Deep Learning for Computer Vision: Algorithms, Theory and Application
Share This Topical Collection
Editors
 Prof. Dr. Jungong Han
Prof. Dr. Jungong Han
Prof. Dr. Jungong Han
E-Mail
Website
Collection Editor
Data Science Group, University of Warwick, Coventry CV4 7AL, UK
Interests: video analytics; computer vision; machine learning; artificial intelligence
Prof. Dr. Guiguang Ding
Prof. Dr. Guiguang Ding
E-Mail
Website
Collection Editor
School of Software, Tsinghua University, Beijing 100084, China
Interests: multimedia analysis; computer vision; machine learning
Topical Collection Information
Dear Colleagues,
In recent years, deep learning methods have made important breakthroughs in several fields, with computer vision being one of the most prominent cases. Compared with traditional machine learning methods that rely on handcrafted features, deep learning-based methods allow the acquisition of knowledge directly from data and are hence capable of extracting much more abstract and semantic features with better representation capability. With their cascaded layers that can contain hundreds of millions of parameters, they can model highly nonlinear functions. Despite these advances, issues such as with handling noisy or distorted data, training deep networks with limited labeled data, and training models while protecting data confidentiality and integrity are some of the challenges faced by deep computer vision practitioners. As such, it is now necessary to explore the advanced algorithms, theories, and optimization approaches as applied to deep computer vision.
This Topical Collection aims at bringing together researchers and scientists from various disciplines to present recent advances in dealing with the challenging problems of computer vision within the framework of deep learning. We invite authors to submit manuscripts on topics related to the theme of the Topical Collection and which have not been previously published. The topics of interest include, but are not limited to:
- Deep learning algorithms and models (supervised/weakly supervised/unsupervised)
- Feature learning and feature representation based on deep learning
- Deep learning-based image recognition
- Deep learning-based video understanding
- Deep learning-based remote sensing image analysis
- Deep learning-based saliency/co-saliency detection
- Deep learning-based visual object tracking
- Deep learning-based image super-resolution
- Deep learning-based image quality assessment
- Deep network compression and acceleration
Prof. Dr. Jungong Han
Prof. Dr. Guiguang Ding
Collection Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Electronics is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- deep learning
- artificial intelligence
- neural networks
- visual analysis
- vision application
Published Papers (39 papers)
Open AccessArticle
Channel Interaction Mamba-Guided Generative Adversarial Network for Depth-Image-Based Rendering 3D Image Watermarking
by
Qingmo Chen, Zhongxing Sun, Rui Bai and Chongchong Jin
Viewed by 1173
Abstract
In the field of 3D technology, depth-image-based rendering (DIBR) has been widely adopted due to its inherent advantages including low data volume and strong compatibility. However, during network transmission of DIBR 3D images, both center and virtual views are susceptible to unauthorized copying
[...] Read more.
In the field of 3D technology, depth-image-based rendering (DIBR) has been widely adopted due to its inherent advantages including low data volume and strong compatibility. However, during network transmission of DIBR 3D images, both center and virtual views are susceptible to unauthorized copying and distribution. To protect the copyright of these images, this paper proposes a channel interaction mamba-guided generative adversarial network (CIMGAN) for DIBR 3D image watermarking. To capture cross-modal feature dependencies, a channel interaction mamba (CIM) is designed. This module enables lightweight cross-modal channel interaction through a channel exchange mechanism and leverages mamba for global modeling of RGB and depth information. In addition, a feature fusion module (FFM) is devised to extract complementary information from cross-modal features and eliminate redundant information, ultimately generating high-quality 3D image features. These features are used to generate an attention map, enhancing watermark invisibility and identifying robust embedding regions. Compared to the current state-of-the-art (SOTA) 3D image watermarking methods, the proposed watermark model shows superior performance in terms of robustness and invisibility while maintaining computational efficiency.
Full article
►▼
Show Figures
Open AccessArticle
A Content-Aware Method for Detecting External-Force-Damage Objects on Transmission Lines
by
Min Liu, Ming Chen, Benhui Wu, Minghu Wu, Juan Wang, Jianda Wang, Hengbo Hu and Yonggang Ye
Cited by 2 | Viewed by 1411
Abstract
The security of ultra-high-voltage (UHV) overhead transmission lines is frequently threatened by diverse external-force damages. As real-world transmission line scenarios are complex and external-force-damage objects exhibit varying scales, deep learning-based object detection methods necessitate the capture of multi-scale information. However, the downsampling and
[...] Read more.
The security of ultra-high-voltage (UHV) overhead transmission lines is frequently threatened by diverse external-force damages. As real-world transmission line scenarios are complex and external-force-damage objects exhibit varying scales, deep learning-based object detection methods necessitate the capture of multi-scale information. However, the downsampling and upsampling operations employed to learn multi-scale features work locally, resulting in the loss of details and boundaries, which makes it difficult to accurately locate external-force-damage objects. To address this issue, this paper proposes a content-aware method based on the generalized efficient layer aggregation network (GELAN) framework. A newly designed content-aware downsampling module (CADM) and content-aware upsampling module (CAUM) were integrated to optimize the operations with global receptive information. CADM and CAUM were embedded into the GELAN detection framework, providing a new content-aware method with improved cost accuracy trade-off. To validate the method, a large-scale dataset of external-force damages on transmission lines with complex backgrounds and diverse lighting was constructed. The experimental results demonstrate the proposed method’s superior performance, achieving 96.50% mean average precision (mAP) on the transmission line dataset and 91.20% mAP on the pattern analysis, statical modeling and computational learning visual object classes (PASCAL VOC) dataset.
Full article
►▼
Show Figures
Open AccessArticle
Foul Detection for Table Tennis Serves Using Deep Learning
by
Guang Liang Yang, Minh Nguyen, Wei Qi Yan and Xue Jun Li
Cited by 5 | Viewed by 3408
Abstract
Detecting serve fouls in table tennis is critical for ensuring fair play. This paper explores the development of foul detection of table tennis serves by leveraging 3D ball trajectory analysis and deep learning techniques. Using a multi-camera setup and a custom dataset, we
[...] Read more.
Detecting serve fouls in table tennis is critical for ensuring fair play. This paper explores the development of foul detection of table tennis serves by leveraging 3D ball trajectory analysis and deep learning techniques. Using a multi-camera setup and a custom dataset, we employed You Only Look Once (YOLO) models for ball detection and Transformers for critical trajectory point identification. We achieved 87.52% precision in detecting fast-moving balls and an F1 score of 0.93 in recognizing critical serve points such as the throw, highest, and hit points. These results enable precise serve segmentation and robust foul detection based on criteria like toss height and vertical angle compliance. The approach simplifies traditional methods by focusing solely on the ball motion, eliminating computationally intensive pose estimation. Despite limitations such as a controlled experimental environment, the findings demonstrate the feasibility of artificial intelligence (AI)-driven referee systems for table tennis games, providing a foundation for broader applications in sports officiating.
Full article
►▼
Show Figures
Open AccessArticle
Dual Convolutional Malware Network (DCMN): An Image-Based Malware Classification Using Dual Convolutional Neural Networks
by
Bassam Al-Masri, Nader Bakir, Ali El-Zaart and Khouloud Samrouth
Cited by 12 | Viewed by 2807
Abstract
Malware attacks have a cascading effect, causing financial harm, compromising privacy, operations and interrupting. By preventing these attacks, individuals and organizations can safeguard the valuable assets of their operations, and gain more trust. In this paper, we propose a dual convolutional neural network
[...] Read more.
Malware attacks have a cascading effect, causing financial harm, compromising privacy, operations and interrupting. By preventing these attacks, individuals and organizations can safeguard the valuable assets of their operations, and gain more trust. In this paper, we propose a dual convolutional neural network (DCNN) based architecture for malware classification. It consists first of converting malware binary files into 2D grayscale images and then training a customized dual CNN for malware multi-classification. This paper proposes an efficient approach for malware classification using dual CNNs. The model leverages the complementary strengths of a custom structure extraction branch and a pre-trained ResNet-50 model for malware image classification. By combining features extracted from both branches, the model achieved superior performance compared to a single-branch approach.
Full article
►▼
Show Figures
Open AccessArticle
Multimodal Driver Condition Monitoring System Operating in the Far-Infrared Spectrum
by
Mateusz Knapik, Bogusław Cyganek and Tomasz Balon
Cited by 10 | Viewed by 3968
Abstract
Monitoring the psychophysical conditions of drivers is crucial for ensuring road safety. However, achieving real-time monitoring within a vehicle presents significant challenges due to factors such as varying lighting conditions, vehicle vibrations, limited computational resources, data privacy concerns, and the inherent variability in
[...] Read more.
Monitoring the psychophysical conditions of drivers is crucial for ensuring road safety. However, achieving real-time monitoring within a vehicle presents significant challenges due to factors such as varying lighting conditions, vehicle vibrations, limited computational resources, data privacy concerns, and the inherent variability in driver behavior. Analyzing driver states using visible spectrum imaging is particularly challenging under low-light conditions, such as at night. Additionally, relying on a single behavioral indicator often fails to provide a comprehensive assessment of the driver’s condition. To address these challenges, we propose a system that operates exclusively in the far-infrared spectrum, enabling the detection of critical features such as yawning, head drooping, and head pose estimation regardless of the lighting scenario. It integrates a channel fusion module to assess the driver’s state more accurately and is underpinned by our custom-developed and annotated datasets, along with a modified deep neural network designed for facial feature detection in the thermal spectrum. Furthermore, we introduce two fusion modules for synthesizing detection events into a coherent assessment of the driver’s state: one based on a simple state machine and another that combines a modality encoder with a large language model. This latter approach allows for the generation of responses to queries beyond the system’s explicit training. Experimental evaluations demonstrate the system’s high accuracy in detecting and responding to signs of driver fatigue and distraction.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
YOLO-FMDI: A Lightweight YOLOv8 Focusing on a Multi-Scale Feature Diffusion Interaction Neck for Tomato Pest and Disease Detection
by
Hao Sun, Isack Thomas Nicholaus, Rui Fu and Dae-Ki Kang
Cited by 21 | Viewed by 4317
Abstract
At the present stage, the field of detecting vegetable pests and diseases is in dire need of the integration of computer vision technologies. However, the deployment of efficient and lightweight object-detection models on edge devices in vegetable cultivation environments is a key issue.
[...] Read more.
At the present stage, the field of detecting vegetable pests and diseases is in dire need of the integration of computer vision technologies. However, the deployment of efficient and lightweight object-detection models on edge devices in vegetable cultivation environments is a key issue. To address the limitations of current target-detection models, we propose a novel lightweight object-detection model based on YOLOv8n while maintaining high accuracy. In this paper, (1) we propose a new neck structure, Focus Multi-scale Feature Diffusion Interaction (FMDI), and inject it into the YOLOv8n architecture, which performs multi-scale fusion across hierarchical features and improves the accuracy of pest target detection. (2) We propose a new efficient Multi-core Focused Network (MFN) for extracting features of different scales and capturing local contextual information, which optimizes the processing power of feature information. (3) We incorporate the novel and efficient Universal Inverted Bottleneck (UIB) block to replace the original bottleneck block, which effectively simplifies the structure of the block and achieves the lightweight model. Finally, the performance of YOLO-FMDI is evaluated through a large number of ablation and comparison experiments. Notably, compared with the original YOLOv8n, our model reduces the parameters, GFLOPs, and model size by 18.2%, 6.1%, and 15.9%, respectively, improving the mean average precision (mAP50) by 1.2%. These findings emphasize the excellent performance of our proposed model for tomato pest and disease detection, which provides a lightweight and high-precision solution for vegetable cultivation applications.
Full article
►▼
Show Figures
Open AccessArticle
Training Acceleration Method Based on Parameter Freezing
by
Hongwei Tang, Jialiang Chen, Wenkai Zhang and Zhi Guo
Cited by 4 | Viewed by 2968
Abstract
As deep learning has evolved, larger and deeper neural networks are currently a popular trend in both natural language processing tasks and computer vision tasks. With the increasing parameter size and model complexity in deep neural networks, it is also necessary to have
[...] Read more.
As deep learning has evolved, larger and deeper neural networks are currently a popular trend in both natural language processing tasks and computer vision tasks. With the increasing parameter size and model complexity in deep neural networks, it is also necessary to have more data available for training to avoid overfitting and to achieve better results. These facts demonstrate that training deep neural networks takes more and more time. In this paper, we propose a training acceleration method based on gradually freezing the parameters during the training process. Specifically, by observing the convergence trend during the training of deep neural networks, we freeze part of the parameters so that they are no longer involved in subsequent training and reduce the time cost of training. Furthermore, an adaptive freezing algorithm for the control of freezing speed is proposed in accordance with the information reflected by the gradient of the parameters. Concretely, a larger gradient indicates that the loss function changes more drastically at that position, implying that there is more room for improvement with the parameter involved; a smaller gradient indicates that the loss function changes less and the learning of that part is close to saturation, with less benefit from further training. We use ViTDet as our baseline and conduct experiments on three remote sensing target detection datasets to verify the effectiveness of the method. Our method provides a minimum speedup ratio of 1.38×, while maintaining a maximum accuracy loss of only 2.5%.
Full article
►▼
Show Figures
Open AccessReview
A Contemporary Survey on Deepfake Detection: Datasets, Algorithms, and Challenges
by
Liang Yu Gong and Xue Jun Li
Cited by 49 | Viewed by 34116
Abstract
Deepfakes are notorious for their unethical and malicious applications to achieve economic, political, and social reputation goals. Recent years have seen widespread facial forgery, which does not require technical skills. Since the development of generative adversarial networks (GANs) and diffusion models (DMs), deepfake
[...] Read more.
Deepfakes are notorious for their unethical and malicious applications to achieve economic, political, and social reputation goals. Recent years have seen widespread facial forgery, which does not require technical skills. Since the development of generative adversarial networks (GANs) and diffusion models (DMs), deepfake generation has been moving toward better quality. Therefore, it is necessary to find an effective method to detect fake media. This contemporary survey provides a comprehensive overview of several typical facial forgery detection methods proposed from 2019 to 2023. We also analyze and group them into four categories in terms of their feature extraction methods and network architectures: traditional convolutional neural network (CNN)-based detection, CNN backbone with semi-supervised detection, transformer-based detection, and biological signal detection. Furthermore, it summarizes several representative deepfake detection datasets with their advantages and disadvantages. Finally, we evaluate the performance of these detection models with respect to different datasets by comparing their evaluating metrics. Across all experimental results on these state-of-the-art detection models, we find that the accuracy is largely degraded if we utilize cross-dataset evaluation. These results will provide a reference for further research to develop more reliable detection algorithms.
Full article
►▼
Show Figures
Open AccessArticle
An Efficient Ship-Detection Algorithm Based on the Improved YOLOv5
by
Jia Wang, Qiaoruo Pan, Daohua Lu and Yushuang Zhang
Cited by 13 | Viewed by 2875
Abstract
Aiming to solve the problems of large-scale changes, the dense occlusion of ship targets, and a low detection accuracy caused by challenges in the localization and identification of small targets, this paper proposes a ship target-detection algorithm based on the improved YOLOv5s model.
[...] Read more.
Aiming to solve the problems of large-scale changes, the dense occlusion of ship targets, and a low detection accuracy caused by challenges in the localization and identification of small targets, this paper proposes a ship target-detection algorithm based on the improved YOLOv5s model. First, in the neck part, a weighted bidirectional feature pyramid network is used from top to bottom and from bottom to top to solve the problem of a large target scale variation. Second, the CNeB2 module is designed to enhance the correlation of coded spatial space, reduce interference from redundant information, and enhance the model’s ability to distinguish dense targets. Finally, the Separated and Enhancement Attention Module attention mechanism is introduced to enhance the proposed model’s ability to identify and locate small targets. The proposed model is verified by extensive experiments on the sea trial dataset. The experimental results show that compared to the YOLOv5 algorithm, the accuracy, recall rate, and mean average precision of the proposed algorithm are increased by 1.3%, 1.2%, and 2%, respectively; meanwhile, the average precision value of the proposed algorithm for the dense occlusion category is increased by 4.5%. In addition, the average precision value of the proposed algorithm for the small target category is increased by 5% compared to the original YOLOv5 algorithm. Moreover, the detection speed of the proposed algorithm is 66.23 f/s, which can meet the requirements for detection speed and ensure high detection accuracy and, thus, realize high-speed and high-precision ship detection.
Full article
►▼
Show Figures
Open AccessArticle
INTS-Net: Improved Navigator-Teacher-Scrutinizer Network for Fine-Grained Visual Categorization
by
Huilong Jin, Jiangfan Xie, Jia Zhao, Shuang Zhang, Tian Wen, Song Liu and Ziteng Li
Cited by 2 | Viewed by 2560
Abstract
Fine-grained image recognition, as a significant branch of computer vision, has become prevalent in various applications in the real world. However, this image recognition is more challenging than general image recognition due to the highly localized and subtle differences in special parts. Up
[...] Read more.
Fine-grained image recognition, as a significant branch of computer vision, has become prevalent in various applications in the real world. However, this image recognition is more challenging than general image recognition due to the highly localized and subtle differences in special parts. Up to now, many classic models, including Bilinear Convolutional Neural Networks (Bilinear CNNs), Destruction and Construction Learning (DCL), etc., have emerged to make corresponding improvements. This paper focuses on optimizing the Navigator-Teacher-Scrutinizer Network (NTS-Net). The structure of NTS-Net determines its strong ability to capture subtle information areas. However, research finds that this advantage will lead to a bottleneck of the model’s learning ability. During the training process, the loss value of the training set approaches zero prematurely, which is not conducive to later model learning. Therefore, this paper proposes the INTS-Net model, in which the Stochastic Partial Swap (SPS) method is flexibly added to the feature extractor of NTS-Net. By injecting noise into the model during training, neurons are activated in a more balanced and efficient manner. In addition, we obtain a speedup of about 4.5% in test time by fusing batch normalization and convolution. Experiments conducted on CUB-200-2011 and Stanford cars demonstrate the superiority of INTS-Net.
Full article
►▼
Show Figures
Open AccessArticle
Attention-Enhanced Lightweight One-Stage Detection Algorithm for Small Objects
by
Nan Jia, Zongkang Wei and Bangyu Li
Cited by 8 | Viewed by 2645
Abstract
The majority of object detection algorithms based on convolutional neural network are focused on larger objects. In order to improve the accuracy and efficiency of small object detection, a novel lightweight object detection algorithm with attention enhancement is proposed in this paper. The
[...] Read more.
The majority of object detection algorithms based on convolutional neural network are focused on larger objects. In order to improve the accuracy and efficiency of small object detection, a novel lightweight object detection algorithm with attention enhancement is proposed in this paper. The network part of the proposed algorithm is based on a single-stage framework and takes MobileNetV3-Large as a backbone. The representation of shallower scale features in the scale fusion module is enhanced by introducing an additional injection path from the backbone and a detection head specially responsible for detecting small objects is added. Instead of pooling operators, dilated convolution with hierarchical aggregation is used to reduce the effect of background pixels on the accuracy of small object locations. To improve the efficacy of merging, the spatial and channel weights of scale features are modified adaptively. Last but not least, to improve the representation of small objects in the training datasets, the Consistent Mixed Cropping method is also proposed. The small labels of standard datasets are expanded with the self-collected samples for the training of the algorithm network. According to the test results and visualization on the 64-Bit Extended (X86-64) platform and embedded Advanced RISC Machine (ARM) platform, we find that the average accuracy (mAP) of the proposed algorithm is 4.6% higher than YOLOv4 algorithm, which achieves better small object detection performance than YOLOv4 algorithm, and the computational complexity is only 12% of YOLOv4 algorithm.
Full article
►▼
Show Figures
Open AccessArticle
DMFF-Net: Densely Macroscopic Feature Fusion Network for Fast Magnetic Resonance Image Reconstruction
by
Zhicheng Sun, Yanwei Pang, Yong Sun and Xiaohan Liu
Cited by 2 | Viewed by 2056
Abstract
The task of fast magnetic resonance (MR) image reconstruction is to reconstruct high-quality MR images from undersampled images. Most of the existing methods are based on U-Net, and these methods mainly adopt several simple connections within the network, which we call microscopic design
[...] Read more.
The task of fast magnetic resonance (MR) image reconstruction is to reconstruct high-quality MR images from undersampled images. Most of the existing methods are based on U-Net, and these methods mainly adopt several simple connections within the network, which we call microscopic design ideas. However, these considerations cannot make full use of the feature information inside the network, which leads to low reconstruction quality. To solve this problem, we rethought the feature utilization method of the encoder and decoder network from a macroscopic point of view and propose a densely macroscopic feature fusion network for fast magnetic resonance image reconstruction. Our network uses three stages to reconstruct high-quality MR images from undersampled images from coarse to fine. We propose an inter-stage feature compensation structure (IFCS) which makes full use of the feature information of different stages and fuses the features of different encoders and decoders. This structure uses a connection method between sub-networks similar to dense form to fuse encoding and decoding features, which is called densely macroscopic feature fusion. A cross network attention block (CNAB) is also proposed to further improve the reconstruction performance. Experiments show that the quality of undersampled MR images is greatly improved, and the detailed information of MR images is enriched to a large extent. Our reconstruction network is lighter than many previous methods, but it achieves better performance. The performance of our method is about 10% higher than that of the original method, and about 3% higher than that of most existing methods. Compared with the nearest optimal algorithms, the performance of our method is improved by about 0.01–0.45%, and our computational complexity is only 1/14 of these algorithms.
Full article
►▼
Show Figures
Open AccessArticle
Research on Steel Surface Defect Detection Based on YOLOv5 with Attention Mechanism
by
Jianting Shi, Jian Yang and Yingtao Zhang
Cited by 50 | Viewed by 5579
Abstract
Due to the irresistible factors of material properties and processing technology in the steel production, there may be different types of defects on the steel surface, such as rolling scale, patches and so on, which seriously affect the quality of steel, and thus
[...] Read more.
Due to the irresistible factors of material properties and processing technology in the steel production, there may be different types of defects on the steel surface, such as rolling scale, patches and so on, which seriously affect the quality of steel, and thus have a negative impact on the economic efficiency of the enterprises. Different from the general target detection tasks, the defect detection tasks have small targets and extreme aspect ratio targets. The contradiction of high positioning accuracy for targets and their inconspicuous features makes the defect detection tasks difficult. Therefore, the original YOLOv5 algorithm was improved in this paper to enhance the accuracy and efficiency of detecting defects on steel surfaces. Firstly, an attention mechanism module was added in the process of transmitting the shallow feature map from the backbone structure to the neck structure, aiming at improving the algorithm attention to small targets information in the feature map and suppressing the influence of irrelevant information on the algorithm, so as to improve the detection accuracy of the algorithm for small targets. Secondly, in order to improve the algorithm effectiveness in detecting extreme aspect ratio targets, K-means algorithm was used to cluster and analyze the marked steel surface defect dataset, so that the anchor boxes can be adapted to all types of sizes, especially for extreme aspect ratio defects. The experimental results showed that the improved algorithms were better than the original YOLOv5 algorithm in terms of the average precision and the mean average precision. The mean average precision, demonstrating the largest increase among the improved YOLOv5 algorithms, was increased by 4.57% in the YOLOv5+CBAM algorithm. In particular, the YOLOv5+CBAM algorithm had a significant increase in the average precision for small targets and extreme aspect ratio targets. Therefore, the YOLOv5+CBAM algorithm could make the accurate localization and classification of steel surface defects, which can provide a reference for the automatic detection of steel defects.
