


Genes, Volume 10, Issue 1 (January 2019) – 71 articles
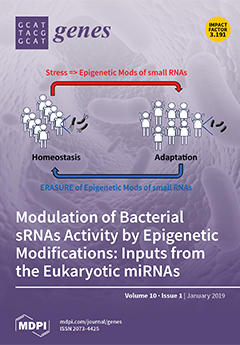
Cover Story (view full-size image):
How epigenetic Modifications (Mods) of small RNAs facilitate adaptation and the way back to homeostasis. This occurs all the way from bacteria (black bacilli from our gut loosing their pili) to humans (blue fellows raising their hands). View this paper.
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue