Abstract
Advancements in natural language processing (NLP), particularly Large Language Models (LLMs), have greatly improved how we access knowledge. However, in critical domains like biomedicine, challenges like hallucinations—where language models generate information not grounded in data—can lead to dangerous misinformation. This paper presents a hybrid approach that combines LLMs with Knowledge Graphs (KGs) to improve the accuracy and reliability of question-answering systems in the biomedical field. Our method, implemented using the LangChain framework, includes a query-checking algorithm that checks and, where possible, corrects LLM-generated Cypher queries, which are then executed on the Knowledge Graph, grounding answers in the KG and reducing hallucinations in the evaluated cases. We evaluated several LLMs, including several GPT models and Llama 3.3:70b, on a custom benchmark dataset of 50 biomedical questions. GPT-4 Turbo achieved 90% query accuracy, outperforming most other models. We also evaluated prompt engineering, but found little statistically significant improvement compared to the standard prompt, except for Llama 3:70b, which improved with few-shot prompting. To enhance usability, we developed a web-based interface that allows users to input natural language queries, view generated and corrected Cypher queries, and inspect results for accuracy. This framework improves reliability and accessibility by accepting natural language questions and returning verifiable answers directly from the knowledge graph, enabling inspection and reproducibility. The source code for generating the results of this paper and for the user-interface can be found in our Git repository: https://git.zib.de/lpusch/cyphergenkg-gui, accessed on 1 November 2025.
1. Introduction
Advances in natural language processing (NLP) have improved access to knowledge, allowing users to retrieve it in everyday language. In high-stakes areas like biomedicine, however, these advancements introduce new challenges, especially the risk of hallucinations [1,2,3,4], where models generate information unsupported by the underlying data. Inaccuracies in biomedical contexts can lead to harmful misinformation, such as incorrect treatments or diagnoses.
Biomedical databases, often organized as Knowledge Graphs (KGs), model complex data like diseases, drugs, and proteins, but remain challenging for non-experts to query due to specialized query languages. This paper addresses the challenge of reliable natural language question answering over biomedical KGs, focusing on reducing hallucinations. We propose a novel approach that integrates Large Language Models (LLMs) with KGs, enhancing the accuracy and reliability of responses by grounding answers in structured data.
Our method builds on the LangChain [5] framework to convert natural language into Cypher, the query language for graph databases like Neo4j. An important feature is a query-checking algorithm that validates LLM-generated Cypher queries to ensure they align with the KG’s schema, reducing errors and improving reliability. Validated queries are executed on the KG, and the results are used to generate a natural language response via retrieval-augmented generation (RAG) [6].
As an example, we applied our method to PrimeKG [7], a biomedical KG encompassing data on diseases, drugs, and proteins. Our system allows users to pose questions, view Cypher queries, and examine results through a user-friendly web interface. We evaluated this approach by doing a systematic comparison of LLMs and prompt strategies with a custom benchmark dataset of 50 biomedical questions, testing several LLMs, including GPT-4 Turbo, GPT-5, and Llama 3.3:70b. Results show that GPT-4 Turbo yields the most accurate queries, while the 70b Llama3 models lead the field of open source models tested in this benchmark.
In summary, our pipeline combines LLMs and KGs to address challenges such as hallucinations, providing accurate biomedical question answering and making advanced query capabilities accessible to non-experts.
Problem Statement and Research Goals
This paper addresses key challenges in using Large Language Models (LLMs) for accurate question answering over Knowledge Graphs, specifically tackling data gaps and hallucinations, where models produce ungrounded or incorrect information.
Our research focuses on these main objectives:
- Reducing Data Gaps and Hallucinations: We aim to decrease inaccuracies and fabrications in LLM responses by integrating them with Knowledge Graphs and using a query-checking algorithm that verifies and corrects Cypher queries generated by LLMs, targeting common syntactic and schema alignment issues. Additionally, we optimize prompts to guide LLMs in producing more accurate queries, enhancing response reliability.
- Evaluating LLM Performance: We assess the performance of several LLMs, including GPT-4 Turbo and Llama 3:70b, on a custom benchmark dataset to identify model strengths and weaknesses and explore improvements for open-source models via prompt engineering.
- Creating a Benchmark Dataset: We developed a dataset of 50 biomedical questions based on a subset of PrimeKG for evaluating LLMs’ ability to generate accurate Cypher queries for a specific biomedical Knowledge Graph, providing a foundation for future research in this domain.
- Designing a User-Friendly Interface: To make the system accessible, we created a user-friendly web-based interface where users can input natural language queries, view generated and corrected Cypher queries, and inspect results.
Our overarching goal is to combine the accessibility of LLMs and the reliability of complex digital information systems, specifically, Knowledge Graphs, to enable non-expert users to benefit from them.
2. A New Approach for LLM-Based Knowledge Graph Queries
In this section, we introduce our approach designed to address the challenges associated with using Large Language Models (LLMs) for information retrieval.
The overall method consists of three main steps:
- The user’s question, along with the graph schema, is passed to the LLM, which generates a Cypher query.
- This generated query is then subjected to the query-checking algorithm for validation and potential correction.
- Finally, the validated query is executed on the Knowledge Graph, and the results are returned.
2.1. Step 1: Initial Cypher Query Generation
The initial Cypher query is generated by the LLM using a prompt that includes the user query and the full graph schema, which is created with LangChain Neo4jGraph [8]. We use exact matching by design to isolate reasoning-to-Cypher under a fixed schema. Adding semantic or fuzzy matching would change the construct to alias coverage and is out of scope for this evaluation. Consistent with this design, our study is a systematic comparison of LLMs and prompt strategies for KG querying under a fixed schema, not a global leaderboard across heterogeneous KGQA paradigms. All models are evaluated identically on the same KG snapshot and parsing pipeline. The LLM outputs a Cypher query to retrieve answers from the Knowledge Graph, choosing node and relationship types from the schema. More information about the prompts can be found in Section 5. If the message consisted of a single fenced Cypher code block, we used its contents after removing the fence. Otherwise, we extracted the first contiguous span starting at the first line containing MATCH and ending at the first line containing RETURN, discarding any text before or after that span. This procedure was applied identically across models. Outputs without a Cypher block or a MATCH…RETURN span were marked invalid.
2.2. Step 2: Query Checker
The query checker checks common schema and direction issues before execution and can correct near-miss errors; it is designed to improve validity, not to serve as a full verifier. This process involves three components, each targeting specific aspects of query validation.
Consider the example query: “What are the names of the drugs that are contraindicated when a patient has multiple sclerosis?” A typical LLM-generated Cypher query might look like this:
MATCH (d:pathway {name:"multiple
⤷ sclerosis"})-[:contraindication]->(dr:drug)
RETURN dr;
However, this translation has the following issues:
- “Name” attribute missing from the returned node: The output RETURN dr; would return the entire drug node, including all its properties, rather than just the drug names. Thus, the syntax checker would refine the query to RETURN dr.name;.
- Wrong node type: (d:pathway {name:“multiple sclerosis”}) The LLM incorrectly identifies “multiple sclerosis” as a pathway, instead of a disease. The node checker would correct this error by modifying the Cypher query to: (d:disease {name:“multiple sclerosis”}).
- Relationship direction error: The query incorrectly directs the “contraindication” relationship as -[:contraindication]->, pointing from the disease to the drug. The correct direction should have the relationship pointing from the drug to the disease. This will be corrected by the relation checker to: <-[:contraindication]-.
In summary, the query checker executes the following three steps:
- Syntax Node Checker: This component ensures that the output of the Cypher query returns the resulting node names by appending the .name property to each node in the return statement. It also verifies that any variables specified in the return clause are correctly associated with their respective node types in the MATCH statement, in the form of node: node_type.
- Node Checker: This checker validates the types of nodes referenced in the query, ensuring they are the correct type for the item that was extracted from the question. If an incorrect node type is identified, it automatically substitutes the correct type. It also evaluates whether the relationships involving the corrected node type are appropriate and adjusts them if necessary, unless no compatible relationships exist, in which case the step is skipped.
- Relation Checker: This component verifies the directionality of relationships between nodes, ensuring that they are oriented correctly within the query. If any relationships are found to be reversed, the Relation Checker automatically corrects their direction to maintain the integrity of the query’s logic.
2.3. Step 3: Querying the Knowledge Graph
The Cypher query, generated by the LLM and verified by the query checker, is executed on the Knowledge Graph using Neo4jGraph from LangChain. Then, an answer sentence can be generated by the LLM based on the returned list. This retrieval-augmented generation (RAG) grounds each answer in the Knowledge Graph.
3. Data
This section describes the data used in our experiments, including the Knowledge Graph and a custom set of questions and answers.
3.1. PrimeKG-Based Knowledge Graph
We used a subset of the biomedical Knowledge Graph PrimeKG [7], specifically a 2-hop subgraph around multiple sclerosis. This subset contains 44,348 triples, 22 unique relations, and 7413 entities, covering node types such as drug, disease, phenotype, gene/protein, anatomy, cellular component, pathway, molecular function, exposure, and biological process. To optimize query execution, we made all relations unidirectional (except self-connections). Further details can be found in Appendix A.
3.2. Tailored Question/Answer Set
Traditional question datasets often don’t adequately assess a pipeline’s performance in querying Knowledge Graphs, but rather the graph completeness, as they are not tailored to the graph in question. To address this, we developed a custom set of questions specifically tailored for the selected Knowledge Graph. These questions are directly answerable using the graph’s data (see Appendix B for the original set and Appendix C for the paraphrased set). Initially, we identified paths that met our structural criteria and included only those with non-empty result sets (to make it possible to automatically assess correctness based on the answers). Questions were created using 1, 2, and 3-hop paths, representing five distinct structures. In Knowledge Graphs, a ‘hop’ refers to the number of edges between nodes; a 1-hop represents a direct connection, while higher hops indicate more complex queries involving intermediate nodes and relationships. These different structures allowed us to test the pipeline’s ability to handle queries of varying complexity. The dataset is designed to test schema comprehension and query construction over 1-, 2-, and 3-hop patterns in PrimeKG, not recall of disease facts or entity-specific knowledge.
During testing, we found that LLMs sometimes identified alternate, valid paths for answering questions that weren’t initially considered. These alternative answers, validated through manual curation, showcased the models’ flexibility in navigating the Knowledge Graph.
The way we structured questions into five types based on 1, 2, or 3-hop paths is outlined below.
3.2.1. One-Hop
For 1-hop questions, there is a straightforward structure involving a direct relationship between two entities. This allows for simple, direct queries; see Figure 1.

Figure 1.
Example structure for 1-hop question.
- Structure 1: A single, direct relationship between two nodes, typically excluding bidirectional relations. Example question: What are the names of the drugs that are contraindicated when a patient has multiple sclerosis?
3.2.2. Two-Hop
Two-hop questions allow for slightly more complex queries, involving either a single entity directly related to two others or a linear arrangement (chain) of three entities.
- Structure 2: One entity is directly connected to two other entities; see Figure 2. The question for this path was What side effects does a drug have that is indicated for Richter syndrome?
 Figure 2. Example structure for 2-hop question (structure 2).
Figure 2. Example structure for 2-hop question (structure 2). - Structure 3: A linear arrangement (chain) where one entity is connected to a second, which in turn is connected to a third; see Figure 3. The question for this path was What are phenotypes that gene POMC is associated with that also occur in neuromyelitis optica?
 Figure 3. Example structure for 2-hop question (structure 3).
Figure 3. Example structure for 2-hop question (structure 3).
3.2.3. Three-Hop
Three-hop questions introduce the highest complexity, involving either a sequential chain of four items or a configuration where an entity interfaces with multiple others in a more extended arrangement.
- Structure 4: A sequential chain of four connected items; see Figure 4. The question for this path was What pathways do the exposures that can lead to multiple sclerosis interact with?
 Figure 4. Example structure for 3-hop question (structure 4).
Figure 4. Example structure for 3-hop question (structure 4). - Structure 5: An entity has relationships interfacing with two other entities, one of which interfaces with a fourth entity; see Figure 5. The question for this path was Which biological processes are affected by the gene APOE and are also affected by an exposure to something that is linked to multiple sclerosis?
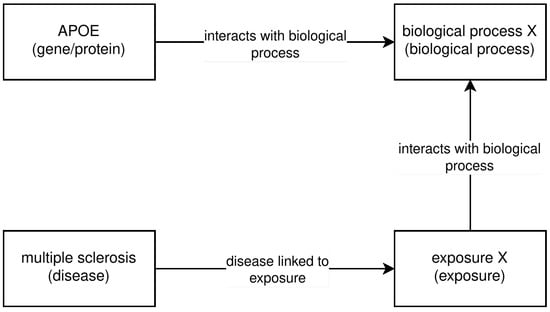 Figure 5. Example structure for 3-hop question (structure 5).
Figure 5. Example structure for 3-hop question (structure 5).
4. Experimental Setup
The LLMs used in our experiments are detailed in Table 1. The core pipeline is built using the LangChain Expression Language (LCEL) [9]. GPT models were called via their official APIs (prices at experiment time: GPT-4o $2.50/1 M tokens input and $10/1 M tokens output; GPT-4 Turbo $10/1 M tokens input and $30/1 M tokens output; GPT-5 $1.25/1 M tokens input and $10/1 M tokens output). Open-source models ran on our in-house cluster via Ollama and incurred no external billing. Wall-clock runtime was not benchmarked because latency depends on deployment choices (such as hardware allocation and batching), which are outside this study’s scope, focused on correctness and the checker ablation.

Table 1.
Overview of the used LLMs.
Evaluation Metrics
We evaluated each LLM based on the number of correct answers across all 50 questions (Section 3.2) in our dataset. For each question, we fixed a ground-truth result set during benchmark construction. Assuming the KG is correct, a model is correct if its generated Cypher, executed verbatim on the same database snapshot, returns exactly the ground-truth set of results (order ignored).
5. Cypher Generation with Zero-Shot Prompting
In this experiment, we evaluated several LLMs’ abilities to generate Cypher queries from natural language inputs in a zero-shot setting, where no examples or demonstrations are provided to guide the LLM. Each LLM was prompted to generate Cypher queries for the 50 questions in our benchmark set (see Section 3.2), with schema information provided as described in Section 2.1. The shortened prompt was adapted from the LangChain Cypher Graph QA chain [30]. The full prompt can be found in Appendix D.1. The placeholders schema and question are replaced by the respective content before execution.
(Shortened) Zero-shot prompt:
Task: Generate Cypher statement to query a graph database.
Schema: {schema}
The question is: {question}
To maintain consistency, each LLM had a temperature setting of 0 to reduce randomness, unless a custom temperature was not allowed. The generated Cypher queries were parsed to retain only relevant portions, removing non-Cypher content, and then processed by the query-checking algorithm (see Section 2.2) to correct common errors, including incorrect node types, relationship misdirections, and missing attributes.
5.1. Results
The proprietary GPT models, especially GPT-4 Turbo, often outperform the open-source models. Table 2 reports, for each LLM, the number correct out of 50, accuracy, and 95% Wilson CIs. Table 3 shows Holm-adjusted McNemar pairwise tests, with significant results at bold and starred. According to these results, GPT-4 Turbo and GPT-5 outperform all open-source models except Llama 3.3 70B, where the difference is not significant. GPT-4o also does not differ significantly from Llama 3 70B. The GPT models do not differ significantly among themselves. Within the open-source group, Llama 3.3 70B leads, outperforming 13 models, followed by Llama 3 70B, which outperforms 9.
Table 2.
The number of correct answers (out of 50 total), accuracy and Wilson 95% confidence intervals for all LLMs.
Table 3.
Holm-adjusted McNemar pairwise comparisons of models (row-column); Green = Positive, Red = Negative. Bold and starred cells are significant ().
Figure 6 depicts the relationship between the number of parameters (in billions) and the number of correct answers. Although proprietary GPT models were excluded due to undisclosed parameter counts, a general trend indicates that models with more parameters tend to yield better results.

Figure 6.
Scatterplot of number of parameters by correct answers; excluding GPT because the number of parameters is likely too high.
Figure 7 explores model performance based on query complexity, measured by the “hop” count between entities. Most models performed well on simpler, one-hop queries, but only the GPT models maintained high accuracy on both of the more complex two- and three-hop queries.

Figure 7.
Percentage of correct answers by hop count (# hops).
Overall, our findings indicate that for generating reliable Cypher queries from biomedical questions with a zero-shot prompt, the GPT variants are currently the most effective models within the proposed framework. Among them, GPT-4 Turbo and GPT-5 outperformed more open source variants than the GPT-4o model.
5.2. Influence of the Query Checker
We evaluate the checker by comparing, per model and item, correctness before vs. after applying it. The checker is monotone by design: as a rule-based algorithm, it never alters a correct query, and either fixes an error or leaves it unchanged. Across all 23 × 50 evaluations it corrected 172 of 999 items that were wrong pre-checker, for an overall help rate of 0.172 with a Wilson 95% CI of [0.15, 0.2] (Wilson 95% CI reported per model in Table 4). This yields an average accuracy uplift of +14.95 percentage points.
Table 4.
Per-model pre/post query checker results on 50 items per model. Counts show items correct without the checker, corrected by the checker, still wrong (no checking opportunities or despite checking), and totals. Accuracy uplift is defined as the increase in accuracy when applying the checker. Help rate is the effectiveness on eligible errors with 95% Wilson CIs. Residual error rate is the remaining error rate after the checker.
The effect is model-dependent. The checker amplifies strong models: GPT-5 shows a help rate of 0.84 [0.71, 0.91], GPT-4o 0.80 [0.66, 0.89], and GPT-4 Turbo 0.69 [0.44, 0.86], with sizable uplift and low residual error. Notably, without the checker, the first two models have few correct queries, yet they rank among the highest once checking is applied. In contrast, Llama 3.3:70b starts with many correct queries but achieves only a 0.14 help rate, suggesting its remaining errors are harder for the checker to repair. Mid-tier models benefit but retain significant residual error, for example, Llama 3:70b at 0.45 help and 0.54 residual, and Goliath:120b at 0.31 help and 0.62 residual. Low-baseline models rarely improve, often near 0 with Wilson upper bounds around 0.07. In conclusion, the checker helps most when the base model is already strong, gives moderate gains in the middle, and cannot rescue low-end failures.
The checker addresses schema/syntax issues (e.g., node names or relationship directions). It cannot repair conceptual errors or missing reasoning steps. Therefore, it helps most when the model’s queries are “almost right” and least when queries are structurally off or syntactically incorrect. A pooled one-sided binomial test on help rate confirms the checker does not fix a majority of errors overall (baseline p0 = 0.5), but it yields meaningful accuracy gains in aggregate due to the volume of eligible near-misses.
5.3. Influence of Paraphrased Questions
We tested whether paraphrasing affects pipeline performance by rewriting all 50 questions from Section 3.2 (Appendix C) and re-evaluating the two top models: GPT-4 Turbo (closed-source) and Llama 3.3 70B (open-source). Table 5 reports the number of correct answers, accuracy, and 95% Wilson CIs. Using McNemar tests with Holm correction, Table 6 compares each model to itself across normal vs. paraphrased questions and compares the models to each other on each set. We find no significant within-model difference between normal and paraphrased questions. On the normal set, GPT-4 Turbo significantly outperforms Llama 3.3 70B; this contrast was not flagged in Table 3 because that table applies a more stringent correction across a larger family of comparisons. Finally, Table 7 aggregates normal and paraphrased questions and shows that GPT-4 Turbo remains significantly better than Llama 3.3 70B; total answer counts per model in this combined analysis are also reported in Table 5.
Table 5.
The number of correct answers, accuracy and Wilson 95% confidence intervals for all LLMs.
Table 6.
Holm-adjusted McNemar pairwise comparisons of GPT-4 Turbo and Llama 3.3:70b on both normal and paraphrased questions (row-column); Green = Positive, Red = Negative. Bold and starred cells are significant ().
Table 7.
Holm-adjusted McNemar pairwise comparisons of GPT-4 Turbo and Llama 3.3:70b on normal and paraphrased questions together (row-column); Green = Positive, Red = Negative. Bold and starred cells are significant ().
6. Cypher Generation with Optimized Prompting
In this experiment, we investigated how prompt optimization could improve the quality of Cypher queries generated by LLMs. Using the 50 questions from our benchmark dataset, we tested optimized prompts, including specific examples and tailored instructions, to help the LLMs produce more accurate Cypher queries.
This section presents results from experiments focused on optimizing prompts for the two models, GPT-4 Turbo and Llama 3:70b. We tested three prompting strategies (zero-shot, one-shot, and few-shot prompting) and explored various prompt crafting techniques to enhance initial Cypher query generation and improve overall pipeline performance.
6.1. Multi-Shot Prompts
Providing different numbers of examples in prompts can significantly affect model performance. To evaluate this effect, we compared zero-shot (no examples), one-shot (one example), and few-shot (multiple examples) prompting to assess their impact on Cypher query generation. Below are examples of these prompts; full versions with more hints for the LLM are available in Appendices Appendix D.2 and Appendix D.3.
(Shortened) One-Shot Prompt:
Task:Generate Cypher statement to query a graph database.
Schema: {schema}
Follow these Cypher examples when Generating Cypher
⤷ statements:
# How many actors played in Top Gun?
MATCH (m:movie {{name:"Top Gun"}})<-[:acted_in]-(a:actor)
RETURN a.name
The question is:
{question}
(Shortened) Few-Shot Prompt:
Task:Generate Cypher statement to query a graph database.
Schema: {schema}
Follow these Cypher example when Generating Cypher
⤷ statements:
# Which actors played in Top Gun?
MATCH (m:movie {{name:"Top Gun"}})<-[:acted_in]-(a:actor)
RETURN a.name
# What town were the actors that played in Top Gun born in?
MATCH (m:movie {{name:"Top
⤷ Gun"}})<-[:acted_in]-(a:actor)-[:born_in]->(t:town)
RETURN t.name
The question is:
{question}
Table 8 shows the total number of correct answers out of a maximum of 50, the accuracy and the Wilson 95% confidence intervals for GPT-4 Turbo and Llama 3:70b. When doing a Holm-adjusted McNemar pairwise comparison of the prompt types and models, as shown in Table 9, we see that for GPT-4 Turbo, adding examples does not significantly change performance. However, for Llama 3:70b, few-shot prompting showed a significant improvement over zero-shot. One-shot does not lead to significant improvements. When comparing Llama 3:70b and GPT-4 Turbo, combining the GPT model with zero-shot prompting significantly outperforms all Llama 3 variants except Llama 3 Few-Shot. Moreover, every shot-combination coupled with a GPT model outperforms Llama 3 zero-shot prompting. This underscores the advantage of using few-shot prompting with a model like Llama 3:70b.
Table 8.
n-shot comparison for GPT-4 Turbo and Llama 3:70b: the number of correct answers (out of 50 total), accuracy and Wilson 95% confidence intervals.
Table 9.
Holm-adjusted McNemar pairwise comparisons of Zero-Shot, One-Shot and Few-Shot prompts for GPT-4 Turbo and Llama 3:70b; Green = Positive, Red = Negative. Bold and starred cells are significant ().
6.2. Promptcrafting
Prompt design can substantially influence model performance. To explore this, we tested different prompt formulations to measure their impact on Cypher query generation. Building on our initial prompts, we experimented with several variations:
- Simplified Prompt: Removed detailed instructions to evaluate the effect of minimal guidance (Appendix D.4).
- Syntax Emphasis Prompt: Added a sentence instructing the model to focus on correct syntax usage (Appendix D.5).
- Social Engineering Prompt: Introduced a scenario where the prompter could face consequences (e.g., being fired) if the LLM made mistakes (Appendix D.6).
- Expert Role Prompt: Positioned the LLM as a Cypher query expert to encourage more accurate query generation (Appendix D.7).
These variations were applied to both GPT-4 Turbo and Llama 3:70b. Table 10 shows the total number of correct answers out of a maximum of 50, the accuracy and the Wilson 95% confidence intervals for GPT-4 Turbo and Llama 3:70b. When doing a Holm-adjusted McNemar pairwise comparison of the prompt types and models, as shown in Table 11, we see that the simplified prompt was the worst choice for GPT, with the Social and Expert prompts being significantly better. For Llama 3:70b, the promptcrafting did not have a statistically significant impact on performance. When comparing GPT-4 Turbo and Llama 3:70b, it is notable that the GPT model performs significantly better, except for the Simple prompt, which only performs significantly better than Llama 3 combined with the same prompt.
Table 10.
Promptcrafting comparison for GPT-4 Turbo and Llama 3:70b: the number of correct answers (out of 50 total), accuracy and Wilson 95% confidence intervals. The compared prompts are the standard prompt used in the experiment above, a simplified prompt with minimal guidance, a prompt with special emphasis on correct syntax, a social engineering prompt and a prompt positioning the LLM as an expert.
Table 11.
Holm-adjusted McNemar pairwise comparisons of different prompt types for the best GPT-model (GPT-4 Turbo) and the best open source model (Llama 3:70b); Green = Positive, Red = Negative. Bold and starred cells are significant ().
7. User Interface
We created a web-based user interface (UI) for this system specifically designed for interacting with the Knowledge Graph described in Section 3 through natural language queries. A screenshot is shown in Figure 8. Using this UI, users can input questions, view the initial Cypher query generated by the LLM, and inspect the corrected query after validation by the query-checking algorithm, all within the same interface. This feature allows users to clearly compare the original and corrected queries and check which node and relationship types are being used in the query, providing transparency into the modifications made.

Figure 8.
Screenshot of GUI.
The GUI was developed using Streamlit [31]. It interfaces with Neo4j [32] and Ollama [33], making all downloaded LLMs and a Knowledge Graph available for question answering.
8. Related Work
Recent advancements in question answering over Knowledge Graphs (KGs) increasingly leverage large language models (LLMs) to enhance query generation and answer formulation. Approaches integrating LLMs with KGs include direct translation methods, prompt optimization, subgraph extraction, and entity matching. This section reviews these methods, highlighting their contributions to KG-based question answering. While we briefly compare non-LLM KGQA methods to contextualize the space, our experimental scope is limited to LLM-based KG querying and prompting under a shared KG and pipeline.
- Direct Translation and Fine-Tuning of Language Models
Several studies focus on directly translating natural language questions into SPARQL queries through fine-tuned LLMs. Wang et al. [34] introduced NLQxform, where a BART model is fine-tuned on SPARQL, avoiding ID hallucinations by using entity names rather than IDs and employing string matching for entity recognition. They construct a “logical form” as a query template based on the question, selecting results via template matching. Similarly, Luo et al. [35] proposed ChatKBQA, fine-tuning an LLM on pairs of questions and logical forms of SPARQL queries and generating queries by identifying the top-k similar entities and relations for each candidate form. Fine-tuning LLMs has proven effective for SPARQL generation, minimizing ID hallucinations and improving entity recognition through template matching.
- Chain-of-Thought Prompting and Few-Shot Learning
Chain-of-thought (CoT) prompting enhances LLMs’ reasoning in query generation. Zahera et al. [36] utilized CoT prompting and provided extracted entities and relations from the input question, along with few-shot examples that match the question’s structure. Their method leverages entity-linking and relation extraction libraries to inform the LLM. Avila et al. [37] match question-query pairs to the input question by similarity in question structure. They get passed to the LLM alongside entities and relations and the input question to perform few-shot prompting. Overall, CoT prompting and few-shot learning have been shown to enhance the reasoning capabilities of LLMs.
- Semantic Parsing and Template-Based Methods
Semantic parsing has been an important technique in transforming natural language into machine-understandable queries. Pérez et al. [38] explored semantic parsing for conversational question answering with two distinct approaches. The first involved creating a subgraph from identified KG entities and their one-hop neighborhoods, which, along with the question and context, was input into a semantic parser to generate SPARQL queries. The second approach used an encoder–decoder model to convert questions into logical form templates, predicting query structures and relations. Entity recognition and linking were facilitated by a dedicated model, and a graph attention network encoded the graph schema to fill in missing template parts. Agarwal et al. [39] presented a self-supervised program synthesis approach for zero-shot KGQA. They generated question-query pairs by traversing the KG and having the LLM formulate questions for the paths found. For real questions, similar pairs were retrieved based on the cosine similarity of sentence embeddings to serve as few-shot examples. Candidates were re-ranked by regenerating questions from queries to find the closest match. In essence, semantic parsing techniques and template-based methods offer a structured approach for question-answering.
- Subgraph Extraction and Contextualization
Efficient subgraph extraction can help to reduce token usage and focus the LLM on relevant information. Avila et al. [37] proposed a framework that retrieves a subgraph centered around the user’s question. They grouped triples by subject and property to form sentences, computed embeddings to identify those closest to the question, and reconstructed a connected subgraph. The LLM then generated multiple SPARQL queries, selected the best one based on the results, and formulated a natural language answer. Pliukhin and Rehm’s [40] method also involved subgraph extraction by deriving two-hop paths containing relevant objects, which were merged and used to prompt the LLM. They also passed a question-query pair that is similar to the question and validated the query by removing hallucinated symbols. Soman et al. [41] focused on biomedical KGs by extracting disease entities using an LLM and computing vector similarities with disease concept embeddings in SPOKE [42]. They fetched neighboring nodes, converted triples into sentences, and pruned the context by selecting sentences with high similarity scores to the input prompt. This pruned context, along with the question, was provided to the LLM. Pérez et al. [38] constructed a subgraph from KG entities identified in the question and their one-hop neighborhoods. Thus, subgraph extraction techniques that focus on constructing relevant subgraphs from KG entities allow LLMs to generate more accurate queries by providing concise and context-rich input.
- Entity and Relation Matching Techniques
Accurate entity and relation matching is important for the validity of generated queries. Zahera et al. [36] and Wang et al. [34] utilized entity-linking and relation extraction libraries with string matching techniques, respectively, to identify relevant KG components. Steinigen et al. [43] improved upon this by performing entity extraction to replace synonyms with the corresponding graph entities. Their work, Fact Finder, closely aligns with our approach by incorporating the KG schema and relation descriptions into the prompt for the LLM to generate Cypher queries. They also implemented query preprocessing steps such as formatting, lowercasing properties, synonym mapping, and fixing deprecated code issues. Jia et al. [44] leveraged LLMs for semantic query processing in a scholarly knowledge graph. Their approach involves the LLM generating a triple structure that could potentially answer the user’s question. All triples from the KG that fulfill this structure are then extracted. The LLM evaluates these triples to determine which ones answer the question effectively. Entity matching is performed by checking if lowercased labels of entities are contained within the input text, and relevance is assessed based on the frequency of entity labels appearing in clusters of triples. If no exact matches are found, they employ query relaxation by removing parts of the triple or substituting relations with similar ones. Luo et al. [35] enhanced entity and relation matching by calculating similarities for entities and relations in the logical forms and retrieving the top matches. In conclusion, entity and relation matching methods enhance query accuracy by leveraging string matching, synonym mapping, and semantic processing to align input questions with the corresponding graph entities and relations.
9. Conclusions
This research aimed to improve the accuracy and reliability of natural language question-answering systems by integrating Large Language Models (LLMs) with Knowledge Graphs, particularly in the biomedical domain. We developed a pipeline where LLMs generate Cypher queries, which are then validated and corrected using a query-checking algorithm. To evaluate our approach, we created a benchmark dataset of 50 biomedical questions and compared the performance of various LLMs, including GPT-4 Turbo, GPT-5 and Llama 3.3:70b.
Our results show that GPT-4 Turbo and GPT-5 consistently outperformed current open-source models in generating accurate Cypher queries. Although switching from zero-shot prompting to few-shot prompting notably improved the performance of the open-source model Llama 3:70b, it did not reach the accuracy and reliability levels achieved by GPT-4 Turbo. Promptcrafting also did not increase the performance of Llama 3:70b. These findings suggest that while prompt engineering can enhance open-source model performance, a gap remains between open-source and proprietary models in Cypher query generation. When analyzing whether paraphrasing the questions influences performance, we could find no difference for the models we used in the analysis, GPT-4 Turbo and Llama 3.3:70b.
This study also contributes a valuable dataset of 50 biomedical questions and answers tailored to a subset of PrimeKG, offering a resource for future benchmarking and inspiring similar datasets across other Knowledge Graphs.
10. Outlook
We identify several avenues to refine the pipeline. Expanding the question set may be informative but is not required for the present conclusions, which target schema-grounded NL-to-Cypher synthesis on 1- to 3-hop queries. A separate research track is entity linking and semantic matching. This targets surface-form resolution rather than query reasoning and can be studied independently on top of our system.
Future work includes integrating a second language model to assist with query validation or refinement. Longer-term, linking individual patient data to the knowledge graph could enable patient-specific querying. This would require data governance, consent, privacy-preserving processing, and harmonization across modalities (e.g., omics, labs, EKG), and sits beyond the present study’s scope.
Author Contributions
Conceptualization, L.P. and T.O.F.C.; methodology, L.P.; software, L.P.; validation, L.P. and T.O.F.C.; data curation, L.P.; writing—original draft preparation, L.P.; writing—review and editing, L.P. and T.O.F.C.; funding acquisition, T.O.F.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Deutsche Forschungsgemeinschaft (DFG) (project grant 460135501).
Data Availability Statement
The source code for generating the results of this paper and for the user-interface can be found in our Git repository: https://git.zib.de/lpusch/cyphergenkg-gui (accessed on 1 December 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. PrimeKG Structure and Changes
In optimizing PrimeKG for efficient testing, several modifications were made to its structure and names. The graph was first reduced to a 2-hop subgraph centered around ’multiple sclerosis,’ cutting it down from around 8 million triples, 30 relational types, and 130,000 entities to about 45,000 triples, 22 unique relational types, and 7413 distinct entities. This reduction aimed to make queries faster.
Additionally, the graph’s relational directionality was altered to make only self-relations bidirectional. This helped streamline information and improve logical consistency in sentence generation.
Table A1.
Adjustments Made to PrimeKG.
Table A1.
Adjustments Made to PrimeKG.
| Type of Change | PrimeKG | Adjusted Version | Reason |
|---|---|---|---|
| 2-hop subgraph around ’multiple sclerosis’ | ∼8 M triples, 30 distinct relations, ∼130k unique items | ∼45k triples, 22 distinct relations, ∼7400 unique items | Make querying graph faster |
| Relation direction | All relations unidirectional | Only self-relations bidirectional | Shrink graph information, makes more sense in a sentence |
Appendix B. Questions and Answers
This table contains the 50 questions and answers that were used as a benchmark.
Table A2.
50 questions.
Table A2.
50 questions.
| Question | Answer |
|---|---|
| What are the names of the drugs that are contraindicated when a patient has multiple sclerosis? | Ascorbic acid, Zinc gluconate |
| Which drugs are contraindicated when I have dermatitis? | Hydrocortisone, Cortisone acetate, Triamcinolone |
| Which drugs cause Alkalosis as a side effect? | Methylprednisolone, Prednisone |
| Which drugs have Anxiety as side effect? | Methylprednisolone, Prednisone, Hydrocortisone, Dexamethasone, Betamethasone |
| Which genes are expressed in the eye? | CBLB, RBPJ, KCNJ10, SLC11A1, CLEC16A |
| What genes are expressed in the nasopharynx? | RBPJ |
| What proteins interact with GRB2? | CBLB, GC, IL7R, P2RX7, TNFRSF1A, VCAM1 |
| What proteins interact with the protein KPNA2? | CBLB, IL7R, IL10, VCAM1 |
| What are off-label uses of Zinc gluconate? | methemoglobinemia, sulfhemoglobinemia, attention deficit-hyperactivity disorder, attention deficit hyperactivity disorder, inattentive type, gastroenteritis, acrodermatitis enteropathica |
| What are off-label uses for Ascorbic acid? | Coronavinae infectious disease |
| In which cellular components is a protein expressed that is associated with the Spasticity phenotype? | plasma membrane, cytoplasm, integral component of plasma membrane, membrane raft, actin cytoskeleton, glutamatergic synapse, mitochondrial outer membrane, integral component of presynaptic membrane, GABA-ergic synapse, growth cone, integral component of mitochondrial membrane |
| In which cellular components is a protein expressed that is associated with Nausea? | cytoplasm, extracellular space, extracellular region, secretory granule, secretory granule lumen |
| What side effects does a drug have that is indicated for Richter syndrome? | Abdominal distention, Abdominal pain, Adrenal insufficiency, Alkalosis, Alopecia, Alopecia of scalp, Anaphylactic shock, Poor appetite, Anxiety, Arrhythmia, Arthralgia, Hypertrophic cardiomyopathy, Corneal ulceration, Delusions, Inflammatory abnormality of the skin, Atopic dermatitis, Vertigo, Bruising susceptibility, Edema, Abnormality of the endocrine system, Seizure, Abnormality of the eye, Fatigue, Fever, Erythema, Recurrent fractures, Gastrointestinal hemorrhage, Glycosuria, Hallucinations, Headache, Cardiac arrest, Cardiomegaly, Congestive heart failure, Hepatomegaly, Hirsutism, Hypercholesterolemia, Hyperglycemia, Hypernatremia, Hyperthyroidism, Hypothyroidism, Abnormal joint morphology, Arthropathy, Lethargy, Leukocytosis, Nausea, Abnormal peripheral nervous system morphology, Polyneuropathy, Peripheral neuropathy, Avascular necrosis, Osteoporosis, Generalized osteoporosis, Pancreatitis, Optic neuritis, Papilledema, Paraplegia, Paresthesia, Peptic ulcer, Petechiae, Pruritus, Pulmonary edema, Facial erythema, Loss of consciousness, Syncope, Tachycardia, Telangiectasia, Thrombophlebitis, Vasculitis, Vomiting, Increased body weight, Agitation, Emotional lability, Mood swings, Mood changes, Dermal atrophy, EEG abnormality, Impaired glucose tolerance, Growth delay, Increased intracranial pressure, Muscle weakness, Tendon rupture, Striae distensae, Irregular menstruation, Malnutrition, Abnormality of the skin, Paraparesis, Myalgia, Polyphagia, Memory impairment, Ocular hypertension, Subcapsular cataract, Personality changes, Vertebral compression fractures, Myopathy, Lipoatrophy, Mania, Blurred vision, Scaling skin, Hyperactivity, Hyperkinetic movements, Bradycardia, Dementia, Facial edema, Hyperhidrosis, Dry skin |
| If I take drugs for dry eye syndrome, what side effects will they have? | Abdominal distention, Anaphylactic shock, Arrhythmia, Hypertrophic cardiomyopathy, Corneal ulceration, Atopic dermatitis, Bruising susceptibility, Edema, Inflammatory abnormality of the skin, Headache, Cardiac arrest, Cardiomegaly, Congestive heart failure, Hepatomegaly, Hirsutism, Hypernatremia, Abnormal joint morphology, Arthropathy, Keratitis, Mydriasis, Nausea, Abnormal peripheral nervous system morphology, Polyneuropathy, Peripheral neuropathy, Osteoporosis, Generalized osteoporosis, Pancreatitis, Optic neuritis, Papilledema, Paraplegia, Paresthesia, Peptic ulcer, Petechiae, Pulmonary edema, Seizure, Vertigo, Loss of consciousness, Syncope, Tachycardia, Thrombophlebitis, Vasculitis, Increased body weight, Hypokalemic alkalosis, Emotional lability, Mood swings, Mood changes, Avascular necrosis, Increased intracranial pressure, Muscle weakness, Tendon rupture, Striae distensae, Irregular menstruation, Paraparesis, Polyphagia, Ocular hypertension, Subcapsular cataract, Erythema, Personality changes, Vertebral compression fractures, Myopathy, Blurred vision, Bradycardia, Visual impairment, Pain, Hyperhidrosis, Dry skin |
| In what anatomical structures is there no expression of proteins that interact with leukocyte migration? | cerebellar vermis |
| In what anatomical structures is there no expression of proteins that interact with cell migration? | vastus lateralis, cerebellar vermis |
| What genes and biological processes does an exposure to Tobacco Smoke Pollution interact with? | regulation of blood pressure, triglyceride metabolic process, respiratory system process, gene expression, DNA methylation, spermatogenesis, cognition, regulation of DNA methylation, developmental growth, immune response, cholesterol metabolic process, behavior, lipid metabolic process, DNA methylation on cytosine within a CG sequence, inflammatory response, regulation of gene silencing by miRNA, regulation of respiratory gaseous exchange, DNA metabolic process, respiratory gaseous exchange by respiratory system, menopause, circulatory system process, mRNA methylation, feeding behavior, hypersensitivity, estrone secretion, alanine metabolic process, lactate metabolic process, IFNG, IL1B, ARNT, ATF6B, BNIP3L, DDB2, FTH1, GADD45A, RAD51, TP53, TXN, AHRR, CNTNAP2, CYP1A1, EXT1, GFI1, HLA-DPB2, MYO1G, RUNX1, TTC7B, F2RL3, SLC7A8, C11orf52, FRMD4A, IL1B, IFNG, IL4, TNF, SERPINE1 |
| What genes and biological processes does an exposure to Lead interact with? | regulation of blood pressure, gene expression, cognition, head development, regulation of DNA methylation, glucose metabolic process, mitochondrial DNA metabolic process, behavior, lipid metabolic process, DNA methylation on cytosine within a CG sequence, regulation of heart rate, memory, regulation of systemic arterial blood pressure, response to oxidative stress, psychomotor behavior, hemoglobin biosynthetic process, visual perception, developmental process involved in reproduction, metabolic process, regulation of humoral immune response mediated by circulating immunoglobulin, glomerular filtration, cortisol metabolic process, detection of oxidative stress, tissue homeostasis, social behavior, calcium ion homeostasis, heart contraction, humoral immune response, lymphocyte mediated immunity, transport, ethanolamine metabolic process, glutamate metabolic process, urea metabolic process, regulation of cortisol secretion, inositol metabolic process, DNA methylation involved in gamete generation, regulation of multicellular organism growth, regulation of amyloid-beta formation, regulation of genetic imprinting, positive regulation of multicellular organism growth, sensory perception of sound, homocysteine metabolic process, response to auditory stimulus, renal filtration, response to lead ion, detection of mechanical stimulus involved in sensory perception, cellular amine metabolic process, choline metabolic process, creatine metabolic process, brain development, ICAM1, ADAM9, LRPAP1, RTN4, APP, IL6, TNFRSF1B, CRP, ICAM1, H19, HYMAI, IGF2, PEG3, PLAGL1, MIR10A, MIR146A, MIR190B, MIR431, MIR651, IGF1, HEXB, B2M, MIR222, ALB, PON1 |
| With which pathways do proteins interact that are associated with sleep-wake disorder? | Interleukin-1 processing, Pyroptosis, CLEC7A/inflammasome pathway, Interleukin-10 signaling, Interleukin-4 and Interleukin-13 signaling, Interleukin-1 signaling, Purinergic signaling in leishmaniasis infection, Opioid Signalling, Androgen biosynthesis, Glucocorticoid biosynthesis, G-protein activation, Peptide hormone biosynthesis, Endogenous sterols, Peptide ligand-binding receptors, G alpha (s) signalling events, G alpha (i) signalling events, Defective ACTH causes obesity and POMCD, FOXO-mediated transcription of oxidative stress, metabolic and neuronal genes, ADORA2B mediated anti-inflammatory cytokines production |
| With which pathways do proteins interact that are associated with sickle cell anemia? | Immunoregulatory interactions between a Lymphoid and a non-Lymphoid cell, Integrin cell surface interactions, Interleukin-4 and Interleukin-13 signaling, Interferon gamma signaling |
| What are phenotypes that gene POMC is associated with that also occur in neuromyelitis optica? | Ocular pain, Nausea |
| What are phenotypes that gene IFNG is associated with that also occur in neuromyelitis optica? | Nausea |
| What drugs should I take if I have a disease because of an exposure to Lead? | Methylprednisolone, Prednisone, Dalfampridine, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Betamethasone, Natalizumab, Teriflunomide, Ozanimod, Triamcinolone |
| What drugs should I take if I have a disease because of an exposure to Tobacco Smoke Pollution? | Methylprednisolone, Prednisone, Dalfampridine, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Betamethasone, Natalizumab, Teriflunomide, Ozanimod, Triamcinolone |
| What diseases are the diseases where Dalfampridine is contraindicated for related to? | brain disease |
| What diseases are the diseases where Morphine is contraindicated for related to? | multiple sclerosis, megalencephalic leukoencephalopathy with cysts, encephalopathy, acute, infection-induced, diabetic encephalopathy, hydrocephalus, brain compression, cerebral sarcoidosis, hepatic encephalopathy, visual pathway disease, central nervous system origin vertigo, cerebellar disease, olfactory nerve disease, thalamic disease, pituitary gland disease, disorder of optic chiasm, basal ganglia disease, epilepsy, mental disorder, subarachnoid hemorrhage (disease), central nervous system cyst (disease), migraine disorder, prion disease, delayed encephalopathy after acute carbon monoxide poisoning, cerebral malaria, akinetic mutism, Reye syndrome, brain edema, encephalomalacia, intracranial hypertension, intracranial hypotension, kernicterus, Wernicke encephalopathy, encephalopathy, recurrent, of childhood, progressive bulbar palsy, cerebrovascular disorder, disorder of medulla oblongata, brain inflammatory disease, narcolepsy-cataplexy syndrome, meningoencephalocele, cerebral sinovenous thrombosis, autoimmune encephalopathy with parasomnia and obstructive sleep apnea, neurometabolic disease, cerebral organic aciduria, narcolepsy without cataplexy, cerebral lipidosis with dementia, brain neoplasm, colpocephaly, corpus callosum agenesis of blepharophimosis robin type, corpus callosum dysgenesis X-linked recessive, corpus callosum dysgenesis cleft spasm, corpus callosum dysgenesis hypopituitarism, cerebral degeneration, brain injury, encephalopathy, cluster headache syndrome, cerebral cortex disease, midbrain disease, central nervous system disease |
| Which cellular components do the proteins an exposure to Lead affects interact with? | extracellular space, extracellular exosome, collagen-containing extracellular matrix, cell surface, plasma membrane, membrane, integral component of plasma membrane, external side of plasma membrane, membrane raft, focal adhesion, immunological synapse |
| Which cellular components do the proteins an exposure to Tobacco Smoke Pollution affects interact with? | extracellular space, extracellular region, cytosol, lysosome |
| What genes are associated with diseases that are linked to an exposure to Lead? | APOE, BCHE, CASP1, CBLB, CD6, CD40, CD58, CNR1, GC, HLA-DPB1, HLA-DQB1, HLA-DRA, HLA-DRB1, ICAM1, IRF8, IFNB1, IFNG, RBPJ, IL1B, IL1RN, IL2RA, IL7, IL7R, IL10, IL12A, IL17A, KCNJ10, MCAM, CLDN11, P2RX7, PDCD1, POMC, NECTIN2, SELE, SLC11A1, STAT4, TNFAIP3, TNFRSF1A, TYK2, VCAM1, VDR, TNFSF14, KIF1B, CLEC16A, NLRP3 |
| What genes are associated with diseases that are linked to an exposure to Mercury? | APOE, BCHE, CASP1, CBLB, CD6, CD40, CD58, CNR1, GC, HLA-DPB1, HLA-DQB1, HLA-DRA, HLA-DRB1, ICAM1, IRF8, IFNB1, IFNG, RBPJ, IL1B, IL1RN, IL2RA, IL7, IL7R, IL10, IL12A, IL17A, KCNJ10, MCAM, CLDN11, P2RX7, PDCD1, POMC, NECTIN2, SELE, SLC11A1, STAT4, TNFAIP3, TNFRSF1A, TYK2, VCAM1, VDR, TNFSF14, KIF1B, CLEC16A, NLRP3 |
| What side effects of the drug Methylprednisolone are similar to the multiple sclerosis phenotype? | Emotional lability, Paresthesia, Muscle Weakness, Paraplegia, Optic neuritis, Nausea |
| What side effects of the drug Prednisone are similar to the multiple sclerosis phenotype? | Paresthesia, Optic neuritis, Muscle weakness, Emotional lability, Nausea, Paraplegia |
| Which drug is contraindicated in a disease that was linked to an exposure to something that interacts with the protein IFNG? | Ascorbic acid, Zinc gluconate, Methylprednisolone, Prednisone, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Betamethasone, Triamcinolone |
| Which drug is contraindicated in a disease that was linked to an exposure to something that interacts with the protein IL1B? | Ascorbic acid, Zinc gluconate, Methylprednisolone, Prednisone, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Betamethasone, Triamcinolone |
| What pathways do the exposures that can lead to multiple sclerosis interact with? | Immunoregulatory interactions between a Lymphoid and a non-Lymphoid cell, Integrin cell surface interactions, Interleukin-10 signaling, Interleukin-4 and Interleukin-13 signaling, Interferon gamma signaling, Regulation of IFNG signaling, RUNX1 and FOXP3 control the development of regulatory T lymphocytes (Tregs), Gene and protein expression by JAK-STAT signaling after Interleukin-12 stimulation, Interleukin-1 processing, Pyroptosis, CLEC7A/inflammasome pathway, Interleukin-1 signaling, Purinergic signaling in leishmaniasis infection |
| What pathways do the exposures that can lead to atopic eczema interact with? | Immunoregulatory interactions between a Lymphoid and a non-Lymphoid cell, Integrin cell surface interactions, Interleukin-10 signaling, Interleukin-4 and Interleukin-13 signaling, Interferon gamma signaling |
| Which exposure can affect drugs that are approved for off-label-use for dermatitis? | Chlorpyrifos, glyphosate, Insecticides, Organophosphates, Pesticides, Lead, Tobacco Smoke Pollution |
| Which exposure can affect drugs that are approved for off-label-use for heart disease? | Chlorpyrifos, glyphosate, Insecticides, Organophosphates, Pesticides, Lead, Tobacco Smoke Pollution |
| Which drugs have synergistic interactions with drugs that are affected by proteins that CASP1 has protein–protein interactions with? | Methylprednisolone, Prednisone, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Zinc gluconate, Betamethasone, Natalizumab, Teriflunomide, Ozanimod, Triamcinolone |
| Which drugs have synergistic interactions with drugs that are affected by proteins that IL1B has protein–protein interactions with? | Methylprednisolone, Prednisone, Dalfampridine, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Zinc gluconate, Betamethasone, Triamcinolone |
| Which biological processes are affected by the gene APOE which are also affected by an exposure to something that is linked to multiple sclerosis? | cholesterol homeostasis, triglyceride metabolic process, cholesterol metabolic process, gene expression |
| Which biological processes are affected by the gene IL1B which are also affected by an exposure to something that is linked to multiple sclerosis? | inflammatory response, immune response |
| What drugs should I not take for a disease that I got because exposure to Tobacco Smoke Pollution interacts with a protein relevant to that disease? | Ascorbic acid, Zinc gluconate, Methylprednisolone, Prednisone, Dalfampridine, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Betamethasone, Ozanimod, Triamcinolone, Tolvaptan, Nelarabine |
| What drugs should I not take for a disease that I got because exposure to Lead interacts with a protein relevant to that disease? | Ascorbic acid, Zinc gluconate, Methylprednisolone, Prednisone, Prednisolone, Hydrocortisone, Cortisone acetate, Hydrocortisone acetate, Dexamethasone, Betamethasone, Ozanimod, Triamcinolone, Tolvaptan, Nelarabine |
| What side effects does Prednisone have that also occur when a protein is expressed that is influenced by exposure to Tobacco Smoke Pollution? | Memory impairment, Fever, Leukocytosis, Lethargy, Cardiomegaly, Nausea, Seizure, Vomiting |
| What side effects does Dexamethasone have that also occur when a protein is expressed that is influenced by exposure to Tobacco Smoke Pollution? | Fever, Leukocytosis, Lethargy, Cardiomegaly, Nausea, Seizure, Vomiting |
| What drugs can I take that are indicated for a disease whose phenotype is associated with the gene POMC? | Eculizumab |
| What drugs can I take that are indicated for a disease whose phenotype is associated with the gene IFNG? | Eculizumab |
| What drugs can I take that are approved for off-label-use for a disease that I got because exposure to Tobacco Smoke Pollution interacts with a protein relevant to that disease? | Methylprednisolone, Prednisone, Prednisolone, Hydrocortisone, Cortisone acetate, Dexamethasone, Betamethasone, Triamcinolone |
| What drugs can I take that are approved for off-label-use for a disease that I got because exposure to Particulate Matter interacts with a protein relevant to that disease? | Methylprednisolone, Prednisone, Prednisolone, Hydrocortisone, Cortisone acetate, Dexamethasone, Betamethasone, Triamcinolone |
Appendix C. Paraphrased Questions
Table A3.
Original questions and paraphrases.
Table A3.
Original questions and paraphrases.
| Question | Paraphrase |
|---|---|
| What are the names of the drugs that are contraindicated when a patient has multiple sclerosis? | Which medications are contraindicated for patients with multiple sclerosis? |
| Which drugs are contraindicated when I have dermatitis? | Which medications are contraindicated for patients with dermatitis? |
| Which drugs cause Alkalosis as a side effect? | Which medications list Alkalosis as an adverse effect? |
| Which drugs have Anxiety as side effect? | Which medications list Anxiety as a side effect? |
| Which genes are expressed in the eye? | Which genes show expression in the eye? |
| What genes are expressed in the nasopharynx? | Which genes show expression in the nasopharynx? |
| What proteins interact with GRB2? | Which proteins interact with GRB2? |
| What proteins interact with the protein KPNA2? | Which proteins interact with KPNA2? |
| What are off-label uses of Zinc gluconate? | Which off-label indications are reported for Zinc gluconate? |
| What are off-label uses for Ascorbic acid? | Which off-label indications are reported for Ascorbic acid? |
| In which cellular components is a protein expressed that is associated with the Spasticity phenotype? | Which cellular components show expression of the protein associated with Spasticity? |
| In which cellular components is a protein expressed that is associated with Nausea? | Which cellular components show expression of the protein associated with Nausea? |
| What side effects does a drug have that is indicated for Richter syndrome? | What adverse effects are associated with a drug indicated for Richter syndrome? |
| If I take drugs for dry eye syndrome, what side effects will they have? | What adverse effects occur with medications used to treat dry eye syndrome? |
| In what anatomical structures is there no expression of proteins that interact with leukocyte migration? | Which anatomical structures lack expression of proteins that interact with leukocyte migration? |
| In what anatomical structures is there no expression of proteins that interact with cell migration? | Which anatomical structures lack expression of proteins that interact with cell migration? |
| What genes and biological processes does an exposure to Tobacco Smoke Pollution interact with? | Which genes and biological processes interact with exposure to Tobacco Smoke Pollution? |
| What genes and biological processes does an exposure to Lead interact with? | Which genes and biological processes interact with Lead exposure? |
| With which pathways do proteins interact that are associated with sleep-wake disorder? | Which pathways do proteins associated with sleep-wake disorder interact with? |
| With which pathways do proteins interact that are associated with sickle cell anemia? | Which pathways do proteins associated with sickle cell anemia interact with? |
| What are phenotypes that gene POMC is associated with that also occur in neuromyelitis optica? | Which phenotypes linked to POMC also occur in neuromyelitis optica? |
| What are phenotypes that gene IFNG is associated with that also occur in neuromyelitis optica? | Which phenotypes linked to the gene IFNG also occur in neuromyelitis optica? |
| What drugs should I take if I have a disease because of an exposure to Lead? | Which medications are indicated for a disease caused by Lead exposure? |
| What drugs should I take if I have a disease because of an exposure to Tobacco Smoke Pollution? | Which medications are indicated for a disease caused by Tobacco Smoke Pollution exposure? |
| What diseases are the diseases where Dalfampridine is contraindicated for related to? | Which diseases are related to the diseases for which Dalfampridine is contraindicated? |
| What diseases are the diseases where Morphine is contraindicated for related to? | Which diseases are related to the diseases for which Morphine is contraindicated? |
| Which cellular components do the proteins an exposure to Lead affects interact with? | Which cellular components do proteins affected by Lead exposure interact with? |
| Which cellular components do the proteins an exposure to Tobacco Smoke Pollution affects interact with? | Which cellular components do proteins affected by Tobacco Smoke Pollution exposure interact with? |
| What genes are associated with diseases that are linked to an exposure to Lead? | Which genes are associated with diseases linked to Lead exposure? |
| What genes are associated with diseases that are linked to an exposure to Mercury? | Which genes are associated with diseases linked to Mercury exposure? |
| What side effects of the drug Methylprednisolone are similar to the multiple sclerosis phenotype? | Which adverse effects of Methylprednisolone overlap with multiple sclerosis phenotypes? |
| What side effects of the drug Prednisone are similar to the multiple sclerosis phenotype? | Which adverse effects of Prednisone overlap with multiple sclerosis phenotypes? |
| Which drug is contraindicated in a disease that was linked to an exposure to something that interacts with the protein IFNG? | Which drug should be avoided for a disease linked to an exposure that interacts with the protein IFNG? |
| Which drug is contraindicated in a disease that was linked to an exposure to something that interacts with the protein IL1B? | Which drug should be avoided for a disease linked to an exposure that interacts with IL1B? |
| What pathways do the exposures that can lead to multiple sclerosis interact with? | Which pathways are modulated by exposures associated with multiple sclerosis? |
| What pathways do the exposures that can lead to atopic eczema interact with? | Which pathways are modulated by exposures associated with atopic eczema? |
| Which exposure can affect drugs that are approved for off-label-use for dermatitis? | Which exposure can modify the response to off-label dermatitis medications? |
| Which exposure can affect drugs that are approved for off-label-use for heart disease? | Which exposure can modify the response to off-label heart disease medications? |
| Which drugs have synergistic interactions with drugs that are affected by proteins that CASP1 has protein–protein interactions with? | Which agents show synergy with drugs affected by CASP1-interacting proteins? |
| Which drugs have synergistic interactions with drugs that are affected by proteins that IL1B has protein–protein interactions with? | Which agents show synergy with drugs affected by IL1B-interacting proteins? |
| Which biological processes are affected by the gene APOE which are also affected by an exposure to something that is linked to multiple sclerosis? | Which processes regulated by the gene APOE are likewise affected by exposures associated with multiple sclerosis? |
| Which biological processes are affected by the gene IL1B which are also affected by an exposure to something that is linked to multiple sclerosis? | Which processes regulated by the gene IL1B are likewise affected by exposures associated with multiple sclerosis? |
| What drugs should I not take for a disease that I got because exposure to Tobacco Smoke Pollution interacts with a protein relevant to that disease? | Which medications should I avoid for a disease that arose because exposure to Tobacco Smoke Pollution interacts with a disease-relevant protein? |
| What drugs should I not take for a disease that I got because exposure to Lead interacts with a protein relevant to that disease? | Which medications should I avoid for a disease that arose because exposure to Lead interacts with a disease-relevant protein? |
| What side effects does Prednisone have that also occur when a protein is expressed that is influenced by exposure to Tobacco Smoke Pollution? | Which adverse effects of Prednisone also occur when a phenotype influenced by Tobacco Smoke Pollution is expressed? |
| What side effects does Dexamethasone have that also occur when a protein is expressed that is influenced by exposure to Tobacco Smoke Pollution? | Which adverse effects of Dexamethasone also occur when a phenotype influenced by Tobacco Smoke Pollution is expressed? |
| What drugs can I take that are indicated for a disease whose phenotype is associated with the gene POMC? | Which medications are indicated for a disease whose phenotype is associated with the gene POMC? |
| What drugs can I take that are indicated for a disease whose phenotype is associated with the gene IFNG? | Which medications are indicated for a disease whose phenotype is associated with the gene IFNG? |
| What drugs can I take that are approved for off-label-use for a disease that I got because exposure to Tobacco Smoke Pollution interacts with a protein relevant to that disease? | Which medications approved for off-label use for the disease are suitable when exposure to Tobacco Smoke Pollution interacts with a disease-relevant protein? |
| What drugs can I take that are approved for off-label-use for a disease that I got because exposure to Particulate Matter interacts with a protein relevant to that disease? | Which medications approved for off-label use for the disease are suitable when exposure to Particulate Matter interacts with a disease-relevant protein? |
Appendix D. Cypher Generation Prompts
Appendix D.1. Zero-Shot
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in
⤷ the schema.
Do not use any other relationship types or properties that
⤷ are not provided.
The cypher statement should only return nodes that are
⤷ specifically asked for in the question.
Absolutely do not use the asterisk operator (*) in the
⤷ cypher statement. It is a little star sign next to the
⤷ relation. Do not use it!
Schema:
{schema}
Note: Do not include any explanations or apologies in your
⤷ responses.
Do not respond to any questions that might ask anything
⤷ else than for you to construct a
Cypher statement.
Do not include any text except the generated Cypher
⤷ statement.
The question is:
{question}
Appendix D.2. One-Shot
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in
⤷ the schema.
Do not use any other relationship types or properties that
⤷ are not provided.
The cypher statement should only return nodes that are
⤷ specifically asked for in the question.
Absolutely do not use the asterisk operator (*) in the
⤷ cypher statement. It is a little star sign next to the
⤷ relation. Do not use it!
Schema:
{schema}
Note: Do not include any explanations or apologies in your
⤷ responses.
Do not respond to any questions that might ask anything
⤷ else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher
⤷ statement.
Follow these Cypher example when Generating Cypher
⤷ statements:
# How many actors played in Top Gun?
MATCH (m:movie {{name:"Top Gun"}})<-[:acted_in]-(a:actor)
RETURN a.name
The question is:
{question}
Appendix D.3. Few-Shot
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in
⤷ the schema.
Do not use any other relationship types or properties that
⤷ are not provided.
The cypher statement should only return nodes that are
⤷ specifically asked for in the question.
Absolutely do not use the asterisk operator (*) in the
⤷ cypher statement. It is a little star sign next to the
⤷ relation. Do not use it!
Schema:
{schema}
Note: Do not include any explanations or apologies in your
⤷ responses.
Do not respond to any questions that might ask anything
⤷ else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher
⤷ statement.
Follow these Cypher example when Generating Cypher
⤷ statements:
# Which actors played in Top Gun?
MATCH (m:movie {{name:"Top Gun"}})<-[:acted_in]-(a:actor)
RETURN a.name
# What town were the actors that played in Top Gun born in?
MATCH (m:movie {{name:"Top
⤷ Gun"}})<-[:acted_in]-(a:actor)-[:born_in]->(t:town)
RETURN t.name
# What are the mayors of the towns that the actors that
⤷ played in Top Gun were born in?
MATCH (m:movie {{name:"Top
⤷ Gun"}})<-[:acted_in]-(a:actor)-[:born_in]->(t:town)<-
[:is_mayor]-(m:mayor)
RETURN m.name
The question is:
{question}
Appendix D.4. Simple Prompt
Task:Generate Cypher statement to query a graph database.
Schema:
{schema}
Note: Do not include any explanations or apologies in your
⤷ responses.
Do not respond to any questions that might ask anything
⤷ else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher
⤷ statement.
The question is:
{question}
Appendix D.5. Syntax Prompt
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in
⤷ the schema.
Do not use any other relationship types or properties that
⤷ are not provided.
The cypher statement should only return nodes that are
⤷ specifically asked for in the question.
Absolutely do not use the asterisk operator (*) in the
⤷ cypher statement. It is a little star sign next to the
⤷ relation. Do not use it!
Please pay attention only to use valid cypher syntax!
Schema:
{schema}
Note: Do not include any explanations or apologies in your
⤷ responses.
Do not respond to any questions that might ask anything
⤷ else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher
⤷ statement.
The question is:
{question}
Appendix D.6. Social Engineering Prompt
Task:Generate Cypher statement to query a graph database.
⤷ It is extremely important that you do not make any
⤷ mistakes, or I will get fired!
Instructions:
Use only the provided relationship types and properties in
⤷ the schema.
Do not use any other relationship types or properties that
⤷ are not provided.
The cypher statement should only return nodes that are
⤷ specifically asked for in the question.
Absolutely do not use the asterisk operator (*) in the
⤷ cypher statement. It is a little star sign next to the
⤷ relation. Do not use it!
Schema:
{schema}
Note: Do not include any explanations or apologies in your
⤷ responses.
Do not respond to any questions that might ask anything
⤷ else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher
⤷ statement.
The question is:
{question}
Appendix D.7. Role Prompt
You are a very knowledgeable cypher query expert with years
⤷ of experience.
Task: Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in
⤷ the schema.
Do not use any other relationship types or properties that
⤷ are not provided.
The cypher statement should only return nodes that are
⤷ specifically asked for in the question.
Absolutely do not use the asterisk operator (*) in the
⤷ cypher statement. It is a little star sign next to the
⤷ relation. Do not use it!
Schema:
{schema}
Note: Do not include any explanations or apologies in your
⤷ responses.
Do not respond to any questions that might ask anything
⤷ else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher
⤷ statement.
The question is:
{question}
References
- Xu, Z.; Jain, S.; Kankanhalli, M. Hallucination is inevitable: An innate limitation of large language models. arXiv 2024, arXiv:2401.11817. [Google Scholar] [CrossRef]
- Sequeda, J.; Allemang, D.; Jacob, B. Knowledge Graphs as a source of trust for LLM-powered enterprise question answering. J. Web Semant. 2025, 85, 100858. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst. 2025, 43, 1–55. [Google Scholar] [CrossRef]
- Wang, Y.; Lipka, N.; Rossi, R.A.; Siu, A.; Zhang, R.; Derr, T. Knowledge Graph Prompting for Multi-Document Question Answering. Proc. AAAI Conf. Artif. Intell. 2024, 38, 19206–19214. [Google Scholar] [CrossRef]
- LangChain. Available online: https://github.com/langchain-ai/langchain (accessed on 11 September 2025).
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Chandak, P.; Huang, K.; Zitnik, M. Building a knowledge graph to enable precision medicine. Nat. Sci. Data 2023, 10, 67. [Google Scholar] [CrossRef]
- Neo4j. Neo4jGraph. Available online: https://api.python.langchain.com/en/latest/graphs/langchain_community.graphs.neo4j_graph.Neo4jGraph.html (accessed on 11 September 2025).
- LangChain. LangChain Expression Language (LCEL). Available online: https://python.langchain.com/v0.1/docs/expression_language/ (accessed on 11 September 2025).
- Liu, H.; Li, C.; Li, Y.; Lee, Y.J. Improved Baselines with Visual Instruction Tuning. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2023. [Google Scholar]
- Hartford, E.; Atkins, L.; Fernandes, F.; Cognitive Computations. Dolphin Llama 3. Available online: https://huggingface.co/dphn/dolphin-2.9-llama3-8b (accessed on 11 September 2025).
- Malartic, Q.; Chowdhury, N.R.; Cojocaru, R.; Farooq, M.; Campesan, G.; Djilali, Y.A.D.; Narayan, S.; Singh, A.; Velikanov, M.; Boussaha, B.E.A.; et al. Falcon2-11B Technical Report. arXiv 2024, arXiv:2407.14885. [Google Scholar] [CrossRef]
- Gemma Team, T.M.; Hardin, C.; Dadashi, R.; Bhupatiraju, S.; Sifre, L.; Rivière, M.; Kale, M.S.; Love, J.; Tafti, P.; Hussenot, L.; et al. Gemma. 2024. Available online: https://www.kaggle.com/models/google/gemma (accessed on 15 October 2025).
- Alpindale. Goliath. Available online: https://huggingface.co/alpindale/goliath-120b (accessed on 11 September 2025).
- OpenAI. GPT-4 Technical Report. 2023. Available online: https://openai.com/research/gpt-4 (accessed on 11 September 2025).
- OpenAI. Introducing GPT-4 Turbo. 2023. Available online: https://openai.com/product/gpt-4 (accessed on 11 September 2025).
- OpenAI. Introducing GPT-5, 7 August 2025. Available online: https://openai.com/index/introducing-gpt-5/ (accessed on 31 October 2025).
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Liu, Z.; Ping, W.; Roy, R.; Xu, P.; Lee, C.; Shoeybi, M.; Catanzaro, B. ChatQA: Surpassing GPT-4 on Conversational QA and RAG. arXiv 2024, arXiv:2401.10225. [Google Scholar]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar] [CrossRef]
- Meta AI. Llama 3.3 70B Instruct - Model Card, 6 December 2024. Available online: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct (accessed on 31 October 2025).
- llSourcell. medllama2. Available online: https://huggingface.co/llSourcell/medllama2_7b (accessed on 11 September 2025).
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar] [CrossRef]
- Jiang, A.Q.; Sablayrolles, A.; Roux, A.; Mensch, A.; Savary, B.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Hanna, E.B.; Bressand, F.; et al. Mixtral of experts. arXiv 2024, arXiv:2401.04088. [Google Scholar] [CrossRef]
- Pankajmathur. orca mini 70b. Available online: https://huggingface.co/pankajmathur/orca_mini_v3_70b (accessed on 11 September 2025).
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen Technical Report. arXiv 2023, arXiv:2309.16609. [Google Scholar] [CrossRef]
- Zhu, B.; Frick, E.; Wu, T.; Zhu, H.; Ganesan, K.; Chiang, W.-L.; Zhang, J.; Jiao, J. Starling-7B: Improving helpfulness and harmlessness with RLAIF. In Proceedings of the First Conference on Language Modeling, Philadelphia, PA, USA, 7–9 October 2024. [Google Scholar]
- Lmsys. vicuna-33b. Available online: https://huggingface.co/lmsys/vicuna-33b-v1.3 (accessed on 11 September 2025).
- Xu, C.; Sun, Q.; Zheng, K.; Geng, X.; Zhao, P.; Feng, J.; Tao, C.; Jiang, D. Wizardlm: Empowering large language models to follow complex instructions. arXiv 2023, arXiv:2304.12244. [Google Scholar] [CrossRef]
- LangChain. Neo4j DB QA Chain. 2025. Available online: https://python.langchain.com/docs/tutorials/graph/ (accessed on 11 September 2025).
- Streamlit. Available online: https://streamlit.io/ (accessed on 11 September 2025).
- Neo4j. Available online: https://neo4j.com (accessed on 11 September 2025).
- Ollama. Available online: https://ollama.com/ (accessed on 11 September 2025).
- Wang, R.; Zhang, Z.; Rossetto, L.; Ruosch, F.; Bernstein, A. NLQxform: A Language Model-based Question to SPARQL Transformer. arXiv 2023, arXiv:2311.07588. [Google Scholar] [CrossRef]
- Luo, H.; E, H.; Tang, Z.; Peng, S.; Guo, Y.; Zhang, W.; Ma, C.; Dong, G.; Song, M.; Lin, W.; et al. Chatkbqa: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models. arXiv 2023, arXiv:2310.08975. [Google Scholar]
- Zahera, H.M.; Ali, M.; Sherif, M.A.; Moussallem, D.; Ngomo, A.C.N. Generating sparql from natural language using chain-of-thoughts prompting. In Proceedings of the SEMANTICS 2024, Amsterdam, The Netherlands, 17–19 September 2024. [Google Scholar]
- Avila, C.V.S.; Casanova, M.A.; Vidal, V.M. A Framework for Question Answering on Knowledge Graphs Using Large Language Models. In Proceedings of the European Semantic Web Conference (ESWC), Hersonissos, Greece, 26–30 May 2024. [Google Scholar]
- Perez-Beltrachini, L.; Jain, P.; Monti, E.; Lapata, M. Semantic parsing for conversational question answering over knowledge graphs. arXiv 2023, arXiv:2301.12217. [Google Scholar] [CrossRef]
- Agarwal, D.; Das, R.; Khosla, S.; Gangadharaiah, R. Bring your own kg: Self-supervised program synthesis for zero-shot kgqa. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, 16–21 June 2024; pp. 896–919. [Google Scholar]
- Pliukhin, D.; Radyush, D.; Kovriguina, L.; Mouromtsev, D. Improving Subgraph Extraction Algorithms for One-Shot SPARQL Query Generation with Large Language Models. In Proceedings of the QALD/SemREC@ ISWC, Athens, Greece, 6–10 November 2023. [Google Scholar]
- Soman, K.; Rose, P.W.; Morris, J.H.; Akbas, R.E.; Smith, B.; Peetoom, B.; Villouta-Reyes, C.; Cerono, G.; Shi, Y.; Rizk-Jackson, A.; et al. Biomedical knowledge graph-optimized prompt generation for large language models. Bioinformatics 2024, 40, btae560. [Google Scholar] [CrossRef]
- Morris, J.H.; Soman, K.; Akbas, R.E.; Zhou, X.; Smith, B.; Meng, E.C.; Huang, C.C.; Cerono, G.; Schenk, G.; Rizk-Jackson, A.; et al. The scalable precision medicine open knowledge engine (SPOKE): A massive knowledge graph of biomedical information. Bioinformatics 2023, 39, btad080. [Google Scholar] [CrossRef]
- Steinigen, D.; Teucher, R.; Ruland, T.H.; Rudat, M.; Flores-Herr, N.; Fischer, P.; Milosevic, N.; Schymura, C.; Ziletti, A. Fact Finder–Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs. arXiv 2024, arXiv:2408.03010. [Google Scholar]
- Jia, R.; Zhang, B.; Méndez, S.J.R.; Omran, P.G. Leveraging Large Language Models for Semantic Query Processing in a Scholarly Knowledge Graph. arXiv 2024, arXiv:2405.15374. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).