



Information 2025, 16(6), 458; https://doi.org/10.3390/info16060458 - 29 May 2025
Cited by 3 | Viewed by 2360
Abstract
►
Show Figures
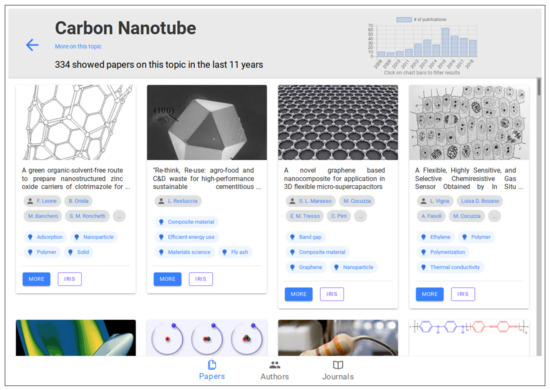
Malware continues to evolve rapidly, posing significant challenges to network security. Traditional signature-based detection methods often struggle to cope with advanced evasion techniques such as polymorphism, metamorphism, encryption, and stealth, which are commonly employed by cybercriminals. As a result, these conventional approaches frequently
[...] Read more.
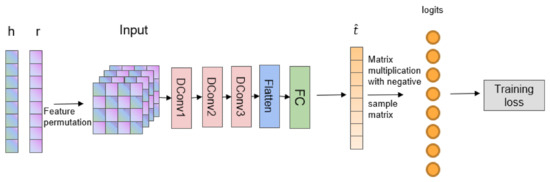
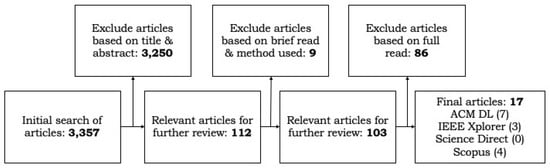
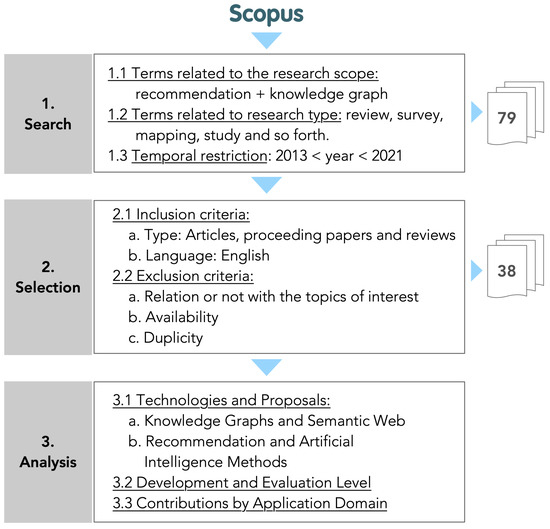
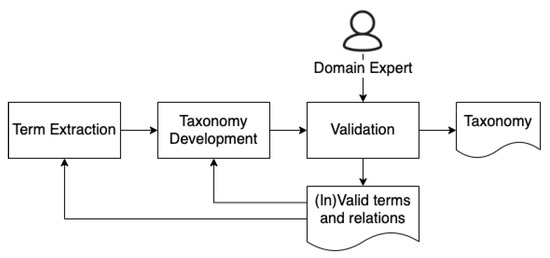
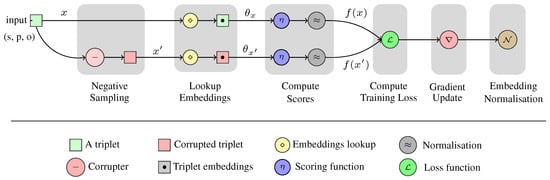
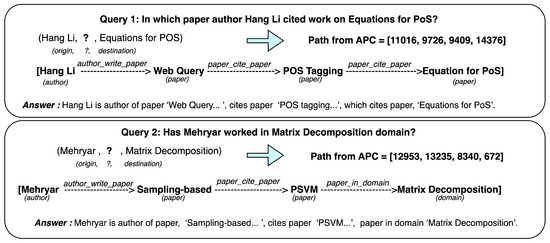
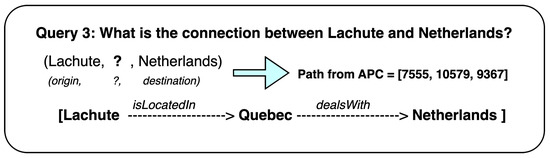
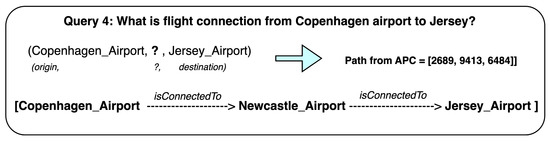
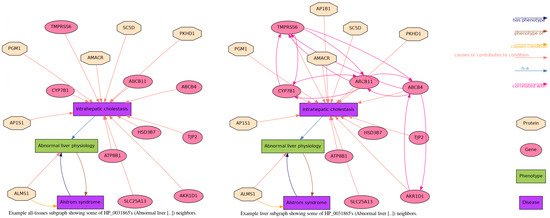
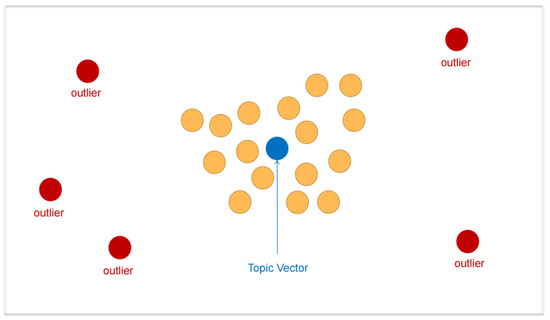
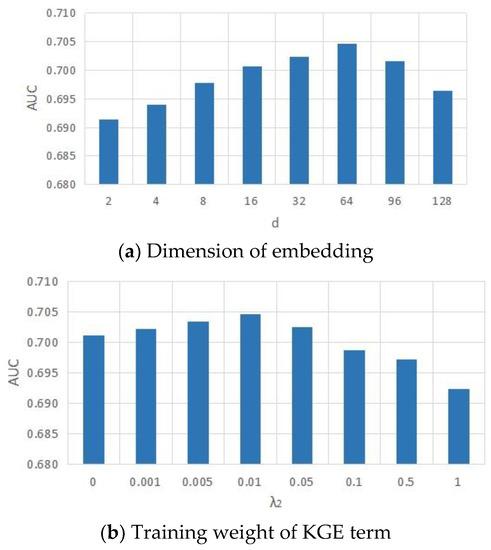
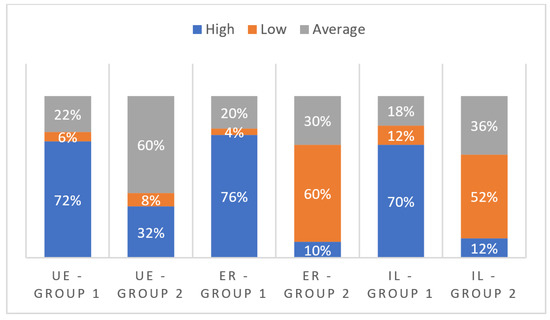
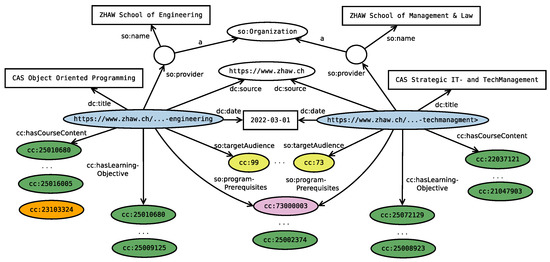
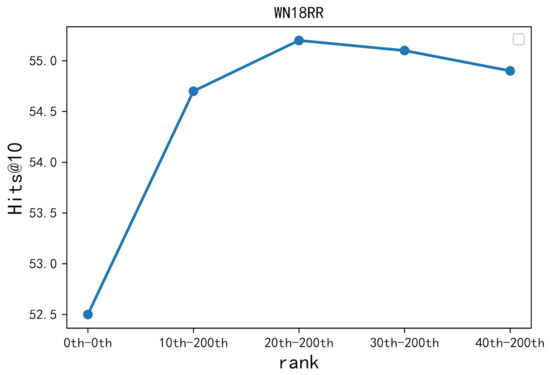
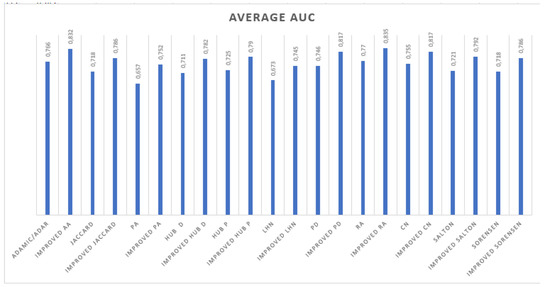
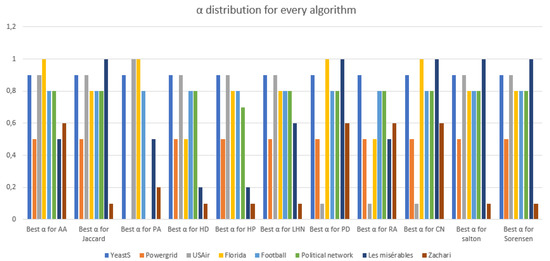
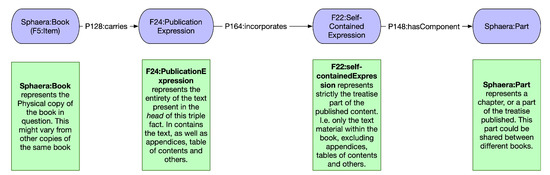
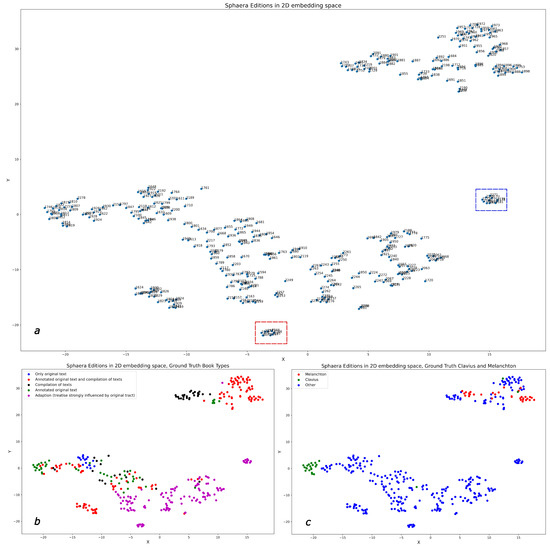
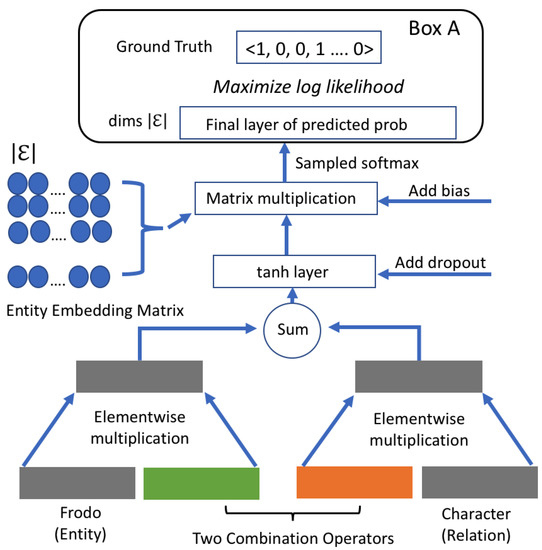
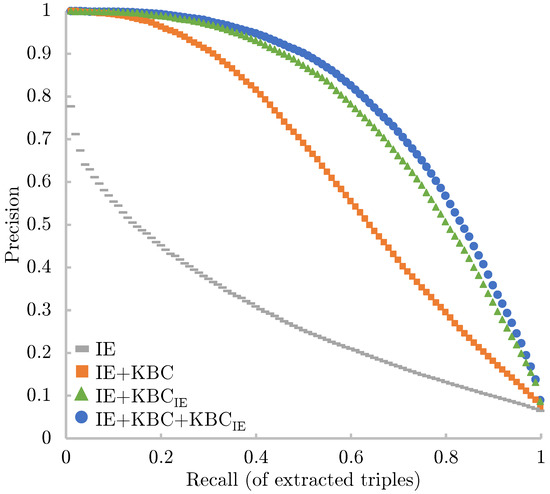
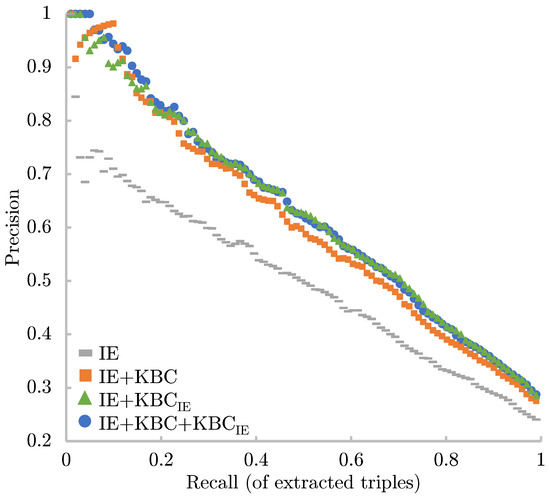
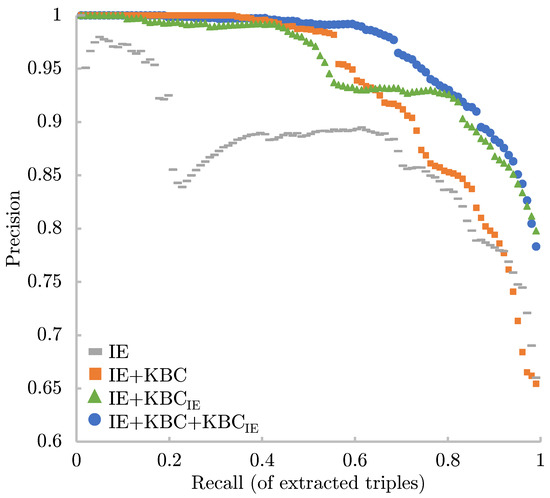
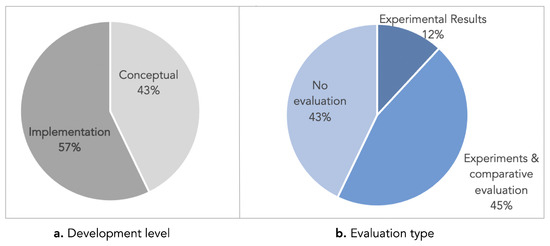
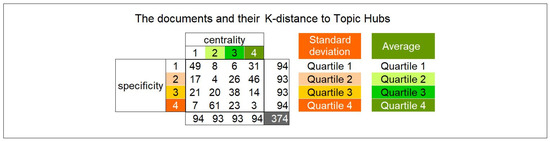
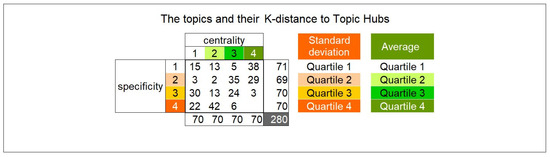
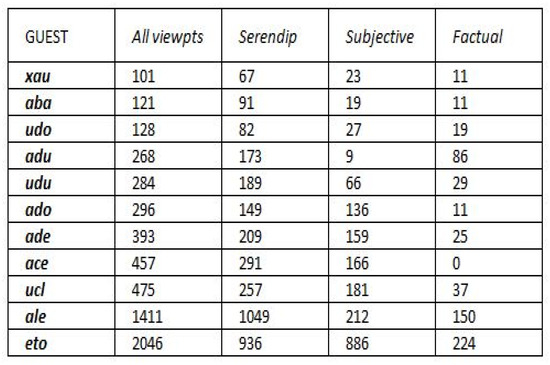
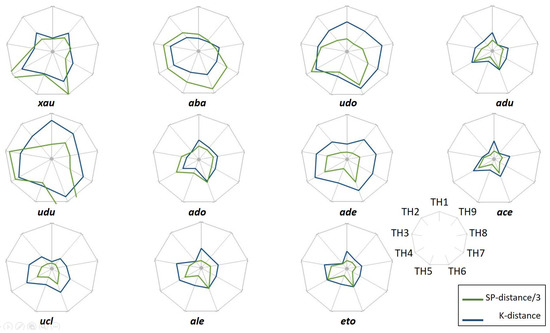
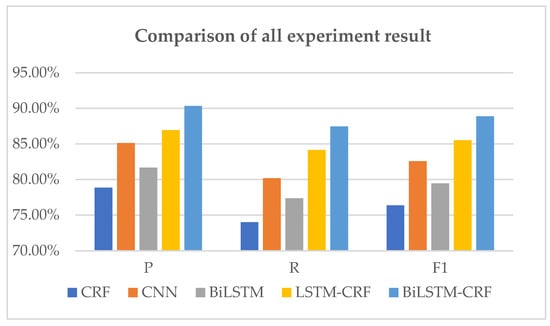
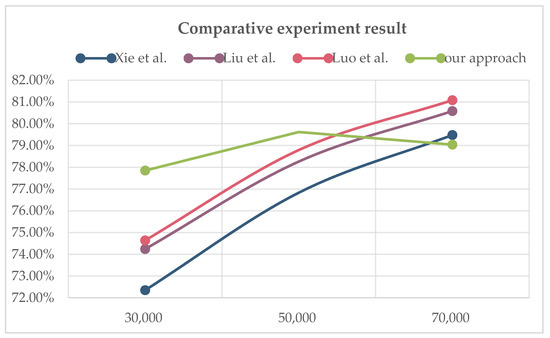
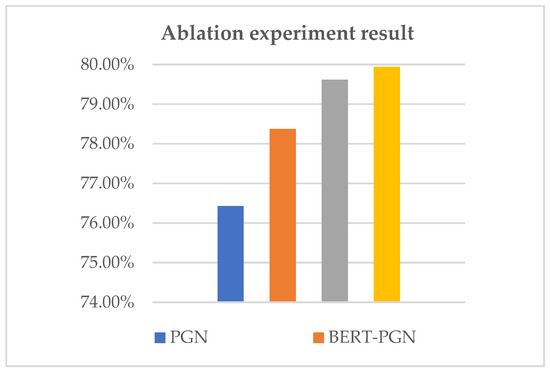
Malware continues to evolve rapidly, posing significant challenges to network security. Traditional signature-based detection methods often struggle to cope with advanced evasion techniques such as polymorphism, metamorphism, encryption, and stealth, which are commonly employed by cybercriminals. As a result, these conventional approaches frequently fail to detect newly emerging malware variants in a timely manner. To address this limitation, Zero-Shot Learning (ZSL) has emerged as a promising alternative, offering improved classification capabilities for previously unseen malware samples. ZSL models leverage auxiliary semantic information and binary feature representations to enhance the recognition of novel threats. This study proposes a Transductive Zero-Shot Learning (TZSL) model based on the Vector Quantized Variational Autoencoder (VQ-VAE) architecture, integrated with a malware knowledge graph constructed from sandbox behavioral analysis of ransomware families. The model is further optimized through hyperparameter tuning to maximize classification performance. Evaluation metrics include per-family classification accuracy, precision, recall, F1-score, and Receiver Operating Characteristic (ROC) curves to ensure robust and reliable detection outcomes. In particular, the harmonic mean (H-mean) metric from the Generalized Zero-Shot Learning (GZSL) framework is introduced to jointly evaluate the model’s performance on both seen and unseen classes, offering a more holistic view of its generalization ability. The experimental results demonstrate that the proposed VQ-VAE model achieves an F1-score of 93.5% in ransomware classification, significantly outperforming other baseline models such as LeNet-5 (65.6%), ResNet-50 (71.8%), VGG-16 (74.3%), and AlexNet (65.3%). These findings highlight the superior capability of the VQ-VAE-based TZSL approach in detecting novel malware variants, improving detection accuracy while reducing false positives.
Full article

Figure 1


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}