1. Introduction
An omnibus test (e.g., an overall test for the equality of multiple proportions) is a statistical procedure used to assess whether there are any significant differences among a set of parameters of the same type. Examples include tests for equality of means, equality of proportions, equality of multiple regression coefficients, equality (or parallelism) of survival curves or distributions, etc. As part of a sequential testing framework, an omnibus test is often followed by multiple pairwise comparisons (MPCs) to identify which specific pairs (e.g., of proportions) contribute to the overall significance.
MPC procedures involve statistical comparisons between two or more groups (often referred to as treatments) and are widely applied across business, education, and scientific research. The foundational work of Hsu (1996) [
1], Edwards and Hsu (1983) [
2], Hsu and Edwards (1983) [
3], and Hsu (1982) [
4] establishes the theoretical framework for MPCs, introduces inferential methods using confidence intervals (CIs), provides real data examples, and highlights approaches enhanced by advanced computational algorithms.
Hence, the purpose of MPC testing is not to re-evaluate overall significance but rather to assess the significance of individual pairwise effects while controlling the experiment-wise error rate at a specified significance level (α). However, the aforementioned foundational works on MPC methods [
1,
2,
3,
4] do not account for the presence of misclassification errors (i.e., false positives, false negatives, or both). In contrast, there is a body of literature that addresses misclassified binomial data—both for one-sample and two-sample cases—and considers either one type or both types of misclassifications using Bayesian or frequentist (likelihood-based) approaches. Nonetheless, these studies do not incorporate multiplicity adjustments in the context of MPCs. For instance, Rahardja (2015, 2015, 2019, 2019) [
5,
6,
7,
8] provides reviews of such previous research.
Stamey et al. (2004) [
9] provided a multiple comparisons method for comparing Poisson rate parameters when count data are subject to misclassification. However, their method is specific to Poisson data and does not extend to binomial data. More recently, Rahardja (2020) [
10] introduced MPC methods for binomial data in the presence of a single type of misclassification, either false positives or false negatives, but not both simultaneously.
In this study, we extend the likelihood-based approach introduced by Rahardja (2020) [
10], which addressed only a single type of misclassification (either false positives or false negatives), to accommodate both types of misclassifications in binomial data using a double sampling design. We then address the issue of multiplicity by applying three adjustment methods: Bonferroni, Šidák, and Dunn. These methods are employed to control the experiment-wise Type I error rate, ensuring it remains at the nominal significance level (α), avoiding inflation or deflation due to repeated testing across subgroups. Because our algorithm is closed-form, implementing these multiplicity adjustment methods is straightforward.
The manuscript is organized as follows:
Section 2,
Section 3 and
Section 4 present the first stage of our two-stage procedure, followed by a simulation study in
Section 5. The second stage is described in
Section 6.
Section 7 summarizes the key distinction between the previous literature work [
10], which only involved one type of binomial misclassification, and this expanded work, which accounts for both types of binomial misclassifications. Finally,
Section 8 provides a discussion and conclusion.
In the first stage (see
Section 2,
Section 3 and
Section 4), we develop three likelihood-based (frequentist) methods to compare the difference in proportions between a single pair of independent binomial samples, each represented by distinct variables, in the presence of both types of misclassifications (false positives and false negatives) in binary data. To contextualize this, we revisit the framework presented in Rahardja (2020) [
10], where the comparison of gender-based differences in disease prevalence—such as cancer, diabetes, chronic pain, and depression—is of common interest. In such studies, the grouping variable (e.g., male vs. female) is typically recorded without error, while the response variable (e.g., presence or absence of disease) is often subject to misclassification. In cases involving terminal illnesses, under-reporting (false negatives) may occur when an individual (male or female) dies from the disease, but the cause is not accurately reflected in official records. Conversely, in vehicle accident situations, there may be instances of over-reporting (false positives) when drivers mislead police officers by claiming they were wearing a seatbelt, while hospital records indicate otherwise. Building upon the single-type misclassification framework introduced by Rahardja (2020) [
10], this work expands to address simultaneously both forms of binomial misclassifications. For example, one might seek to calculate the risk difference for lung cancer (or vehicle accidents) between males and females among different stages of cancer (stages I to IV).
Several researchers, including Bross (1954) [
11], Zelen and Haitovsky (1991) [
12], and Rahardja and Yang (2015a) [
5], have emphasized that failing to account for misclassification—specifically, the presence of false positives and false negatives—can result in severely biased estimates. However, correcting for this bias by incorporating parameters for misclassification into the model introduces a new challenge: the potential for overparameterization, where the number of model parameters exceeds the available sufficient statistics. To address this identifiability issue, we implement a double sampling scheme, which provides additional information and ensures that the model remains both identifiable and unbiased.
Past literature highlights the advantages of using a double-sampling approach (Rahardja et al., 2015 [
6]; Rahardja and Yang, 2015 [
5]; Tenenbein, 1970 [
13]). To integrate the benefits of double sampling into the MPC framework, the concept has already been summarized by Rahardja (2019, 2019, 2020) [
7,
8,
10]. A review of previous related studies is provided in these papers and is therefore not repeated here.
In this manuscript, the first stage (see
Section 2,
Section 3 and
Section 4) focuses on developing maximum likelihood estimation (MLE) based methods to make inferences for MPCs of proportional differences in doubly sampled data subject to both types of misclassifications. This work extends upon the previous studies by Rahardja (2020) [
10] by expanding from scenarios with only one type of misclassification to those involving both. We begin by describing the data and then present three MLE-based confidence intervals as part of the first stage. In
Section 5, we demonstrate and compare the performance of the three MLE methods developed in
Section 2,
Section 3 and
Section 4 through simulation studies.
In the second stage (see
Section 6), we construct adjusted CIs by modifying the CI widths from the first stage (
Section 2,
Section 3 and
Section 4) to account for the multiplicity effects on the differences between all-pair proportion parameters in multiple-sample misclassified binomial data. We then test whether zero falls within each adjusted interval. If zero is included in any interval, the corresponding subgroup pair is not considered to contribute to a significant difference at the adjusted Type I error significance level. Using real data, we illustrate the application of the three MPC methods. In
Section 7, we highlight the key distinction between the previous framework of a single type of binary misclassification proposed by Rahardja (2020) [
10] and the broader framework introduced in this paper, which encompasses both types of misclassifications. Lastly, in
Section 8, we present our findings and wrap up the discussion.
2. Data
Building on the data framework presented in Rahardja (2020) [
10], we extend the setting to incorporate both types of misclassifications—false positives and false negatives—rather than only a single type. In this section, we establish the structure of our dataset for both the main study and the sub-study, along with the associated probabilities, as outlined in
Table 1 and
Table 2. Specifically, for each group
i (
i = 1, 2), we define
mi and
ni as the sample sizes for the main study and sub-study, respectively. The total sample size for group
i is thus
Ni =
mi +
ni.
Subsequently, for the jth unit in the ith group, where i = 1, 2 and j = 1, …, Ni, let Fij and Tij be the binary response variables measured by the error-prone and error-free devices, respectively. We define Fij = 1 if the error-prone device yields a positive result and Fij = 0 otherwise. Similarly, Tij = 1 indicates a truly positive result as measured by the error-free device, and Tij = 0 otherwise. The variable Fij is observed for all units in both the main study and sub-study, whereas Tij is observed for units in the sub-study. Misclassification is said to occur when Fij ≠ Tij.
In the main study, let
xi and
yi denote the number of positive and negative classifications, respectively, in group
i as determined by the error-prone device. In the sub-study, for
i = 1, 2,
j = 0, 1, and
k = 0, 1, let
nijk represent the number of units in group
i classified as
j by the error-free device and as
k by the error-prone device. The summary counts for both the main study and sub-study in group
i are presented in
Table 1.
We now define the relevant parameters for group
i, extending the framework from Rahardja (2020) [
10] to accommodate both types of misclassifications, false positives and false negatives. Let
pi =
Pr(
Tij = 1) denote the true proportion parameter of interest as measured by the error-free device. Let
be the proportion parameter of the error-prone device. The false positive rate of the error-prone device is defined as
, and the false negative rate of the error-prone device is defined as
. It is important to note that
πi is not an independent parameter; rather, it is a function of the other parameters. Specifically, by the law of total probability:
where
qi = 1 −
pi. The corresponding cell probabilities for the summary counts in
Table 1 are presented in
Table 2.
First, we aim to conduct statistical inference on the difference in proportions between a single pair of groups—specifically, between group 1 and group 2—within a setting that may involve multiple groups (
g). Second, we extend the method to incorporate three multiplicity adjustment techniques, Bonferroni, Šidák, and Dunn, for use in MPCs. We denote the proportion difference for the pair of interest as follows:
3. Model
In this section, we conduct statistical inference regarding the difference in proportions outlined in Equation (2). Our objective is to develop both point estimates and CIs for the proportion difference in Equation (2).
The data being examined are displayed in
Table 1. For group
i, the observed counts
from the sub-study are modeled with a quadrinomial distribution, having a total sample size of
ni. The corresponding probabilities are listed in the upper right 2 × 2 submatrix of
Table 2. Specifically,
Furthermore, the recorded counts (
xi,
yi) in the main study follow this binomial distribution:
Given that
and
are independent within group
i and these cell counts are also independent among different groups, the full likelihood function can be expressed, up to a constant, as follows:
where
.
Directly maximizing (3) with respect to
η is not a simple task, as it necessitates the use of iterative numerical methods. Instead of direct enumeration, we employ a reparameterization of
η, which allows us to derive a closed-form solution. In this context, we particularly define new parameters as follows:
Then, the new parameter set is represented as
. By applying Equation (3), the full log likelihood function in terms of
γ is given by the following:
The associated score vector can be expressed as follows:
By equating the aforementioned score vector to 0, the MLE for γ can be found as , , and . By solving Equations (1) and (4), along with considering the invariance property of the MLE, we obtain the MLE for η as , , and .
By applying Equation (5) presented earlier, the expected Fisher information matrix
is a diagonal matrix with the following diagonal elements:
The regularity conditions can be verified and are met with this model. Consequently, the MLE
follows an asymptotic multivariate normal distribution with a mean of
γ and a covariance matrix represented by
. This covariance matrix is diagonal, with its diagonal elements specified as follows:
Consequently, in the asymptotic sense, we have the following:
Furthermore, are asymptotically independent.
Given that
and that
are asymptotically independent, we can use the Delta method to express the variance of
as follows:
A consistent estimator of
is the following:
Given a consistent estimator for is A naïve 100(1 − α)% Wald (nWald) CI for δ is with representing the upper α/2th quantile of the standard normal distribution. We refer to this CI as the naïve Wald CI, as this CI can extend beyond the range of −1 to 1 and often results in an unnecessarily narrow width when applied to small sample sizes.
To enhance the naïve Wald test, we introduce a transformation denoted as The MLE for is By employing the Delta method, we obtain Then, a consistent estimator for is
Consequently, a 100(1 − α)% CI for is represented by Finally, a 100(1 ˗ α)% CI for δ is derived by applying function g to where represents the inverse transformation. We refer to this CI as the modified Wald (mWald) CI.
When dealing with small sample sizes, Wald-type confidence intervals are known to exhibit under-nominal coverage. A common solution is to add small counts to the dataset and then compute Wald intervals based on the adjusted data. The method of adding these small counts can vary depending on the specific dataset. In 1998, Agresti and Coull [
14] performed a similar analysis and suggested adding a count of two to the cells for one-sample binomial problems. They determined this count by exploring the connection between Wald confidence intervals (CIs) and Score CIs. In a related study on one-sample misclassified binary data affected by a single type of misclassification, Lee and Byun in 2008 [
15] also confirmed the validity of adding either one or two to the cell counts. Our rationale for incorporating this small addition to the cell counts in our study aligns with the reasoning presented by Lee and Byun in 2008 [
15]. As a result, we refer to this method as the mWald.2 approach.
5. Simulations
We conducted a series of simulations to evaluate and compare the performance of the three CI methods under various conditions. Performance was assessed using two key metrics: coverage probabilities (CPs) and average lengths (ALs) of two-sided 90% CIs. For simplicity, we assumed equal overall sample sizes (N1 = N2 = N), equal sub-study sample sizes (n1 = n2 = n), equal false positive rates (ϕ1 = ϕ2 = ϕ), and equal false negative rates (θ1 = θ2 = θ).
In our simulations, the performance of all CI methods was evaluated by varying the following conditions:
Misclassification rates: False positive rate ϕ = 0.1 and false negative rate θ = 0.1.
Sub-study proportion: The ratio of sub-study to total sample size was at s = n/N = 0.2.
Total sample sizes: N ranged from 100 to 400, in increments of 10.
True proportion parameters: Two pairs were considered—(p1, p2) = (0.4, 0.6) and (0.1, 0.2)—corresponding to true proportion differences of –0.2 and –0.1, respectively.
For each simulation setting, defined by a fixed combination of (p1, p2), ϕ, θ, n/N, and N, we generated K = 10,000 simulated datasets.
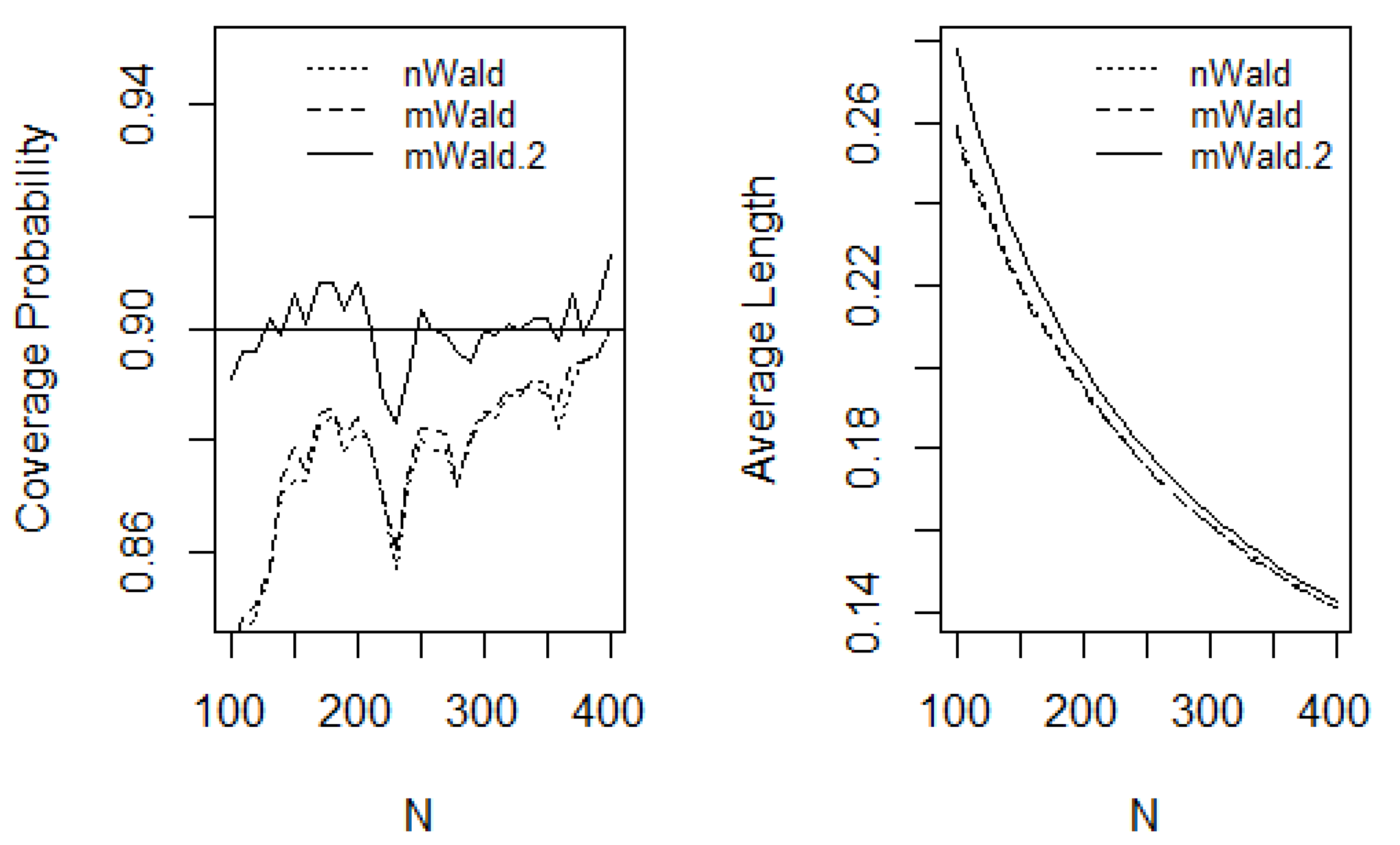
Figure 1 and
Figure 2 display the plots of CPs and ALs for all CI methods as functions of
N for the scenarios (
p1,
p2) = (0.4, 0.6) and (
p1,
p2) = (0.1, 0.2), respectively. When the true proportions are closer to 0.5—as in the case of (
p1,
p2) = (0.4, 0.6)—the underlying binomial distributions tend to be approximately symmetric around their means. This symmetry represents a “best-case” or “fair-coin” scenario in which the CI methods are generally expected to perform well. Persistently, across the entire range of sample sizes considered,
Figure 1 shows that all three CI methods maintain CPs close to the nominal level, with the mWald.2 method performing particularly well. The nWald and mWald methods appear more conservative, as they converge more slowly to the nominal 90% CP—only reaching it at around
N = 275. In terms of ALs, all three methods exhibit similar performance. In contrast, when the true proportion parameters are farther from the “fair-coin” case—as in (
p1,
p2) = (0.1, 0.2)—the binomial distributions become increasingly skewed, and their behavior becomes less favorable for inference. Under such conditions, particularly for small sample sizes, the CI methods are not expected to perform as reliably, and coverage may deviate from the nominal level.
The plots in
Figure 2 illustrate that both the nWald and mWald CIs exhibit poor CPs when sample sizes are small. Their CPs approach the nominal level only as sample sizes become large. Remarkably, the mWald.2 method maintains consistently strong coverage across all sample sizes, with its CPs fluctuating closely around the nominal 90% level—even when
N is as low as 100. For all three methods, the ALs are comparable throughout the sample size range.
The following provides guidance on the sample size ranges for which the three CI methods yield valid coverage. For the mWald.2 CI, when (p1, p2) = (0.4, 0.6), representing a “fair-coin” or best-case scenario, the CPs remain close to the nominal level, ranging approximately between 89% and 91%, even with total sample sizes as low as N > 100. Similarly, for the more challenging case of (p1, p2) = (0.1, 0.2), where the proportions are farther from 0.5, the mWald.2 method still maintains reasonable coverage (approximately 88% to 91%) for sample sizes N > 100.
For the other two CI methods, nWald and mWald, achieving coverage probabilities close to the nominal 90% level (approximately between 87% and 91%) requires larger sample sizes. When (p1, p2) = (0.4, 0.6), both methods require at least N > 250. In the more challenging case of (p1, p2) = (0.1, 0.2), acceptable coverage is attained only when N > 300.
Our simulations indicate that the mWald.2 CI method outperforms the other two methods, as it consistently maintains coverage probabilities close to the nominal level, even for relatively smaller sample sizes. Therefore, our findings align with the recommendations and conclusions of Agresti and Coull (1998) [
14] and Lee and Byun (2008) [
15].
6. Multiple Pairwise Comparisons (MPCs) in the Presence of Misclassified Binomial Data
When misclassified binomial data (including both false positives and false negatives) are present in pairwise comparisons involving more than two groups, as outlined in
Section 2,
Section 3,
Section 4 and
Section 5, a multiplicity issue arises. This issue, whether related to hypothesis testing or confidence intervals, stems from the repeated comparisons made between each pair of
g groups. Therefore, it is essential to address this multiplicity problem. The typical objective is to control the family-wise error rate (FWER). This refers to the likelihood of committing at least one Type I error among the multiple pairwise comparisons. Consequently, it is essential to keep the FWER at a specified overall threshold, known as α. Numerous methods for MPC procedures, such as Bonferroni, Šidák, and Dunn, are available in the literature to achieve this control. These MPC adjustment techniques vary in how they modify the α value to account for the effects of multiple comparisons.
In this manuscript, we utilize three adjustment techniques—Bonferroni, Šidák, and Dunn—to account for differences in proportion parameters while considering both types of misclassifications (false positives and false negatives) in multiple-sample binomial data during the final calculation of CIs.
It is important to note that given there are
g groups, the unique number of comparison pairs (combinations, not permutations) is as follows:
Additionally, it is essential to note that when we compare with a control group, the number of comparisons conducted is limited to the following:
As a result, when ≠ 1 for the pairs (and m is a positive integer), testing each pair at an overall significance level of α = 0.05 is no longer a fair or valid comparison (i.e., too lenient) because when we perform hypothesis testing multiple times (over and over again), it will be progressively easier for such multiple tests to be significant, and hence the overall α level should be penalized more stringently. Each pair must have its α significance level adjusted accordingly. The methods for the adjustment are outlined below.
6.1. Bonferroni Adjustment of CI for Misclassified Binomial Data
In the realm of machine learning, Salzberg (1997) [
17] identifies the Bonferroni correction technique as a general approach to addressing the issue of multiple testing, with references to Hochberg (1988) [
18], Holland (1991) [
19], and Hommel (1988) [
20], who also discuss this method. Salzberg points out that while the Bonferroni correction is the earliest and simplest method for understanding multiple testing, it tends to be overly conservative, making it slow to reject the null hypothesis of equality tests, and it may produce weak results due to its reliance on the assumption of independence among hypotheses. Nevertheless, we have opted to use the Bonferroni correction first when dealing with over-reported and/or under-reported binomial data. This correction operates as a single-step procedure, meaning that all CIs are compared against the same CI threshold across the
m-adjusted intervals (Holland and Copenhaver, 1987 [
21]; Hochberg and Tamhane, 1987 [
22]).
To achieve an overall confidence level of (1 −
α) × 100%, the Bonferroni adjustment procedure applied in a single step for each of the
m individual CIs for
δ is as follows:
where
m is derived from Equation (6). If zero lies within the (adjusted) interval defined in Equation (8), we do not reject the equality of the pair’s proportions. Conversely, if zero is outside the (adjusted) interval (8), it indicates a significant difference between the pair’s proportions at each significance level of
α/
m (Bonferroni adjusted).
Using the Bonferroni adjustment outlined in Equation (8), with
m specified in Equation (6), we analyze the North Carolina Traffic Data categorized into
g = 4 groups (A = Male High Damage, B = Female High Damage, C = Male Low Damage, and D = Female Low Damage). This results in
m = 6 (mWald.2) CIs, which are presented in
Table 5.
Table 5 illustrates that, when applying the Bonferroni adjustment method outlined in Equation (8), significant differences are identified in all pairs, as zero falls outside the Bonferroni-adjusted intervals for all these pairs. To attain an overall 90% CI with
α = 0.1, the single-step Bonferroni adjustment method yields a Bonferroni CI of 98.33% for all of the
m = 6 (mWald.2) CIs.
6.2. Šidák Adjustment of CI for Misclassified Binomial Data
Like the Bonferroni correction, the Šidák correction introduced in 1967 [
23] is another widely used single-step method for adjusting multiple tests to control the FWER. However, this method is applicable only when the tests are independent or positively dependent. As with other single-step procedures, it involves comparing all CIs to the same CI threshold across each of the
m-adjusted intervals for every zero tested.
To achieve an overall confidence level of (1 −
α) × 100%, the single-step Šidák adjustment or correction technique for each
m individual CI for
δ is formulated as follows:
where
m is from Equation (6). If zero falls within the adjusted interval in Equation (9), we do not reject the equality of the pair’s proportions. Conversely, if zero is not included in the adjusted interval (9), it indicates a significant difference between the pair’s proportions at each significance level adjusted by Šidák, specifically at the
level.
By using the Šidák adjustment in Equation (9), along with
m from Equation (6), for the North Carolina Traffic Data categorized into g = 4 groups (A = Male High Damage, B = Female High Damage, C = Male Low Damage, and D = Female Low Damage), we derive
m = 6 (mWald.2) CIs, as presented in
Table 5.
Table 5 illustrates that when applying the Šidák adjustment method as outlined in Equation (9), significant differences are found in all pairs. In this case involving traffic data, the results align with those obtained using the Bonferroni adjustment method detailed in Equation (8). To achieve an overall 90% CI (or
α = 0.1), the single-step Šidák adjustment method yields a Šidák CI of 98.26% for each of the
m = 6 (mWald.2) CIs.
6.3. Dunn Adjustment of CI for Misclassified Binomial Data
A widely used single-step adjustment method for corrections is the Dunn method (Dunn, 1961 [
24]), which manages the family-wise error rate (FWER) by dividing
α by
m, the total number of comparisons conducted, where
m is specified in Equation (7). This approach involves selecting one group as the control and comparing all other groups against it. The remainder of this procedure is straightforward to apply, as it follows the same protocol as the previously mentioned Bonferroni method outlined in Equation (8) of
Section 6.1 but utilizes
m from Equation (7) instead.
In this manuscript, we do not implement this adjustment or correction method to the traffic data because we do not designate any of the four groups (A, B, C, or D) as a control (placebo) group, akin to the typical approach taken in drug development (pharmaceutical studies).
8. Discussion and Conclusions
In this manuscript, we first develop three MLE methods (presented in the first stage,
Section 2,
Section 3 and
Section 4) to estimate the proportion difference between two independent binomial samples in the presence of misclassifications. In
Section 5, we conduct simulations to demonstrate the performance of these three MLE methods under binomial misclassifications. In the second stage (
Section 6), we adjust the interval width to account for the multiplicity effect in MPCs. Subsequently, we highlight the key differences in
Section 7 between the former framework of a single type of binary misclassification introduced in the previous literature [
10] and the expanded framework developed in this paper, which includes both types of binomial misclassifications.
In the first stage (
Section 2,
Section 3 and
Section 4), we employ a double sampling scheme to obtain additional information, ensure model identifiability, and reduce bias. During this process, we reparametrize the original full likelihood function, leading to a closed-form likelihood function that is computationally feasible. Without this reparameterization, such a closed-form expression would be computationally unattainable. As a result, the MLE and the corresponding three CI methods—nWald, mWald, and mWald.2—can be computed when evaluating the proportion difference.
In
Section 5, during the simulations for the first stage, we apply the three CI methods to the large sample dataset from Hochberg (1977) [
16] (shown in
Table 4), focusing on Group A (Male, High Car Damage) and Group B (Female, High Car Damage). As expected, the three methods produce similar CIs due to the large sample sizes in the Hochberg dataset. It is worth noting that previous studies by Agresti and Coull (1998) [
14] and Lee and Byun (2008) [
15] have shown that adding one or two counts to the cell counts in small sample binomial data can help correct bias. This explains why, among the three likelihood-based methods, the mWald.2 method performs the best—its CPs consistently stay closest to the nominal values across all simulated scenarios, even with small sample sizes.
In the second stage (
Section 6), to address the multiplicity effect in MPCs, we incorporate three adjustment methods—Bonferroni, Sidak, and Dunn—into the calculation of adjusted CIs for the differences in proportion parameters. These adjustments account for both types of misclassifications in multiple-sample binomial data.
As an illustration of the second stage, we apply the adjustment methods to the pairwise comparisons using MPCs on the large sample dataset from Hochberg (1977) [
16], which includes four groups: Group A (Male and High Car Damage), Group B (Female and High Car Damage), Group C (Male and Low Car Damage), and Group D (Female and Low Car Damage). In this example, both the Bonferroni and Sidak adjustment methods reveal significant differences across all pairs.
As a recap,
Section 7 pointed out the key distinctions between the single-type binomial misclassification framework introduced by Rahardja (2020) [
10] and the broader framework discussed in this manuscript, which simultaneously accounts for both types of misclassifications.
In conclusion, we propose likelihood-based estimation methods to obtain confidence intervals (CIs) for comparing pairwise proportion differences under three multiplicity adjustment methods (Bonferroni, Sidak, and Dunn) in the context of misclassified multiple-sample binomial data using a double sampling scheme. These MPC methods will be valuable tools for practitioners and researchers working in the field of binomial misclassification.





{kind=link}
{kind=link}