
State of the Art and Future Directions of Small Language Models: A Systematic Review



Abstract
1. Introduction
- Section 2—Methodology for the SLR illustrates the study design, the criteria adopted for the selection of publications, and the metrics used to ensure the reproducibility of the research.
- Section 3—Small Language Model background overview delves into the theoretical and practical bases of such models, highlighting the differences with respect to Large Language Models and the attributes that characterize them.
- Section 4, Section 5, Section 6 and Section 7—Discussions about research questions focus on the discussions and answers to the research questions posed, critically analyzing the results obtained. In this section, the most common concepts present in the state of the art will be described and explained based on the topic covered.
- Section 8—Future directions and new solutions for SLM challenges provide an overview of future SLM development by examining emerging strategies designed to address the challenges identified in Research Question 4.
- Section 9—Limitations of the study evaluate the scope and potential biases of our review—parameter-count thresholds, English-language restriction, and database coverage, while suggesting concrete ways future reviews can expand coverage.
- Section 10—Conclusions close the paper by synthesizing the main findings and providing clear, actionable insights for researchers.
2. Methodology for the Systematic Literature Review
2.1. Inclusion and Exclusion Criteria
2.2. Selection Process
| Listing 1. Database search query used in the SLR for Scopus, IEEE Xplore, Web of Science, and ACM Digital Library. |
| "small language model*" OR "tiny language model*" OR "compact language model*" OR "lightweight language model*" OR "efficient language model*" OR "mobile language model*" OR "low-resource language model*" OR "reduced-size language model*" OR "edge language model*" OR "compressed language model*" |
- Database search: An initial automated filtering step was performed to manage the large volume of records and prepare the corpus for manual review. Using the filtering tools available in each database, we automatically removed non-English papers and those not published between January 2023 and January 2025. The remaining papers from each of the four databases were then imported into a spreadsheet file. A total of 706 records were identified: 335 from Scopus, 121 from IEEE, 115 from ACM Digital Library, and 135 from Web of Science.
- Duplicate removal: Duplicate records were identified and removed. A total of 381 records were removed before screening.
- Title and Abstract Screening: The screening of titles and abstracts was conducted manually by two independent reviewers (M.P. and M.L.) without any automation tools to assess each record against the inclusion criteria in Section 2.1. Although more labor-intensive, this consensus-based approach aligns with PRISMA 2020 and minimizes the risk of biases. It also improves the trustworthiness of the review’s findings, especially for novel topics, where AI screeners can miss relevant papers [15,17,18].A formal consensus protocol was used to ensure consistency and reliability throughout the study: any discrepancies between the reviewers regarding study eligibility were resolved through a discussion meeting, and if a consensus could not be reached, a third author (F.C.) made the final determination. This initial screening resulted in the exclusion of 270 records, primarily because they were out of scope, published outside the specified date range, or focused on models larger than 7 billion parameters.
- Full-text Screening and Snowballing: For the articles that passed the initial screening, the full texts were retrieved for a final validation of their eligibility. This step ensured that each study met all inclusion criteria. The same consensus protocol described above was applied to this final assessment. To ensure comprehensive coverage, we then applied the Snowball technique to this set. This involved examining the citation lists to identify additional relevant studies for each included article that met our initial criteria. This supplementary search identified an additional 15 articles, which completes the final selection for the review. Although no additional papers were excluded at this stage, full-text screening was essential to confirm eligibility and to allow comprehensive data extraction for subsequent analysis.
- Data extraction: To systematically address our research questions, we performed a structured data extraction from each included study. Using a predefined spreadsheet with columns for model name, parameter size, architecture, application domain, benchmarks used, optimization techniques, etc., reviewers manually entered the relevant information during the full-text review stage. This curated dataset was then analyzed using a Python script to generate the statistics and visualizations presented in this review. The list of papers is shown in Table A1 and in our Codeberg repository List of papers extracted: https://codeberg.org/matteo_unicam/SLR_SLMs/src/branch/main/paper_list.md, (accessed on 15 July 2025). The following are the research questions that guide this study:
- (a)
- What are the types of papers, applications, and public availability related to Small Language Models?
- (b)
- What are the most prevalent architectures and their associated compression and optimization methods in current research?
- (c)
- What are the most common benchmarks?
- (d)
- What are the current challenging areas?
2.3. Paper Overview
- Model-focused publications: These papers introduce a new SLM or a significant modification to an existing model. They typically include details about the model architecture, the training process, and initial evaluation results.
- Method-focused publications: Focus on advancing the use and understanding of existing methods through experimental studies, technical innovations, and applications. These articles test and compare model performance on specific tasks, introduce new techniques to enhance efficiency, and explore adaptations for new domains, often involving benchmarking and comparative analysis. They contribute to refining and optimizing SLMs across various domains without introducing new models.
3. Small Language Model Background Overview
3.1. Definition
3.2. Fundamentals
3.3. Attention Mechanisms
3.4. Feedforward Network
3.5. Layer Normalization and Residual Connections
3.6. Parameter Compression and Reduction in Transformers
- Knowledge distillation: It is a training technique in which a large model (the teacher) transfers its knowledge to a smaller model (the student). Instead of training the small model from scratch purely on the original data, the student model is trained to mimic the behavior of the teacher. This typically involves having the teacher generate “soft” targets (such as probability distributions over classes or even intermediate representations) and training the student to match those outputs. By learning to approximate the teacher’s outputs (and sometimes its internal feature representations), the student can achieve a level of performance closer to the teacher than it would using the original training data alone. Knowledge distillation has been highly successful for Transformers. For example, DistilBERT is a distilled version of BERT that is 40% smaller and 60% faster, yet it retains 97% of BERT’s language understanding performance [28]. This shows that a well-trained student (DistilBERT) can replicate most of the capabilities of a much larger teacher model (BERT) by leveraging the guidance of the teacher during training. Overall, knowledge distillation is a powerful way to compress models: it produces an entirely new smaller model that learns from the large model, rather than simply chopping or compressing the original weights. This approach can be seen as a form of depth compression, as it effectively reduces the number of layers in the student model while preserving knowledge from the teacher model.
- Pruning: It removes unnecessary or less important parts of a neural network to reduce its size. In Transformer models, network pruning can operate at various levels of granularity from removing individual weight parameters to removing entire components like attention heads, neurons in the feedforward layers, or even whole Transformer blocks. The idea is to identify components that contribute little to model performance (for example, attention heads that pay mostly redundant attention or weights with near-zero importance) and eliminate them, creating a sparser model. Structured pruning (removing larger components like heads or neurons) has the advantage that it can lead to actual speed-ups and memory savings in practice since entire units are dropped. Unstructured pruning (removing arbitrary individual weights) can greatly reduce the parameter count, though the resulting weight matrices become sparse and may need specialized hardware or libraries to realize computational gains. Either way, pruning leverages the observation that large models often have a lot of redundancy. Researchers have found that Transformers can lose many parameters with only minor drops in accuracy, especially if pruning is combined with a fine-tuning or recovery step to restore performance. In summary, pruning directly eliminates redundant model parameters or structures, yielding a smaller (often much sparser) Transformer model without retraining from scratch. In other words, pruning aligns closely with sparse connectivity, as it removes redundant parameters or layers while preserving the overall network structure.
- Quantization: It reduces the memory and compute requirements of a Transformer by using lower-precision numerical representations for its parameters (and sometimes for activations). Instead of storing weights as 32-bit floating-point numbers, we might use 16-bit or 8-bit integers, for example. By quantizing a full-precision model to 8-bit, the model’s size can be roughly quartered (since 8-bit is 4× smaller than 32-bit). This directly cuts down on memory usage and can accelerate inference on hardware that supports low-precision arithmetic because operations on smaller integers are faster and more energy-efficient. The challenge is to do this without hurting the model’s accuracy. Lower precision means less numerical range and accuracy for representing weights. Techniques like post-training quantization and quantization-aware training (training the model with quantization in mind) are used to maintain performance. Transformers have been shown to tolerate moderate quantization well; for instance, many BERT-like models can be compressed to 8-bit weights with only minimal loss in downstream task accuracy. In practice, quantization offers a trade-off: a slight reduction in model accuracy for a large gain in efficiency. When carefully applied (sometimes with a small amount of fine-tuning on a calibration dataset), quantization can shrink model size and speed up inference, enabling Transformer models to run on resource-constrained devices or with lower latency.
4. RQ1: What Are the Types of Papers, Applications, and Public Availability Related to Small Language Models?
4.1. Our Findings in Context
4.2. Theoretical and Practical Implications
4.3. Synthesis and Takeaways for RQ1
5. RQ2: What Are the Most Prevalent Architectures and Their Associated Compression and Optimization Methods in Current Research?
5.1. Our Findings in Context
- Knowledge distillation: It occurs 43% of the time (e.g., employed specifically to impart mathematical reasoning skills [49,50], refine mathematical expertise from weak supervision [30], transfer complex capabilities like self-evaluation from larger models [51], enhance reasoning in knowledge-intensive tasks [52], empower SLMs with insights from teacher models [53], and implicitly in the ‘teaching’ methodology of Orca 2 [47]), suggesting that transferring knowledge from larger teacher models remains a universally popular approach. In essence, a compact student model is trained to match the output (or soft logits) of a more robust ‘teacher.’ This process produces smaller models that can retain a surprisingly high level of linguistic fluency and comprehension if the teacher covers all tasks thoroughly. The distillation process can preserve much of the teacher’s performance, and the method has become a cornerstone for building smaller specialized models in both the research and the production settings.
- Quantization: It reduces numerical precision (e.g., from 32-bit floating point to 8-bit or even lower), thereby shrinking the memory footprint and often improving inference speed. It occurs 27% of the time in the dataset, for example, utilized in methods for spatial data discovery [54], lightweight model calibration [55], combined with Low-Rank Adaptation (LoRA) for greater efficiency [56], making it the second most frequent strategy after knowledge distillation. Advances in integer-only arithmetic and mixed precision strategies have improved the viability of quantized models, but researchers investigating quantization still have to balance trade-offs between accuracy drops and compression ratio. On-device applications, where memory and processing limitations are the most severe, are particularly interested in these techniques.
- Pruning and parameter-efficient fine-tuning: While extremely effective in certain contexts, pruning large Transformer networks can be more complex than in simpler feedforward architectures, particularly if one aims to preserve multi-head attention fidelity (e.g., as investigated by techniques like EFTNAS [57] or within the concept of elastic language models [35]). Unlike pruning, which reduces memory and computes requirements by removing all parameters, Low-Rank Adaptation (LoRA) takes a different approach by freezing most of the pre-trained model parameters and introducing learnable low-rank update matrices, occurring 18% of the time within this reviewed set. Although LoRA does not serve as a traditional compression method such as pruning, it achieves efficiency by limiting parameter updates rather than eliminating them during fine-tuning. While originally designed for large models, Low-Rank Adaptation (LoRA) has gained traction in the SLM community for adapting models to specific domains. For instance, it has been used in the LQ-LoRA fine-tuning framework [56], for specialized applications like robot navigation (FASTNav [58]), and in mixture-of-task adapters for multitask learning [59].
5.2. Theoretical and Practical Implications
5.3. Synthesis and Takeaways for RQ2
6. RQ3: What Are the Most Common Benchmarks?
6.1. Our Findings in Context
- Knowledge and reading-comprehension: Benchmarks such as MMLU, Natural Questions (NQ), SQuAD, TriviaQA, and HotpotQA test how well models retrieve, process, and synthesize textual information. These emphasize factual accuracy and contextual reasoning.
- Reasoning and logic: Tasks such as GSM8K (math word problems), MultiArith, MATH (advanced math), and ARC evaluate arithmetic, logical deductions, or multistep problem solving. Researchers use these to assess whether smaller models can manage complex reasoning pipelines.
- Common sense and social understanding: Tests like OpenbookQA, PIQA, SIQA, and WinoGrande measure the grasp of a model of everyday knowledge or social cues.
- Code and programming skills: Specialized benchmarks (HumanEval, MBPP, CodeXGLUE) assess code generation, debugging, and analysis. These are critical for applications such as AI-assisted coding tools, where precision and logic are essential.
- Multitask evaluation: Frameworks like Big-Bench Hard (BBH) and MMLU combine diverse tasks such as language understanding, math, and reasoning into unified benchmarks. They provide a holistic view of model strengths and weaknesses, highlighting capabilities single-task tests might overlook.
6.2. Theoretical and Practical Implications
6.3. Synthesis and Takeaways for RQ3
7. RQ4: What Are the Current Challenging Areas?
7.1. Our Findings in Context
- Generalization: SLMs such as the Llama series [45] offer an attractive mix of speed and frugal resource use. The downside is a more limited storage of world knowledge. This limitation shows up most clearly when the task demands broad factual coverage: on MMLU, for example, SLMs trail models trained on massive book corpora, and their learning curve on common-sense-reasoning suites tends to flatten sooner. A comparable challenge arises when the simplified BERT variants are fine-tuned for individual languages or tasks [43]. Because many subtleties never appear in the pre-training data, the models can misapply learned patterns when they stray into unfamiliar domains. Two common remedies are proving effective. First, knowledge distillation pipelines pass high-level representations from a large teacher network to a lightweight student [53]. Second, targeted data augmentation enlarges the training set precisely where coverage is thin [63]. Together, these strategies broaden the generalization reach of SLMs without inflating their parameter counts.
- Data availability: Beyond generalization, the most persistent hurdle for SLMs is the shortage of high-quality training material. Due to their limited parameter budgets, SLMs overfit quickly when data are sparse, noisy, or unbalanced conditions typical of specialist or low-resource domains. To expand the evidence base, researchers are turning to automatic augmentation pipelines [63] and fully synthetic corpora. A flagship example is TinyStories: a collection of child-like narratives written entirely by an LLM that enabled sub-10 million parameter models to learn fluent story structure, provided the output was rigorously filtered [44]. The same approach, if left unchecked, can introduce artifacts and bias, underscoring the need for robust data pipelines and explicit curation standards, especially in safety-critical arenas such as healthcare [33,64], finance, and multilingual deployments.
- Hallucinations: Roughly one-fifth of the failure cases reported in recent SLM studies involve the generation of factually incorrect or internally inconsistent statements. The current work tackles the issue on three fronts:
- -
- Evaluation: New benchmarks and metrics are being designed expressly to surface hallucinations, complementing traditional task scores.
- -
- Training: Knowledge-distillation pipelines that transfer ‘truthfulness’ signals from a larger teacher have been shown to suppress hallucination rates in the student model.
- -
- Decoding: Insights into knowledge overshadowing the dominance of frequent but inaccurate associations have inspired alternative sampling schemes that prioritize verifiable facts over popularity.
Although the problem is usually highlighted in large-scale models, smaller architectures are no less vulnerable: their lean embedding spaces and truncated context windows leave them prone to filling gaps with plausible sounding fabrications. In fact, the stakes increase as SLMs migrate to resource-constrained settings such as mobile hand-sets or edge servers, where downstream checks may be limited. For example, MobileLLM 350M [39] performs well on specific tasks like API calls, matching the accuracy of the much larger Llama-v2 7B. However, in open-ended conversations or on questions requiring deep knowledge, its limited capacity can lead it to generate plausible but inaccurate responses, a form of hallucination. This tendency to produce “plausible-sounding fabrications” is directly related to the concept of hallucinations in language models.One way to counter the issue is to make the model spell out its reasoning. For example, after Llama-2 13B was adapted to the chain-of-thought demonstrations of Llama-2-70B, its accuracy in CommonsenseQA improved from 63.4% to 85.9%, substantially reducing unsupported answers [65]. Similarly, in the LM-Guided-CoT framework, a lightweight Flan-T5-Small (80M parameters) that generates rationales enables a frozen Flan-T5-XXL (11B) to raise its F1 score on 2WikiMultiHopQA, with improved performance in various experimental settings [66]. These concrete gains illustrate why reasoning-first prompts, particularly chain-of-thought, are increasingly used to curb hallucinations. - Scalability: Another SLM research concern is scalability, namely raw throughput and memory pressure. Scalability means keeping an SLM fast and lightweight enough to stream tokens in real time, remain stable across heterogeneous inputs, and plug into existing back-ends without blowing past latency or memory budgets. The hard limits are tokens-per-second and the RAM consumed by parameters and activations. Algorithmic efficiency is the present day solution to the problem. Classic compression tricks structured pruning [57], sub-4-bit quantization [56], and knowledge distillation [49,50,52,53] shrink the footprint without crippling accuracy. Researchers found another way to face the “Compute-optimal inference” problem that we are going to see in the next section.
- Interpretability. Roughly fifteen percent of the shortcomings reported for SLMs concern our limited ability to see why a given answer emerges as an issue that becomes mission-critical in medicine [33], finance, and other regulated settings. In theory, a leaner network should be more transparent; in practice, aggressive compression (quantization [56], structured pruning [57]), gating layers such as SwiGLU, and lightweight tuning modules like LoRA [56] can tangle the internal signal path almost as thoroughly as scale does. Classic probes attention heat-maps, and gradient-based attributions run faster on SLMs, certainly, yet they still leave important causal chains in shadow. Current research therefore follows a dual track. Architectures that enforce modularity from the outset, or adopt inherently legible forms such as certain Mixture-of-Experts variants, make it easier to trace how evidence flows toward a conclusion [10]. Another one is that NLP tool kits are being returned to the quirks of compressed models, while new benchmarks rank systems on the faithfulness of explanation alongside task accuracy [60]. SLMs will often run on personal or edge devices. Long-term users and domain experts must be able to inspect, audit, and, when needed, correct the model’s reasoning.
7.2. Theoretical and Practical Implications
7.3. Synthesis and Takeaways for RQ4
8. Future Directions and New Solutions for SLM Challenges
8.1. Enhancing Generalization
- Architectural and training innovations: Moving beyond vanilla Transformers, researchers are exploring architectural tweaks that help small models generalize. One approach (already used in LLMs) is retrieval-augmented SLMs, which equip the model with a retriever to fetch relevant text from an external corpus. By injecting pertinent facts into the context, even a small model can perform competitively on knowledge-intensive tasks, effectively generalizing beyond its fixed parameters [68]. For example, MiniRAG introduces a retrieval-augmented generation system designed for extreme simplicity and efficiency, enabling small models to integrate external knowledge effectively [69].Another idea is modular or Mixture-of-Experts architectures, where different parts of the model handle different types of data or sub-tasks, expanding the range of what a single SLM can do. On the training side, multitasking and instruction tuning have shown promise: rather than training on one narrow task, SLMs are being trained or fine-tuned on diverse collections of tasks (spanning Q&A, reasoning, translation, etc.), which improves their zero-shot and few-shot generalization.An important insight is that scaling up is not the only route to strong reasoning performance; with the right training regimen, models in the 1–7B range can achieve competitive reasoning ability. Techniques like structured reasoning training (e.g., training on chain-of-thought explanations) or post-training compression (distilling knowledge from a larger model) can yield robust reasoning in SLMs. These findings challenge the notion of an inherent scale threshold for generalization, instead pointing to smarter training as a way forward [70,71].
- Fine-tuning strategies and knowledge distillation: To bridge the performance gap to LLMs, a common theme is knowledge transfer from larger models. Knowledge distillation has been widely used, where a large teacher model’s outputs (or even its intermediate representations) guide the training of the smaller model. This can improve the small model’s generalization on the teacher’s domain without increasing model size [50]. For instance, the Orca series of models demonstrated that by training on the explanation traces of GPT-4 (not just its final answers), a 13B model could emulate much of the larger model’s reasoning ability (e.g., [21,47]).Refining explanations with step-by-step solutions crafted by a teacher aids SLMs in developing reasoning skills and extrapolating to new, unseen problems. Conversely, fine-tuning techniques involve progressive learning, initially training an SLM on simpler tasks before advancing to more complex ones. Additionally, contrastive tuning enhances the differentiation of embeddings. When these strategies are integrated with data-focused methods (as previously mentioned) and compression, they have the potential to boost efficiency while maintaining performance.In summary, a small model that is well-initialized and then “educated” by a larger model’s knowledge and explanations can be generalized in ways that naive training would not achieve. Future research is extending this to new modalities and investigating how far we can push the student–teacher paradigm for SLMs.
- Domain adaptation and continual learning: Generalization is especially tested when an SLM is deployed in a new domain or evolving environment. Here, lightweight adaptation techniques are crucial. Recent work underscores the effectiveness of adapter modules and LoRA for domain shifts: by inserting small learned layers into a frozen model. SLMs can quickly personalize or specialize to a new domain (e.g., medical text, legal documents) without forgetting their original capabilities. Such adapters have minimal impact on computation but allow the model to capture domain-specific patterns. Moreover, researchers advocate for continual learning approaches, where SLMs incrementally update new data over time instead of one-off fine-tuning [11]. This is particularly relevant for on-device models that can learn from user data. One proposed future direction is meta-learning: training SLMs with algorithms that make them inherently quick learners so that given a new domain, they adapt in just a few gradient steps [72]. While current SLMs may still show domain-specific overfitting (tuning on a narrow dataset can hurt performance outside that domain), ongoing research is tackling this via regularization and smarter data scheduling. The goal is an SLM that can maintain a core of general knowledge while flexibly absorbing new information when needed, essentially narrowing the generalization gap with larger models. Continued research on cross-domain evaluation benchmarks and transfer learning techniques is expected to ensure SLMs can be reliably deployed across a range of scenarios [68].
