Abstract
Target-oriented opinion words extraction (TOWE) is a novel subtask of aspect-based sentiment analysis (ABSA), which aims to extract opinion words corresponding to a given opinion target within a sentence. In recent years, neural networks have been widely used to solve this problem and have achieved competitive results. However, when faced with complex and long sentences, the existing methods struggle to accurately identify the semantic relationships between distant opinion targets and opinion words. This is primarily because they rely on literal distance, rather than semantic distance, to model the local context or opinion span of the opinion target. To address this issue, we propose a neural network model called DTOWE, which comprises (1) a global module using Inward-LSTM and Outward-LSTM to capture general sentence-level context, and (2) a local module that employs BiLSTM combined with DT-LCF to focus on target-specific opinion spans. DT-LCF is implemented in two ways: DT-LCF-Mask, which uses a binary mask to zero out non-local context beyond a dependency tree distance threshold, α, and DT-LCF-weight, which applies a dynamic weighted decay to downweigh distant context based on semantic distance. These mechanisms leverage dependency tree structures to measure semantic proximity, reducing the impact of irrelevant words and enhancing the accuracy of opinion span detection. Extensive experiments on four benchmark datasets demonstrate that DTOWE outperforms state-of-the-art models. Specifically, DT-LCF-Weight achieves F1-scores of 73.62% (14lap), 82.24% (14res), 75.35% (15res), and 83.83% (16res), with improvements of 2.63% to 3.44% over the previous state-of-the-art (SOTA) model, IOG. Ablation studies confirm that the dependency tree-based distance measurement and DT-LCF mechanism are critical to the model’s effectiveness, validating their ability to handle complex sentences and capture semantic dependencies between targets and opinion words.
1. Introduction
Aspect-level sentiment analysis (ABSA) [1,2,3,4,5] is a fine-grained sentiment analysis task within the Natural Language Processing (NLP) domain. It primarily encompasses sentiment classification, opinion target extraction, and opinion word extraction. Opinion targets, also known as aspect terms, are the words in a review sentence that represent entities about which users express attitudes. Opinion words are terms that clearly convey attitudes and opinions within a given sentence. Fan et al. introduced a novel ABSA sequence tagging task: target-oriented opinion words’ extraction (TOWE) [6]. In domains such as product reviews, opinion extraction fulfills critical practical needs, highlighting its urgency: consumers frequently express opinions about various aspects of a product (e.g., “The camera is amazing, but the battery life is poor”). Extracting opinion words associated with specific targets (e.g., “amazing” for “camera” and “poor” for “battery life”) allows businesses to identify strengths and weaknesses, thereby guiding product improvements.
The objective of the TOWE task is to identify opinion words that correspond to specified opinion targets within a sentence. For instance, in the review sentence “We ordered the special branzino at a posh Michelin restaurant, that was so infused with bone, it was unpalatable,” the phrases “branzino” and “Michelin restaurant” serve as the given opinion targets. TOWE is tasked with extracting “unpalatable” and “special” as the opinion word for the target “branzino” and “posh” for the target “Michelin restaurant”.
The neural network model has achieved competitive results, and distance information has been proven useful for most ABSA tasks [1,7]. However, the existing works have primarily focused on modeling the local context or the opinion span of the opinion target, which refers to the range of words that have a sentimental impact on the target, using only the literal distance between the target and the opinion words within the sentence, rather than their semantic distance. When dealing with complex and long sentences, the opinion span cannot be accurately captured. A dependency tree is a useful tool for modeling the syntactic structure of a sentence, thereby obtaining the semantic distance between words [8]. In the dependency tree, each word corresponds to a node, and two words with a dependency relationship are directly or indirectly connected. Semantic distance refers to the shortest path between nodes in the dependency tree. The paired opinion words and targets have a strong semantic relationship, which means their semantic distance in the dependency tree should be very close. Using semantic distance instead of literal distance can refine the local context of the opinion target and produce a more accurate distance measurement. For example, as shown in Figure 1, the distance between “unpalatable” and “branzino” is 16 in the sentence, but they are more closely connected in the dependency tree with a distance of 2, which provides a more concise and reasonable measurement.
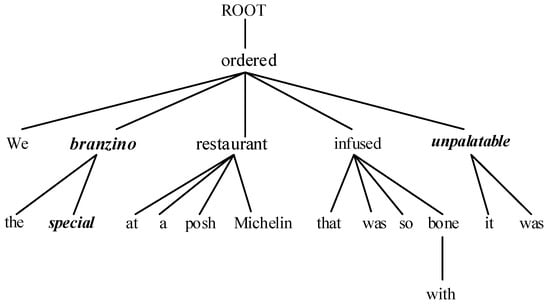
Figure 1.
A dependency tree for “We ordered the special branzino at a posh Michelin restaurant, that was so infused with bone, it was unpalatable”.
Given the success of deep-learning-based methods in sentiment analysis tasks and the superiority of dependency trees in capturing long-distance semantic relationships, we propose a neural network that incorporates dependency-tree-based distance measurement to address TOWE tasks. Our model is primarily divided into a global module and a local module. The global module captures a more general context representation for the entire sentence, whereas the local module concentrates on the local context surrounding the opinion targets.
Our contributions are as follows:
- We propose a novel neural network model, DTOWE, designed to address the TOWE task. This model is adept at processing complex and lengthy sentences.
- Additionally, we introduce a dependency-tree-based local context focusing mechanism, known as DT-LCF, along with two of its implementations: DT-LCF-Mask and DT-LCF-weight. These mechanisms effectively capture the opinion span of the targets under consideration.
- Experimental results across four datasets demonstrate that our model outperforms state-of-the-art models. Furthermore, an extensive analysis confirms the efficacy of our approach.
2. Related Works
ABSA mainly includes sentiment classification, opinion target extraction, and opinion word extraction. A lot of research has been conducted on the task of sentiment classification [1,2,3,4,5], but few people have paid attention to opinion target and opinion words extraction (TOWE). Traditional methods mainly include unsupervised/semi-supervised methods [8,9] and supervised methods [10,11]. With the ascent of neural networks, deep-learning-based data-driven models have made great progress in this task. Fan et al. [6] first explicitly introduced the TOWE task and released a benchmark corpus. They formulated it as a sequence-labeling task. Li et al. [12] designed two LSTMs with extended memory and neural memory operations to jointly process aspects and perspective extraction tasks through memory interaction. Wang et al. [13] used opinion summary and opinion target detection history for aspect extraction tasks. There are also some works that jointly extract opinion targets and opinion words in a unified model framework [8,12,14]. However, they mainly focused on the linear order of words and overlooked the rich syntactic structure information.
Recently, several works have also explored structural dependencies within a sentence to optimize the target opinion mining and ABSA tasks simultaneously. Zhang et al. [15] presents a convolution over a dependency tree model that exploits a Bi-LSTM to learn representations for features of a sentence and further enhances the embeddings with a graph convolutional network (GCN) that operates directly on the dependency tree of the sentence. Zhang et al. [16] introduced a dependency-enhanced graph convolutional network (D-GCN) to capture syntactic and semantic relationships between aspect terms and opinion words. Veyseh et al. [17] proposed to incorporate the syntactic structures of the sentences into the deep learning models for TOWE, leveraging the syntax-based opinion possibility scores and the syntactic connections between the words. These methods mainly leverage dependency trees as global structural features to enhance overall semantic representations, often through graph embedding to propagate syntactic relationships. We adopted a different perspective by using it as a tool to measure the semantic relationship between opinion words and opinion targets.
3. Proposed Model
In this section, we will provide a detailed introduction to our model: the dependency-tree-based target-oriented opinion words extraction model (DTOWE). We will specifically explain the task formulation, the model framework, the global context feature extraction module, the local context feature extraction module, and the final decoding and training components.
3.1. Task Formulation
The goal of the TOWE task is to extract corresponding opinion words from a review sentence, which can be viewed as a sequence-labeling problem. Specifically, for a review sentence consisting of n words s, and the opinion target , where and represent the starting and ending position of the target respectively, our goal is to label each word in the review sentence with (B: beginning; I: inside; O: others), where the labels B and I mean the beginning and inside part of the opinion words, and O represents irrelevant words. For instance, as illustrated in Table 1, we employ for sequence labeling. When the opinion target is “branzino”, the corresponding opinion word are annotated as “unpalatable/B” and “special/B”; when the opinion target is “Michelin restaurant”, the corresponding opinion word is “posh”; when the opinion target is “pizza”, the corresponding opinion words are “healthy/B” and “full/B of/I flavor/I”.

Table 1.
TOWE annotated data instance.
3.2. Framework
To deal with the complex and long sentences in the TOWE task, we propose a neural network model called DTOWE, as shown in Figure 2. The model consists of a global context feature extraction module (global module for short) on the left, a local context feature extraction module (local module for short) on the right, and a feature fusion layer on the top. The global module aims to obtain a more general context representation for the whole sentence, and it draws on the idea of TD-LSTM [7], which contains an inward-LSTM layer and an outward-LSTM layer, and the two LSTM layers are merged together to obtain the global context features. The local module focuses more on the surrounding words of the opinion target so as to generate a more concise local context representation. To enhance the learning of local context features, we develope a dependency-tree-based local context focusing mechanism (DT-LCF), and we introduce an attention layer to accurately identify the opinion span. The local module is initialized with BiLSTM, and then passed to the proposed DT-LCF and attention layers. Finally, the feature fusion layer fuses the global and local context features and generates a final prediction.
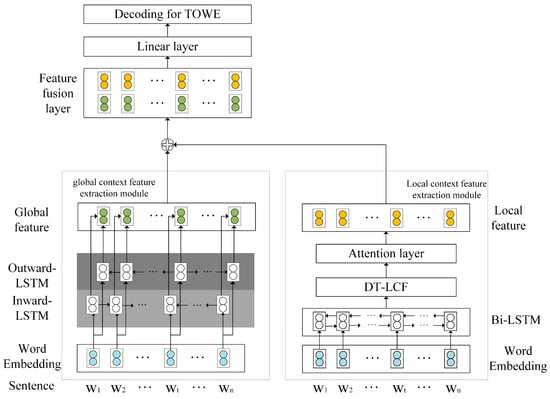
Figure 2.
Architecture of DTOWE.
3.3. Global Context Feature Extraction
The semantics of the whole sentence provides a more general context for the opinion targets inside; meanwhile, the target and the context have a mutual influence to each other. Therefore, we model this bidirectional interaction through an Inward-LSTM and an Outward-LSTM and their combination to capture the global semantics conveyed by the whole sentence.
3.3.1. Inward-LSTM
As shown in Figure 2, the Inward-LSTM layer features two LSTMs running from both ends of the sentence to the opinion target. The direction of the arrow indicates the running direction of the LSTM. This is a process of passing contextual information to the target. The left side and right side of Inward-LSTM are defined as follows:
where and represent the left-side and right-side context representations, respectively. represents the word embedding of word .
When performing Inward-LSTM, the opinion target is processed twice, so we get the representation of the target by averaging the representations from both sides as follows:
Inward features for the whole sentence are as follows: .
The algorithm for processing Inward-LSTM is shown as Algorithm 1.
| Algorithm 1: Inward-LSTM for the ith layer. |
//LSTM calculation |
3.3.2. Outward-LSTM
Likewise, the Outward-LSTM layer has two LSTMs running from the target to both ends of the sentence. This is a process of passing target features to the context. The left side, right side, and the final representations of Outward-LSTM are defined as follows:
Outward features for the whole sentence are as follows: .
The algorithm for processing Inward Outward-LSTM is shown as Algorithm 2:
| Algorithm 2: Outward-LSTM for the ith Layer. |
3.3.3. IO-LSTM
The Inward-LSTM and Outward-LSTM are transferring representations in opposite directions, and the two strategies can be combined to complement each other and form an IO-LSTM as a final global contextual representation, which is the concatenation of the two vectors defined as follows:
3.4. Local Context Feature Extraction
The global module is designed to extract sentence-level features, but it does not highlight the opinion span of the target. Consequently, we have developed the local module and introduced a novel type of local context focusing mechanism based on the dependency tree, which can describe the semantic relations between the target and opinion words and provides a more accurate distance measurement. As shown in Figure 2, the local module mainly includes BiLSTM, DT-LCF, and an attention layer.
3.4.1. BiLSTM
In the global module, the Inward-LSTM and Outward-LSTM divide the entire sentence into three parts: the left-side context, the right-side context, and the opinion target, resulting in non-continuous representations for the sentence. To address this issue, in the local module, we use a continuous BiLSTM to initialize the sentence embedding, which is defined as follows:
3.4.2. DT-LCF
Introducing word distances is effective for most NLP tasks. However, previous models have primarily been based on simple literal distances, rather than semantic distances, and they often overlook the situation where, in complex long sentences, the opinion target is frequently far removed from the opinion word. Measuring the semantic distance in a sentence is crucial for defining the opinion span of a target. A dependency tree can offer assistance in this regard.
A dependency tree is a graph in which nodes represent words in the sentence, and edges indicate syntactic dependencies (e.g., subject–verb and modifier–head relationships) between words, as parsed from the sentence. Given a dependency tree, the semantic distance from a word to the target can be defined as the length of the shortest path that connects them, denoted as SRD. As SRD increases, the words are less semantically related.
To extract local context based on the dependency tree, we propose a new local context focusing mechanism called DT-LCF, and provide two of its implementations: DT-LCF with dynamic masking (DT-LCF-Mask) and DT-LCF with dynamic weighted decay (DT-LCF-Weight).
- DT-LCF-Mask
In the DT-LCF-Mask layer, a distance threshold, α, is used to mask the non-local context of the opinion target, setting it to a zero vector, while the local context is emphasized with its features remaining intact, as shown in Figure 3.
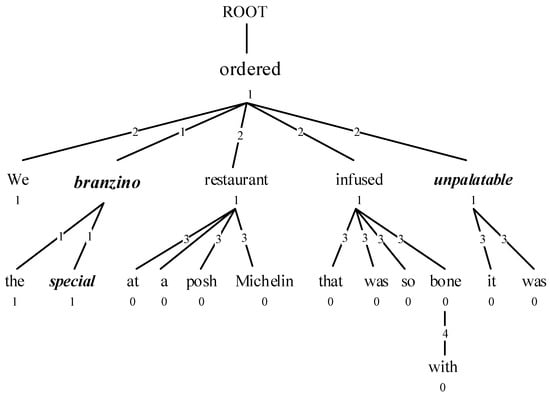
Figure 3.
Illustration of the DT-LCF-Mask. The numbers on the edges indicate the distance to the opinion target, and the numbers beneath the words denote whether these words are within the local context of the opinion target. If the distance threshold α is set to 2, non-local contexts with a distance exceeding 2 from the opinion target will be masked by zero vectors, labeled as 0 in the tree, whereas local contexts are labeled as 1.
In the mask layer, we employ a mask vector to cover up the non-local context, while using the unit vector E to preserve the local context, as illustrated in Equations (11)–(13):
where is the unit vector and is the zero vector, SRD represents the distance from the current word to the opinion target in the dependency tree, and α represents the distance threshold for local context. The mask vector can be represented as (11), where is used to mask non-local context, while is used to retain local context. The mask vectors form the mask matrix shown in (12), and the input features have been transformed into through the DT-LCF-Mask layer as shown in (13).
The algorithm for DT-LCF-mask is shown as Algorithm 3:
| Algorithm 3: DT-LCF-mask |
at each position |
- DT-LCF-Weight
In DT-LCF-Mask, we cover all non-local contexts directly, which may result in information loss for weakly dependent nodes. Consequently, we propose a gentler approach named DT-LCF-Weight, which utilizes a dynamic weighted decay strategy based on word distances within the dependency tree. This ensures that the farther a word is, the less its impact on the opinion target, as depicted in Figure 4.
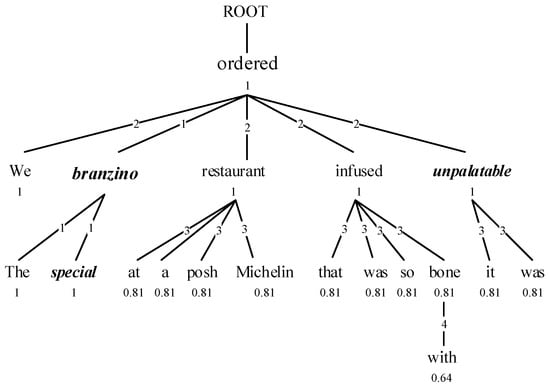
Figure 4.
Illustration of DT-LCF-Weight. The numbers on the edges represent the distances to the target. The number beneath each word indicates its weight, which signifies its influence on the opinion target, as calculated by Formula (14). Therefore, the word “posh” is less influential to the target word “branzino” than the word “unpalatable”.
In DT-LCF-Weight, we utilize a decay vector, , to represent the diminishing influences from a word to the target, as illustrated in Equations (14)–(16):
where SRD and have the same meaning as in (11), the unit vector is used to preserve local context, is the length of the sentence, r is a hyperparameter that controls the decaying rate, a high-order decay function may make the impact more sensitive to the distance. The decay vectors form the decay matrix shown in (15), and the input features has been transformed into through the DT-LCF-Weight layer as depicted in Equation (16).
The algorithm for DT-LCF-weight is shown as Algorithm 4:
| Algorithm 4: DT-LCF-weight |
at each position |
3.4.3. Attention Mechanism
After obtaining or through the DT-LCF layer, we introduce an attention layer to strengthen the weight of possible emotional words. The attention score is defined as follows:
where represents the embedding dimension of the word, is the hidden state of the opinion target after BiLSTM processing, represents or , and S represents the attention score. The final representation from the local module is defined as follows:
3.5. Feature Fusion
To obtain more comprehensive semantic information from the model, we fuse local context representations with global context representations through a concatenation operation in the Feature Fusion Layer to achieve a hybrid representation , as shown in (19).
3.6. Decoding and Training
Target-oriented opinion word extraction is a sequence-labeling task. The input of the model is a review sentence, which, after being processed by the global and local modules, yields the high-order sentence representation HLG. HLG is then passed to the decoding module to generate the final label. The process can be formulated using , where (B: Beginning; I: Inside; O: Others) is the emotional label for each word. We employ softmax-based greedy decoding and treats each word position as a three-way classification task to find the most likely label, as shown in (20):
where represents the probability of each candidate tag at the -th position. is the weight matrix and is the bias vector.
Greedy decoding selects the label with the highest probability at each position. During decoding, the relationship between words is not considered, which allows for very fast operation. We train the model using the cross-entropy loss function.
where represents the word at the -th position. is the indicator function.
4. Experimental Results and Analysis
4.1. Experiment Environments
Table 2.
The software environment.
Table 3.
Hardware environment.
4.2. Data Sets
To evaluate the generalization of the proposed DTOWE model, we selected four widely recognized benchmark data sets from the aspect-level sentiment analysis (ABSA) domain [6]. Data sets 14res and 14lap originate from the SemEval Challenge 2014, Task 4, while 15res and 16res are from the SemEval Challenges of 2015 and 2016, respectively [18,19,20]. They extend the 14res data set with more complex sentences and additional annotations for implicit opinion targets. The data sets cover two distinct domains—restaurants and laptops—allowing us to assess model performance across different linguistic contexts and cross-domain stability. All data sets include explicit annotations for both opinion targets and their corresponding opinion words. The suffixes “res” and “lap” denote the restaurant data set and the laptop data set, respectively. The data sets are summarized in Table 4. A review sentence may contain multiple opinion targets.
Table 4.
Summary of benchmark dataset. # means number and mention in the text.
Additionally, we have analyzed the literal and semantic distances from opinion and non-opinion words to the opinion target in each data set. Specifically, we define two concepts, relative literal distance (RLD) and relative semantic distance (RSD), to represent the distances from words to the target, with and without considering the dependency tree. This approach helps to mitigate the impact of varying sentence lengths. The computation of RLD and RSD is as follows:
where A and B are word sets which can be opinion words, non-opinion words or opinion target, i and j are elements belonging to A and B, and denote the literal positions of i and j within the sentence, means the size of sets A and B, n is the length of the sentence, denotes the semantic distance between i and j within the sentence’s dependency tree, with m indicating the depth of the dependency tree.
From Table 5, it is evident that the differentiation between option words and non-opinion words is less pronounced when employing literal distance compared to when using dependency tree-based semantic distance. This observation underscores the rationale behind utilizing dependency trees to model semantic relationships.
Table 5.
Summary of benchmark data set data.
4.3. Settings
In our model, we initialize word embeddings using 300-dimensional GloVe vectors [21] and set the hidden state dimension of the LSTM unit to be 200. We employ cross-validation to train the model, randomly allocating 20% of the data set as the development set for hyperparameter tuning and early stopping. The model is run five times to record the best results. The Adam [22] optimization method is used. To prevent overfitting, the L2 regularization parameter is set to 10−5 the dropout probability is set to 0.1, and the learning rate is set to 10−3. The threshold, , and the high-order distance decay factor, , in the local module are both set to five different values, i.e., {1,2,3,4,5}. We use StanfordCoreNLP [23] to construct syntactic dependency trees. This is a renowned NLP toolkit from Stanford University that supports fundamental NLP tasks such as tokenization, part-of-speech tagging, and the construction of syntactic dependency trees.
4.4. Evaluation Metrics
We use precision(P), recall(R), and the F1-score(F1) as evaluation metrics to compare the performance of our model with that of other works. Precision refers to the proportion of correct opinion words among all predicted opinion words, while recall refers to the proportion of correctly identified opinion words out of all opinion words. The F1-score is the harmonic mean of precision and recall, representing the model’s overall performance, as indicated in Equations (24)–(26).
where TP represents the number of successful positive predictions; FP represents the number of negative instances, which are incorrectly predicted as the positive label; FN represents the number of positive instances, which are incorrectly predicted as the negative label.
4.5. Compared Methods
In the experiments, we compared the proposed method with seven baseline methods:
- Distance-rule [9]. This is an early model that relies on distance rules and part-of-speech (POS) tags, selecting the nearest adjective words to the opinion target as the corresponding opinion words.
- Dependency-rule [24]. This model employs dependency-tree-based templates to identify opinion pairs. It records the part-of-speech (POS) tags of the opinion targets and opinion words, as well as the dependency path between them in the training set, as rule templates. The dependency templates that occur with high frequency are utilized for detecting the corresponding opinion words in the testing set.
- LSTM/BiLSTM [25]. This model is designed for extracting aspect–opinion pairs at the sentence level. It begins by initializing with word embeddings within the sentence, which are then fed through an LSTM/BiLSTM layer to create sentence representations. The softmax layer classifies the hidden state at each position into three categories.
- Pipeline [6]. This is an aspect-level opinion extraction model. It combines BiLSTM with distance rules to select the nearest adjectives as the target opinion words.
- Target-Concatenated BiLSTM (TC-BiLSTM) [26]. This method integrates target information into sentences through concatenation. A target vector is derived from the average pooling of target word embeddings. The word representation at each position is the concatenation of the word embedding and the target vector, which is subsequently fed into a BiLSTM for sequence labeling.
- PE-BiLSTM [14]. This model integrates position embeddings into the TOWE task, and then extracts opinion words through BiLSTM.
- IOG [6]. This is the first work to propose the TOWE task. It utilizes six distinct positional and directional LSTMs to extract opinion words. This model achieves state-of-the-art performance.
4.6. Results and Discussion
The main experiment results are shown in Table 6. All the methods in the table use greedy decoding.
Table 6.
Main experiment results (%). The best results are indicated in bold (precision, recall, and F1-score; larger values denote better performance).
As shown in Table 3, our proposed models, DTOWE-Mask and DTOWE-Weight, outperform other methods across all data sets. The overall performance of all methods on 14lap and 15res is less effective than on 14res and 16res, which can largely be attributed to the relatively smaller data set size, potentially causing overfitting and robustness issues. Among all the models compared, the rule-based method performs poorly, with particularly low recall. This is because the distance-rule method simply extracts the closest single word as the opinion word, which is only suitable for simple sentences. The dependency-rule-based method shows some improvement, but it still lags behind deep-learning-based methods.
Compared with other neural network models, LSTM and BiLSTM perform poorly because they do not highlight localized opinion spans for the opinion target. They extract the same opinion span for different targets within a sentence. Pipeline, which is based on BiLSTM, selects the nearest adjective as the target opinion, essentially selecting different opinion spans for different opinion targets and thus achieving better results than the basic BiLSTM. In TC-LSTM, the target information is embedded at each position and passed to BiLSTM for processing. The recall is improved, but the precision is reduced, indicating that the target embedding method is not suitable for this task. The PE-BiLSTM model incorporates target information into TOWE through position embedding. Although the model is simple, it achieves high precision. The F1-score achieves a 5.12% improvement over BiLSTM, indicating that position information can be effectively used in TOWE tasks to identify the opinion span. IOG is the state-of-the-art model, which uses six different positional and directional LSTMs to obtain rich representations for the sentence and its contexts.
