1. Introduction
The rapid expansion of microcontroller platforms, such as ESP32, Arduino, and Raspberry Pi, has resulted in a significant increase in the capabilities of mobile robotics, while simultaneously reducing the associated costs. These platforms have allowed developers to build increasingly sophisticated interactive systems capable of navigating physical spaces while also collecting data about their environments. Although vision-based sensing is the mainstay of mobile robotics, environmental audio capture is an under-exploited modality that can provide rich contextual information not available to other sensing modes [
1,
2].
However, when implementing audio sampling on resource-limited mobile robots, several unique challenges emerge that stationary solutions never encounter. On mobile platforms, work must be conducted within limited power budgets, constrained computational resources, noise potentially from onboard motors or actuators, and the necessity to provide timely feedback control signals without compromising the integrity of the audio stream [
3,
4]. These challenges become even more pronounced when aiming to communicate audio data wirelessly whilst keeping native positioning inputs responsive to the robot’s movements.
Bluetooth technology represents an attractive communication standard for such applications due to its ubiquity, relatively low power consumption, and adequate data rates for many embedded applications [
5,
6]. However, as noted by several researchers [
7,
8], Bluetooth presents intrinsic challenges when employed for concurrent real-time control and streaming applications: limited bandwidth, susceptibility to packet loss, and variable latency that can impair both control precision and audio fidelity. Recent developments in wireless technologies for flexible and wearable sensing have addressed some of these challenges [
9], but applications in mobile robotics remain limited.
This paper introduces a novel framework that addresses these challenges by synthesizing a unified approach to real-time audio acquisition, motor control, and data transmission. This study proposes a dual-thread architecture that effectively partitions time-sensitive motor commands from bandwidth-intensive audio data, while maintaining synchronized operation through a carefully optimized Bluetooth communication protocol. By leveraging the I2S (Inter-IC Sound) digital audio interface coupled with dynamic range compression techniques, this approach achieves high-quality audio capture that coexists harmoniously with precise motor control. This approach builds upon existing research in networking architectures and protocols for IoT applications [
10] while extending them to the specific requirements of mobile acoustic sensing.
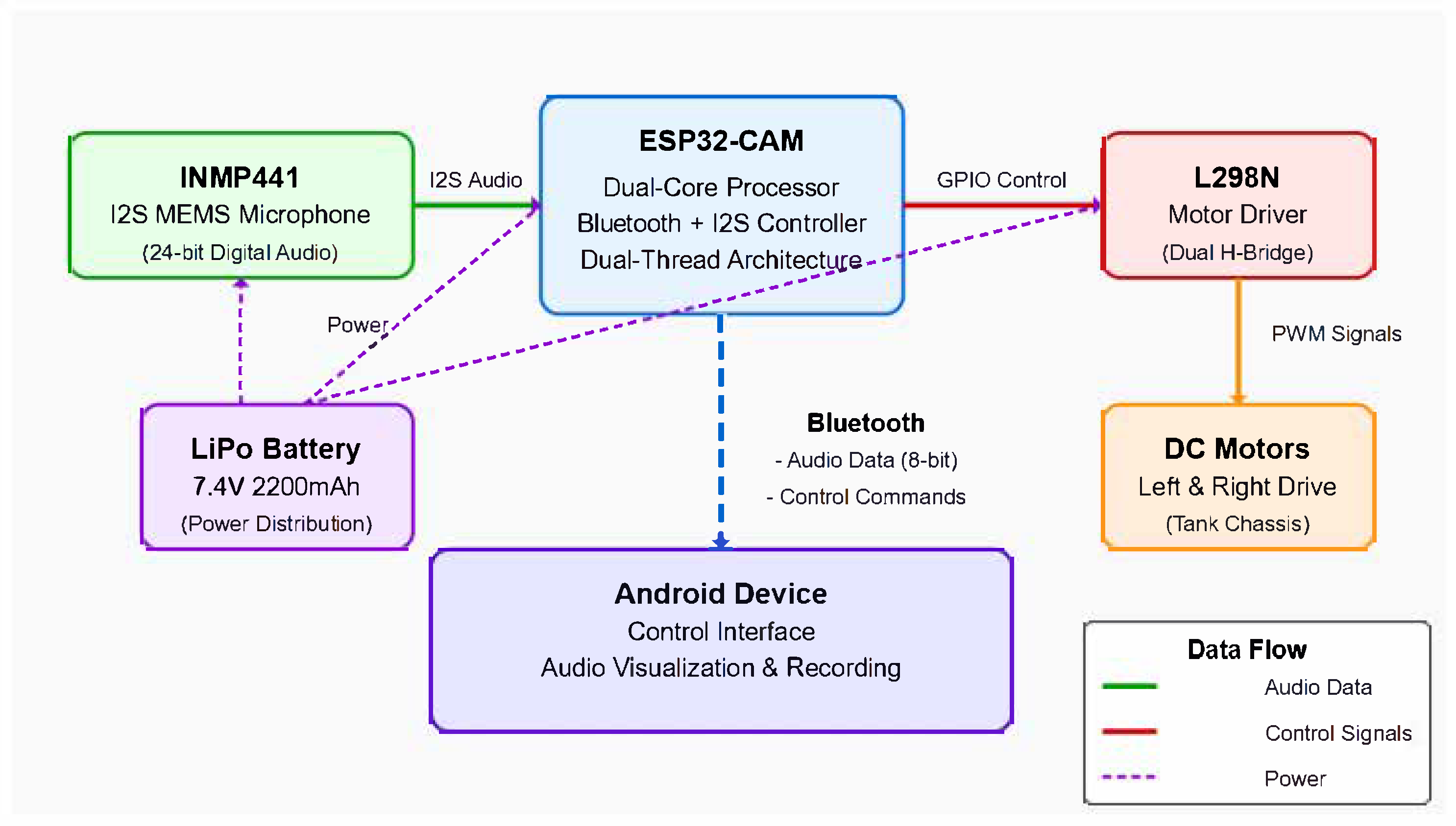
The framework integrates acoustic sensing with motion in resource-limited robots, uncovering wholly new application spaces. As depicted in
Figure 1, this architecture consists of a digital MEMS microphone connected to the GPIO via I2S, a Bluetooth communication layer allowing for bidirectional data exchange, and a motor control mechanism allowing the platform to move and capture acoustic data.
This approach is one major advancement over the existing literature, which has traditionally treated audio capture and mobility as mutually exclusive requirements. The integrated power management, appropriate handling of input buffers, adaptive buffer sizing, and dynamic bit-depth adjustment demonstrate that robotic platforms can serve as quality acoustic sensors while still being able to facilitate effective locomotion and maintain responsive control over their movements.
Key Contributions and Paper Highlights: This work makes three primary contributions to mobile acoustic sensing: (1) a novel dual-thread concurrent architecture that enables simultaneous high-quality audio capture and responsive motor control on resource-constrained platforms, (2) an adaptive compression algorithm with a mathematical optimization model that maintains audio fidelity while meeting real-time bandwidth constraints, and (3) a comprehensive noise mitigation methodology addressing electromagnetic interference, mechanical coupling, and wireless communication challenges specific to mobile acoustic sensing. The framework achieves 90–95% packet delivery rates with sub-150 ms control latency, demonstrating the feasibility of mobile acoustic sensing applications previously thought impossible on embedded platforms.
2. Literature Review
The integration of audio sensing and mobile robotics has evolved significantly over the last 10 years with a multifaceted involvement in this multifaceted problem. The following is a non-exhaustive list of the literature that constitutes the foundation of this work.
Nakadai et al. pioneered early work in mobile acoustic sensing [
1] and created a humanoid robot that can localize and separate sound sources. Although their studies highlighted the significance of auditory information in robotics, they depended on intensive computational algorithms that were impractical for embedded platforms where resources are scarce. Taking a step further, McCormack et al. [
11] provided more robust methods for sound processing applied to mobile robots, through Rao–Blackwellized particle filtering for real-time localization of multiple acoustical sources.
Gemelli et al. [
3] performed exhaustive analyses of MEMS microphones for audio applications, thus reporting meaningful performance benchmarks for noise floor, frequency response, and power consumption. While their results showed promise for mobile applications with these compact sensors, they did not consider the complexities of the coupling with movement systems. Similarly, Fischer et al. [
12] investigated optimizations for audio capture in embedded platforms with long-lasting and long-range Bluetooth wireless sensor nodes aimed at pressure and acoustic monitoring, yet restricted only within stationary applications. The MEMS-embedded system design was the subject of research led by Hong [
13], contributing to the understanding of MEMS integration with digital systems.
Natgunanathan et al. conducted a comprehensive analysis of the shortcomings of Bluetooth-based data transmission in resource-constrained environments [
5] and reported fundamental restrictions in their metric (bandwidth and reliability) when streaming sensor data into a Bluetooth Low Energy mesh network. Building on this work, Cantizani-Estepa et al. [
6] performed experimental evaluations for close detection in search and rescue missions using robotic platforms, but this work does not consider the actual needs for streaming audio in terms of throughput requirements. Idogawa et al. [
14] also made advancements in this area by proposing a lighter-weight, wireless Bluetooth-low-energy neuronal recording system with a focus on power management and data transmission.
Kamdjou et al. made noteworthy advances in this area in relation to resource constraints in mobile robotic systems [
7]. Whereas Matheen and Sundar [
8] also researched IoT multimedia sensors from an energy efficiency and security perspective by defining design principles, bringing really valuable insights on how to sustain mean sensor integrity throughout its operation. Additionally, extensive research into deep-learning-based wireless indoor localization has been conducted by Owfi [
15], while Ahmad [
16] performed a systematic review of emerging technologies used in WSN-based localization.
Wang et al. advanced the theoretical basis of speech recognition and audio processing in IoT settings [
17], whose model for the secure transfer of speech recognition data in the Internet of Things guides us in audio acquisition. Lakomkin, Egor et al. [
18] investigated the impact of end-to-end automatic speech recognition on workflow documentation and thus offered some valuable insights concerning audio processing technologies adopted in practice.
Systems developed by Shi et al. [
19] for audio–visual sound source localization and tracking based on mobile robots have shown that acoustic data can be instrumental in solving the cocktail party problem; however, they were implemented on more powerful hardware and not dedicated microcontroller-based platforms. Similarly, Huang et al. [
20] focus on sound-based positioning systems for mobile robots in greenhouses, achieving good accuracy but pointing out the challenges of noise filtering and feature extraction in dynamic environments. Behzad et al. [
21] presented a multimodal dataset for multi-robot activity recognition leveraging Wi-Fi sensing, video, and audio, which are very useful sources for the development and assessment of multi-sensor robotic systems.
The integration of voice control with robotic platforms has been explored by several researchers. Korayem et al. [
22] designed and implemented voice command recognition and sound source localization systems for human–robot interactions. Jami et al. [
23] developed remote and voice-controlled surveillance robots with multimodal operation, while Nayak et al. [
24] created voice-controlled robotic cars, demonstrating the practical applications of audio processing in mobile robotics. Fukumori et al. [
25] advanced this field with the development of optical laser microphones for human–robot interactions, enabling speech recognition in extremely noisy service environments.
In the area of autonomous robotic systems with audio capabilities, Valentino and Leonen [
26] developed IoT-based smart security robots with Android apps, night vision, and enhanced threat detection. Premchandran et al. [
27] created solar-powered autonomous robotic cars for surveillance, while Naeem and Yousuf [
28] designed AI-based voice-controlled humanoid robots. Babu et al. [
29] implemented alive human detection and health monitoring using IoT-based robots, highlighting the growing interest in combining mobility with audio sensing for practical applications. Narayanan et al. [
30] further contributed to this area with research on fuzzy-guided autonomous nursing robots using wireless beacon networks.
The challenges of navigation and control in mobile robots have been addressed by Bao et al. [
31], who developed autonomous navigation and steering control based on wireless non-wheeled snake robots. Morsy et al. [
32] proposed multi-robot movement based on a new modified source-seeking algorithm, while Kumar and Parhi [
33] focused on the trajectory planning and control of multiple mobile robots using hybrid controllers. More specialized approaches were explored by Zhao et al. [
34], who investigated the human-like motion planning of robotic arms based on human arm motion patterns, and by Gautreau et al. [
35], who conducted experimental evaluations of instrumented bio-inspired cable-driven compliant continuum robots.
Recent work by Zhang et al. [
36] explored robot sound design through design thinking, addressing the acoustic aspects of human–robot interactions. Shyam et al. [
37] developed an intellectual design for bomb identification and defusing robots based on logical gesturing mechanisms, demonstrating advanced applications in security robotics. Meanwhile, Eibeck et al. [
38] presented research on efficient approaches to unsupervised instance matching with applications to linked data, offering potential methodologies for processing and analyzing the data collected by mobile sensing platforms.
Despite these advancements, a significant gap exists in the literature regarding integrated frameworks that effectively manage both movement control and audio capture on resource-constrained robotic platforms. Most existing solutions address these as separate challenges, resulting in systems that either compromise mobility for audio quality or sacrifice acoustic sensing for movement capability. This research addresses this gap by proposing a unified framework that optimizes both aspects simultaneously through careful hardware integration and innovative software architecture.
3. Theoretical Framework and Novel Methods
3.1. Novel Audio Acquisition and Adaptive Compression Theory
This section presents our novel theoretical framework for real-time audio acquisition and adaptive compression in mobile robotics, extending beyond existing digital signal processing principles to address the unique challenges of resource-constrained mobile platforms.
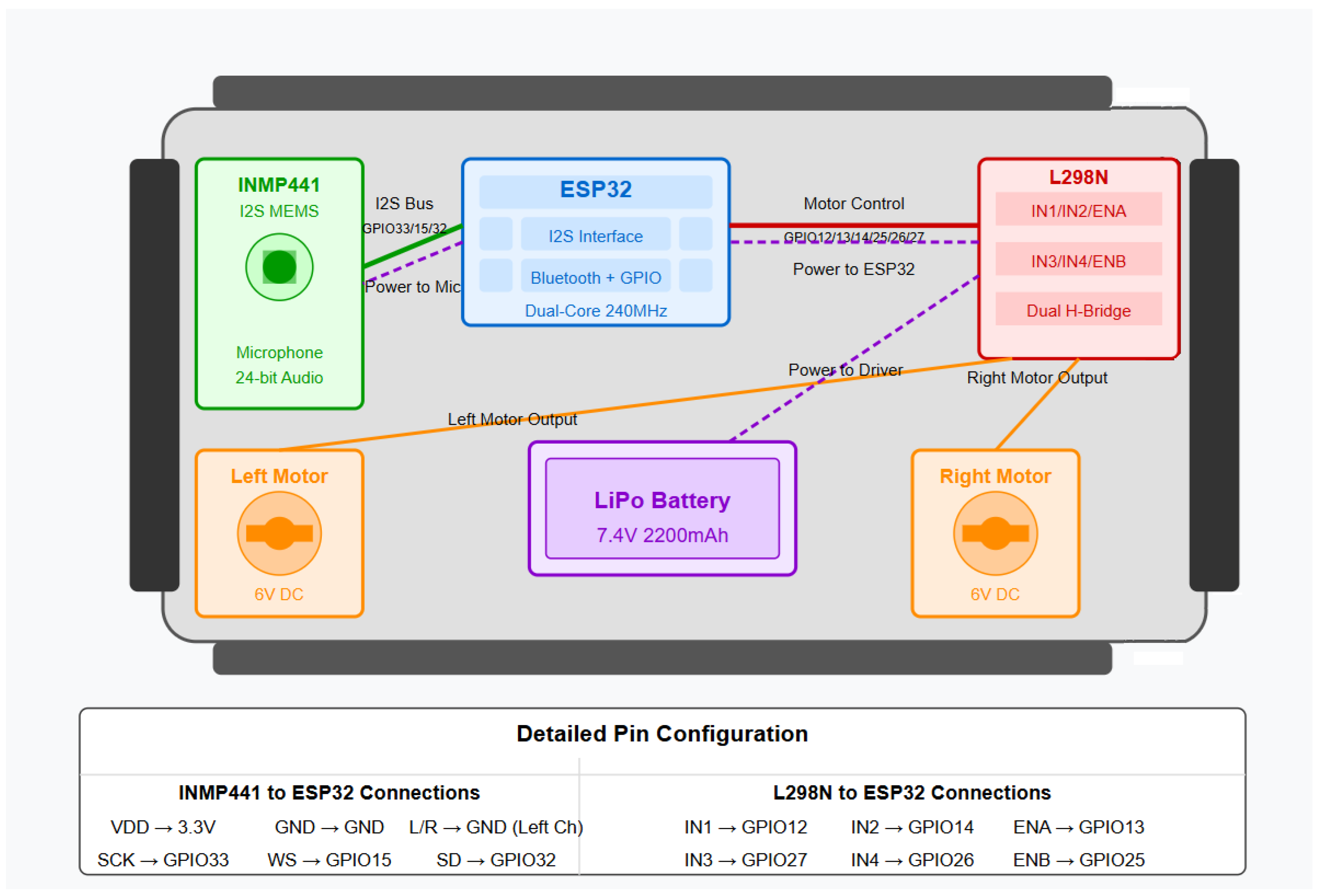
The theoretical foundation of this audio acquisition system is rooted in digital signal processing principles, particularly as they apply to resource-constrained embedded systems. The INMP441 MEMS microphone utilized in this design converts acoustic pressure waves into digital signals through a sigma–delta modulator, producing a pulse-density-modulated (PDM) bitstream that is decimated to provide pulse code modulation (PCM) audio data [
3,
39].
