

Information, Volume 10, Issue 9 (September 2019) – 24 articles
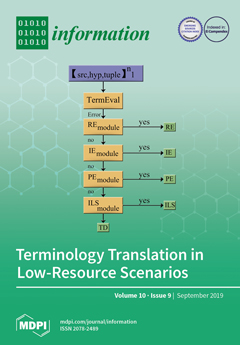
Cover Story (view full-size image):
A polysemous term has many potential translation equivalents in a target language. The translation could lose its meaning if the term translation and domain knowledge are not taken into account. The evaluation of terminology translation has been one of the least-explored areas in machine translation (MT) research. To the best of our knowledge, as of now, no one has proposed any effective way to evaluate terminology translation in MT automatically. This work presents a semi-automatic terminology annotation strategy from which a gold standard for evaluating terminology translation in automatic translation can be created. The paper also introduces a classification framework that can automatically classify term translation-related errors and expose specific problems in relation to terminology translation in MT. View this paper
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue