

Data 2026, 11(5), 123; https://doi.org/10.3390/data11050123 - 20 May 2026
Abstract
Peptide-based cancer vaccines have emerged as a prominent focus in contemporary oncological research, as the quest for innovative cancer treatment modalities continues to gain momentum. A pivotal facet of their development is the precise delineation and characterization of immunogenic tumor antigens. In this
[...] Read more.
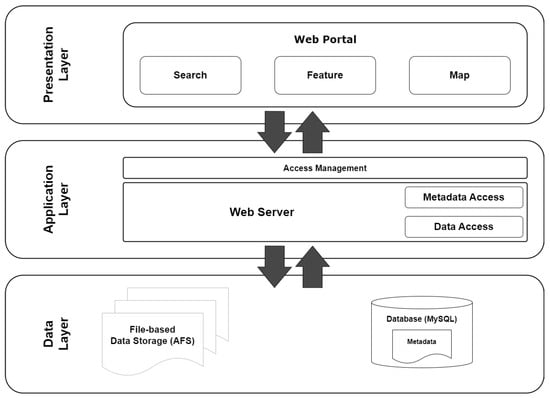
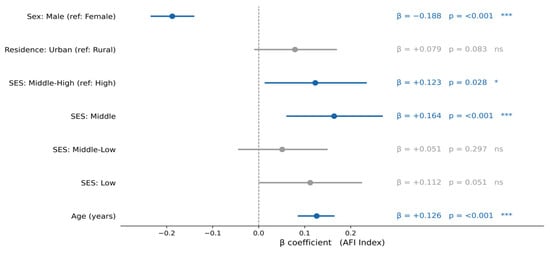
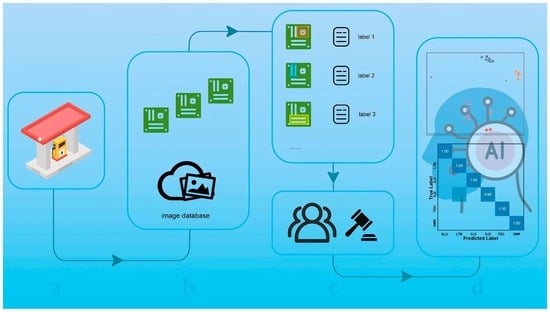
Peptide-based cancer vaccines have emerged as a prominent focus in contemporary oncological research, as the quest for innovative cancer treatment modalities continues to gain momentum. A pivotal facet of their development is the precise delineation and characterization of immunogenic tumor antigens. In this context, VaxiJen stands out as one of the most widely used and cited computational servers for predicting immunogenicity, making it an invaluable tool for in silico antigen prediction. However, the database underpinning VaxiJen’s predictions has not undergone a comprehensive update for over fifteen years. To address this, a systematic search of the PubMed database was conducted to identify scholarly articles reporting data on novel immunogenic proteins and peptides undergoing human testing. The corresponding sequences of these proteins and peptides were subsequently curated from UniProtKB. Therefore, in this study, we introduce an updated dataset encompassing a repertoire of tumor immunogens, comprising 546 full-length human proteins and 212 human tumor peptides, as well as tumor non-immunogens, comprising 548 full-length human proteins and 181 human tumor peptides. The recently compiled VaxiGen tumor dataset is openly accessible. Researchers can conveniently download, search, and process it. This dataset, when paired with a suitable negative dataset, can further serve as a valuable training set, thereby facilitating improved predictions of the potential immunogenicity of hitherto uncharacterized protein or peptide sequences.
Full article
(This article belongs to the Section Computational Biology, Bioinformatics, and Biomedical Data Science)
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}