
Multi-Level Fusion Model for Person Re-Identification by Attribute Awareness



Abstract
:1. Introduction
- Our model includes a multi-task learning module, local information alignment module, and global information learning module. The local information alignment module transforms pedestrian attitude alignment into local information alignment to inference pedestrian attributes.
- We design an improved network based on non-local and instance batch normalization (IBN) to learn more discriminative feature representations.
- The proposed method outperforms the latest person re-identification methods.
2. Related Work
3. Proposed Method
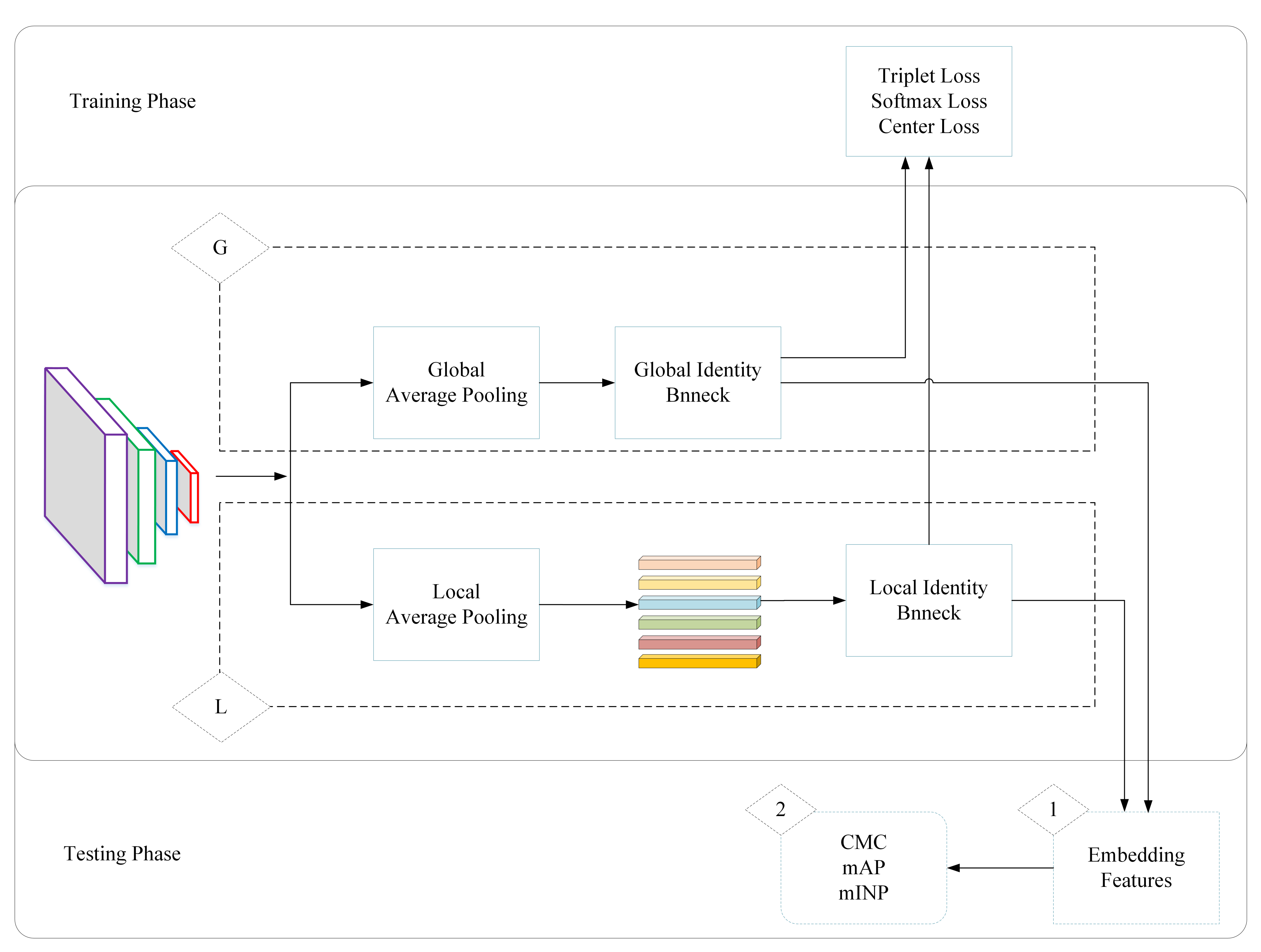
3.1. Network Structure
3.2. Non-Local Residual Network (ResNet) of Instance Batch Normalization (IBN)
3.3. Loss Function
4. Experiment
| Algorithm 1 MLAReID algorithm. |
| Input: Initialize learning rate (lr = 0.00035), optimizer (“Adam”), batchsize = 64 |
| Input: Input pedestrain images, pedestrain attributes |
| Input: Initialize multi-level fusion model (global-local, non-local, IBN) |
| 1: for each do |
| 2: Extract feature vectors from input images by the model |
| 3: Predict labels, attributes from input images by the model |
| 4: Update ID loss with Equation (3) |
| 5: Update Triplet loss with Equation (5) |
| 6: Update Attribute loss with Equation (9) |
| 7: end for |
| Output: F1 score, Recall, Accuracy, cmc, mAP, mINP |
4.1. Datasets and Settings
- Market-1501 [28]This dataset was collected by six cameras in front of a supermarket at Tsinghua University. It has 1501 identities and 32,668 annotated bounding boxes. Each annotated identity appeared in at least two cameras. The dataset is divided into 751 training identities and 750 testing identities, corresponding to 12,936 and 19,732 images, respectively. Attributes are annotated by pedestrian identity. Each image has 30 attributes. Note that although the upper- and lower-body clothing have seven and eight attributes, respectively, each identity has only one color marked “yes”.
- The dataset from Duke University contains 1812 identities and 34,183 annotated bounding boxes. It is divided into 702 training identities and 1110 testing identities, corresponding to 16,522 and 17,661 images, respectively. Attributes are annotated by pedestrian identity. Each image has 23 attributes.
4.2. Evaluation Metrics
4.3. Datasets and Settings
4.4. Comparison with the State-of-the-Art
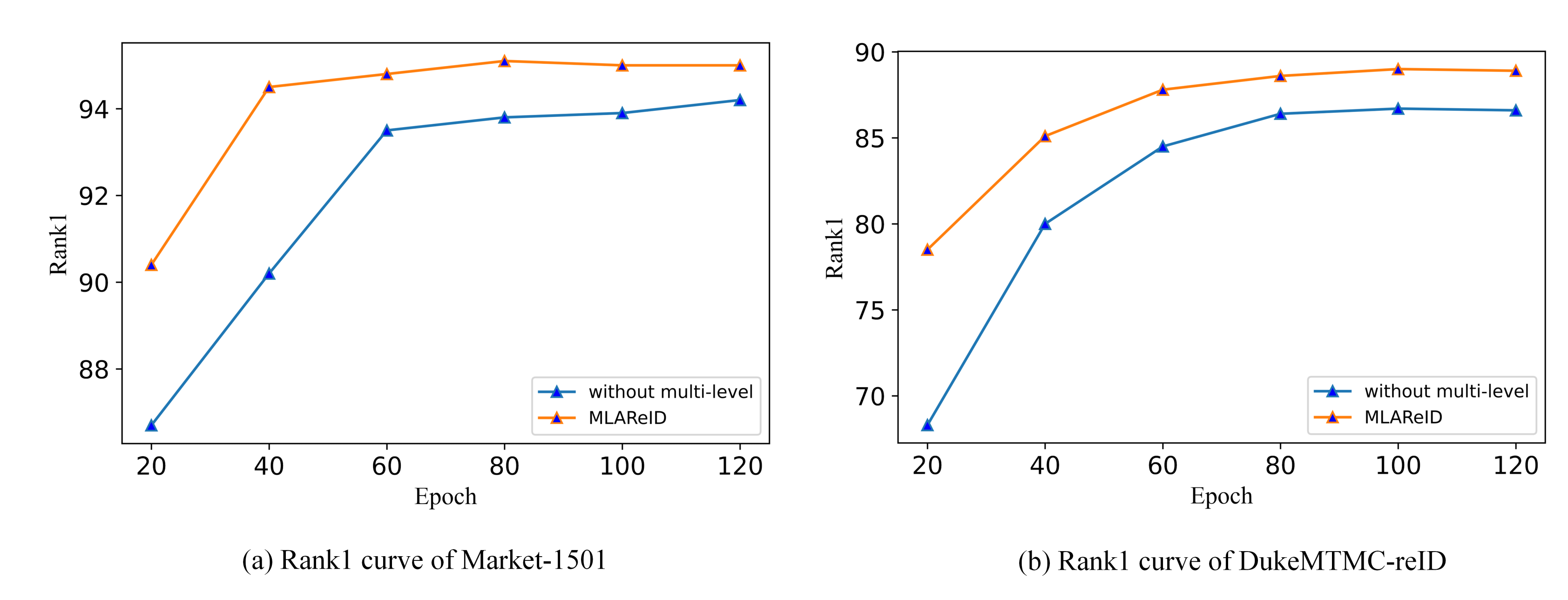
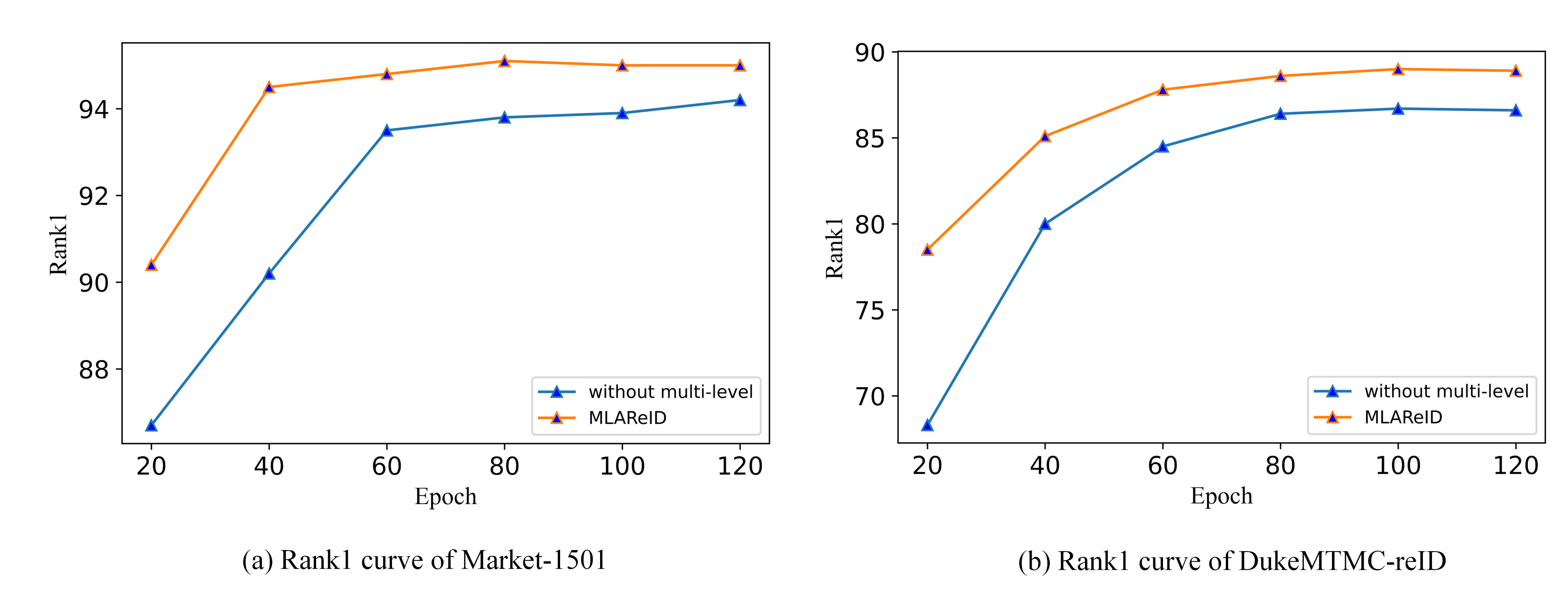
4.5. Ablation Study
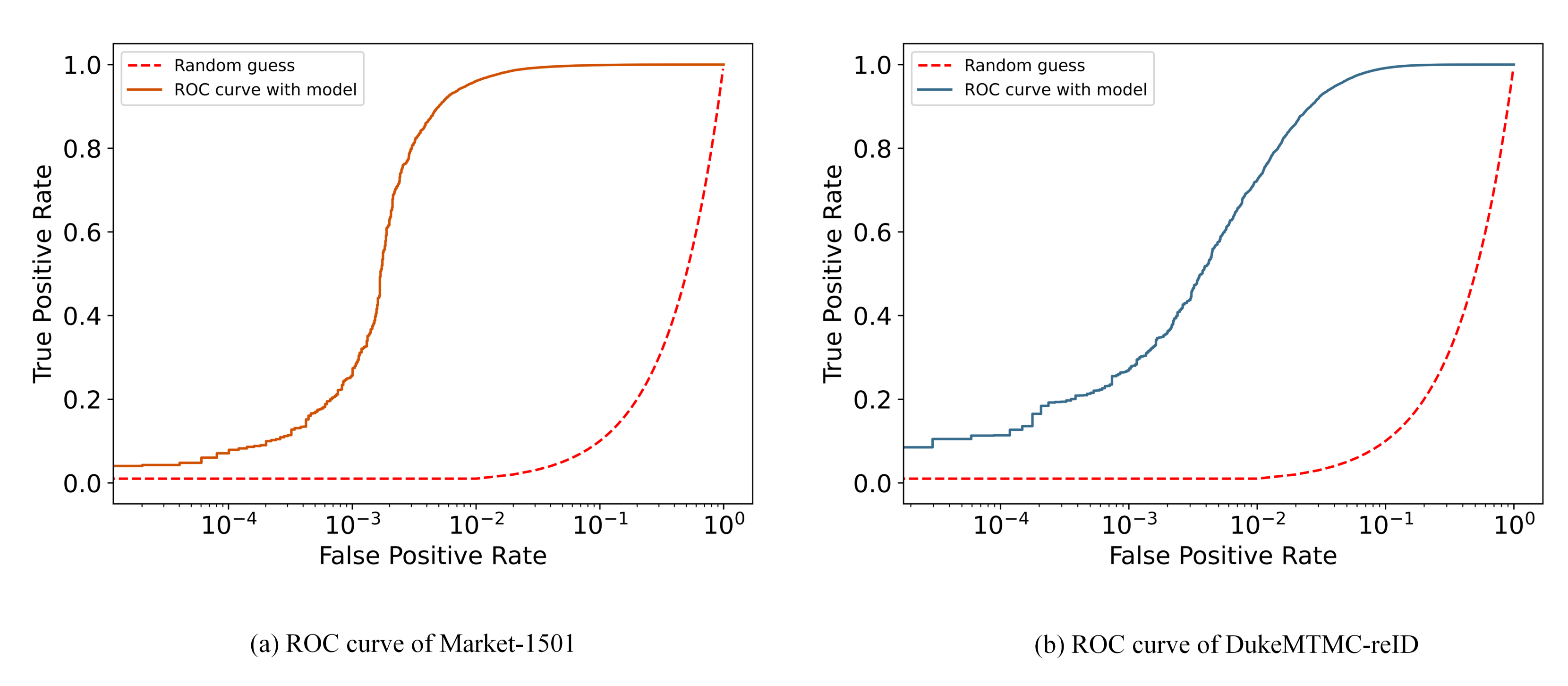
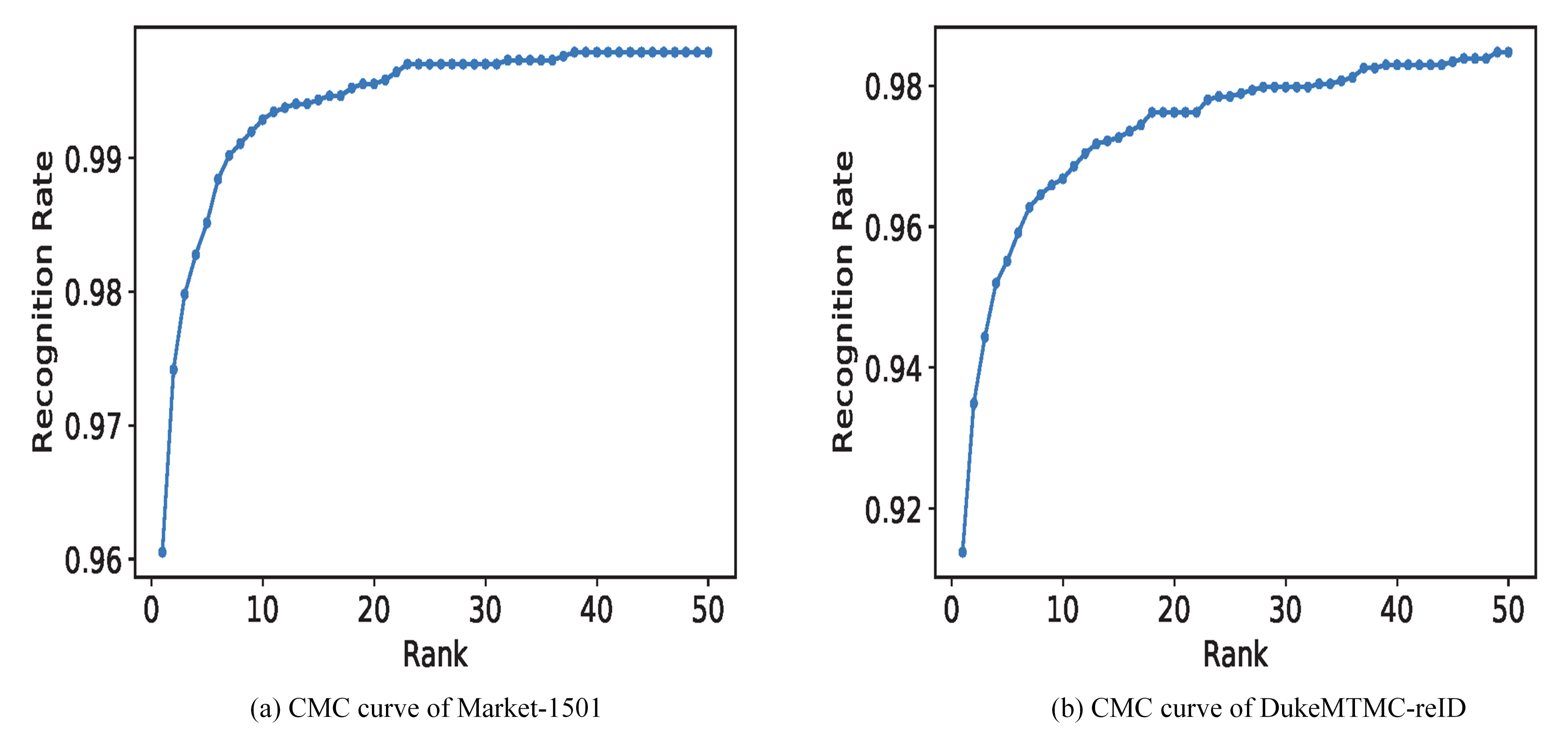
4.6. Visualization