Full article
►▼
Show Figures
Open AccessArticle
A Vision-Based Bio-Inspired Reinforcement Learning Algorithms for Manipulator Obstacle Avoidance
by
Abhilasha Singh, Mohamed Shakeel, V. Kalaichelvi and R. Karthikeyan
Cited by 8 | Viewed by 4231
Abstract
Path planning for robotic manipulators has proven to be a challenging issue in industrial applications. Despite providing precise waypoints, the traditional path planning algorithm requires a predefined map and is ineffective in complex, unknown environments. Reinforcement learning techniques can be used in cases
[...] Read more.
Path planning for robotic manipulators has proven to be a challenging issue in industrial applications. Despite providing precise waypoints, the traditional path planning algorithm requires a predefined map and is ineffective in complex, unknown environments. Reinforcement learning techniques can be used in cases where there is a no environmental map. For vision-based path planning and obstacle avoidance in assembly line operations, this study introduces various Reinforcement Learning (RL) algorithms based on discrete state-action space, such as Q-Learning, Deep Q Network (DQN), State-Action-Reward- State-Action (SARSA), and Double Deep Q Network (DDQN). By positioning the camera in an eye-to-hand position, this work used color-based segmentation to identify the locations of obstacles, start, and goal points. The homogeneous transformation technique was used to further convert the pixel values into robot coordinates. Furthermore, by adjusting the number of episodes, steps per episode, learning rate, and discount factor, a performance study of several RL algorithms was carried out. To further tune the training hyperparameters, genetic algorithms (GA) and particle swarm optimization (PSO) were employed. The length of the path travelled, the average reward, the average number of steps, and the time required to reach the objective point were all measured and compared for each of the test cases. Finally, the suggested methodology was evaluated using a live camera that recorded the robot workspace in real-time. The ideal path was then drawn using a TAL BRABO 5 DOF manipulator. It was concluded that waypoints obtained via Double DQN showed an improved performance and were able to avoid the obstacles and reach the goal point smoothly and efficiently.
Full article
►▼
Show Figures
Open AccessArticle
MFFRand: Semantic Segmentation of Point Clouds Based on Multi-Scale Feature Fusion and Multi-Loss Supervision
by
Zhiqing Miao, Shaojing Song, Pan Tang, Jian Chen, Jinyan Hu and Yumei Gong
Cited by 4 | Viewed by 2821
Abstract
With the application of the random sampling method in the down-sampling of point clouds data, the processing speed of point clouds has been greatly improved. However, the utilization of semantic information is still insufficient. To address this problem, we propose a point cloud
[...] Read more.
With the application of the random sampling method in the down-sampling of point clouds data, the processing speed of point clouds has been greatly improved. However, the utilization of semantic information is still insufficient. To address this problem, we propose a point cloud semantic segmentation network called MFFRand (Multi-Scale Feature Fusion Based on RandLA-Net). Based on RandLA-Net, a multi-scale feature fusion module is developed, which is stacked by encoder-decoders with different depths. The feature maps extracted by the multi-scale feature fusion module are continuously concatenated and fused. Furthermore, for the network to be trained better, the multi-loss supervision module is proposed, which could strengthen the control of the training process of the local structure by adding sub-losses in the end of different decoder structures. Moreover, the trained MFFRand network could be connected to the inference network by different decoder terminals separately, which could achieve the inference of different depths of the network. Compared to RandLA-Net, MFFRand has improved mIoU on both S3DIS and Semantic3D datasets, reaching 71.1% and 74.8%, respectively. Extensive experimental results on the point cloud dataset demonstrate the effectiveness of our method.
Full article
►▼
Show Figures
Open AccessArticle
The Incoherence of Deep Isotropic Neural Networks Increases Their Performance in Image Classification
by
Wenfeng Feng, Xin Zhang, Qiushuang Song and Guoying Sun
Cited by 3 | Viewed by 2634
Abstract
Although neural-network architectures are critical for their performance, how the structural characteristics of a neural network affect its performance has still not been fully explored. Here, we map architectures of neural networks to directed acyclic graphs (DAGs), and find that incoherence, a structural
[...] Read more.
Although neural-network architectures are critical for their performance, how the structural characteristics of a neural network affect its performance has still not been fully explored. Here, we map architectures of neural networks to directed acyclic graphs (DAGs), and find that incoherence, a structural characteristic to measure the order of DAGs, is a good indicator for the performance of corresponding neural networks. Therefore, we propose a deep isotropic neural-network architecture by folding a chain of the same blocks and then connecting the blocks with skip connections at different distances. Our model, named FoldNet, has two distinguishing features compared with traditional residual neural networks. First, the distances between block pairs connected by skip connections increase from always equal to one to specially selected different values, which lead to more incoherent graphs and let the neural network explore larger receptive fields and, thus, enhance its multi-scale representation ability. Second, the number of direct paths increases from one to multiple, which leads to a larger proportion of shorter paths and, thus, improves the direct propagation of information throughout the entire network. Image-classification results on CIFAR-10 and Tiny ImageNet benchmarks suggested that our new network architecture performs better than traditional residual neural networks. FoldNet with 25.4M parameters can achieve 72.67% top-1 accuracy on the Tiny ImageNet after 100 epochs, which is competitive compared with the-state-of-art results on the Tiny ImageNet.
Full article
►▼
Show Figures
Open AccessArticle
A Novel Approach to Maritime Image Dehazing Based on a Large Kernel Encoder–Decoder Network with Multihead Pyramids
by
Wei Yang, Hongwei Gao, Yueqiu Jiang and Xin Zhang
Cited by 6 | Viewed by 2597
Abstract
With the continuous increase in human–robot integration, battlefield formation is experiencing a revolutionary change. Unmanned aerial vehicles, unmanned surface vessels, combat robots, and other new intelligent weapons and equipment will play an essential role on future battlefields by performing various tasks, including situational
[...] Read more.
With the continuous increase in human–robot integration, battlefield formation is experiencing a revolutionary change. Unmanned aerial vehicles, unmanned surface vessels, combat robots, and other new intelligent weapons and equipment will play an essential role on future battlefields by performing various tasks, including situational reconnaissance, monitoring, attack, and communication relay. Real-time monitoring of maritime scenes is the basis of battle-situation and threat estimation in naval battlegrounds. However, images of maritime scenes are usually accompanied by haze, clouds, and other disturbances, which blur the images and diminish the validity of their contents. This will have a severe adverse impact on many downstream tasks. A novel large kernel encoder–decoder network with multihead pyramids (LKEDN-MHP) is proposed to address some maritime image dehazing-related issues. The LKEDN-MHP adopts a multihead pyramid approach to form a hybrid representation space comprising reflection, shading, and semanteme. Unlike standard convolutional neural networks (CNNs), the LKEDN-MHP uses many kernels with a 7 × 7 or larger scale to extract features. To reduce the computational burden, depthwise (DW) convolution combined with re-parameterization is adopted to form a hybrid model stacked by a large number of different receptive fields, further enhancing the hybrid receptive fields. To restore the natural hazy maritime scenes as much as possible, we apply digital twin technology to build a simulation system in virtual space. The final experimental results based on the evaluation metrics of the peak signal-to-noise ratio, structural similarity index measure, Jaccard index, and Dice coefficient show that our LKEDN-MHP significantly enhances dehazing and real-time performance compared with those of state-of-the-art approaches based on vision transformers (ViTs) and generative adversarial networks (GANs).
Full article
►▼
Show Figures
Open AccessArticle
Automatic Modulation Classification with Neural Networks via Knowledge Distillation
by
Shuai Wang and Chunwu Liu
Cited by 3 | Viewed by 3771
Abstract
Deep learning is used for automatic modulation recognition in neural networks, and because of the need for high classification accuracy, deeper and deeper networks are used. However, these are computationally very expensive for neural network training and inference, so its utility in the
[...] Read more.
Deep learning is used for automatic modulation recognition in neural networks, and because of the need for high classification accuracy, deeper and deeper networks are used. However, these are computationally very expensive for neural network training and inference, so its utility in the case of a mobile with memory limitations or weak computational power is questionable. As a result, a trade-off between network depth and network classification accuracy must be considered. To address this issue, we used a knowledge distillation method in this study to improve the classification accuracy of a small network model. First, we trained Inception–Resnet as a teacher network, which has a size of 311.77 MB and a final peak classification accuracy of 93.09%. We used the method to train convolutional neural network 3 (CNN3) and increase its peak classification accuracy from 79.81 to 89.36%, with a network size of 0.37 MB. It was also used similarly to train mini Inception–Resnet and increase its peak accuracy from 84.18 to 93.59%, with a network size of 39.69 MB. When we compared all classification accuracy peaks, we discover that knowledge distillation improved small networks and that the student network had the potential to outperform the teacher network. Using knowledge distillation, a small network model can achieve the classification accuracy of a large network model. In practice, choosing the appropriate student network based on the constraints of the usage conditions while using knowledge distillation (KD) would be a way to meet practical needs.
Full article
►▼
Show Figures
Open AccessArticle
A New Compact Method Based on a Convolutional Neural Network for Classification and Validation of Tomato Plant Disease
by
Shivali Amit Wagle, Harikrishnan R, Vijayakumar Varadarajan and Ketan Kotecha
Cited by 9 | Viewed by 3104
Abstract
With recent advancements in the classification methods of various domains, deep learning has shown remarkable results over traditional neural networks. A compact convolutional neural network (CNN) model with reduced computational complexity that performs equally well compared to the pretrained ResNet-101 model was developed.
[...] Read more.
With recent advancements in the classification methods of various domains, deep learning has shown remarkable results over traditional neural networks. A compact convolutional neural network (CNN) model with reduced computational complexity that performs equally well compared to the pretrained ResNet-101 model was developed. This three-layer CNN model was developed for plant leaf classification in this work. The classification of disease in tomato plant leaf images of the healthy and disease classes from the PlantVillage (PV) database is discussed in this work. Further, it supports validating the models with the images taken at “Krishi Vigyan Kendra Narayangaon (KVKN),” Pune, India. The disease categories were chosen based on their prevalence in Indian states. The proposed approach presents a performance improvement concerning other state-of-the-art methods; it achieved classification accuracies of 99.13%, 99.51%, and 99.40% with N1, N2, and N3 models, respectively, on the PV dataset. Experimental results demonstrate the validity of the proposed approach under complex background conditions. For the images captured at KVKN for predicting tomato plant leaf disease, the validation accuracy was 100% for the N1 model, 98.44% for the N2 model, and 96% for the N3 model. The training time for the developed N2 model was reduced by 89% compared to the ResNet-101 model. The models developed are smaller, more efficient, and less time-complex. The performance of the developed model will help us to take a significant step towards managing the infected plants. This will help farmers and contribute to sustainable agriculture.
Full article
►▼
Show Figures
Open AccessArticle
Global Correlation Enhanced Hand Action Recognition Based on NST-GCN
by
Shiqiang Yang, Qi Li, Duo He, Jinhua Wang and Dexin Li
Cited by 2 | Viewed by 2776
Abstract
Hand action recognition is an important part of intelligent monitoring, human–computer interaction, robotics and other fields. Compared with other methods, the hand action recognition method using skeleton information can ignore the error effects caused by complex background and movement speed changes, and the
[...] Read more.
Hand action recognition is an important part of intelligent monitoring, human–computer interaction, robotics and other fields. Compared with other methods, the hand action recognition method using skeleton information can ignore the error effects caused by complex background and movement speed changes, and the computational cost is relatively small. The spatial-temporal graph convolution networks (ST-GCN) model has excellent performance in the field of skeleton-based action recognition. In order to solve the problem of the root joint and the further joint not being closely connected, resulting in a poor hand-action-recognition effect, this paper firstly uses the dilated convolution to replace the standard convolution in the temporal dimension. This is in order to process the time series features of the hand action video, which increases the receptive field in the temporal dimension and enhances the connection between features. Then, by adding non-physical connections, the connection between the joints of the fingertip and the root of the finger is established, and a new partition strategy is adopted to strengthen the hand correlation of each joint point information. This helps to improve the network’s ability to extract the spatial-temporal features of the hand. The improved model is tested on public datasets and real scenarios. The experimental results show that compared with the original model, the 14-category top-1 and 28-category top-1 evaluation indicators of the dataset have been improved by 4.82% and 6.96%. In the real scene, the recognition effect of the categories with large changes in hand movements is better, and the recognition results of the categories with similar trends of hand movements are poor, so there is still room for improvement.
Full article
►▼
Show Figures
Open AccessArticle
Face-Based CNN on Triangular Mesh with Arbitrary Connectivity
by
Hui Wang, Yu Guo and Zhengyou Wang
Cited by 4 | Viewed by 4750
Abstract
Applying convolutional neural networks (CNNs) to triangular meshes has always been a challenging task. Because of the complex structure of the meshes, most of the existing methods apply CNNs indirectly to them, and require complex preprocessing or transformation of the meshes. In this
[...] Read more.
Applying convolutional neural networks (CNNs) to triangular meshes has always been a challenging task. Because of the complex structure of the meshes, most of the existing methods apply CNNs indirectly to them, and require complex preprocessing or transformation of the meshes. In this paper, we propose a novel face-based CNN, which can be directly applied to triangular meshes with arbitrary connectivity by defining face convolution and pooling. The proposed approach takes each face of the meshes as the basic element, similar to CNNs with pixels of 2D images. First, the intrinsic features of the faces are used as the input features of the network. Second, a sort convolution operation with adjustable convolution kernel sizes is constructed to extract the face features. Third, we design an approximately uniform pooling operation by learnable face collapse, which can be applied to the meshes with arbitrary connectivity, and we directly use its inverse operation as unpooling. Extensive experiments show that the proposed approach is comparable to, or can even outperform, state-of-the-art methods in mesh classification and mesh segmentation.
Full article
►▼
Show Figures
Open AccessArticle
LLGF-Net: Learning Local and Global Feature Fusion for 3D Point Cloud Semantic Segmentation
by
Jiazhe Zhang, Xingwei Li, Xianfa Zhao and Zheng Zhang
Cited by 4 | Viewed by 3783
Abstract
Three-dimensional (3D) point cloud semantic segmentation is fundamental in complex scene perception. Currently, although various efficient 3D semantic segmentation networks have been proposed, the overall effect has a certain gap to 2D image segmentation. Recently, some transformer-based methods have opened a new stage
[...] Read more.
Three-dimensional (3D) point cloud semantic segmentation is fundamental in complex scene perception. Currently, although various efficient 3D semantic segmentation networks have been proposed, the overall effect has a certain gap to 2D image segmentation. Recently, some transformer-based methods have opened a new stage in computer vision, which also has accelerated the effective development of methods in 3D point cloud segmentation. In this paper, we propose a novel semantic segmentation network named LLGF-Net that can aggregate features from both local and global levels of point clouds, effectively improving the ability to extract feature information from point clouds. Specifically, we adopt the multi-head attention mechanism in the original Transformer model to obtain the local features of point clouds and then use the position-distance information of point clouds in 3D space to obtain the global features. Finally, the local features and global features are fused and embedded into the encoder–decoder network to generate our method. Our extensive experimental results on the 3D point cloud dataset demonstrate the effectiveness and superiority of our method.
Full article
►▼
Show Figures
Open AccessArticle
Depth Estimation of Monocular PCB Image Based on Self-Supervised Convolution Network
by
Zedong Huang, Jinan Gu, Jing Li, Shuwei Li and Junjie Hu
Viewed by 2440
Abstract
To improve the accuracy of using deep neural networks to predict the depth information of a single image, we proposed an unsupervised convolutional neural network for single-image depth estimation. Firstly, the network is improved by introducing a dense residual module into the encoding
[...] Read more.
To improve the accuracy of using deep neural networks to predict the depth information of a single image, we proposed an unsupervised convolutional neural network for single-image depth estimation. Firstly, the network is improved by introducing a dense residual module into the encoding and decoding structure. Secondly, the optimized hybrid attention module is introduced into the network. Finally, stereo image is used as the training data of the network to realize the end-to-end single-image depth estimation. The experimental results on KITTI and Cityscapes data sets show that compared with some classical algorithms, our proposed method can obtain better accuracy and lower error. In addition, we train our models on PCB data sets in industrial environments. Experiments in several scenarios verify the generalization ability of the proposed method and the excellent performance of the model.
Full article
►▼
Show Figures
Open AccessReview
Face Image Analysis Using Machine Learning: A Survey on Recent Trends and Applications
by
Muhammad Hameed Siddiqi, Khalil Khan, Rehan Ullah Khan and Amjad Alsirhani
Cited by 9 | Viewed by 5128
Abstract
Human face image analysis using machine learning is an important element in computer vision. The human face image conveys information such as age, gender, identity, emotion, race, and attractiveness to both human and computer systems. Over the last ten years, face analysis methods
[...] Read more.
Human face image analysis using machine learning is an important element in computer vision. The human face image conveys information such as age, gender, identity, emotion, race, and attractiveness to both human and computer systems. Over the last ten years, face analysis methods using machine learning have received immense attention due to their diverse applications in various tasks. Although several methods have been reported in the last ten years, face image analysis still represents a complicated challenge, particularly for images obtained from ’in the wild’ conditions. This survey paper presents a comprehensive review focusing on methods in both controlled and uncontrolled conditions. Our work illustrates both merits and demerits of each method previously proposed, starting from seminal works on face image analysis and ending with the latest ideas exploiting deep learning frameworks. We show a comparison of the performance of the previous methods on standard datasets and also present some promising future directions on the topic.
Full article
►▼
Show Figures
Open AccessArticle
Accelerated Diagnosis of Novel Coronavirus (COVID-19)—Computer Vision with Convolutional Neural Networks (CNNs)
by
Arfan Ghani, Akinyemi Aina, Chan Hwang See, Hongnian Yu and Simeon Keates
Cited by 16 | Viewed by 3446
Abstract
Early detection and diagnosis of COVID-19, as well as the exact separation of non-COVID-19 cases in a non-invasive manner in the earliest stages of the disease, are critical concerns in the current COVID-19 pandemic. Convolutional Neural Network (CNN) based models offer a remarkable
[...] Read more.
Early detection and diagnosis of COVID-19, as well as the exact separation of non-COVID-19 cases in a non-invasive manner in the earliest stages of the disease, are critical concerns in the current COVID-19 pandemic. Convolutional Neural Network (CNN) based models offer a remarkable capacity for providing an accurate and efficient system for the detection and diagnosis of COVID-19. Due to the limited availability of RT-PCR (Reverse transcription-polymerase Chain Reaction) tests in developing countries, imaging-based techniques could offer an alternative and affordable solution to detect COVID-19 symptoms. This paper reviewed the current CNN-based approaches and investigated a custom-designed CNN method to detect COVID-19 symptoms from CT (Computed Tomography) chest scan images. This study demonstrated an integrated method to accelerate the process of classifying CT scan images. In order to improve the computational time, a hardware-based acceleration method was investigated and implemented on a reconfigurable platform (FPGA). Experimental results highlight the difference between various approximations of the design, providing a range of design options corresponding to both software and hardware. The FPGA-based implementation involved a reduced pre-processed feature vector for the classification task, which is a unique advantage of this particular application. To demonstrate the applicability of the proposed method, results from the CPU-based classification and the FPGA were measured separately and compared retrospectively.
Full article
►▼
Show Figures
Open AccessArticle
CondNAS: Neural Architecture Search for Conditional CNNs
by
Gunju Park and Youngmin Yi
Cited by 5 | Viewed by 3197
Abstract
As deep learning has become prevalent and adopted in various application domains, the need for efficient convolution neural network (CNN) inference on diverse target platforms has increased. To address the need, a neural architecture search (NAS) technique called once-for-all, or OFA, which aims
[...] Read more.
As deep learning has become prevalent and adopted in various application domains, the need for efficient convolution neural network (CNN) inference on diverse target platforms has increased. To address the need, a neural architecture search (NAS) technique called once-for-all, or OFA, which aims to efficiently find the optimal CNN architecture for the given target platform using genetic algorithm (GA), has recently been proposed. Meanwhile, a conditional CNN architecture, which allows early exits with auxiliary classifiers in the middle of a network to achieve efficient inference without accuracy loss or with negligible loss, has been proposed. In this paper, we propose a NAS technique for the conditional CNN architecture, CondNAS, which efficiently finds a near-optimal conditional CNN architecture for the target platform using GA. By attaching auxiliary classifiers through adaptive pooling, OFA’s SuperNet is successfully extended, such that it incorporates the various conditional CNN sub-networks. In addition, we devise machine learning-based prediction models for the accuracy and latency of an arbitrary conditional CNN, which are used in the GA of CondNAS to efficiently explore the large search space. The experimental results show that the conditional CNNs from CondNAS is 2.52× and 1.75× faster than the CNNs from OFA for Galaxy Note10+ GPU and CPU, respectively.
Full article
►▼
Show Figures
Open AccessArticle
Region Resolution Learning and Region Segmentation Learning with Overall and Body Part Perception for Pedestrian Detection
by
Yu Zhang, Hui Wang, Yizhuo Liu and Mao Lu
Cited by 1 | Viewed by 2547
Abstract
Pedestrian detection is a great challenge, especially in complex and diverse occlusion environments. When a pedestrian is in an occlusion situation, the pedestrian visible part becomes incomplete, and the body bounding box contains part of the pedestrian, other objects and backgrounds. Based on
[...] Read more.
Pedestrian detection is a great challenge, especially in complex and diverse occlusion environments. When a pedestrian is in an occlusion situation, the pedestrian visible part becomes incomplete, and the body bounding box contains part of the pedestrian, other objects and backgrounds. Based on this, we attempt different methods to help the detector learn more features of the pedestrian under different occlusion situations. First, we propose region resolution learning, which learns the pedestrian regions on the input image. Second, we propose fine-grained segmentation learning to learn the outline and shape of different parts of pedestrians. We propose an anchor-free approach that combines a pedestrian detector CSP, region Resolution learning and Segmentation learning (CSPRS). We help the detector to learn extra features. CSPRS provides another way to perceive pixels, outline and shapes in pedestrian areas. This detector includes region resolution learning, and segmentation learning helps the detector to locate pedestrians. By simply adding the region resolution learning branch and segmentation branch, CSPRS achieves good results. The experimental results show that both methods of learning pedestrian features improve performance. We evaluate our proposed detector CSPRS on the CityPersons benchmark, and the experiments show that CSPRS achieved 42.53% on the heavy subset on the CityPersons dataset.
Full article
►▼
Show Figures
Open AccessArticle
Lane following Learning Based on Semantic Segmentation with Chroma Key and Image Superposition
by
Javier Corrochano, Juan M. Alonso-Weber, María Paz Sesmero and Araceli Sanchis
Cited by 3 | Viewed by 3371
Abstract
There are various techniques to approach learning in autonomous driving; however, all of them suffer from some problems. In the case of imitation learning based on artificial neural networks, the system must learn to correctly identify the elements of the environment. In some
[...] Read more.
There are various techniques to approach learning in autonomous driving; however, all of them suffer from some problems. In the case of imitation learning based on artificial neural networks, the system must learn to correctly identify the elements of the environment. In some cases, it takes a lot of effort to tag the images with the proper semantics. This is also relevant given the need to have very varied scenarios to train and to thus obtain an acceptable generalization capacity. In the present work, we propose a technique for automated semantic labeling. It is based on various learning phases using image superposition combining both scenarios with chromas and real indoor scenarios. This allows the generation of augmented datasets that facilitate the learning process. Further improvements by applying noise techniques are also studied. To carry out the validation, a small-scale car model is used that learns to automatically drive on a reduced circuit. A comparison with models that do not rely on semantic segmentation is also performed. The main contribution of our proposal is the possibility of generating datasets for real indoor scenarios with automatic semantic segmentation, without the need for endless human labeling tasks.
Full article
►▼
Show Figures
Open AccessArticle
A Semantic Segmentation Method for Early Forest Fire Smoke Based on Concentration Weighting
by
Zewei Wang, Change Zheng, Jiyan Yin, Ye Tian and Wenbin Cui
Cited by 8 | Viewed by 3398
Abstract
Forest fire smoke detection based on deep learning has been widely studied. Labeling the smoke image is a necessity when building datasets of target detection and semantic segmentation. The uncertainty in labeling the forest fire smoke pixels caused by the non-uniform diffusion of
[...] Read more.
Forest fire smoke detection based on deep learning has been widely studied. Labeling the smoke image is a necessity when building datasets of target detection and semantic segmentation. The uncertainty in labeling the forest fire smoke pixels caused by the non-uniform diffusion of smoke particles will affect the recognition accuracy of the deep learning model. To overcome the labeling ambiguity, the weighted idea was proposed in this paper for the first time. First, the pixel-concentration relationship between the gray value and the concentration of forest fire smoke pixels in the image was established. Second, the loss function of the semantic segmentation method based on concentration weighting was built and improved; thus, the network could pay attention to the smoke pixels differently, an effort to better segment smoke by weighting the loss calculation of smoke pixels. Finally, based on the established forest fire smoke dataset, selection of the optimum weighted factors was made through experiments. mIoU based on the weighted method increased by 1.52% than the unweighted method. The weighted method cannot only be applied to the semantic segmentation and target detection of forest fire smoke, but also has a certain significance to other dispersive target recognition.
Full article
►▼
Show Figures
Open AccessArticle
Multi-Stage Attention-Enhanced Sparse Graph Convolutional Network for Skeleton-Based Action Recognition
by
Chaoyue Li, Lian Zou, Cien Fan, Hao Jiang and Yifeng Liu
Viewed by 2989
Abstract
Graph convolutional networks (GCNs), which model human actions as a series of spatial-temporal graphs, have recently achieved superior performance in skeleton-based action recognition. However, the existing methods mostly use the physical connections of joints to construct a spatial graph, resulting in limited topological
[...] Read more.
Graph convolutional networks (GCNs), which model human actions as a series of spatial-temporal graphs, have recently achieved superior performance in skeleton-based action recognition. However, the existing methods mostly use the physical connections of joints to construct a spatial graph, resulting in limited topological information of the human skeleton. In addition, the action features in the time domain have not been fully explored. To better extract spatial-temporal features, we propose a multi-stage attention-enhanced sparse graph convolutional network (MS-ASGCN) for skeleton-based action recognition. To capture more abundant joint dependencies, we propose a new strategy for constructing skeleton graphs. This simulates bidirectional information flows between neighboring joints and pays greater attention to the information transmission between sparse joints. In addition, a part attention mechanism is proposed to learn the weight of each part and enhance the part-level feature learning. We introduce multiple streams of different stages and merge them in specific layers of the network to further improve the performance of the model. Our model is finally verified on two large-scale datasets, namely NTU-RGB+D and Skeleton-Kinetics. Experiments demonstrate that the proposed MS-ASGCN outperformed the previous state-of-the-art methods on both datasets.
Full article
►▼
Show Figures
Open AccessArticle
Increasing Information Entropy of Both Weights and Activations for the Binary Neural Networks
by
Wanbing Zou, Song Cheng, Luyuan Wang, Guanyu Fu, Delong Shang, Yumei Zhou and Yi Zhan
Cited by 2 | Viewed by 3246
Abstract
In terms of memory footprint requirement and computing speed, the binary neural networks (BNNs) have great advantages in power-aware deployment applications, such as AIoT edge terminals, wearable and portable devices, etc. However, the networks’ binarization process inevitably brings considerable information losses, and further
[...] Read more.
In terms of memory footprint requirement and computing speed, the binary neural networks (BNNs) have great advantages in power-aware deployment applications, such as AIoT edge terminals, wearable and portable devices, etc. However, the networks’ binarization process inevitably brings considerable information losses, and further leads to accuracy deterioration. To tackle these problems, we initiate analyzing from a perspective of the information theory, and manage to improve the networks information capacity. Based on the analyses, our work has two primary contributions: the first is a newly proposed median loss (ML) regularization technique. It improves the binary weights distribution more evenly, and consequently increases the information capacity of BNNs greatly. The second is the batch median of activations (BMA) method. It raises the entropy of activations by subtracting a median value, and simultaneously lowers the quantization error by computing separate scaling factors for the positive and negative activations procedure. Experiment results prove that the proposed methods utilized in ResNet-18 and ResNet-34 individually outperform the Bi-Real baseline by 1.3% and 0.9% Top-1 accuracy on the ImageNet 2012. Proposed ML and BMA for the storage cost and calculation complexity increments are minor and negligible. Additionally, comprehensive experiments also prove that our methods can be applicable and embedded into the present popular BNN networks with accuracy improvement and negligible overhead increment.
Full article
►▼
Show Figures
Open AccessArticle
Improving Heterogeneous Network Knowledge Transfer Based on the Principle of Generative Adversarial
by
Feifei Lei, Jieren Cheng, Yue Yang, Xiangyan Tang, Victor S. Sheng and Chunzao Huang
Cited by 13 | Viewed by 3009
Abstract
Deep learning requires a large amount of datasets to train deep neural network models for specific tasks, and thus training of a new model is a very costly task. Research on transfer networks used to reduce training costs will be the next turning
[...] Read more.
Deep learning requires a large amount of datasets to train deep neural network models for specific tasks, and thus training of a new model is a very costly task. Research on transfer networks used to reduce training costs will be the next turning point in deep learning research. The use of source task models to help reduce the training costs of the target task models, especially heterogeneous systems, is a problem we are studying. In order to quickly obtain an excellent target task model driven by the source task model, we propose a novel transfer learning approach. The model linearly transforms the feature mapping of the target domain and increases the weight value for feature matching to realize the knowledge transfer between heterogeneous networks and add a domain discriminator based on the principle of generative adversarial to speed up feature mapping and learning. Most importantly, this paper proposes a new objective function optimization scheme to complete the model training. It successfully combines the generative adversarial network with the weight feature matching method to ensure that the target model learns the most beneficial features from the source domain for its task. Compared with the previous transfer algorithm, our training results are excellent under the same benchmark for image recognition tasks.
Full article
►▼
Show Figures
Open AccessArticle
VRBagged-Net: Ensemble Based Deep Learning Model for Disaster Event Classification
by
Muhammad Hanif, Muhammad Atif Tahir and Muhammad Rafi
Cited by 7 | Viewed by 3561
Abstract
A flood is an overflow of water that swamps dry land. The gravest effects of flooding are the loss of human life and economic losses. An early warning of these events can be very effective in minimizing the losses. Social media websites such
[...] Read more.
A flood is an overflow of water that swamps dry land. The gravest effects of flooding are the loss of human life and economic losses. An early warning of these events can be very effective in minimizing the losses. Social media websites such as Twitter and Facebook are quite effective in the efficient dissemination of information pertinent to any emergency. Users on these social networking sites share both textual and rich content images and videos. The Multimedia Evaluation Benchmark (MediaEval) offers challenges in the form of shared tasks to develop and evaluate new algorithms, approaches and technologies for explorations and exploitations of multimedia in decision making for real time problems. Since 2015, the MediaEval has been running a shared task of predicting several aspects of flooding and through these shared tasks, many improvements have been observed. In this paper, the classification framework VRBagged-Net is proposed and implemented for flood classification. The framework utilizes the deep learning models Visual Geometry Group (VGG) and Residual Network (ResNet), along with the technique of Bootstrap aggregating (Bagging). Various disaster-based datasets were selected for the validation of the VRBagged-Net framework. All the datasets belong to the MediaEval Benchmark Workshop, this includes Disaster Image Retrieval from Social Media (DIRSM), Flood Classification for Social Multimedia (FCSM) and Image based News Topic Disambiguation (INTD). VRBagged-Net performed encouraging well in all these datasets with slightly different but relevant tasks. It produces Mean Average Precision at different levels of 98.12, and Average Precision at 480 of 93.64 on DIRSM. On the FCSM dataset, it produces an F1 score of 90.58. Moreover, the framework has been applied on the dataset of Image-Based News Topic Disambiguation (INTD), and exceeds the previous best result by producing an F1 evaluation of 93.76. The VRBagged-Net with a slight modification also ranked first in the flood-related Multimedia Task at the MediaEval Workshop 2020.
Full article
►▼
Show Figures
Open AccessArticle
Crowd Counting Using End-to-End Semantic Image Segmentation
by
Khalil Khan, Rehan Ullah Khan, Waleed Albattah, Durre Nayab, Ali Mustafa Qamar, Shabana Habib and Muhammad Islam
Cited by 25 | Viewed by 7239
Abstract
Crowd counting is an active research area within scene analysis. Over the last 20 years, researchers proposed various algorithms for crowd counting in real-time scenarios due to many applications in disaster management systems, public events, safety monitoring, and so on. In our paper,
[...] Read more.
Crowd counting is an active research area within scene analysis. Over the last 20 years, researchers proposed various algorithms for crowd counting in real-time scenarios due to many applications in disaster management systems, public events, safety monitoring, and so on. In our paper, we proposed an end-to-end semantic segmentation framework for crowd counting in a dense crowded image. Our proposed framework was based on semantic scene segmentation using an optimized convolutional neural network. The framework successfully highlighted the foreground and suppressed the background part. The framework encoded the high-density maps through a guided attention mechanism system. We obtained crowd counting through integrating the density maps. Our proposed algorithm classified the crowd counting in each image into groups to adapt the variations occurring in crowd counting. Our algorithm overcame the scale variations of a crowded image through multi-scale features extracted from the images. We conducted experiments with four standard crowd-counting datasets, reporting better results as compared to previous results.
Full article
►▼
Show Figures
Open AccessArticle
Traffic Police Gesture Recognition Based on Gesture Skeleton Extractor and Multichannel Dilated Graph Convolution Network
by
Xin Xiong, Haoyuan Wu, Weidong Min, Jianqiang Xu, Qiyan Fu and Chunjiang Peng
Cited by 27 | Viewed by 5636
Abstract
Traffic police gesture recognition is important in automatic driving. Most existing traffic police gesture recognition methods extract pixel-level features from RGB images which are uninterpretable because of a lack of gesture skeleton features and may result in inaccurate recognition due to background noise.
[...] Read more.
Traffic police gesture recognition is important in automatic driving. Most existing traffic police gesture recognition methods extract pixel-level features from RGB images which are uninterpretable because of a lack of gesture skeleton features and may result in inaccurate recognition due to background noise. Existing deep learning methods are not suitable for handling gesture skeleton features because they ignore the inevitable connection between skeleton joint coordinate information and gestures. To alleviate the aforementioned issues, a traffic police gesture recognition method based on a gesture skeleton extractor (GSE) and a multichannel dilated graph convolution network (MD-GCN) is proposed. To extract discriminative and interpretable gesture skeleton coordinate information, a GSE is proposed to extract skeleton coordinate information and remove redundant skeleton joints and bones. In the gesture discrimination stage, GSE-based features are introduced into the proposed MD-GCN. The MD-GCN constructs a graph convolution with a multichannel dilated to enlarge the receptive field, which extracts body topological and spatiotemporal action features from skeleton coordinates. Comparison experiments with state-of-the-art methods were conducted on a public dataset. The results show that the proposed method achieves an accuracy rate of 98.95%, which is the best and at least 6% higher than that of the other methods.
Full article
►▼
Show Figures
Open AccessArticle
Overwater Image Dehazing via Cycle-Consistent Generative Adversarial Network
by
Shunyuan Zheng, Jiamin Sun, Qinglin Liu, Yuankai Qi and Jianen Yan
Cited by 9 | Viewed by 3949
Abstract
In contrast to images taken on land scenes, images taken over water are more prone to degradation due to the influence of the haze. However, existing image dehazing methods are mainly developed for land-scene images and perform poorly when applied to overwater images.
[...] Read more.
In contrast to images taken on land scenes, images taken over water are more prone to degradation due to the influence of the haze. However, existing image dehazing methods are mainly developed for land-scene images and perform poorly when applied to overwater images. To address this problem, we collect the first overwater image dehazing dataset and propose a Generative Adversial Network (GAN)-based method called OverWater Image Dehazing GAN (OWI-DehazeGAN). Due to the difficulties of collecting paired hazy and clean images, the dataset contains unpaired hazy and clean images taken over water. The proposed OWI-DehazeGAN is composed of an encoder–decoder framework, supervised by a forward-backward translation consistency loss for self-supervision and a perceptual loss for content preservation. In addition to qualitative evaluation, we design an image quality assessment neural network to rank the dehazed images. Experimental results on both real and synthetic test data demonstrate that the proposed method performs superiorly against several state-of-the-art land dehazing methods. Compared with the state-of-the-art, our method gains a significant improvement by 1.94% for SSIM, 7.13% for PSNR and 4.00% for CIEDE2000 on the synthetic test dataset.
Full article
►▼
Show Figures
Open AccessArticle
Robust Image Classification with Cognitive-Driven Color Priors
by
Peng Gu, Chengfei Zhu, Xiaosong Lan, Jie Wang and Shuxiao Li
Cited by 1 | Viewed by 2500
Abstract
Existing image classification methods based on convolutional neural networks usually use a large number of samples to learn classification features hierarchically, causing the problems of over-fitting and error propagation layer by layer. Thus, they are vulnerable to adversarial samples generated by adding imperceptible
[...] Read more.
Existing image classification methods based on convolutional neural networks usually use a large number of samples to learn classification features hierarchically, causing the problems of over-fitting and error propagation layer by layer. Thus, they are vulnerable to adversarial samples generated by adding imperceptible disturbances to input samples. To address the above issue, we propose a cognitive-driven color prior model to memorize the color attributes of target samples inspired by the characteristics of human memory. At inference stage, color priors are indexed from the memory and fused with features of convolutional neural networks to achieve robust image classification. The proposed color prior model is cognitive-driven and has no training parameters, thus it has strong generalization and can effectively defend against adversarial samples. In addition, our method directly combines the features of the prior model with the classification probability of the convolutional neural network, without changing the network structure and its parameters of the existing algorithm. It can be combined with other adversarial attack defense methods, such as various preprocessing modules such as PixelDefense or adversarial training methods, to improve the robustness of image classification. Experiments on several benchmark datasets show that the proposed method improves the anti-interference ability of image classification algorithms.
Full article
►▼
Show Figures
Open AccessArticle
Efficient Facial Landmark Localization Based on Binarized Neural Networks
by
Hanlin Chen, Xudong Zhang, Teli Ma, Haosong Yue, Xin Wang and Baochang Zhang
Cited by 1 | Viewed by 4030
Abstract
Facial landmark localization is a significant yet challenging computer vision task, whose accuracy has been remarkably improved due to the successful application of deep Convolutional Neural Networks (CNNs). However, CNNs require huge storage and computation overhead, thus impeding their deployment on computationally limited
[...] Read more.
Facial landmark localization is a significant yet challenging computer vision task, whose accuracy has been remarkably improved due to the successful application of deep Convolutional Neural Networks (CNNs). However, CNNs require huge storage and computation overhead, thus impeding their deployment on computationally limited platforms. In this paper, to the best of our knowledge, it is the first time that an efficient facial landmark localization is implemented via binarized CNNs. We introduce a new network architecture to calculate the binarized models, referred to as Amplitude Convolutional Networks (ACNs), based on the proposed asynchronous back propagation algorithm. We can efficiently recover the full-precision filters only using a single factor in an end-to-end manner, and the efficiency of CNNs for facial landmark localization is further improved by the extremely compressed 1-bit ACNs. Our ACNs reduce the storage space of convolutional filters by a factor of 32 compared with the full-precision models on dataset LFW+Webface, CelebA, BioID and 300W, while achieving a comparable performance to the full-precision facial landmark localization algorithms.
Full article
►▼
Show Figures
Open AccessEditor’s ChoiceArticle
Pruning Convolutional Neural Networks with an Attention Mechanism for Remote Sensing Image Classification
by
Shuo Zhang, Gengshen Wu, Junhua Gu and Jungong Han
Cited by 37 | Viewed by 7442
Abstract
Despite the great success of Convolutional Neural Networks (CNNs) in various visual recognition tasks, the high computational and storage costs of such deep networks impede their deployments in real-time remote sensing tasks. To this end, considerable attention has been given to the filter
[...] Read more.
Despite the great success of Convolutional Neural Networks (CNNs) in various visual recognition tasks, the high computational and storage costs of such deep networks impede their deployments in real-time remote sensing tasks. To this end, considerable attention has been given to the filter pruning techniques, which enable slimming deep networks with acceptable performance drops and thus implementing them on the remote sensing devices. In this paper, we propose a new scheme, termed Pruning Filter with Attention Mechanism (PFAM), to compress and accelerate traditional CNNs. In particular, a novel correlation-based filter pruning criterion, which explores the long-range dependencies among filters via an attention module, is employed to select the to-be-pruned filters. Distinct from previous methods, the less correlated filters are first pruned after the pruning stage in the current training epoch, and they are reconstructed and updated during the next training epoch. Doing so allows manipulating input data with the maximum information preserved when executing the original training strategy such that the compressed network model can be obtained without the need for the pretrained model. The proposed method is evaluated on three public remote sensing image datasets, and the experimental results demonstrate its superiority, compared to state-of-the-art baselines. Specifically, PFAM achieves a 0.67% accuracy improvement with a 40% model-size reduction on the Aerial Image Dataset (AID) dataset, which is impressive.
Full article
►▼
Show Figures









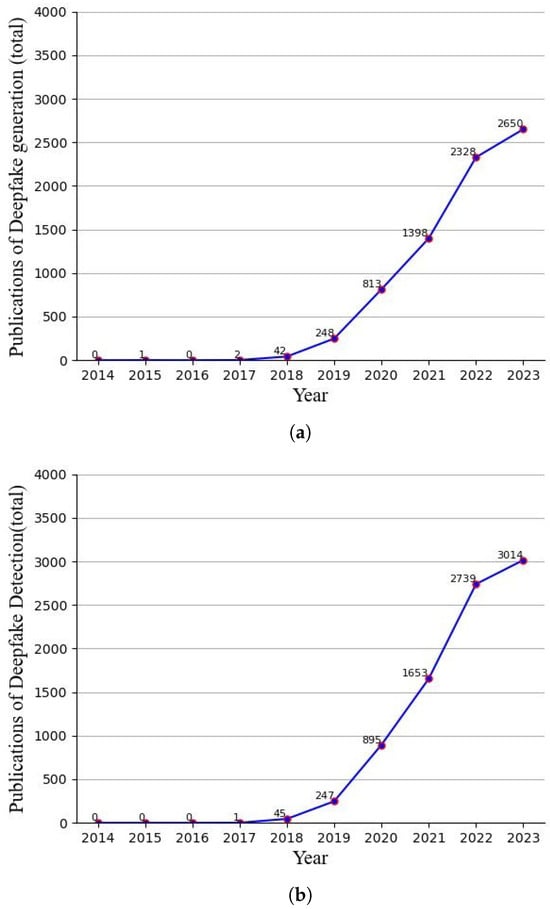
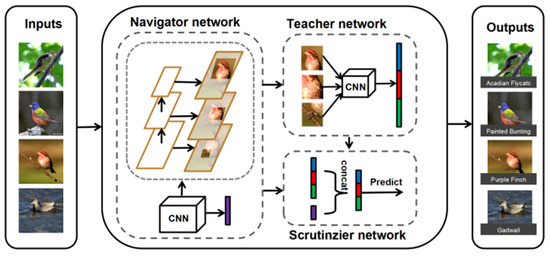
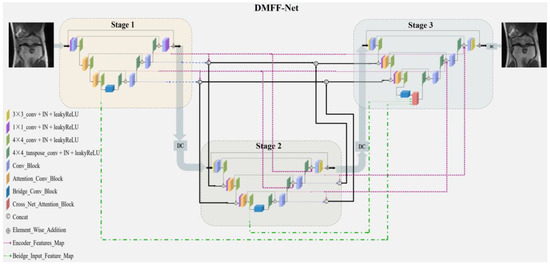
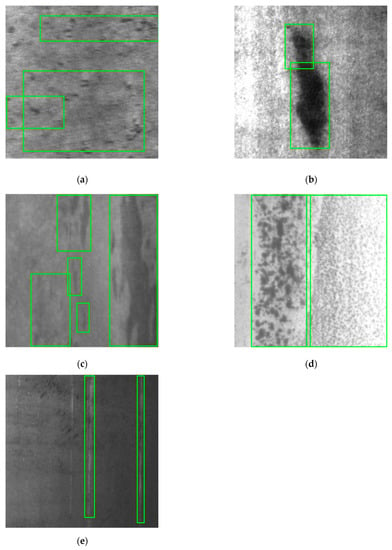

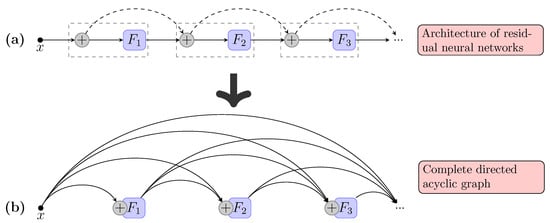

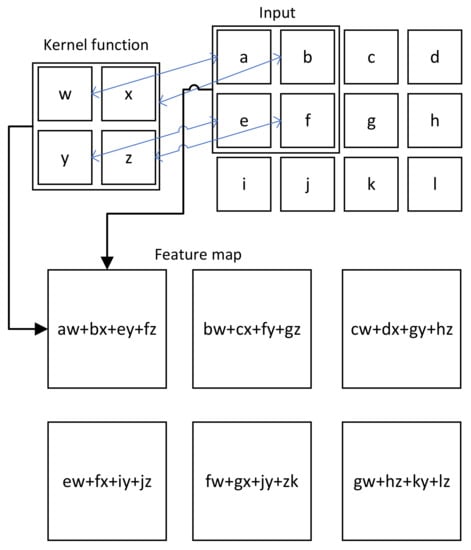





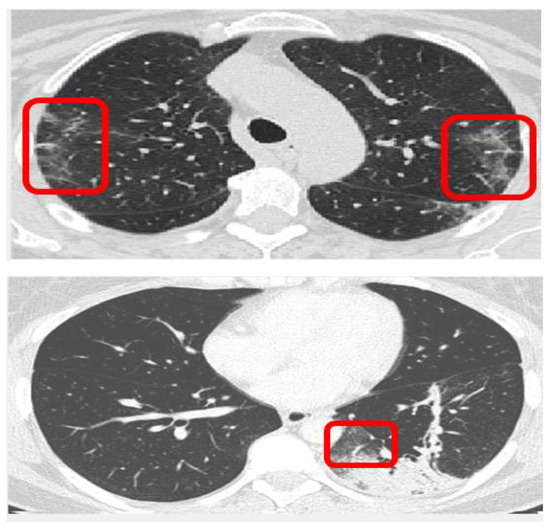
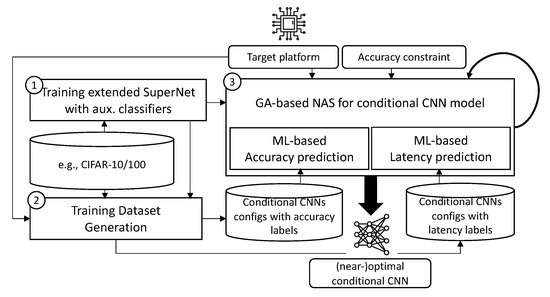
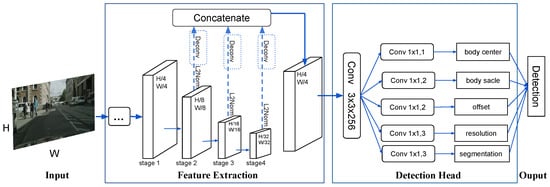

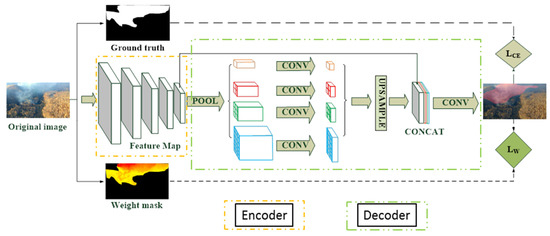
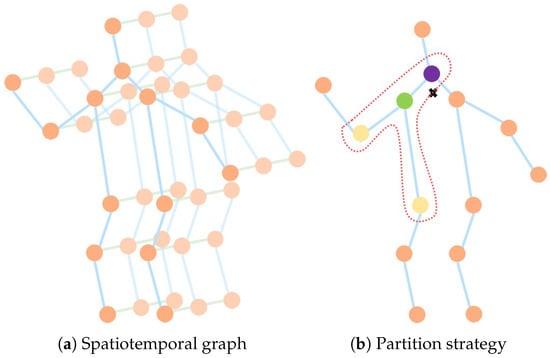
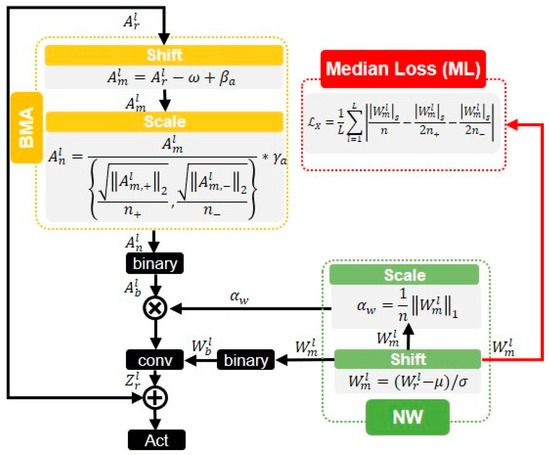
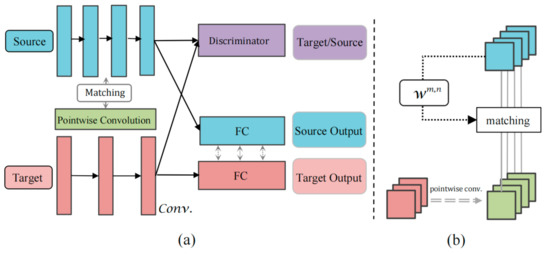
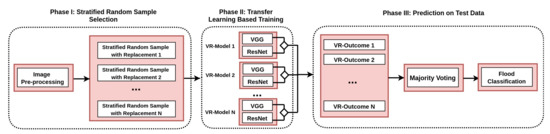



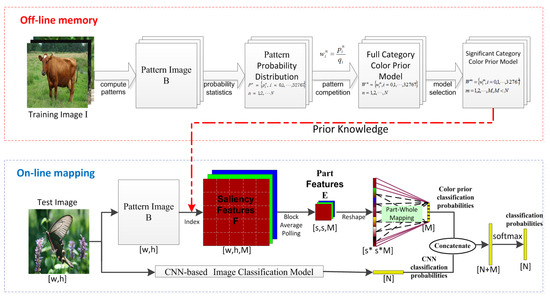
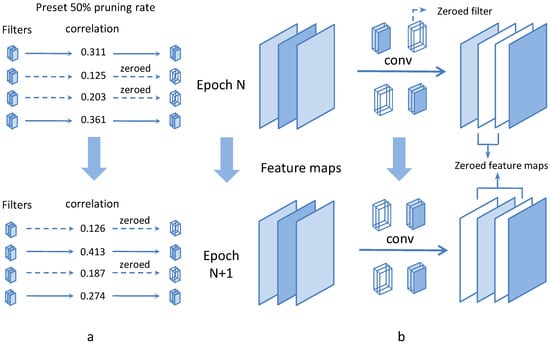
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
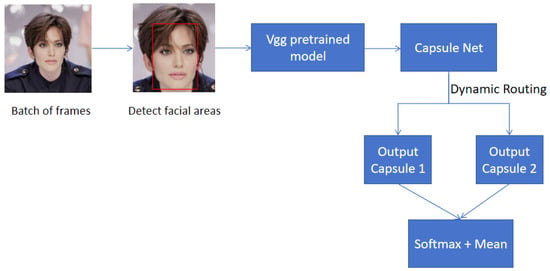{kind=link}
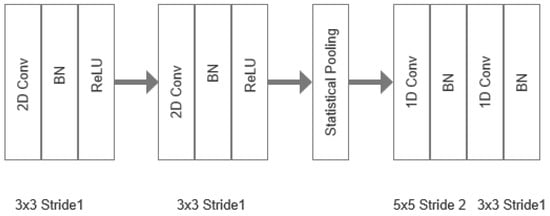{kind=link}
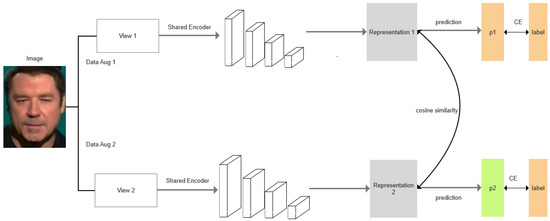{kind=link}
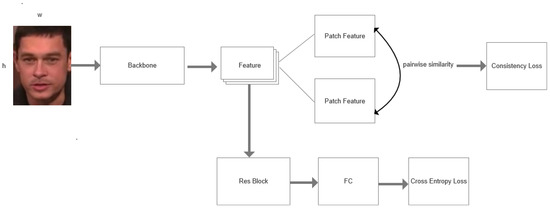{kind=link}
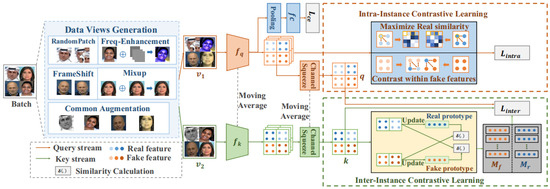{kind=link}
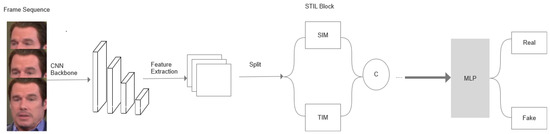{kind=link}
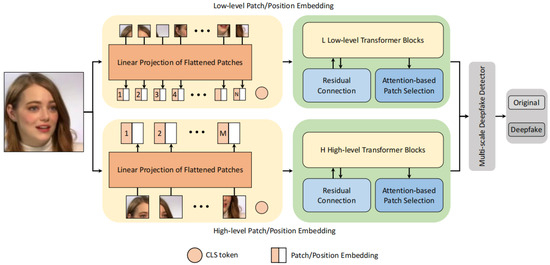{kind=link}
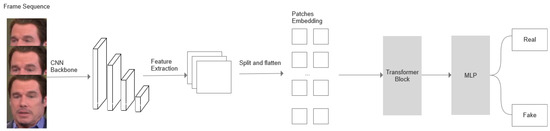{kind=link}
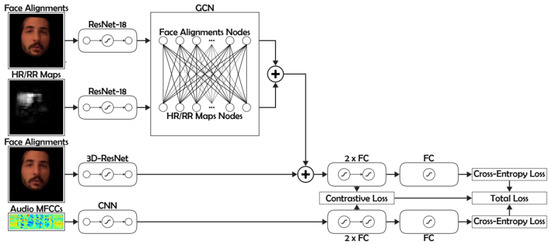{kind=link}
{kind=link}
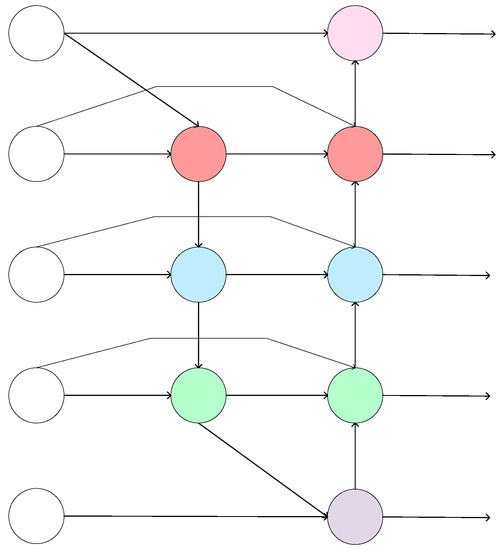{kind=link}
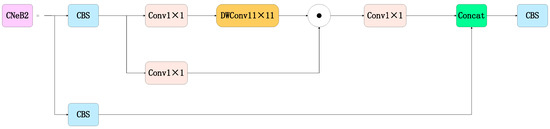{kind=link}
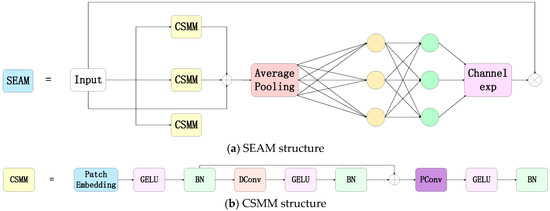{kind=link}
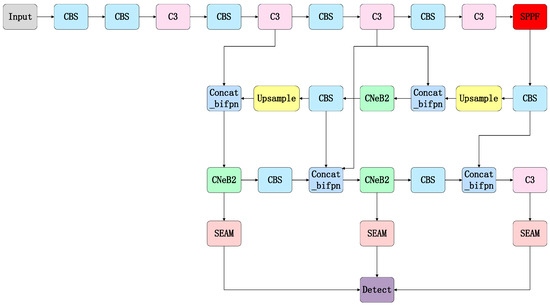{kind=link}
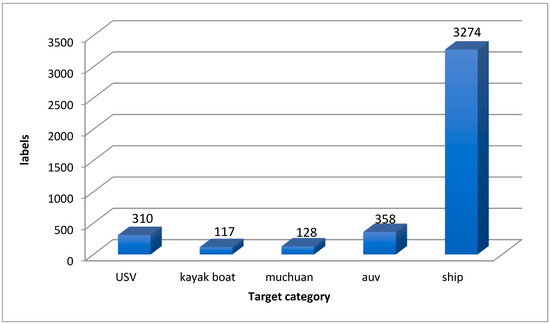{kind=link}
{kind=link}
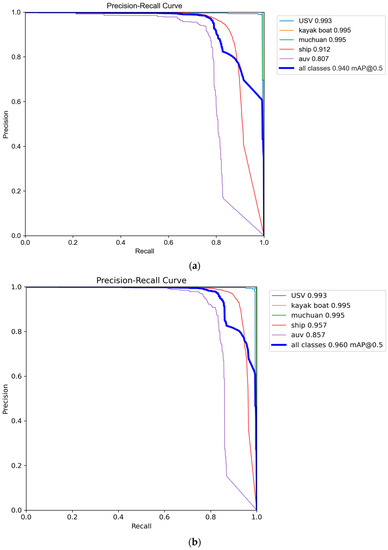{kind=link}
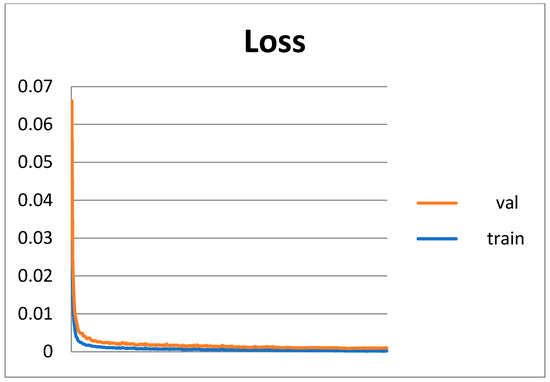{kind=link}
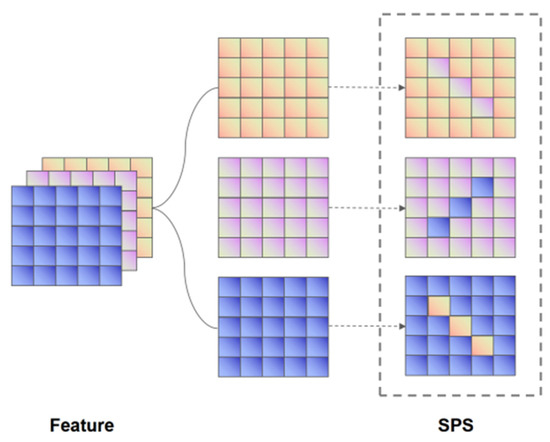{kind=link}
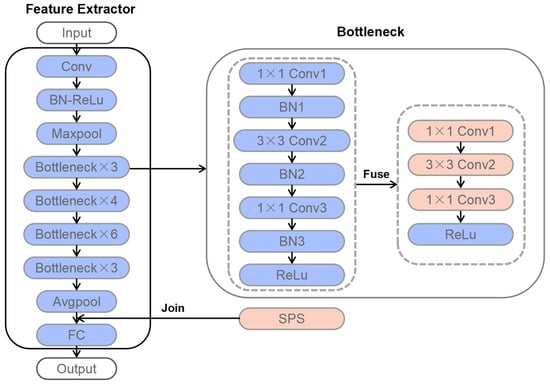{kind=link}
{kind=link}
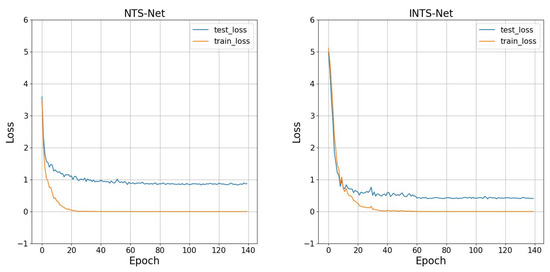{kind=link}
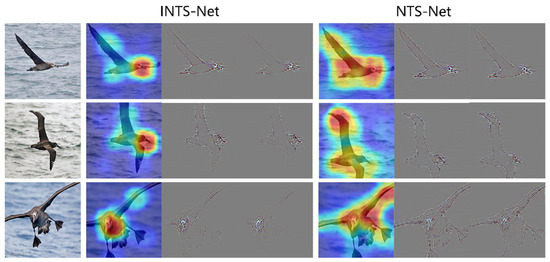{kind=link}
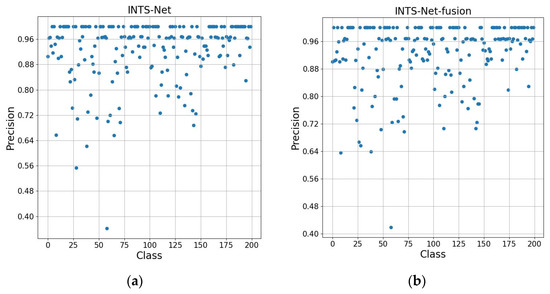{kind=link}
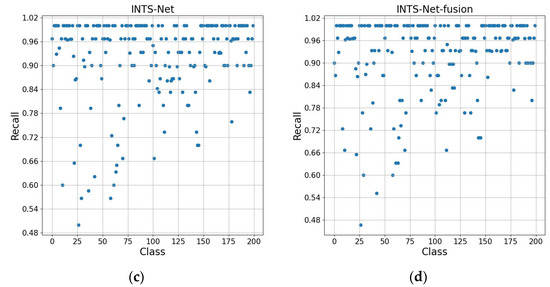{kind=link}
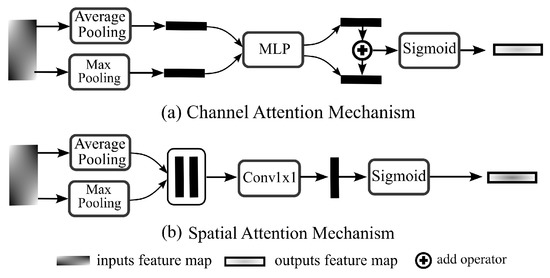{kind=link}
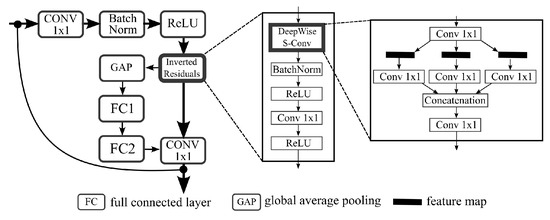{kind=link}
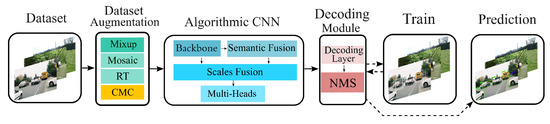{kind=link}
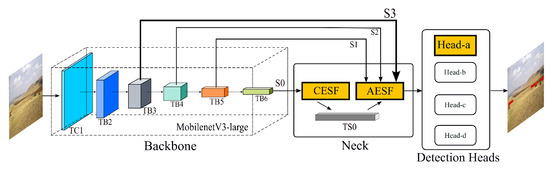{kind=link}
{kind=link}
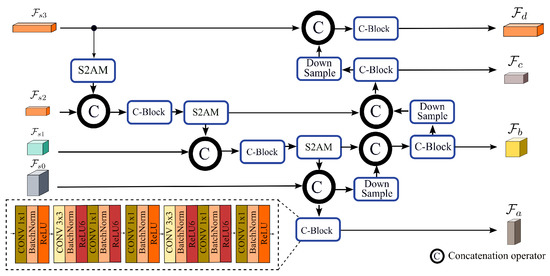{kind=link}
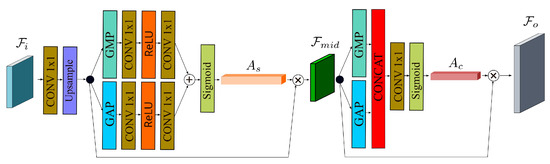{kind=link}
{kind=link}
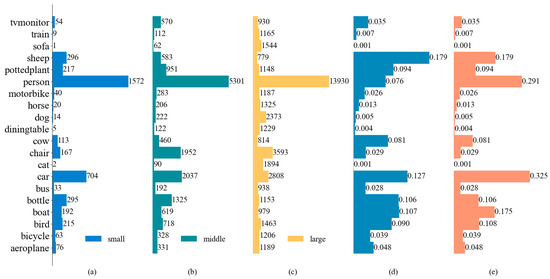{kind=link}
{kind=link}
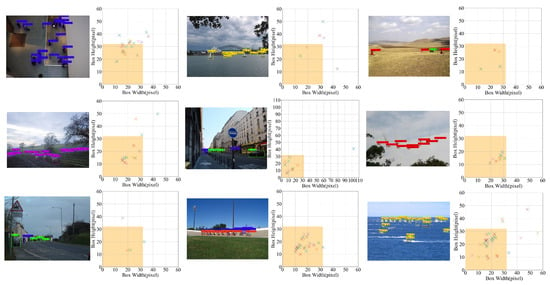{kind=link}
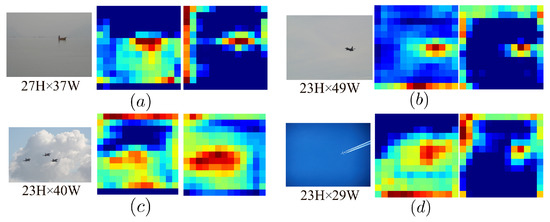{kind=link}
{kind=link}
{kind=link}
{kind=link}
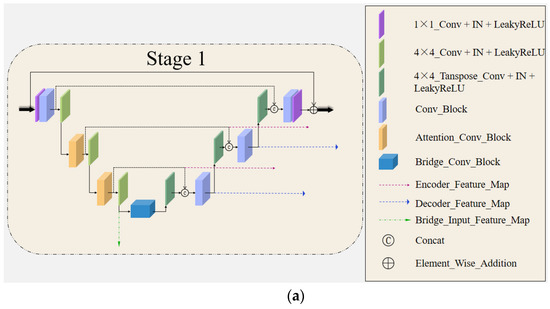{kind=link}
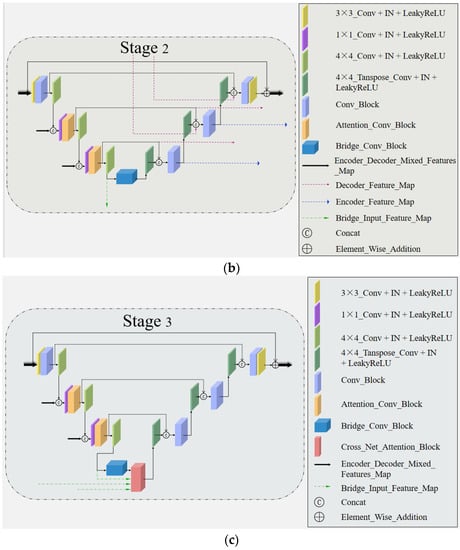{kind=link}
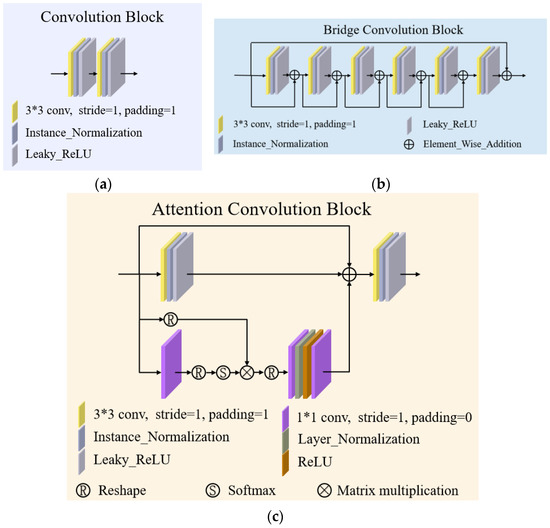{kind=link}
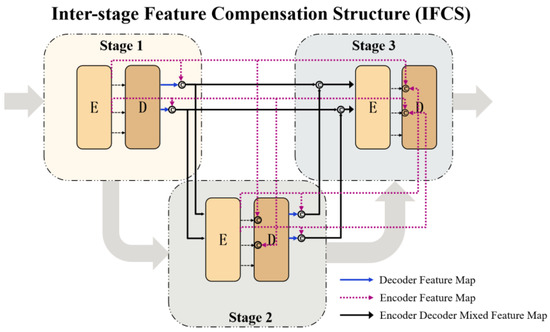{kind=link}
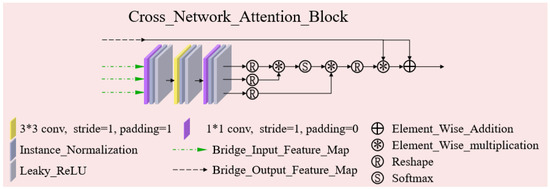{kind=link}
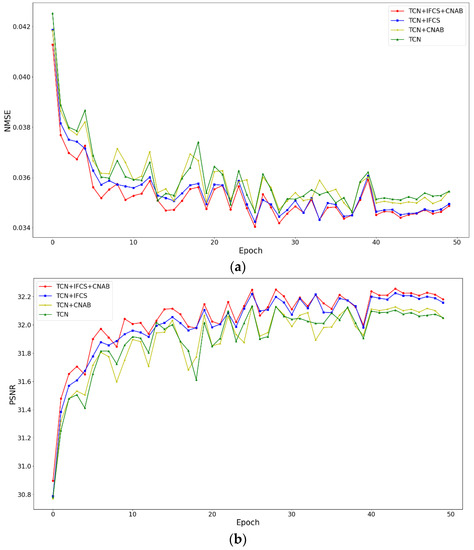{kind=link}
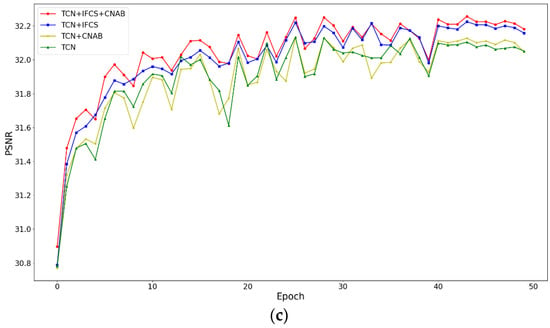{kind=link}
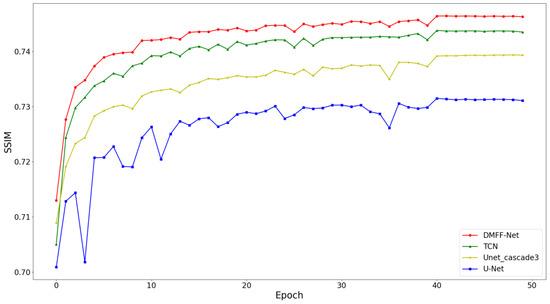{kind=link}
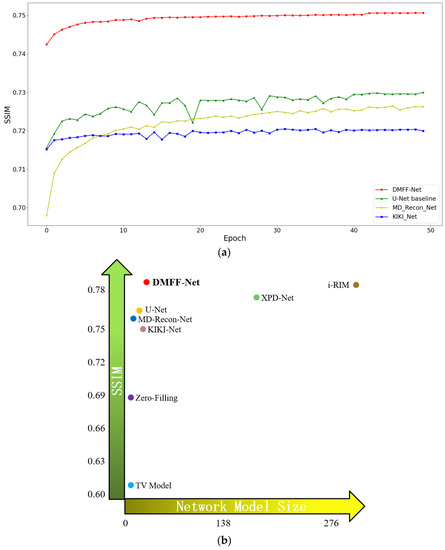{kind=link}
{kind=link}
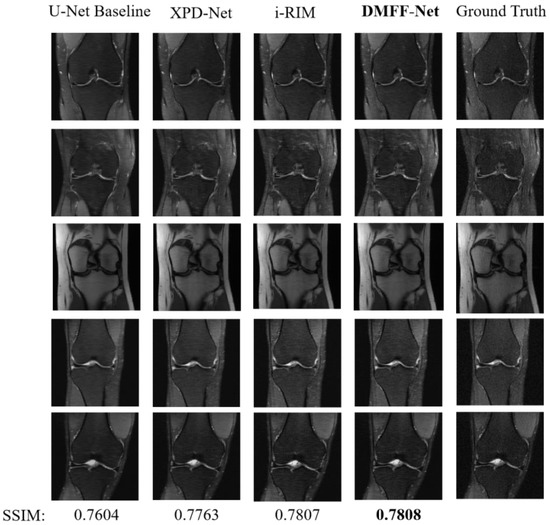{kind=link}
{kind=link}
{kind=link}
{kind=link}
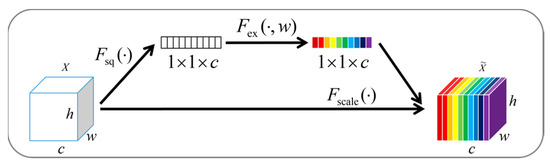{kind=link}
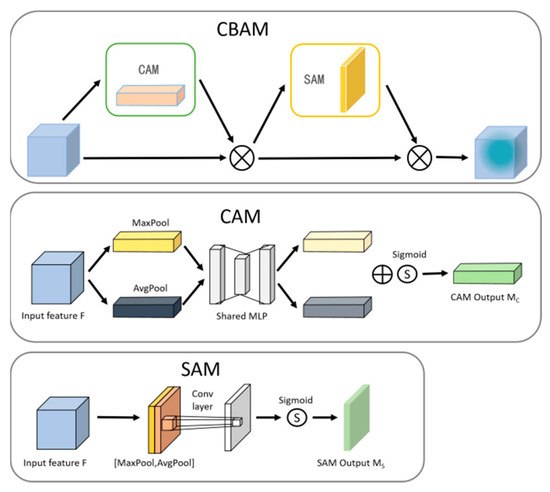{kind=link}
{kind=link}
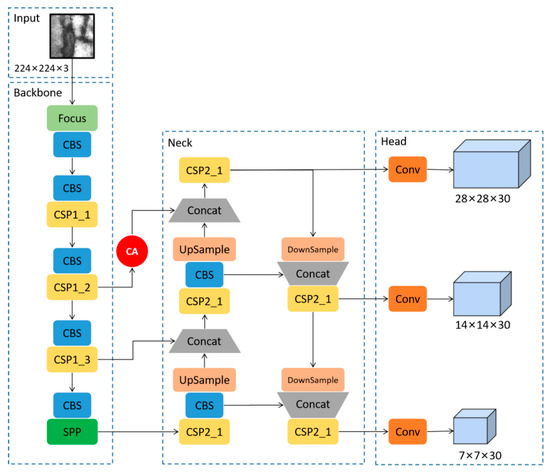{kind=link}
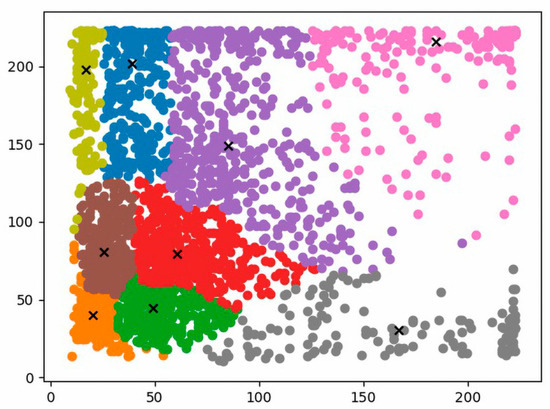{kind=link}
{kind=link}
{kind=link}
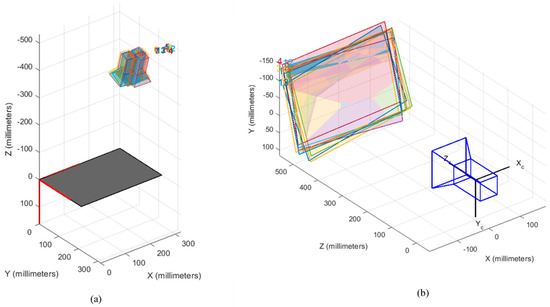{kind=link}
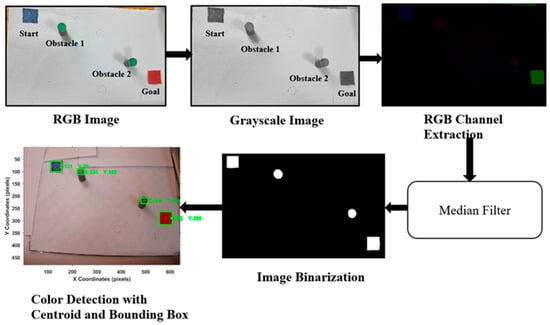{kind=link}
{kind=link}
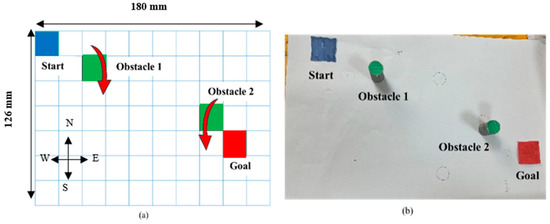{kind=link}
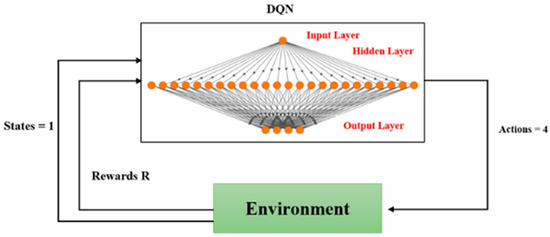{kind=link}
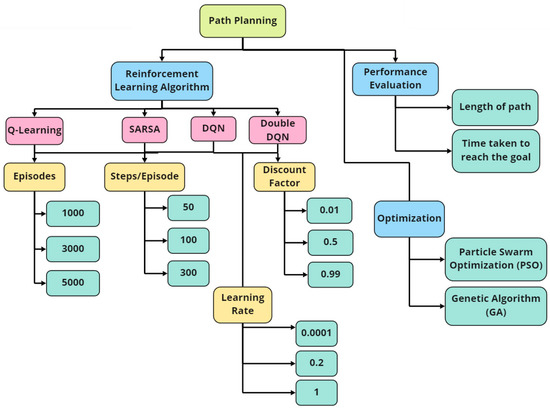{kind=link}
{kind=link}
{kind=link}
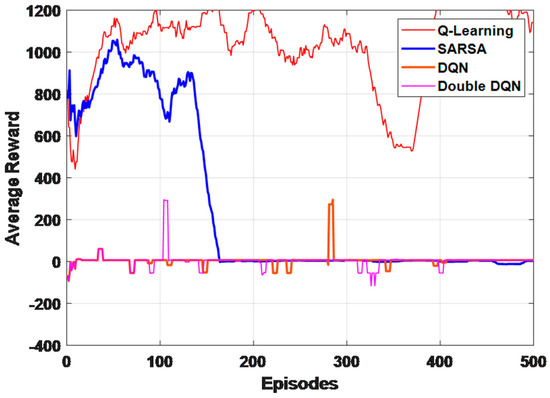{kind=link}
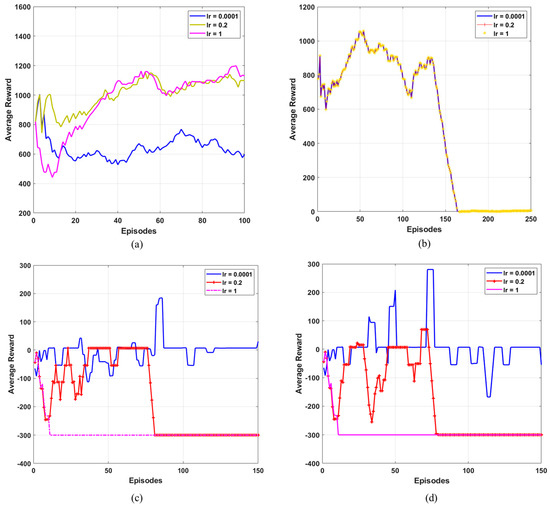{kind=link}
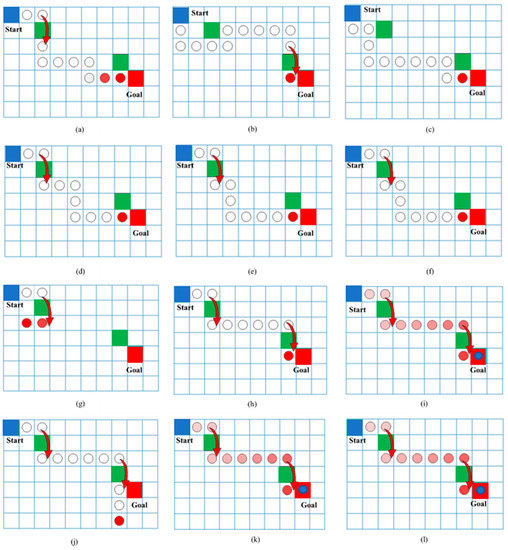{kind=link}
{kind=link}
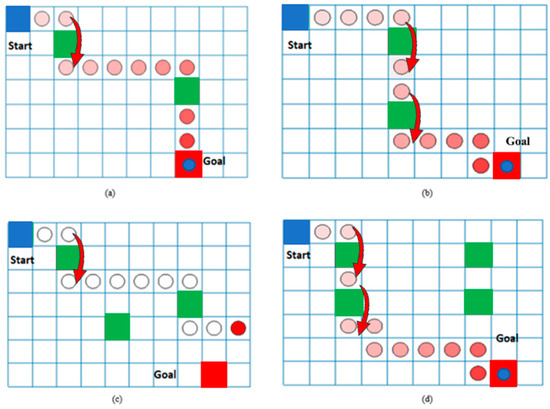{kind=link}
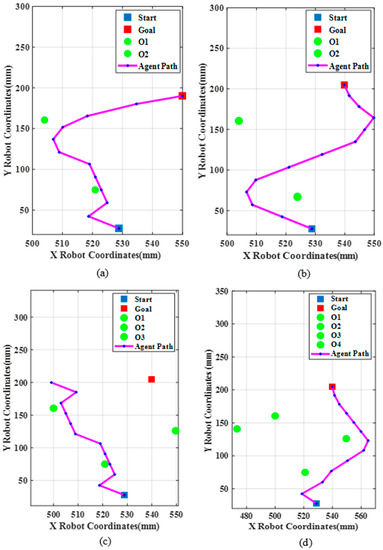{kind=link}
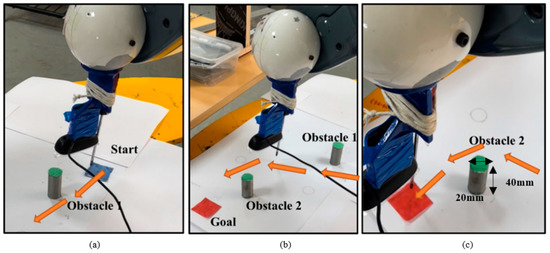{kind=link}
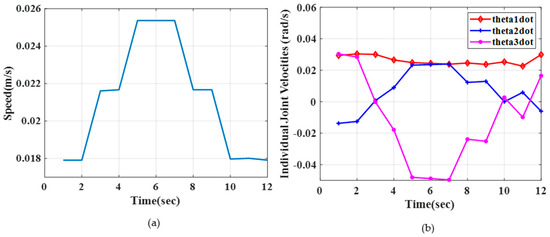{kind=link}
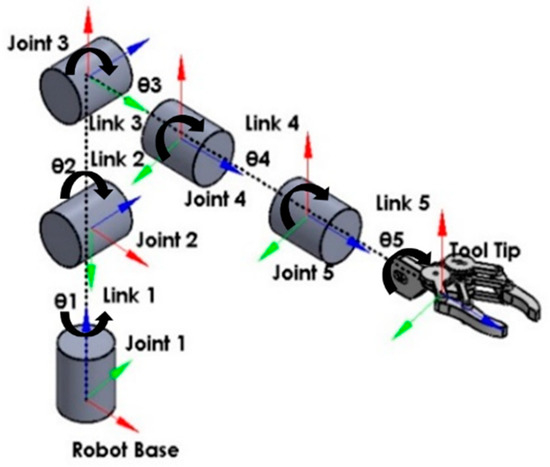{kind=link}
{kind=link}
{kind=link}
{kind=link}
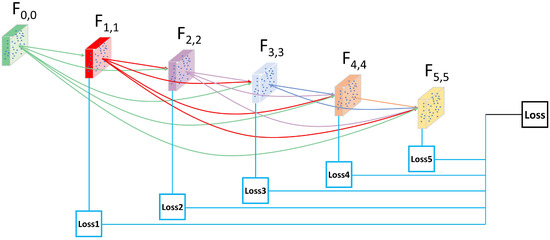{kind=link}
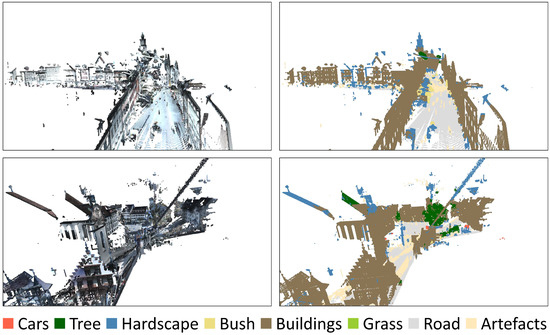{kind=link}
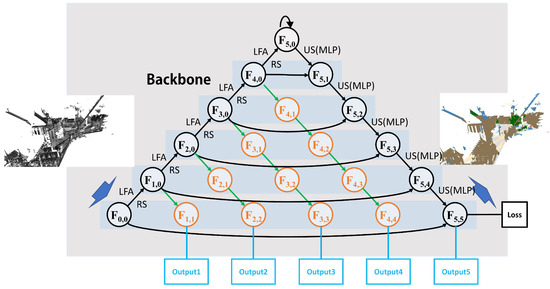{kind=link}
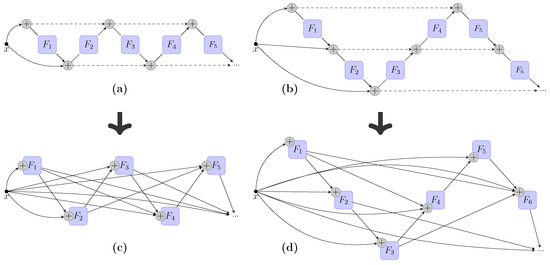{kind=link}
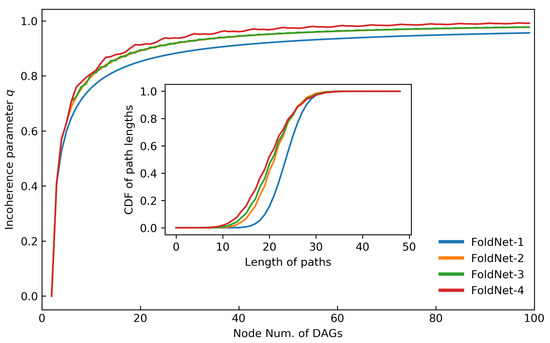{kind=link}
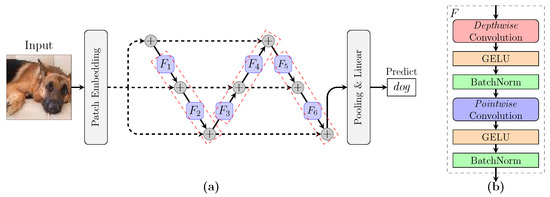{kind=link}
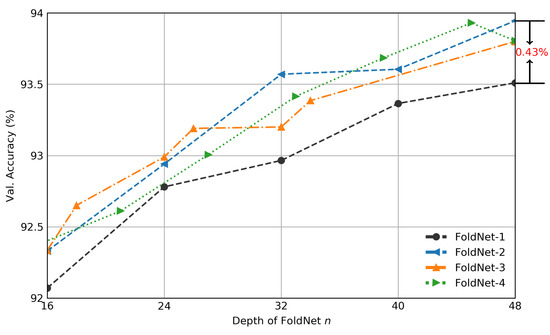{kind=link}
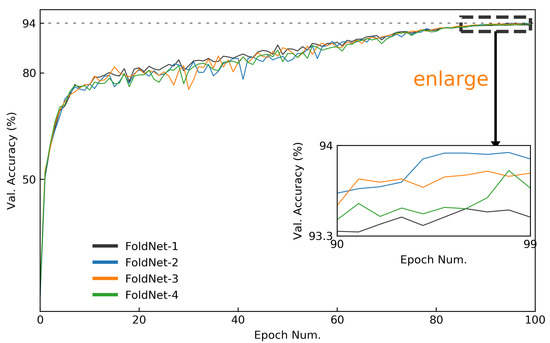{kind=link}
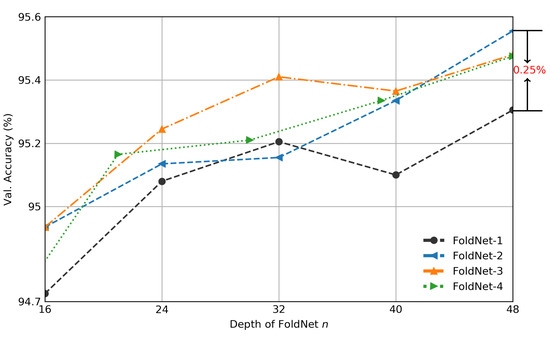{kind=link}
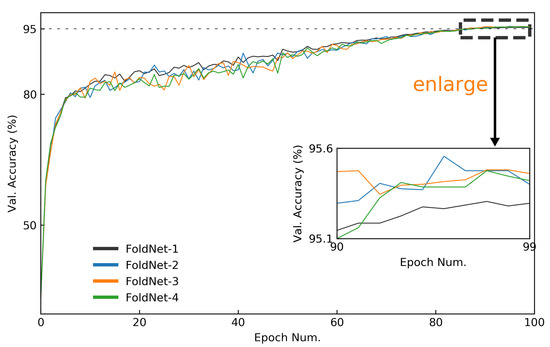{kind=link}
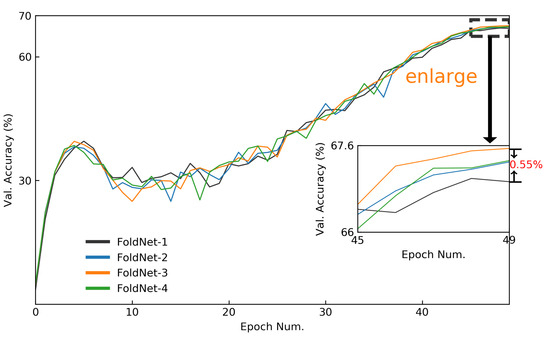{kind=link}
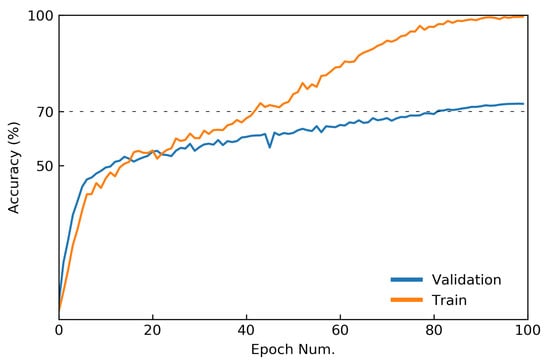{kind=link}
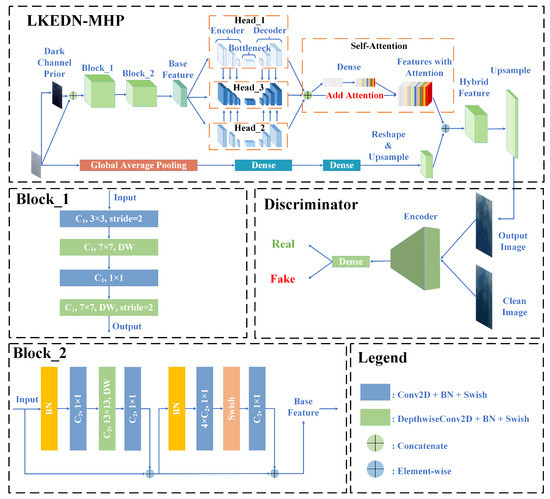{kind=link}
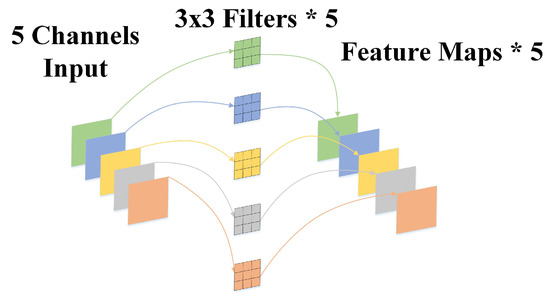{kind=link}
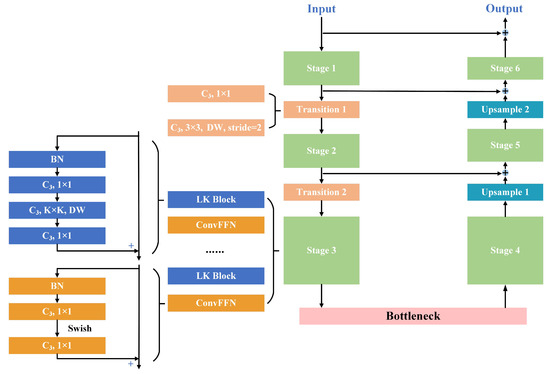{kind=link}
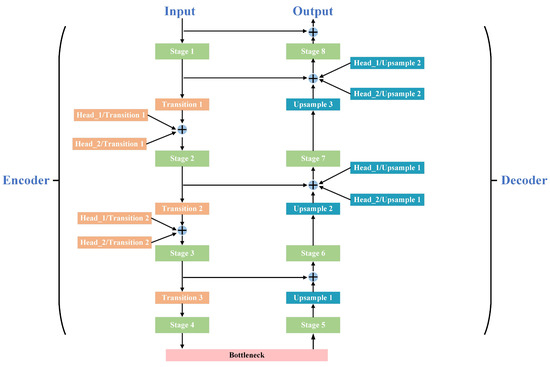{kind=link}
{kind=link}
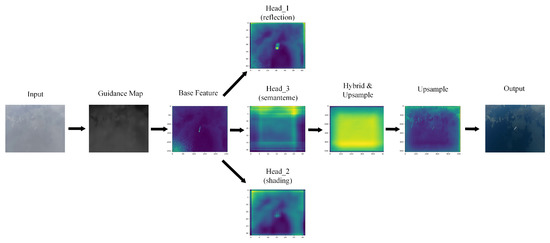{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
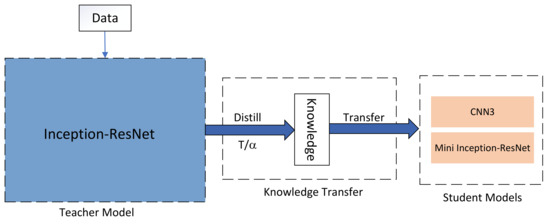{kind=link}
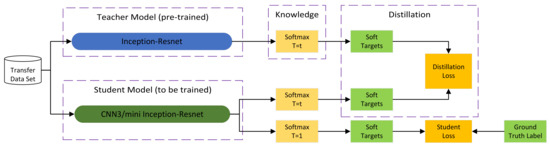{kind=link}
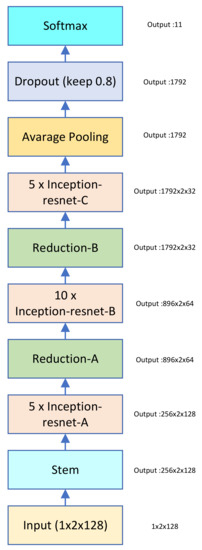{kind=link}
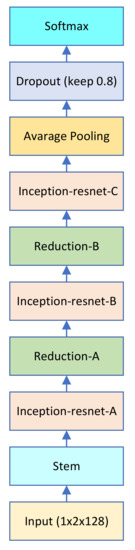{kind=link}
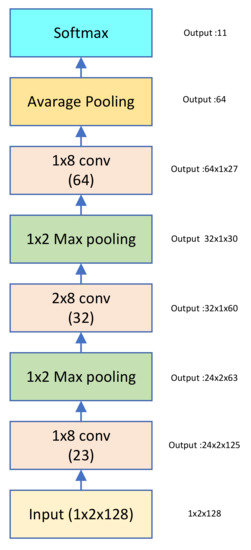{kind=link}
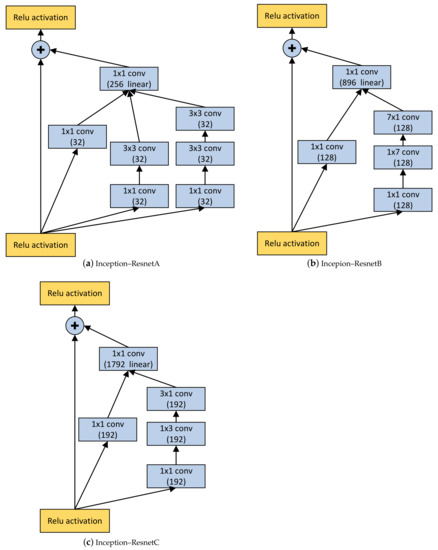{kind=link}
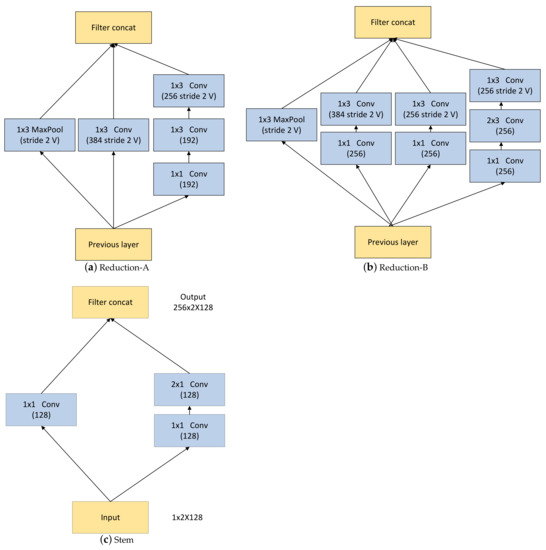{kind=link}
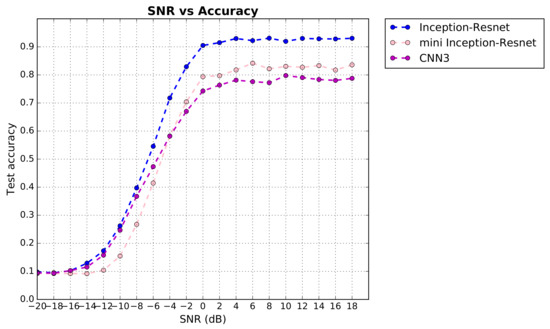{kind=link}
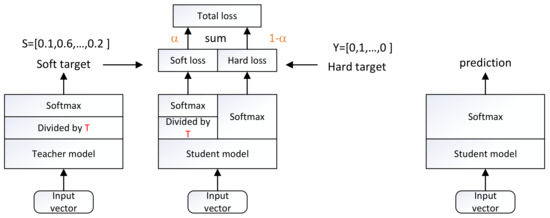{kind=link}
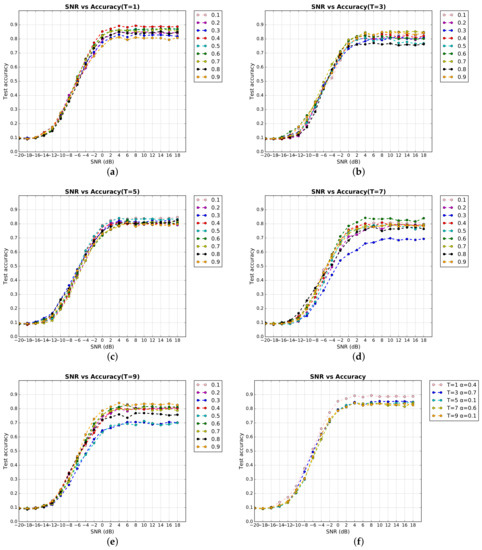{kind=link}
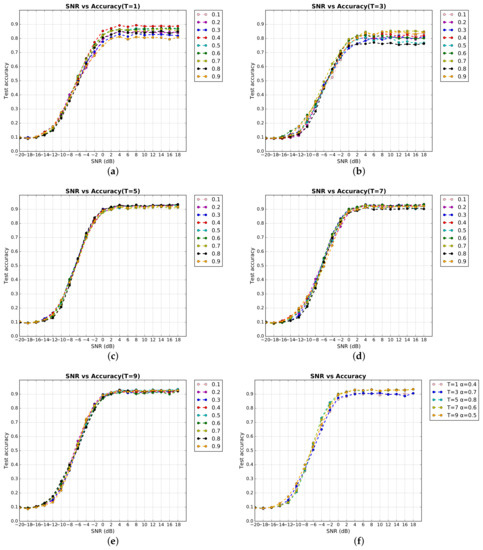{kind=link}
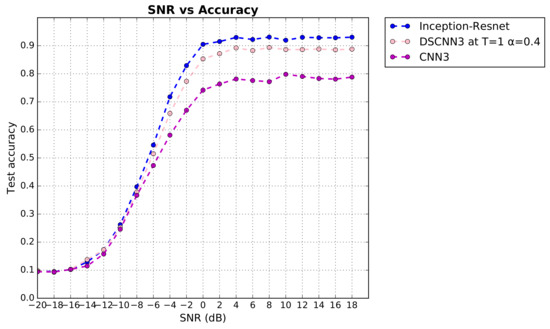{kind=link}
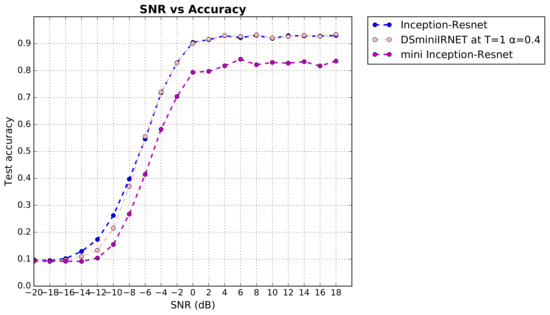{kind=link}
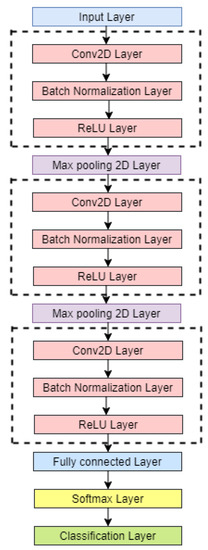{kind=link}
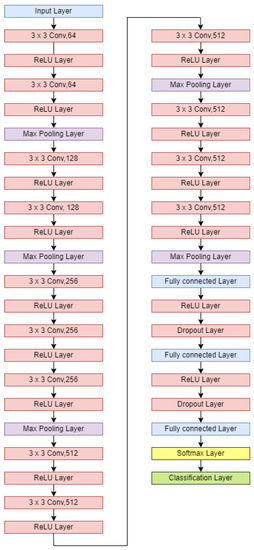{kind=link}
{kind=link}
{kind=link}
{kind=link}
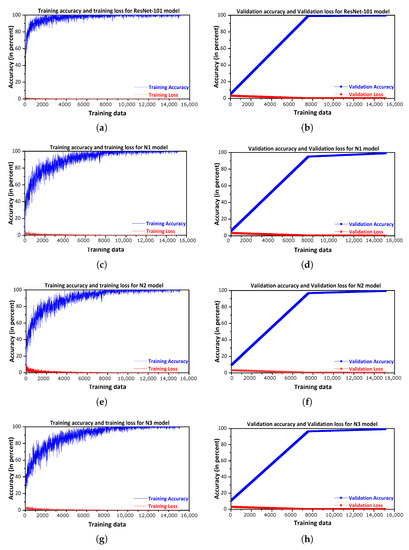{kind=link}
{kind=link}
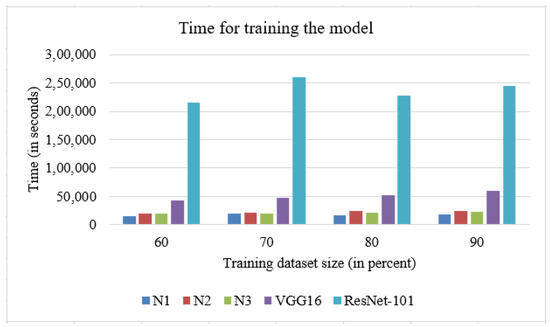{kind=link}
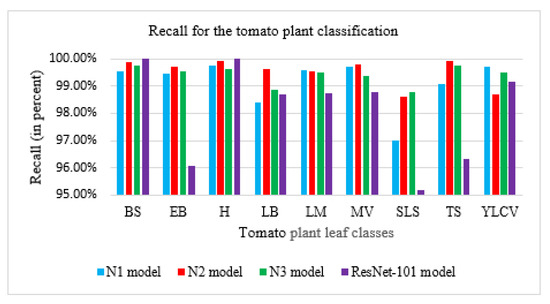{kind=link}
{kind=link}
{kind=link}
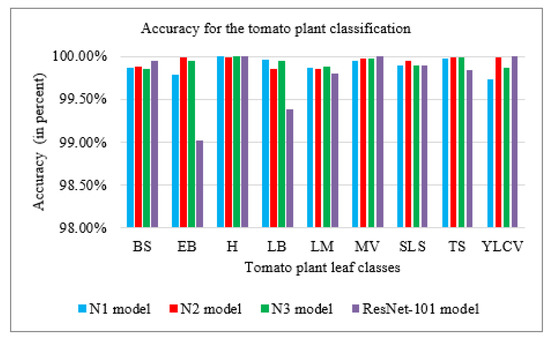{kind=link}
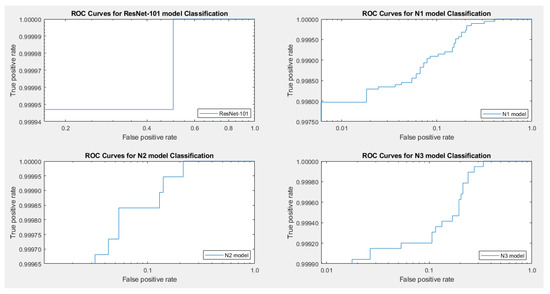{kind=link}
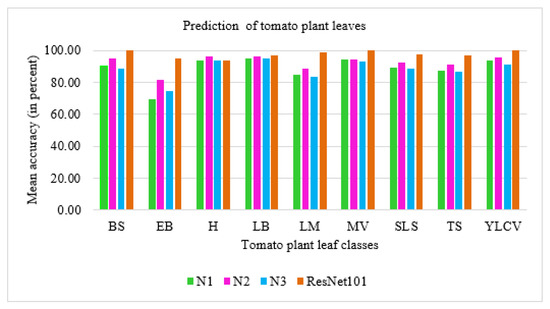{kind=link}
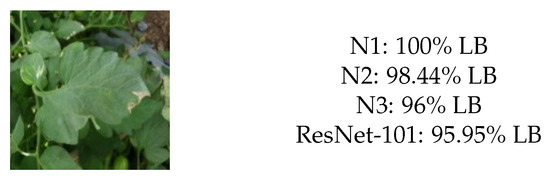{kind=link}
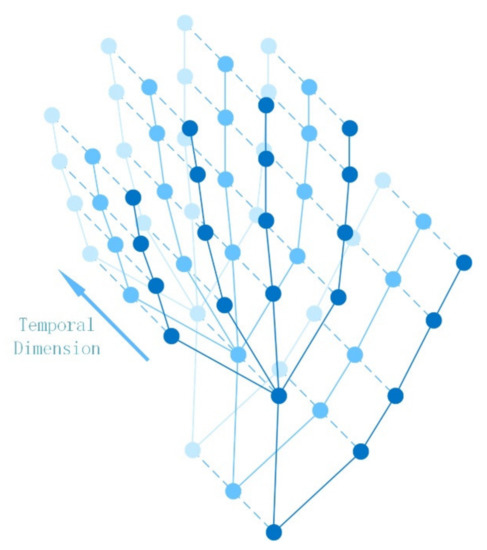{kind=link}
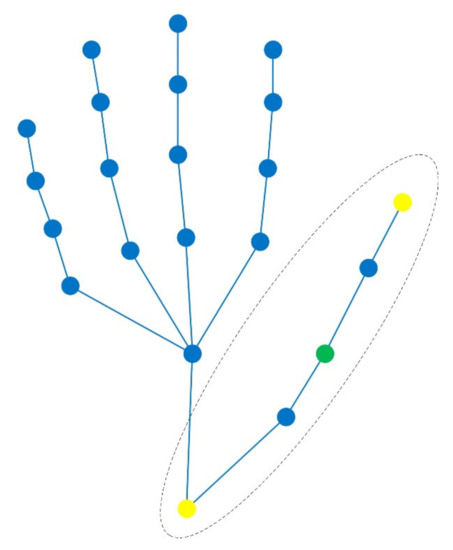{kind=link}
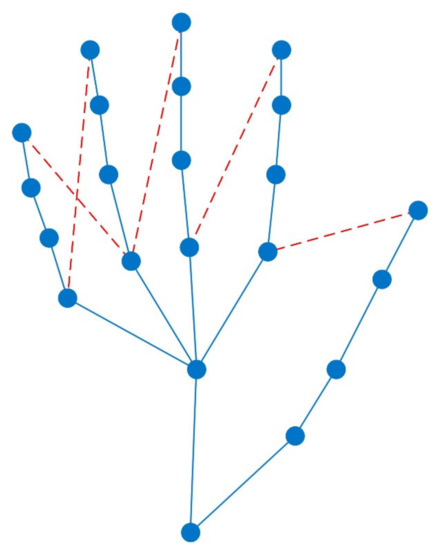{kind=link}
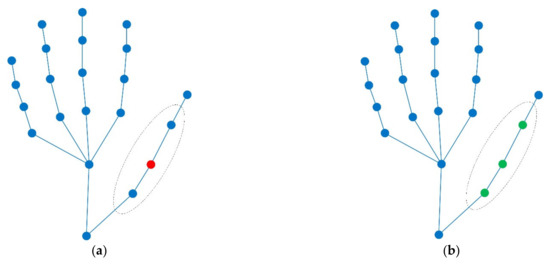{kind=link}
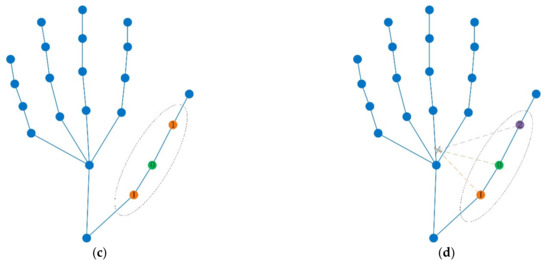{kind=link}
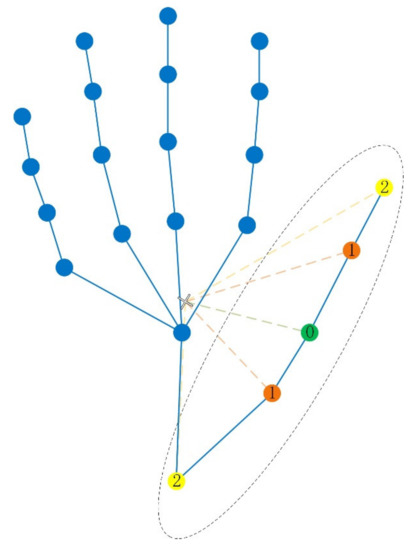{kind=link}
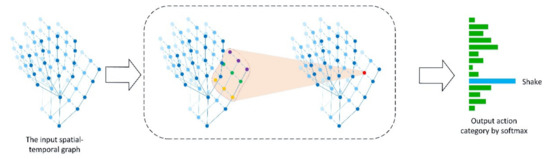{kind=link}
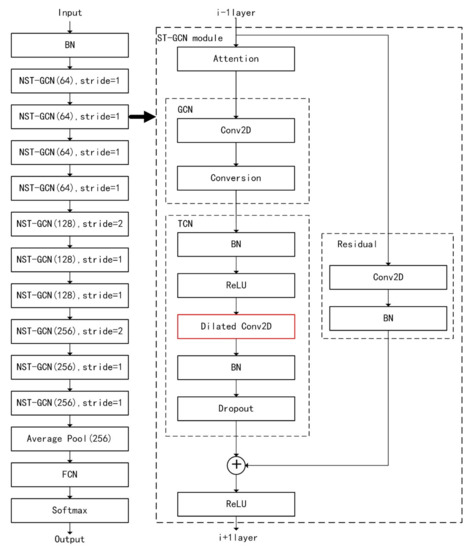{kind=link}
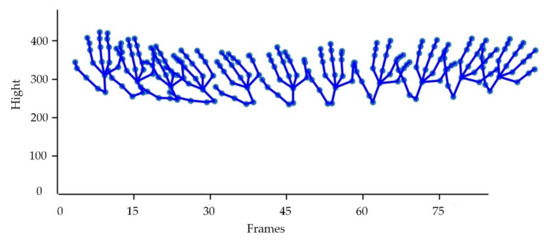{kind=link}
{kind=link}
{kind=link}
{kind=link}
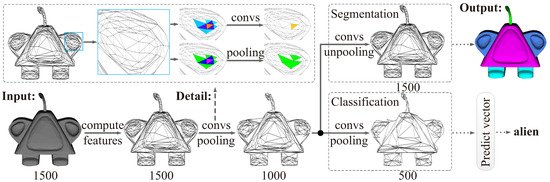{kind=link}
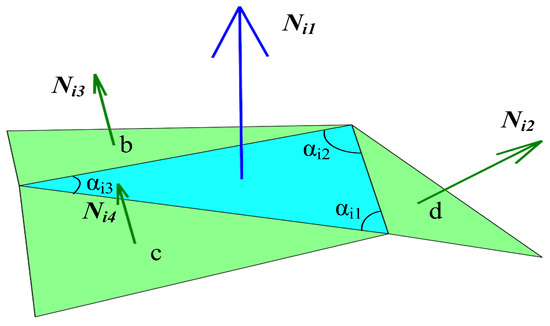{kind=link}
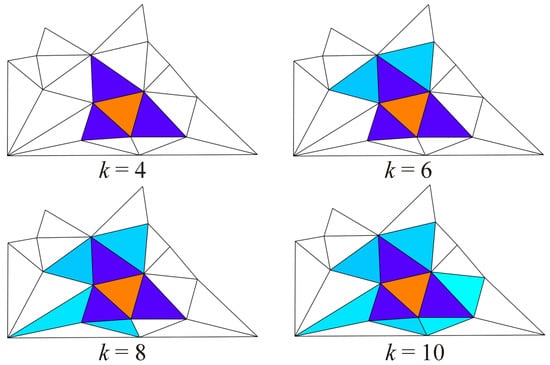{kind=link}
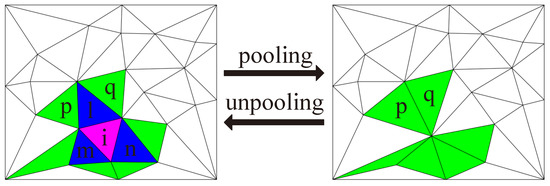{kind=link}
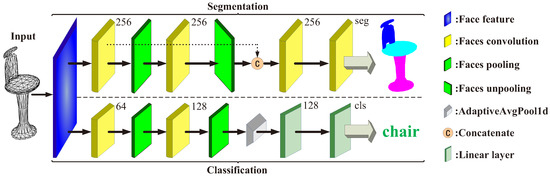{kind=link}
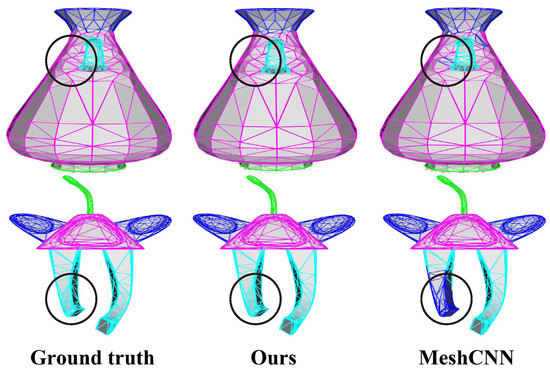{kind=link}
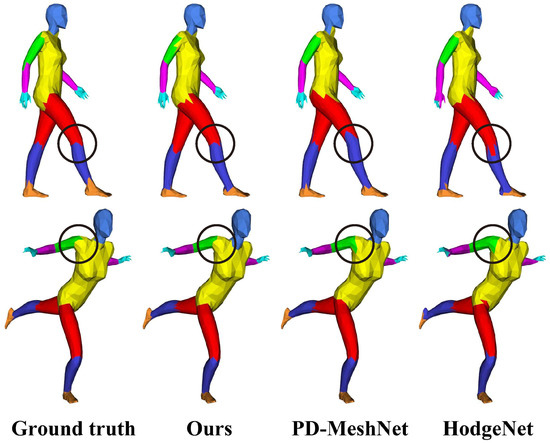{kind=link}
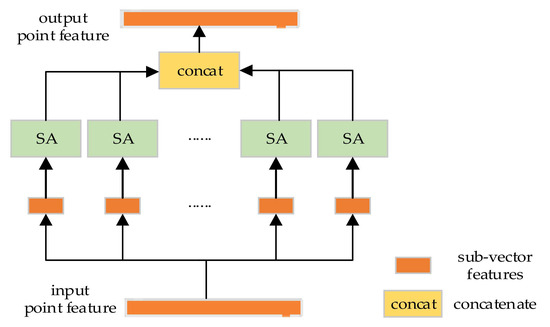{kind=link}
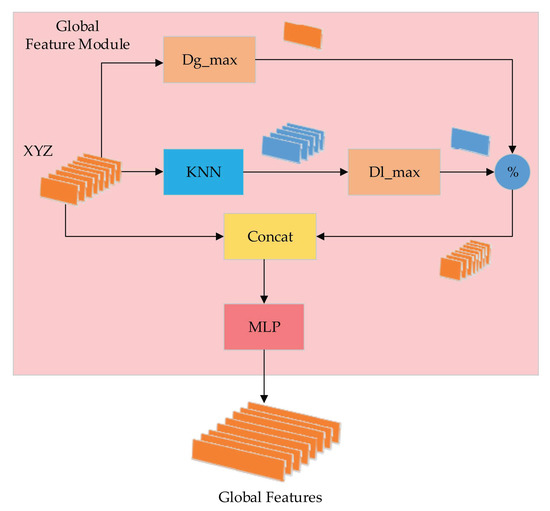{kind=link}
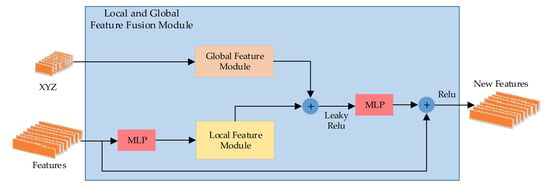{kind=link}
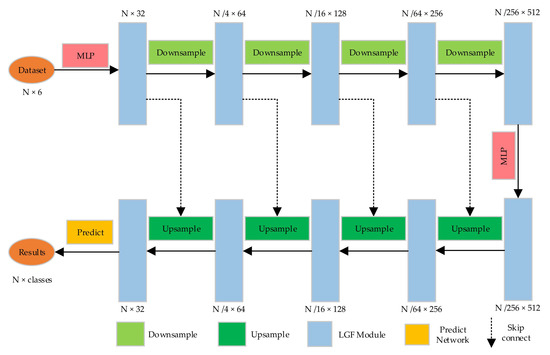{kind=link}
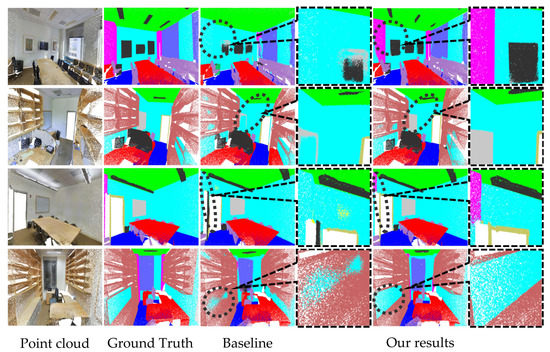{kind=link}
{kind=link}
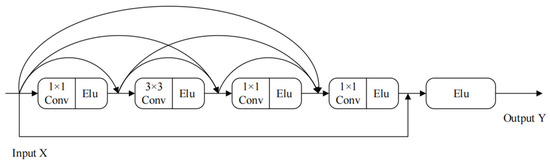{kind=link}
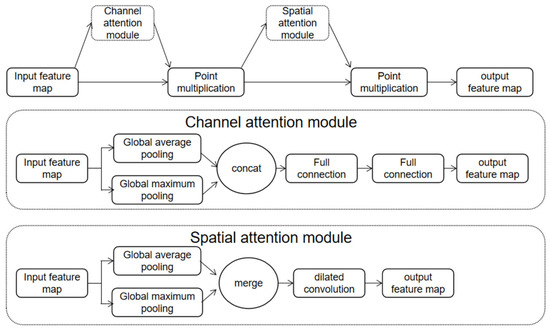{kind=link}
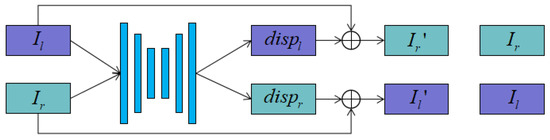{kind=link}
{kind=link}
{kind=link}
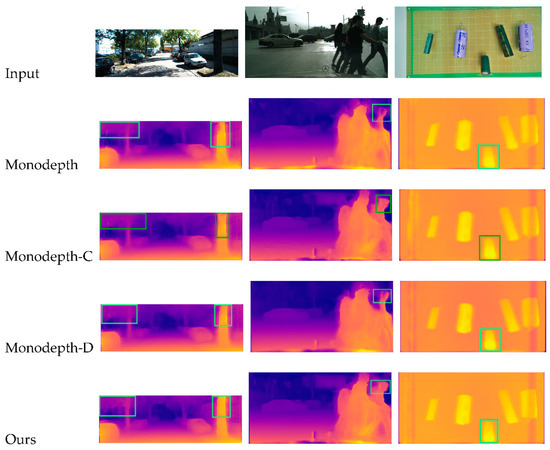{kind=link}
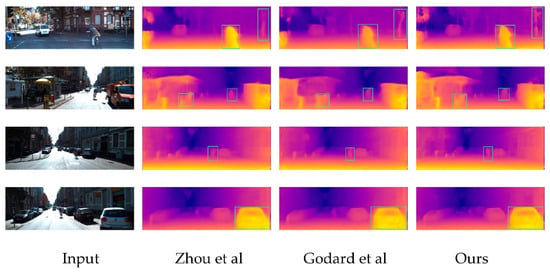{kind=link}
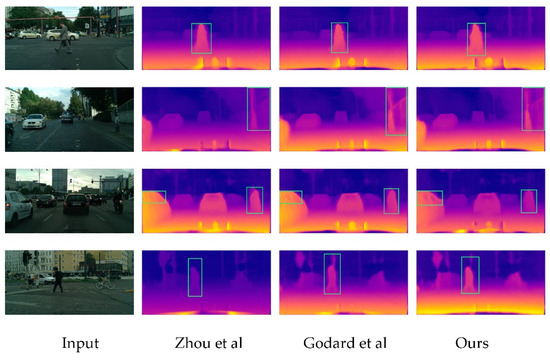{kind=link}
{kind=link}
{kind=link}
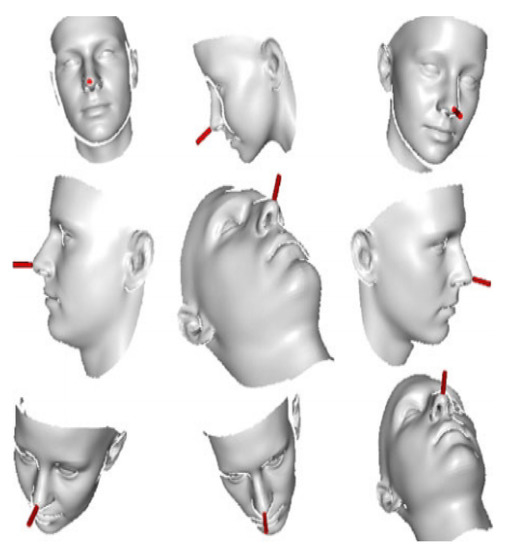{kind=link}
{kind=link}
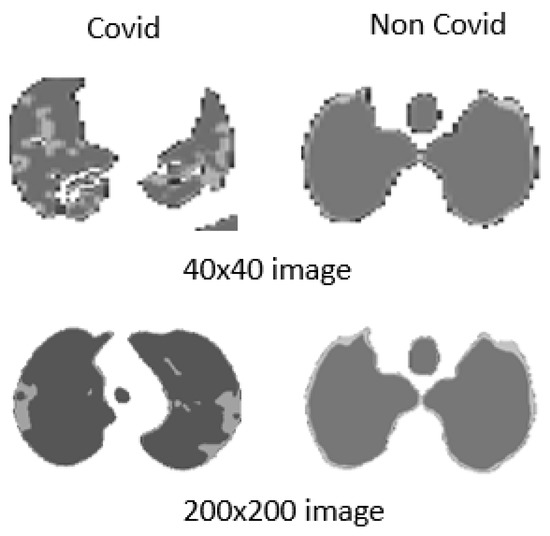{kind=link}
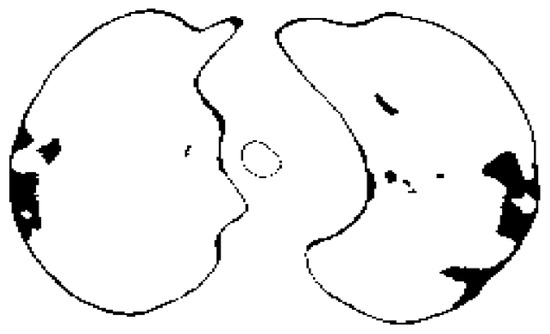{kind=link}
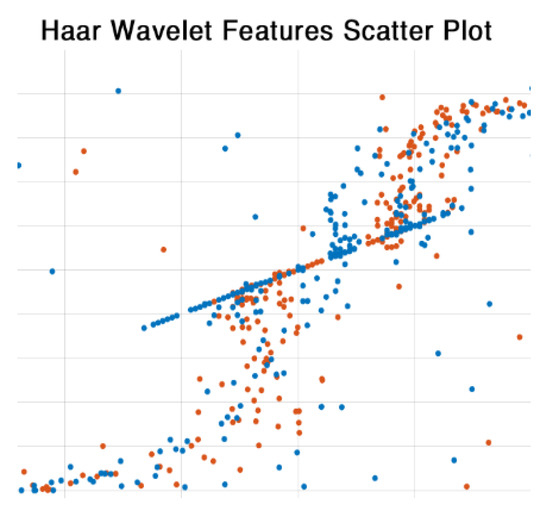{kind=link}
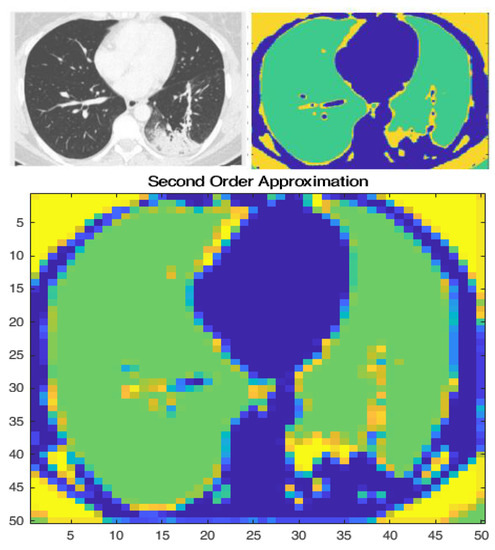{kind=link}
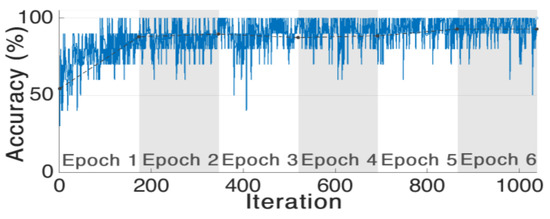{kind=link}
{kind=link}
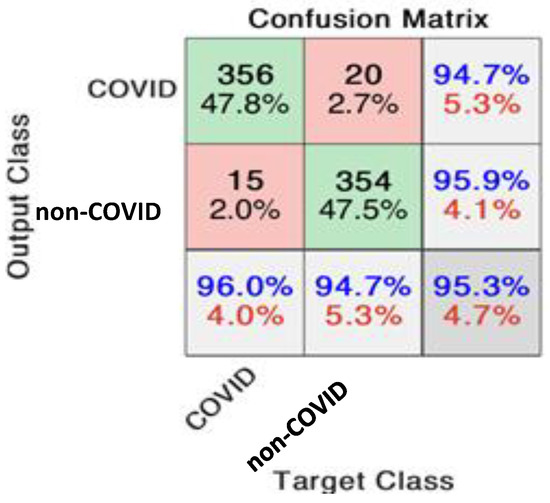{kind=link}
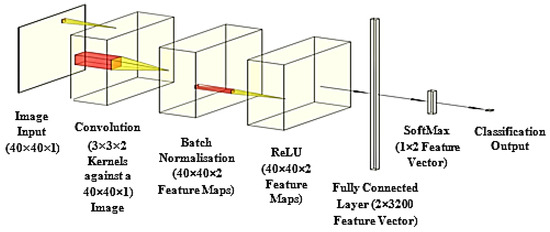{kind=link}
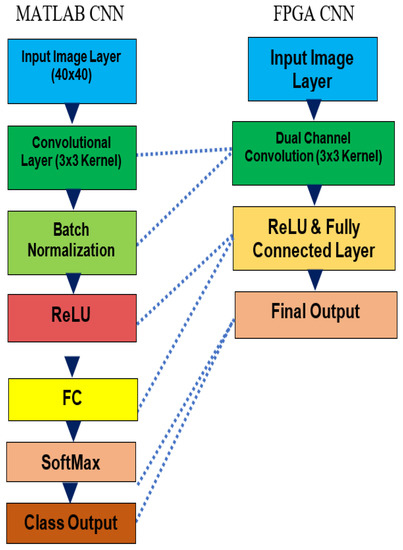{kind=link}
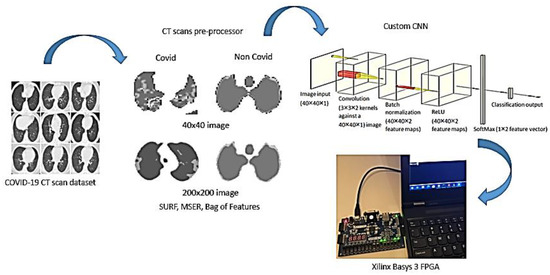{kind=link}
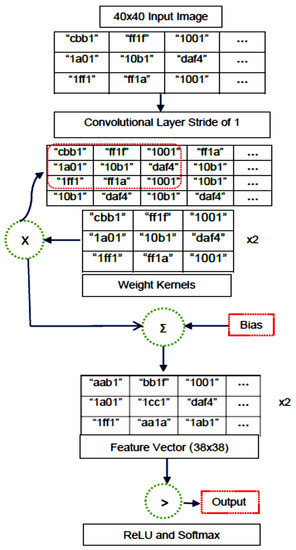{kind=link}
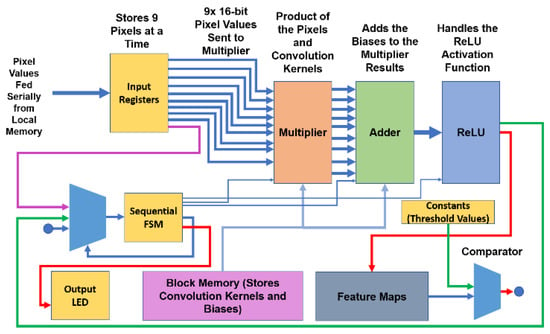{kind=link}
{kind=link}
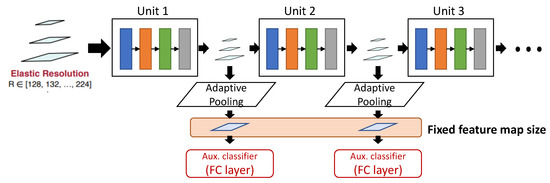{kind=link}
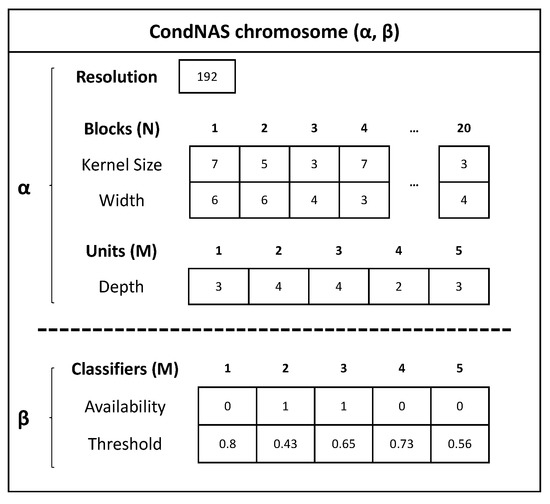{kind=link}
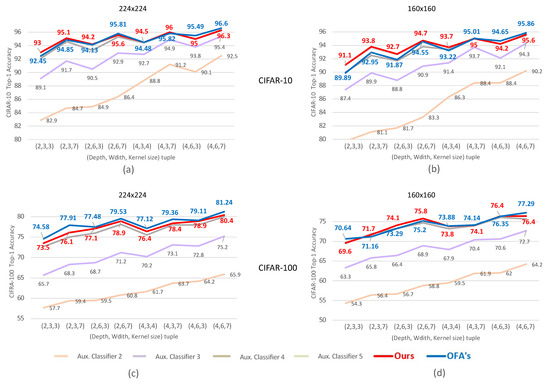{kind=link}
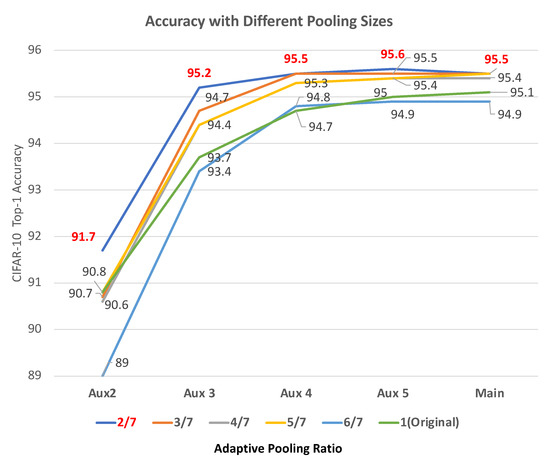{kind=link}
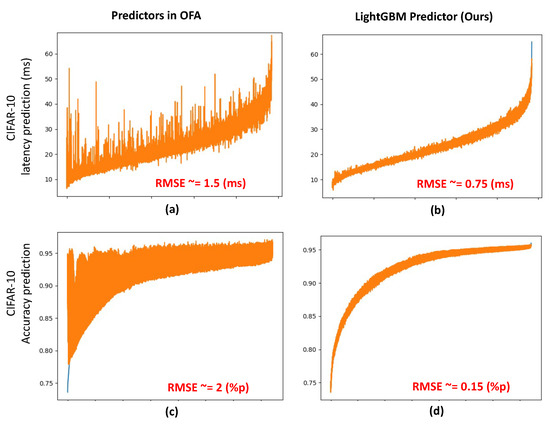{kind=link}
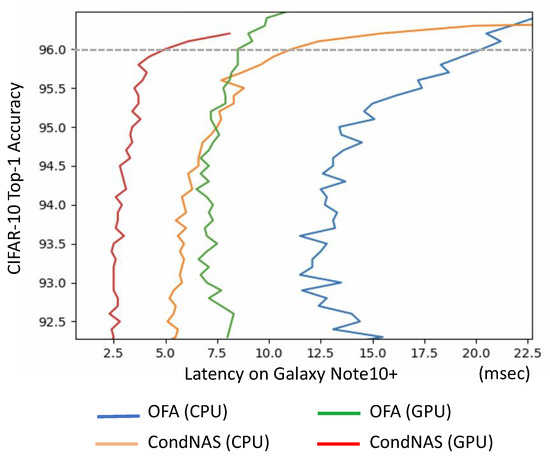{kind=link}
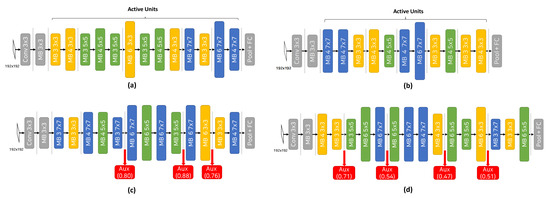{kind=link}
{kind=link}
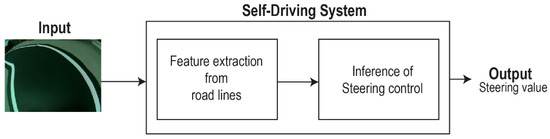{kind=link}
{kind=link}