While previous position-based models have yielded satisfactory results, they rely on absolute positioning or direct distance calculations, neglecting the crucial factor in determining the opinion span for the TOWE task: the semantic relationships between words. These relationships can be effectively modeled using a dependency tree. Our model, DTOWE, utilizes dependency-tree-based distance measurements to address these shortcomings. It offers two implementations: DTOWE-Mask and DTOWE-Weight. The results in Table 6 demonstrate that our model achieves the best performance across the four data sets, with DTOWE-Weight slightly outperforming DTOWE-Mask. Both versions achieve approximately a 2% to 3% improvement in F1-score compared to IOG. Specifically, the F1-score of DTOWE-Weight has increased by 3.70%, 2.51%, 4.78%, and 2.73% on the data sets 14lap, 14res, 15res, and 16res, respectively. These findings indicate that our model is capable of effectively handling complex and lengthy sentences in the TOWE task.
4.7. Ablation Study
We investigate and report five typical ablation conditions, and the results are shown in Table 7.
Table 7.
Ablation studies of DTOWE (%).
- DTOWE-without-Local: denotes that we remove the Local Module and use only the Global Module.
- DTOWE-without-DT-LCF: denotes that we remove the dependency-tree-based local context focusing mechanism.
- DTOWE-Mask-without-Attention: denotes that we remove the attention mechanism when we use DT-LCF-Mask.
- DTOWE-Weight-without-Attention: denotes that we remove the attention mechanism when we use DT-LCF-Weight.
- DTOWE-Literal-Distance: denotes that we remove DT-LCF module and use the literal distance instead of the semantic distance.
As indicated in Table 7, DTOWE-without-Local performs the least effectively compared to other models, as the global module alone cannot efficiently capture the opinion span of the target. Experimental outcomes based on DTOWE-without-DT-LCF demonstrate that DT-LCF contributes positively to the model’s performance. The effectiveness of the attention mechanism is confirmed through the results of DTOWE-Mask-without-Attention and DTOWE-Weight-without-Attention. DTOWE-Literal-Distance utilizes literal distance instead of the semantic distance provided via DT-LCF. We observe that the results from the last three configurations are inferior to those of DTOWE-Mask and DTOWE-Weight, which underscores the importance of semantic distance information over literal distance in the TOWE task and confirms that DT-LCF can effectively capture the opinion span of the target.
4.8. Error Propagation for Dependency Tree
The proposed DTOWE model significantly depends on the accuracy of dependency tree parsing; an incorrect dependency tree can propagate errors to downstream tasks, such as the local context focusing mechanism. We examined all testing data across four data sets to classify the reasons for errors, and the findings are presented in Table 8. The numbers indicate the proportion of cases where the correctness of the dependency trees deviates from the prediction outcomes.
Table 8.
Error propagation for dependency.
As indicated in Table 8, when the dependency is parsed incorrectly, approximately 20.13% of the cases yield correct DTOWE-Mask-based predictions, which is lower than the 28.18% of cases that implement DTOWE-Weight. These figures suggest that dependency errors can propagate to downstream tasks. Nevertheless, there are instances where correct predictions are still generated, primarily because a global module assists in producing accurate outcomes. Additionally, DTOWE-Weight can somewhat mitigate the intensity of the local focusing mechanism, which in turn helps to achieve better results.
For correctly parsed dependency trees, most predictions are accurate. However, DTOWE-Mask performs less effectively than DTOWE-Weight due to its strict local context masking mechanism. Regarding the cases where predictions are incorrect, there are several contributing factors.
4.9. Hyper-Parameter Sensitivity on Different Datasets
First, we conducted an experiment to analyze the impact of different α values on various data sets. We set different thresholds in DT-LCF-Mask, with α = {1,2,3,4,5}, to distinguish between local and non-local contexts. The results are presented in Figure 5.
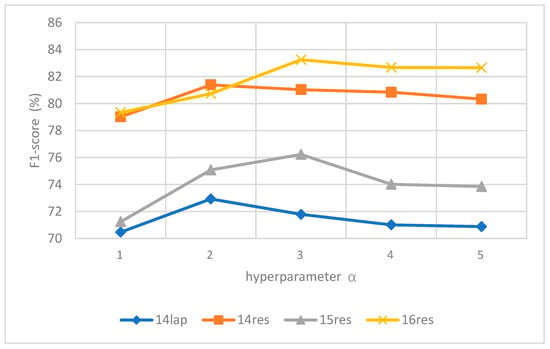
Figure 5.
The influence of local context threshold α for data sets in DT-LCF-Mask.
From Figure 5, it is evident that DT-LCF-Mask is highly sensitive to the parameter α. Different data sets have distinct optimal α values, and performance significantly diminishes when α deviates from these optimal values (for instance, α = 2 for the 14lap data set). A smaller α (α = 1) truncates crucial local context, while a larger α (α = 4) introduces noise, thereby reducing precision. This sensitivity occurs because masking constitutes a hard cutoff, allowing no margin for gradual adjustment.
Secondly, we examine the effects of varying α and γ on different data sets. We set α to the optimal values determined for each dataset by DT-LCF-Mask, specifically α = {2,3}. Subsequently, we vary γ from 1 to 5 in DT-LCF-Weight to assess the sensitivities of the combined effects of α and γ. The results are depicted in Figure 6.
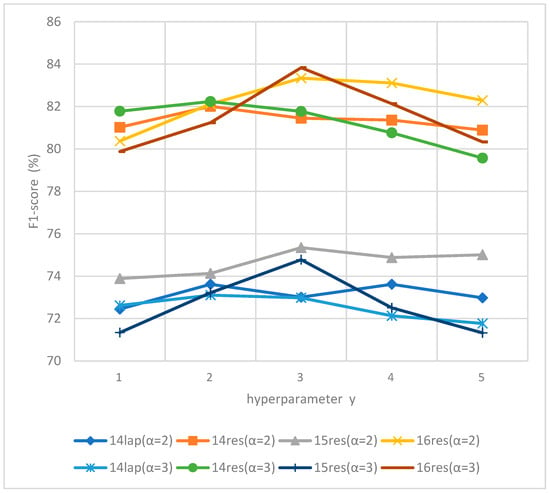
Figure 6.
The influence of local context threshold α and decay rate γ for data sets in DT-LCF-Weight.
In addition to the impact of α, which is similar to that in DT-LCF-Mask, DT-LCF-Weight is also influenced by the decay rate γ. As illustrated in Figure 6, different data sets have different optimal γ values. Performance significantly decreases when γ deviates from the optimal value (for example, γ = 2 for 14lap). A smaller γ (γ = 1) fails to effectively differentiate local context; a larger γ (γ = 4) causes DT-LCF-Weight to regress to DT-LCF-Mask.
4.10. Training Complexity
The computational complexities of the two mechanisms differ due to their distinct processing of local context features; the results are shown in Table 9.
Table 9.
Training complexity for DTOWE-Mask and DTOWE-Weight.
DT-LCF-Mask utilizes a binary mask matrix to directly eliminate non-local context features that exceed the threshold, α. This process involves straightforward element-wise multiplication, which leads to reduced computational overhead per iteration. In actual application, DT-LCF-Mask achieves convergence approximately 15–20% quicker than DT-LCF-Weight, as evidenced by repeated experiments (5 runs) across all four data sets. DT-LCF-Weight incorporates a dynamic decay matrix that employs distance-dependent weight calculations. This method adds extra arithmetic operations, such as exponentiation and scaling for each word, which increases the complexity per iteration and requires a greater number of epochs to reach convergence.
4.11. Cross-Domain Performance Analysis
The four data sets utilized in this paper are domain-specific: one from the laptop domain (14lap) and three from the restaurant domain (14res, 15res, 16res). To evaluate in-domain and cross-domain transferability, we designed two key scenarios:
1. Training on the 14res dataset and testing on the 14top, 15res, and 16res datasets, which encompasses both cross-domain (restaurant→laptop) and in-domain (restaurant→-restaurant) transfers.
2. Training on the 14lap dataset and testing on the 14res, 15res, and 16res datasets, primarily covering cross-domain (laptop→-restaurant) transfer.
We only executed DTOWE-Weight and retained the same metrics (precision, recall, and F1-score) for cross-domain evaluation. The results are presented in Table 10, where A-B signifies that A is the training data set and B is the testing data set. Cross-domain results are shaded.
Table 10.
Cross-domain performance among different datasets.
As indicated in Table 10, when transferring the model across various domains, performance does indeed suffer due to significant differences in the usage of words and expressions for opinion targets across different domains. (With training and testing conducted on pairs such as 14lap-14les, 14res-14lap, 14lap-15res, and 14res-15lap, the results are inferior to the original outcomes.) Additionally, employing a larger data set may mitigate this issue (as evidenced by the 14res-14lap pair performing better than 14lap-14res).
4.12. Case Study
To evaluate our model more intuitively, we selected several examples from the data sets and analyzed the extracted opinion words from different models, as shown in Table 11. Here, the targets are labeled in blue and bold, while the correct option words are labeled in red and italicized.
Table 11.
Examples of successfully extracted option words.
In the first example, Distance-rule-based models fail to extract the opinion phrase for the given opinion target, resulting in incorrect extraction. The BiLSTM method processes the entire sentence to obtain features without emphasizing the opinion span of the opinion target. However, when different opinion targets within a sentence share the same opinion span, it may lead to errors, such as the confusion in the second sentence. The third example demonstrates that merely selecting the nearest adjective using Distance-rule-based approaches cannot encompass all cases. In the last two complex and long sentences, the state-of-the-art model IOG makes incorrect predictions, whereas our proposed models, DTOWE-Mask and DTOWE-Weight, successfully extract target-dependent opinion words. The results indicate that our models can effectively capture the opinion span of the opinion target and can better handle complex and long sentences.
The cases of failed opinion word extraction are presented in Table 12 all of which exhibit complex sentence structures and unclear boundaries for opinion targets and opinion words.
Table 12.
Examples of failed extraction of opinion words.
5. Conclusions and Future Works
In this paper, we present a novel neural network model, DTOWE, designed to address the task of target-oriented opinion words extraction. This model incorporates a dependency tree to establish a local context focusing mechanism, enabling it to effectively capture the opinion spans associated with the opinion targets. The model has achieved state-of-the-art performance on four benchmark datasets.
In future work, we hope to pass the information captured via TOWE to downstream tasks such as sentiment classification to construct a multi-task model. Additionally, the data sets are small, which severely limits the performance of the model; therefore, we consider expanding the data sets to enhance the performance of the model.
Author Contributions
Conceptualization, Y.W. and E.Y.; methodology, Y.W. and E.Y.; software, J.Q. and L.C.; validation, Y.C.; formal analysis, S.L.; investigation, Y.C.; data curation, S.L.; writing—original draft preparation, E.Y.; writing—review and editing, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key Research and Development Program of China (No.2022ZD0119501); National Natural Science Foundation of China (No.52374221); Natural Science Foundation of Shandong Province (ZR2022MF288, ZR2023MF097); Education Ministry Humanities and Social Science Research Planning Fund Project of China (23YJAZH192).
Data Availability Statement
The data sets used to support the findings of this study are openly available at https://github.com/NJUNLP/TOWE/tree/master/data (accessed on 1 December 2024).
Conflicts of Interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
References
- Huang, B.; Guo, R.; Zhu, Y.; Fang, Z.; Zeng, G.; Liu, J.; Wang, Y.; Fujita, H.; Shi, Z. Aspect-level sentiment analysis with aspect-specific context position information. Knowl. Based Syst. 2022, 243, 108473. [Google Scholar] [CrossRef]
- Jiang, L.; Li, Y.; Liao, J.; Zou, Z.; Jiang, C. Research on non-dependent aspect-level sentiment analysis. Knowl. Based Syst. 2023, 266, 110419. [Google Scholar] [CrossRef]
- Shang, W.; Chai, J.; Cao, J.; Lei, X.; Zhu, H.; Fan, Y.; Ding, W. Aspect-level sentiment analysis based on aspect-sentence graph convolution network. Inf. Fusion 2024, 104, 102143. [Google Scholar] [CrossRef]
- Liu, N.; Zhao, J. A BERT-based aspect-level sentiment analysis algorithm for cross-domain text. Comput. Intell. Neurosci. 2022, 2022, 8726621. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Xu, L.; Bing, L.; Huang, F.; Lu, W.; Si, L. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8600–8607. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, Z.; Dai, X.; Huang, S.; Chen, J. Target-oriented opinion words extraction with target-fused neural sequence labelling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–6 June 2019; Volume 1, pp. 2509–2518. [Google Scholar]
- Yang, H.; Zeng, B.; Yang, J.; Song, W.; Xu, R. A multi-task learning model for China-oriented aspect polarity classification and aspect term extraction. Neurocomputing 2021, 419, 344–356. [Google Scholar] [CrossRef]
- Liu, K.; Xu, H.L.; Liu, Y.; Zhao, J. Opinion target extraction using partially-supervised word alignment model. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Qiu, G.; Liu, B.; Bu, J.; Chen, C. Opinion word expansion and target extraction through double propagation. Comput. Linguist. 2011, 37, 9–27. [Google Scholar] [CrossRef]
- Li, X.; Lam, W. Deep multi-task learning for aspect term extraction with memory interaction. In Proceedings of the 2017 Con-Ference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2886–2892. [Google Scholar]
- Li, X.; Bing, L.; Li, P.; Lam, W.; Yang, Z. Aspect term extraction with history attention and selective transformation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 12–19 July 2018. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Wu, Z.; Zhao, F.; Dai, X.Y.; Huang, S.; Chen, J. Latent opinions transfer network for target-oriented opinion words extraction. Proc. AAAI Conf. Artif. Intell. 2020, 34, 9298–9305. [Google Scholar] [CrossRef]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-level sentiment analysis via convolution over dependency tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5679–5688. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect Sentiment Pair Extraction with Dependency-Enhanced Graph Convolutional Net-works. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 1234–1245. [Google Scholar]
- Veyseh, A.P.B.; Nouri, N.; Dernoncourt, F.; Dou, D.; Nguyen, T.H. Introducing syntactic structures into target opinion word extraction with deep learning. arXiv 2020, arXiv:2010.13378. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. Semeval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 27–35. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Al-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; Clercq, O.D.; et al. SemEval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MA, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Zhuang, L.; Jing, F.; Zhu, X.Y. Movie review mining and summarization. In Proceedings of the 15th ACM International Confer-Ence on Information and Knowledge Management, Arlington, VA, USA, 6–11 November 2006; pp. 43–50. [Google Scholar]
- Liu, P.; Joty, S.; Meng, H. Fine-grained Opinion Mining with Recurrent Neural Networks and Word Embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for target-dependent sentiment classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).