





Systems 2026, 14(6), 634; https://doi.org/10.3390/systems14060634 (registering DOI) - 2 Jun 2026
Abstract
Background: Science–practice knowledge co-production, grounded in mutual learning, is a key strategy for generating and integrating knowledge to support informed decision-making in the face of complex societal challenges. However, it remains unclear to what extent the general population recognizes the need for such
[...] Read more.
Background: Science–practice knowledge co-production, grounded in mutual learning, is a key strategy for generating and integrating knowledge to support informed decision-making in the face of complex societal challenges. However, it remains unclear to what extent the general population recognizes the need for such co-production. Methods: We conducted a quota-sampled survey (July-August 2021) among 3067 adult residents of the German-speaking countries in Europe (D-A-CH). Using multinomial regression models, we calculated odds ratios (OR) and 95% confidence intervals (95%CI), investigating correlates of agreement on the relevance of partnerships between science and practice. Results: In total, 81.8% of the sample expected science to provide clear results, and 90.1% agreed that complex challenges require science–practice knowledge co-production. In multivariable-adjusted models, agreement with the importance of science–practice co-production correlated positively with higher age (ORfully-agree = 1.04; 95%CI = 1.03–1.06), being male (versus being female), and residing in Austria and Germany (versus residing in Switzerland). It was also significantly higher among participants without a migration history (vs. first- or second-generation migrants), and higher educational attainment (ORfully-agree = 1.59; 95%CI = 1.08–2.33), and differed by several personality characteristics. Conclusions: Our findings indicate that a majority of respondents in the D-A-CH region view informed decision-making and policy development for complex challenges as requiring the collaboration and mutual learning between scientific and practice-based actors in addressing complex societal challenges. These findings suggest that educational and institutional interventions may contribute to strengthening collaboration between science and practice.
Full article
(This article belongs to the Special Issue Systems Approaches in Knowledge Management and Organizational Innovation)
►
Show Figures
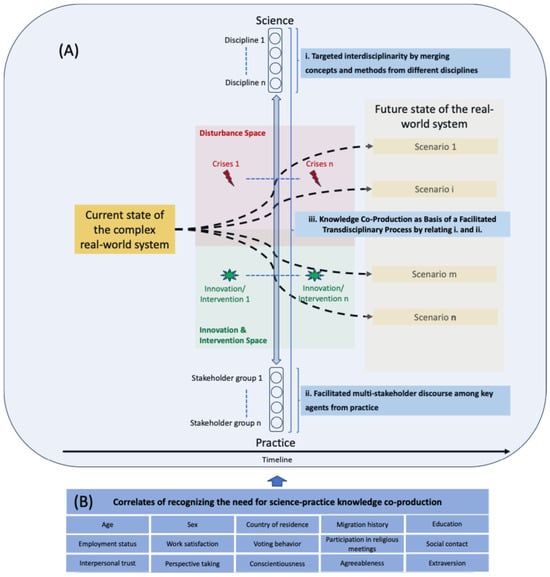
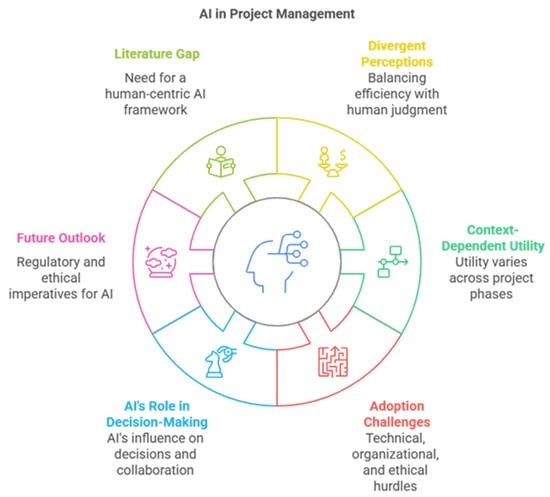
Figure 1




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}