
Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey



Abstract
:1. Introduction
1.1. Motivation: Why Simple Questions?
1.2. Related Surveys
1.3. Aim of the Survey
- is the first one focusing on the state-of-the-art of KGSQA;
- elaborates in detail the challenges, techniques, solution performance, and trends of KGSQA, and in particular, a variety of deep learning models used in KGSQA; and
- provides new key recommendations, which are not only useful for developing KGSQA, but can also be extended to more general KGQA systems.
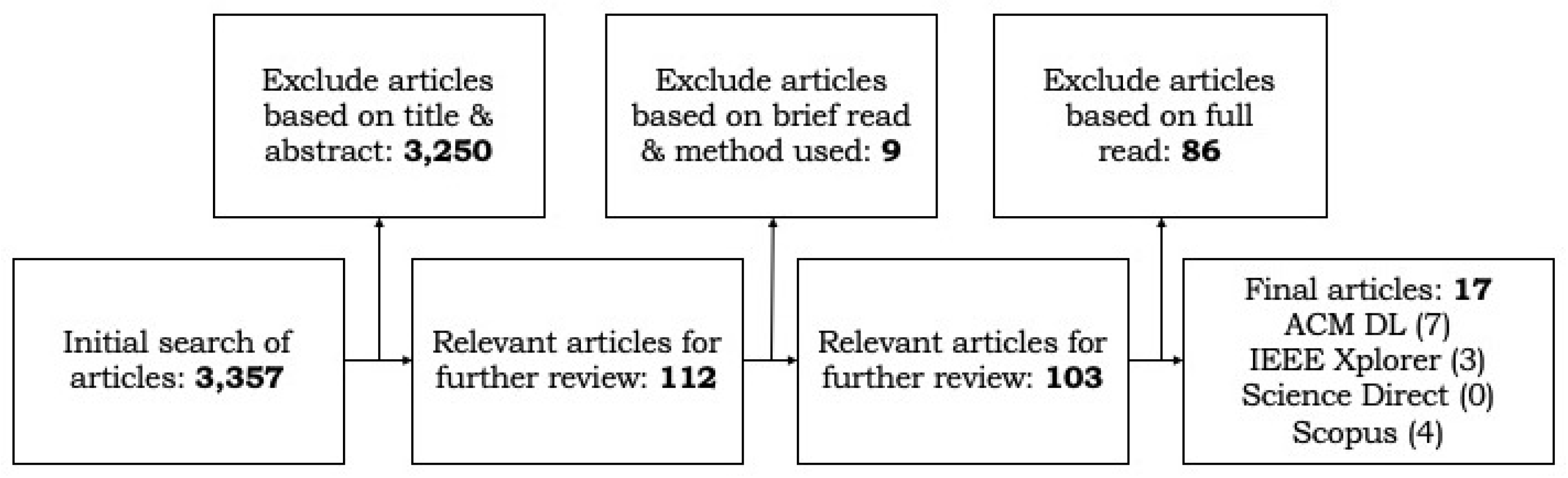
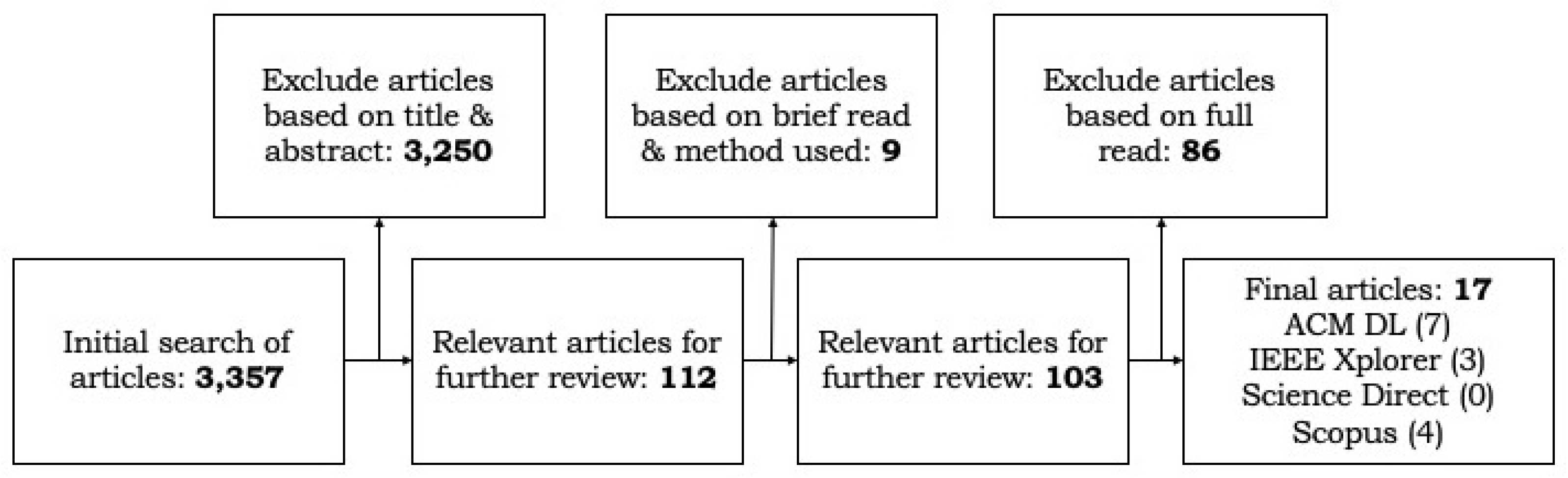
2. Methodology
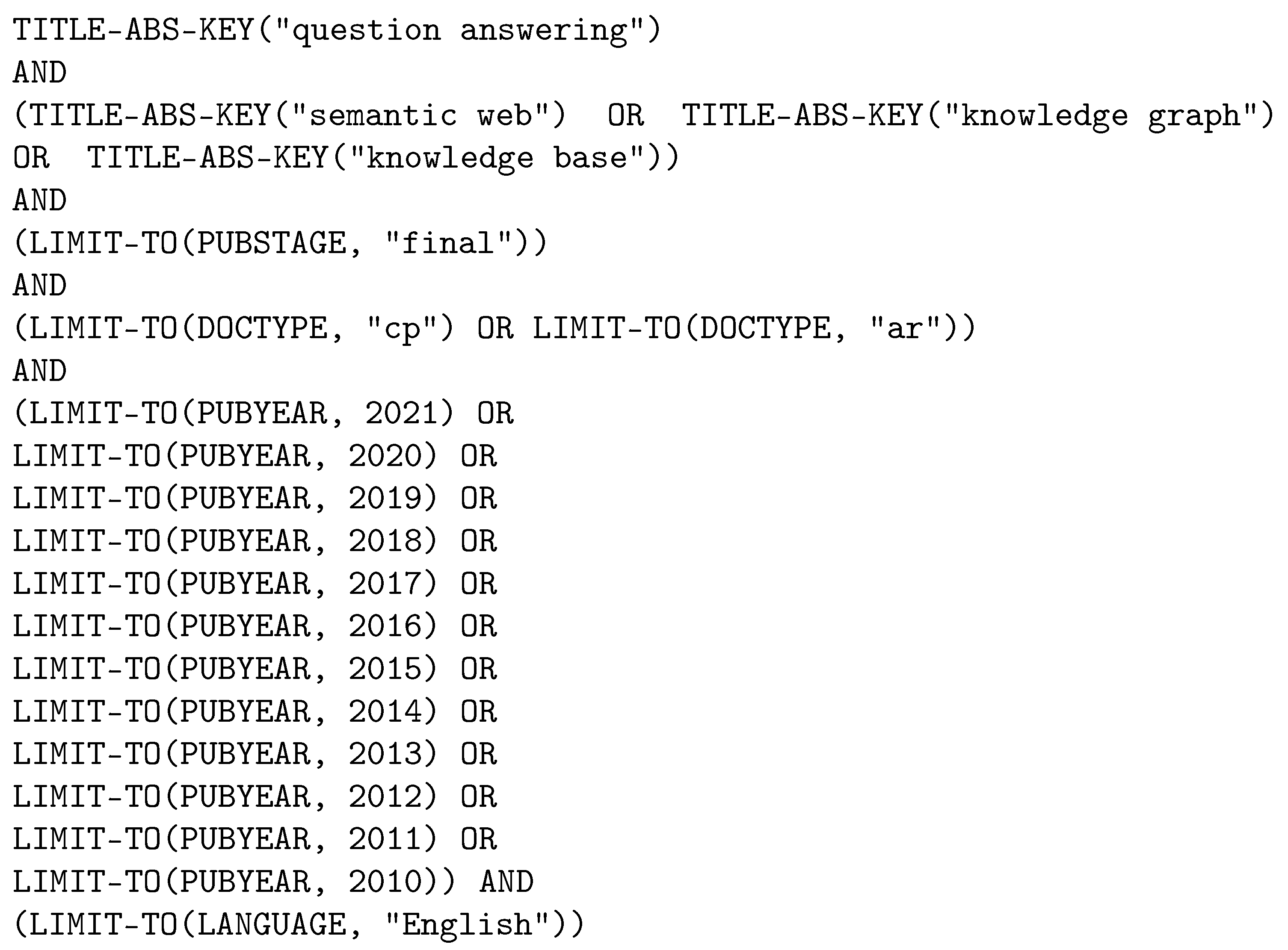
2.1. Initial Search
- (i)
- matches “question answering”; and
- (ii)
- matches either “semantic web”, or “knowledge graph”, or “knowledge base”.
2.2. Article Selection Process
2.2.1. (Further) Selection Based on Title and Abstract
2.2.2. Selection through Quick Reading
2.2.3. Selection through Full Reading
3. Results
3.1. Terminology
3.2. Tasks and Challenges in KGSQA
3.2.1. Entity and Relation Detection, Prediction, and Linking
3.2.2. Answer Matching
3.3. State-of-the-Art Approaches in KGSQA
4. Discussion
4.1. Existing KGSQA Systems with Its Models, Achievements, and Strengths and Weaknesses
4.1.1. Bordes et al.’s System
4.1.2. Yin et al.’s System
4.1.3. Dai et al.’s System
4.1.4. He and Golub’ System
4.1.5. Lukovnikov et al.’s System
4.1.6. Zhu et al.’s System
4.1.7. Türe and Jojic’s System
4.1.8. Chao and Li’s System
4.1.9. Zhang et al.’s System
4.1.10. Huang et al.’s System
4.1.11. Wang et al.’s System
4.1.12. Lan et al.’s System
4.1.13. Lukovnikov et al.’s System
4.1.14. Zhao et al.’s System
4.1.15. Luo et al.’s System
4.1.16. Zhang et al.’s System
4.1.17. Li et al.’s System
4.2. Open Challenges in the Future Research
4.2.1. Paraphrase Issue
4.2.2. Ambiguity Issue
4.2.3. Benchmark Data Set Issue
4.2.4. Computational Cost Issue
4.3. Recommendation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Data Set | Number of Questions | KG |
|---|---|---|
| QALD-1 | Unavailable | Unavailable |
| QALD-2 | Unavailable | Unavailable |
| QALD-3 [67] | 100 for each KG | DBPedia, MusicBrainz |
| QALD-4 [68] | 200 | DBPedia |
| QALD-5 [69] | 300 | DBPedia |
| QALD-6 [70] | 350 | DBPedia |
| QALD-7 [71] | 215 | DBPedia |
| QALD-8 [72] | 219 | DBPedia |
| QALD-9 [73] | 408 | DBPedia |
| SimpleQuestions | >100 k | Freebase [20] |
| 49 k | Wikidata [21] | |
| 43 k | DBPedia [22] | |
| LC-QuAD 1.0 [74] | 5 k | DBPedia |
| LC-QuAD 2.0 [19] | 30 k | DBPedia and Wikidata |
| WebQuestions [17] | 6 k | Freebase |
| Free197 [75] | 917 | Freebase |
| ComplexQuestions [76] | 150 | Freebase |
| ComplexWebQuestionsSP [18] | 34 k | Freebase |
| ConvQuestions [77] | 11 k | Wikidata |
| TempQuestions [78] | 1 k | Freebase |
| NLPCC-ICCPOL [79] | 24 + k | NLPCC-ICCPOL |
| BioASQ | 100 per-task | Freebase |

Appendix A.1. QALD
| Series | Challenges |
|---|---|
| QALD-1 | Heterogeneous and distributed interlinked data |
| QALD-2 | Linked data interaction |
| QALD-3 | Multilingual QA and ontology lexicalization |
| QALD-4, 5, and 6 | Multilingual on hybrid of interlinked data sets (structured and unstructured data) |
| QALD-7 | HOBBIT for big linked data |
| QALD-8 and 9 | Web of data (GERBIL QA challenge) |
Appendix A.2. SimpleQuestions
Appendix A.3. LC-QuAD
Appendix A.4. WebQuestions
Appendix A.5. Free917
Appendix A.6. ComplexQuestions
Appendix A.7. ComplexWebQuestionsSP
Appendix A.8. ConvQuestions
Appendix A.9. TempQuestions
Appendix A.10. NLPCC-ICCPOL
Appendix A.11. BioASQ
| Publication Venue | Step 1 | Step 2 | Step 3 |
|---|---|---|---|
| SIGIR | 4 | 3 | 0 |
| WWW | 12 | 12 | 1 |
| TOIS | 1 | 1 | 1 |
| CIKM | 10 | 9 | 1 |
| VLDB | 2 | 2 | 0 |
| SIGMOD | 3 | 3 | 0 |
| IMCOM | 2 | 2 | 0 |
| SBD | 1 | 1 | 0 |
| EDBT | 1 | 1 | 0 |
| SEM | 2 | 1 | 0 |
| GIR | 1 | 1 | 0 |
| WSDM | 1 | 1 | 1 |
| SIGWEB | 1 | 0 | 0 |
| IHI | 1 | 1 | 0 |
| TURC | 1 | 1 | 0 |
| CoRR | 3 | 3 | 3 |
| Number of articles from ACM Digital Library | 46 | 42 | 7 |
| BESC | 1 | 1 | 1 |
| DCABES | 1 | 1 | 0 |
| ICCI*CC | 1 | 1 | 0 |
| ICCIA | 2 | 2 | 0 |
| ICDE | 1 | 1 | 0 |
| ICINCS | 1 | 1 | 0 |
| ICITSI | 1 | 1 | 0 |
| ICSC | 2 | 2 | 0 |
| IEEE Access | 3 | 3 | 1 |
| IEEE Intelligent Sys tems | 1 | 0 | 0 |
| IEEE TKDE | 1 | 1 | 0 |
| IEEE/ACM TASLP | 1 | 1 | 1 |
| IJCNN | 1 | 0 | 0 |
| ISCID | 1 | 1 | 0 |
| PIC | 1 | 1 | 0 |
| TAAI | 1 | 1 | 0 |
| Number of articles from IEEE Xplore | 20 | 18 | 3 |
| Artificial Intelligent in Medicine | 1 | 0 | 0 |
| Experts Systems with Applications | 3 | 2 | 0 |
| Information Processing and Management | 1 | 1 | 0 |
| Informations Sciences | 2 | 1 | 0 |
| Journal of Web Semantics | 2 | 2 | 0 |
| Neural Networks | 1 | 1 | 0 |
| Neurocomputing | 1 | 1 | 0 |
| Number of articles from Science Direct | 11 | 8 | 0 |
| Publication Venue | Step 1 | Step 2 | Step 3 |
|---|---|---|---|
| EMNLP | 2 | 2 | 1 |
| Turkish Journal of Electrical Engineering and Computer Sciences | 1 | 1 | 0 |
| Data Technologies and Applications | 1 | 1 | 0 |
| ICDM | 1 | 1 | 0 |
| IHMSC | 1 | 1 | 0 |
| AICPS | 1 | 1 | 0 |
| WETICE | 1 | 1 | 0 |
| Cluster Computing | 1 | 1 | 0 |
| ICWI | 1 | 1 | 0 |
| Data Science and Engineering | 1 | 1 | 0 |
| LNCS | 3 | 3 | 1 |
| NAACL | 2 | 2 | 0 |
| CEUR Workshop Proceedings | 3 | 3 | 0 |
| LNI | 1 | 1 | 0 |
| SWJ | 1 | 1 | 0 |
| PLOS ONE | 1 | 1 | 0 |
| Information (Switzerland) | 1 | 1 | 0 |
| SEKE | 1 | 1 | 0 |
| ICSC | 1 | 1 | 0 |
| ISWC | 2 | 2 | 0 |
| COOLING | 1 | 1 | 0 |
| ACL | 2 | 2 | 2 |
| Knowledge-Based Systems | 1 | 1 | 0 |
| IJCNW | 1 | 1 | 1 |
| WWW | 1 | 1 | 1 |
| Number of articles from Scopus | 35 | 35 | 7 |
| Total (# ACM Digital Library + # IEEE Xplore + # Scopus) | 112 | 103 | 17 |
References
- Yang, M.; Lee, D.; Park, S.; Rim, H. Knowledge-based question answering using the semantic embedding space. Expert Syst. Appl. 2015, 42, 9086–9104. [Google Scholar] [CrossRef]
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Hybrid Question Answering over Knowledge Base and Free Text. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference: Technical Papers, Osaka, Japan, 11–16 December 2016; Calzolari, N., Matsumoto, Y., Prasad, R., Eds.; ACL: Stroudsburg, PA, USA, 2016; pp. 2397–2407. [Google Scholar]
- Zheng, W.; Yu, J.X.; Zou, L.; Cheng, H. Question Answering Over Knowledge Graphs: Question Understanding Via Template Decomposition. Proc. VLDB Endow. PVLDB 2018, 11, 1373–1386. [Google Scholar] [CrossRef] [Green Version]
- Hu, S.; Zou, L.; Yu, J.X.; Wang, H.; Zhao, D. Answering Natural Language Questions by Subgraph Matching over Knowledge Graphs. IEEE Trans. Knowl. Data Eng. 2018, 30, 824–837. [Google Scholar] [CrossRef]
- Zhang, X.; Meng, M.; Sun, X.; Bai, Y. FactQA: Question answering over domain knowledge graph based on two-level query expansion. Data Technol. Appl. 2020, 54, 34–63. [Google Scholar] [CrossRef]
- Bakhshi, M.; Nematbakhsh, M.; Mohsenzadeh, M.; Rahmani, A.M. Data-driven construction of SPARQL queries by approximate question graph alignment in question answering over knowledge graphs. Expert Syst. Appl. 2020, 146, 113205. [Google Scholar] [CrossRef]
- Zhang, H.; Cai, J.; Xu, J.; Wang, J. Complex Question Decomposition for Semantic Parsing. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July– 2August 2019; Volume 1: Long Papers. Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4477–4486. [Google Scholar] [CrossRef]
- Ji, G.; Wang, S.; Zhang, X.; Feng, Z. A Fine-grained Complex Question Translation for KBQA. In Proceedings of the ISWC 2020 Demos and Industry Tracks: From Novel Ideas to Industrial Practice Co-Located with 19th International Semantic Web Conference (ISWC 2020), Globally Online, 1–6 November 2020; (UTC). Taylor, K.L., Gonçalves, R.S., Lécué, F., Yan, J., Eds.; 2020; Volume 2721, pp. 194–199. [Google Scholar]
- Shin, S.; Lee, K. Processing knowledge graph-based complex questions through question decomposition and recomposition. Inf. Sci. 2020, 523, 234–244. [Google Scholar] [CrossRef]
- Lu, X.; Pramanik, S.; Roy, R.S.; Abujabal, A.; Wang, Y.; Weikum, G. Answering Complex Questions by Joining Multi-Document Evidence with Quasi Knowledge Graphs. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, 21–25 July 2019; Piwowarski, B., Chevalier, M., Gaussier, É., Maarek, Y., Nie, J., Scholer, F., Eds.; ACM: New York, NY, USA, 2019; pp. 105–114. [Google Scholar] [CrossRef] [Green Version]
- Vakulenko, S.; Garcia, J.D.F.; Polleres, A.; de Rijke, M.; Cochez, M. Message Passing for Complex Question Answering over Knowledge Graphs. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November 2019; Zhu, W., Tao, D., Cheng, X., Cui, P., Rundensteiner, E.A., Carmel, D., He, Q., Yu, J.X., Eds.; ACM: New York, NY, USA, 2019; pp. 1431–1440. [Google Scholar] [CrossRef] [Green Version]
- Hu, S.; Zou, L.; Yu, J.X.; Wang, H.; Zhao, D. Answering Natural Language Questions by Subgraph Matching over Knowledge Graphs (Extended Abstract). In Proceedings of the 34th IEEE International Conference on Data Engineering, ICDE 2018, Paris, France, 16–19 April 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 1815–1816. [Google Scholar] [CrossRef]
- Zhu, S.; Cheng, X.; Su, S.; Lang, S. Knowledge-based Question Answering by Jointly Generating, Copying and Paraphrasing. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, CIKM 2017, Singapore, 6–10 November 2017; Lim, E., Winslett, M., Sanderson, M., Fu, A.W., Sun, J., Culpepper, J.S., Lo, E., Ho, J.C., Donato, D., Agrawal, R., et al., Eds.; ACM: Washington, DC, USA, 2017; pp. 2439–2442. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, Y.; Mao, Y.; Huai, J. Question Answering in Knowledge Bases: A Verification Assisted Model with Iterative Training. ACM Trans. Inf. Syst. 2019, 37, 40:1–40:26. [Google Scholar] [CrossRef]
- Lan, Y.; Wang, S.; Jiang, J. Knowledge Base Question Answering With a Matching-Aggregation Model and Question-Specific Contextual Relations. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1629–1638. [Google Scholar] [CrossRef]
- Türe, F.; Jojic, O. No Need to Pay Attention: Simple Recurrent Neural Networks Work! In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, 9–11 September 2017; Palmer, M., Hwa, R., Riedel, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2866–2872. [Google Scholar] [CrossRef]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic Parsing on Freebase from Question-Answer Pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, Grand Hyatt Seattle. Seattle, WA, USA, 18–21 October 2013; A Meeting of SIGDAT, a Special Interest Group of the ACL: Stroudsburg, PA, USA, 2013; pp. 1533–1544. [Google Scholar]
- Talmor, A.; Berant, J. The Web as a Knowledge-Base for Answering Complex Questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, LA, USA, 1–6 June 2018; Volume 1 (Long Papers). Walker, M.A., Ji, H., Stent, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 641–651. [Google Scholar] [CrossRef] [Green Version]
- Dubey, M.; Banerjee, D.; Abdelkawi, A.; Lehmann, J. LC-QuAD 2.0: A Large Dataset for Complex Question Answering over Wikidata and DBpedia. In Proceedings of the Semantic Web—ISWC 2019—18th International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; Proceedings, Part II; Lecture Notes in Computer Science. Ghidini, C., Hartig, O., Maleshkova, M., Svátek, V., Cruz, I.F., Hogan, A., Song, J., Lefrançois, M., Gandon, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11779, pp. 69–78. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Chopra, S.; Weston, J. Large-scale Simple Question Answering with Memory Networks. arXiv 2015, arXiv:1506.02075. [Google Scholar]
- Diefenbach, D.; Tanon, T.P.; Singh, K.D.; Maret, P. Question Answering Benchmarks for Wikidata. In Proceedings of the ISWC 2017 Posters & Demonstrations and Industry Tracks co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, 23–25 October 2017; CEUR Workshop Proceedings. Nikitina, N., Song, D., Fokoue, A., Haase, P., Eds.; 2017; Volume 1963. [Google Scholar]
- Azmy, M.; Shi, P.; Lin, J.; Ilyas, I.F. Farewell Freebase: Migrating the SimpleQuestions Dataset to DBpedia. In Proceedings of the 27th International Conference on Computational Linguistics, COLING 2018, Santa Fe, NM, USA, 20–26 August 2018; Bender, E.M., Derczynski, L., Isabelle, P., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 2093–2103. [Google Scholar]
- Höffner, K.; Walter, S.; Marx, E.; Usbeck, R.; Lehmann, J.; Ngomo, A.N. Survey on challenges of Question Answering in the Semantic Web. Semant. Web 2017, 8, 895–920. [Google Scholar] [CrossRef] [Green Version]
- Diefenbach, D.; López, V.; Singh, K.D.; Maret, P. Core techniques of question answering systems over knowledge bases: A survey. Knowl. Inf. Syst. 2018, 55, 529–569. [Google Scholar] [CrossRef]
- Fu, B.; Qiu, Y.; Tang, C.; Li, Y.; Yu, H.; Sun, J. A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges. arXiv 2020, arXiv:2007.13069. [Google Scholar]
- Cimiano, P.; Minock, M. Natural Language Interfaces: What Is the Problem?—A Data-Driven Quantitative Analysis. In Proceedings of the Natural Language Processing and Information Systems, 14th International Conference on Applications of Natural Language to Information Systems, NLDB 2009, Saarbrücken, Germany, 24–26 June 2009; Revised Papers; Lecture Notes in Computer Science. Horacek, H., Métais, E., Muñoz, R., Wolska, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5723, pp. 192–206. [Google Scholar] [CrossRef]
- López, V.; Uren, V.S.; Sabou, M.; Motta, E. Is Question Answering fit for the Semantic Web? A survey. Semant. Web 2011, 2, 125–155. [Google Scholar] [CrossRef] [Green Version]
- Freitas, A.; Curry, E.; Oliveira, J.G.; O’Riain, S. Querying Heterogeneous Datasets on the Linked Data Web: Challenges, Approaches, and Trends. IEEE Internet Comput. 2012, 16, 24–33. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutiérrez, C.; Gayo, J.E.L.; Kirrane, S.; Neumaier, S.; Polleres, A.; et al. Knowledge Graphs. arXiv 2020, arXiv:abs/2003.02320. [Google Scholar]
- Cyganiak, R.; Wood, D.; Lanthaler, M. (Eds.) RDF 1.1 Concepts and Abstract Syntax; W3C Recommendation. 25 February 2014. Available online: http://travesia.mecd.es/portalnb/jspui/bitstream/10421/2427/1/RDF%201.pdf (accessed on 27 June 2021).
- Harris, S.; Seaborne, A. (Eds.) SPARQL 1.1 Query Language; W3C Recommendation. 21 March 2013. Available online: https://www.w3.org/TR/sparql11-query/ (accessed on 27 June 2021).
- Zou, L.; Huang, R.; Wang, H.; Yu, J.X.; He, W.; Zhao, D. Natural language question answering over RDF: A graph data driven approach. In Proceedings of the International Conference on Management of Data, SIGMOD 2014, Snowbird, UT, USA, 22–27 June 2014; Dyreson, C.E., Li, F., Özsu, M.T., Eds.; ACM: New York, NY, USA, 2014; pp. 313–324. [Google Scholar] [CrossRef]
- Shin, S.; Jin, X.; Jung, J.; Lee, K. Predicate constraints based question answering over knowledge graph. Inf. Process. Manag. 2019, 56, 445–462. [Google Scholar] [CrossRef]
- Unger, C.; Bühmann, L.; Lehmann, J.; Ngomo, A.N.; Gerber, D.; Cimiano, P. Template-based question answering over RDF data. In Proceedings of the 21st World Wide Web Conference 2012, WWW 2012, Lyon, France, 16–20 April 2012; Mille, A., Gandon, F.L., Misselis, J., Rabinovich, M., Staab, S., Eds.; ACM: New York, NY, USA, 2012; pp. 639–648. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge Graph Embedding Based Question Answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM 2019, Melbourne, VIC, Australia, 11–15 February 2019; Culpepper, J.S., Moffat, A., Bennett, P.N., Lerman, K., Eds.; ACM: New York, NY, USA, 2019; pp. 105–113. [Google Scholar] [CrossRef]
- Dai, Z.; Li, L.; Xu, W. CFO: Conditional Focused Neural Question Answering with Large-scale Knowledge Bases. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Berlin, Germany, 7–12 August 2016; Volume 1: Long Papers. The Association for Computer Linguistics: Stroudsburg, PA, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Yin, W.; Yu, M.; Xiang, B.; Zhou, B.; Schütze, H. Simple Question Answering by Attentive Convolutional Neural Network. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference: Technical Papers, Osaka, Japan, 11–16 December 2016; Calzolari, N., Matsumoto, Y., Prasad, R., Eds.; ACL, 2016; pp. 1746–1756. [Google Scholar]
- Chao, Z.; Li, L. The Combination of Context Information to Enhance Simple Question Answering. In Proceedings of the 5th International Conference on Behavioral, Economic, and Socio-Cultural Computing, BESC 2018, Kaohsiung, Taiwan, 12–14 November 2018; IEEE: Kaohsiung, Taiwan, 2018; pp. 109–114. [Google Scholar] [CrossRef] [Green Version]
- Lukovnikov, D.; Fischer, A.; Lehmann, J. Pretrained Transformers for Simple Question Answering over Knowledge Graphs. In Proceedings of the Semantic Web—ISWC 2019—18th International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; Proceedings, Part I; Lecture Notes in Computer Science. Ghidini, C., Hartig, O., Maleshkova, M., Svátek, V., Cruz, I.F., Hogan, A., Song, J., Lefrançois, M., Gandon, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11778, pp. 470–486. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Chung, T.; Goyal, A.K.; Metallinou, A. Simple Question Answering with Subgraph Ranking and Joint-Scoring. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 324–334. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Zhang, M.; Chao, Z.; Xiang, J. Using context information to enhance simple question answering. World Wide Web 2021, 24, 249–277. [Google Scholar] [CrossRef]
- He, X.; Golub, D. Character-Level Question Answering with Attention. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, TX, USA, 1–4 November 2016; Su, J., Carreras, X., Duh, K., Eds.; The Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1598–1607. [Google Scholar] [CrossRef]
- Lukovnikov, D.; Fischer, A.; Lehmann, J.; Auer, S. Neural Network-based Question Answering over Knowledge Graphs on Word and Character Level. In Proceedings of the 26th International Conference on World Wide Web, WWW 2017, Perth, Australia, 3–7 April 2017; Barrett, R., Cummings, R., Agichtein, E., Gabrilovich, E., Eds.; ACM: New York, NY, USA, 2017; pp. 1211–1220. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Ling, Z.; Hu, Y. Knowledge Base Question Answering With Attentive Pooling for Question Representation. IEEE Access 2019, 7, 46773–46784. [Google Scholar] [CrossRef]
- Luo, D.; Su, J.; Yu, S. A BERT-based Approach with Relation-aware Attention for Knowledge Base Question Answering. In Proceedings of the 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, C.; Zhou, D.; He, Y.; Zhang, M. A Bayesian end-to-end model with estimated uncertainties for simple question answering over knowledge bases. Comput. Speech Lang. 2021, 66, 101167. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S.; Song, Y.; Rim, H. Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, EMNLP 2008, Proceedings of the Conference, Honolulu, HI, USA, 25–27 October 2008; A Meeting of SIGDAT, A Special Interest Group of the ACL. ACL: Stroudsburg, PA, USA, 2008; pp. 410–418. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A.C. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Aggarwal, C.C. Neural Networks and Deep Learning—A Textbook; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. 2020. Available online: https://d2l.ai (accessed on 27 June 2021).
- Lin, T.; Etzioni, O. Entity Linking at Web Scale. In Proceedings of the Joint Workshop on Automatic Knowledge Base Construction and Web-Scale Knowledge Extraction, AKBC-WEKEX@NAACL-HLT 2012, Montrèal, QC, Canada, 7–8 June 2012; Fan, J., Hoffman, R., Kalyanpur, A., Riedel, S., Suchanek, F.M., Talukdar, P.P., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 84–88. [Google Scholar]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; Burges, C.J.C., Bottou, L., Ghahramani, Z., Weinberger, K.Q., Eds.; MIT Press: Cambridge, MA, USA, 2013; pp. 2787–2795. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Camacho-Collados, J.; Pilehvar, M.T. From Word To Sense Embeddings: A Survey on Vector Representations of Meaning. J. Artif. Intell. Res. 2018, 63, 743–788. [Google Scholar] [CrossRef] [Green Version]
- Goyal, P.; Ferrara, E. Graph embedding techniques, applications, and performance: A survey. Knowl. Based Syst. 2018, 151, 78–94. [Google Scholar] [CrossRef] [Green Version]
- Nickel, M.; Tresp, V.; Kriegel, H. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; Getoor, L., Scheffer, T., Eds.; Omnipress: Madison, WI, USA, 2011; pp. 809–816. [Google Scholar]
- García-Durán, A.; Bordes, A.; Usunier, N. Effective Blending of Two and Three-way Interactions for Modeling Multi-relational Data. In Proceedings of the Machine Learning and Knowledge Discovery in Databases—European Conference, ECML PKDD 2014, Nancy, France, 15–19 September 2014; Proceedings, Part I; Lecture Notes in Computer Science. Calders, T., Esposito, F., Hüllermeier, E., Meo, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8724, pp. 434–449. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Brodley, C.E., Stone, P., Eds.; AAAI Press: Menlo Park, CA, USA, 2014; pp. 1112–1119. [Google Scholar]
- He, S.; Liu, K.; Ji, G.; Zhao, J. Learning to Represent Knowledge Graphs with Gaussian Embedding. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management, CIKM 2015, Melbourne, VIC, Australia, 19–23 October 2015; Bailey, J., Moffat, A., Aggarwal, C.C., de Rijke, M., Kumar, R., Murdock, V., Sellis, T.K., Yu, J.X., Eds.; ACM: New York, NY, USA, 2015; pp. 623–632. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph and Text Jointly Embedding. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; A Meeting of SIGDAT, a Special Interest Group of the ACL. Moschitti, A., Pang, B., Daelemans, W., Eds.; ACL, 2014; pp. 1591–1601. [Google Scholar] [CrossRef] [Green Version]
- Sherkat, E.; Milios, E.E. Vector Embedding of Wikipedia Concepts and Entities. In Proceedings of the Natural Language Processing and Information Systems—22nd International Conference on Applications of Natural Language to Information Systems, NLDB 2017, Liège, Belgium, 21–23 June 2017; Lecture Notes in Computer Science. Frasincar, F., Ittoo, A., Nguyen, L.M., Métais, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10260, pp. 418–428. [Google Scholar] [CrossRef] [Green Version]
- Camacho-Collados, J.; Pilehvar, M.T.; Navigli, R. Nasari: Integrating explicit knowledge and corpus statistics for a multilingual representation of concepts and entities. Artif. Intell. 2016, 240, 36–64. [Google Scholar] [CrossRef] [Green Version]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:abs/1910.03771. [Google Scholar]
- Madnani, N.; Dorr, B.J. Generating Phrasal and Sentential Paraphrases: A Survey of Data-Driven Methods. Comput. Linguist. 2010, 36, 341–387. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Cabrio, E.; Cimiano, P.; López, V.; Ngomo, A.N.; Unger, C.; Walter, S. QALD-3: Multilingual Question Answering over Linked Data. In Proceedings of the Working Notes for CLEF 2013 Conference, Valencia, Spain, 23–26 September 2013; Forner, P., Navigli, R., Tufis, D., Ferro, N., Eds.; 2013; Volume 1179. [Google Scholar]
- Unger, C.; Forascu, C.; López, V.; Ngomo, A.N.; Cabrio, E.; Cimiano, P.; Walter, S. Question Answering over Linked Data (QALD-4). In Proceedings of the Working Notes for CLEF 2014 Conference, Sheffield, UK, 15–18 September 2014; Cappellato, L., Ferro, N., Halvey, M., Kraaij, W., Eds.; 2014; Volume 1180, pp. 1172–1180. [Google Scholar]
- Unger, C.; Forascu, C.; López, V.; Ngomo, A.N.; Cabrio, E.; Cimiano, P.; Walter, S. Question Answering over Linked Data (QALD-5). In Proceedings of the Working Notes of CLEF 2015—Conference and Labs of the Evaluation Forum, Toulouse, France, 8–11 September 2015; Cappellato, L., Ferro, N., Jones, G.J.F., SanJuan, E., Eds.; 2015; Volume 1391. [Google Scholar]
- Unger, C.; Ngomo, A.N.; Cabrio, E. 6th Open Challenge on Question Answering over Linked Data (QALD-6). In Proceedings of the Semantic Web Challenges—Third SemWebEval Challenge at ESWC 2016, Heraklion, Crete, Greece, 29 May–2 June 2016; Revised Selected Papers; Communications in Computer and Information Science. Sack, H., Dietze, S., Tordai, A., Lange, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 641, pp. 171–177. [Google Scholar] [CrossRef]
- Usbeck, R.; Ngomo, A.N.; Haarmann, B.; Krithara, A.; Röder, M.; Napolitano, G. 7th Open Challenge on Question Answering over Linked Data (QALD-7). In Proceedings of the Semantic Web Challenges—4th SemWebEval Challenge at ESWC 2017, Portoroz, Slovenia, 28 May–1 June 2017; Revised Selected Papers; Communications in Computer and Information Science. Dragoni, M., Solanki, M., Blomqvist, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 769, pp. 59–69. [Google Scholar] [CrossRef]
- Usbeck, R.; Ngomo, A.N.; Conrads, F.; Röder, M.; Napolitano, G. 8th Challenge on Question Answering over Linked Data (QALD-8) (invited paper). In Proceedings of the 4th Workshop on Semantic Deep Learning (SemDeep-4) and NLIWoD4: Natural Language Interfaces for the Web of Data (NLIWOD-4) and 9th Question Answering over Linked Data challenge (QALD-9) Co-Located with 17th International Semantic Web Conference (ISWC 2018), Monterey, CA, USA, 8–9 October 2018; Choi, K., Anke, L.E., Declerck, T., Gromann, D., Kim, J., Ngomo, A.N., Saleem, M., Usbeck, R., Eds.; 2018; Volume 2241, pp. 51–57. [Google Scholar]
- Usbeck, R.; Gusmita, R.H.; Ngomo, A.N.; Saleem, M. 9th Challenge on Question Answering over Linked Data (QALD-9) (invited paper). In Proceedings of the 4th Workshop on Semantic Deep Learning (SemDeep-4) and NLIWoD4: Natural Language Interfaces for the Web of Data (NLIWOD-4) and 9th Question Answering over Linked Data Challenge (QALD-9) Co-Located with 17th International Semantic Web Conference (ISWC 2018), Monterey, CA, USA, 8–9 October 2018; Choi, K., Anke, L.E., Declerck, T., Gromann, D., Kim, J., Ngomo, A.N., Saleem, M., Usbeck, R., Eds.; 2018; Volume 2241, pp. 58–64. [Google Scholar]
- Trivedi, P.; Maheshwari, G.; Dubey, M.; Lehmann, J. LC-QuAD: A Corpus for Complex Question Answering over Knowledge Graphs. In Proceedings of the Semantic Web—ISWC 2017—16th International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; Proceedings, Part II; Lecture Notes in Computer Science. d’Amato, C., Fernández, M., Tamma, V.A.M., Lécué, F., Cudré-Mauroux, P., Sequeda, J.F., Lange, C., Heflin, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10588, pp. 210–218. [Google Scholar] [CrossRef]
- Cai, Q.; Yates, A. Large-scale Semantic Parsing via Schema Matching and Lexicon Extension. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, ACL 2013, Sofia, Bulgaria, 4–9 August 2013; Volume 1: Long Papers. The Association for Computer Linguistics: Stroudsburg, PA, USA, 2013; pp. 423–433. [Google Scholar]
- Abujabal, A.; Yahya, M.; Riedewald, M.; Weikum, G. Automated Template Generation for Question Answering over Knowledge Graphs. In Proceedings of the 26th International Conference on World Wide Web, WWW 2017, Perth, Australia, 3–7 April 2017; Barrett, R., Cummings, R., Agichtein, E., Gabrilovich, E., Eds.; ACM: New York, NY, USA, 2017; pp. 1191–1200. [Google Scholar] [CrossRef]
- Christmann, P.; Roy, R.S.; Abujabal, A.; Singh, J.; Weikum, G. Look before you Hop: Conversational Question Answering over Knowledge Graphs Using Judicious Context Expansion. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November 2019; Zhu, W., Tao, D., Cheng, X., Cui, P., Rundensteiner, E.A., Carmel, D., He, Q., Yu, J.X., Eds.; ACM: New York, NY, USA, 2019; pp. 729–738. [Google Scholar] [CrossRef] [Green Version]
- Jia, Z.; Abujabal, A.; Roy, R.S.; Strötgen, J.; Weikum, G. TempQuestions: A Benchmark for Temporal Question Answering. In Proceedings of the Companion of the Web Conference 2018 on the Web Conference 2018, WWW 2018, Lyon, France, 23–27 April 2018; Champin, P., Gandon, F.L., Lalmas, M., Ipeirotis, P.G., Eds.; ACM: New York, NY, USA, 2018; pp. 1057–1062. [Google Scholar] [CrossRef] [Green Version]
- Shen, C.; Huang, T.; Liang, X.; Li, F.; Fu, K. Chinese Knowledge Base Question Answering by Attention-Based Multi-Granularity Model. Information 2018, 9, 98. [Google Scholar] [CrossRef] [Green Version]
| Task (# Articles) | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|
| Entity detection (9) | [36,37] | [16] | [38] | [14,35,39,40] | [41] | ||
| Entity prediction (9) | [36,42] | [13,43] | [35,44] | [45] | [41,46] | ||
| Entity linking (6) | [20] | [37] | [16] | [14,40] | [45] | ||
| Relation prediction (12) | [42] | [13,16,43] | [38] | [14,35,39,40,44] | [41,46] | ||
| Answer matching (17) | [20] | [36,37,42] | [13,16,43] | [38] | [14,15,35,39,40,44] | [45] | [41,46] |
| Subgraph selection (7) | [36] | [43] | [38] | [35,39,40] | [46] |
| Entity detection (ED) employing the following models: |
| Entity prediction (EP) employs the following models: |
Entity linking (EL) employs the following approaches:
|
| Relation prediction (RP) employs the following models: |
| Answer matching (AM) employs the following approaches: |
Subgraph selection (SS) employs the following approaches:
|
| KGSQA | Model (Addressed Task(s)) | Pros (+) and Cons (−) |
|---|---|---|
| Bordes et al. [20] | N-gram matching, optimized similarity (EL, AM) | (+) Can work on natural language and an enormous memory (−) The difference of pattern between a KG and ReVerbs leads to more effort to align |
| Yin et al. [37] | Bi-LSTM with CRF, n-gram matching, CNN with attentive pooling (ED, EL, AM) | (+) A simple architecture (+) The entity linker cover higher coverage of ground truth entities (−) The entity linker does not cover the semantics of an entity |
| Dai et al. [36] | Bi-GRU with linear CRF, Bi-GRU, Bi-GRU, string or structure similarity, string matching mentions (ED, EP, RP, AM, SS) | (+) A reduced search space of subject mention during inference (−) Less smooth in entity representations |
| He and Golub [42] | LSTM and temporal CNN as encoder and LSTM with attention as decoder, direct query construction (EP, RP, AM) | (+) Using 16 times fewer parameters (+) Using a smaller data (+) Can be used to generalize unseen entities (−) Difficult to address the lexical gaps |
| Lukovnikov et al. [43] | GRU, GRU, string matching mentions, direct query construction (EP, RP, SS, AM) | (+) Can handle out-of-vovabulary and rare word problems (+) Not requiring NLP pipeline construction (+) Avoids error propagation (+) Reusable for different domains (−) Hard to solve ambiguity issues |
| Zhu et al. [13] | Bi-LSTM as encoder and LSTM as decoder, direct query construction (EP, RP, AM) | (+) Can address synonymy issues (−) A lower performance for a larger KB |
| Türe and Jojic [16] | GRU+Bi+GRU and LSTM+Bi-LSTM, n-gram matching, GRU+Bi+GRU and LSTM+Bi-LSTM, direct query construction (ED, EL, RP, AM) | (+) Simple architecture (−) Inherent ambiguity issues have not been solved |
| Chao and Li [38] | Bi-LSTM, Bi-GRU, String or structure similarity (ED, RP, AM) | (+) Useful to distinguish a polysemy entity (−) It has not addressed other ambiguity issues such as synonymy, hyponymy, and hypernymy |
| KGSQA | Model (Addressed Task(s)) | Pros (+) and Cons (−) |
|---|---|---|
| Zhang et al. [14] | Bi-GRU with linear CRF, n-gram matching, GRU and Bi-GRU as encoder and GRU as decoder, SVM (ED, EL, RP, AM) | (+) Robust in predicting the correct relation path connected with multiple target entities (−) Vulnerable to error in predicting relations in their paraphrase or synonym |
| Huang et al. [35] | Bi-LSTM, Bi-LSTM with attention, Bi-LSTM with attention, optimized similarity, string matching (ED, EP, RP, AM, SS) | (+) Can address entity and relation ambiguity (−) Not good for non-KG embeddings |
| Wang et al. [44] | Bi-LSTM with attentionm, direct query constructio (EP, RP, AM) | (+) Can capture relation-dependent questions representations (−) Difficult to address the lexical gaps and synonymy issue |
| Lan et al. [15] | Matching aggregation framework: ReLU linear layer; attention mechanism; and LSTM as aggregator (AM) | (+) Support for the contextual intention of questions (−) Hard to choose the correct path of facts when a question is ambiguous |
| Lukovnikov et al. [39] | BERT, BERT, string or structure similarity, string matching mentions (ED, RP, AM, SS) | (+) Powerful for sequence learning (of entity and relation) in an NLQ (−) Costly and can overfit easily when learning facts from a KG |
| Zhao et al. [40] | Bi-LSTM with CRF, CNN with adaptive max-pooling, CNN with adaptive max-pooling, optimized similarity in embedding space between KG entities and questions (ED, EL, RP, AM) | (+) Can address inexact matching using literal and semantic approach (−) The ambiguity issue is unsolved |
| Luo et al. [45] | BERT, n-gram matching, a custom architecture: BERT; relation-aware attention network; Bi-LSTM; and a linear layer (EP, EL, AM) | (+) Support the solution for semantic gaps between questions and KBs (−) Questions ambiguity and KGs redundancy issue has not been solved |
| Zhang et al. [46] | Bayesian Bi-LSTM, Bayesian Bi-LSTM, optimized similarity, string matching mentions (EP, RP, AM, SS) | (+) Easy to use and retrain for different domains (−) Cannot address ambiguous questions |
| Li et al. [41] | Bi-LSTM, LTSM with attention, LSTM with attention in the end-to-end and pipeline framework, direct query construction (ED, EP, RP, AM) | (+) Can address polysemy entity (−) Inefficient model training |
| KGSQA System | Year | Model (Addressed Task(s)) | T.A |
|---|---|---|---|
| Bordes et al. [20] | 2015 | N-gram matching, optimized similarity (EL, AM) | 63.9 |
| Yin et al. [37] | 2016 | Bi-LSTM with CRF, n-gram matching, CNN with attentive pooling (ED, EL, AM) | 76.4 |
| Dai et al. [36] | 2016 | Bi-GRU with linear CRF, Bi-GRU, Bi-GRU, String and structure similarity, string matching mentions (ED, EP, RP, AM, SS) | 75.7 |
| He and Golub [42] | 2016 | LSTM and temporal CNN as encoder and LSTM with attention as decoder, or direct query construction (EP, RP, AM) | 70.9 |
| Lukovnikov et al. [43] | 2017 | GRU, GRU, string matching mentions, direct query construction (EP, RP, SS, AM) | 71.2 |
| Zhu et al. [13] | 2017 | Bi-LSTM as encoder and LSTM as decoder, direct query construction (EP, RP, AM) | 77.4 |
| Türe and Jojic [16] | 2017 | GRU+Bi+GRU and LSTM+Bi-LSTM, n-gram matching, GRU+Bi+GRU and LSTM+Bi-LSTM, direct query construction (ED, EL, RP, AM) | 88.3 |
| Chao and Li [38] | 2018 | Bi-LSTM, Bi-GRU, String or structure similarity (ED, RP, AM) | 66.6 |
| Zhang et al. [14] | 2019 | Bi-GRU with linear CRF, n-gram matching, GRU and Bi-GRU as encoder and GRU as decoder, SVM (ED, EL, RP, AM) | 81.7 |
| Huang et al. [35] | 2019 | Bi-LSTM, Bi-LSTM with attention, Bi-LSTM with attention, optimized similarity, string matching (ED, EP, RP, AM, SS) | 75.4 |
| Wang et al. [44] | 2019 | Bi-LSTM with attention, direct query construction (EP, RP, AM) | 82.2 |
| Lan et al. [15] | 2019 | Matching aggregation framework consisting of ReLU linear layer, attention mechanism, and LSTM as aggregator (AM) | 80.9 |
| Lukovnikov et al. [39] | 2019 | BERT, BERT, string or structure similarity, string matching mentions (ED, RP, AM, SS) | 77.3 |
| Zhao et al. [40] | 2019 | Bi-LSTM with CRF, CNN with adaptive max-pooling, CNN with adaptive max-pooling, optimized similarity in embedding space between KG entities and questions (ED, EL, RP, AM) | 85.4 |
| Luo et al. [45] | 2020 | BERT, n-gram matching, a custom architecture consiting of BERT, relation-aware attention network, Bi-LSTM, and a linear layer (EP, EL, AM) | 80.9 |
| Zhang et al. [46] | 2021 | Bayesian Bi-LSTM, Bayesian Bi-LSTM, optimized similarity, string matching mentions (EP, RP, AM, SS) | 75.1 |
| Li et al. [41] | 2021 | Bi-LSTM, LTSM with attention, LSTM with attention in the end-to-end and pipeline framework, direct query construction (ED, EP, RP, AM) | 71.8 |
| Survey Focus | Original Paper | Year |
|---|---|---|
| Knowledge graph embedding | Wang et al. [54] | 2017 |
| Representation of meaning | Camacho-Collados and Pilehvar [55] | 2018 |
| Graph embedding | Goyal and Ferrara [56] | 2018 |
| Task | Caption | Input | Output | Used in |
|---|---|---|---|---|
| Named entity recognition | To classify tokens according to a class | Text | NER | Entity and relation linking |
| Extractive question answering | To extract an answer from a text given a question | Context | Answers | Entity and relation linking |
| Masked language model | To mask tokens in a sequence | Text | Filled mask | Entity missing detection |
| Original Question [20] | Word-Level Paraphrasing | Question-Level Paraphrasing |
|---|---|---|
| “Where did John Drainie die?” | “Where did John Drainie decease?” | “John Drainie died in which city?” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yani, M.; Krisnadhi, A.A. Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey. Information 2021, 12, 271. https://doi.org/10.3390/info12070271
Yani M, Krisnadhi AA. Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey. Information. 2021; 12(7):271. https://doi.org/10.3390/info12070271
Chicago/Turabian StyleYani, Mohammad, and Adila Alfa Krisnadhi. 2021. "Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey" Information 12, no. 7: 271. https://doi.org/10.3390/info12070271
APA StyleYani, M., & Krisnadhi, A. A. (2021). Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey. Information, 12(7), 271. https://doi.org/10.3390/info12070271