



Big Data Cogn. Comput. 2026, 10(3), 75; https://doi.org/10.3390/bdcc10030075 (registering DOI) - 1 Mar 2026
Abstract
►
Show Figures
Semantic segmentation plays a pivotal role in autonomous driving, enabling pixel-level understanding of road scenes. Although transformer-based models such as SegFormer have shown exceptional performance on large datasets, their generalization to smaller and geographically diverse datasets remains underexplored. In this work, we analyze
[...] Read more.
Semantic segmentation plays a pivotal role in autonomous driving, enabling pixel-level understanding of road scenes. Although transformer-based models such as SegFormer have shown exceptional performance on large datasets, their generalization to smaller and geographically diverse datasets remains underexplored. In this work, we analyze the scalability and transferability of SegFormer variants (B3, B4, B5) using CamVid as the base dataset. We perform cross-dataset transfer learning to KITTI and IDD, evaluate class-level performance, and explore explainable AI via confidence heatmaps. Our findings show that SegFormer-B5 achieves the highest accuracy (
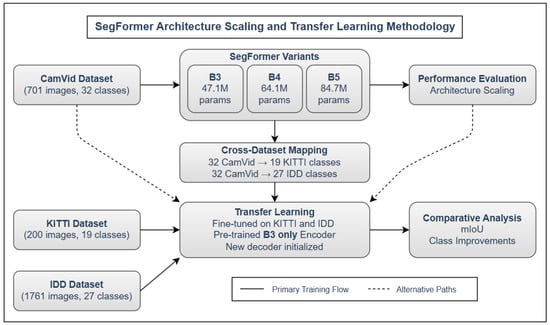
Figure 1















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}