Copy-Move Forgery Detection and Localization Using a Generative Adversarial Network and Convolutional Neural-Network



Abstract
1. Introduction
2. Related Works
3. Proposed Copy-Move Forgery Detection Strategy
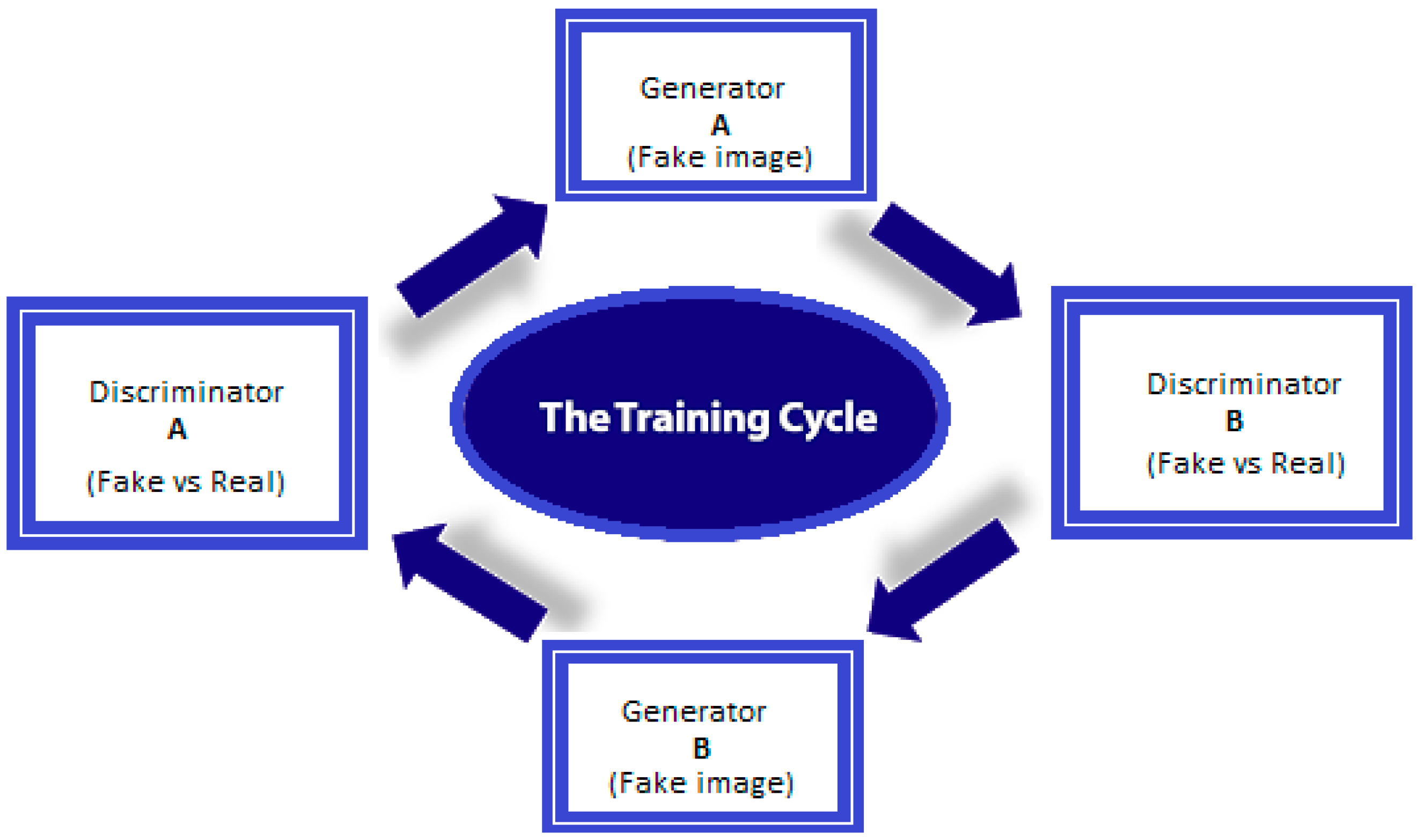
3.1. GANs Create Forged Images
3.1.1. GAN Tasks
3.1.2. GAN Processing Steps
3.1.3. Support Vector Machines
3.2. CNN for Matching or Detecting Similar Patches
3.2.1. Similarity-Matching Tasks
3.2.2. Feature Extraction
3.2.3. Feature Extraction Problems
4. Proposed Algorithm Overview
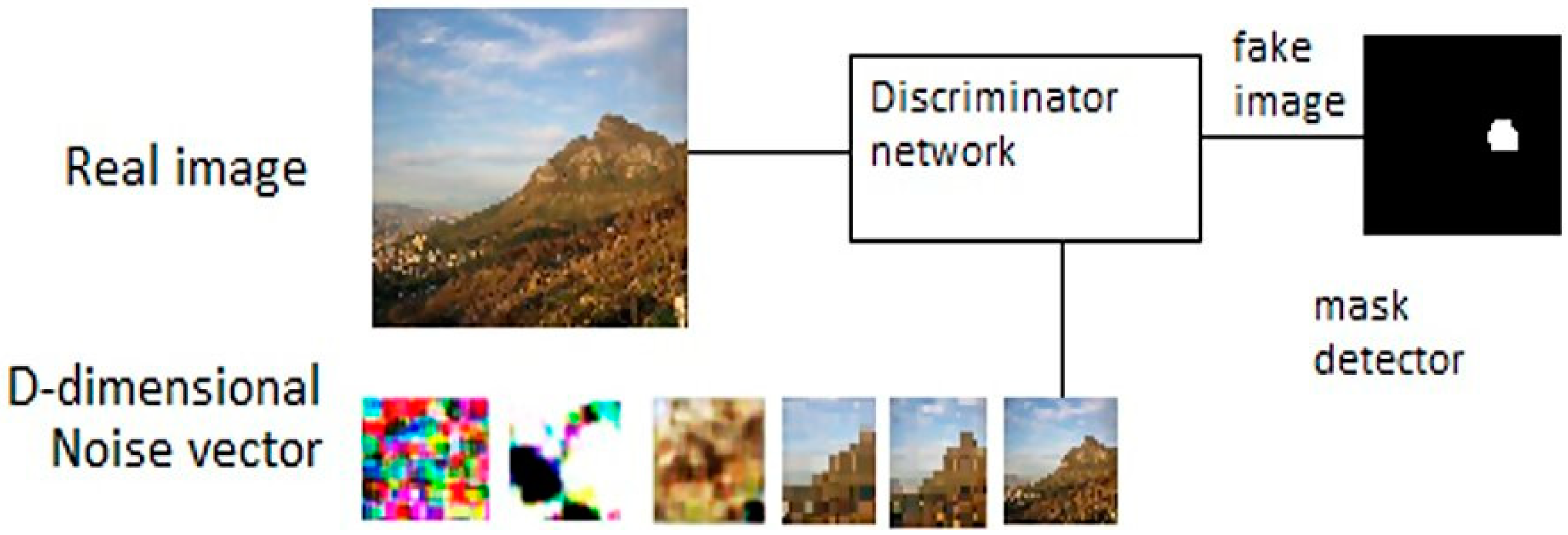
4.1. Discriminator Network
4.2. Generator Network
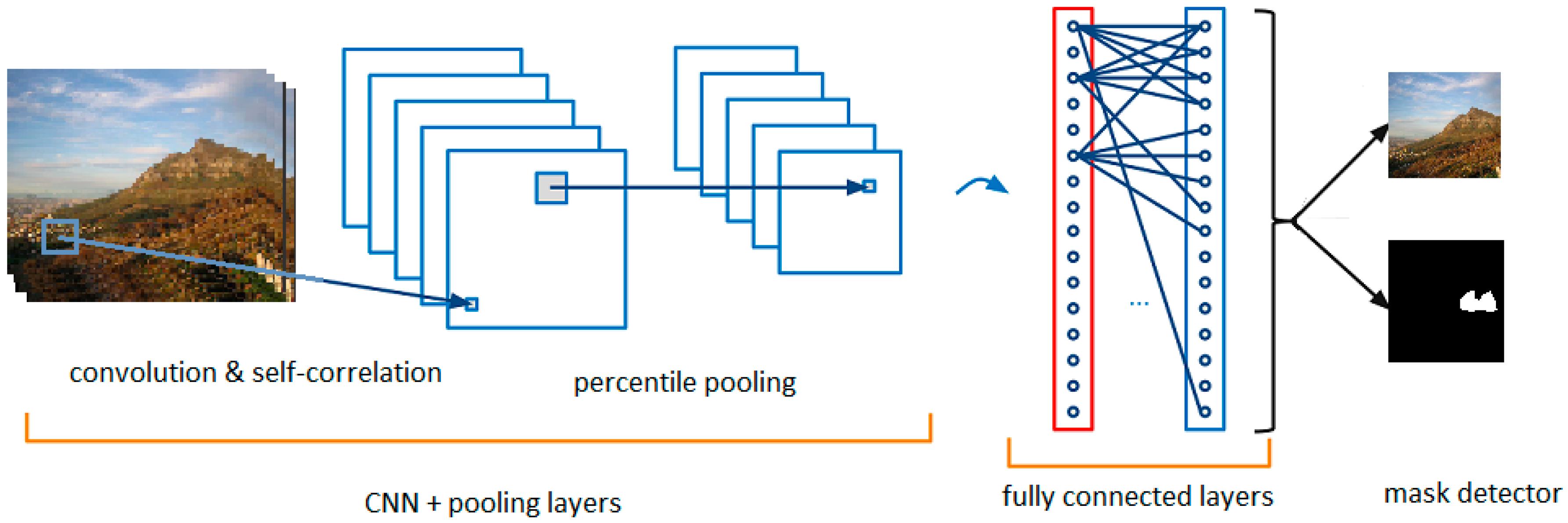
4.3. CNN Networks
4.4. Merging Network
- CMFD classifier: we used an SVM linear classifier. Eventually, our SVM classifier uses the merging of the vector features of the two models and is trained over the whole training set.
- Output Masking: shows three images with copy-move forgeries, the corresponding ground truth, and the detection map output from our method. Note that the forgery is easily detected, and the map is quite accurate, although the original and copied regions are distinguished from one another
5. Proposal Implementation
6. Results and Discussion
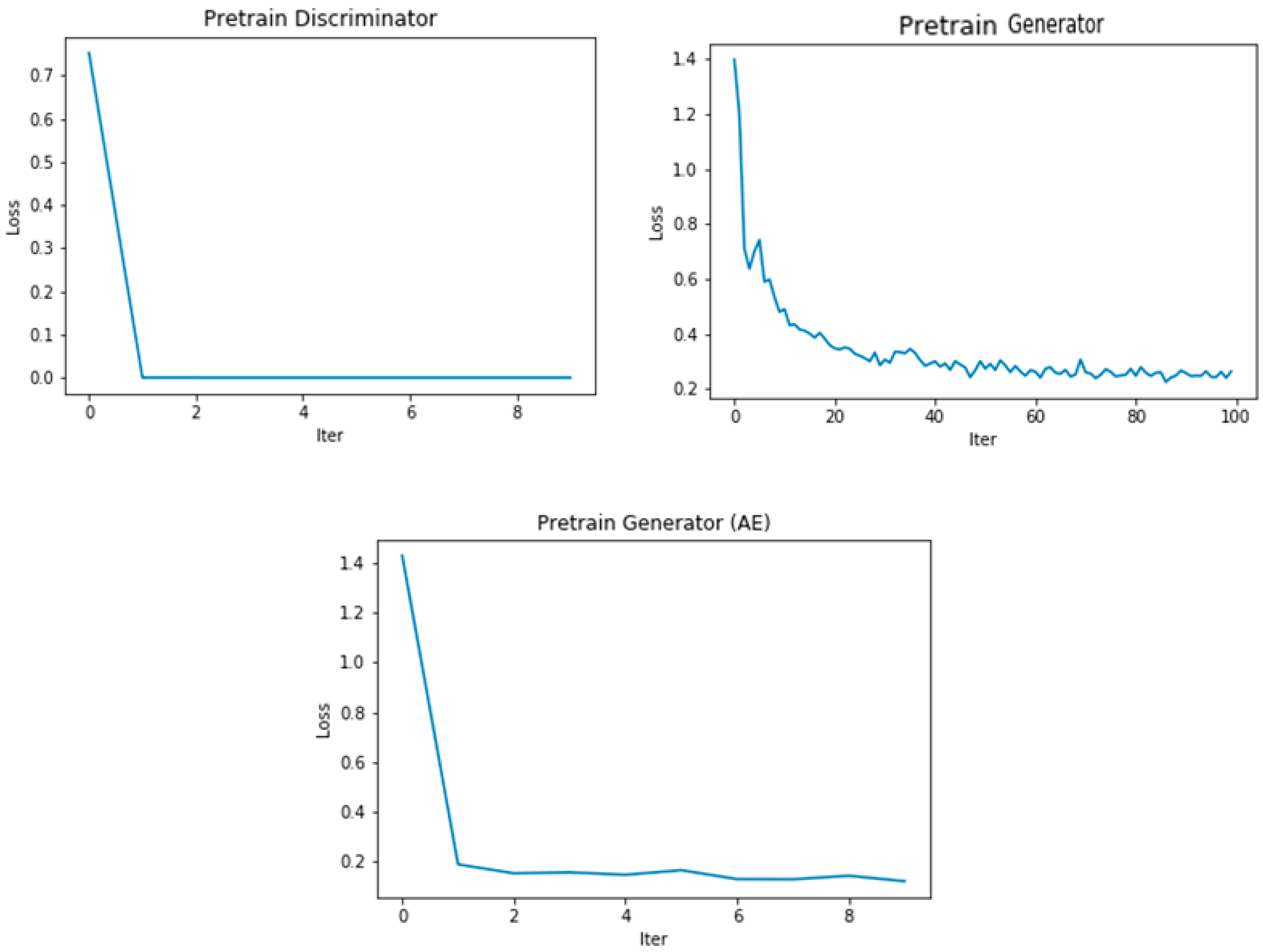
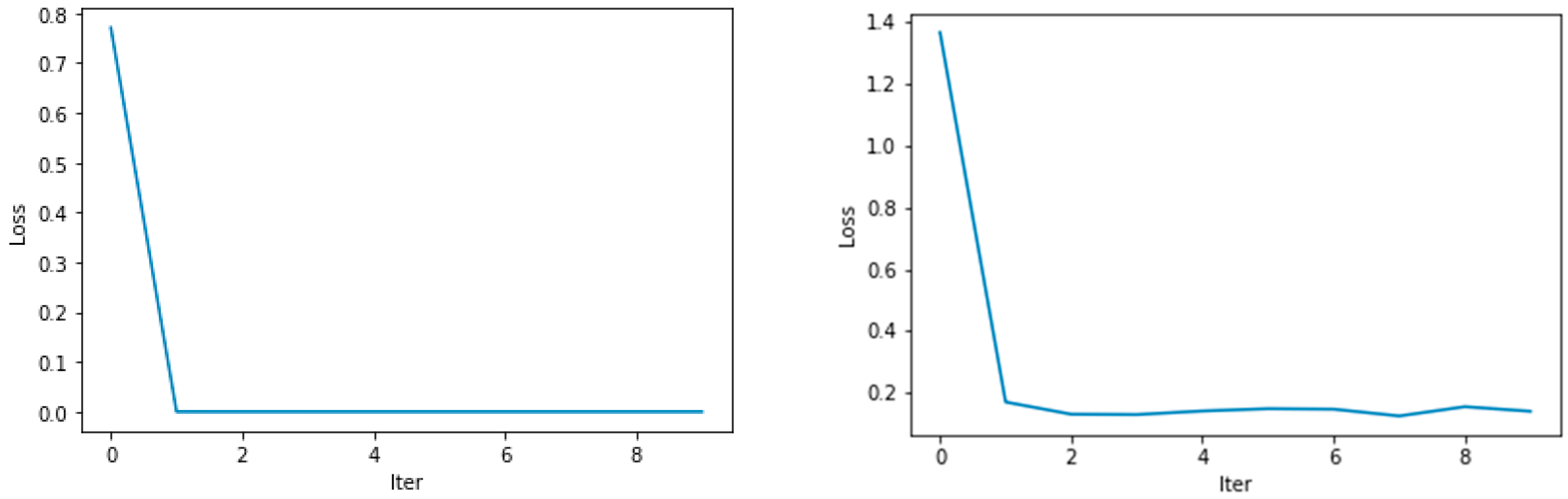
6.1. Training GAN Models in Forgery Detection
6.1.1. Data Environment
6.1.2. Experimental Setup
Analysis
- (a)
- Train the discriminator:
- (b)
- Train the generator (to have the discriminator label samples as valid):G Loss = combined train (noise, valid)Noise = random batch on imageValid = adversarial ground truth
6.2. Training CNN Models in Similarity Detection
6.2.1. How the Model Works
6.2.2. Some Result Using Different Datasets
6.3. Training the CMFD Classification Model for Localization
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Explanation |
| CNN | Convolutional neural network. |
| GANs | Generative adversarial networks. |
| CMFD | Copy-move forgery detection. |
| SVM | Support vector machine. |
| PCA | Principal component analysis. |
| DCT | Discrete cosine transforms. |
| SIFT | Scale-invariant feature transform. |
| DNNs | Deep neural networks. |
| SGD | Stochastic sub-gradient descent. |
| VGG | Visual geometry group. |
| ConvNet | Convolutional network layer. |
| ReLU | Rectified linear unit layer. |
| ROC | Receiver operating characteristic. |
| AUC | The area under the curve. |
| HD5-HDF5 | Hierarchical data format. |
| F1 score | A measure of a test’s accuracy. |
| BCE | Binary cross entropy. |
| PR | Positive rate. |
| ORB | Oriented FAST and rotated BRIEF. |
| SURF | Speed up robust feature. |
| SIFT | Scale invariant feature transform. |
| VGG16 | Visual geometry group (VGG Network with 16 layers). |
| Conv | Convolutional layer. |
| cGAN | Conditional generative adversarial network. |
| cNets | Capsule network. |
| CIFAR-10 | Dataset consists of 60,000 32 × 32 color images in 10 classes. |
| MNIST | Dataset of handwritten digits with 60,000 examples. |
| MICC_F600 | Copy-move dataset composed by 660 images in total. |
References
- Rocha, A.; Scheirer, W.; Boult, T.; Goldenstein, S. Vision of the unseen: Current trends and challenges in the digital image and video forensics. ACM Comput. Surv. 2011, 43, 26. [Google Scholar] [CrossRef]
- Piva, A. An overview on image forensics. ISRN Signal Process. 2013, 2013, 22. [Google Scholar] [CrossRef]
- Stamm, C.; Wu, M.; Liu, K.J.R. Information forensics: An overview of the first decade. IEEE Access 2013, 1, 167–200. [Google Scholar] [CrossRef]
- Fridrich, A.J.; Soukal, B.D.; Lukáš, A.J. Detection of copy-move forgery in digital images. In Proceedings of the Digital Forensic Research Workshop, Cleveland, OH, USA, 6–8 August 2003. [Google Scholar]
- Ke, Y.; Sukthankar, R.; Huston, L. An efficient parts-based near-duplicate and sub-image retrieval system. In Proceeding of the 12th Annual ACM International Conference on Multimedia, New York, NY, USA, 10–16 October 2004; pp. 869–876. [Google Scholar]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. BusterNet: Detection Copy-Move Image Forgery with Source/Target Localization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Fan, S.; Ng, T.-T.; Koenig, B.L.; Herberg, J.S.; Jiang, M.; Shen, Z.; Zhao, Q. Image Visual Realism: From Human Perception to Machine Computation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2180–2193. [Google Scholar] [CrossRef] [PubMed]
- Lyu, S.; Farid, H. How realistic is photorealistic? IEEE Trans. Signal Process. 2005, 53, 845–850. [Google Scholar] [CrossRef]
- Wu, R.; Li, X.; Yang, B. Identifying computer generated graphics VIA histogram features. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1933–1936. [Google Scholar]
- Dehnie, S.; Sencar, T.; Memon, N. Digital Image Forensics for Identifying Computer Generated and Digital Camera Images. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 2313–2316. [Google Scholar]
- Dirik, A.; Bayram, S.; Sencar, H.; Memon, N. New features to identify computer generated images. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16 September–19 October 2007; pp. IV-433–IV-436. [Google Scholar]
- Gallagher, A.; Chen, T. Image authentication by detecting traces of demosaicing. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Lalonde, J.-F.; Efros, A. Using color compatibility for assessing image realism. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Zhang, R.; Wang, R.-D.; Ng, T.-T. Distinguishing photographic images and photorealistic computer graphics using visual vocabulary on local image edges. In International Workshop on Digital Forensics and Watermarking; Springer: Berlin/Heidelberg, Germany, 2011; pp. 292–305. [Google Scholar]
- Rahmouni, N.; Nozick, V.; Yamagishi, J.; Echizen, I. Distinguishing computer graphics from natural images using convolution neural networks. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]
- De Rezende, E.R.; Ruppert, G.C.; Carvalho, T. Detecting Computer Generated Images with Deep Convolutional Neural Networks. In Proceedings of the 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Niteroi, Brazil, 17–20 October 2017; pp. 71–78. [Google Scholar]
- Holmes, O.; Banks, M.S.; Farid, H. Assessing and Improving the Identification of Computer-Generated Portraits. ACM Trans. Appl. Percept. 2016, 13, 1–12. [Google Scholar] [CrossRef]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Webb, R.; Wang, W. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Haouchine, N.; Roy, F.; Courtecuisse, H.; Nießner, M.; Cotin, S. Calipso: Physics-based image and video editing through cad model proxies. arXiv 2017, arXiv:1708.03748. [Google Scholar] [CrossRef]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2Face: Real-Time Face Capture and Reenactment of RGB Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2387–2395. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Farid, H. Seeing is not believing. IEEE Spectr. 2009, 46, 44–51. [Google Scholar] [CrossRef]
- Bayram, S.; Sencar, H.T.; Memon, N. An efficient and robust method for detecting copy-move forgery. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1053–1056. [Google Scholar]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Efficient Dense-Field Copy–Move Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2284–2297. [Google Scholar] [CrossRef]
- Huang, D.Y.; Huang, C.N.; Hu, W.C.; Chou, C.H. Robustness of copy-move forgery detection under high jpeg compression artifacts. Multimed. Tools Appl. 2017, 76, 1509–1530. [Google Scholar] [CrossRef]
- Mahdian, B.; Saic, S. Detection of copy–move forgery using a method based on blur moment invariants. Forensic Sci. Int. 2007, 171, 180–189. [Google Scholar] [CrossRef] [PubMed]
- Pun, C.M.; Yuan, X.C.; Bi, X.L. Image forgery detection using adaptive over-segmentation and feature point matching. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1705–1716. [Google Scholar]
- Ryu, S.J.; Lee, M.J.; Lee, H.K. Detection of copy-rotate-move forgery using Zernike moments. In International Workshop on Information Hiding; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6387, pp. 51–65. [Google Scholar]
- Ardizzone, E.; Bruno, A.; Mazzola, G. Copy–Move Forgery Detection by Matching Triangles of Keypoints. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2084–2094. [Google Scholar] [CrossRef]
- Manu, V.; Mehtre, B.M. Detection of copy-move forgery in images using segmentation and surf. In Advances in Signal Processing and Intelligent Recognition Systems; Springer: Cham, Switzerland, 2016; pp. 645–654. [Google Scholar]
- Shivakumar, B.; Baboo, S. Detection of region duplication forgery in digital images using surf. Int. J. Comput. Sci. Issues 2011, 8, 199–205. [Google Scholar]
- Silva, E.A.; Carvalho, T.; Ferreira, A.; Rocha, A. Going deeper into copy-move forgery detection: Exploring image telltales via multi-scale analysis and voting processes. J. Vis. Commun. Image Represent. 2015, 29, 16–32. [Google Scholar] [CrossRef]
- Costanzo, A.; Amerini, I.; Caldelli, R.; Barni, M. Forensic Analysis of SIFT Keypoint Removal and Injection. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1450–1464. [Google Scholar] [CrossRef]
- Yang, B.; Sun, X.; Guo, H.; Xia, Z.; Chen, X. A copy-move forgery detection method based on CMFD-SIFT. Multimed. Tools Appl. 2017, 77, 837–855. [Google Scholar] [CrossRef]
- Amerini, I.; Ballan, L.; Caldelli, R.; Del Bimbo, A.; Serra, G. A SIFT-Based Forensic Method for Copy–Move Attack Detection and Transformation Recovery. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1099–1110. [Google Scholar] [CrossRef]
- Li, J.; Li, X.; Yang, B.; Sun, X. Segmentation-based image copy-move forgery detection scheme. IEEE Trans. Inf. Forensics Secur. 2015, 10, 507–518. [Google Scholar]
- Birajdar, G.K.; Mankar, V.H. Digital image forgery detection using passive techniques: A survey. Digit. Investig. 2013, 10, 226–245. [Google Scholar] [CrossRef]
- Asghar, K.; Habib, Z.; Hussain, M. Copy-move and splicing image forgery detection and localization techniques: A review. Aust. J. Forensic Sci. 2017, 49, 281–307. [Google Scholar] [CrossRef]
- Soni, B.; Das, P.; Thounaojam, D. Cmfd: A detailed review of block-based and key feature-based techniques in image copy-move forgery detection. IET Image Process. 2017, 12, 167–178. [Google Scholar] [CrossRef]
- Warif, N.B.A.; Wahab, A.W.A.; Idris, M.Y.I.; Ramli, R.; Salleh, R.; Shamshirband, S.; Choo, K.-K.R. Copy-move forgery detection: Survey, challenges and future directions. J. Netw. Comput. Appl. 2016, 75, 259–278. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhou, Y.; Zhou, H.; Gong, X. Ultrasound image edge detection based on a novel multiplicative gradient and canny operator. Ultrason. Imaging 2015, 37, 238–250. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Huang, P.; Chen, L.; Zhang, B. An efficient circle detection not relying on edge detection. Adv. Space Res. 2016, 57, 2359–2375. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Liu, T.; Li, Y.; Ye, W. Edge Detection Algorithm of a Symmetric Difference Kernel SAR Image Based on the GAN Network Model. Symmetry 2019, 11, 557. [Google Scholar] [CrossRef]
- Luan, S.; Chen, C.; Zhang, B.; Han, J.; Liu, J. Gabor Convolutional Networks. IEEE Trans. Image Process. 2018, 27, 4357–4366. [Google Scholar] [CrossRef] [PubMed]
- Park, K.; Kim, D.H. Accelerating Image Classification using Feature Map Similarity in Convolutional Neural Networks. Appl. Sci. 2019, 9, 108. [Google Scholar] [CrossRef]
- Hsu, C.C.; Lee, C.Y.; Zhuang, Y.X. Learning to Detect Fake Face Images in the Wild. In 2018 International Symposium on Computer, Consumer and Control (IS3C); IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Snape, P.; Pszczolkowski, S.; Zafeiriou, S.; Tzimiropoulos, G.; Ledig, C.; Rueckert, D. A Robust Similarity Measure for Volumetric Image Registration with Outliers. Image Vis. Comput. 2016, 52, 97–113. [Google Scholar] [CrossRef]
- Liu, Y.; Guan, Q.; Zhao, X. Copy-move forgery detection based on convolutional kernel network. Multimed. Tools Appl. 2017, 77, 18269–18293. [Google Scholar] [CrossRef]
- Bunk, J.; Bappy, J.H.; Mohammed, T.M.; Nataraj, L.; Flenner, A.; Manjunath, B.; Chandrasekaran, S.; Roy-Chowdhury, A.K.; Peterson, L. Detection and localization of image forgeries using resampling features and deep learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1881–1889. [Google Scholar]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Deep matching and validation network: An end-to-end solution to constrained image splicing localization and detection. In Proceedings of the 2017 ACM on Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; Volume MM’17, pp. 1480–1502. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-Stream Neural Networks for Tampered Face Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Dang, L.; Hassan, S.; Im, S.; Lee, J.; Lee, S.; Moon, H. Deep learning based computer generated face identification using a convolutional neural network. Appl. Sci. 2018, 8, 2610. [Google Scholar] [CrossRef]
- Zhu, Y.; Shen, X.; Chen, H. Copy-move forgery detection based on a scaled orb. Multimed. Tools Appl. 2016, 75, 3221–3233. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.S.; Chandrasekaran, S.; Flenner, A.; Bappy, J.H.; Roy-Chowdhury, A.K. Detecting GAN generated fake images using co-occurrence matrices. arXiv 2019, arXiv:1903.06836. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-generated Fake Images over Social Networks. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval, Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar]
- Carey, O. Generative Adversarial Networks GANs. 2018. Available online: http://towardsdatascience.com/generative-adversarial-networks-gans-a-beginners-guide-5b38eceece24 (accessed on 19 February 2019).
- Bupe, C. Why Is SVM Not Popular Nowadays; University of Zambia: Lusaka, Zambia, 2018; Available online: https://www.quora.com/ (accessed on 25 April 2019).
- Cozzoline, D.; Gragnaniello, D.; Verdoliva, L. Image forgery detection based on the fusion of machine learning and block-matching methods. Computer Science—Computer Vision and Pattern Recognition. arXiv 2013, arXiv:1311.6934C. [Google Scholar]
- Popescu, A.C.; Farid, H. Exposing Digital Forgeries by Detecting Duplicated Image Regions; Tech. Rep. TR2004-515; Dartmouth College: Hanover, NH, USA, 2004. [Google Scholar]
- Huang, Y.; Lu, W.; Sun, W.; Long, D. Improved DCT-based detection of copy-move forgery in images. Forensic Sci. Int. 2011, 206, 178–184. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, T.; Nawaz, T.; Irtaza, A.; Ashraf, R.; Shah, M. Copy-Move Forgery Detection Technique for Forensic Analysis in Digital Images. Math. Probl. Eng. 2016, 2016, 1–13. [Google Scholar] [CrossRef]
- Yarlagadda, S.K.; Güera, D.; Bestagini, P.; Maggie Zhu, F.; Tubaro, S.; Delp, E.J. Satellite Image Forgery Detection and Localization Using GAN and One-Class Classification. arXiv 2018, arXiv:1802.04881v1. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T.N. Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3859–3869. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Jing, W.; Hongbin, Z. Exposing digital forgeries by detecting traces of image splicing. In 2006 8th International Conference on Signal Processing; IEEE: Piscataway, NJ, USA, 2006; Volume 2. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2011; pp. 44–51. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Visualizing deep convolutional neural networks using natural pre-images. Int. J. Comput. Vis. 2016, 12, 233–255. [Google Scholar] [CrossRef]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, paste and learn: Surprisingly easy synthesis for instance detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wagner, Forensically Beta, 16 08 2015. Available online: https://29a.ch/photo-forensics/#forensic-magnifier (accessed on 28 August 2019).
- McQuaid, J. MagNet. 2015. Available online: https://www.magnetforensics.com/for-forensic-examiners/ (accessed on 28 August 2019).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdalla, Y.; Iqbal, M.T.; Shehata, M. Copy-Move Forgery Detection and Localization Using a Generative Adversarial Network and Convolutional Neural-Network. Information 2019, 10, 286. https://doi.org/10.3390/info10090286
Abdalla Y, Iqbal MT, Shehata M. Copy-Move Forgery Detection and Localization Using a Generative Adversarial Network and Convolutional Neural-Network. Information. 2019; 10(9):286. https://doi.org/10.3390/info10090286
Chicago/Turabian StyleAbdalla, Younis, M. Tariq Iqbal, and Mohamed Shehata. 2019. "Copy-Move Forgery Detection and Localization Using a Generative Adversarial Network and Convolutional Neural-Network" Information 10, no. 9: 286. https://doi.org/10.3390/info10090286
APA StyleAbdalla, Y., Iqbal, M. T., & Shehata, M. (2019). Copy-Move Forgery Detection and Localization Using a Generative Adversarial Network and Convolutional Neural-Network. Information, 10(9), 286. https://doi.org/10.3390/info10090286