






Big Data Cogn. Comput. 2026, 10(6), 191; https://doi.org/10.3390/bdcc10060191 - 11 Jun 2026
Abstract
Foreign-exchange decisions rest on hierarchically organized evidence whose latent structure is inadequately captured by Euclidean representations. Reinforcement-learning agents trained on flat embeddings inherit stability guarantees that do not transfer to the manifold supporting the latent state. We address both limitations through a hybrid
[...] Read more.
Foreign-exchange decisions rest on hierarchically organized evidence whose latent structure is inadequately captured by Euclidean representations. Reinforcement-learning agents trained on flat embeddings inherit stability guarantees that do not transfer to the manifold supporting the latent state. We address both limitations through a hybrid architecture in which a schema-constrained structured chain-of-thought is embedded into a Poincaré ball, transported to a qubit register via angle encoding, and processed by an L-layer hardware-efficient variational ansatz on a state-vector backend. The circuit exposes two read-outs to the policy, namely, a scalar Pauli-Z observable and a projected quantum kernel inducing a fidelity-based similarity over magnet-price attractors, the latter identified via kernel-weighted recurrence density and finite-time Lyapunov statistics. The Lipschitz constraint on the action-value function is lifted from the hyperbolic geodesic distance to a joint metric on
(This article belongs to the Topic Artificial Intelligence Applications in Financial Technology, 2nd Edition)
►
Show Figures

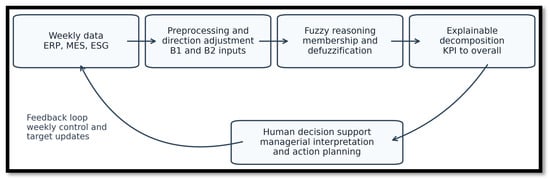
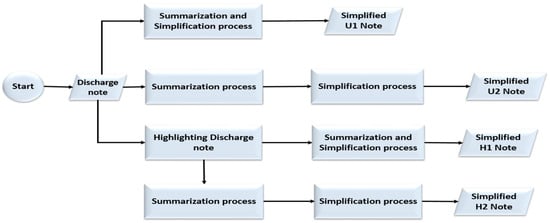
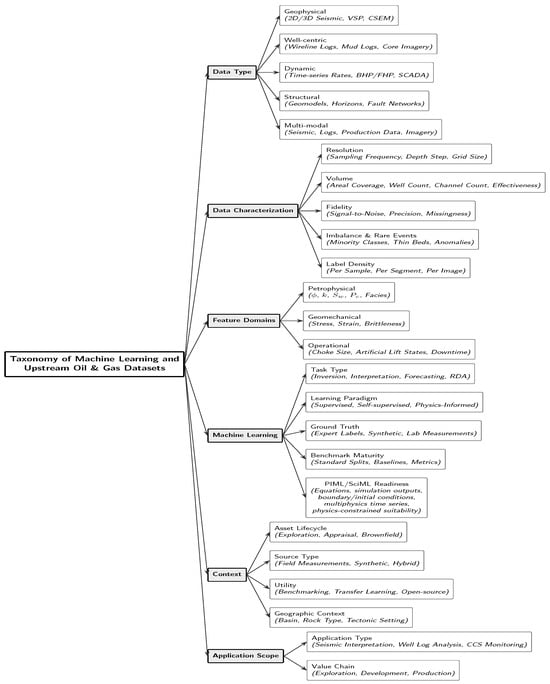
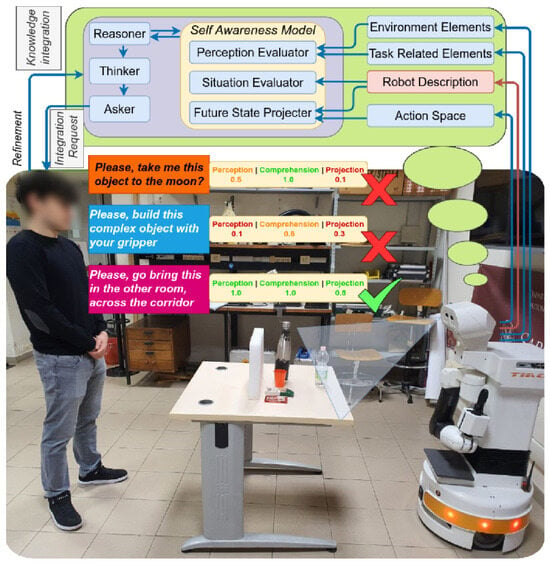
Figure 1





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}