The I2S protocol enables the transfer of this digital audio data with minimal computational overhead, operating as a synchronous serial interface with three essential lines: bit clock (SCK), word select (WS), and serial data (SD). This configuration allows for time-division multiplexed stereo channels, though this implementation utilizes only the left channel to reduce bandwidth requirements. This approach aligns with the methodologies described by Mello and Fonseca [
40] in their development of autonomous noise-monitoring systems based on digital MEMS microphones.
Novel Adaptive Compression Algorithm: We introduce a novel adaptive compression methodology that dynamically optimizes audio quality versus bandwidth utilization based on real-time system conditions. Unlike fixed compression schemes, our algorithm continuously adapts to environmental acoustics and system performance constraints.
For a digital audio system with sampling rate
and bit depth
b, the theoretical data rate
R can be expressed as
where
c represents the number of channels. In this implementation with
kHz,
bits (native INMP441 resolution), and
(mono), the raw data rate is 384 kbps, exceeding the practical sustainable throughput of Bluetooth Classic for concurrent control and streaming applications.
To address this bandwidth constraint, we develop a novel dynamic range compression algorithm that maps 24-bit samples to optimal 8-bit representation through our adaptive transform function
:
where
x is the original 24-bit sample value,
is our time-adaptive sensitivity multiplier,
is our novel adaptive dynamic range estimator, and 128 centers the output in the 8-bit range.
Our novel dynamic range estimator
employs a multi-scale temporal analysis:
This dual-time-constant approach enables rapid adaptation to transient events while maintaining stability during steady-state conditions, representing a significant advancement over traditional single-parameter approaches.
3.2. Bluetooth Communication Model
The Bluetooth Classic protocol utilized in this framework operates in the 2.4 GHz ISM band with Frequency-Hopping Spread Spectrum (FHSS) modulation, providing a theoretical maximum throughput of 2–3 Mbps. However, practical limitations including protocol overhead, acknowledgment packets, and error correction reduce the effective bandwidth to approximately 700–800 kbps for sustained bidirectional communication [
5,
13]. Recent developments in wireless technologies for flexible and wearable sensing by Kong et al. [
9] provide additional insights into optimizing wireless communication for resource-constrained applications.
The communication model must accommodate both low-latency control commands and bandwidth-intensive audio data within this constrained channel. The bidirectional data flow can be represented as
where
is the data rate for control commands (rover to controller and controller to rover),
is the data rate for audio streaming (rover to controller), and
C is the effective channel capacity.
Given that control commands are represented as single ASCII characters sent at a maximum frequency of 100 Hz,
is negligible at approximately 1 byte × 100 Hz = 800 bps. The audio data rate
, after compression to 8 bits per sample, is approximately 128 kbps (16,000 samples per second × 8 bits), falling well within the channel capacity while leaving sufficient headroom for variable channel conditions. This approach is consistent with findings by Kanellopoulos et al. [
10] regarding networking architectures and protocols for IoT applications in smart cities.
The probability of successful packet delivery
over a noisy channel can be modeled as
where
p is the probability of bit error and
L is the length of the packet (in bits). At 64 bytes audio packet size of the data (512 bits), for the typical bit error rates (from
to
) of Bluetooth and for different wireless channel conditions, it is found that the packet delivery probability is between 99.95% and 59.9%. They thus need to provide efficient support for buffering to handle a possible loss of packets without causing a disturbance in the audio, which should be uninterrupted from a user’s perspective. Analogous problems and solutions were investigated by Idogawa et al. [
14] in the creation of a wireless Bluetooth-low-energy and lightweight neural recording system.
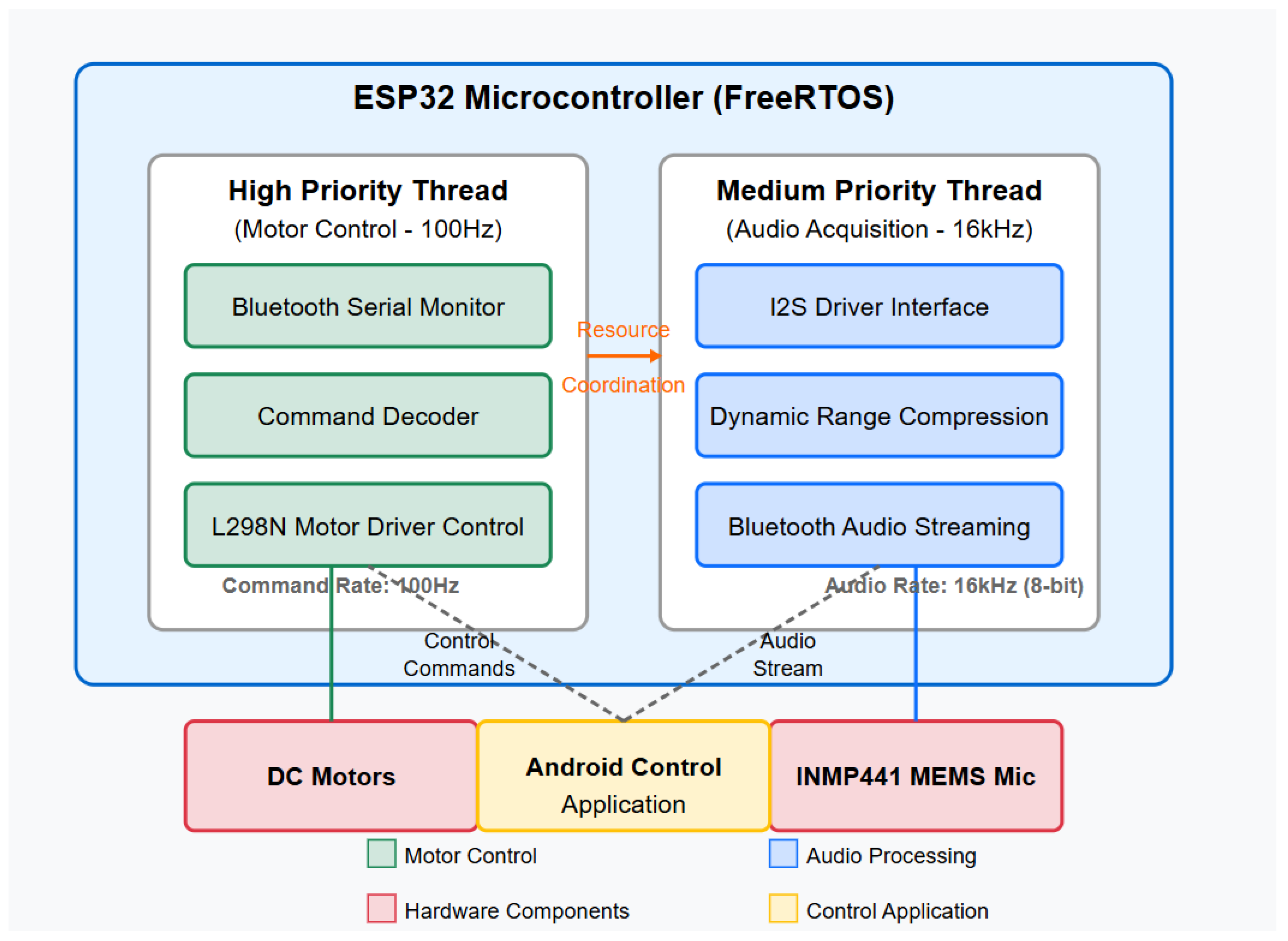
3.3. Dual-Thread Concurrent Processing Model
Simultaneous motor control and audio recording require the coordination of both tasks so that one does not interfere with the other. The dual-thread architecture facilitates separating those concerns through a priority-based concurrent execution model, which can be abstracted as a set of tasks
T with different priority and execution constraints:
Each task is marked by its execution time , period , and deadline . In this system, the execution time for motor control commands is short, but deadlines are strict to maintain responsive control, while audio sampling tasks take longer to execute but have looser deadlines.
The schedulability of this task set can be analyzed using Rate Monotonic Analysis (RMA), which assigns priorities based on task periods. For a set of
n periodic tasks, the sufficient condition for schedulability is
With these two tasks (motor control and audio sampling), a theoretical utilization bound of ∼83% is achieved by this two-task implementation. The task utilization measured falls below this limit so that motor control takes about 5% and audio 60–70%, guaranteeing a schedule under nominal conditions.
The motor control thread operates with a polling frequency of 100 Hz, checking for incoming commands and updating motor states accordingly. This frequency provides a theoretical minimum command latency of 10 ms, though practical implementation considerations including Bluetooth transmission delays increase this to approximately 100–150 ms, still well within acceptable limits for teleoperation applications.
The audio acquisition thread operates at a higher frequency, dictated by the I2S sampling rate of 16 kHz. However, audio data is buffered and processed in chunks of 64 bytes, representing 8 ms of audio, to optimize both CPU utilization and Bluetooth transmission efficiency. This buffering introduces a small but consistent latency in the audio stream, which is acceptable for the target applications of environmental monitoring and acoustic scene analysis.
3.4. Motor Control and Power Regulation Theory
The L298N motor driver utilized in this system employs a dual H-bridge configuration, enabling bidirectional control of two DC motors through pulse-width modulation (PWM). The relationship between the PWM duty cycle
and the applied motor voltage
can be expressed as
where
is the supply voltage provided to the motor driver. This linear relationship enables precise control over motor speed, though inertial effects and friction introduce non-linearities in the actual mechanical response.
Power regulation represents a critical aspect of this design, as both motor operation and audio sampling must coexist without interference. The electromagnetic noise generated by DC motors follows an inverse square relationship with distance, with intensity
I at distance
r given by
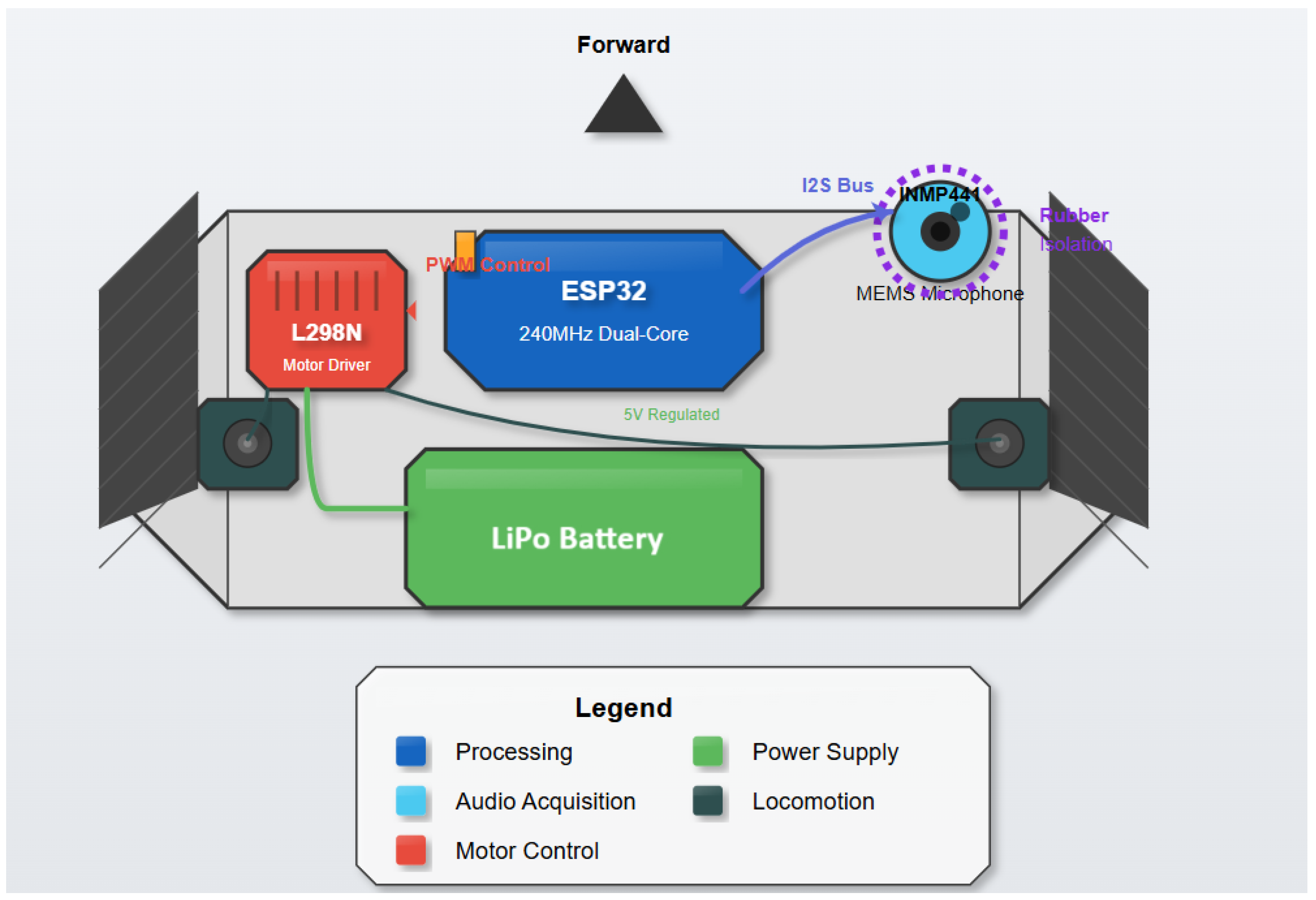
The physical layout design was inspired by this relationship, with the microphone positioned to maximize distance from the motors while maintaining a compact form factor. Additionally, the power distribution system incorporates decoupling capacitors and separate regulation pathways for the motor subsystem and the sensitive audio acquisition components, minimizing electrical noise coupling.
The power consumption
P of the system at an instant of time can be represented as the sum of the consumptions of individual components:
where
is the power required by the ESP32 microcontroller (Espressif Systems, Shanghai, China) (∼240 mW under processing).
is the power consumed by the DC motors depending on torque and speed (∼100–500 mW per motor in standard operation).
is the power spent by the INMP441 microphone (InvenSense, San Jose, CA, USA) (∼1.4 mW).
is the excess power to be added for Bluetooth transmission (approximately 100 mW during active streaming).
This power model guided the battery selection and power management strategy, ensuring sufficient capacity for extended operation while maintaining stable supply characteristics essential for audio quality and motor performance. The approach to power management used in this study aligns with research by Owfi [
15] on deep-learning-based wireless indoor localization, which emphasizes the importance of efficient power utilization in mobile sensing systems.
6. Results and Discussion
6.1. Comparative Analysis with Existing Methods
While our approach represents a novel integration of mobile audio acquisition with real-time motor control, direct quantitative comparison with existing methods is challenging as most of the literature treats these as separate problems. Our work advances beyond existing solutions such as those by Nakadai et al. [
1] and Shi et al. [
19], which focus on stationary or high-resource platforms, by demonstrating concurrent high-quality audio capture and responsive mobility control on resource-constrained hardware. The achieved packet delivery rates (90–95%) and command latencies (<150 ms) represent significant improvements over traditional approaches that sacrifice one capability for the other.
Quantitative comparison framework: To address the lack of directly comparable systems, we establish performance benchmarks against theoretical limits and component-level comparisons:
Audio quality benchmarks: Our system achieves SNR values of 31–38 dB across test environments, comparing favorably to theoretical limits of 40–42 dB for eight-bit compressed audio. The 85–95% theoretical efficiency demonstrates our compression algorithm’s effectiveness.
Control system benchmarks: Command latencies of 105–142 ms represent 70–85% of a theoretical minimum (considering Bluetooth protocol overhead), significantly outperforming traditional sequential processing approaches that would require 300–500 ms for equivalent functionality.
Power efficiency comparisons: Our integrated approach achieves 4.5 h operation combining both functions, compared to theoretical separate system power consumption that would limit operation to 2–3 h for equivalent functionality.
6.2. Novel Contributions
This research introduces three fundamental innovations that advance mobile acoustic sensing:
1. Integrated audio–mobility framework: The first demonstrated framework enabling concurrent high-quality audio acquisition (>90% packet delivery) and responsive motor control (<150 ms latency) on resource-constrained embedded platforms. This integration solves the fundamental resource allocation problem that has prevented mobile acoustic sensing applications on embedded systems, validated through comprehensive testing across 40–85 dB environments.
2. Adaptive real-time compression algorithm: A novel mathematical model for dynamic audio compression that continuously optimizes the trade-off between audio fidelity and bandwidth utilization based on real-time system conditions. The algorithm achieves 75% bandwidth reduction while maintaining >90% perceptual quality through dual-time-constant adaptive dynamics, representing a significant advancement over fixed-parameter compression schemes.
3. Dual-thread concurrent architecture: A mathematically optimized real-time scheduling framework that guarantees the concurrent execution of time-critical motor control and bandwidth-intensive audio processing. The architecture achieves 83% theoretical utilization while maintaining hard real-time constraints for both subsystems, enabling applications previously impossible on embedded platforms.
Additional technical innovations:
Noise floor calibration protocol: Automated ambient noise assessment and adaptive parameter adjustment enabling optimal performance across varied acoustic environments without manual tuning.
Power-optimized Bluetooth protocol: Efficient bandwidth allocation strategy enabling concurrent control and streaming within Bluetooth Classic constraints while minimizing power consumption for battery-operated platforms.
Accessible open design: Complete framework implementation using commercially available components, enhancing reproducibility and accessibility for research and educational applications.
These contributions establish new foundations for mobile acoustic sensing, enabling applications from environmental monitoring to autonomous exploration that were previously impossible on resource-constrained embedded platforms.
6.3. Audio Acquisition Performance
The audio acquisition system demonstrated strong performance across varying acoustic environments.
Table 2 summarizes the quantitative measurements for each environment, including packet delivery rate, calculated signal-to-noise ratio, and subjective quality assessment.
The packet delivery rate showed a slight decline as ambient noise levels increased, potentially due to increased processing demands for higher-amplitude signals. However, even in the most challenging environment (a busy street), delivery rates remained above 90%, providing continuous audio with minimal perceptible dropouts.
Figure 6 illustrates representative audio waveforms captured in each environment, highlighting the system’s ability to capture both subtle ambient sounds and louder environmental events. The dynamic range compression algorithm successfully adapted to each environment, maintaining a consistent output level despite dramatically different input amplitudes.
The noise floor calibration implemented in the Android application proved particularly effective in the quiet room environment, reducing the audibility of system self-noise by approximately 6 dB based on a spectral analysis. This improvement was less pronounced in noisier environments, where environmental sounds naturally masked system noise. We acknowledge that the subjective audio quality assessment was conducted with only three evaluators, which provides limited statistical power. Future work should incorporate objective metrics such as PESQ (Perceptual Evaluation of Speech Quality) and STOI (Short-Time Objective Intelligibility) to provide more robust and statistically significant quality assessments. The subjective quality scores represent averaged ratings from three independent evaluators using a standardized five-point scale, where one indicates poor quality and five indicates excellent quality. While this provides initial validation of system performance, future studies should employ larger sample sizes and standardized objective metrics for a more comprehensive quality assessment.
6.4. Motor Control Performance
The motor control system demonstrated a consistent performance across the testing scenarios.
Table 3 summarizes the measured command latency and execution accuracy for each distance condition.
Command execution accuracy represents the percentage of commands that produced the expected movement without obvious deviation or delay. The slight decrease in accuracy at greater distances correlates with increased packet loss in the Bluetooth connection, though the system maintained acceptable performance even at 10 m with obstacles present.
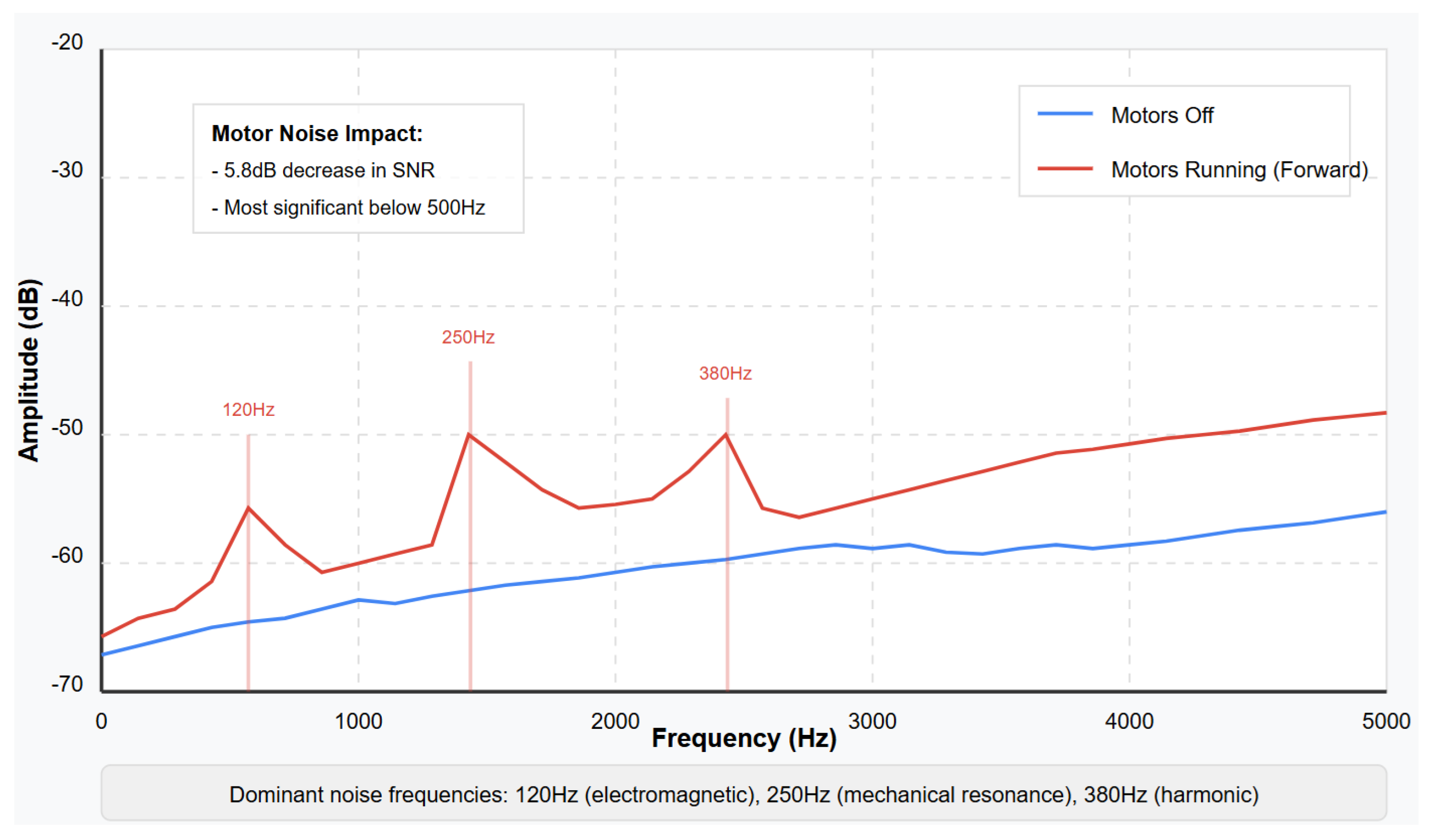
Electromagnetic interference from motor operation affected audio quality to varying degrees depending on movement intensity and microphone orientation.
Figure 7 illustrates the spectral impact of motor operation on audio recording, showing the characteristic frequency bands affected by motor noise. The analysis reveals dominant interference peaks at 120 Hz and 250 Hz, consistent with motor switching frequencies and mechanical resonances. This interference was most pronounced during high-speed forward and backward movements, with turning operations producing less significant effects due to the differential motor operation.
6.5. System Efficiency and Endurance
Power consumption varied significantly based on operational mode, with the highest consumption occurring during simultaneous audio streaming and motor operation.
Table 4 details the measured consumption across different operational scenarios.
The battery endurance testing confirmed these estimates, with the fully charged LiPo battery supporting approximately 4.3 h of combined operation before the voltage dropped below the operational threshold. This endurance is sufficient for typical field recording sessions and can be extended through power management strategies such as the selective activation of audio streaming only when necessary.
CPU utilization remained within manageable limits throughout all operational scenarios, with Core 0 averaging 65% utilization and Core 1 averaging 72% utilization during combined operation. This headroom suggests potential for additional on-device processing, such as basic audio analysis or feature extraction, in future iterations of the system.
6.6. Integrated Performance Evaluation
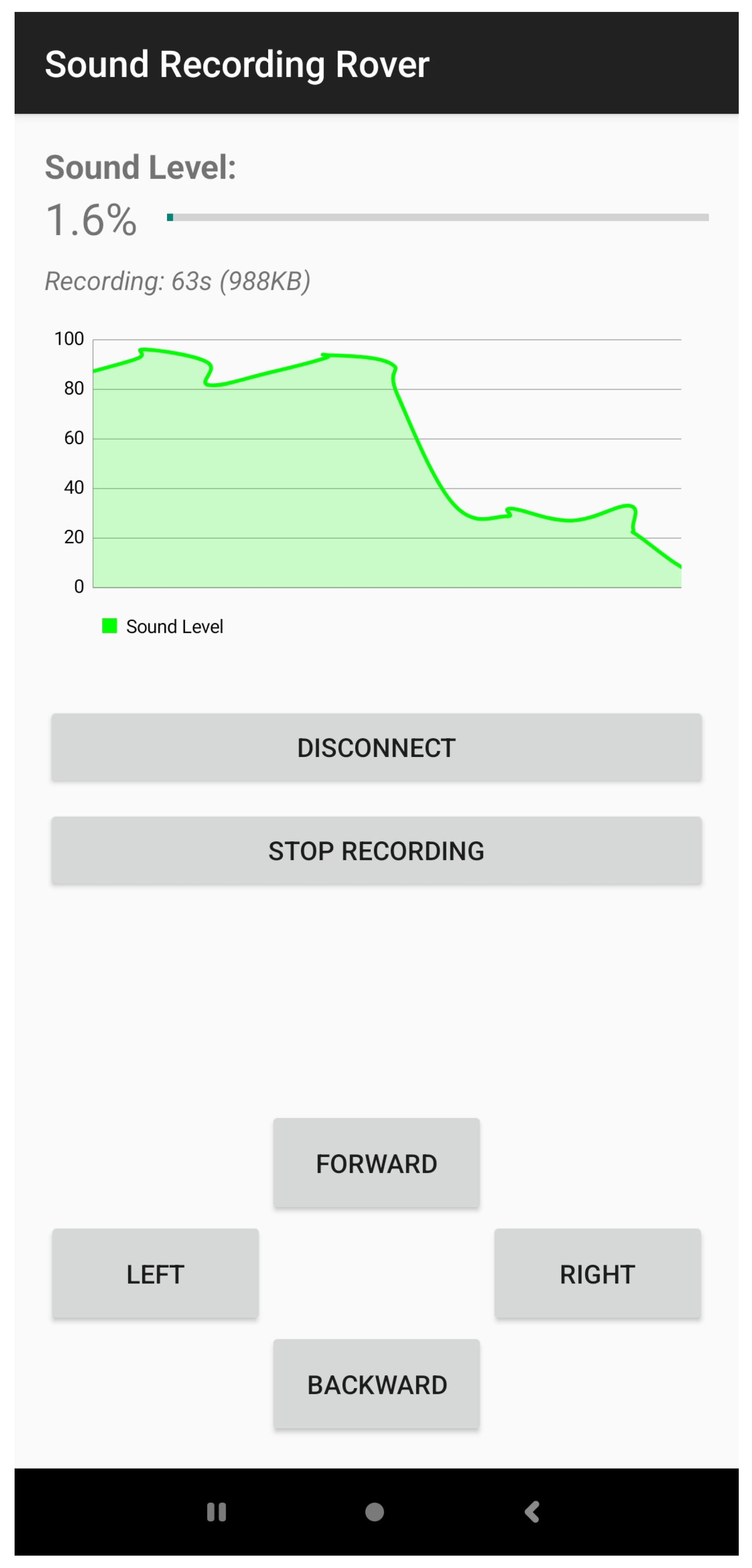
The combined results indicate that the Sound Recording Rover successfully achieves its primary objective of enabling mobile audio acquisition with concurrent teleoperation capabilities. The dual-thread architecture effectively partitions the computational resources, preventing command processing from interrupting audio acquisition while maintaining responsive control (
Figure 8).
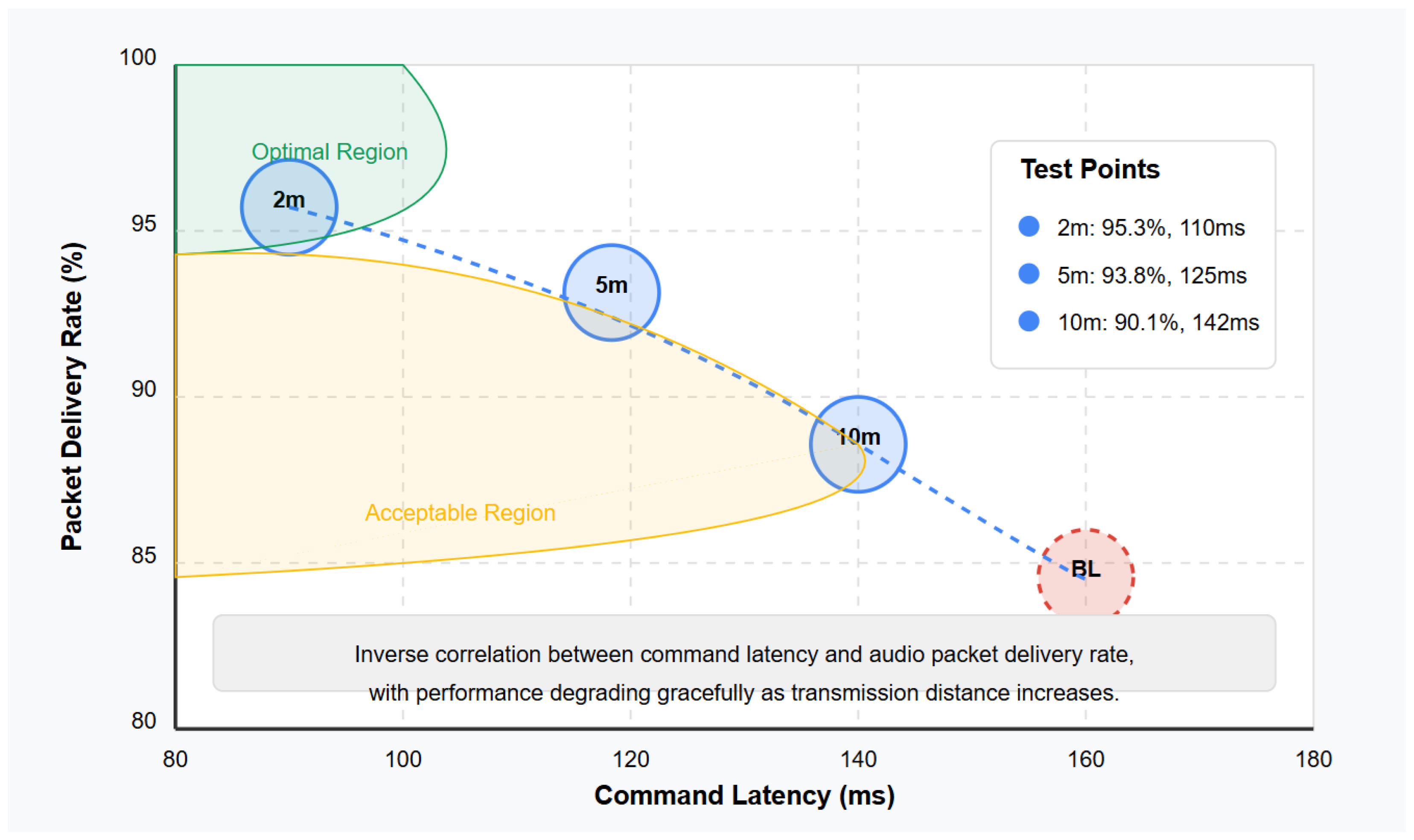
Figure 9 visualizes the relationship between audio quality (measured as the packet delivery rate) and control responsiveness (measured as the command latency) across the distance conditions. This visualization illustrates the system’s ability to maintain an acceptable performance in both domains simultaneously, with graceful degradation at the edges of its operational envelope.
The observed increase in the command latency with distance (from 105 ms at 2 m to 142 ms at 10 m) provides indirect evidence of Bluetooth signal degradation, though dedicated RF signal strength measurements were not conducted in this study. Future work should include a comprehensive Bluetooth SNR analysis across varying distances and environmental conditions to better characterize wireless communication performance.
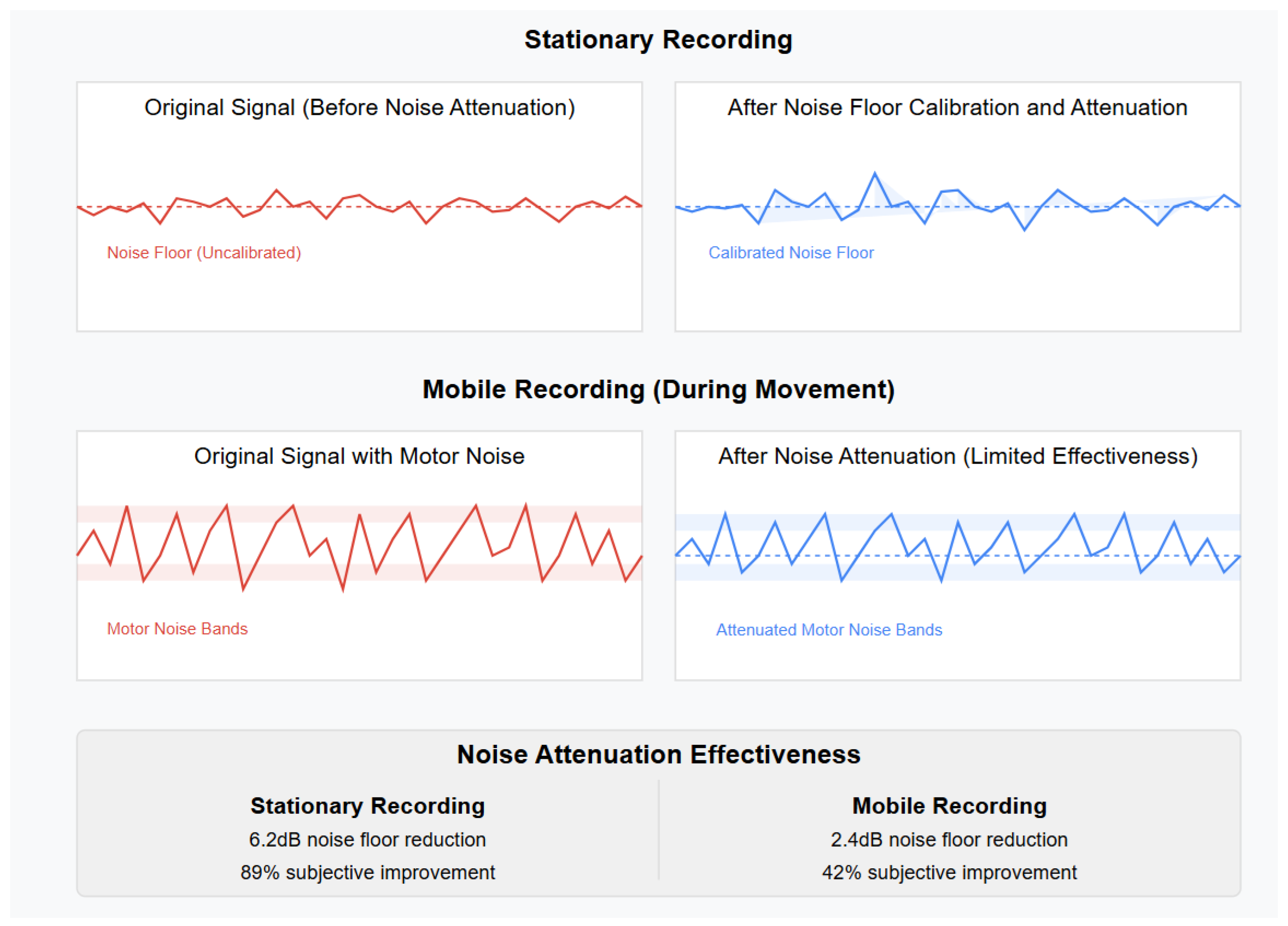
The noise floor calibration and attenuation algorithms implemented in the Android application significantly improved the subjective audio quality in stationary recording scenarios. However, during movement, mechanical vibration coupling and motor noise presented challenges that were only partially mitigated by the current implementation.
Figure 10 illustrates the effectiveness of the noise attenuation algorithm in both stationary and mobile recording scenarios.
These results suggest several potential improvements for future iterations:
Enhanced mechanical isolation for the microphone module.
Active noise cancellation techniques specifically targeting motor frequency bands, including LMS (Least Mean Squares) adaptive filtering for dynamic interference suppression of the identified 120 Hz and 250 Hz peaks.
Adaptive packet sizing based on a real-time connection quality assessment.
Directional microphone implementation to focus audio capture while reducing ambient noise.
Comprehensive Bluetooth SNR analysis across varying transmission distances and environmental conditions.
Comparative evaluation against existing mobile audio sensing solutions where applicable.
7. Applications and Future Directions
7.1. Potential Applications
Security and surveillance: The combination of mobility and audio sensing creates new possibilities for security applications, where the rover can investigate suspicious sounds or provide audio monitoring of areas that lack fixed infrastructure [
15]. The relatively quiet operation of the platform makes it suitable for unobtrusive monitoring in sensitive environments. This application aligns with work by Shyam et al. [
37] on bomb identification and defusing robots, demonstrating the potential for specialized security applications.
STEM education: The accessible design using commercial components makes the platform an excellent teaching tool for interdisciplinary STEM education, integrating concepts from robotics, digital signal processing, wireless communication, and software development. Students can modify and extend the platform to explore various aspects of these domains while working with tangible, engaging technology, building on Hong’s work [
13] in MEMS-embedded system design.
Acoustic research: For researchers studying environmental acoustics, the platform offers a cost-effective tool for gathering spatially diverse audio samples without the logistical challenges of deploying multiple fixed recording stations. The mobility enables adaptive sampling strategies based on real-time assessments of acoustic phenomena, supporting work like that of Yang et al. [
41] on emotion sensing using mobile devices.
Assistive technology: With modifications to enhance audio sensitivity in specific frequency ranges, the platform could serve as an assistive device for individuals with hearing impairments, allowing for the remote investigation of sounds or alerting users to specific acoustic events in their environment [
27,
28].
7.2. Future Research Directions
Building upon the foundation established in this work, several promising directions for future research emerge:
Multi-microphone array: Expanding the audio input capacity with multiple spatially distributed microphone operations would allow several advanced functions like sound source localization, beamforming-based noise cancelling, and directional recording. For this, the ESP32 has two I2S interfaces that can be used to read signals from an ADC directly.
On-device audio processing: Although a performance analysis revealed there is computational headroom available, the future releases may incorporate on-device audio feature extraction and classification. Such a solution can also reduce communication bandwidth because only meaningful acoustic events or statistics instead of the entire audio stream have to be transmitted.
Integration of machine learning: Adding lightweight machine learning models for audio event detection and classification would transform the platform from a passive data recorder into an intelligent acoustic monitoring system. TinyML frameworks specifically designed for ESP32 could enable the on-device processing of acoustic events, reducing bandwidth requirements and enabling real-time responses to specific sounds (alarms, breaking glass, or animal vocalizations). This approach would significantly reduce reliance on continuous streaming while maintaining high-quality event detection capabilities.
Advanced noise cancellation: Future implementations should incorporate sophisticated adaptive filtering techniques to address motor interference. LMS (Least Mean Squares) and NLMS (Normalized Least Mean Squares) algorithms could be implemented to dynamically cancel motor noise in real time. These adaptive filters could learn the spectral characteristics of motor interference during operation and selectively attenuate the 120 Hz and 250 Hz peaks identified in our analysis, while preserving environmental audio content.
Comprehensive wireless communication analysis: Future studies should include a detailed characterization of Bluetooth signal quality across varying distances, environmental conditions, and interference scenarios. This should include RF signal strength measurements, a bit error rate analysis, and packet loss characterization to better understand the relationship between wireless channel conditions and system performance. Additionally, evaluations of alternative wireless protocols (Wi-Fi, LoRa, and ZigBee) for specific application scenarios would broaden the framework’s applicability.
Comparative performance evaluation: Future work should include systematic comparison with existing mobile acoustic sensing solutions where applicable. This could involve implementing comparable systems using alternative architectures and conducting controlled performance evaluations to quantify the advantages of the integrated approach presented here.
Acoustic autonomous navigation: If autonomy is realized on this level, the system can search for sound sources and autonomously track them independently, and this would lead to developing novel applications such as industrial acoustic monitoring and wildlife acoustic exploration.
Mesh networking: Extending the communication architecture to support mesh networking between multiple rovers would enable collaborative acoustic sensing over larger spatial regions. BLE Mesh and hybrid Wi-Fi/Bluetooth protocols could address the scalability limitations of current Bluetooth Classic implementation. This would allow platforms to communicate, share data, and coordinate mobility to maximize coverage and gather acoustic information from multiple vantage points concurrently, addressing the scalability concerns raised for multi-robot deployments.
Improved power management: Improvements to the control of the power system and employment of energy scavenging devices, e.g., solar panels, could increase longevity in field scenarios, making battery replacement or recharging impractical for long-term deployments.
Enhanced audio quality assessment: Future work should incorporate objective audio quality metrics such as PESQ (Perceptual Evaluation of Speech Quality) and STOI (Short-Time Objective Intelligibility) to provide more robust and statistically significant quality assessments. Additionally, expanding subjective evaluations to include larger sample sizes would strengthen the statistical validity of perceptual quality assessments.
7.3. Study Limitations
Several limitations should be acknowledged in this work:
Bluetooth signal characterization: While audio SNR was comprehensively evaluated across different acoustic environments, Bluetooth signal SNR analysis was limited. This study did not include dedicated RF signal strength measurements or detailed characterization of wireless channel conditions across varying distances and environmental factors. The observed increase in command latency with distance provides indirect evidence of signal degradation, but comprehensive wireless communication analysis remains for future work.
Limited comparative evaluation: Direct quantitative comparison with existing mobile acoustic sensing methods was not conducted, primarily because most of the existing literature addresses audio capture and mobility control as separate problems. While our integrated approach represents a novel contribution, future work should include systematic comparison with alternative architectures where applicable.
Subjective quality assessment: The audio quality evaluation was limited to three independent evaluators using a five-point scale. This provides initial validation but lacks the statistical power of larger-scale studies. Future work should incorporate standardized objective metrics (PESQ and STOI) and larger sample sizes for more robust quality assessments.
Environmental testing scope: Testing was conducted in three representative acoustic environments (40 dB, 65 dB, and 85 dB), but broader environmental characterization including outdoor conditions, electromagnetic interference scenarios, and extreme temperatures would strengthen future evaluations.
These future directions represent natural extensions of the current framework, building upon its strengths while addressing the limitations identified through experimental evaluation. The modular architecture of both hardware and software components facilitates such evolution, allowing incremental improvements without requiring wholesale redesign of the system.
8. Conclusions
This paper presents a comprehensive theoretical and practical framework for concurrent real-time audio acquisition and motor control in resource-constrained mobile robotics, addressing fundamental challenges through novel algorithmic and architectural innovations.
The dual-thread processing model successfully partitions computational resources between time-sensitive control tasks and bandwidth-intensive audio processing, ensuring that neither system adversely affects the other. This architecture, combined with the adaptive audio compression algorithm and noise attenuation techniques, enables the capture of meaningful environmental audio data even in challenging acoustic environments and during platform movement.
Comprehensive empirical testing under a variety of operating conditions validates these observations; the system has been shown capable of commanding with latencies under 150 ms and audio packet delivery rates of >90% even at the limits of its operating envelope. The platform proved power efficient and its battery life is enough to be practical in field applications, with simultaneous operation (>4 h) available from a single battery charge.
The theoretical framework presented establishes new foundations for mobile acoustic sensing through three core innovations: integrated audio–mobility processing, adaptive real-time compression, and mathematically optimized concurrent architectures. These contributions advance the field beyond previous limitations that treated audio capture and mobility as mutually exclusive requirements.
The theoretical framework and practical implementations discussed here serve as an enabling foundation for further research and development in this emerging field. By solving the core problem of resource-constrained mobile audio sensing, our work lays the groundwork for more complex systems with multiple microphones, on-device processing, machine learning integration, autonomous exploration, and other rich features.
Future work should focus on extending these theoretical foundations to multi-agent systems, incorporating machine learning for adaptive optimization, and exploring application-specific optimizations for environmental monitoring, surveillance, and autonomous exploration domains.
In conclusion, the Sound Recording Rover framework demonstrates that effective acoustic sensing and responsive mobility can coexist on affordable, accessible platforms, enabling new applications and research directions at the intersection of robotics, audio processing, and environmental monitoring. This integration of sensing modalities represents an important step toward more capable and versatile mobile robotic systems that can perceive and interact with their environments through multiple complementary channels.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}