8.2. Overcoming Data Scarcity
- Synthetic data generation: A trend is to use large models to generate artificial training examples for smaller models. Synthetic text produced with LLMs has improved the performance of SLMs in low-resource settings by augmenting or substituting real data [73]. For example, TinyStories is a fully synthetic corpus of childlike stories that successfully trains very small (<10 M) models to generate fluent, factual narratives. (e.g., [21,44]). Researchers are now calling for standardized pipelines for synthetic data curation, using techniques such as automated filtering and prompt engineering to ensure high-quality, diverse training data. This interdisciplinary effort (blending generative AI with data management) is viewed as crucial to reliably improving Small Language Model knowledge and robustness.
- Low-resource adaptation: Another line of work explores making the most of limited data through efficient adaptation methods. Parameter-efficient fine-tuning (e.g., adapters and LoRA modules) allows SLMs to specialize to new domains or languages with minimal training data; for example, with only 1 GB of text plus a small knowledge graph, adapter-based tuning yields gains in language modeling and downstream tasks for low-resource languages. In addition, these small multilingual models (e.g., mBERT, XLM-R) match or outperform the complete fine-tuning of a larger model while updating far fewer parameters [74]. In fact, a well-tuned 1B SLM can compete with massive LLMs (like GPT-4 or Llama) on underrepresented languages or specific tasks. This suggests that aligning model capacity to the available data (rather than simply scaling up) leads to better efficiency. Continued research is exploring meta-learning and transfer learning to further improve adaptation with extremely sparse data, as well as cross-lingual and cross-domain transfer as an interdisciplinary bridge (e.g., leveraging knowledge graphs or linguistic resources alongside text).
- Interdisciplinary benchmarks: The community has started developing innovative benchmarks to drive data-efficient learning. Some works propose new evaluation tasks that simulate real-world low-resource scenarios or require models to learn from synthetic data. For example, TinyGSM introduced a generated dataset of grade school math problems with solutions, and a 1.3B SLM fine-tuned on it reached 81.5% accuracy, surpassing models 30 times larger and even rivaling its GPT-3.5 data generator. Such results spur the creation of benchmarks that test how well small models learn reasoning or domain knowledge from minimal, machine-generated data [21].Interdisciplinary collaboration can also enrich SLM training (e.g., with cognitive science to design curricula like TinyStories, or with curators of the knowledge base to provide factual data). Going forward, researchers emphasize the need for more robust evaluation frameworks and shared datasets to ensure that improvements in Small Language Model training methodologies can be measured consistently.
8.3. Mitigating Hallucinations
- Evaluation and benchmarking: A first step is to reliably detect and quantify hallucinations. SLMs can sometimes produce plausible but unverified reasoning steps, leading to subtle factual errors. However, existing fact-checking methods often fail in multistep or generative tasks [68]. To address this, researchers are creating specialized benchmarks and metrics for hallucination. The object hallucination or DiaHalu benchmark, which focuses on dialogue-level hallucination evaluation [75], has been used to measure hallucination rates in model outputs [76]. Another example is OnionEval [77], a multi-layer evaluation framework with a context influence score to assess how varying context lengths impact the factual accuracy of SLMs. This revealed that while SLMs excel at factual recall, they struggle with context-heavy reasoning, often leading to hallucinations. Solutions such as prompting SLMs to reason step by step (e.g., chain-of-thought prompts) have shown marked success in reducing such hallucinations. These trends imply that future research may involve the incorporation of explicit reasoning processes into the design to enhance faithfulness or the integration of models with external knowledge bases or structured databases for real-time fact-checking. This would ensure that SLMs’ assertions are verified against reliable data before a response is finalized.
- Distillation of knowledge and truthfulness: As mentioned above in the generalization section, knowledge distillation is good at tackling hallucinations. In fact, empirical results in 2025 show that distillation can reduce hallucination rates without degrading overall performance [78]. For example, in a summarization task, a 2.5B parameter student model trained on teacher explanations produced summaries with far fewer fabricated details than a conventionally fine-tuned model. In the future, we expect teacher–student frameworks (e.g., large models ‘teaching’ small ones to say ‘I don’t know’ when uncertain) and rationalized training to become key in aligning Small Language Models’ output with truth [79].
- Knowledge-aware generation strategies: Researchers are also tackling hallucinations by adjusting how SLMs represent and generate knowledge. A 2025 study identified knowledge overshadowing, in which popular or context-dominant facts interfere with recall of less obvious but correct information, as a cause of hallucinations. It formalized a quantitative scaling law, showing that hallucination frequency increases predictably with the logarithm of knowledge popularity, context length, and model size. Based on this analysis, a novel decoding method, called Contrastive Decoding (CODE) [80], was proposed to amplify underrepresented facts during generation. CODE achieved substantial gains in factual accuracy in targeted hallucination benchmarks by preemptively countering the dominance of misleading context. The phenomenon of ‘knowledge overshadowing’ and methods such as Contrastive Decoding (CODE) are especially relevant for smaller language models. Due to their limited parameter count and reduced representational capacity, SLMs are more susceptible to being dominated by popular or contextually dominant information. These advances point to future research on knowledge-balanced architectures (e.g,. retrieval-augmented SLMs or dynamic context weighting) that can proactively minimize hallucinations through a better understanding of what the model does not know.
8.4. Improving Scalability
- Model pruning and quantization: As we discussed earlier, these are classic techniques for shrinking model size; for example, quantization, in particular, has advanced to 4-bit or even 2-bit weights for LLMs [81]. Also, a 4-bit precision can reduce the memory footprint by 70% with negligible performance loss, and forcing models to ultra-low bit widths (with careful calibration to avoid accuracy drop) means that much larger architectures become deployable under small-model resource constraints. In the future, we might see hybrid 8-bit/4-bit SLM deployments on edge devices [11]. This would bring powerful language capabilities to smartphones and IoT hardware, representing a convergence of model compression research and hardware-aware design.
- Compute-optimal inference: A striking development in 2025 is the use of Test-Time Scaling (TTS), where additional computation is used at inference (through techniques such as iterative decoding, majority voting, or tree search) to increase accuracy. With an optimal TTS strategy, extremely small models can outperform giants in challenging tasks [82]. For example, experiments found a 1B parameter model solving math problems better than a 405B parameter model when allowed more iterative reasoning and voting at test time, and this flip in performance, achieved by trading extra inference cycles for model size reduction, suggests a new research direction: compute-optimal inference.
- Knowledge distillation and compression: Knowledge distillation can enhance many aspects of SLMs from generalization to scalability. For example, the Neural-Symbolic Collaborative Distillation (NesyCD) framework decouples general and specialized knowledge by combining neural and symbolic knowledge. In this framework, an SLM is taught broad reasoning skills by a large model, while task-specific rare knowledge is distilled into an explicit symbolic knowledge base, by offloading niche facts to a human-readable knowledge base and only teaching general skills to the 8B parameter model; for example, a Qwen2 7B SLM distilled using this method surpasses OpenAI’s 175B GPT-3.5 on reasoning tasks and nearly matches a 70B Llama-3 model. This underscores that clever training paradigms can compress critical knowledge and strategies from very large models into much smaller ones, improving scalability [83].
8.5. Advancing Interpretability and Explainability
- Architectural transparency: One promising direction is to design SLMs that are interpretable by construction. Rather than treating explainability as an afterthought (post hoc probing of a trained model), researchers are inventing training objectives that directly promote modular, disentangled representations in SLMs, adding a cluster ability loss during training to encourage the model to organize its neurons into semi-independent ’circuits’ [84]. By penalizing excessive entanglement, the resulting network develops more modular subnetworks that can be analyzed in isolation. In experiments on small Transformers, this approach yielded models that split their computations into distinct clusters, each responsible for different aspects of the task. In practice, SLMs were limited to learning simpler disjoint functions, making it easier to trace input/output pathways. Continuing in similar lines, as discussed in the Generalization section before, another promising way to make large SLMs more understandable is to build them so that their inner workings are naturally clearer using the “Mixture-of-Experts” (MoE) setup; for example, MoE-X, a model designed specifically for easier interpretation. They made sure that each expert focused on their own unique piece of the puzzle without overlap, so it was much easier to pinpoint what each expert was doing. As a result, we can check the contribution of each ‘expert’ and see how it affects the model output. That means we maintain the model’s performance while also making its decision-making clearer and more transparent [85].
- Explaining and evaluating SLM Decisions: In addition to building inherently interpretable models, another active area is developing techniques to explain the output behavior of any given Small Language Model. Many standard explainability tools in NLP (such as saliency maps, attention weight analysis, and counterfactual generation) need to be adjusted to the small-model regime. Currently, most benchmarks focus on accuracy (as we saw in the SLR), but we see initial efforts to create explanation-sensitive evaluations. For example, some question answering datasets now require a reference rationale, and models are scored on rationale correctness in addition to the answer. SLMs could particularly benefit from these, as they encourage training for faithful reasoning. Another future direction is to leverage human-in-the-loop evaluations for SLM interpretability. Because SLMs can be deployed on a scale (for example, on personal devices), and end users or domain experts could directly inspect or adjust the model’s reasoning.
9. Limitations of the Study
9.1. Scope and Definitional Boundaries
9.2. Search and Selection Bias
9.3. Analysis and Interpretation Limitations
10. Conclusions
10.1. Divergent Contributions of Academia and Industry
10.2. Emerging Designs for Efficient Model Architecture
10.3. The Emphasis on Reasoning and Responsible AI in SLM Benchmarks
10.4. Research Challenges and Clear Solution Pathways
- Generalization: SLMs face limitations in broad factual coverage and can misapply learned patterns in unfamiliar domains. Solutions involve architectural and training innovations, such as retrieval-augmented SLMs that fetch external facts [69], modular or Mixture-of-Experts architectures, and multitask or instruction tuning on diverse tasks. Furthermore, domain adaptation and continual learning techniques like adapter modules and LoRA allow SLMs to quickly specialize to new domains with minimal computational impact, aiming to narrow the generalization gap with larger models.
- Data Availability: SLMs struggle with sparse, noisy, or unbalanced data due to their limited parameter budgets. Current research prioritizes “better tokens” over “more tokens” by utilizing synthetic data generation from Large Language Models (LLMs) to augment or substitute real data, like the TinyStories corpus [44].
- Hallucinations: Approximately one-fifth of reported failures in SLM studies involve the generation of factually incorrect or inconsistent statements, particularly in open-ended conversational scenarios or when requiring extensive encyclopedic knowledge. Solutions include creating specialized benchmarks and metrics for hallucination detection to complement traditional task scores. Additionally, knowledge-aware generation strategies like Contrastive Decoding (CODE) [80] amplify underrepresented facts during generation to counteract the dominance of popular but misleading information, which is particularly relevant for SLMs due to their limited capacity.
- Scalability: This challenge concerns maintaining fast, lightweight, and stable SLM performance under tight latency and memory budgets. Solutions involve model pruning and quantization, with advancements allowing for ultra-low-bit weights (e.g., 4-bit or 2-bit), reducing memory footprint, and enabling deployment on resource-constrained devices like smartphones and IoT hardware. Furthermore, knowledge distillation frameworks like Neural-Symbolic Collaborative Distillation (NesyCD) [83] improve scalability by decoupling general and specialized knowledge, offloading niche facts to external knowledge bases and focusing on teaching general skills to SLMs.
- Interpretability: Around 15% of reported shortcomings in SLMs relate to the limited ability to understand why a specific answer is generated, which is critical in high-stakes fields like medicine and finance. One promising avenue is to design models with built-in modularity—for example, using Mixture-of-Experts (MoE) architectures like MoE-X [85], where each expert specializes in a distinct sub-task. By ensuring these experts do not overlap in their focus, we can trace the model’s reasoning back to the responsible component.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper Title | Type |
|---|---|
| AcKnowledge: A Small Language Model for Open-Domain Question Answering [62] | model |
| Snowballed: TinyStories: How Small Can Language Models Be and Still Speak Coherent English? [44] | model |
| GPT-wee: How Small Can a Small Language Model Really Get? [48] | model |
| FLAME: A Small Language Model for Spreadsheet Formulas [41] | model |
| Exploring Transformers as Compact, Data-efficient Language Models [86] | model |
| Expanding the Vocabulary of BERT for Knowledge Base Construction [87] | model |
| On Elastic Language Models [35] | model |
| Snowballed: Gemma: Open models based on gemini research and technology [25] | model |
| Snowballed: Phi-3 technical report: A highly capable language model locally on your phone [10] | model |
| Development of Language Models for Continuous Uzbek Speech Recognition System [88] | model |
| Snowballed: MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases [39] | model |
| Snowballed: Qwen2 technical report [46] | model |
| LAPIS: Language Model-Augmented Police Investigation System [32] | model |
| Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis [42] | model |
| Snowballed: CodeT5+: Open Code Large Language Models for Code Understanding and Generation [40] | model |
| Deciphering the protein landscape with ProtFlash, a lightweight language model [38] | model |
| Snowballed: TinyLlama: An Open-Source Small Language Model [24] | model |
| Snowballed: Mistral 7B [16] | model |
| Snowballed: The Flan Collection: Designing Data and Methods for Effective Instruction Tuning [37] | model |
| TeenyTinyLlama: open-source tiny language models trained in Brazilian Portuguese [31] | model |
| Snowballed: The Surprising Power of Small Language Models [89] | model |
| Snowballed: Orca 2: Teaching Small Language Models How to Reason [47] | model |
| Snowballed: Llama 2: Open Foundation and Fine-Tuned Chat Models [9] | model |
| Snowballed: The Falcon Series of Open Language Models [90] | model |
| Snowballed: Gemini: A Family of Highly Capable Multimodal Models [36] | model |
| Towards Multi-Modal Mastery: A 4.5B Parameter Truly Multi-Modal Small Language Model [91] | model |
| Snowballed: Llama: Open and Efficient Foundation Language Models [45] | model |
| Blaze-IT and Flare-IT: Lightweight BERT Models for Italian [43] | model |
| Towards Pareto Optimal Throughput in Small Language Model Serving [92] | method |
| Leveraging Small Language Models for Text2SPARQL tasks to improve the resilience of AI assistance [93] | method |
| LitCab: Lightweight Language Model Calibration over Short- and Long-form Responses [55] | method |
| Enhancing Small Language Models via ChatGPT and Dataset Augmentation [63] | method |
| LQ-LORA: Low-Rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning [56] | method |
| Making Small Language Models Better Multi-task Learners with Mixture-of-Task-Adapters [59] | method |
| Modeling Overregularization in Children with SLMs | method |
| Open-source Small Language Models for personal medical assistant chatbots [61] | method |
| Towards a Small Language Models powered chain-of-reasoning for open-domain question answering [94] | method |
| Tiny Language Models Enriched with Multimodal Knowledge from Multiplex Networks [95] | method |
| Test-Time Self-Adaptive Small Language Models for Question Answering | method |
| Spatial Data Discovery Using Small Language Model [96] | method |
| Specializing Small Language Models Towards Complex Style Transfer via Latent Attribute Pre-Training [97] | method |
| Teaching Small Language Models to Reason for Knowledge-Intensive Multi-Hop Question Answering [98] | method |
| Mind’s Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models [51] | method |
| Open-Source or Proprietary Language Models? An Initial Comparison on the Assessment of an Educational Task [99] | method |
| FASTNav: Fine-tuned Adaptive Small-language-models Trained for Multi-point Robot Navigation [58] | method |
| Hybrid Small Language Models and LLM for Edge-Cloud Collaborative Inference [100] | method |
| Aligning Large and Small Language Models via Chain-of-Thought Reasoning [65] | method |
| An emulator for fine-tuning Large Language Models using Small Language Models [101] | method |
| BLU-SynTra: Synergies and Trade-offs Between SDGs Using Small Language Models [102] | method |
| Can Small Language Models be Good Reasoners for Sequential Recommendation? [103] | method |
| Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought [66] | method |
| Can Small Language Models With Retrieval-Augmented Generation Replace Large Language Models When Learning Computer Science? [67] | method |
| Chain-of-Thought in Neural Code Generation: From and for Lightweight Language Models [104] | method |
| COCONUT: Contextualized Commonsense Unified Transformers for Graph-Based Commonsense Augmentation of Language Models [105] | method |
| Combining Small Language Models and Large Language Models for Zero-Shot NL2SQL [29] | method |
| Could Small Language Models Serve as Recommenders? Towards Data-centric Cold-start Recommendation [106] | method |
| Deeploy: Enabling Energy-Efficient Deployment of Small Language Models on Heterogeneous Microcontrollers [60] | method |
| Teaching Small Language Models to Reason [72] | method |
| Distilling Mathematical Reasoning Capabilities into Small Language Models [49] | method |
| Distilling Multi-Step Reasoning Capabilities into Smaller Language Model [50] | method |
| Efficient Knowledge Distillation: Empowering Small Language Models with Teacher Model Insights [53] | method |
| EFTNAS: Searching for Efficient Language Models in First-Order Weight-Reordered Super-Networks [57] | method |
| Enhancing SLMs via ChatGPT and Dataset Augmentation [63] | method |
| Enhancing Small Medical Learners with Privacy-preserving Contextual Prompting [64] | method |
| Exploring Domain Robust Lightweight Reward Models based on Router Mechanism [34] | method |
| ZARA: Improving Few-Shot Self-Rationalization for Small Language Models [107] | method |
| FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models [108] | method |
| From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models [109] | method |
| From Large to Tiny: Distilling and Refining Mathematical Expertise for Math Word Problems with Weakly Supervision [30] | method |
| Knowledge-Augmented Reasoning Distillation for Small Language Models in Knowledge-Intensive Tasks [52] | method |
| Small Language Model Can Self-correct [110] | method |
| Abbreviation | Full Form |
|---|---|
| 7B | 7 billion parameters |
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| BBH | Big-Bench Hard |
| BERT | Bidirectional Encoder Representations from Transformers |
| Code Gen. | Code Generation |
| Content Gen. | Content Generation |
| CPU | Central Processing Unit |
| FFN | Feedforward Network |
| GELU | Gaussian Error Linear Unit |
| GeGLU | GELU–Gated Linear Unit |
| GPT | Generative Pre-trained Transformer |
| GPU | Graphics Processing Unit |
| GSM8K | Grade School Math 8K |
| IR | Information Retrieval |
| IoT | Internet of Things |
| LayerNorm | Layer Normalization |
| LLMs | Large Language Models |
| LoRA | Low-Rank Adaptation |
| MMLU | Massive Multitask Language Understanding |
| MoE | Mixture-of-Experts |
| NesyCD | Neural-Symbolic Collaborative Distillation |
| NL2SQL | Natural Language to Structured Query Language |
| NLP | Natural Language Processing |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| QA | Question Answering |
| QA/IR/Class. | Question Answering/Information Retrieval/Classification |
| RAI | Responsible AI |
| Reason/Math | Reasoning and Mathematics |
| ReLU | Rectified Linear Unit |
| RMSNorm | Root Mean Square Normalization |
| RoPE | Rotary Positional Embeddings |
| SLR | Systematic Literature Review |
| SQL | Structured Query Language |
| SQuAD | Reading-comprehension Question Answering |
| SQuAD-IT | Italian Reading-comprehension Question Answering |
| SQuADv2 | Reading-comprehension Question Answering |
| SuperGLUE | Advanced Natural Language Understanding benchmark |
| SVAMP | Algebraic Word Problems (reasoning) |
| SwiGLU | Sigmoid-Weighted Linear Unit |
| T5 | Text-to-Text Transfer Transformer |
| TriviaQA | Open-domain trivia Question Answering |
| TTS | Test-Time Scaling |
| UK | United Kingdom |
| USA | United States of America |
| VRAM | Video Random Access Memory |
| WinoGrande | Coreference commonsense reasoning |
References
- Brants, T.; Popat, A.C.; Xu, P.; Och, F.J.; Dean, J. Large Language Models in Machine Translation. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL); Eisner, J., Ed.; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 858–867. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [PubMed]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://api.semanticscholar.org/CorpusID:49313245 (accessed on 15 July 2025).
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A Comprehensive Overview of Large Language Models. arXiv 2024, arXiv:2307.06435. [Google Scholar] [CrossRef]
- Minaee, S.; Mikolov, T.; Nikzad, N.; Chenaghlu, M.; Socher, R.; Amatriain, X.; Gao, J. Large Language Models: A Survey. arXiv 2024, arXiv:2402.06196. [Google Scholar] [PubMed]
- Hadi, M.U.; Qureshi, R.; Shah, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; Mirjalili, S.; Shah, M.; et al. A Survey on Large Language Models: Applications, Challenges, Limitations, and Practical Usage. Authorea Prepr. 2023, 1, 1–26. [Google Scholar] [CrossRef]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol. 2024, 15, 3641289. [Google Scholar] [CrossRef]
- Schick, T.; Schütze, H. It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tur, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; pp. 2339–2352. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Abdin, M.; Aneja, J.; Behl, H.; Bubeck, S.; Eldan, R.; Gunasekar, S.; Harrison, M.; Hewett, R.J.; Javaheripi, M.; Kauffmann, P.; et al. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv 2024, arXiv:2404.14219. [Google Scholar] [CrossRef]
- Lu, Z.; Li, X.; Cai, D.; Yi, R.; Liu, F.; Zhang, X.; Lane, N.D.; Xu, M. Small Language Models: Survey, Measurements, and Insights. arXiv 2024, arXiv:2409.15790. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, Z.; Zhang, X.; Wu, Z.; Mo, T.; Lu, Q.; Wang, W.; Li, R.; Xu, J.; Tang, X.; et al. A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness. arXiv 2024, arXiv:2411.03350. [Google Scholar] [CrossRef]
- Nguyen, C.V.; Shen, X.; Aponte, R.; Xia, Y.; Basu, S.; Hu, Z.; Chen, J.; Parmar, M.; Kunapuli, S.; Barrow, J.; et al. A Survey of Small Language Models. arXiv 2024, arXiv:2410.20011. [Google Scholar] [PubMed]
- Garg, M.; Raza, S.; Rayana, S.; Liu, X.; Sohn, S. The Rise of Small Language Models in Healthcare: A Comprehensive Survey. arXiv 2025, arXiv:2504.17119. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. BMJ 2021, 372, n71. Available online: https://www.bmj.com/content/372/bmj.n71.full.pdf (accessed on 15 July 2025). [CrossRef] [PubMed]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar] [CrossRef]
- Lieberum, J.L.; Toews, M.; Metzendorf, M.I.; Heilmeyer, F.; Siemens, W.; Haverkamp, C.; Böhringer, D.; Meerpohl, J.J.; Eisele-Metzger, A. Large language models for conducting systematic reviews: On the rise, but not yet ready for use—A scoping review. J. Clin. Epidemiol. 2025, 181, 111746. [Google Scholar] [CrossRef] [PubMed]
- Gartlehner, G.; Affengruber, L.; Titscher, V.; Noel-Storr, A.; Dooley, G.; Ballarini, N.; König, F. Single-reviewer abstract screening missed 13 percent of relevant studies: A crowd-based, randomized controlled trial. J. Clin. Epidemiol. 2020, 121, 20–28. [Google Scholar] [CrossRef] [PubMed]
- DeepSeek Team. DeepSeek-V3 Technical Report. arXiv 2025, arXiv:2412.19437. [Google Scholar]
- Allen-Zhu, Z.; Li, Y. Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws. arXiv 2024, arXiv:2404.05405. [Google Scholar] [CrossRef]
- Subramanian, S.; Elango, V.; Gungor, M. Small Language Models (SLMs) Can Still Pack a Punch: A survey. arXiv 2025, arXiv:2501.05465. [Google Scholar]
- Li, C.; Wang, W.; Hu, J.; Wei, Y.; Zheng, N.; Hu, H.; Zhang, Z.; Peng, H. Common 7B Language Models Already Possess Strong Math Capabilities. arXiv 2024, arXiv:2403.04706. [Google Scholar] [CrossRef]
- Wu, C.; Song, Y. Scaling Context, Not Parameters: Training a Compact 7B Language Model for Efficient Long-Context Processing. arXiv 2025, arXiv:2505.08651. [Google Scholar] [CrossRef]
- Zhang, P.; Zeng, G.; Wang, T.; Lu, W. TinyLlama: An Open-Source Small Language Model. arXiv 2024, arXiv:2401.02385. [Google Scholar]
- Gemini Team. Gemma: Open Models Based on Gemini Research and Technology. arXiv 2024, arXiv:2403.08295. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, Y.; Guo, J.; Tu, Z.; Han, K.; Hu, H.; Tao, D. A Survey on Transformer Compression. arXiv 2024, arXiv:2402.05964. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2020, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Fan, J.; Gu, Z.; Zhang, S.; Zhang, Y.; Chen, Z.; Cao, L.; Li, G.; Madden, S.; Du, X.; Tang, N. Combining Small Language Models and Large Language Models for Zero-Shot NL2SQL. Proc. VLDB Endow. 2024, 17, 2750–2763. [Google Scholar] [CrossRef]
- Lin, Q.; Xu, B.; Huang, Z.; Cai, R. From Large to Tiny: Distilling and Refining Mathematical Expertise for Math Word Problems with Weakly Supervision. In Advanced Intelligent Computing Technology and Applications; Springer Nature: Singapore, 2024; pp. 251–262. [Google Scholar] [CrossRef]
- Corrêa, N.K.; Falk, S.; Fatimah, S.; Sen, A.; De Oliveira, N. TeenyTinyLlama: Open-source tiny language models trained in Brazilian Portuguese. Mach. Learn. Appl. 2024, 16, 100558. [Google Scholar] [CrossRef]
- Kim, H.; Kim, D.; Lee, J.; Yoon, C.; Choi, D.; Gim, M.; Kang, J. LAPIS: Language Model-Augmented Police Investigation System. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, New York, NY, USA, 21–25 October 2024; CIKM ’24. pp. 4637–4644. [Google Scholar] [CrossRef]
- Magnini, M.; Aguzzi, G.; Montagna, S. Open-source small language models for personal medical assistant chatbots. Intell.-Based Med. 2025, 11, 100197. [Google Scholar] [CrossRef]
- Namgoong, H.; Jung, J.; Jung, S.; Roh, Y. Exploring Domain Robust Lightweight Reward Models based on Router Mechanism. In Proceedings of the Findings of the Association for Computational Linguistics: ACL; ACL: Bangkok, Thailand, 2024; pp. 8644–8652. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, B.; Song, D. On Elastic Language Models. ACM Trans. Inf. Syst. 2024, 42, 3677375. [Google Scholar] [CrossRef]
- Team, G. Gemini: A Family of Highly Capable Multimodal Models. arXiv 2024, arXiv:2312.11805. [Google Scholar]
- Longpre, S.; Hou, L.; Vu, T.; Webson, A.; Chung, H.W.; Tay, Y.; Zhou, D.; Le, Q.V.; Zoph, B.; Wei, J.; et al. The Flan Collection: Designing Data and Methods for Effective Instruction Tuning. arXiv 2023, arXiv:2301.13688. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, H.; Xu, W.; Xue, Z.; Wang, Y. Deciphering the protein landscape with ProtFlash, a lightweight language model. Cell Rep. Phys. Sci. 2023, 4, 101600. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, C.; Iandola, F.; Lai, C.; Tian, Y.; Fedorov, I.; Xiong, Y.; Chang, E.; Shi, Y.; Krishnamoorthi, R.; et al. MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases. arXiv 2024, arXiv:2402.14905. [Google Scholar]
- Wang, Y.; Le, H.; Gotmare, A.D.; Bui, N.D.Q.; Li, J.; Hoi, S.C.H. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. arXiv 2023, arXiv:2305.07922. [Google Scholar]
- Joshi, H.; Ebenezer, A.; Sanchez, J.C.; Gulwani, S.; Kanade, A.; Le, V.; Radiček, I.; Verbruggen, G. FLAME: A small language model for spreadsheet formulas. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024. AAAI’24/IAAI’24/EAAI’24. [Google Scholar] [CrossRef]
- Lemerle, T.; Obin, N.; Roebel, A. Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Kos Island, Greece, 1–5 September 2024; pp. 3420–3424. [Google Scholar] [CrossRef]
- Russo, F.; Filannino, M. Blaze-IT: A lightweight BERT model for the Italian language. In Proceedings of the CLiC-it 2023: 9th Italian Conference on Computational Linguistics, Venice, Italy, 30 November–2 December 2023; Volume 3596. [Google Scholar]
- Eldan, R.; Li, Y. TinyStories: How Small Can Language Models Be and Still Speak Coherent English? arXiv 2023, arXiv:2305.07759. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Yang, A.; Yang, B.; Hui, B.; Zheng, B.; Yu, B.; Zhou, C.; Li, C.; Li, C.; Liu, D.; Huang, F.; et al. Qwen2 Technical Report. arXiv 2024, arXiv:2407.10671. [Google Scholar]
- Mitra, A.; Corro, L.D.; Mahajan, S.; Codas, A.; Simoes, C.; Agarwal, S.; Chen, X.; Razdaibiedina, A.; Jones, E.; Aggarwal, K.; et al. Orca 2: Teaching Small Language Models How to Reason. arXiv 2023, arXiv:2311.11045. [Google Scholar] [CrossRef]
- Bunzeck, B.; Zarrieß, S. GPT-wee: How Small Can a Small Language Model Really Get? In Proceedings of the CoNLL 2023-BabyLM Challenge at the 27th Conference on Computational Natural Language Learning, Singapore, 6 December 2023; pp. 35–46. [Google Scholar]
- Zhu, X.; Li, J.; Liu, Y.; Ma, C.; Wang, W. Distilling mathematical reasoning capabilities into Small Language Models. Neural Netw. 2024, 179, 106594. [Google Scholar] [CrossRef] [PubMed]
- Yim, Y.; Wang, Z. Distilling Multi-Step Reasoning Capabilities into Smaller Language Model. In Proceedings of the ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2024; pp. 530–535. [Google Scholar] [CrossRef]
- Liu, W.; Li, G.; Zhang, K.; Du, B.; Chen, Q.; Hu, X.; Xu, H.; Chen, J.; Wu, J. Mind’s Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2024, Mexico City, Mexico, 16–21 June 2024; Volume 1, pp. 6748–6763. [Google Scholar] [CrossRef]
- Kang, M.; Lee, S.; Baek, J.; Kawaguchi, K.; Hwang, S.J. Knowledge-Augmented Reasoning Distillation for Small Language Models in Knowledge-Intensive Tasks. Adv. Neural Inf. Process. Syst. 2023, 36, 48573–48602. [Google Scholar]
- Ballout, M.; Krumnack, U.; Heidemann, G.; Kühnberger, K.U. Efficient Knowledge Distillation: Empowering Small Language Models with Teacher Model Insights. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2024; Volume 14762 LNCS, pp. 32–46. [Google Scholar] [CrossRef]
- Thakur, S.K.; Tyagi, N. Spatial Data Discovery Using Small Language Model. In Proceedings of the 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), Uttar Pradesh, India, 9–10 February 2024; Volume 5, pp. 899–905. [Google Scholar]
- Liu, X.; Khalifa, M.; Wang, L. LITCAB: LIGHTWEIGHT LANGUAGE MODEL CALIBRATION OVER SHORT- AND LONG-FORM RESPONSES. In Proceedings of the 12th International Conference on Learning Representations, ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Guo, H.; Greengard, P.; Xing, E.P.; Kim, Y. LQ-lora: Low-rank plus quantized matrix decomposition for efficient language model finetuning. In Proceedings of the 12th International Conference on Learning Representations, ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Munoz, J.P.; Zheng, Y.; Jain, N. EFTNAS: Searching for Efficient Language Models in First-Order Weight-Reordered Super-Networks. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italia, 20–25 May 2024; Calzolari, N., Kan, M.Y., Hoste, V., Lenci, A., Sakti, S., Xue, N., Eds.; pp. 5596–5608. [Google Scholar]
- Chen, Y.; Han, Y.; Li, X. FASTNav: Fine-Tuned Adaptive Small-Language- Models Trained for Multi-Point Robot Navigation. IEEE Robot. Autom. Lett. 2025, 10, 390–397. [Google Scholar] [CrossRef]
- Xie, Y.; Wang, C.; Yan, J.; Zhou, J.; Deng, F.; Huang, J. Making Small Language Models Better Multi-Task Learners with Mixture-of-Task-Adapters. In Proceedings of the WSDM 2024-Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Yucatán, Mexico, 4–8 March 2024; pp. 1094–1097. [Google Scholar] [CrossRef]
- Scherer, M.; Macan, L.; Jung, V.J.B.; Wiese, P.; Bompani, L.; Burrello, A.; Conti, F.; Benini, L. Deeploy: Enabling Energy-Efficient Deployment of Small Language Models on Heterogeneous Microcontrollers. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 4009–4020. [Google Scholar] [CrossRef]
- Haga, A.; Sugawara, S.; Fukatsu, A.; Oba, M.; Ouchi, H.; Watanabe, T.; Oseki, Y. Modeling Overregularization in Children with Small Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; ACL: Bangkok, Thailand, 2024; pp. 14532–14550. [Google Scholar] [CrossRef]
