Abstract
This article introduces new counterfactual standardization techniques for comparing duration distributions subject to random censoring through counterfactual decompositions. The counterfactual distribution of one population relative to another is computed after estimating the conditional distribution, using either a semiparametric or a nonparametric specification. We consider both the semiparametric proportional hazard model and a fully nonparametric partition-based estimator. The finite-sample performance of the proposed methods is evaluated through Monte Carlo experiments. We also illustrate the methodology with an application to unemployment duration in Spain during the period between 2004 and 2007, focusing on gender differences. The results indicate that observable characteristics account for only a small portion of the observed gap.
1. Introduction
When comparing a phenomenon across populations, it is essential to account for differences in population composition in order to avoid drawing misleading conclusions. For example, in analyzing differences in unemployment duration between men and women, it is necessary to control for differences in human capital and job tenure to ensure comparability. This can be carried out by estimating the outcome of interest in both populations under a common composition, i.e., the unemployment duration distribution that would arise if men and women shared the same levels of human capital and tenure.
() introduced standardization techniques to compare crude death rates across districts in Great Britain, accounting for differences in age structure. In this context, standardization entails re-estimating counterfactual values of the outcome under a common distribution of covariates. Typically, this distribution corresponds to that of one of the populations, although it may also be defined as the pooled distribution or another external benchmark. Later, () formalized this approach and proposed decomposing the total difference in mortality rates into a composition effect, driven by differences in population characteristics, and a structure effect reflecting differences in group-specific risks. The latter term captures disparities in returns to observable characteristics and is often interpreted as reflecting institutional factors, behavioral responses, or potential discrimination (; ; ). The structural effect should therefore be interpreted as a statistical measure of unexplained heterogeneity rather than as evidence of a specific causal mechanism. () extended this framework to decomposing the differences between the characteristics of the cumulative distribution functions (CDFs) of two populations.
In the context of unemployment duration gender gaps, the composition effect measures the share of the observed difference that arises solely from disparities in observable characteristics. In contrast, the structure effect captures the residual difference that would remain even if both groups shared identical covariate distributions. Moreover, the composition effect can be further decomposed to assess the relative contribution of each covariate (; ).
In economics, counterfactual decompositions became prominent through their application to the analysis of gender wage gaps. The Oaxaca–Blinder (OB) decomposition, introduced independently by () and (), partitions the difference between sample means into two counterfactual components based on a linear specification of the regression function. In this framework, the counterfactual mean is obtained as the average of fitted values using coefficient estimates from one population and covariate observations from the other. The OB approach has been extended to other features of the cumulative distribution function and applied widely in the study of gender wage differentials (e.g., ; ; ; and ). Related work has analyzed other wage differentials, including racial (; ), union (), skill-related (), cross-country (), policy-induced (), and immigrant–native () gaps. () provides a comprehensive review of methodologies for decomposing changes in wage distributions.
Nonparametric and semiparametric extensions relax the linearity assumption to address mean and distributional decompositions, often relying on kernel regression or density estimation (e.g., ; ). For other distributional features, decompositions employ flexible nonparametric or semiparametric specifications of the conditional CDF. () provide an extensive overview of these methodological developments. Despite their broad use, only a limited number of studies have examined duration outcomes such as unemployment spells. More recent contributions include (), who generalize the OB framework to nonlinear models, and (), who propose a simultaneous decomposition of means and inequality.
Although these methods are widely used in applied work, relatively few studies focus on duration outcomes, such as unemployment spells. Analyzing duration data requires stronger identification assumptions, particularly concerning the censoring mechanism. We propose counterfactual decomposition techniques for right-censored duration outcomes that encompass alternative standardizations of the distribution function, using both nonparametric and semiparametric specifications of the underlying cumulative distribution function. We also provide a detailed discussion of how to implement OB-type decompositions in this setting. The original OB proposal cannot be directly extended to other distributional features that are nonlinear in the underlying conditional CDF. In particular, the cumulative hazard rate (CHR) is defined as the integral of the conditional CDF over the corresponding survival function. The averaged CHR (ACHR) is not directly related to the HR, and the two can exhibit very different shapes, as shown in the empirical example. Furthermore, the interpretation of the ACHR is not obvious. The HR is the main research tool in duration analysis, providing valuable information on the underlying duration distribution. In the context of unemployment spells, it measures the instantaneous probability of finding a job after remaining unemployed for a period of length t. Nevertheless, as we show in this article, the counterfactual HR can be derived from the counterfactual CDF, and this estimator can be used to decompose the difference between the HR estimates in the two populations.
The Cox proportional cumulative hazard rate (PCHR) model has been widely used to study gender gaps in unemployment duration, typically through the averaged cumulative hazard function (ACHF), i.e., the conditional hazard function integrated with respect to the marginal distribution of covariates, see, e.g., (), (), and (). Since the ACHF and the marginal hazard function (HF) are generally unrelated, inference based on the ACHF may be misleading. To our knowledge, no studies have implemented direct standardization of the HF or other distributional features under right censoring, nor have these methods been applied beyond unemployment. The counterfactual decomposition methodology presented in this article is directly transferable to these domains, offering a unified framework for analyzing differences in censored duration outcomes. Beyond unemployment analysis, the proposed methods can be applied to a wide range of outcomes that can be expressed as duration times. Examples include time to school dropout, time to credit default or repayment, duration until job promotion or contract termination, patient recovery times in medical studies, or the length of stay in migration.
Because the mean duration cannot be consistently estimated in the presence of censoring, comparisons based on the restricted mean survival time (RMST), i.e., the expected duration within a fixed time window, are more appropriate. For example, comparisons over the first 12 months (short-run unemployment) or 24 months (long-run unemployment) are meaningful. We extend our framework to incorporate RMST-based standardization and counterfactual decomposition. Our analysis connects to this broader research agenda, complementing recent work on counterfactual survival analysis (), on the role of heterogeneous survival expectations in shaping structural effects (), and on semiparametric methods for counterfactual inference in duration models ().
We evaluate the performance of the proposed methods through Monte Carlo simulations under alternative data-generating processes, and we illustrate their empirical application by decomposing gender gaps in unemployment duration in Spain during 2004–2007, using data from the European Union Statistics on Income and Living Conditions (EU-SILC). The results indicate that composition effects account for only a small fraction of the observed gender gap. Moreover, estimates based on ACHR and HR differ substantially, with nonparametric approaches providing more robust and reliable insights.
The remainder of this article is structured as follows. Section 2 introduces the main notation, standardization techniques, and counterfactual decomposition methods. Section 3 develops estimators based on both the PCHR model and nonparametric specifications of the conditional distribution. Section 4 evaluates the finite-sample performance through Monte Carlo simulations. Section 5 applies the proposed methods to Spanish unemployment duration data. Finally, Section 6 concludes with key findings and remarks.
2. Standardization Under Censoring
Consider the duration random variable for populations observed under right censoring according to variable , . Counterfactual decompositions must be performed from the observed random vector where is the observed vector of population components, or characteristics, with explanatory power for , and indicates whether or not the observed duration is censored with , the indicator function of event A. Censoring appears due to the lack of follow-up for the individuals. When individuals are observed over a fixed period, complete durations are not always available because the relevant event did not occur at the end of the observation period (administrative censoring) or because the individual drops out before completion (loss to follow-up).
Let be the joint cumulative distribution function (CDF) of and the corresponding CDF of given , i.e.,
for all and where is the corresponding CDF of a generic random variable, or random vector, , and is the upper bound of its support. Note that the sample does not provide information beyond , which implies that cannot be identified from the CDF of the observable random vector . Thus, the consistent estimation of the sub-DF,
is the best we can hope for, where for any generic CDF and is the number of jumps in Notice that for all , and also for all when either, .
The standardized version of , taking population s as standard, is
which represents the distribution that population j would exhibit if it had the covariate distribution of population s. For instance, in the context of gender differences in unemployment duration, this would correspond to the distribution of unemployment duration for women if they had the same observable characteristics as men. Henceforth, we take for granted that integrals in (1) are well defined, which requires that the support of the components in the standard population is contained in the support of the standardized population. Notice that The counterfactual distribution is the basis for identifying their moments or other characteristics. In particular, the standardized cumulative HR is
where is the standarized HR. This is interpreted, in the context of unemployment duration analysis, as the instant probability of finding a job that would have a worker unemployed during a period of length t, taken at random from population j, if population j had the same distribution of covariates than population s.
As it was mentioned in the introduction, the existing applied work on counterfactual duration analysis of unemployment duration gender gaps is based on the ACHR, where is the CHR, defined as (2) in terms of the cumulative CHR
Obviously, the and shapes are not necessarily related.
Alternative estimators can also be considered, relying on different specifications of the conditional CDF, which is equivalently characterized by the conditional hazard rate (CHR) for censored duration variables. Examples include semiparametric approaches such as the accelerated failure time (AFT) model (), the proportional odds (PO) model (), or, more recently, the distributional regression framework for censored duration data proposed by (). These alternatives to the Cox model may be preferred depending on the context. In this article, we have focused on Cox’s specification because it is by far the most popular. The advantage of a nonparametric model is that the underlying CHR is not specified, and the regularity conditions needed to justify the consistency of the proposed partition estimate are minimal taking a fixed number of partitions. Notice that, because we are estimating integrals using KM weights, independence between the survival variable T and the censoring variable C is needed. Naturally, other nonparametric estimators could also be employed.
While the hazard rate remains the central distributional feature in duration analysis, mean-based comparisons are often of interest from a policy perspective. Since the unconditional mean of duration cannot be consistently estimated under censoring, a natural alternative is the restricted mean survival time (RMST), defined as,
The RMST is the average duration in the first periods. For instance, if , this is the average unemployment duration during the first 12 months, which is related to short-term unemployment. (), (), (), and () provide applications of RMST to different contexts. The parameter of the corresponding counterfactual CDF is
The crucial step to estimate the standardized quantities, either , , or requires the prior estimation of . To this end, we consider two possibilities. One is based on the PCHR specification, which assumes that the underlying CHR, belongs to the family of monotonically increasing functions where and .
When the CHR specification is correct, there exists a and such that
The identification of and requires that
- A.0.
