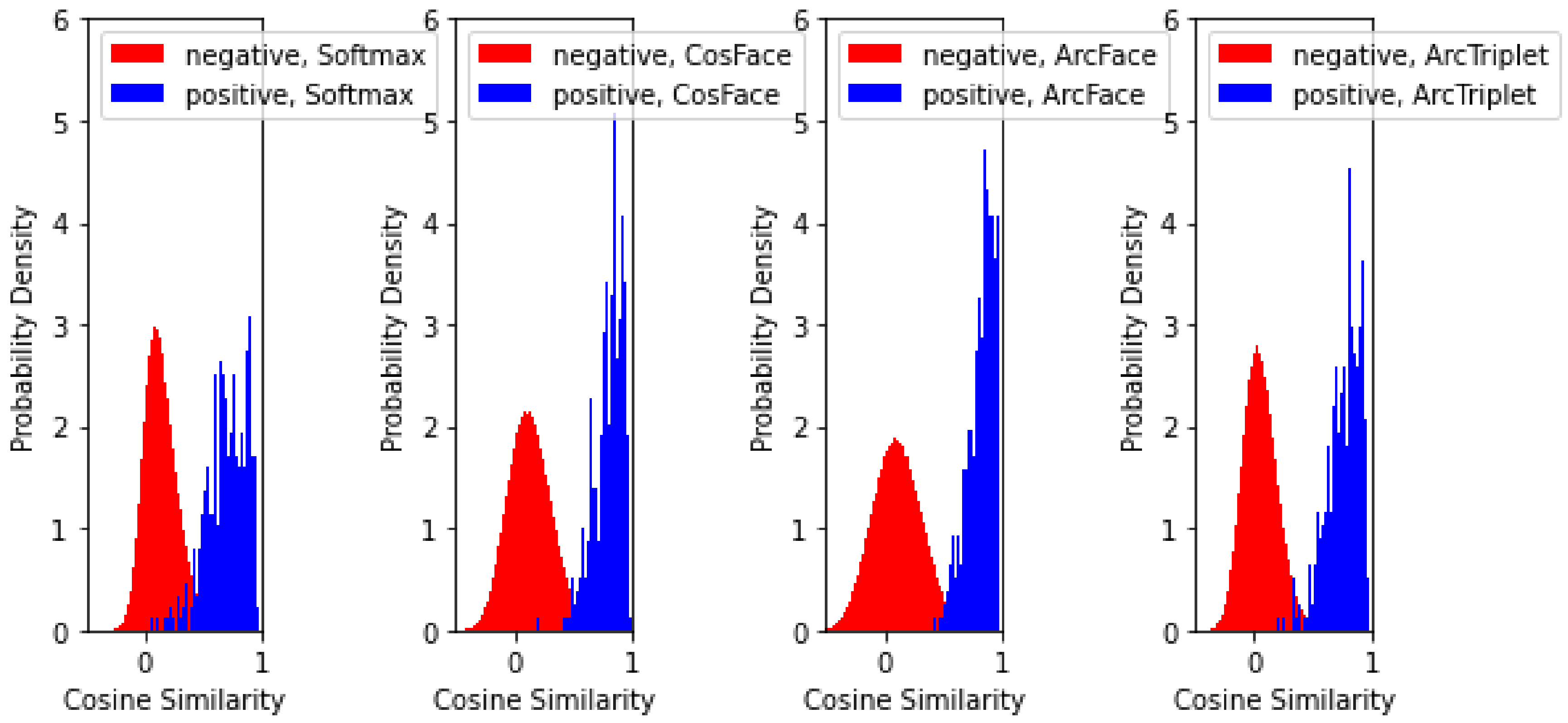
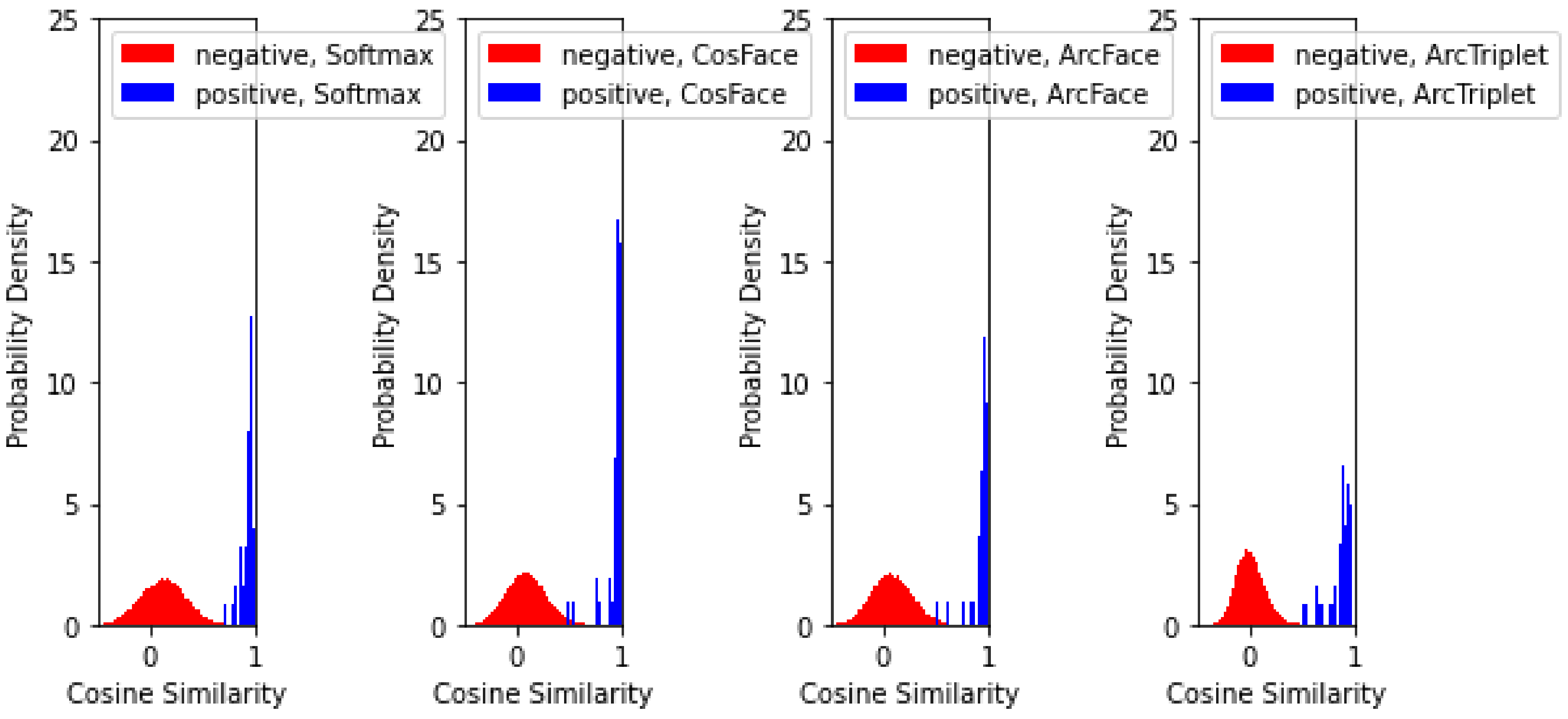
4. Experiments and Results
4.1. Datasets
- CASIA-Iris-Thousand. The CASIA-Iris-Thousand [14] includes 20,000 images collected from 1000 subjects using the IKEMB-100 camera. Eyeglasses and specular reflections cause the main challenges in this dataset. CASIA-Iris-Thousand is the first available iris dataset of 1000 people. This large number of classes causes a challenge for analyzing unique iris characteristics and requires new classification methods. The images in this collection were recorded in resolution in jpg format. The resolution of the segmented image is . we used the 10 left iris images from all subjects for the training set. We also select five random right iris images from each category to test the network performance;
- IITD. The IITD [15] contains 2240 images of the iris collected from 224 students and staff in Delhi, India.The database consists of 176 males and 48 females in the age range 14–55 years. There are different (iris) sizes and distributions of colors in this dataset. The images were recorded at resolution and BMP format. The segmented images have a size of . We use the five images from the left iris images for network training and the five right iris images for testing.
4.2. Experimental Settings
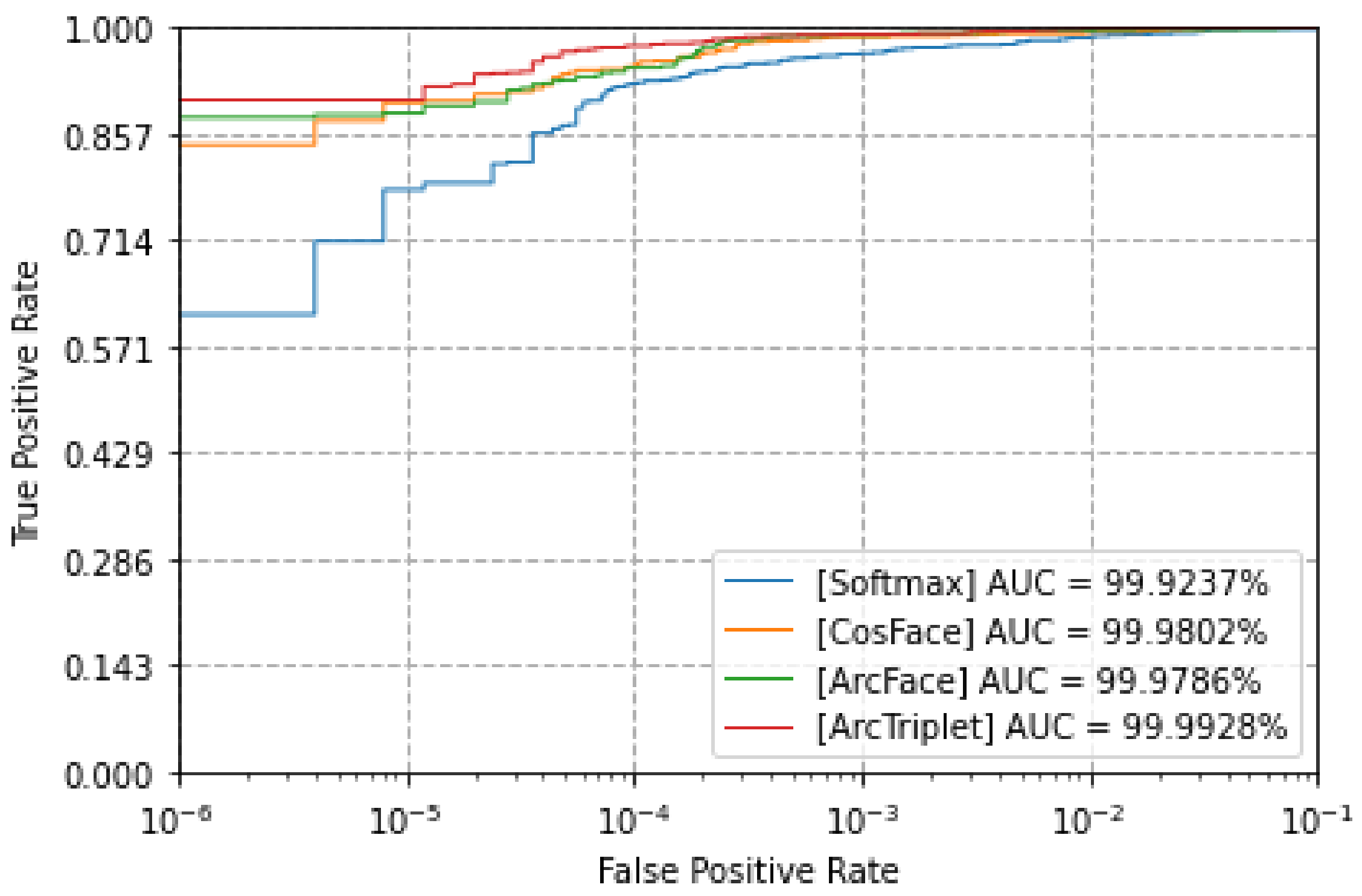
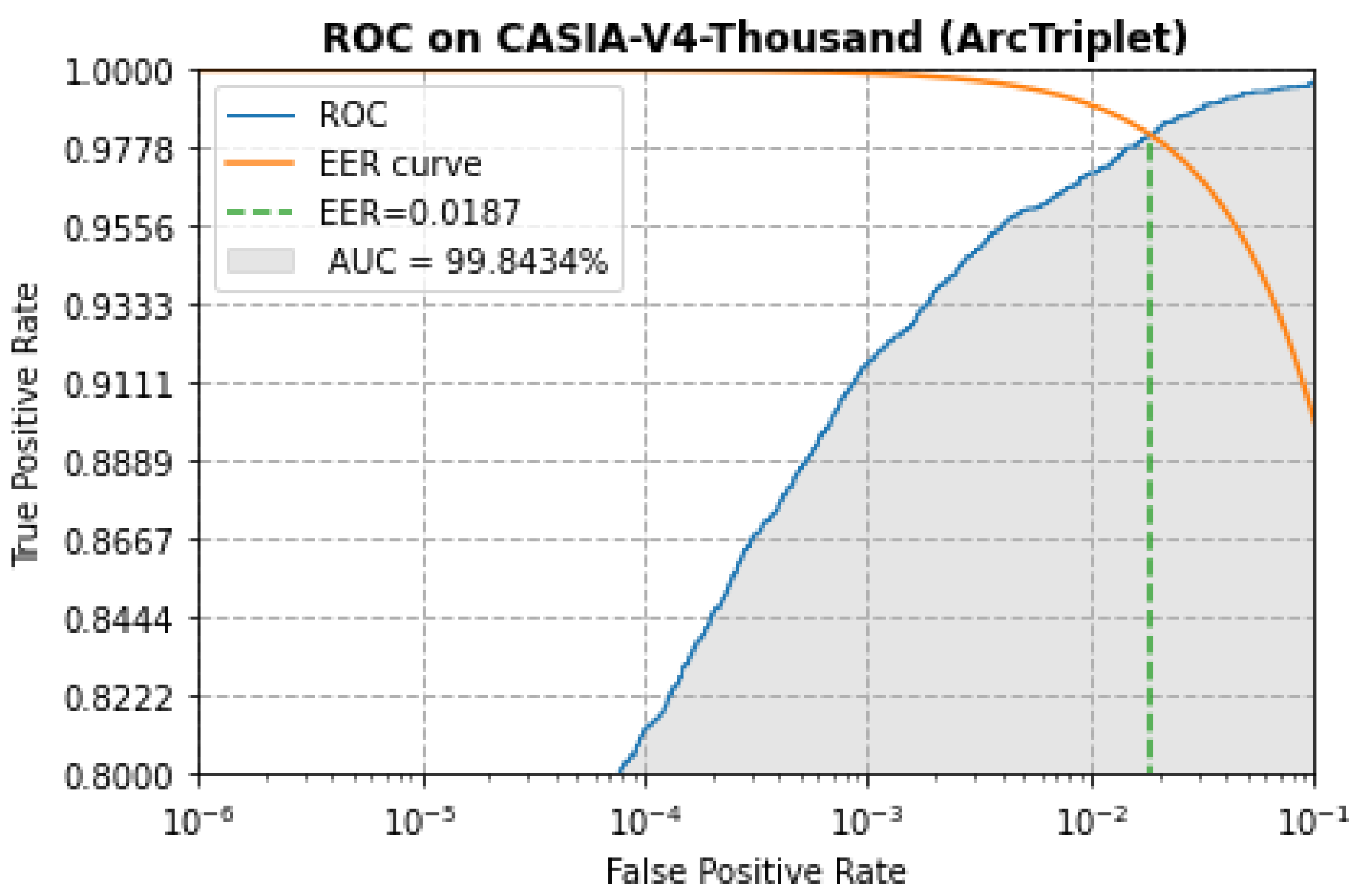
4.3. Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Khaldi, Y.; Benzaoui, A.; Ouahabi, A.; Jacques, S.; Taleb-Ahmed, A. Ear recognition based on deep unsupervised active learning. IEEE Sens. J. 2021, 21, 20704–20713. [Google Scholar] [CrossRef]
- Hu, J.; Wang, L.; Luo, Z.; Wang, Y.; Sun, Z. A Large-scale Database for Less Cooperative Iris Recognition. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Gomez-Barrero, M.; Drozdowski, P.; Rathgeb, C.; Patino, J.; Todisco, M.; Nautsch, A.; Damer, N.; Priesnitz, J.; Evans, N.; Busch, C. Biometrics in the era of COVID-19: Challenges and opportunities. arXiv 2021, arXiv:2102.09258. [Google Scholar]
- Jain, A.K.; Arora, S.S.; Cao, K.; Best-Rowden, L.; Bhatnagar, A. Fingerprint recognition of young children. IEEE Trans. Inf. Forensics Secur. 2016, 12, 1501–1514. [Google Scholar] [CrossRef]
- Bonnen, K.; Klare, B.F.; Jain, A.K. Component-based representation in automated face recognition. IEEE Trans. Inf. Forensics Secur. 2012, 8, 239–253. [Google Scholar] [CrossRef] [Green Version]
- Mundial, I.Q.; Hassan, M.S.U.; Tiwana, M.I.; Qureshi, W.S.; Alanazi, E. Towards facial recognition problem in COVID-19 pandemic. In Proceedings of the 2020 4th International Conference on Electrical, Telecommunication and Computer Engineering (ELTICOM), Medan, Indonesia, 3–4 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 210–214. [Google Scholar]
- Rahman, A.; Hossain, M.S.; Alrajeh, N.A.; Alsolami, F. Adversarial Examples—Security threats to COVID-19 deep learning systems in medical IoT devices. IEEE Internet Things J. 2020, 8, 9603–9610. [Google Scholar] [CrossRef]
- Talahua, J.S.; Buele, J.; Calvopiña, P.; Varela-Aldás, J. Facial recognition system for people with and without face mask in times of the covid-19 pandemic. Sustainability 2021, 13, 6900. [Google Scholar] [CrossRef]
- Daugman, J.G. High confidence visual recognition of persons by a test of statistical independence. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1148–1161. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Chinese Academy of Sciences Institute of Automation. Casia Iris Image Database. 2017. Available online: http://www.cbsr.ia.ac.cn/english/IrisDatabase.asp (accessed on 22 January 2021).
