
CIDOC2VEC: Extracting Information from Atomized CIDOC-CRM Humanities Knowledge Graphs



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. CIDOC-CRM
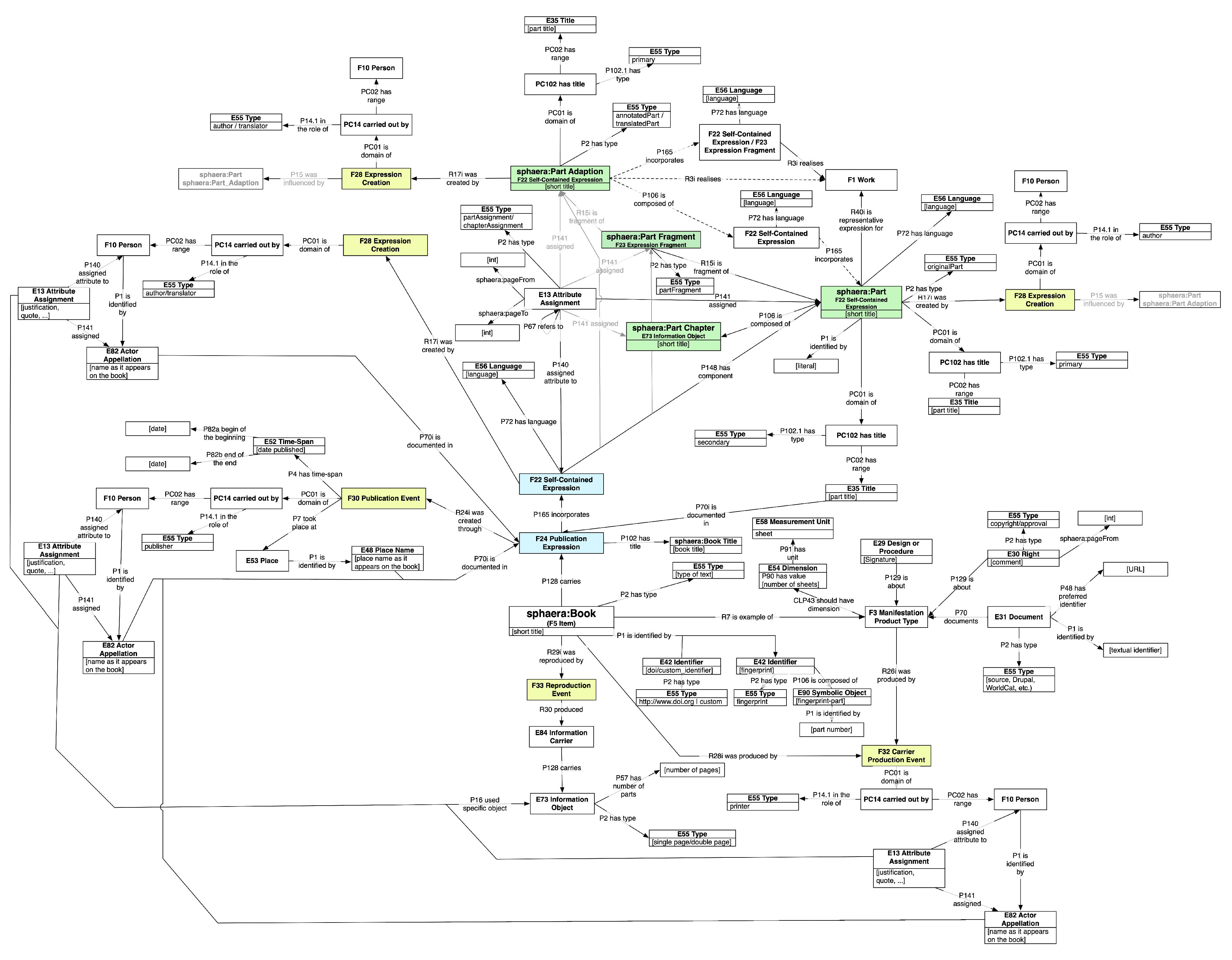
4. The Sphaera Knowledge Graph
- Original treatises, which are editions that represent the Tractatus de Sphaera as a stand-alone work;
- Annotated original treatises, which are editions that include the Tractatus de Sphaera with annotations and commentary by other authors;
- Compilations of texts, which are editions that exclusively include the Tractatus de Sphaera among other treatises by different authors;
- Compilations of texts and annotated originals, which include editions that feature the Tractatus de Sphaera as the basis for a commentary or annotation, and also includes work by other authors;
- Adaptions, which are editions that contain texts that are heavily influenced by the Tractatus de Sphaera in terms of content and structure, but do not include the original text.
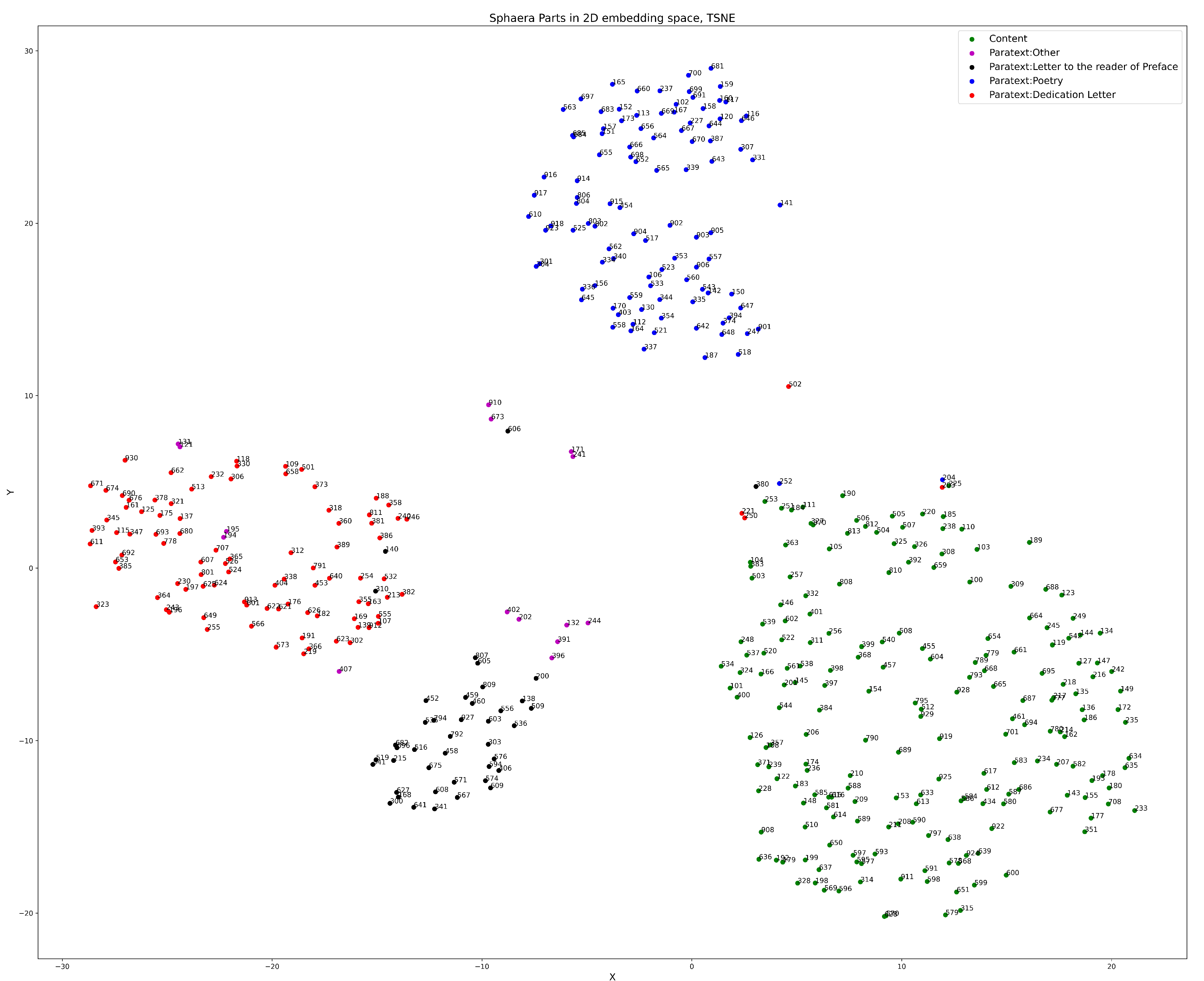
- Content parts, which are the core scientific texts that rarely changed and were considered as the reference text in each edition;
- Paratext—poetry, which represents short poem dedications, often added at the beginning of certain editions;
- Paratext—dedications letters are short passages of dedication, and can often be an indication of the level of prestige of certain editions;
- Paratext—letters to reader or preface, are short passages addressing the reader;
- Paratext—other, which represents a small group of texts that do not fit in the previous three paratext categories.
5. Method: CIDOC2VEC
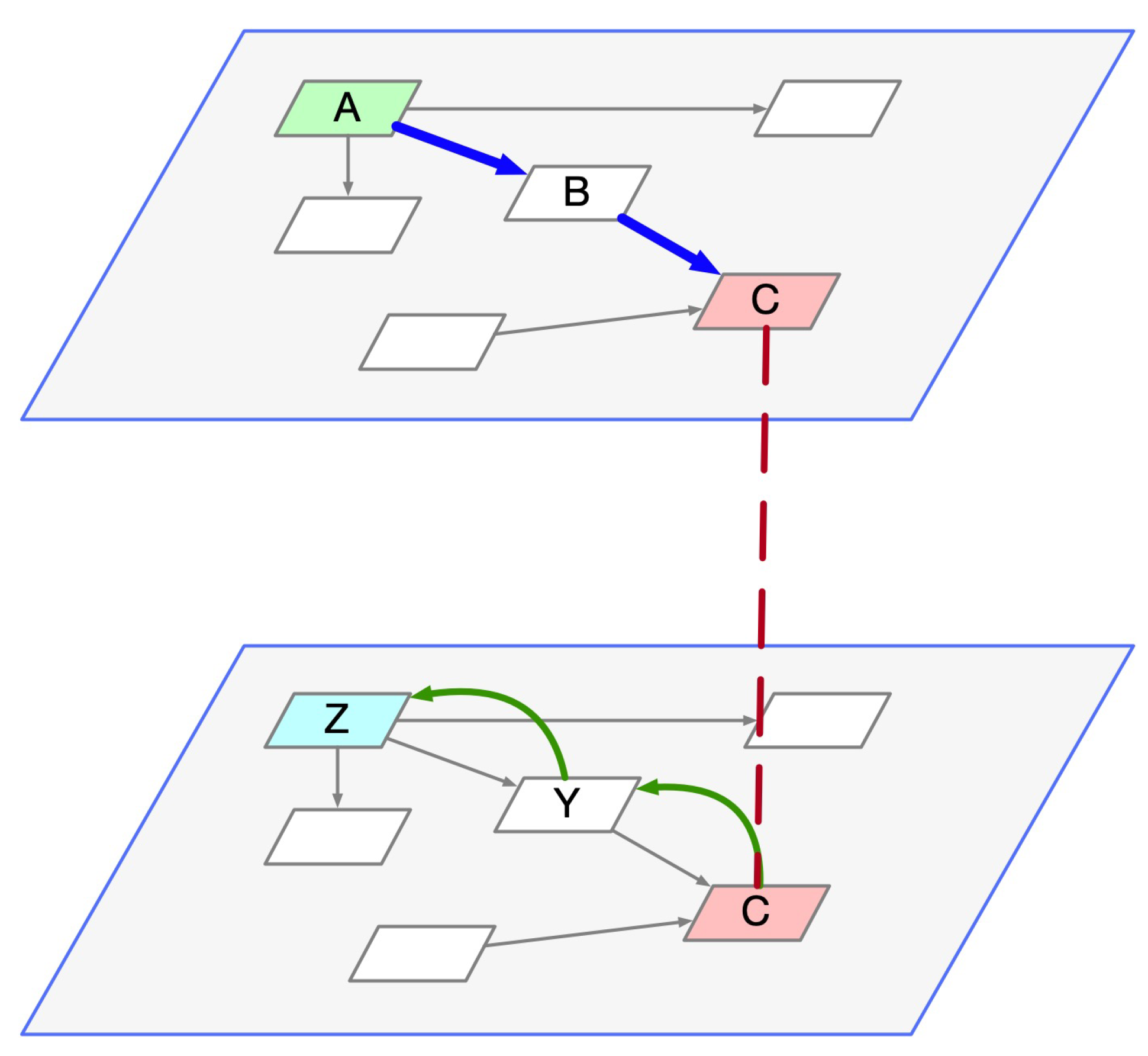
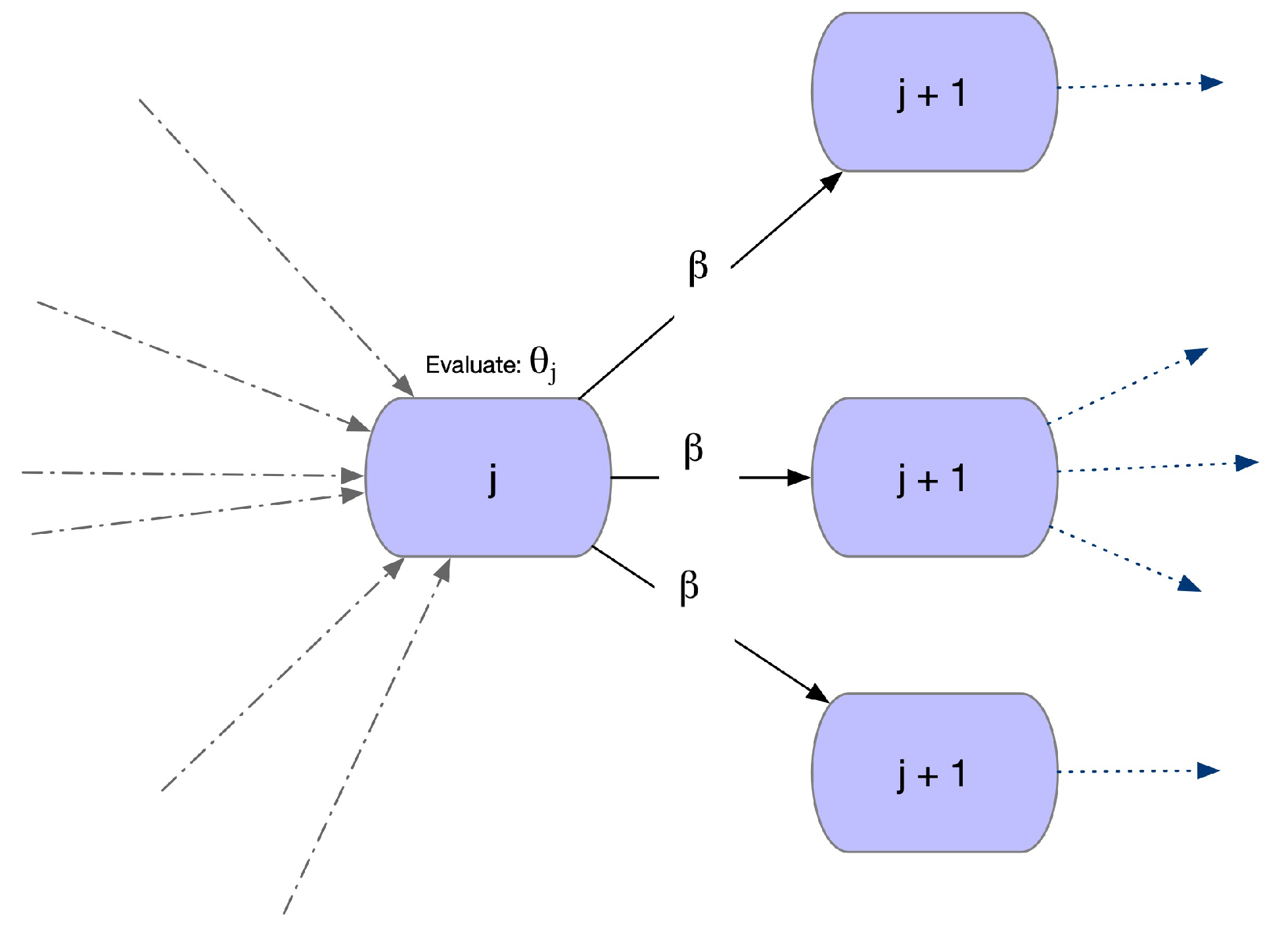
5.1. Relative Sentence Walk (RSW)
RSW Algorithm
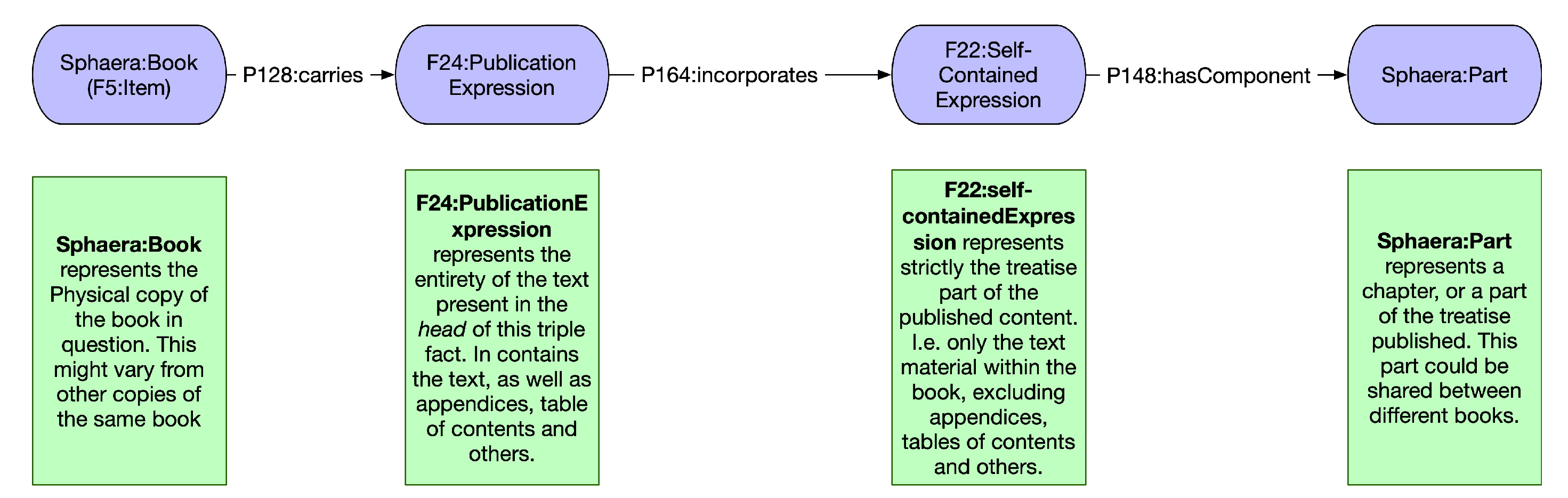
- Regular sentence: Book:A—Carries—a Publication Expression—incorporates a Self Contained Expression—has Language—Latin.
- Relative Sentence: Book:A—Carries a—Publication Expression—incorporates—a Self Contained Expression—has component—Part:C—which is component—of a self-contained expression—incorporated in—a Public Expression—carried by—Book:B.
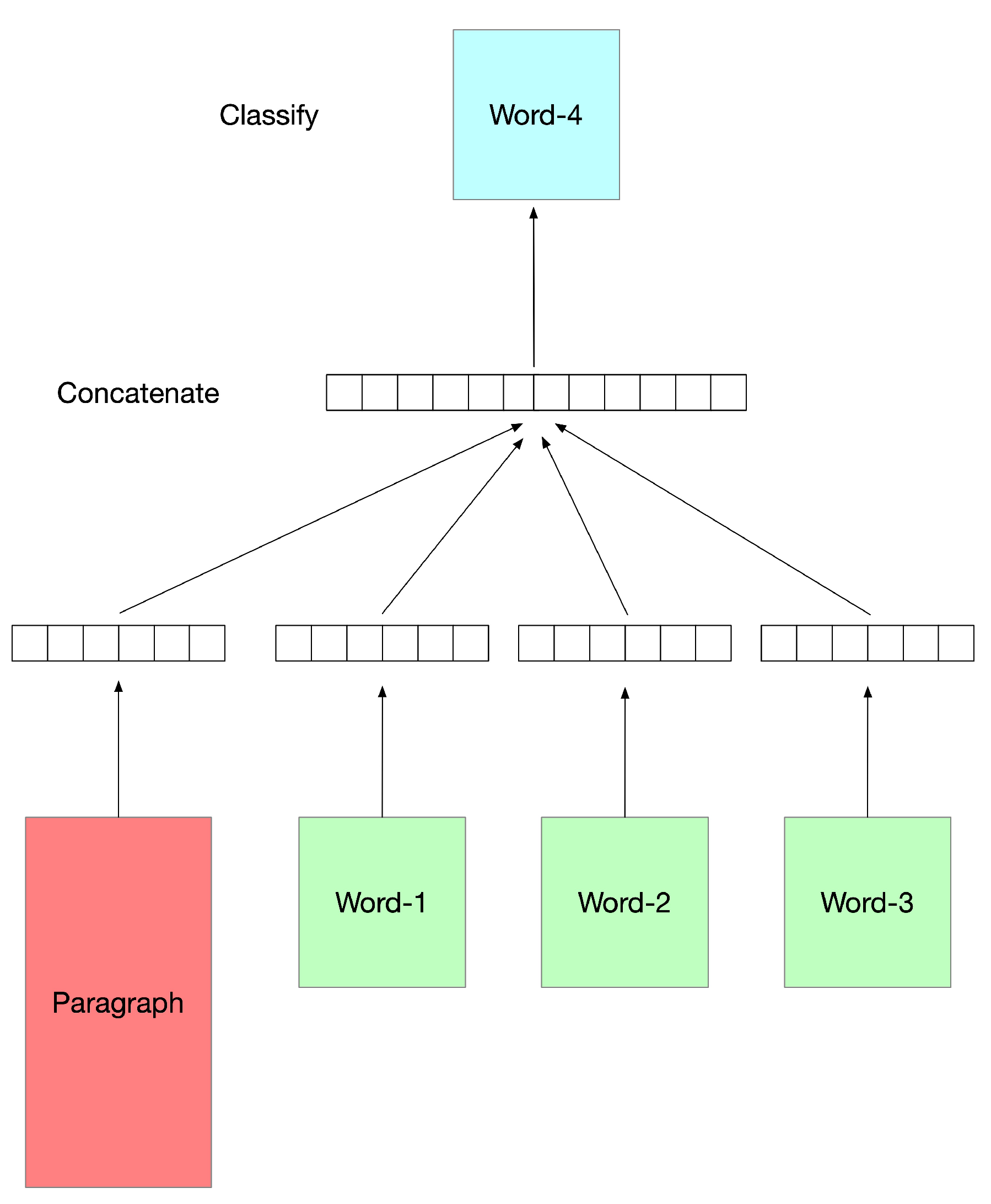
5.2. Document Representation Using DOC2VEC
| Algorithm 1 CIDOC2VEC. |
|
Initialize empty Doc |
Initialize empty DocList |
forl in L do |
while do |
Sentence = |
Append Sentence to Doc |
end while |
Append Doc to DocList |
end for |
forDoc in DocList do |
Embedding = doc2vec(Doc) |
end for |
| Algorithm 2 Relative Sentence Walk, RSW. |
|
Initialize empty Sentence |
Initialize hop counter |
whiledo |
if then |
Calculate |
if then |
Calculate considering only out-edges |
else |
Calculate considering reverse walk, in-edges. |
end if |
end if |
Evaluate hop probability and execute hop. |
Append current Entity to Sentence |
end while |
return Sentence |
6. Results
6.1. Sphaera Editions
6.2. Sphaera Text-Parts
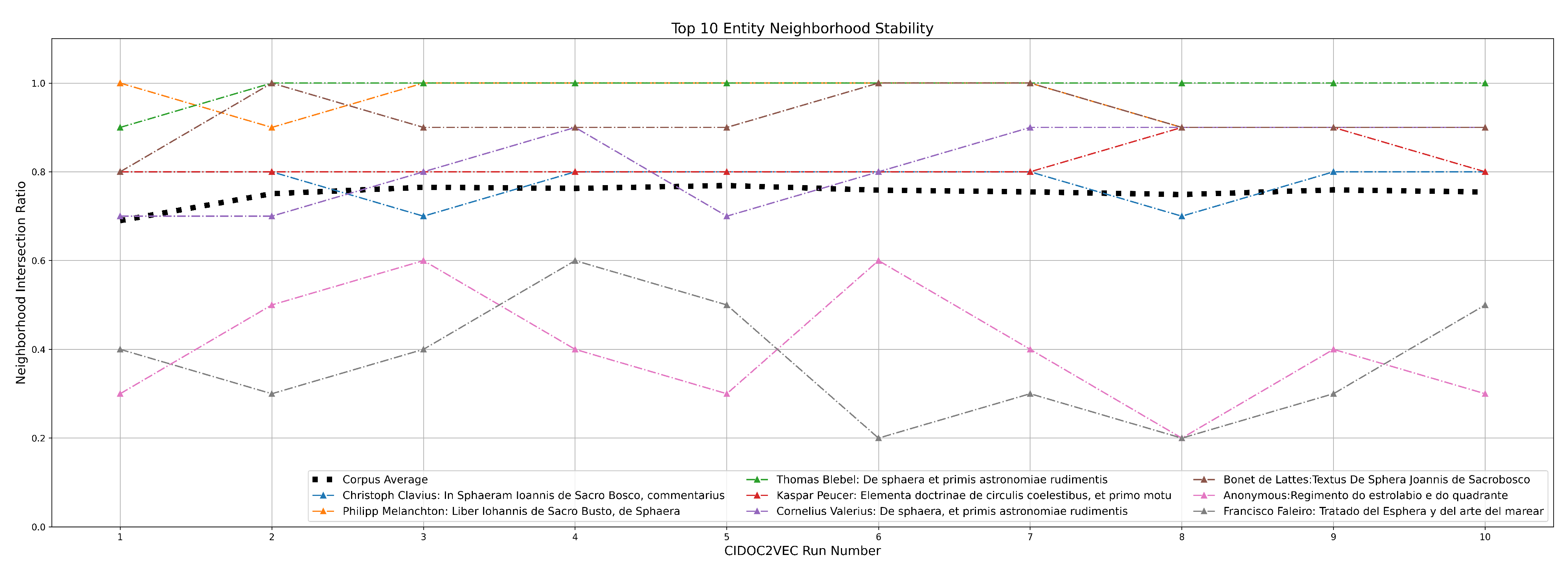
6.3. Model Stability
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 950–958. [Google Scholar]
- Christmann, P.; Saha Roy, R.; Abujabal, A.; Singh, J.; Weikum, G. Look before You Hop: Conversational Question Answering over Knowledge Graphs Using Judicious Context Expansion. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 729–738. [Google Scholar]
- Kraütli, F.; Valleriani, M. CorpusTracer: A CIDOC Database for Tracing Knowlege Networks. Digit. Scholarsh. Humanit. 2018, 33, 336–346. [Google Scholar] [CrossRef] [Green Version]
- Görz, G.; Seidl, C.; Thiering, M. Linked Biondo: Modelling Geographical Features in Renaissance Texts and Maps. e-Perimetron Int. Web J. Sci. Technol. Affin. Hist. Cartogr. Maps 2021, 16, 78–93. [Google Scholar]
- Koho, M.; Ikkala, E.; Leskinen, P.; Tamper, M.; Tuominen, J.; Hyvönen, E. WarSampo Knowledge Graph: Finland in the Second World War as Linked Open Data. Semantic Web 2021, 12, 265–278. [Google Scholar] [CrossRef]
- Sinikallio, L.; Drobac, S.; Tamper, M.; Leal, R.; Koho, M.; Tuominen, J.; La Mela, M.; Hyvönen, E. Plenary Debates of the Parliament of Finland as Linked Open Data and in Parla-CLARIN Markup. In Proceedings of the 3rd Conference on Language, Data and Knowledge (LDK 2021), Zaragoza, Spain, 1–3 September 2021; Gromann, D., Sérasset, G., Declerck, T., McCrae, J.P., Gracia, J., Bosque-Gil, J., Bobillo, F., Heinisch, B., Eds.; Schloss Dagstuhl—Leibniz-Zentrum für Informatik: Dagstuhl, Germany, 2021; Volume 93, pp. 8:1–8:17. [Google Scholar]
- Mäkëla, E.; Törnros, J.; Lindquist, T.; Hyvönen, E. WW1LOD: An application of CIDOC-CRM to World War 1 linked data. Int. J. Digit. Libr. 2015, 18, 333–342. [Google Scholar] [CrossRef] [Green Version]
- Felicetti, A.; Murano, F. Scripta Manent: A CIDOC CRM Semiotic Reading of Ancient Texts. Int. J. Digit. Libr. 2017, 18, 263–270. [Google Scholar] [CrossRef]
- Haslhofer, B.; Isaac, A.; Simon, R. Knowledge Graphs in the Libraries and Digital Humanities Domain. In Encyclopedia of Big Data Technologies; Sakr, S., Zamaya, A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 1–8. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web; Aberer, K., Choi, K.S., Noy, N., Allemang, D., Lee, K.I., Nixon, L., Golbeck, J., Mika, P., Maynard, D., Mizoguchi, R., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A Free Collaborative Knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked Data—The Story So Far. Int. J. Semantic Web Inf. Syst. 2009, 5, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Bekiari, C.; Bruseke, G.; Doerr, M.; Ore, C.E.; Stead, S.; Velios, A. Definition of the CIDOC Conceptual Reference Model v7.1.1. 2021. Available online: https://cidoc-crm.org/sites/default/files/cidoc_crm_v.7.1.1_0.pdf (accessed on 1 December 2021).
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Advances in Neural Information Processing Systems; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Beijing, China, 2015; pp. 687–696. [Google Scholar]
- Fan, M.; Zhou, Q.; Chang, E.; Zheng, T.F. Transition-based Knowledge Graph Embedding with Relational Mapping Properties. In Proceedings of the 28th Pacific Asia Conference on Language, Information and Computing, Phuket, Thailand, 12–14 December 2014; pp. 328–337. [Google Scholar]
- Xiao, H.; Huang, M.; Hao, Y.; Zhu, X. TransA: An Adaptive Approach for Knowledge Graph Embedding. arXiv 2015, arXiv:abs/1509.05490. [Google Scholar]
- Dain, Y.; Wang, S.; Xiong, N.; Guo, W. A Survey of Knowledge Graph Embedding: Approaches, Applications, and Benchmarks. Electronics 2020, 9, 750. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 809–816. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data. Mach. Learn. 2014, 94, 233–259. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 327–333. [Google Scholar]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning With Neural Tensor Networks for Knowledge Base Completion. In Advances in Neural Information Processing Systems; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Meghini, C.; Doerr, M. A first-order logic expression of the CIDOC conceptual reference model. Int. J. Metadata Semant. Ontol. 2018, 13, 131–149. [Google Scholar] [CrossRef]
- Valleriani, M.; Kraütli, F.; Zamani, M.; Tejedor, A.; Sander, C.; Vogl, M.; Bertram, S.; Funke, G.; Kantz, H. The Emergence of Epistemic Communities in the Sphaera Corpus: Mechanisms of Knowledge Evolution. J. Hist. Netw. Res. 2019, 3, 50–91. [Google Scholar]
- Bekiari, C.; Doerr, M.; Boeuf, P.L.; Riva, P. Definition of FRBRoo: A Conceptual Model for Bibliographic Information in Object-Oriented Formalism. 2015. Available online: https://repository.ifla.org/handle/123456789/659 (accessed on 23 October 2021).
- Zamani, M.; Tejedor, A.; Vogl, M.; Kraütli, F.; Valleriani, M.; Kantz, H. Evolution and transformation of early modern cosmological knowledge: A network study. Sci. Rep. 2020, 10, 19822. [Google Scholar] [CrossRef] [PubMed]
- Toutanova, K.; Chen, D.; Pantel, P.; Poon, H.; Choudhury, P.; Gamon, M. Representing Text for Joint Embedding of Text and Knowledge Bases. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1499–1509. [Google Scholar]
- Liang, S.; Kurt Stockinger, T.M.; Anisimova, M.; Gil, M. Querying Knowledge Graphs in Natural Language. J. Big Data 2021, 8, 3. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, O.; Ge, H.; Shakeri, S.; Al-Rfou, R. Large Scale Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training. arXiv 2020, arXiv:abs/2010.12688. [Google Scholar]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 855–864. [Google Scholar]
- Park, N.; Kan, A.; Dong, X.L.; Zhao, T.; Faloutsos, C. Estimating Node Importance in Knowledge Graphs Using Graph Neural Networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 596–606. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Xing, E.P., Jebara, T., Eds.; PMLR: Bejing, China, 2014; Volume 32, pp. 1188–1196. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Lattis, J. Between Copernicus and Galileo: Christoph Clavius and the Collapse of the Ptolemaic Cosmology; The University of Chicago Press: Chicago, IL, USA, 1994. [Google Scholar]
- Sigismondi, C. Christopher Clavius astronomer and mathematician. Il Nuovo C. 2012, 36, 231–236. [Google Scholar]
- Brosseder, C. Im Bann der Sterne: Caspar Peucer, Philipp Melanchthon und andere Wittenberger Astrologen; Akademie Verlag: Berlin, Germany, 2004. [Google Scholar]
- Westman, R.S. The Melanchthon Circle, Rheticus, and the Wittenberg Interpretation of the Copernican Theory. Isis 1975, 66, 165–193. [Google Scholar] [CrossRef]
- Werner, S. Studying Early Printed Books, 1450–1800: A Practical Guide; Wiley Blackwell: Hoboken, NJ, USA, 2019. [Google Scholar]
- Maclean, I. Episodes in the Life of the Early Modern Learned Book; Brill: Leiden, The Netherlands, 2020. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El-Hajj, H.; Valleriani, M. CIDOC2VEC: Extracting Information from Atomized CIDOC-CRM Humanities Knowledge Graphs. Information 2021, 12, 503. https://doi.org/10.3390/info12120503
El-Hajj H, Valleriani M. CIDOC2VEC: Extracting Information from Atomized CIDOC-CRM Humanities Knowledge Graphs. Information. 2021; 12(12):503. https://doi.org/10.3390/info12120503
Chicago/Turabian StyleEl-Hajj, Hassan, and Matteo Valleriani. 2021. "CIDOC2VEC: Extracting Information from Atomized CIDOC-CRM Humanities Knowledge Graphs" Information 12, no. 12: 503. https://doi.org/10.3390/info12120503
APA StyleEl-Hajj, H., & Valleriani, M. (2021). CIDOC2VEC: Extracting Information from Atomized CIDOC-CRM Humanities Knowledge Graphs. Information, 12(12), 503. https://doi.org/10.3390/info12120503