- is independent of conditionally on
The standardized with respect to population assuming that , is
with corresponding cumulative HR
with HR which is typically unrelated to the ACHR The corresponding standardized RMST is,
Note that for all under a correct specification, but this is not necessarily the case under misspecification.
We can avoid specifying the CDF by noticing that standardizations can also be performed from any given partition of such that for all since
with
and This suggests the standardization
Thus, it is not needed to specify to obtain the components in the counterfactual decomposition, but only Notice that, unlike the semiparametric standardization we always have that despite the actual underlying CDF shape, but for In order to identify for we need to assume that,
- A.1
- is independent of
- A.2
- and are independent conditional on a.s.,
Condition A.1 is the standard identification condition for the nonparametric which justifies the consistency of the Kaplan–Meier (KM) product limit estimator using censored data (). Assumption A.2 is the extra condition, provided by () to identify , which establishes the relation between the covariates and the censoring mechanism. Notice that we have a different standardization for each possible partition, which is the cost that one must pay for not imposing a more restrictive specification.
The standardized RMST using partitions is
An alternative standardization for the RMST relies on a semiparametric specification of the conditional mean of the restricted version of the outcome , i.e., imposing restrictions on since
In particular, a linear specification of produces the OB standardization analog for the RMST. That is, taking into account that with parameters such that has zero mean and is uncorrelated with the OB standardization of is .
The total CDF difference can be written in terms of the counterfactual effects using as
where is the counterfactual structural effect, is the counterfactual composition effect, and . We can perform a similar decomposition using but we must take into account that the decomposition is for which is different than under the misspecification of the conditional CDF .
The HR or the RMST differences can be decomposed differently from (6). That is, if represents a particular distributional feature of population e.g., can be , , or
3. Estimation
The sample observed consists of as . Henceforth, ties within censored or uncensored duration times are ordered arbitrarily, and ties among uncensored and censored durations are treated as if the former precedes the latter.
Assuming a PCHR specification, is estimated by
where is the () estimator of and is the Partial Maximum Likelihood (PML) estimator of (). Henceforth, we avoid references to the sample size.
The weak convergence of is an immediate consequence of the well-developed asymptotic theory for . () showed that, under and Thus, applying Theorem 4.1 in (), for when the PCHR specification is correct,
where as .
Asymptotic confidence intervals for can be obtained applying results in (). Bootstrap confidence intervals can also be obtained using techniques designed for the PCHR model, as in (), which can be justified in the lines of Theorem 4.2 in ().
The Cox estimator adapted to the counterfactual context is consistent when the CHR is correctly specified but inconsistent under misspecification. The formal justification of inferences based on the proposed counterfactual decompositions is beyond the scope of this article. The results in () can be used to derive a functional central limit theorem (CLT) for the counterfactual estimator of the HR based on the Cox’s specification. Inferences using the nonparametric CDF estimator based on partitions and KM weights can be carried out using results in () and (). These partition estimators can be implemented when regressors are not necessarily random variables, but other random objects such as those used when dealing with spatial, networks, or functional data. Inferences of the counterfactual CDF estimator when the number of sets in the partitions diverges and the size of the sets converges to zero as the sample size diverges could be justified using universal consistency results (), as implemented for partition estimators of conditional moments by ().
Under A.1, is consistently estimated by the KM estimator,
where
are KM weights, and for any generic sequence is the concomitant of the ordered i.e., if . Then, is the mass attached to . Likewise, under A.1 and A.2, is consistently estimated by
Therefore, the estimator of in (5) is estimated by
with and
Any of the above DF standardizations results in alternative estimates of the cumulative HR. Let denote either or and the estimator is
which is a jump function in both cases. The corresponding estimate is the value of the jump
or the smooth version
where and K is a kernel function integrating to one.
Each standarized DF results in alternative estimates, i.e.,
using the PCHR specification, and
when is nonparametric, using the estimator based on grouped data.
An OB estimator of can be obtained after noticing that
with and with This suggests applying the OB approach by estimating as which is inconsistent when is nonlinear.
() shows, under and that and that for any function and such that , is a consistent estimator of for which shows that and are consistent estimators of and respectively. This justifies that is a consistent estimator of () derives the asymptotic distribution of . Bootstrap confidence intervals can be obtained following the procedure described in (). A formal justification of the inferential properties is beyond the scope of this paper.
Regarding the decompositions, we estimate by and the corresponding decomposition is
The estimated counterfactual structural and composition effects, and are consistent estimates of and respectively. Decompositions based on are performed in the same way, but consistent estimation requires the correct specification of the underlying CHR. Likewise, we can perform decomposition of the differences between HR and RSTM estimates.
4. Monte Carlo Simulations
This section provides evidence on the finite sample performance of the alternative standardization methods for the RMST using only one component (). Henceforth, PML stands for the method using the Partial Maximum Likelihood estimator assuming a PCHR specification, OB-KM and OB-KM-Pol3 for the method based on the classical OB decomposition, using KM weights, under a linear and polynomial of order 3 specifications, respectively, and NP for the nonparametric method with and 10 with classes of equal size.