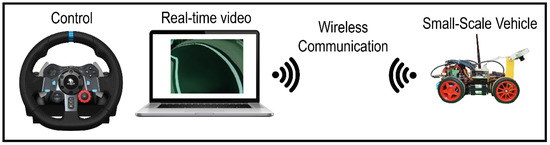{kind=link}
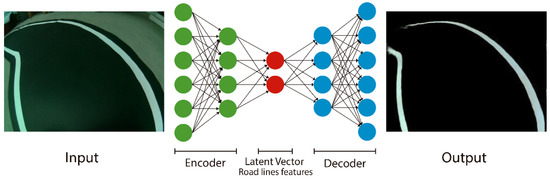{kind=link}
{kind=link}
{kind=link}
{kind=link}
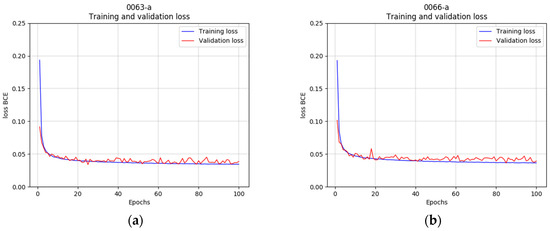{kind=link}
{kind=link}
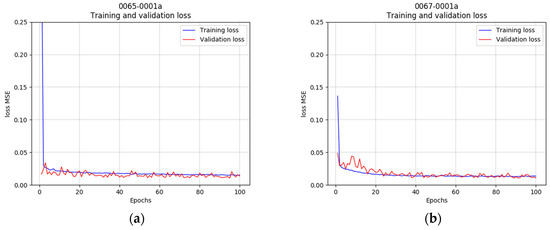{kind=link}
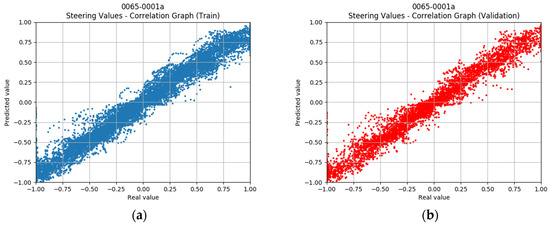{kind=link}
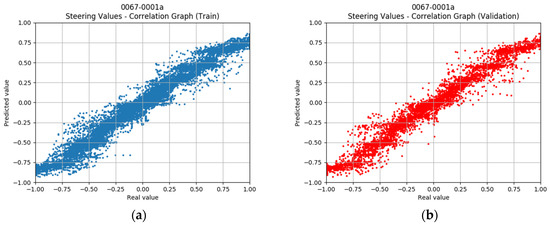{kind=link}
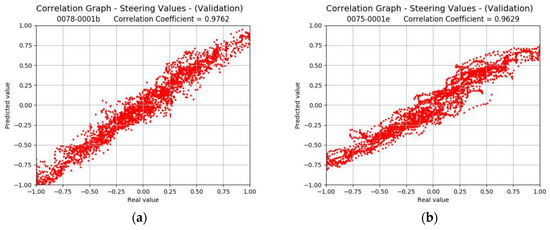{kind=link}
{kind=link}
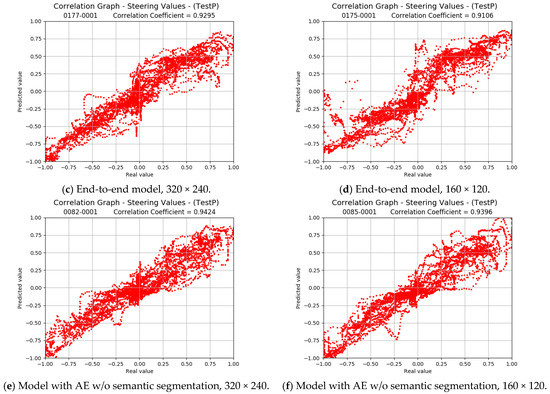{kind=link}
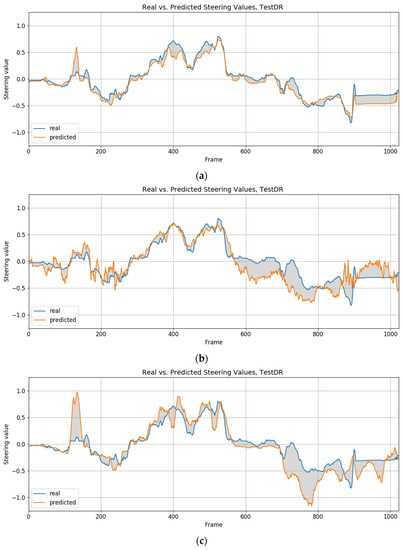{kind=link}
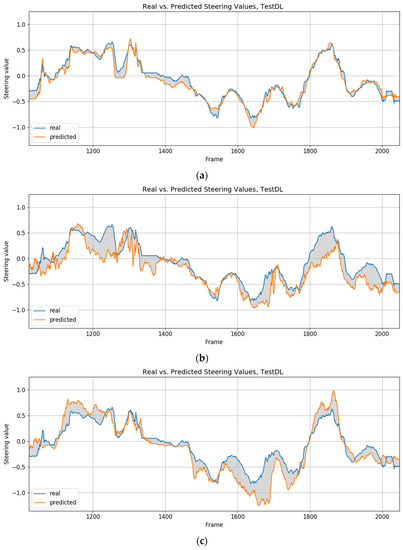{kind=link}
{kind=link}
{kind=link}
{kind=link}
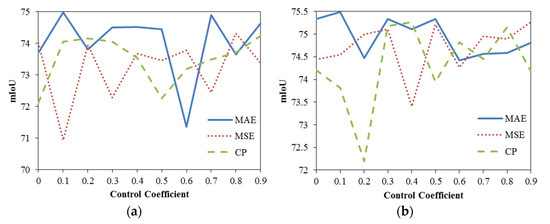{kind=link}
{kind=link}
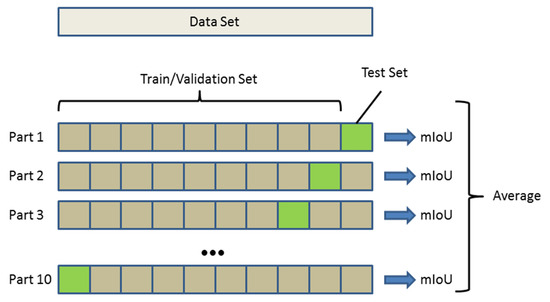{kind=link}
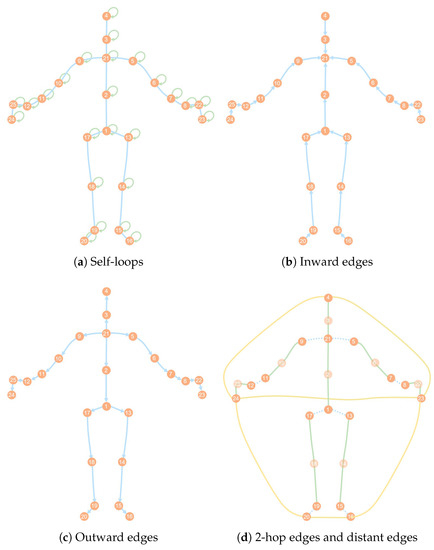{kind=link}
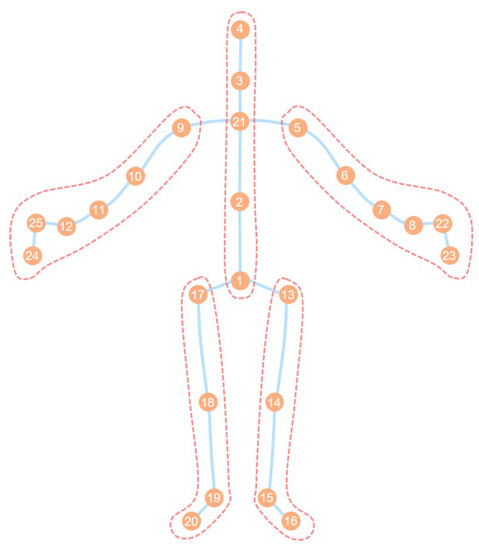{kind=link}
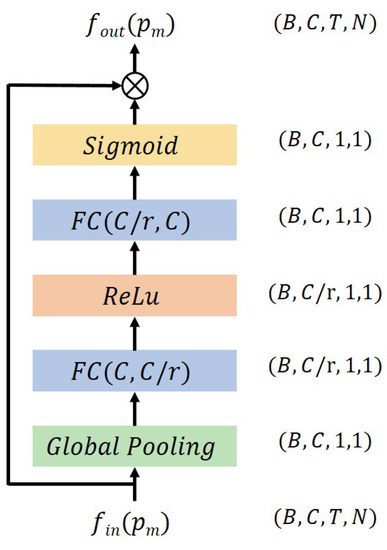{kind=link}
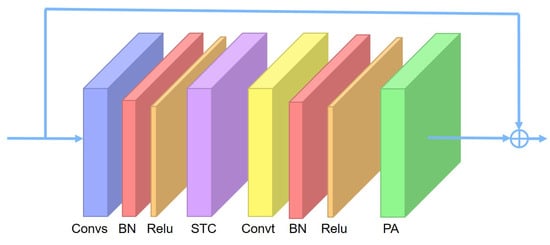{kind=link}
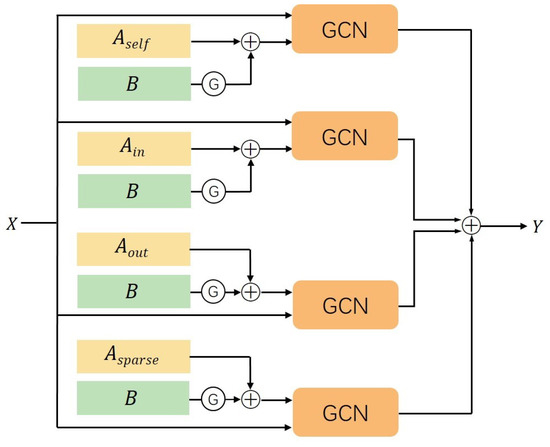{kind=link}
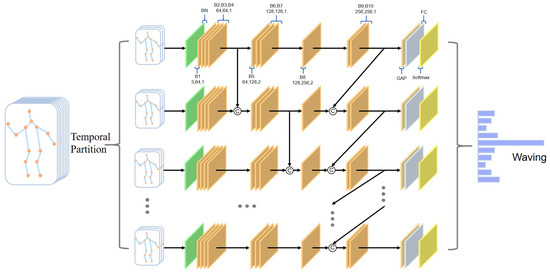{kind=link}
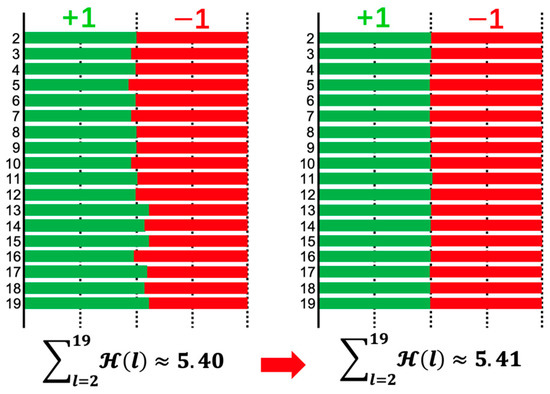{kind=link}
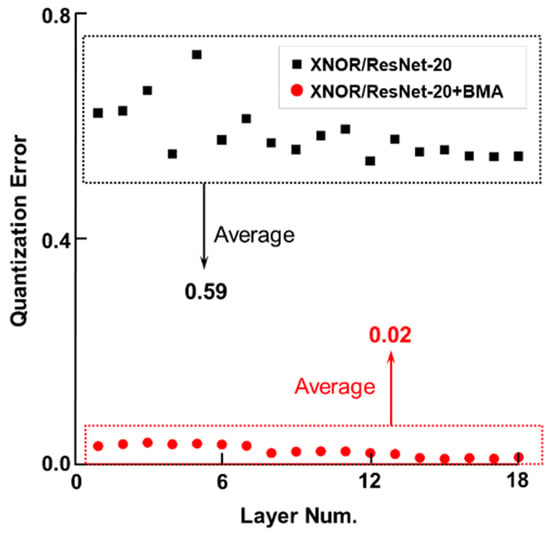{kind=link}
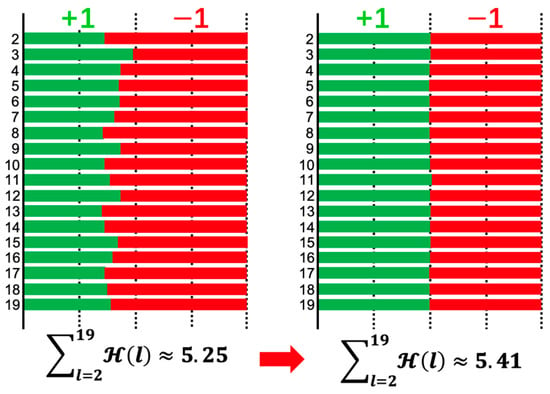{kind=link}
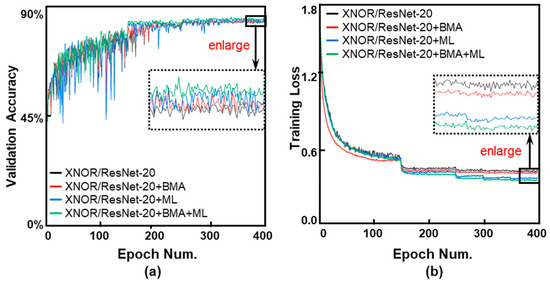{kind=link}
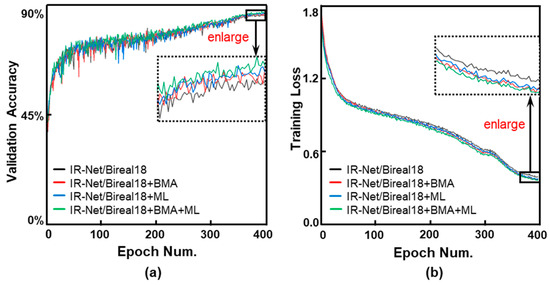{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
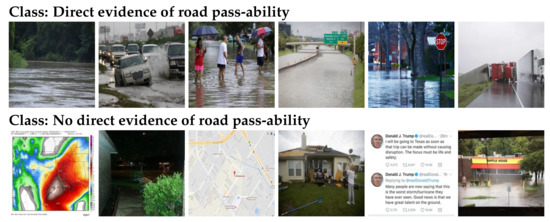{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
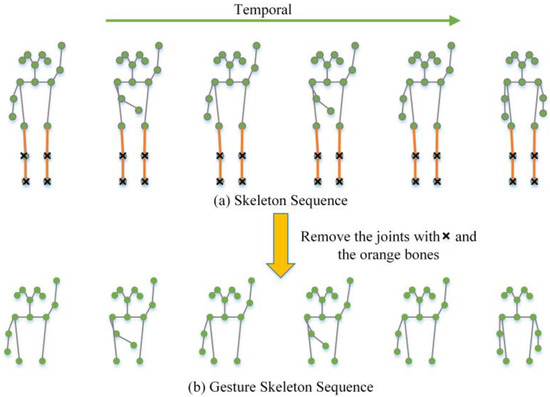{kind=link}
{kind=link}
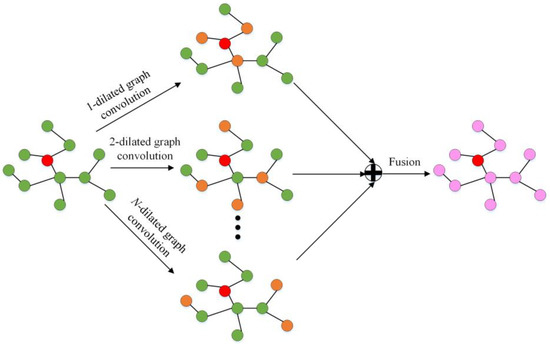{kind=link}
{kind=link}
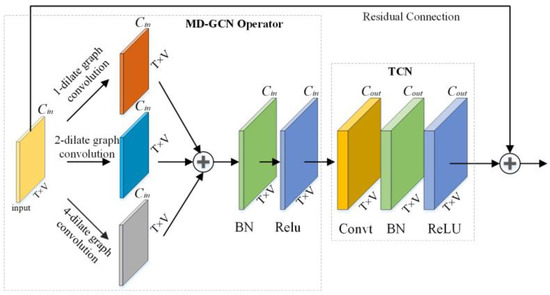{kind=link}
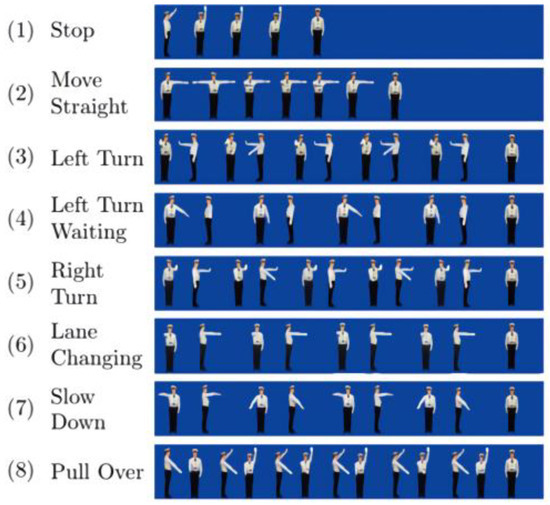{kind=link}
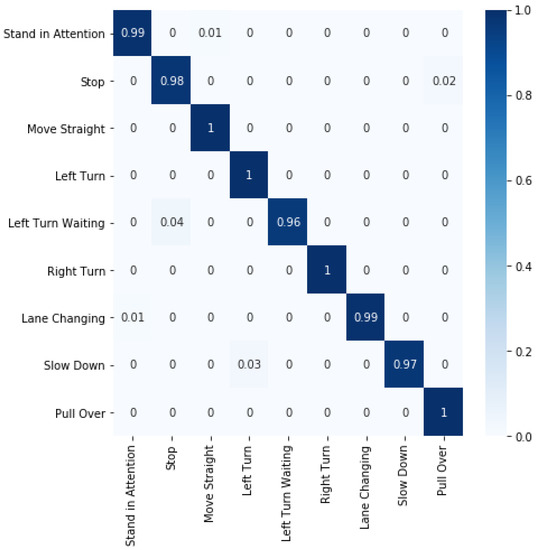{kind=link}
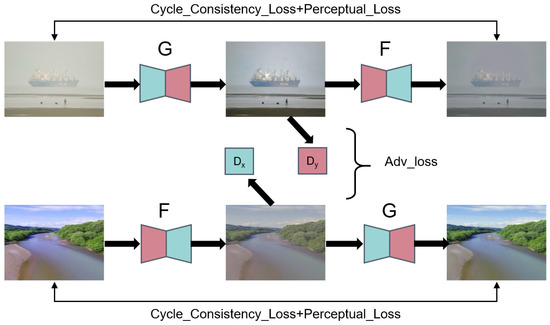{kind=link}
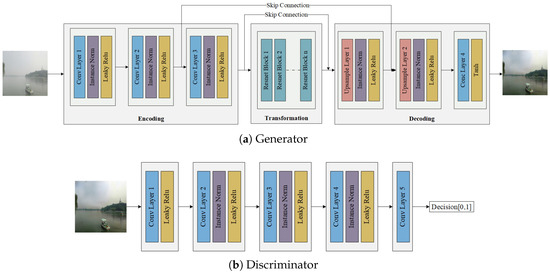{kind=link}
{kind=link}
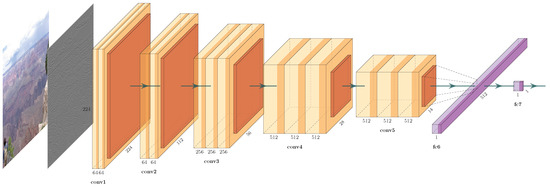{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
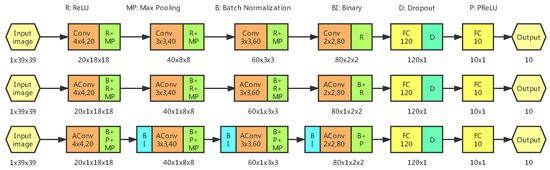{kind=link}
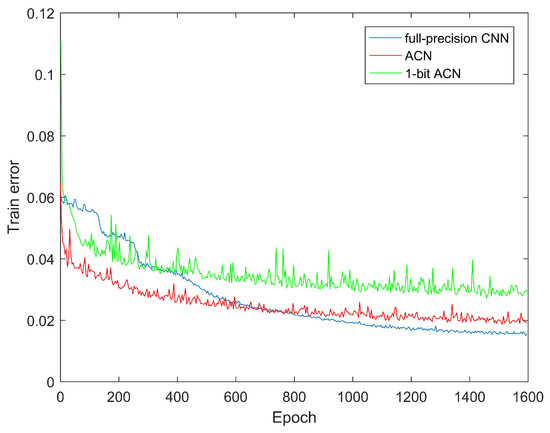{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
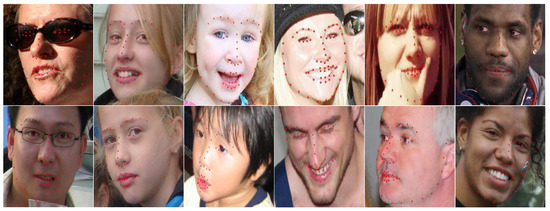{kind=link}
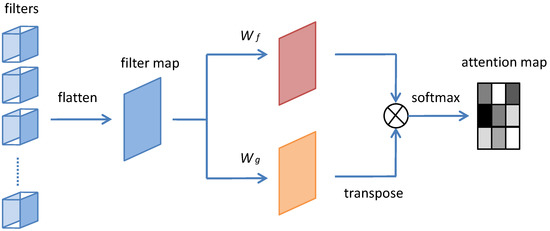{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}