
Channel Interaction Mamba-Guided Generative Adversarial Network for Depth-Image-Based Rendering 3D Image Watermarking


Abstract
1. Introduction
- (1)
- We propose the CFEGAN for depth-image-based rendering (DIBR) 3D image watermarking. The experimental results show that the proposed method maintains high visual quality and strong robustness while also having a low computational cost.
- (2)
- We design the CIM by using the global modeling of mamba to facilitate cross-modal feature interactions at the channel level, considering that RGB images and depth maps contain distinct image information.
- (3)
- We devise the FFM by using the modality correlations for generating 3D image features to guide watermarking, so that RGB and depth features can be fused effectively.
2. Related Work
2.1. Deep Learning-Based 2D Image Watermarking
2.2. DIBR 3D Image Watermarking
3. Proposed Method
3.1. Preliminaries
3.2. Overview of CIMGAN
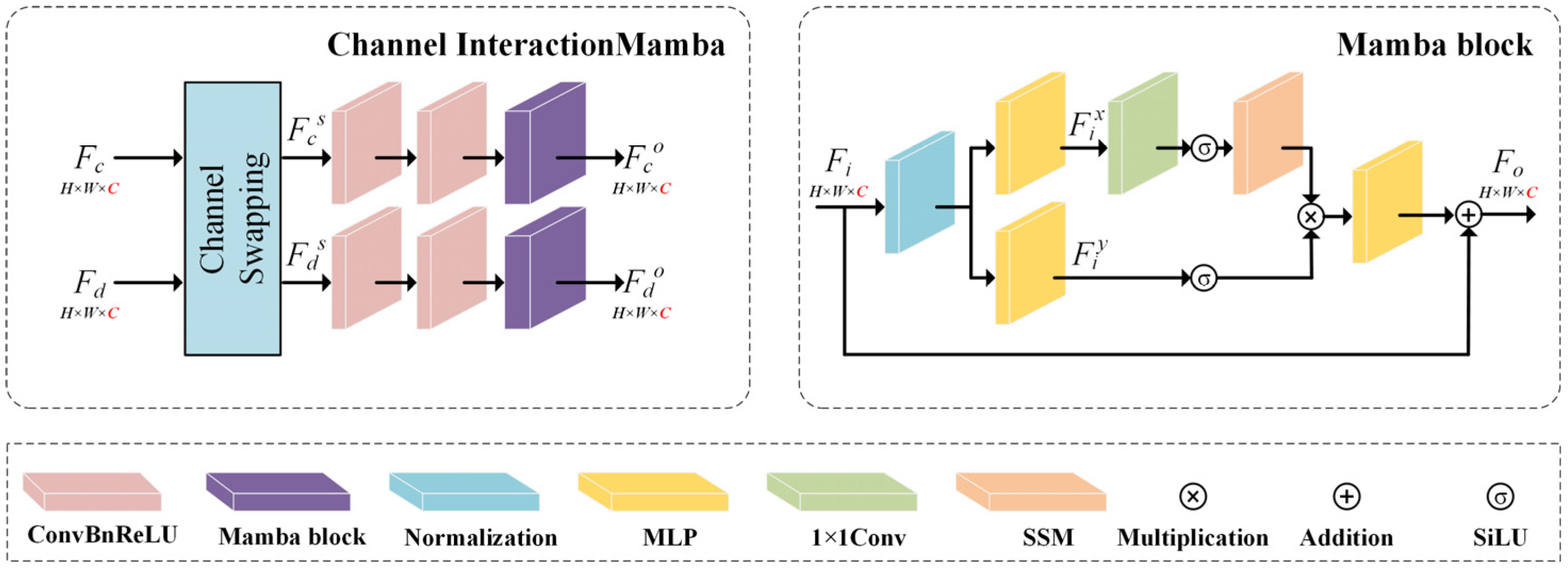
3.3. Channel Interaction Mamba (CIM)
3.4. Feature Fusion Module (FFM)
4. Experimental Results
4.1. Watermarking Invisibility Evaluation
4.2. Robustness on DIBR
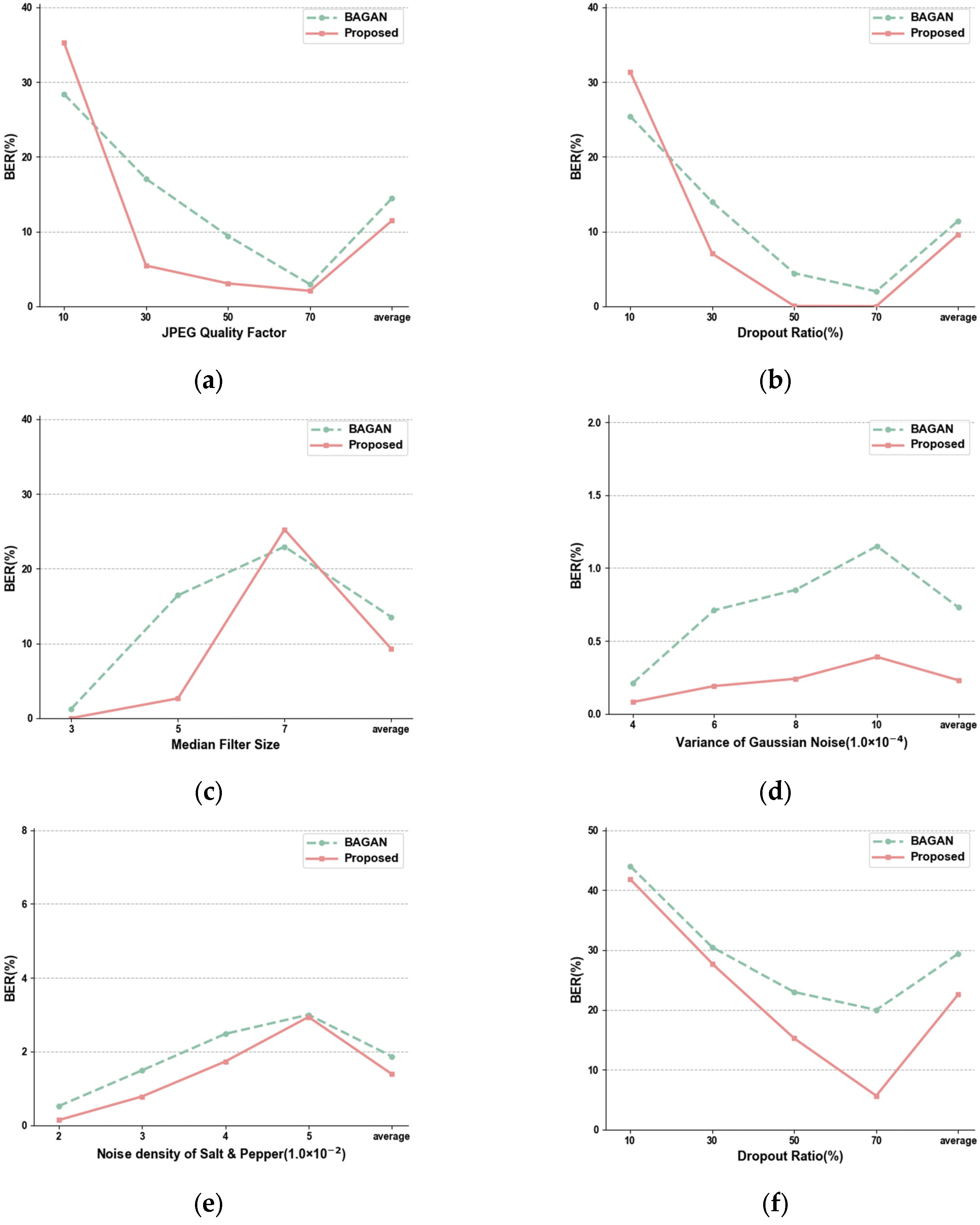
4.3. Robustness in Common Image Processing
4.3.1. Robustness of Center View
4.3.2. Robustness of Synthesized View
4.4. Comparison Under the NYU Dataset
4.5. Statistical Significance Analysis
4.6. Ablation Study
5. Discussion of Computational Cost
6. Conclusions
7. Future Work
- (1)
- The model architecture can be further refined by leveraging the rendering characteristics of DIBR to improve watermarking robustness and imperceptibility.
- (2)
- By integrating visual perception technology, the watermark embedding strategy can be optimized to embed more watermark information in complex texture regions and reduce embedding strength in smooth areas, thereby minimizing perceptual distortion.