We consider the following designs,
- DGP1:
- DGP2:
- DGP3:
Monte Carlo experiments are based on 1000 replications with sample sizes of 200, 800, and 3200. We report the root mean squared error (RMSE) for the different estimators. Simulations are performed using as the target parameter and without exploiting the fact that, in the three designs, and are unbounded, i.e., and Parameter is consistently estimated by and the RMST is calculated with
Table 1 reports results under DGP1 design. Since the PCHR specification is incorrect, the PML estimator is inconsistent for , , which explains the large biases. The regression function is linear and hence both OB-KM and OB-KM-Pol3 are consistent. As expected, OB-KM, which is asymptotically the most efficient, performs best in finite samples, but there are no significant loses using the overparameterized OB-KM-Pol3. As expected, the nonparametric NP(3) and NP(10) estimators are inefficient.

Table 1.
Comparison of alternative procedures under DGP1.
Table 2 reports results under the DGP2 specification. The OB-KM and OB-KM-Pol3 are still consistent estimators of , but they are inconsistent estimators of for . In turn, since the PCHR specification is correct, the PML is consistent and efficient. This is confirmed by the simulations. Interestingly, OB-KM-Pol3 is a fairly robust alternative to OB-KM and performs similarly to NP(m).
Table 2.
Comparison of alternative procedures under DGP2.
Table 3 reports results under the DGP3. In this case, NP(m), OB-KM, and OB-KM-Pol3 are consistent for but the PML is inconsistent. However, OB-KM and OB-KM-Pol3 are inconsistent for but NP(m) consistently estimates NP(m) performs much better than both PML and OB-KM in this case. However, there is sensitivity with respect to the number of classes chosen, i.e., NP(3) versus NP(10). OB-KM-Pol3 shows to be a robust alternative to OB-KM that fairly captures nonlinearities in the underlying regression.
Table 3.
Comparison of alternative procedures under DGP3.
We also study the effect of ignoring censoring. First, assessing the effect on the estimates when censoring is not taken into account, and second, analyzing the effect of trying to estimate the mean, which is not identified because is bounded. Table 4 provides the RMSEs under DGP1 based on OLS fits using censored and uncensored observations, i.e., assuming that is the actual duration. These biased estimates are compared with the corresponding OB-KM estimator. Simulation results show serious biases when ignoring censoring.
Table 4.
Effect of ignoring censoring.
Table 5 illustrates the effect of neglecting the fact that when estimating the duration mean. In this case, cannot be consistently estimated beyond , and unlike previous experiments, where it is not possible to estimate or for We compare the PML estimators of under design DGP2, i.e., PML is efficient, when is censored, using as the censoring variable, i.e., . Table 5 confirms high biases for estimating the mean when , but the PML estimator still performs well as an estimator of . This illustrates the importance of focusing the statistical inference in truncated or restricted parameters as the RMST.
Table 5.
Estimation of RMST and mean with .
5. Unemployment Duration Gender Gaps in Spain
This section investigates the causes of unemployment duration gender gaps in Spain using counterfactual decompositions of HR and RMST differences. We also provide a comparison between ACHR and HR estimates using the alternative specifications. The Spanish case is particularly interesting because it has experienced one of the highest unemployment rates among OECD countries in recent decades. According to official statistics, for the period 1995–2005, the average unemployment rate was around 6.8% in OECD countries and 5% in the US while it was 14% in Spain. Moreover, the difference in unemployment rates by gender has also been important. For the same period, women exhibited an unemployment rate 9 percentage points (p.p.) higher, while in the US this gap was around 0.04 p.p.
The existing literature has mainly paid attention to gender gaps in the aggregated unemployment rate (; ; ; ), but gender gaps in other unemployment features, like spells of unemployment duration, have received less attention. Research on unemployment duration gender gaps has almost exclusively focused in explaining the gender differences in the ACHR rather than HR. See Section 1 for a discussion.
We implement the proposed methodology to perform counterfactual decompositions of the HR and RMST differences using data from the Survey of Income and Living Conditions (SILC) for the period 2004–2007. Data is available on the website of the Spanish National Institute of Statistics https://www.ine.es/dyngs/INEbase/operacion.htm?c=Estadistica_C&cid=1254736176807&menu=resultados&idp=1254735976608#_tabs-1254736195153 (accessed on 15 october 2022). This survey, carried out by the European Commission, is a rotative household panel that collects information on socioeconomic characteristics, including the occupational status (monthly) for a period of 4 years. Our population consists of unemployed workers older than 25 starting a spell of unemployment during the period 2004–2007. All data used in this study are publicly available from the Spanish National Statistics Institute (INE). We measure unemployment duration as the number of months that a worker is not employed, which is usually referred to as non-employment duration.
We consider as composition variables those commonly used in unemployment duration analysis such as age, educational level, tenure, marital status, whether the individual is the head of the household, the number of unemployed in the household, city size (according to three levels of urbanization in the SILC as big city, medium size city, and small city), and region (; ; ). The first three variables refer to human capital characteristics, while the others are related to the opportunity cost of being unemployed and the reservation wage. Table 6 provides summary statistics for the discrete explanatory variables and Figure 1 the corresponding QQ plots for the continuous variables, i.e., age and tenure. Compositions are similar in the two populations, except for tenure. Therefore, the composition effect should not be particularly important. We observe censoring levels of 21.4% for women and 16.2% for men.
Table 6.
Descriptive statistics of composition variables.
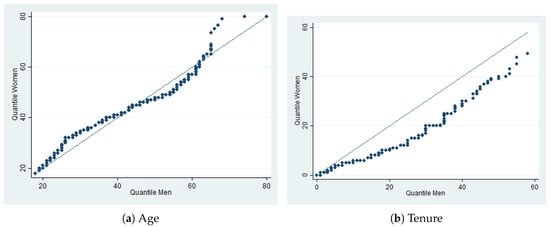
Figure 1.
QQ plots for age and tenure by gender. (a) QQ plot of age. (b) QQ plot of tenure.
Henceforth, population 0 corresponds to women and population 1 to men. First, we analyze the HR differences between the two populations. Figure 2 provides KM estimates of the marginal HR, and the corresponding nonparametric estimates of based on a partition , as well as the HR difference, into counterfactual effects. The partition is based on classes and is estimated using kernel smoothing, , with an Epanechnikov kernel and the bandwidth chosen by the classical plug-in method. The number of classes in the partition was established according to the structure of the composition variables using some natural thresholds for the continuous variables. For instance, we grouped workers between 25 and 40 years old (prime-age workers) and workers with less than 10 years tenure. If the number of partitions is too high, some classes could contain very few observations, particularly when there is a high dependence on covariates, e.g., there are few observations in a partition class with young workers of more than 10 years tenure, married, and with a high education level. Therefore, by using age, labor market size, and marital status, we construct eight classes. This method has the advantage that the classes in a partition can be chosen in a natural way, accounting for the observed relation between duration and covariates.
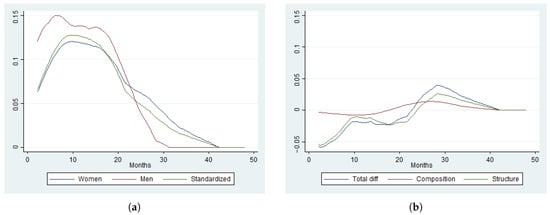
Figure 2.
Standardization and decomposition of the averaged hazard rate based on a nonparametric specification (NP(8)). (a) Averaged conditional hazard. (b) Counterfactual components.
The nonparametric KM estimates of the HR show an acceleration of women HR after 24 months of unemployment, which is consistent with the unemployment compensation normative in Spain during the analyzed period. Unemployment benefits expired after 24 months and workers received 70% of their salary during the first 6 months and 60% for up to 24 months. Figure 2 suggests that, on average, women exhaust all unemployment benefits, producing a spike in the HR starting around the expiration rate. That is, women and men exhibit different optimal delays in job acceptance. This phenomenon has also been documented by () and () using Norwegian and Slovenian data, respectively. We observe that the estimated composition effect is very small at any period. That is, HR differences between women and men do not seem to be explained by the socioeconomic characteristics considered in this study, which are almost identical, but by anything else, like circumstances of the labor market’s tightness and discrimination related to institutional factors, labor circumstances, or behavioral aspects ().
We have checked Cox’s model specification for the two populations using the popular () residual based goodness-of-fit test, which results in p-values of 0.031 and 0.654 for women and men, respectively. Therefore, Cox’s specification is rejected for women but not for men, at 5% significance. Figure 3 shows the smooth version of PML standardized HR estimates, with the same kernel and bandwidths used in the nonparametric case. The estimates are quantitatively very different to the nonparametric ones in Figure 2, possibly because of misspecification, though it also shows a composition effect close to zero at any period and an acceleration of the HR for women after 24 months of unemployment.
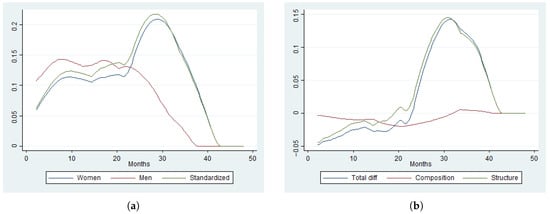
Figure 3.
Standardization and decomposition of the marginal hazard rate. Based on a nonparametric specification, NP(8). (a) Marginal hazard. (b) Counterfactual components.
Figure 4 and Figure 5 provide the ACHR estimates and its standardizations using NP(8) and PML, respectively. The HR and ACHR shapes are very different for each estimator. However, the counterfactual composition effect of both HR and ACHR are close to zero. The ACHR estimates of the counterfactual decompositions using PML is particularly hard to interpret.
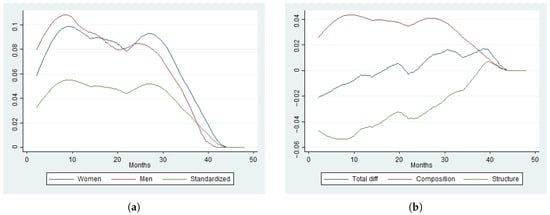
Figure 4.
Standardization and decomposition of the averaged hazard rate based on the PCHR specification. (a) Averaged conditional hazard. (b) Counterfactual components.
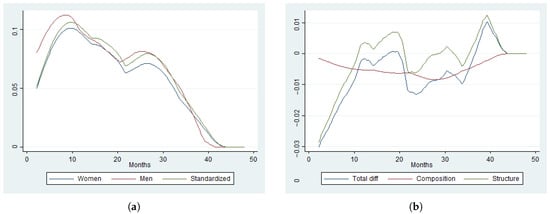
Figure 5.
Standardization and decomposition of the marginal hazard rate based on the PCHR specification. (a)Marginal hazard. (b) Counterfactual components.
Next, we analyze the and estimates for using OB-KM, PML, and NP(8), which produces estimates of the duration means when and also for , which are of interest when studying short- and medium-term unemployment differences. RMST estimates and their corresponding counterfactual decompositions can be found in Table 7 and Table 8, respectively. The estimate of the non-standardized RMST during the first 42 months is around 10.8 months for women and 7.9 months for men. The standardized RMST estimate, which is interpreted as the average unemployment duration during the first 42 months if women would have the same components than men is around 10.3 months, close to the corresponding nonstandardized value. Results across methods are qualitatively similar and reveal a reduction in the corresponding standardized RMST.
Table 7.
Standardized RMST.
Table 8.
Decomposition components’ RMST.
The counterfactual decompositions of RMST using OB-KM and PML for (see Table 8) are fairly different compared to the NP(8), which may indicate a misspecification of the underlying assumed structures. For instance, the OB-KM estimator might be biased because is nonlinear and the PML is also biased because the underlying CDF does not follow a PCHR model, which was confirmed by Schoenfeld’s test.
The counterfactual composition effect for any is close to zero for any of the three methods. This indicates that the difference in worker characteristics slightly increases the severity of women’s unemployment duration compared to men, which might be driven mainly because of tenure, as suggested in previous descriptive analyses. Notice that the counterfactual effects using the OB-KM and PML methods are similar, but the composition effect using NP(8) is much smaller, as we have already seen for the HR in Figure 2 and Figure 3. Similar results are obtained for and . However, based on NP(8) and OB-KM, it seems that the composition effect is more important when explaining unemployment duration gender gaps in the first stages of unemployment, but this is always much smaller than the structure effect.
6. Conclusions
We have presented a new methodology for standardizing duration distributions using right-censored data. To this end, we introduced the counterfactual hazard function, as well as parameters that summarize the characteristics of the duration CDF, such as the RMST. These are nonlinear functionals of the underlying conditional CDF, and we have shown that the OB technique for obtaining counterfactual means cannot, in general, be extrapolated to this setting. In particular, the ACHR—obtained by averaging certain conditional hazard rates, typically under a proportional hazards specification—lacks a clear interpretation and may lead to misleading conclusions.
We proposed the following two types of counterfactual estimators of the conditional CDF: on the one hand, nonparametric estimators are based on partitioning the support of the explanatory variables into a fixed number of classes, and consistently estimate the joint CDF of durations and covariates using Kaplan–Meier (KM) weights; on the other hand, semiparametric estimators are based on a Cox proportional hazard specification, which are inconsistent under model misspecification.
The finite-sample properties of these estimators and the resulting decompositions—evaluated through Monte Carlo simulations and an application to gender gaps in unemployment duration using Spanish data—show that the nonparametric approach performs reasonably well in finite samples. Moreover, the OB approach using KM weights proves robust for RMST decompositions when a flexible functional form (such as a polynomial) is used for the underlying regression. In contrast, estimates based on the semiparametric PCHR specification perform very poorly under misspecification.
The empirical application shows that decompositions of hazard rate (HR) differences, rather than of averaged hazard rates (ACHR), yield more reliable results. The analysis suggests that the gender gap is mainly driven by the structure effect.
There are several potential applications and extensions of the proposed methods that are of interest. For example, the counterfactual estimators developed in this study can be applied across a broad range of disciplines such as health, labor and education economics, finance, management, and public policy. From a methodological standpoint, future work could refine the proposed estimators by incorporating more flexible frameworks for conditional distribution estimation and by developing data-driven partition selection rules in the nonparametric context.
Author Contributions
Conceptualization, M.A.D. and A.G.-S.; methodology, M.A.D.; software, A.G.-S.; validation, M.A.D. and A.G.-S.; formal analysis, M.A.D.; data curation, A.G.-S.; writing—original draft preparation, M.A.D.; writing—review and editing, A.G.-S.; visualization, A.G.-S.; supervision, M.A.D.; project administration, M.A.D.; funding acquisition, M.A.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Ministerio de Ciencia, Innovación y Universidades (MICIU) and Agencia Nacional de Investigación (AEI, 10.13039/501100011033), grant numbers CEX2021-001181-M and PID2021-125178NB-I00, and Comunidad de Madrid, grant EPUC3M11 (V PRICIT).
Data Availability Statement
The data used are openly available and their sources are fully documented in the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Addison, J., & Portugal, P. (2003). Unemployment duration competing and defective risks. Journal of Human Resources, 38, 156–191. [Google Scholar] [CrossRef]
- Andersen, P., & Gill, R. (1982). Cox’s regression model for counting processes: A large sample study. The Annals of Statistics, 10, 1100–1120. [Google Scholar] [CrossRef]
- Azmat, G., Güell, M., & Manning, A. (2006). Gender gaps in unemployment rates in OECD countries. Journal of Labor Economics, 24, 1–37. [Google Scholar] [CrossRef]
- Bachmann, R., & Sinning, M. (2016). Decomposing the ins and outs of cyclical unemployment. Oxford Bulletin of Economics and Statistics, 78, 853–876. [Google Scholar] [CrossRef]
- Blau, F., & Kahn, L. (1992). The gender earnings gap: Learning from international comparisons. The American Economic Review, 82, 533–538. [Google Scholar]
- Blinder, A. (1973). Wage discrimination: Reduced form and structural estimates. Journal of Human Resources, 8, 436–455. [Google Scholar] [CrossRef]
- Boone, J., & van Ours, J. (2012). Why is there a spike in the job finding rate at benefit exhaustion? De Economist, 160, 413–438. [Google Scholar] [CrossRef]
- Breslow, N. (1974). Covariance analysis of censored survival data. Biometrics, 30, 89–99. [Google Scholar] [CrossRef]
- Burr, D. (1994). A comparison of certain bootstrap confidence intervals in the Cox model. Journal of the American Statistical Association, 89, 1290–1302. [Google Scholar] [CrossRef]
- Cain, G. (1986). The economic analysis of labor market discrimination: A survey. In O. Ashenfelter, & D. Card (Eds.), Handbook of labor economics (Vol. 1, pp. 693–785). Elsevier Science Publishers. [Google Scholar]
- Chapfuwa, P., Assaad, S., Zeng, S., Pencina, M. J., Carin, L., & Henao, R. (2021, April 8–10). Enabling counterfactual survival analysis with balanced representations. ACM Conference on Health, Inference, and Learning (CHIL) (pp. 133–145), Virtual Event. [Google Scholar]
- Charpentier, A., & Flachaire, E. (2024). Oaxaca-Blinder decomposition of changes in means and inequality: A simultaneous approach. Economics Bulletin, 44(1), 308–320. [Google Scholar]
- Chen, P. Y., & Tsiatis, A. (2001). Causal inference on the difference of the restricted mean lifetime between two groups. Biometrics, 57, 1030–1038. [Google Scholar] [CrossRef]
- Chernozhukov, V., Fernández-Val, I., & Melly, B. (2013). Inference on counterfactual distributions. Econometrica, 81, 2205–2268. [Google Scholar] [CrossRef]
- Chiquiar, D., & Hanson, G. H. (2005). International migration, self-selection, and the distribution of wages: Evidence from Mexico and the United States. Journal of Political Economy, 113, 239–281. [Google Scholar] [CrossRef]
- Clayton, A. D. G. (1976). An odds ratio comparison for ordered categorical data with censored observations. Biometrika, 63, 405–408. [Google Scholar] [CrossRef]
- Cox, D. R. (1972). Regression models and life-tables. Journal of the Royal Statistical Society: Series B (Methodological), 34, 87–122. [Google Scholar]
- de Bresser, J. (2024). Evaluating the accuracy of counterfactuals: Heterogeneous survival expectations in a life cycle model. The Review of Economic Studies, 91(5), 2717–2743. [Google Scholar] [CrossRef]
- Delgado, M. A., García-Suaza, A., & Sant’Anna, P. H. C. (2022). Distribution regression in duration analysis: An application to unemployment spells. The Econometrics Journal, 25(3), 675–698. [Google Scholar] [CrossRef]
- DiNardo, J., Fortin, N. M., & Lemieux, T. (1996). Labor market institutions and the distribution of wages, 1973–1992: A semiparametric approach. Econometrica, 64(5), 1001–1044. [Google Scholar] [CrossRef]
- Donald, S., & Hsu, Y.-C. (2014). Estimation and inference for distribution functions and quantile functions in treatment effect models. Journal of Econometrics, 178, 383–397. [Google Scholar] [CrossRef]
- Du, F., & Dong, X.-Y. (2009). Why do women have longer durations of unemployment than men in post-restructuring urban China? Cambridge Journal of Economics, 33, 233–252. [Google Scholar] [CrossRef]
- Fortin, N., Lemieux, T., & Firpo, S. (2011). Decomposition methods in economics. In O. Ashenfelter, & D. Card (Eds.), Handbook of labor economics (Vol. 4, pp. 1–102). Elsevier. [Google Scholar]
- Freeman, R. B. (1980). Unionism and the dispersion of wages. ILR Review, 34, 3–23. [Google Scholar] [CrossRef]
- Guo, K., & Basse, G. (2021). The generalized Oaxaca-Blinder estimator. Journal of the American Statistical Association, 118(541), 524–536. [Google Scholar] [CrossRef]
- Györfi, L., Kohler, M., Krzyżak, A., & Walk, H. (2002). A distribution-free theory of nonparametric regression. Springer Series in Statistics. Springer. [Google Scholar]
- Ham, J., Svejnar, J., & Terrell, K. (1999). Women’s unemployment during transition: Evidence from Czech and Slovak micro-data. Economics of Transition, 7, 47–78. [Google Scholar] [CrossRef]
