

BioMedInformatics 2026, 6(3), 32; https://doi.org/10.3390/biomedinformatics6030032 - 21 May 2026
Abstract
This study developed two Causal Graphical Models (CGMs) to analyze the transitions associated with Bacterial Vaginosis (BV) and to identify key bacterial species at each stage. BV results from an imbalance in the vaginal microbiota, whose composition varies among women and across developmental
[...] Read more.
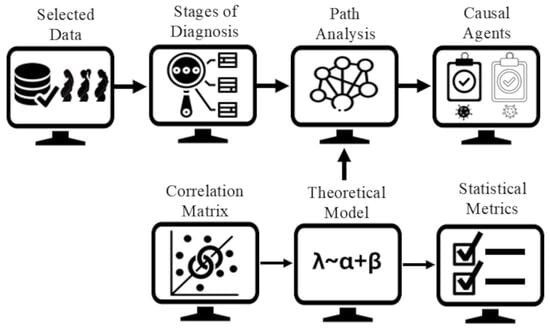
This study developed two Causal Graphical Models (CGMs) to analyze the transitions associated with Bacterial Vaginosis (BV) and to identify key bacterial species at each stage. BV results from an imbalance in the vaginal microbiota, whose composition varies among women and across developmental stages. A previous CGM identified influential bacteria but did not address changes between microbiota states. Here, we extend that framework to capture these associations. Path Analysis, a structural equation modeling method based on observed variables that estimates effects through correlations and covariances, was applied to a dataset of 132 pregnant women (4–24 weeks of gestation) from Tabasco, Mexico, previously collected by third parties during healthy pregnancy campaigns and associated with BV diagnosis. Models were validated using statistical metrics and evaluation by a clinical microbiologist. The first model, representing the transition from normal microbiota (BV−) to an indeterminate state (I), identified Megasphaera Type 1 as significant. The second model, from I to bacterial vaginosis-positive (BV+), identified Atopobium vaginae and Bacterial Vaginosis-Associated Bacterium Type 2 as significant contributors. These findings highlight the importance of the intermediate state in dysbiosis progression and support the use of CGMs for studying microbiome dynamics.
Full article
(This article belongs to the Topic Artificial Intelligence and Big Data in Biomedical Engineering)
►
Show Figures
Graphical abstract




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}