- (3)
- Currently, the watermark embedding capacity of the DIBR 3D image remains limited. Future research may focus on optimizing watermark preprocessing to improve embedding capacity.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, Y.; Li, S.; Liu, Y.; Yan, Z.; Dai, Y.; Yu, P.; Sun, L. A survey of AI-generated content (AIGC). ACM Comput. Surv. 2025, 57, 1–38. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, Y.; Qi, S.; Zhao, R.; Xia, Z.; Weng, J. Security and privacy on generative data in AIGC: A survey. ACM Comput. Surv. 2024, 57, 1–34. [Google Scholar] [CrossRef]
- Luo, T.; Zhou, Y.; He, Z.; Jiang, G.; Xu, H.; Qi, S.; Zhang, Y. StegMamba: Distortion-free Immune-Cover for Multi-Image Steganography with State Space Model. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 4576–4591. [Google Scholar] [CrossRef]
- Zhou, Y.; Luo, T.; He, Z.; Jiang, G.; Xu, H.; Chang, C.C. CAISFormer: Channel-wise attention transformer for image steganography. Neurocomputing 2024, 603, 128295. [Google Scholar] [CrossRef]
- Wan, W.; Wang, J.; Zhang, Y.; Li, J.; Yu, H.; Sun, J. A comprehensive survey on robust image watermarking. Neurocomputing 2022, 488, 226–247. [Google Scholar] [CrossRef]
- Qiu, Z.; He, Z.; Zhan, Z.; Pan, Z.; Xian, X.; Jin, Z. Sc-nafssr: Perceptual-oriented stereo image super-resolution using stereo consistency guided nafssr. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 1426–1435. [Google Scholar]
- Zou, W.; Gao, H.; Chen, L.; Zhang, Y.; Jiang, M.; Yu, Z.; Tan, M. Cross-view hierarchy network for stereo image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1396–1405. [Google Scholar]
- Fehn, C. Depth-image-based rendering (DIBR), compression, and transmission for a new approach on 3D-TV. Stereosc. Disp. Virtual Real. Syst. XI 2004, 5291, 93–104. [Google Scholar]
- Nam, S.H.; Kim, W.H.; Mun, S.M.; Hou, J.U.; Choi, S.; Lee, H.K. A SIFT features based blind watermarking for DIBR 3D images. Multimed. Tools Appl. 2018, 77, 7811–7850. [Google Scholar] [CrossRef]
- Kim, H.D.; Lee, J.W.; Oh, T.W.; Lee, H.K. Robust DT-CWT watermarking for DIBR 3D images. IEEE Trans. Broadcast. 2012, 58, 533–543. [Google Scholar] [CrossRef]
- Nam, S.H.; Mun, S.M.; Ahn, W.; Kim, D.; Yu, I.J.; Kim, W.H.; Lee, H.K. NSCT-based robust and perceptual watermarking for DIBR 3D images. IEEE Access 2020, 8, 93760–93781. [Google Scholar] [CrossRef]
- He, Z.; He, L.; Xu, H.; Chai, T.Y.; Luo, T. A bilateral attention based generative adversarial network for DIBR 3D image watermarking. J. Vis. Commun. Image Represent. 2023, 92, 103794. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Liu, W.; Li, H. Adversarial spatio-temporal learning for video deblurring. IEEE Trans. Image Process. 2018, 28, 291–301. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Li, D.; Luo, W.; Ren, W.; Liu, W. Enhanced spatio-temporal interaction learning for video deraining: Faster and better. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1287–1293. [Google Scholar] [CrossRef] [PubMed]