- Kumar, A.; Passi, A. Comparison and combination of iris matchers for reliable personal authentication. Pattern Recognit. 2010, 43, 1016–1026. Available online: https://www4.comp.polyu.edu.hk/~csajaykr/IITD/Database_Iris.htm (accessed on 25 April 2021). [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Jacques, S. Multi-block color-binarized statistical images for single-sample face recognition. Sensors 2021, 21, 728. [Google Scholar] [CrossRef]
- Militello, C.; Rundo, L.; Vitabile, S.; Conti, V. Fingerprint classification based on deep learning approaches: Experimental findings and comparisons. Symmetry 2021, 13, 750. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Zhang, K.; Muhammad, J.; Lu, T.; Zhang, Q.; Tian, Q.; He, Z.; Sun, Z.; Zhang, Y.; et al. NIR iris challenge evaluation in non-cooperative environments: Segmentation and localization. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Ouahabi, A. Signal and Image Multiresolution Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Ouahabi, A. A review of wavelet denoising in medical imaging. In Proceedings of the 2013 8th International Workshop on Systems, Signal Processing and their Applications (WoSSPA), Algiers, Algeria, 12–15 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 19–26. [Google Scholar]
- Telea, A. An image inpainting technique based on the fast marching method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Birgale, L.; Kokare, M. Iris Recognition without Iris Normalization. J. Comput. Sci. 2010, 6, 1042–1047. [Google Scholar] [CrossRef] [Green Version]
- Lozej, J.; Štepec, D.; Štruc, V.; Peer, P. Influence of segmentation on deep iris recognition performance. In Proceedings of the 2019 7th International Workshop on Biometrics and Forensics (IWBF), Cancun, Mexico, 2–3 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Chen, Y.; Wu, C.; Wang, Y. Whether normalized or not? Towards more robust iris recognition using dynamic programming. Image Vis. Comput. 2021, 107, 104112. [Google Scholar]
- Wildes, R.P. Iris recognition: An emerging biometric technology. Proc. IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef] [Green Version]
- Krichen, E.; Mellakh, M.A.; Garcia-Salicetti, S.; Dorizzi, B. Iris identification using wavelet packets. In Proceedings of the 17th International Conference on Pattern Recognition, 2004, ICPR 2004, Cambridge, UK, 26 August 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 4, pp. 335–338. [Google Scholar]
- Miyazawa, K.; Ito, K.; Aoki, T.; Kobayashi, K.; Nakajima, H. An effective approach for iris recognition using phase-based image matching. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1741–1756. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, M.; Li, H.; Sun, Z.; Tan, T. DeepIris: Learning pairwise filter bank for heterogeneous iris verification. Pattern Recognit. Lett. 2016, 82, 154–161. [Google Scholar] [CrossRef]
- Minaee, S.; Abdolrashidiy, A.; Wang, Y. An experimental study of deep convolutional features for iris recognition. In Proceedings of the 2016 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 3 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the 2016 IEEE international conference on image processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2301–2305. [Google Scholar]
- Nguyen, K.; Fookes, C.; Ross, A.; Sridharan, S. Iris recognition with off-the-shelf CNN features: A deep learning perspective. IEEE Access 2017, 6, 18848–18855. [Google Scholar] [CrossRef]
- Al-Waisy, A.S.; Qahwaji, R.; Ipson, S.; Al-Fahdawi, S.; Nagem, T.A. A multi-biometric iris recognition system based on a deep learning approach. Pattern Anal. Appl. 2018, 21, 783–802. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Li, H.; Sun, Z.; Tan, T. Deep feature fusion for iris and periocular biometrics on mobile devices. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2897–2912. [Google Scholar] [CrossRef]
- Zhao, T.; Liu, Y.; Huo, G.; Zhu, X. A deep learning iris recognition method based on capsule network architecture. IEEE Access 2019, 7, 49691–49701. [Google Scholar] [CrossRef]
- Zhao, Z.; Kumar, A. A deep learning based unified framework to detect, segment and recognize irises using spatially corresponding features. Pattern Recognit. 2019, 93, 546–557. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Ahmad, S.; Fuller, B. Thirdeye: Triplet based iris recognition without normalization. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–9. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 499–515. [Google Scholar]
- Chen, Y.; Wu, C.; Wang, Y. T-center: A novel feature extraction approach towards large-scale iris recognition. IEEE Access 2020, 8, 32365–32375. [Google Scholar] [CrossRef]
- Hsu, G.S.J.; Wu, H.Y.; Yap, M.H. A comprehensive study on loss functions for cross-factor face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 826–827. [Google Scholar]
- Ahmad, S.; Fuller, B. Unconstrained iris segmentation using convolutional neural networks. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 2–4 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 450–466. [Google Scholar]
- Hofbauer, H.; Alonso-Fernandez, F.; Wild, P.; Bigun, J.; Uhl, A. A ground truth for iris segmentation. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 527–532. [Google Scholar]
- Smirnov, E.; Melnikov, A.; Novoselov, S.; Luckyanets, E.; Lavrentyeva, G. Doppelganger mining for face representation learning. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 27–29 October 2017; pp. 1916–1923. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Conti, V.; Rundo, L.; Militello, C.; Salerno, V.M.; Vitabile, S.; Siniscalchi, S.M. A Multimodal Retina-Iris Biometric System Using the Levenshtein Distance for Spatial Feature Comparison. IET Biom. 2021, 10, 44–64. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss Functions | Decision Boundaries |
|---|---|
| Softmax | |
| CosFace | |
| ArcFace |
| Implementation | EER (%) | TPR (%) | AUC (%) |
|---|---|---|---|
| MobileNet + Softmax | 1.11 | 99.77 | 99.92 |
| MobileNet + Cosface | 0.78 | 100 | 99.98 |
| MobileNet + ArcFace | 0.45 | 100 | 99.98 |
| MobileNet + (ArcFace + Triplet) | 0.45 | 100 | 99.99 |
| Implementation | EER (%) | TPR (%) | AUC (%) |
|---|---|---|---|
| MobileNet + Softmax | 4.80 | 97.42 | 98.97 |
| MobileNet + Cosface | 2.64 | 99.22 | 99.67 |
| MobileNet +ArcFace | 1.89 | 99.58 | 99.80 |
| MobileNet + (ArcFace + Triplet) | 1.87 | 99.66 | 99.84 |
| IITD | CASIA-Iris-Thousand | |||||
|---|---|---|---|---|---|---|
| TPR (%) | EER (%) | AUC (%) | TPR (%) | EER (%) | AUC (%) | |
| DeepIrisNet [30] | 95.03 | 1.17 | 99.02 | 86.86 | 4.01 | 97.93 |
| UniNet [35] | 97.35 | 0.89 | 99.20 | 90.61 | 2.79 | 98.67 |
| CapsuleNet [34] | 97.39 | 0.76 | 99.27 | 91.04 | 3.05 | 98.60 |
| T-Center [39] | 97.43 | 0.74 | 99.30 | 92.54 | 2.36 | 98.75 |
| Proposed method (MobileNet + (ArcFace + Triplet)) | 100 | 0.45 | 99.99 | 99.66 | 1.87 | 99.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alinia Lat, R.; Danishvar, S.; Heravi, H.; Danishvar, M. Boosting Iris Recognition by Margin-Based Loss Functions. Algorithms 2022, 15, 118. https://doi.org/10.3390/a15040118
Alinia Lat R, Danishvar S, Heravi H, Danishvar M. Boosting Iris Recognition by Margin-Based Loss Functions. Algorithms. 2022; 15(4):118. https://doi.org/10.3390/a15040118
Chicago/Turabian StyleAlinia Lat, Reihan, Sebelan Danishvar, Hamed Heravi, and Morad Danishvar. 2022. "Boosting Iris Recognition by Margin-Based Loss Functions" Algorithms 15, no. 4: 118. https://doi.org/10.3390/a15040118
APA StyleAlinia Lat, R., Danishvar, S., Heravi, H., & Danishvar, M. (2022). Boosting Iris Recognition by Margin-Based Loss Functions. Algorithms, 15(4), 118. https://doi.org/10.3390/a15040118