- Hausman, J. A., & Woutersen, T. (2014). Estimating the derivative function and counterfactuals in duration models with heterogeneity. Econometric Reviews, 33(1–4), 472–490. [Google Scholar] [CrossRef]
- Johnson, J. D. (1983). Sex differentials in unemployment rates: A case for no concern. Journal of Political Economy, 91, 293–303. [Google Scholar] [CrossRef]
- Juhn, C., Murphy, K. M., & Pierce, B. (1991). Accounting for the slowdown in black-white wage convergence. In M. H. Kosters (Ed.), Workers and their wages (pp. 107–143). American Enterprise Institute. [Google Scholar]
- Kalbfleisch, J., & Prentice, R. (1973). Marginal likelihoods based on Cox’s regression and life model. Biometrika, 60, 267–278. [Google Scholar] [CrossRef]
- Kaplan, E. L., & Meier, P. (1958). Nonparametric estimation from incomplete observations. Journal of the American Statistical Association, 53, 457–481. [Google Scholar] [CrossRef]
- Karrison, T. (1987). Restricted mean life with adjustment for covariates. Journal of the American Statistical Association, 82, 1169–1176. [Google Scholar] [CrossRef]
- Kitagawa, E. M. (1955). Components of a difference between two rates. Journal of the American Statistical Association, 50, 1168–1194. [Google Scholar] [PubMed]
- Kitagawa, E. M. (1964). Standardized comparisons in population research. Demography, 1, 296–315. [Google Scholar] [CrossRef]
- Kuhn, P., & Skuterud, M. (2004). Internet job search and unemployment durations. American Economic Review, 94, 218–232. [Google Scholar] [CrossRef]
- Lemieux, T. (2002). Decomposing changes in wage distributions: A unified approach. Canadian Journal of Economics, 35, 646–688. [Google Scholar] [CrossRef]
- Machado, J. A. F., & Mata, J. (2005). Counterfactual decomposition of changes in wage distributions using quantile regression. Journal of Applied Econometrics, 20, 445–465. [Google Scholar] [CrossRef]
- Melly, B. (2005). Decomposition of differences in distribution using quantile regression. Labour Economics, 12, 577–590. [Google Scholar] [CrossRef]
- Neison, F. (1844). On a method recently proposed for conducting inquiries into the comparative sanatory condition of various districts. Journal of the Statistical Society of London, 7, 40–68. [Google Scholar] [CrossRef]
- Neumark, D. (1988). Employers’ discriminatory behavior and the estimation of wage discrimination. Journal of Human Resources, 23, 279–295. [Google Scholar] [CrossRef]
- Niemi, B. (1974). The female-male differential in unemployment rates. ILR Review, 27, 331–350. [Google Scholar] [CrossRef]
- Oaxaca, R. L. (1973). Male-female wage differentials in urban labor markets. International Economic Review, 14, 693–709. [Google Scholar] [CrossRef]
- Oaxaca, R. L., & Ransom, M. R. (1999). Identification in detailed wage decompositions. The Review of Economics and Statistics, 81, 154–157. [Google Scholar] [CrossRef]
- Queneau, H., & Sen, A. (2007). Evidence regarding persistence in the gender unemployment gap based on the ratio of female to male unemployment rate. Economics Bulletin, 5, 1–10. [Google Scholar]
- Reimers, C. (1983). Labor market discrimination against Hispanic and Black men. The Review of Economics and Statistics, 65, 570–579. [Google Scholar] [CrossRef]
- Roed, K., & Zhang, T. (2003). Does unemployment compensation affect unemployment duration? The Economic Journal, 113, 190–206. [Google Scholar] [CrossRef]
- Rothe, C. (2015). Decomposing the composition effect: The role of covariates in determining between-group differences in economic outcomes. Journal of Business & Economic Statistics, 33(3), 323–337. [Google Scholar] [CrossRef]
- Schoenfeld, D. (1982). Partial residuals for the proportional hazards regression model. Biometrika, 69, 239–241. [Google Scholar] [CrossRef]
- Stock, J. H. (1989). Nonparametric policy analysis. Journal of the American Statistical Association, 84, 567–575. [Google Scholar] [CrossRef]
- Stone, C. J. (1980). Optimal rates of convergence for nonparametric estimators. The Annals of Statistics, 8(6), 1348–1360. [Google Scholar] [CrossRef]
- Stute, W. (1993). Consistent estimation under random censorship when covariables are present. Journal of Multivariate Analysis, 45, 89–103. [Google Scholar] [CrossRef]
- Stute, W., González-Manteiga, W., & Sánchez-Sellero, C. (2000). Nonparametric model checks in censored regression. Communications in Statistics—Theory and Methods, 29, 1611–1629. [Google Scholar] [CrossRef]
- Tansel, A., & Tasci, H. M. (2010). Hazard analysis of unemployment duration by gender in a developing country: The case of Turkey. Labour, 24, 501–530. [Google Scholar] [CrossRef]
- Tsiatis, A. A. (1981). A large sample study of Cox’s regression model. The Annals of Statistics, 9, 93–108. [Google Scholar] [CrossRef]
- Zhang, M., & Schaubel, D. E. (2011). Estimating differences in restricted mean lifetime using observational data subject to dependent censoring. Biometrics, 67, 740–749. [Google Scholar] [CrossRef] [PubMed]
- Zucker, D. M. (1998). Restricted mean life with covariates: Modification and extension of a useful survival analysis method. Journal of the American Statistical Association, 93, 702–709. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).