- Article

Estimation of Two-States Proportional Hazard Rates Models with Unobserved Heterogeneity
- Emilio Congregado,
- David Troncoso-Ponce and
- Alejandro Morales-Kirioukhina
- + 1 author
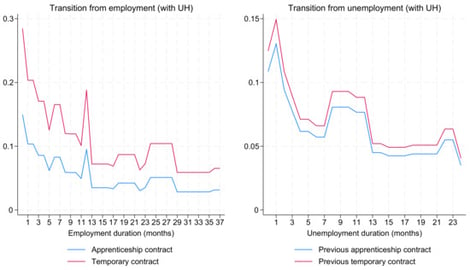
This article examines two-state proportional hazard rate models with unobserved heterogeneity specific to each state, a framework that is especially relevant for labor market transitions. To make estimation feasible in large longitudinal datasets, we implement hshaz2s, a Stata routine that uses analytical expressions for the gradient vector and Hessian matrix of the log-likelihood function through the dual second-order moment (d2 ml) method. The empirical application estimates a discrete-time duration model for transitions between employment and unemployment using Spanish labor market microdata for young low-skilled workers over 2000–2019. The results show that apprenticeship contracts are associated with lower exit rates from employment than other temporary contracts, but not with faster transitions from unemployment back into employment. The estimates also reveal substantial state-specific unobserved heterogeneity, with a large latent group characterized by persistent spells in both states. Analytical second-order information also markedly reduces convergence time under richer heterogeneity structures. Overall, the article makes this class of two-state hazard models operational for applied research and provides new evidence on apprenticeship and temporary contracts in Spain.
28 April 2026