

Econometrics, Volume 13, Issue 4 (December 2025) – 15 articles
Cover Story (view full-size image):
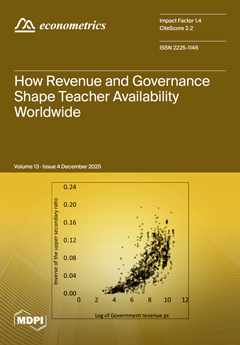
This paper models how government revenue and governance quality affect teacher supply worldwide. Using data from 217 countries (1980–2022), the authors build a nonlinear logistic model linking revenue per capita and governance indicators to the school‑age population‑to‑teacher ratio. They find that higher revenue increases teacher supply, and strong governance amplifies this effect. The model helps predict how fiscal changes could advance progress toward SDG 4.c on expanding qualified teacher numbers. View this paper
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue