
The Classical Model of Type-Token Systems Compared with Items from the Standardized Project Gutenberg Corpus


Abstract
1. Introduction
2. Related Work
2.1. The Classical Model
2.2. Critiques of and Alternatives to the Classical Model
3. Materials and Methods
- To eliminate document length as an interfering variable, all items with less than 100,000 word tokens are rejected. The remainder are trimmed to exactly 100,000 tokens each.
- The item PG4656 Checkmates for Four Pieces by W.B. Fishburne is removed. (This consists almost entirely of chess notation, which is not amenable to iterative process of optimising Maximum Likelihood).
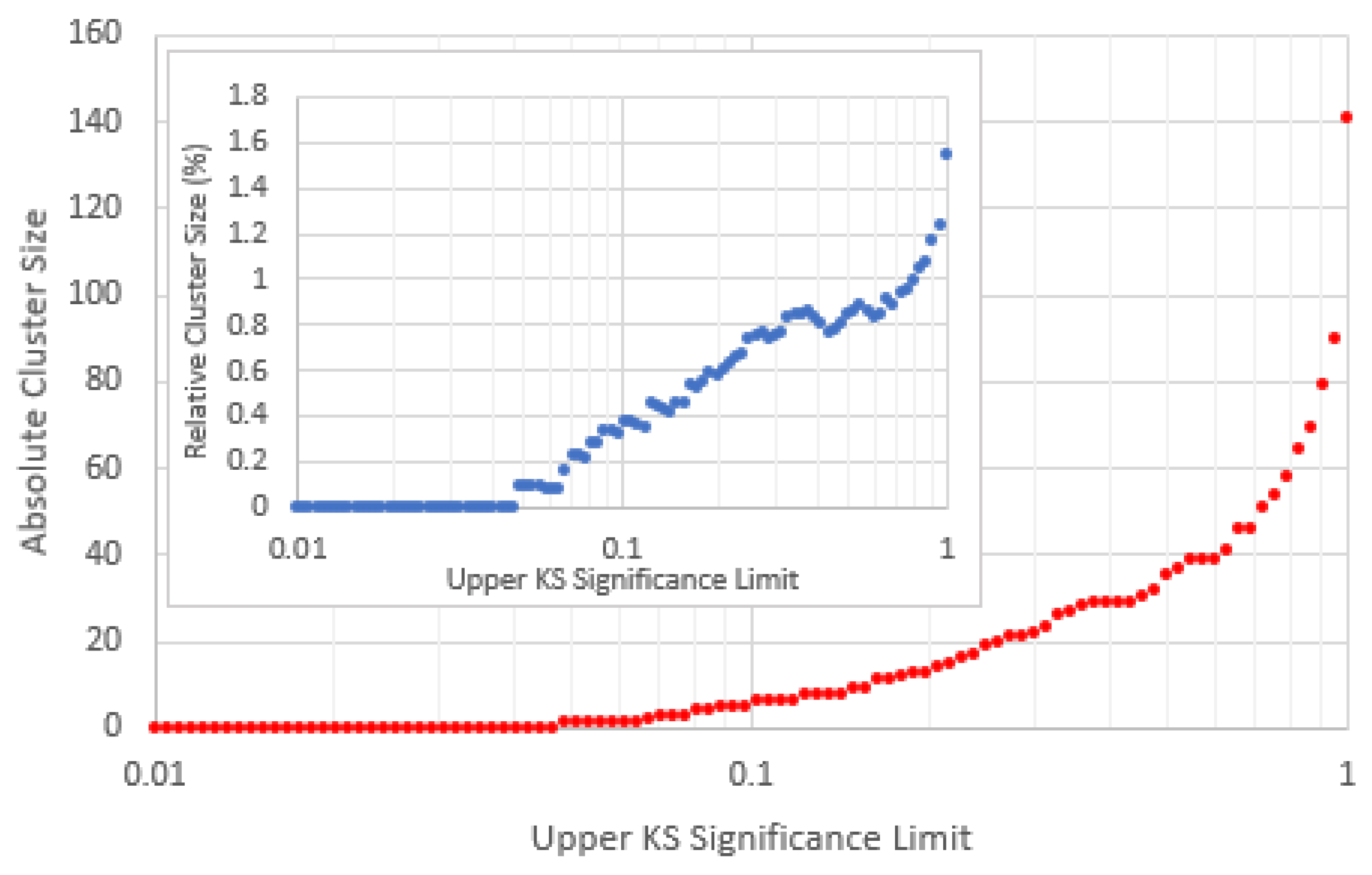
- While most of the remaining data follow a clear “main sequence” (a term we borrow from star classification [35]), anomalies still exist in the data. To classify these consistently we define where is a Gaussian “support” function with standard deviation and is the Zipf index computed for item over the frequency range ( in this case being 7). For item , the average support from the other items , where is the total number of items.
- If (where is some arbitrary threshold) then item is classified as anomalous.
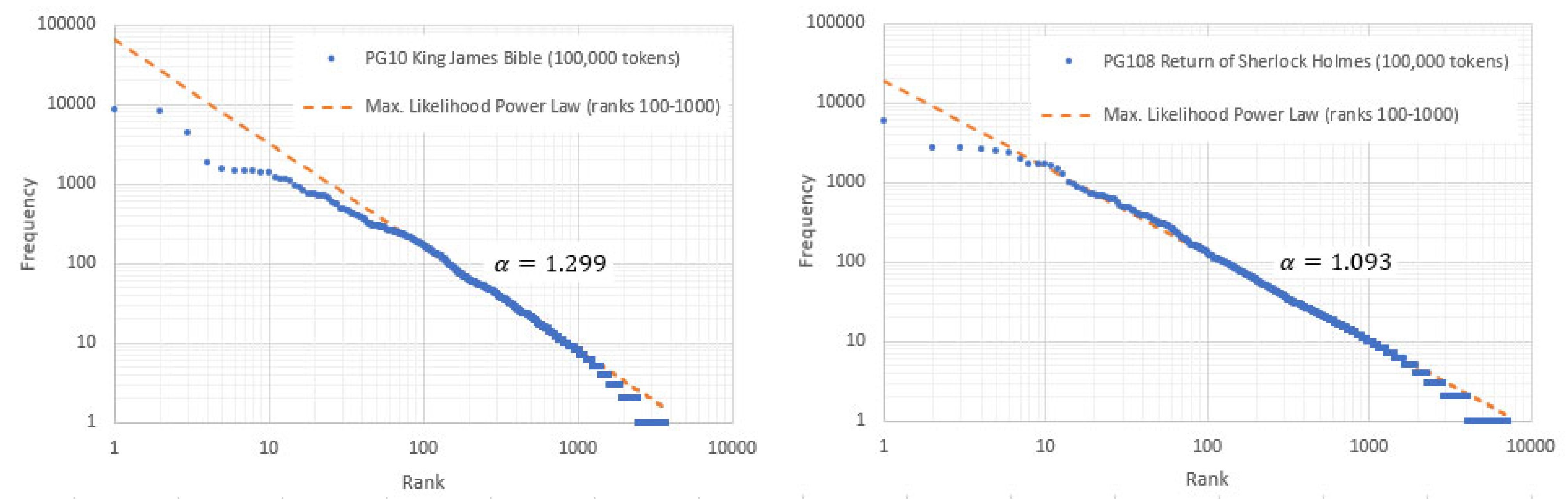
4. Observations on the Zipf Indices
5. Zipf Indices in the Middle Range
6. Alpha vs. Beta
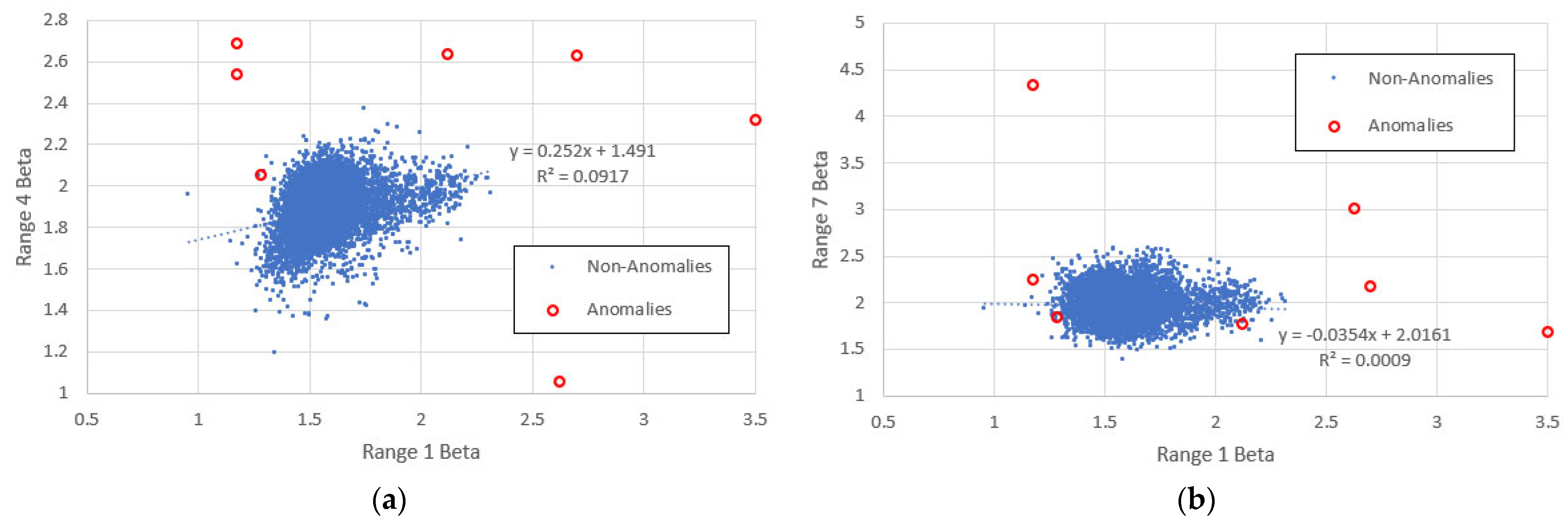
- For the low frequency ranges, the correlation coefficient magnitude is very low. It rises close to unity for range 6, where the frequencies correspond roughly to the middle range ranks across which was computed. It then falls again in range 7.
- Agreement with (4) generally improves as the frequencies increase, the best fit being for range 5. Here, items with higher KS-significance are distributed almost symmetrically around the theoretical line, while items with lower KS-significance exist in separate clusters above and below. There is a hint of this behaviour for ranges 4 and 7, though it is curiously absent for range 6.
- For range 1 (and to a lesser extent 2), there is a distinct cluster of high- points, also characterised by a narrower -range than the main population. These points are numerically quite close to the theoretical curve, though they show no obvious indication of following it. Nearly all these items belong to the high KS-significance group and nearly all of them are Finnish (Finnish items appearing almost nowhere else); we therefore refer to this feature as the “Finnish cluster”. The main cluster centred around is dominated by English items.
- For range 5, there is a distinct “filament” of data points exhibiting low , all of which belong to the low KS-significance group. These include many editions of the CIA World Factbook and other works of reference. Since these clearly are not typical linguistic texts, they are of secondary importance to our study.
6.1. The “Finnish Cluster”
6.2. The Middle Range and the “Low Beta Filament”
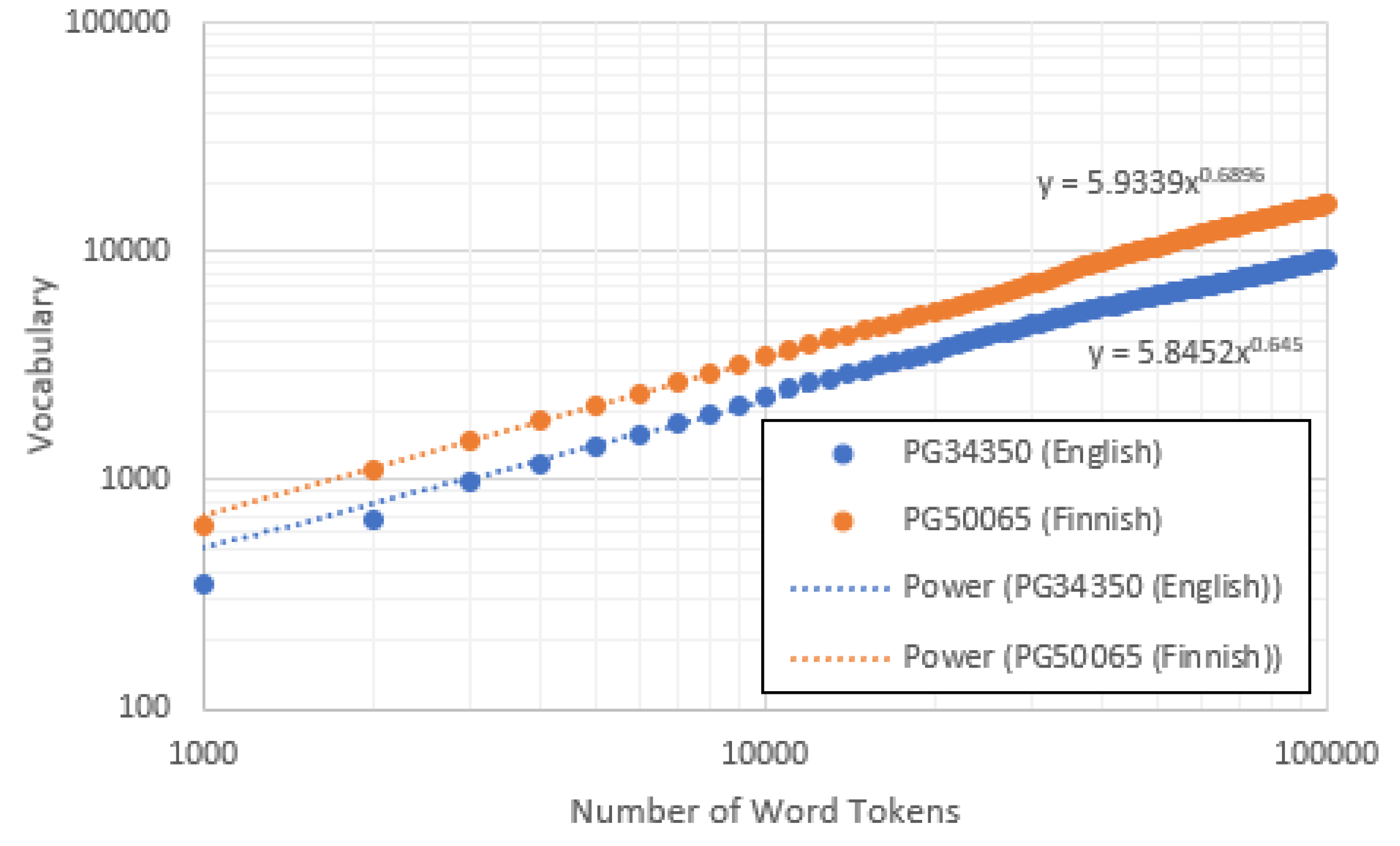
7. Vocabulary Growth and Heaps’ Law
- Generate and as independent Gaussian random variables subject to the constraint , thus ensuring a minimum log–log convexity of vs. . The chosen mean values are 1.9 and 1.6, respectively (roughly the middle values for ranges 1 and 7, see Figure 10) and both standard deviations are 0.15.
- Compute the corresponding -indices, and .
- Use (11) to compute the profile of using 100 steps of 1000 tokens. (The transitional rank is set to 1000, this being the upper limit of the middle range as defined in Section 5).
- Compute the optimal value of in (3) to fit this profile by minimising the mean square error.
- Repeat these four steps 500 times and plot optimised vs. and .
8. Discussions and Conclusions
- Outlying items identified in the -data are nearly all dictionaries, while items with the highest support are dominated by religious works.
- Although wide statistical variations exist, the average index generally increases with increasing frequency, corresponding to a log–log convexity of the types vs. frequency distribution.
- The indices measured for closely overlapping frequency ranges show a strong positive correlation, while those for frequency ranges widely separated show a weak negative correlation. (For example, if is above average in the frequency range 1 to 10, then it is likely to be below average in the range 64–640),
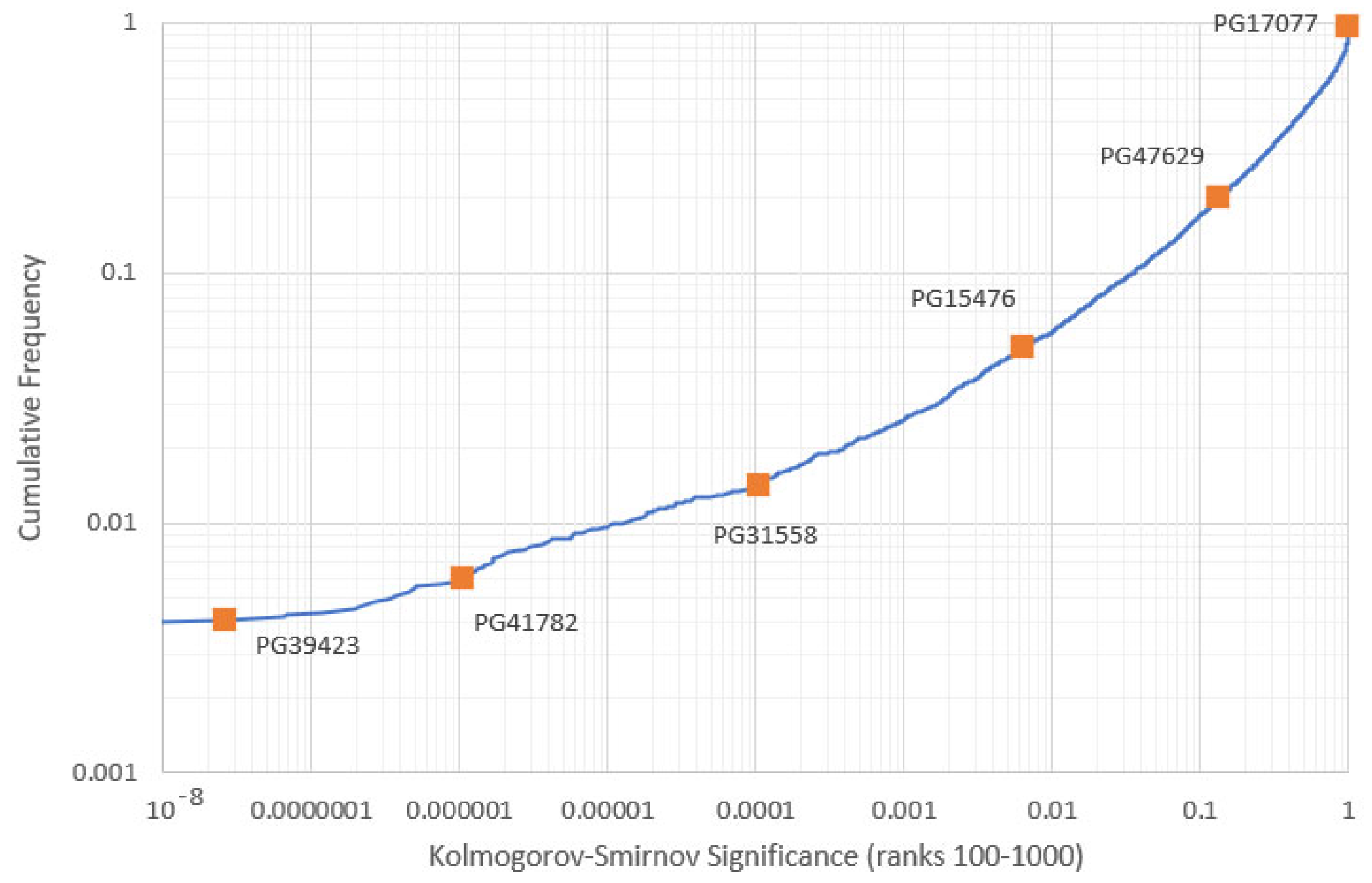
- Adherence to Zipf’s first law across the middle range (defined as the interval between ranks 100 to 1000 inclusive) may be characterised by the Kolmogorov–Smirnov (KS) significance.
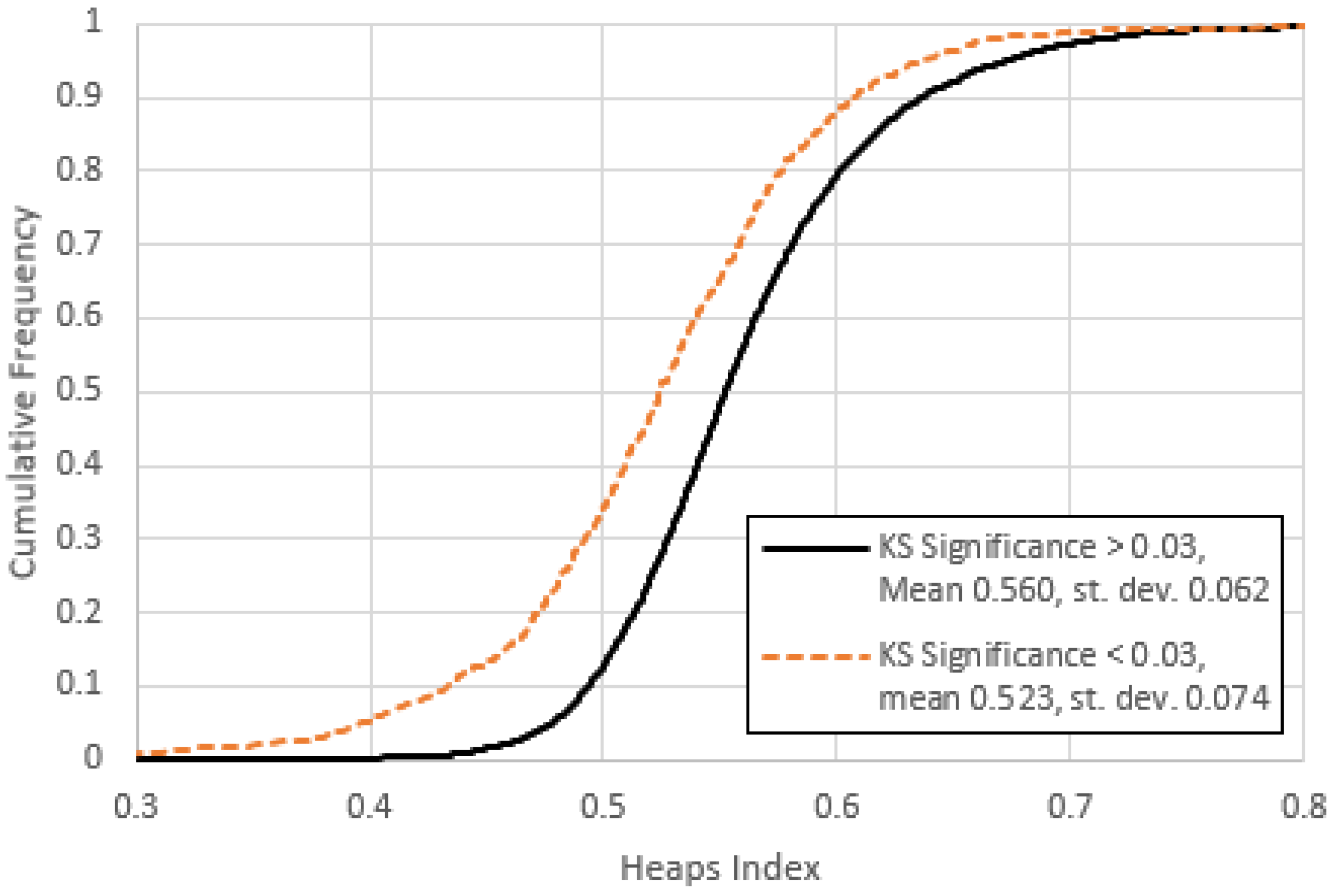
- When the frequency range used to compute corresponds roughly to the previously defined middle range, the points roughly follow the classical Equation (4). Of these, items with the highest KS-significance follow the equation most closely (Figure 12).
- Two notably anomalous phenomena appear in the plots of Firstly, for range 1 (frequencies 1 to 10), there exists a distinct secondary cluster of points, all with high and all of which have high KS-significance (>0.048). Nearly all of these are Finnish, and Finnish items appear almost nowhere outside this cluster. Secondly, for frequencies corresponding to the middle range, we note a “filament” of low- points, all of which have especially low KS-significance (). All of the latter are reference books.
- For the lowest frequency range, the index correlates strongly with the optimised Heaps’ index in a manner roughly consistent with Equation (6). (The Finnish items noted in point 6 are an exception.) This correlation gradually disappears as the frequencies increase.
- A simplified model based upon an abrupt change in and between high and low frequencies (to create a convex distribution) reproduces the basic features observed in the data. We note that the Heaps’ index is largely dependent on the statistics of the lowest-frequency types and is affected only weakly by the high frequency indices.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mora, C.; Tittensor, D.P.; Adl, S.; Simpson, A.G.B.; Worm, B. How Many Species are there on Earth and in the Ocean? PLoS Biol. 2011, 9, e1001127. [Google Scholar] [CrossRef] [PubMed]
- Costello, M.; Wilson, S.; Houlding, B. Predicting Total Global Species Richness using Rates of Species Description and Esitmates of Taxonomic Effort. Syst. Biol. 2012, 61, 871–883. [Google Scholar] [CrossRef] [PubMed]
- de Marzo, G.; Labini, D.; Pietronero, L. Zipf’s Law for Cosmic Structures: How Large are the Greatest Structures in the Universe? Astron. Astrophys. 2021, 651, A114. [Google Scholar] [CrossRef]
- Dodd, J.; Letts, P. Types, Tokens, and Talk about Musical Works. J. Aesthet. Art Crit. 2017, 75, 249–1963. [Google Scholar] [CrossRef]
- Hatton, L. Power-Law Distributions of Component Size in General Software Systems. IEEE Trans. Softw. Eng. 2009, 35, 566–572. [Google Scholar] [CrossRef]
- Linders, G.; Louwerse, M. Zipf’s Law Revisited: Spoken Dialog, Linguistic Units, Parameters and the Princip. Psychon. Bull. Rev. 2023, 30, 77–101. [Google Scholar] [CrossRef]
- Zipf, G. The Unity of Nature, Least-Action, and Natural Social Science. Sociometry 1942, 5, 48–62. [Google Scholar] [CrossRef]
- Zipf, G. Human Behaviour and the Principle of Least Effort; Addison-Wesley: Cambridge, MA, USA, 1949. [Google Scholar]
- Mandelbrot, B. An informational theory of the statistical structure of language. In Communication Theory; Jackson, W., Ed.; Butterworths Scientific Publications: London, UK, 1953; pp. 486–502. [Google Scholar]
- Simon, H.A. On a Class of Skew Distribution Functions. Biometrika 1955, 42, 425–440. [Google Scholar] [CrossRef]
- Gerlach, M.; Fon-Clos, F. A Standardized Project Gutenberg Corpus for Statistical Analysis of Natural Language and Quantitative Linguistics. Entropy 2020, 22, 126. [Google Scholar] [CrossRef]
- Tunnicliffe, M.; Hunter, G. The Predictive Capabilities of Mathematical Models for Type-Token Relationships in English Language Corpora. Comput. Speech Lang. 2021, 70, 101227. [Google Scholar] [CrossRef]
- Tunnicliffe, M.; Hunter, G. Random Sampling of the Zipf-Mandelbrot Distribution as a Representation of Vocabulary Growth. Physica A 2022, 608, 128259. [Google Scholar] [CrossRef]
- Auerbach, F. The Law of Population Concentration. EPB Urban Anal. City Sci. 2023, 50, 290–298. [Google Scholar] [CrossRef]
- Montemurro, M. Beyond the Zipf-Mandelbrot Law in Quantitative Linguistics. Physica A 2021, 300, 567–578. [Google Scholar] [CrossRef]
- Ferrer-i-Cancho, R.; Sole, R. Two Regimes in the Frequency of Words and the Origin of Complex Lexicons: Zipf’s Law Revisited. J. Quant. Linguist. 2001, 8, 165–173. [Google Scholar] [CrossRef]
- Tria, F.; Loreto, V.; Servedio, V. Zipf’s, Heaps’ and Taylor’s Laws are Determined by the Expansion into the Adjacent Possible. Entropy 2018, 20, 752. [Google Scholar] [CrossRef] [PubMed]
- Bolea, S.; Pirnau, M.; Bejinariu, S.; Apopei, A.; Gifu, D.; Teodorescu, H.-N. Some Properties of Zipf’s Law and Applications. Axioms 2024, 13, 146. [Google Scholar] [CrossRef]
- Corbet, S.A. The Distribution of Butterflies in the Malay Peninsula (Lepid.). Proc. R. Ent. Soc. Lond. (A) 1941, 16, 101–116. [Google Scholar] [CrossRef]
- Corral, A.; Bolenda, G.; Ferrer-i-Cancho, R. Zipf’s Law for Word Frequencies: Word Forms versus Lemmas in Long Texts. PLoS ONE 2015, 10, e0129031. [Google Scholar] [CrossRef]
- Herdan, G. Type-Token Mathematics: A Textbook of Mathematical Linguistics; Mouton: The Hague, The Netherlands, 1960. [Google Scholar]
- Brysbaert, M.; Stevens, M.; Mandera, P.; Keuleers, E. How Many Words Do We Know? Practical Estimates of Vocabulary Size Dependent on Word Definition, Degree of Language Input and the Participant’s Age. Front. Psychol. 2016, 7, 1116. [Google Scholar] [CrossRef]
- Dahui, W. True Reason for Zipf’s Law in Language. Physica A 2005, 358, 545–550. [Google Scholar] [CrossRef]
- Kornai, A. Zipf’s Law Outside the Middle Range. In Proceedings of the 6th Meeting on Mathematics of Language, Orlando, FL, USA, 23–25 July 1999. [Google Scholar]
- Lü, L.; Zhang, Z.-K.; Zhou, T. Zipf’s Law Leads to Heaps’ Law: Analysing their Relation in Finite-Sized Systems. PLoS ONE 2010, 5, e14139. [Google Scholar] [CrossRef] [PubMed]
- de Marzo, G.; Gabrielli, A.; Pietronero, L. Dynamical Approach to Zipf’s Law. Phys. Rev. Res. 2021, 3, 013084. [Google Scholar] [CrossRef]
- van Leijenhorst, D.; van der Weide, T. A Formal Derivation of Heaps’ Law. Inf. Sci. 2005, 170, 263–272. [Google Scholar] [CrossRef]
- Evert, S. A Simple LNRE Model for Random Character Sequences. Proc. JADT 2004, 2024, 411–422. [Google Scholar]
- Mandelbrot, B. On the Theory of Word Frequencies and on Related Markovian Models of Discourse. In Structure of Language and its Mathematical Aspects; Jakobson, R., Ed.; American Mathematical Society: Providence, RI, USA, 1961; pp. 190–219. [Google Scholar]
- Corral, Á.; Serra, I.; Ferrer-i-Cancho, R. Distinct Flavours of Zipf’s Law and its Maximum Likelihood Fitting: Rank-Size and Size-Distribution Representations. Phys. Rev. E 2020, 102, 052113. [Google Scholar] [CrossRef]
- Thurner, S.; Hanel, R.; Liu, B.; Corominas-Murtra, B. Understanding Zipf’s Law of Word Frequencies through Sample-Space Collapse in Sentence Formation. J. R. Soc. Interface 2015, 12, 20150330. [Google Scholar] [CrossRef]
- Cugini, D.; Timpanaro, A.; Livan, G.; Guarnieri, G. Universal Emergence of Local Zipf-Mandelbrot Law. 2025. Available online: https://arxiv.org/html/2407.15946v2 (accessed on 12 May 2025).
- Zanette, D.H.; Montemurro, M.A. Dynamics of Text Generation with Realistic Zipf’s Distribution. J. Quant. Linguist. 2005, 12, 29–40. [Google Scholar] [CrossRef]
- Bauke, H. Parameter Estimation for Power-Law Distributions by Maximum Likelihood Methods. Eur. Phys. J. B 2007, 58, 167–173. [Google Scholar] [CrossRef]
- ANTF. The Hertzsprung-Russell Diagram, Commonwealth Scientific and Industrial Research Organization. Available online: https://www.britannica.com/science/Hertzsprung-Russell-diagram (accessed on 15 July 2024).
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes in C: The Art of Scientific Computing, 2nd ed.; Cambridge University Press: Cambridge, UK, 1992. [Google Scholar]
- Yang, Z.; Xiangyi, Z. The Applicability of Zipf’s Law in Report Text. Lect. Notes Lang. Lit. Clausius Can. 2023, 6, 57–64. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Title (Abbreviated) | Author | ) | EDNN |
|---|---|---|---|---|
| PG51155 | Dictionary of Synonyms and Antonyms | Samuel Fallows | 2.40 × 10−82 | 2.837 |
| PG22722 | Glossary for Spelling of Dutch Language | Matthais de Vries | 1.36 × 10−23 | 1.400 |
| PG10681 | Thesaurus of English Words and Phrases | Peter Mark Roget | 3.73 × 1018 | 1.190 |
| PG19704 | A Pocket Dictionary: Welsh-English | William Richards | 1.71 × 1011 | 0.841 |
| PG38390 | A Dictionary of English Synonyms | Richard Soule | 3.38 × 10−10 | 0.760 |
| PG20738 | English-Spanish-Tagalog Dictionary | Sofronio Calderón | 1.18 × 10−9 | 0.721 |
| PG19072 | Selected Pamphlets of the Netherlands | - | 1.93 × 10−7 | 0.594 |
| PG23637 | The Bishop of Cottontown | John Moore | 0.222025 | 0.0565 |
| PG36909 | Memoirs of General Baron de Marbot (v.1) | Baron de Marbot | 0.222453 | 0.0410 |
| PG42645 | Expositor’s Bible: Galatians | George Findlay | 0.223936 | 0.0452 |
| PG8069 | Expositions of Scripture: Isaiah & Jeremiah | Alexander Maclaren | 0.224487 | 0.0410 |
| PG3434 | Social Work of the Salvation Army | Henry Rider | 0.224566 | 0.0023 |
| PG2800 | The Koran (English translation) | - | 0.224596 | 0.0023 |
| PG45143 | The Way to the West—3 Early Americans | Emerson Hough | 0.224600 | 0.0312 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| 1 | 1.000000 | 0.877568 | 0.611796 | 0.302807 | 0.086714 | −0.007730 | −0.030490 |
| 2 | 0.877568 | 1.000000 | 0.843515 | 0.517359 | 0.164752 | −0.004763 | −0.070956 |
| 3 | 0.611796 | 0.843515 | 1.000000 | 0.791427 | 0.376716 | 0.128384 | −0.030850 |
| 4 | 0.302807 | 0.517359 | 0.791427 | 1.000000 | 0.686617 | 0.347544 | 0.017829 |
| 5 | 0.086714 | 0.164752 | 0.376716 | 0.686617 | 1.000000 | 0.694031 | 0.151306 |
| 6 | −0.007730 | −0.004763 | 0.128384 | 0.347544 | 0.694031 | 1.000000 | 0.442205 |
| 7 | −0.030490 | −0.070956 | −0.030850 | 0.017829 | 0.151306 | 0.442205 | 1.000000 |
| Code | Title (Abbreviated) | Author | Language | KS Significance |
|---|---|---|---|---|
| PG17077 | Over literatuur: Critisch en didactisch | M. H. Van Campen, | Dutch | 0.999993 |
| PG47629 | Ang “Filibusterismo” | Jose Rizal | Filipino | 0.134267 |
| PG15476 | The Mahabharata Volume 3 (English translation) | - | English | 0.0063 |
| PG31558 | A Monograph on the Sub-class Cirripedia Vol. 1 | Charles Darwin | English | 0.000104 |
| PG41782 | Moths of the British Isles, First Series | Richard South | English | 1.05738 × 10−6 |
| PG39423 | Manual of the Botany of the Northern United States | Asa Gray | English | 2.6154 × 10−8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tunnicliffe, M.; Hunter, G. The Classical Model of Type-Token Systems Compared with Items from the Standardized Project Gutenberg Corpus. Analytics 2025, 4, 16. https://doi.org/10.3390/analytics4020016
Tunnicliffe M, Hunter G. The Classical Model of Type-Token Systems Compared with Items from the Standardized Project Gutenberg Corpus. Analytics. 2025; 4(2):16. https://doi.org/10.3390/analytics4020016
Chicago/Turabian StyleTunnicliffe, Martin, and Gordon Hunter. 2025. "The Classical Model of Type-Token Systems Compared with Items from the Standardized Project Gutenberg Corpus" Analytics 4, no. 2: 16. https://doi.org/10.3390/analytics4020016
APA StyleTunnicliffe, M., & Hunter, G. (2025). The Classical Model of Type-Token Systems Compared with Items from the Standardized Project Gutenberg Corpus. Analytics, 4(2), 16. https://doi.org/10.3390/analytics4020016