- Hayes, J.; Danezis, G. Generating steganographic images via adversarial training. Adv. Neural Inf. Process. Syst. 2017, 30, 1951–1960. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. Hidden: Hiding data with deep networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 657–672. [Google Scholar]
- Hao, K.; Feng, G.; Zhang, X. Robust image watermarking based on generative adversarial network. China Commun. 2020, 17, 131–140. [Google Scholar] [CrossRef]
- Jia, Z.; Fang, H.; Zhang, W. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 41–49. [Google Scholar]
- Luo, T.; Wu, J.; He, Z.; Xu, H.; Jiang, G.; Chang, C.C. Wformer: A transformer-based soft fusion model for robust image watermarking. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 4179–4196. [Google Scholar] [CrossRef]
- Fang, H.; Jia, Z.; Qiu, Y.; Zhang, J.; Zhang, W.; Chang, E.C. De-END: Decoder-driven watermarking network. IEEE Trans. Multimed. 2022, 25, 7571–7581. [Google Scholar] [CrossRef]
- Halici, E.; Alatan, A.A. Watermarking for depth-image-based rendering. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 4217–4220. [Google Scholar]
- Lee, M.J.; Lee, J.W.; Lee, H.K. Perceptual watermarking for 3D stereoscopic video using depth information. In Proceedings of the 2011 Seventh International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Dalian, China, 14–16 October 2011; pp. 81–84. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Gu, A.; Dao, T.; Ermon, S.; Rudra, A.; Ré, C. Hippo: Recurrent memory with optimal polynomial projections. Adv. Neural Inf. Process. Syst. 2020, 33, 1474–1487. [Google Scholar]
- Luan, T.; Zhang, H.; Li, J.; Zhang, J.; Zhuo, L. Object fusion tracking for RGB-T images via channel swapping and modal mutual attention. IEEE Sens. J. 2023, 23, 22930–22943. [Google Scholar] [CrossRef]
- Wang, C.; Huang, J.; Lv, M.; Du, H.; Wu, Y.; Qin, R. A local enhanced mamba network for hyperspectral image classification. Int. J. Appl. Earth Obs. Geoinf. 2024, 133, 104092. [Google Scholar] [CrossRef]
- Sun, F.; Ren, P.; Yin, B.; Wang, F.; Li, H. CATNet: A cascaded and aggregated transformer network for RGB-D salient object detection. IEEE Trans. Multimed. 2023, 26, 2249–2262. [Google Scholar] [CrossRef]
- Zhou, T.; Fu, H.; Chen, G.; Zhou, Y.; Fan, D.P.; Shao, L. Specificity-preserving RGB-D saliency detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4681–4691. [Google Scholar]
- Collobert, R.; Kavukcuoglu, K.; Farabet, C. Torch7: A matlab-like environment for machine learning. In Proceedings of the BigLearn NIPS Workshop 2011, Sierra Nevada, Spain, 16–17 December 2021. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Zitnick, C.L.; Kang, S.B.; Uyttendaele, M.; Winder, S.; Szeliski, R. High-quality video view interpolation using a layered representation. ACM Trans. Graph. (TOG) 2004, 23, 600–608. [Google Scholar] [CrossRef]
- Hirschmuller, H.; Scharstein, D. Evaluation of cost functions for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | PSNR | SSIM |
|---|---|---|
| BAGAN | 44.91 | 0.9953 |
| NSCT-based | 45.02 | 0.9969 |
| SIFT-based | 46.87 | 0.9972 |
| DTCWT-based | 41.51 | 0.9905 |
| CIMGAN | 45.32 | 0.9948 |
| Dataset | BAGAN | NSCT- Based | SIFT- Based | DTCWT-Based | CIMGAN |
|---|---|---|---|---|---|
| MSR | 0.0000 | 0.0000 | 0.0012 | 0.0118 | 0.0000 |
| HHI | 0.0000 | 0.0000 | 0.0138 | 0.0004 | 0.0000 |
| MSD | 0.0000 | 0.0127 | 0.0073 | 0.0265 | 0.0000 |
| Average | 0.0000 | 0.0042 | 0.0074 | 0.0129 | 0.0000 |
| View | BAGAN | NSCT- Based | SIFT- Based | DTCWT-Based | CIMGAN |
|---|---|---|---|---|---|
| Center | 0.0000 | 0.0042 | 0.0074 | 0.0129 | 0.0000 |
| Synthesized | 0.0027 | 0.0052 | 0.0108 | 0.0217 | 0.0022 |
| Average | 0.0014 | 0.0047 | 0.0091 | 0.0173 | 0.0011 |
| ψtx | BAGAN | NSCT- Based | SIFT- Based | DTCWT-Based | CIMGAN |
|---|---|---|---|---|---|
| 3 | 0.0041 | 0.0051 | 0.0124 | 0.0161 | 0.0018 |
| 4 | 0.0037 | 0.0052 | 0.0105 | 0.0202 | 0.0021 |
| 5 | 0.0027 | 0.0052 | 0.0108 | 0.0217 | 0.0022 |
| 6 | 0.0035 | 0.0053 | 0.0101 | 0.0225 | 0.0029 |
| 7 | 0.0052 | 0.0051 | 0.0111 | 0.0234 | 0.0037 |
| Average | 0.0038 | 0.0052 | 0.0110 | 0.0208 | 0.0025 |
| Noise | BAGAN | NSCT- Based | SIFT- Based | DTCWT-Based | CIMGAN |
|---|---|---|---|---|---|
| JPEG (70) | 0.0685 | 0.1026 | 0.0883 | 0.0969 | 0.0603 |
| JPEG (90) | 0.0284 | 0.0315 | 0.0156 | 0.0256 | 0.0238 |
| Gaussian noise (0.0002) | 0.0029 | 0.0148 | 0.0413 | 0.0405 | 0.0041 |
| Gaussian noise (0.0008) | 0.0091 | 0.0667 | 0.1301 | 0.1272 | 0.0088 |
| Cropping (6%) | 0.0138 | 0.0092 | 0.0138 | 0.0522 | 0.0045 |
| Cropping (15%) | 0.0321 | 0.0445 | 0.0199 | 0.1258 | 0.0071 |
| Translation (3%) | 0.0127 | 0.0138 | 0.0201 | 0.0658 | 0.0107 |
| Translation (6%) | 0.0475 | 0.0551 | 0.0245 | 0.1775 | 0.0249 |
| Salt & Pepper (0.02) | 0.0227 | 0.0232 | 0.0488 | 0.0360 | 0.0132 |
| Salt & Pepper (0.04) | 0.0435 | 0.0475 | 0.1290 | 0.0731 | 0.0403 |
| Average | 0.0242 | 0.0352 | 0.1060 | 0.0778 | 0.0198 |
| Model | PSNR ± Std | 95% CI | SSIM ± Std | 95% CI |
|---|---|---|---|---|
| BAGAN | 43.59 ± 1.14 | [43.51, 43.67] | 0.9929 ± 0.0013 | [0.9928, 0.9930] |
| WFormer | 43.75 ± 1.52 | [43.64, 43.86] | 0.9908 ± 0.0018 | [0.9907, 0.9909] |
| CIMGAN | 44.20 ± 1.23 | [44.11, 44.29] | 0.9926 ± 0.0016 | [0.9925, 0.9927] |
| Noise | BAGAN | Wformer | CIMGAN | |||
|---|---|---|---|---|---|---|
| Center | Synthesized | Center | Synthesized | Center | Synthesized | |
| JPEG (70) | 0.0327 | 0.0782 | 0.0295 | 0.0813 | 0.0228 | 0.0694 |
| Dropout (0.5) | 0.0445 | 0.0489 | 0.0193 | 0.0394 | 0.0090 | 0.0182 |
| Median Filter (3) | 0.0130 | 0.0133 | 0.0082 | 0.0153 | 0.0003 | 0.0037 |
| Crop (0.85) | 0.0102 | 0.0324 | 0.0028 | 0.0097 | 0.0026 | 0.0074 |
| SP (0.04) | 0.0277 | 0.0471 | 0.0493 | 0.0832 | 0.0204 | 0.0440 |
| Translate (0.03) | 0.0068 | 0.0125 | 0.0165 | 0.0243 | 0.0083 | 0.0116 |
| Gaussian noise (0.001) | 0.0112 | 0.0141 | 0.0078 | 0.0152 | 0.0085 | 0.0146 |
| Resize (0.8) | 0.0024 | 0.0053 | 0.0187 | 0.0294 | 0.0104 | 0.0215 |
| Average | 0.0186 | 0.0315 | 0.0190 | 0.0372 | 0.0103 | 0.0238 |
| Model | PSNR | SSIM |
|---|---|---|
| BAGAN | 1 | −1 |
| WFormer | 1 | 1 |
| Noise | BAGAN | Wformer | ||
|---|---|---|---|---|
| Center | Synthesized | Center | Synthesized | |
| JPEG (70) | 1 | 1 | 1 | 1 |
| Dropout (0.5) | 1 | 1 | 1 | 1 |
| Median Filter (3) | 1 | 1 | 1 | 1 |
| Crop (0.85) | 1 | 1 | 0 | 1 |
| SP (0.04) | 1 | 1 | 1 | 1 |
| Translate (0.03) | −1 | 1 | 1 | 1 |
| Gaussian noise (0.001) | 1 | −1 | −1 | 1 |
| Resize (0.8) | −1 | −1 | 1 | 1 |
| Model | PSNR | SSIM |
|---|---|---|
| Model#1 | 43.79 | 0.9864 |
| Model#2 | 45.25 | 0.9946 |
| Model#3 | 44.90 | 0.9921 |
| Model#4 | 44.36 | 0.9897 |
| CIMGAN | 45.32 | 0.9948 |
| Model | View | JPEG (70) | Crop (0.85) | DP (0.5) | MF (5) | SP (0.04) | GN (0.0008) | Average |
|---|---|---|---|---|---|---|---|---|
| Model#1 | Center | 0.0418 | 0.0062 | 0.0154 | 0.0373 | 0.0391 | 0.0046 | 0.0240 |
| Synthesized | 0.0871 | 0.0135 | 0.0272 | 0.0617 | 0.0875 | 0.0096 | 0.0477 | |
| Model#2 | Center | 0.0255 | 0.0029 | 0.0093 | 0.0348 | 0.0227 | 0.0040 | 0.0165 |
| Synthesized | 0.0681 | 0.0064 | 0.0192 | 0.0594 | 0.0495 | 0.0084 | 0.0351 | |
| Model#3 | Center | 0.0241 | 0.0028 | 0.0096 | 0.0301 | 0.0240 | 0.0036 | 0.0157 |
| Synthesized | 0.0597 | 0.0084 | 0.0191 | 0.0457 | 0.0478 | 0.0081 | 0.0315 | |
| Model#4 | Center | 0.0308 | 0.0025 | 0.0109 | 0.0276 | 0.0320 | 0.0055 | 0.0182 |
| Synthesized | 0.0697 | 0.0075 | 0.0221 | 0.0438 | 0.0681 | 0.0093 | 0.0367 | |
| CIMGAN | Center | 0.0205 | 0.0021 | 0.0031 | 0.0264 | 0.0173 | 0.0039 | 0.0122 |
| Synthesized | 0.0603 | 0.0071 | 0.0139 | 0.0411 | 0.0403 | 0.0088 | 0.0285 |
| Model | Different Items | ||
|---|---|---|---|
| Parameter (M) | FLOPs (G) | Running Time (s) | |
| WFormer | 1.98 | 60.97 | 0.0356 |
| BAGAN | 1.18 | 116.37 | 0.0231 |
| CIMGAN | 1.25 | 69.25 | 0.0187 |
| Model | Different Items | ||
|---|---|---|---|
| Parameter (M) | FLOPs (G) | Running Time (s) | |
| Restormer | 1.37 | 99.31 | 0.0206 |
| Swin Transformer | 1.35 | 95.86 | 0.0212 |
| CIMGAN | 1.25 | 69.25 | 0.0187 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Sun, Z.; Bai, R.; Jin, C. Channel Interaction Mamba-Guided Generative Adversarial Network for Depth-Image-Based Rendering 3D Image Watermarking. Electronics 2025, 14, 2050. https://doi.org/10.3390/electronics14102050
Chen Q, Sun Z, Bai R, Jin C. Channel Interaction Mamba-Guided Generative Adversarial Network for Depth-Image-Based Rendering 3D Image Watermarking. Electronics. 2025; 14(10):2050. https://doi.org/10.3390/electronics14102050
Chicago/Turabian StyleChen, Qingmo, Zhongxing Sun, Rui Bai, and Chongchong Jin. 2025. "Channel Interaction Mamba-Guided Generative Adversarial Network for Depth-Image-Based Rendering 3D Image Watermarking" Electronics 14, no. 10: 2050. https://doi.org/10.3390/electronics14102050
APA StyleChen, Q., Sun, Z., Bai, R., & Jin, C. (2025). Channel Interaction Mamba-Guided Generative Adversarial Network for Depth-Image-Based Rendering 3D Image Watermarking. Electronics, 14(10), 2050. https://doi.org/10.3390/electronics14102050