4.7. Time-Complexity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bhattacharya, J.; Sharma, R.K. Ranking-based triplet loss function with intra-class mean and variance for fine-grained classification tasks. Soft Comput. 2020, 24, 15519–15528. [Google Scholar] [CrossRef]
- Zhang, L.; Li, K.; Zhang, Y.; Qi, Y.; Yang, L. Adaptive image segmentation based on color clustering for person re-identification. Soft Comput. 2017, 21, 5729–5739. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C.H. Deep Learning for Person Re-identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Yaghoubi, E.; Kumar, A.; Proena, H. Sss-pr: A short survey of surveys in person re-identification. Pattern Recognit. Lett. 2021, 143, 50–57. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.; Yu, H.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5390–5399. [Google Scholar]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. arXiv 2019, arXiv:1703.07220. [Google Scholar] [CrossRef] [Green Version]
- Yin, J.; Fan, Z.; Chen, S.; Wang, Y. In-depth exploration of attribute information for person re-identification. Appl. Intell. 2020, 50, 3607–3622. [Google Scholar] [CrossRef]
- Yaghoubi, E.; Khezeli, F.; Borza, D.; Kumar, S.V.A.; Neves, J.; Proena, H. Human Attribute Recognition—A Comprehensive Survey. Appl. Sci. 2020, 10, 5608. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, S.; Yang, R.; Zheng, A.; Chen, Z.; Tang, J.; Luo, B. Pedestrian attribute recognition: A survey. Pattern Recognit. 2022, 121, 108220. [Google Scholar] [CrossRef]
- Han, K.; Huang, Y.; Song, C.; Wang, L.; Tan, T. Adaptive super-resolution for person re-identification with low-resolution images. Pattern Recognit. 2021, 114, 107682. [Google Scholar] [CrossRef]
- Bai, S.; Li, Y.; Zhou, Y.; Li, Q.; Torr, P.H.S. Adversarial metric attack and defense for person re-identification. IEEE Trans. Pattern Anal. Mach. 2021, 43, 2119–2126. [Google Scholar] [CrossRef]
- Zou, G.; Fu, G.; Peng, X.; Liu, Y.; Gao, M.; Liu, Z. Person re-identification based on metric learning: A survey. Multimed. Tools Appl. 2021, 80, 26855–26888. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Sudowe, P.; Spitzer, H.; Leibe, B. Person attribute recognition with a jointly-trained holistic CNN model. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Washington, DC, USA, 7–13 December 2015; pp. 329–337. [Google Scholar]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR); IEEE: Piscataway, NJ, USA, 2015; pp. 111–115. [Google Scholar]
- Abdulnabi, A.H.; Wang, G.; Lu, J.; Jia, K. Multi-task CNN model for attribute prediction. IEEE Trans. Multimed. 2015, 17, 1949–1959. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Liao, S.; Yi, D.; Lei, Z.; Li, S.Z. Multi-label CNN based pedestrian attribute learning for soft biometrics. In Proceedings of the 2015 International Conference on Biometrics (ICB), Phuket, Thailand, 19–22 May 2015; pp. 535–540. [Google Scholar]
- Zhao, Y.; Shen, X.; Jin, Z.; Lu, H.; Hua, X. Attribute-Driven Feature Disentangling and Temporal Aggregation for Video Person Re-Identification. In Proceedings of the Attribute-Driven Feature Disentangling and Temporal Aggregation for Video Person Re-Identification, Long Beach, CA, USA, 16–20 June 2019; pp. 4913–4922. [Google Scholar]
- Song, W.; Zheng, J.; Wu, Y.; Chen, C.; Liu, F. Partial attribute-driven video person re-identification. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 539–546. [Google Scholar]
- Radenovi, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Pan, X.; Luo, P.; Shi, J.; Tang, X. Two at once: Enhancing learning and generalization capacities via IBN-net. arXiv 2020, arXiv:1807.09441. [Google Scholar]
- Jin, H.; Lai, S.; Qian, X. Occlusion-sensitive Person Re-identification via Attribute-based Shift Attention. IEEE Trans. Circ. Syst. Video Technol. 2021, in press. [Google Scholar] [CrossRef]
- Xu, S.; Luo, L.; Hu, S. Attention-based model with attribute classification for cross-domain person re-identification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9149–9155. [Google Scholar]
- Taherkhani, F.; Dabouei, A.; Soleymani, S.; Dawson, J.; Nasrabadi, N.M. Attribute Guided Sparse Tensor-Based Model for Person Re-Identification. arXiv 2021, arXiv:2108.04352. [Google Scholar]
- Chen, X.; Liu, X.; Liu, W.; Zhang, X.; Zhang, Y.; Mei, T. Attrimeter: An attribute-guided metric interpreter for person re-identification. arXiv 2021, arXiv:2103.01451. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Computer Vision—ECCV 2016 Workshops; Springer: Berlin, Germany, 2016; Volume 9914, pp. 17–35. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3774–3782. [Google Scholar]
- Ustinova, E.; Ganin, Y.; Lempitsky, V. Multi-region bilinear convolutional neural networks for person re-identification. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Jose, C.; Fleuret, F. Scalable metric learning via weighted approximate rank component analysis. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin, Germany, 2016; pp. 875–890. [Google Scholar]
- Chen, D.; Yuan, Z.; Chen, B.; Zheng, N. Similarity learning with spatial constraints for person re-identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1268–1277. [Google Scholar]
- Matsukawa, T.; Suzuki, E. Person re-identification using CNN features learned from combination of attributes. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2428–2433. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In European Conference on Computer Vision 2016; Springer: Amsterdam, The Netherlands; pp. 791–808.
- Zheng, Z.; Zheng, L.; Yang, Y. A discriminatively learned CNN embedding for person reidentification. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 14, 13:1–13:20. [Google Scholar] [CrossRef]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, 22–25 July 2017; pp. 7398–7407. [Google Scholar]
- Zhao, L. Deeply-Learned Part-Aligned Representations for Person Re-Identification. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3239–3248. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. SVDNet for Pedestrian Retrieval. In Proceedings of the International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Tian, M.; Yi, S.; Li, H.; Li, S.; Zhang, X.; Shi, J.; Yan, J.; Wang, X. Eliminating background-bias for robust person re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5794–5803. [Google Scholar]
- He, L.; Liang, J.; Li, H.; Sun, Z. Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7073–7082. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2119–2128. [Google Scholar]
- Qian, X.; Fu, Y.; Xiang, T.; Wang, W.; Qiu, J.; Wu, Y.; Jiang, Y.; Xue, X. Pose-Normalized Image Generation for Person Re-Identification. In Computer Vision–ECCV 2018; Springer: Berlin, Germany, 2018; pp. 650–667. [Google Scholar]
- Lan, X.; Zhu, X.; Gong, S. Person search by multi-scale matching. In Computer Vision–ECCV 2018; Springer: Berlin, Germany, 2018; pp. 553–569. [Google Scholar]
- Yu, R.; Dou, Z.; Bai, S.; Zhang, Z.; Xu, Y.; Bai, X. Hard-aware point-to-set deep metric for person re-identification. arXiv 2018, arXiv:1807.11206. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-aligned bilinear representations for person re-identification. In Computer Vision–ECCV 2018; Springer: Berlin, Germany, 2018; pp. 418–437. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Computer Vision–ECCV 2018; Springer: Berlin, Germany, 2018; pp. 501–518. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Eberle, A.; Stiefelhagen, R. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 13–18 June 2018; pp. 420–429. [Google Scholar]
- Yu, T.; Li, D.; Yang, Y.; Hospedales, T.M.; Xiang, T. Robust Person Re-Identification by Modelling Feature Uncertainty. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 552–561. [Google Scholar]
- Liu, Z.; Wang, J.; Gong, S.; Tao, D.; Lu, H. Deep reinforcement active learning for human-in-the-loop person re-identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6121–6130. [Google Scholar]
- Jiang, B.; Wang, X.; Tang, J. AttKGCN: Attribute knowledge graph convolutional network for person re-identification. arXiv 2019, arXiv:1911.10544. [Google Scholar]
- Chen, X.; Fu, C.; Zhao, Y.; Zheng, F.; Song, J.; Ji, R.; Yang, A.Y. Salience-guided cascaded suppression network for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 3300–3310. [Google Scholar]
- Zhao, C.; Tu, Y.; Lai, Z.; Shen, F.; Shen, H.T.; Miao, D. Salience-guided iterative asymmetric mutual hashing for fast person re-identification. IEEE Trans. Image Process. 2021, 30, 7776–7789. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Learning generalisable omni-scale representations for person re-identification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Liu, L.; Zhu, L.; Zhang, H. Person re-identification based on multi-scale feature learning. Knowl.-Based Syst. 2021, 228, 107281. [Google Scholar] [CrossRef]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Transferable joint attribute-identity deep learning for unsupervised person re-identification. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2275–2284. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 994–1003. [Google Scholar]
- Zhong, Z.; Zheng, L.; Li, S.; Yang, Y. Generalizing a Person Retrieval Model Hetero- and Homogeneously. In European Conference on Computer Vision 2018; Springer: Munich, Germany, 2018; pp. 172–188. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A Strong Baseline and Batch Normalization Neck for Deep Person Re-Identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Rank1 | Rank5 | Rank10 | mAP |
|---|---|---|---|---|
| MBC [31] | 45.56 | 67 | 76 | 26.11 |
| SML [32] | 45.16 | 68.12 | 76 | - |
| SL [33] | 51.9 | - | - | 26.35 |
| Attri [34] | 58.84 | - | - | 33.04 |
| S-CNN [35] | 65.88 | - | - | 39.55 |
| 2Stream [36] | 79.51 | 90.91 | 94.09 | 59.84 |
| Cont-aware [37] | 80.31 | - | - | 57.53 |
| Part-align [38] | 81.0 | 92.0 | 94.7 | 63.4 |
| SVDNet [39] | 82.3 | 92.3 | 95.2 | 62.1 |
| GAN [30] | 83.97 | - | - | 66.07 |
| EBB [40] | 81.2 | 94.6 | 97.0 | - |
| DSR [41] | 82.72 | - | - | 61.25 |
| AACN [42] | 85.90 | - | - | 66.87 |
| APR [6] | 87.04 | 95.10 | 96.42 | 66.89 |
| PN-GAN [43] | 89.4 | - | - | 72.6 |
| CLSA [44] | 88.9 | - | - | 73.1 |
| HAP2S [45] | 84.59 | - | - | 69.43 |
| PABR [46] | 90.2 | 96.1 | 97.4 | 76 |
| PCB [47] | 92.3 | 97.2 | 98.2 | 77.4 |
| PSE [48] | 87.7 | 94.5 | 96.8 | 69 |
| DistributionNet [49] | 87.26 | 94.74 | 96.73 | 70.82 |
| DRAL [50] | 84.2 | 94.27 | 96.59 | 66.26 |
| AttKGCN [51] | 94.4 | 98 | 98.7 | 85.5 |
| Yin [7] | 92.8 | 97.5 | 98.3 | 79.5 |
| SCSN (4 stages) [52] | 92.4 | - | - | 88.3 |
| SIAMH [53] | 95.4 | - | - | 88.8 |
| Jin [24] | 94.6 | - | - | 87.5 |
| Zhou [54] | 94.8 | - | - | 86.7 |
| Li [55] | 95.5 | - | - | 88.5 |
| MLAReID | 96.1 | 98.5 | 99.3 | 90.3 |
| MLAReID + Reranking | 96.5 | 98.2 | 98.8 | 95.4 |
| Method | Rank1 | Rank5 | Rank10 | mAP |
|---|---|---|---|---|
| BoW + kissme [28] | 25.13 | - | - | 12.17 |
| LOMO + XQDA [56] | 30.75 | - | - | 17.04 |
| AttrCombine [34] | 53.87 | - | - | 33.35 |
| GAN [30] | 67.68 | - | - | 47.13 |
| SVDNet [39] | 76.7 | - | - | 56.8 |
| APR [6] | 73.92 | - | - | 55.56 |
| PSE [48] | 79.8 | 89.7 | 92.2 | 62 |
| DistributionNet [49] | 74.73 | 85.05 | 88.82 | 55.98 |
| AttKGCN [51] | 87.8 | 94.4 | 95.7 | 77.4 |
| Yin [7] | 82.7 | 91 | 93.5 | 66.4 |
| SCSN (4 stages) [52] | 91.0 | - | - | 79.0 |
| SIAMH [53] | 90.1 | - | - | 79.4 |
| Jin [24] | 88.6 | - | - | 78.4 |
| Zhou [54] | 88.7 | - | - | 76.6 |
| Li [55] | 90.2 | - | - | 79.7 |
| MLAReID | 91.4 | 95.5 | 96.7 | 81.4 |
| MLAReID + Rerankingg | 92.7 | 96.1 | 97.2 | 90.6 |
| Method | M→D | D→M | ||
|---|---|---|---|---|
| Rank1 | mAP | Rank1 | mAP | |
| TJ-AIDL(CVPR’18) [57] | 44.3 | 23.0 | 58.2 | 26.5 |
| SPGAN(CVPR’18) [58] | 41.1 | 22.3 | 51.5 | 22.8 |
| ATNet(CVPR’19) [59] | 45.1 | 24.9 | 55.7 | 35.6 |
| StrongReID [60] | 41.4 | 25.7 | 54.3 | 25.5 |
| SPGAN+LMP [58] | 46.4 | 26.2 | 57.7 | 26.7 |
| MLAReID | 50.5 | 32.9 | 61.7 | 33.4 |
| MLAReID + Reranking | 55.4 | 46.7 | 65.6 | 48.2 |
| Component | Market-1501 | DukeMTMC-reID | ||||||
|---|---|---|---|---|---|---|---|---|
| Non-Local | IBN | Attribute | Rank1 | mAP | mINP | Rank1 | mAP | mINP |
| 94.1 | 85.0 | 57.1 | 85.9 | 74.8 | 36.4 | |||
| √ | 94.2 | 86.0 | 59.2 | 86.3 | 75.4 | 38.4 | ||
| √ | √ | 95.3 | 87.6 | 63.6 | 87.7 | 77.9 | 41.1 | |
| √ | √ | 96.0 | 89.5 | 69.2 | 90.5 | 80.2 | 45.2 | |
| √ | √ | √ | 96.1 | 90.3 | 71.0 | 91.4 | 81.4 | 47.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pei, S.; Fan, X. Multi-Level Fusion Model for Person Re-Identification by Attribute Awareness. Algorithms 2022, 15, 120. https://doi.org/10.3390/a15040120
Pei S, Fan X. Multi-Level Fusion Model for Person Re-Identification by Attribute Awareness. Algorithms. 2022; 15(4):120. https://doi.org/10.3390/a15040120
Chicago/Turabian StylePei, Shengyu, and Xiaoping Fan. 2022. "Multi-Level Fusion Model for Person Re-Identification by Attribute Awareness" Algorithms 15, no. 4: 120. https://doi.org/10.3390/a15040120
APA StylePei, S., & Fan, X. (2022). Multi-Level Fusion Model for Person Re-Identification by Attribute Awareness. Algorithms, 15(4), 120. https://doi.org/10.3390/a15040120