





Signals 2026, 7(3), 57; https://doi.org/10.3390/signals7030057 - 10 Jun 2026
Abstract
►
Show Figures
Unauthorised FM broadcasting poses significant challenges to spectrum regulators globally, contributing to interference, degraded service quality, and national security threats. While traditional spectrum monitoring relies primarily on carrier frequency and power measurements, this study demonstrates that FM baseband features—specifically the multiplex (MPX) signal
[...] Read more.
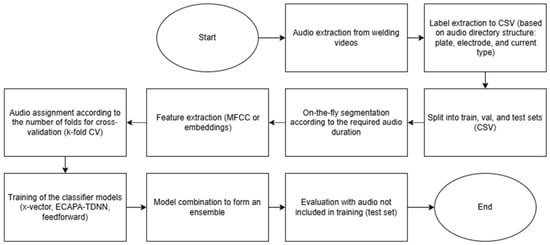
Unauthorised FM broadcasting poses significant challenges to spectrum regulators globally, contributing to interference, degraded service quality, and national security threats. While traditional spectrum monitoring relies primarily on carrier frequency and power measurements, this study demonstrates that FM baseband features—specifically the multiplex (MPX) signal structure, pilot tone, and Radio Data System (RDS) subcarrier—provide robust discriminative markers for detecting non-compliant transmissions. Using a real-world dataset of 3710 pre-processed records collected across Nigeria’s capital region between 2021 and 2024, we extracted and analysed six transmission parameters: assigned frequency, band occupancy (±100 kHz), MPX overshoot percentage, pilot tone presence, and RDS indicators. A Support Vector Machine (SVM) classifier with radial basis function (RBF) kernel was trained to distinguish compliant licensed stations from regulatory non-compliant transmissions—encompassing both unlicensed transmitters and technically non-compliant licensed operators—achieving 99.96% accuracy, 99.38% precision, and 99.63% recall with a false alarm rate of 0.026%. A Comparative analysis against baseline feature sets confirmed that integrating MPX, pilot, and RDS significantly improved detection robustness compared with carrier-only approaches. Results demonstrate that feature-rich baseband analysis enables scalable, cost-effective regulatory enforcement, reducing manual monitoring burden while enhancing detection reliability. This framework offers practical applicability for spectrum management agencies in resource-constrained environments where unauthorised broadcasting remains prevalent.
Full article

Figure 1




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}