


Genes, Volume 10, Issue 3 (March 2019) – 73 articles
Cover Story (view full-size image):
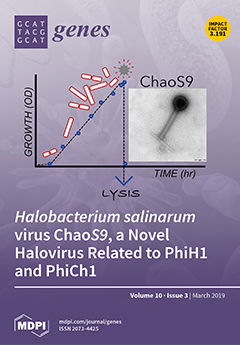
The unexpected lysis of a 1 m3 culture of Halobacterium salinarum strain S9 was found to be caused by a novel caudovirus, pictured in the right panel of the diagram. We named it ChaoS9, partly because of the damage it had caused, and sequenced its 55,145 bp dsDNA genome. The closest relatives were found to be the myohaloviruses phiH1 and phiCh1, both of which infect extremely halophilic archaea (Class Halobacteria). Strong conservation of the tail genes contrasts with major differences of the head genes. Even more surprising is the similarity of the major capsid protein with that of tailed halovirus HHTV-1. Presumably, the evolutionary history of ChaoS9 exemplifies widespread recombination between tailed haloviruses. Another curious feature are many, closely matching CRISPR spacers to ChaoS9 in metagenomic data from hypersaline Antarctic lakes. View this paper.
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue