


Analytics 2026, 5(3), 25; https://doi.org/10.3390/analytics5030025 - 28 Jul 2026
Abstract
►
Show Figures
Text-to-Cypher generator systems translate natural language questions into Cypher queries, enabling intuitive interactions with graph databases such as Neo4j and Amazon Neptune. Despite recent advancements in LLM-based Cypher query generation, the vulnerabilities of the known methods—such as prompt injection attacks—are not discussed in
[...] Read more.
Text-to-Cypher generator systems translate natural language questions into Cypher queries, enabling intuitive interactions with graph databases such as Neo4j and Amazon Neptune. Despite recent advancements in LLM-based Cypher query generation, the vulnerabilities of the known methods—such as prompt injection attacks—are not discussed in detail. In this paper, we employ a robust Retrieval-Augmented Generation (RAG) architecture tailored specifically for text-to-Cypher tasks, leveraging dense vector retrieval to enhance query generation accuracy. We propose a dynamic and self-corrective procedure with feedback-loop-based AI architecture with Large Language Models (LLMs) for near real-time validation and correction of generated queries. We create a systematic procedure for generating datasets specifically designed to assess prompt injection robustness. Comprehensive evaluations are conducted using a diverse set of LLMs, including GPT-4o, DeepSeek R1, Claude 3.5 Sonnet and Qwen 2.5 Coder 32B Instruct. Our evaluation results indicate substantial improvements in resiliency against prompt injection attacks compared to various benchmarks. It is demonstrated that the proposed solution outperforms various training-free prompt injection defense methods.
Full article

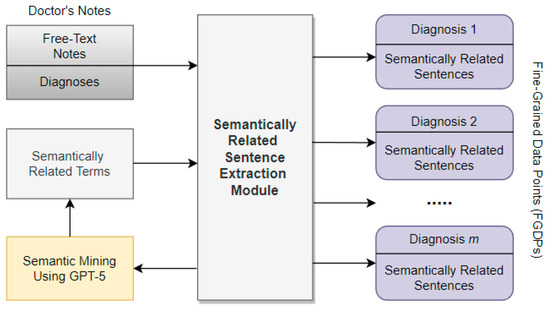
Figure 1






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}