- Das, S.; Chatterji, S.; Mukherjee, I. AcKnowledge: Acquired Knowledge Representation by Small Language Model without Pre-training. In KnowLLM 2024-1st Workshop on Towards Knowledgeable Language Models, Proceedings of the Workshop; Association for Computational Linguistics: Bangkok, Thailand, 2024. [Google Scholar]
- Pieper, T.; Ballout, M.; Krumnack, U.; Heidemann, G.; Kühnberger, K.U. Enhancing Small Language Models via ChatGPT and Dataset Augmentation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2024; Volume 14763 LNCS, pp. 269–279. [Google Scholar] [CrossRef]
- Zhang, X.; Li, S.; Yang, X.; Tian, C.; Qin, Y.; Petzold, L.R. Enhancing small medical learners with privacy-preserving contextual prompting. In Proceedings of the 12th International Conference on Learning Representations, ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Ranaldi, L.; Freitas, A. Aligning Large and Small Language Models via Chain-of-Thought Reasoning. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), St. Julian’s, Malta, 17–22 March 2024; Graham, Y., Purver, M., Eds.; pp. 1812–1827. [Google Scholar]
- Lee, J.; Yang, F.; Tran, T.; Hu, Q.; Barut, E.; Chang, K.W.; Su, C. Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC-COLING 2024-Main Conference Proceedings, Torino, Italy, 20–25 May 2024; pp. 2835–2843. [Google Scholar]
- Liu, S.; Yu, Z.; Huang, F.; Bulbulia, Y.; Bergen, A.; Liut, M. Can Small Language Models With Retrieval-Augmented Generation Replace Large Language Models When Learning Computer Science? In Proceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1, New York, NY, USA, 5–10 July 2024; ITiCSE 2024. pp. 388–393. [Google Scholar] [CrossRef]
- Patil, A. Advancing Reasoning in Large Language Models: Promising Methods and Approaches. arXiv 2025, arXiv:2502.03671. [Google Scholar]
- Fan, T.; Wang, J.; Ren, X.; Huang, C. MiniRAG: Towards Extremely Simple Retrieval-Augmented Generation. arXiv 2025, arXiv:2501.06713. [Google Scholar]
- Srivastava, G.; Cao, S.; Wang, X. Towards Reasoning Ability of Small Language Models. arXiv 2025, arXiv:2502.11569. [Google Scholar]
- Hsieh, C.Y.; Li, C.L.; Yeh, C.K.; Nakhost, H.; Fujii, Y.; Ratner, A.; Krishna, R.; Lee, C.Y.; Pfister, T. Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes. arXiv 2023, arXiv:2305.02301. [Google Scholar]
- Magister, L.C.; Mallinson, J.; Adamek, J.; Malmi, E.; Severyn, A. Teaching Small Language Models to Reason. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 2, pp. 1773–1781. [Google Scholar] [CrossRef]
- Nadas, M.; Diosan, L.; Tomescu, A. Synthetic Data Generation Using Large Language Models: Advances in Text and Code. arXiv 2025, arXiv:2503.14023. [Google Scholar]
- Gurgurov, D.; Vykopal, I.; van Genabith, J.; Ostermann, S. Small Models, Big Impact: Efficient Corpus and Graph-Based Adaptation of Small Multilingual Language Models for Low-Resource Languages. arXiv 2025, arXiv:2502.10140. [Google Scholar]
- Li, J.; Cheng, X.; Zhao, W.X.; Nie, J.Y.; Wen, J.R. HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. arXiv 2023, arXiv:2305.11747. [Google Scholar]
- Yang, Z.; Luo, X.; Han, D.; Xu, Y.; Li, D. Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key. arXiv 2025, arXiv:2501.09695. [Google Scholar]
- Sun, C.; Li, Y.; Wu, D.; Boulet, B. OnionEval: An Unified Evaluation of Fact-conflicting Hallucination for Small-Large Language Models. arXiv 2025, arXiv:2501.12975. [Google Scholar]
- Nguyen, H.; He, Z.; Gandre, S.A.; Pasupulety, U.; Shivakumar, S.K.; Lerman, K. Smoothing Out Hallucinations: Mitigating LLM Hallucination with Smoothed Knowledge Distillation. arXiv 2025, arXiv:2502.11306. [Google Scholar]
- Lewis, A.; White, M.; Liu, J.; Koike-Akino, T.; Parsons, K.; Wang, Y. Winning Big with Small Models: Knowledge Distillation vs. Self-Training for Reducing Hallucination in QA Agents. arXiv 2025, arXiv:2502.19545. [Google Scholar]
- Kim, J.; Kim, H.; Kim, Y.; Ro, Y.M. CODE: Contrasting Self-generated Description to Combat Hallucination in Large Multi-modal Models. arXiv 2024, arXiv:2406.01920. [Google Scholar]
- Giagnorio, A.; Mastropaolo, A.; Afrin, S.; Penta, M.D.; Bavota, G. Quantizing Large Language Models for Code Generation: A Differentiated Replication. arXiv 2025, arXiv:2503.07103. [Google Scholar]
- Liu, R.; Gao, J.; Zhao, J.; Zhang, K.; Li, X.; Qi, B.; Ouyang, W.; Zhou, B. Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling. arXiv 2025, arXiv:2502.06703. [Google Scholar]
- Liao, H.; He, S.; Xu, Y.; Zhang, Y.; Liu, K.; Zhao, J. Neural-Symbolic Collaborative Distillation: Advancing Small Language Models for Complex Reasoning Tasks. arXiv 2025, arXiv:2409.13203. [Google Scholar] [CrossRef]
- Golechha, S.; Chaudhary, M.; Velja, J.; Abate, A.; Schoots, N. Modular Training of Neural Networks aids Interpretability. arXiv 2025, arXiv:2502.02470. [Google Scholar]
- Yang, X.; Venhoff, C.; Khakzar, A.; de Witt, C.S.; Dokania, P.K.; Bibi, A.; Torr, P. Mixture of Experts Made Intrinsically Interpretable. arXiv 2025, arXiv:2503.07639. [Google Scholar]
- Fields, C.; Kennington, C. Exploring Transformers as Compact, Data-efficient Language Models. In Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL), Singapore, 6–7 December 2023; Jiang, J., Reitter, D., Deng, S., Eds.; pp. 521–531. [Google Scholar] [CrossRef]
- Yang, D.; Wang, X.; Celebi, R. Expanding the Vocabulary of BERT for Knowledge Base Construction. In Proceedings of the LM-KBC’23: Knowledge Base Construction from Pre-trained Language Models, Challenge at ISWC 2023, Athens, Greece, 6–10 November 2023; Volume 3577. [Google Scholar]
- Mukhamadiyev, A.; Mukhiddinov, M.; Khujayarov, I.; Ochilov, M.; Cho, J. Development of Language Models for Continuous Uzbek Speech Recognition System. Sensors 2023, 23, 1145. [Google Scholar] [CrossRef] [PubMed]
- Bhosale, M.; Research, M. Phi-2: The Surprising Power of Small Language Models. Microsoft Res. Blog 2023, 1, 3. [Google Scholar]
- Almazrouei, E.; Alobeidli, H.; Alshamsi, A.; Cappelli, A.; Cojocaru, R.; Debbah, M.; Goffinet, É.; Hesslow, D.; Launay, J.; Malartic, Q.; et al. The Falcon Series of Open Language Models. arXiv 2023, arXiv:2311.16867. [Google Scholar] [CrossRef]
- Koska, B.; Horvath, M. Towards Multi-Modal Mastery: A 4.5B Parameter Truly Multi-Modal Small Language Model. In Proceedings of the 2024 2nd International Conference on Foundation and Large Language Models, FLLM 2024, Dubai, United Arab Emirates, 26–29 November 2024; pp. 587–592. [Google Scholar] [CrossRef]
- Recasens, P.G.; Zhu, Y.; Wang, C.; Lee, E.K.; Tardieu, O.; Youssef, A.; Torres, J.; Berral, J.L. Towards Pareto optimal throughput in small language model serving. In Proceedings of the Workshop on Machine Learning and Systems; ACM: New York, NY, USA, 2024; pp. 144–152. [Google Scholar]
- Brei, F.; Frey, J.; Meyer, L.P. Leveraging small language models for Text2SPARQL tasks to improve the resilience of AI assistance. In Proceedings of the D2R2’24: Third International Workshop on Linked Data-driven Resilience Research 2024, Hersonissos, Greece, 27 May 2024; Volume 3707. [Google Scholar]
- Roh, J.; Kim, M.; Bae, K. Towards a small language model powered chain-of-reasoning for open-domain question answering. ETRI J. 2024, 46, 11–21. [Google Scholar] [CrossRef]
- Fields, C.; Natouf, O.; McMains, A.; Henry, C.; Kennington, C. Tiny language models enriched with multimodal knowledge from multiplex networks. In Proceedings of the BabyLM Challenge at the 27th Conference on Computational Natural Language Learning, Singapore, 6–7 December 2023; pp. 47–57. [Google Scholar]
- Jeong, S.; Baek, J.; Cho, S.; Hwang, S.J.; Park, J.C. Test-time self-adaptive small language models for question answering. arXiv 2023, arXiv:2310.13307. [Google Scholar]
- Xu, R.; Huang, Y.; Chen, X.; Zhang, L. Specializing small language models towards complex style transfer via latent attribute pre-training. In ECAI 2023; IOS Press: Amsterdam, The Netherlands, 2023; pp. 2802–2809. [Google Scholar]
- Li, X.; He, S.; Lei, F.; JunYang, J.; Su, T.; Liu, K.; Zhao, J. Teaching Small Language Models to Reason for Knowledge-Intensive Multi-Hop Question Answering. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024; ACL: Bangkok, Thailand, 2024; pp. 7804–7816. [Google Scholar]
- Sterbini, A.; Temperini, M. Open-Source or Proprietary Language Models? An Initial Comparison on the Assessment of an Educational Task. In Proceedings of the 2024 21st International Conference on Information Technology Based Higher Education and Training (ITHET), Paris, France, 6–8 November 2024; pp. 1–7. [Google Scholar]
- Hao, Z.; Jiang, H.; Jiang, S.; Ren, J.; Cao, T. Hybrid SLM and LLM for Edge-Cloud Collaborative Inference. In Proceedings of the Hybrid SLM and LLM for Edge-Cloud Collaborative Inference; ACM: New York, NY, USA, 2024; pp. 36–41. [Google Scholar] [CrossRef]
- Mitchell, E.; Rafailov, R.; Sharma, A.; Finn, C.; Manning, C.D. An emulator for fine-tuning large language models using small language models. In Proceedings of the 12th International Conference on Learning Representations, ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Bergeron, L.; Francois, J.; State, R.; Hilger, J. BLU-SynTra: Distinguish Synergies and Trade-offs between Sustainable Development Goals Using Small Language Models. In Proceedings of the Joint Workshop of the 7th Financial Technology and Natural Language Processing, the 5th Knowledge Discovery from Unstructured Data in Financial Services, and the 4th Workshop on Economics and Natural Language Processing; Chen, C.C., Liu, X., Hahn, U., Nourbakhsh, A., Ma, Z., Smiley, C., Hoste, V., Das, S.R., Li, M., Ghassemi, M., et al., Eds.; Association for Computational Linguistics: Torino, Italia, 2024; pp. 21–33. [Google Scholar]
- Wang, Y.; Tian, C.; Hu, B.; Yu, Y.; Liu, Z.; Zhang, Z.; Zhou, J.; Pang, L.; Wang, X. Can Small Language Models be Good Reasoners for Sequential Recommendation? In Proceedings of the ACM Web Conference 2024, New York, NY, USA, 13–17 May 2024; WWW ’24. pp. 3876–3887. [Google Scholar] [CrossRef]
- Yang, G.; Zhou, Y.; Chen, X.; Zhang, X.; Zhuo, T.Y.; Chen, T. Chain-of-Thought in Neural Code Generation: From and For Lightweight Language Models. arXiv 2024, arXiv:2312.05562. [Google Scholar] [CrossRef]
- Park, J.H.; Lee, M.; Kim, J.; Lee, S. Coconut: Contextualized Commonsense Unified Transformers for Graph-Based Commonsense Augmentation of Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; ACL: Bangkok, Thailand, 2024; pp. 5815–5830. [Google Scholar] [CrossRef]
- Wu, X.; Zhou, H.; Shi, Y.; Yao, W.; Huang, X.; Liu, N. Could Small Language Models Serve as Recommenders? Towards Data-centric Cold-start Recommendation. In Proceedings of the ACM Web Conference 2024, New York, NY, USA, 13–17 May 2024; WWW ’24. pp. 3566–3575. [Google Scholar] [CrossRef]
- Chen, W.L.; Yen, A.Z.; Wu, C.K.; Huang, H.H.; Chen, H.H. ZARA: Improving few-shot self-rationalization for small language models. arXiv 2023, arXiv:2305.07355. [Google Scholar]
- Xiao, R.; Dong, Y.; Zhao, J.; Wu, R.; Lin, M.; Chen, G.; Wang, H. FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models. In Proceedings of the EMNLP 2023-2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 14520–14535. [Google Scholar] [CrossRef]
- Yan, J.; Wang, C.; Zhang, T.; He, X.; Huang, J.; Zhang, W. From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023; ACL: Bangkok, Thailand, 2023; pp. 12413–12425. [Google Scholar] [CrossRef]
- Han, H.; Liang, J.; Shi, J.; He, Q.; Xiao, Y. Small language model can self-correct. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; pp. 18162–18170. [Google Scholar]
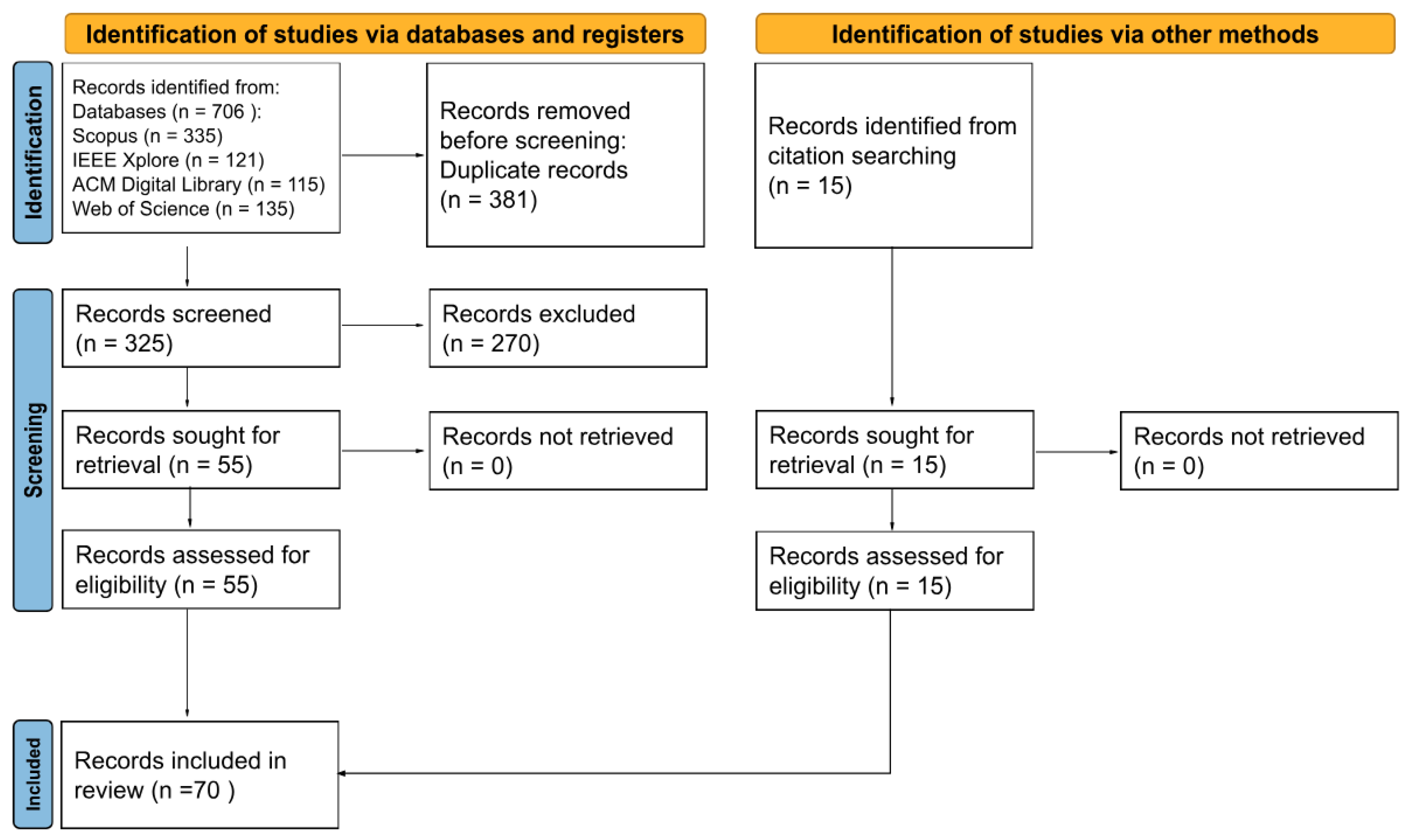

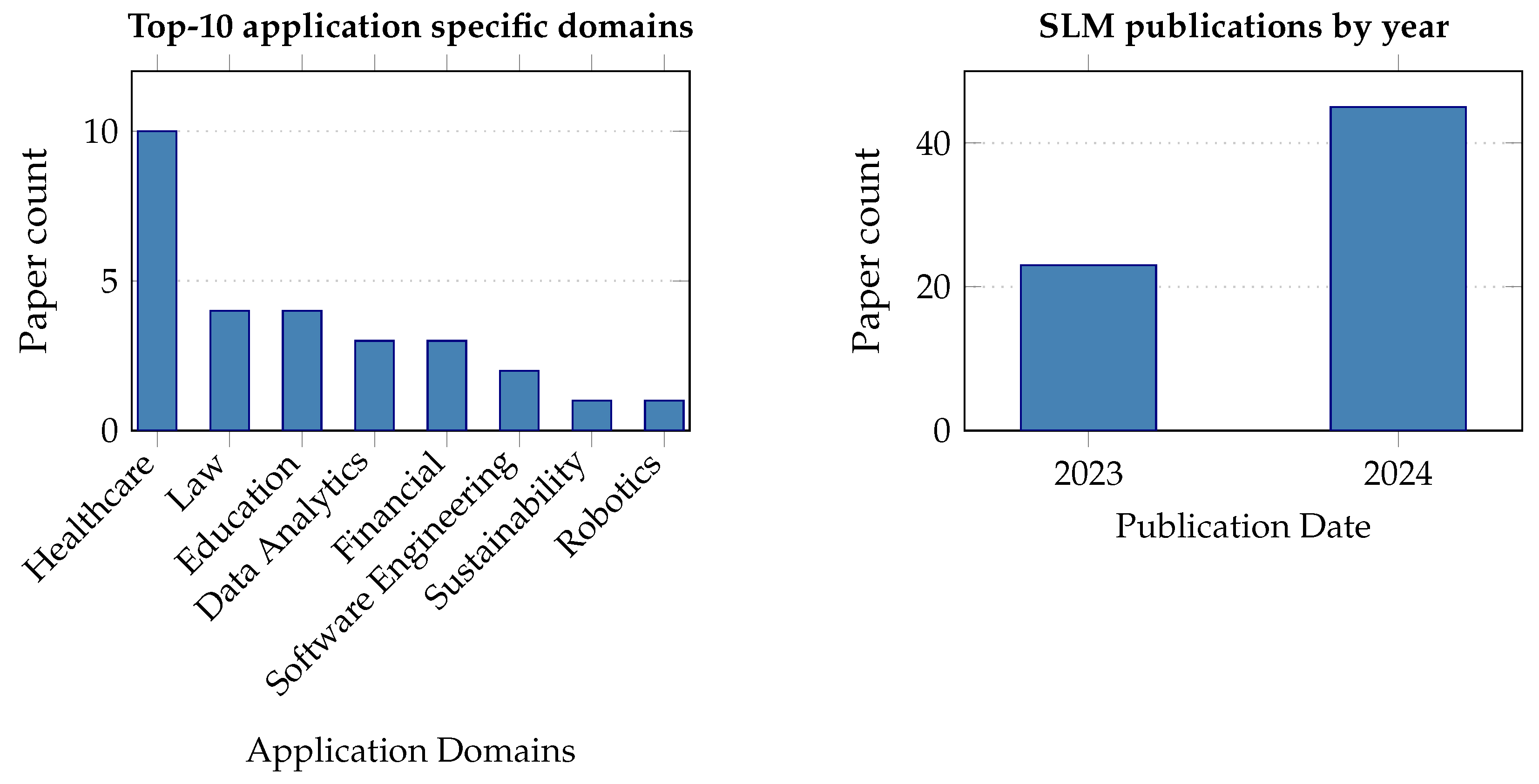
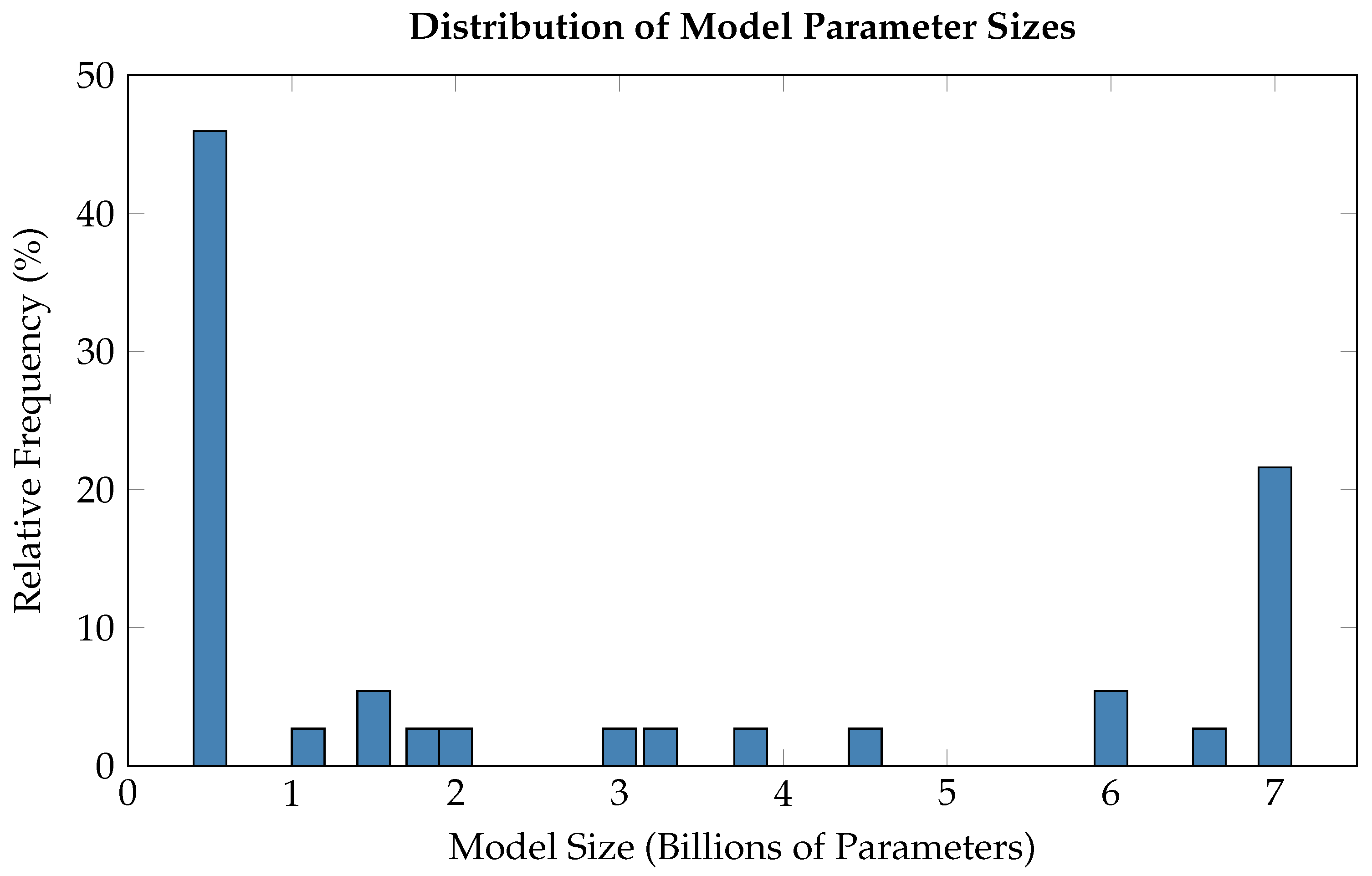
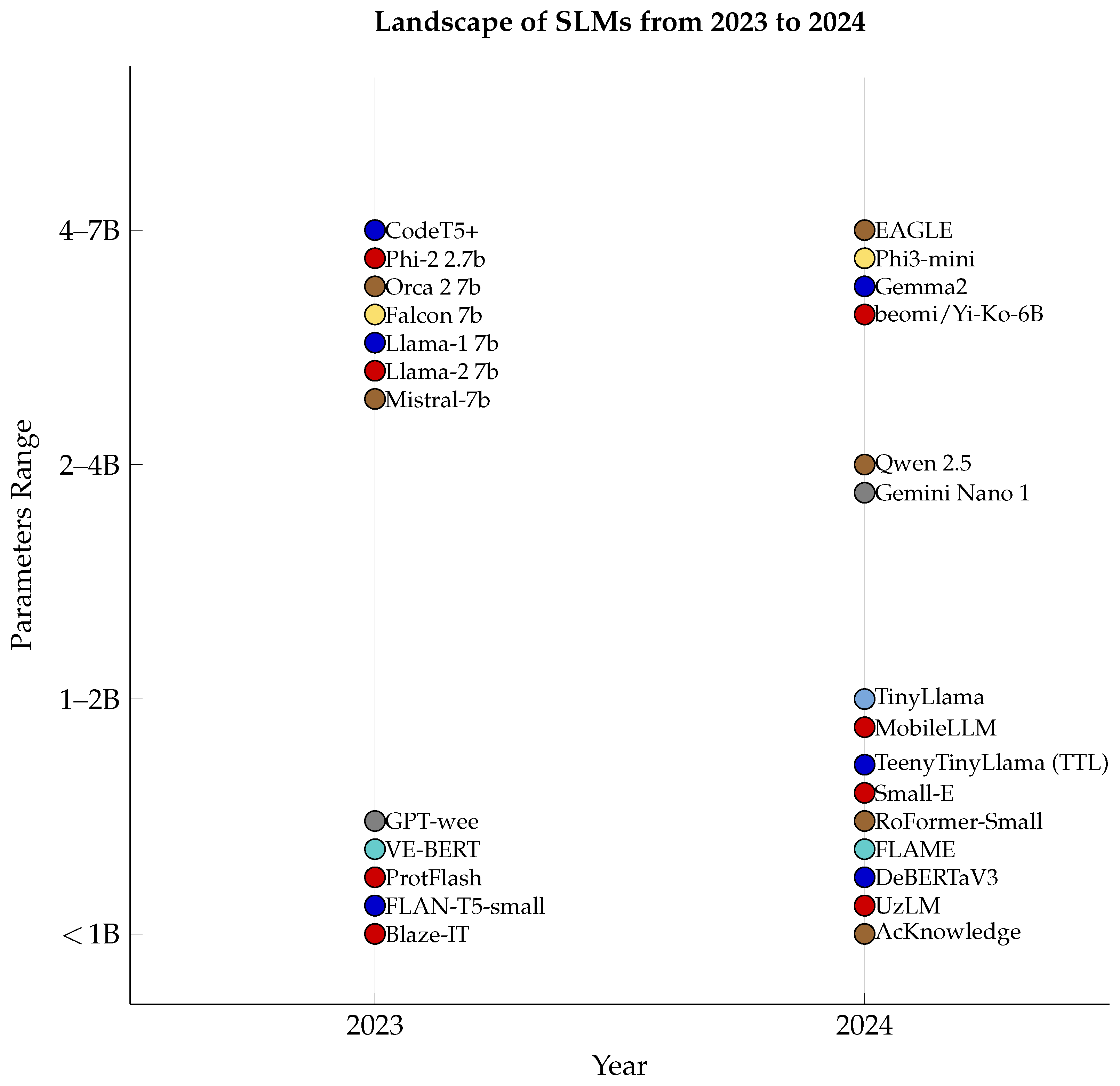
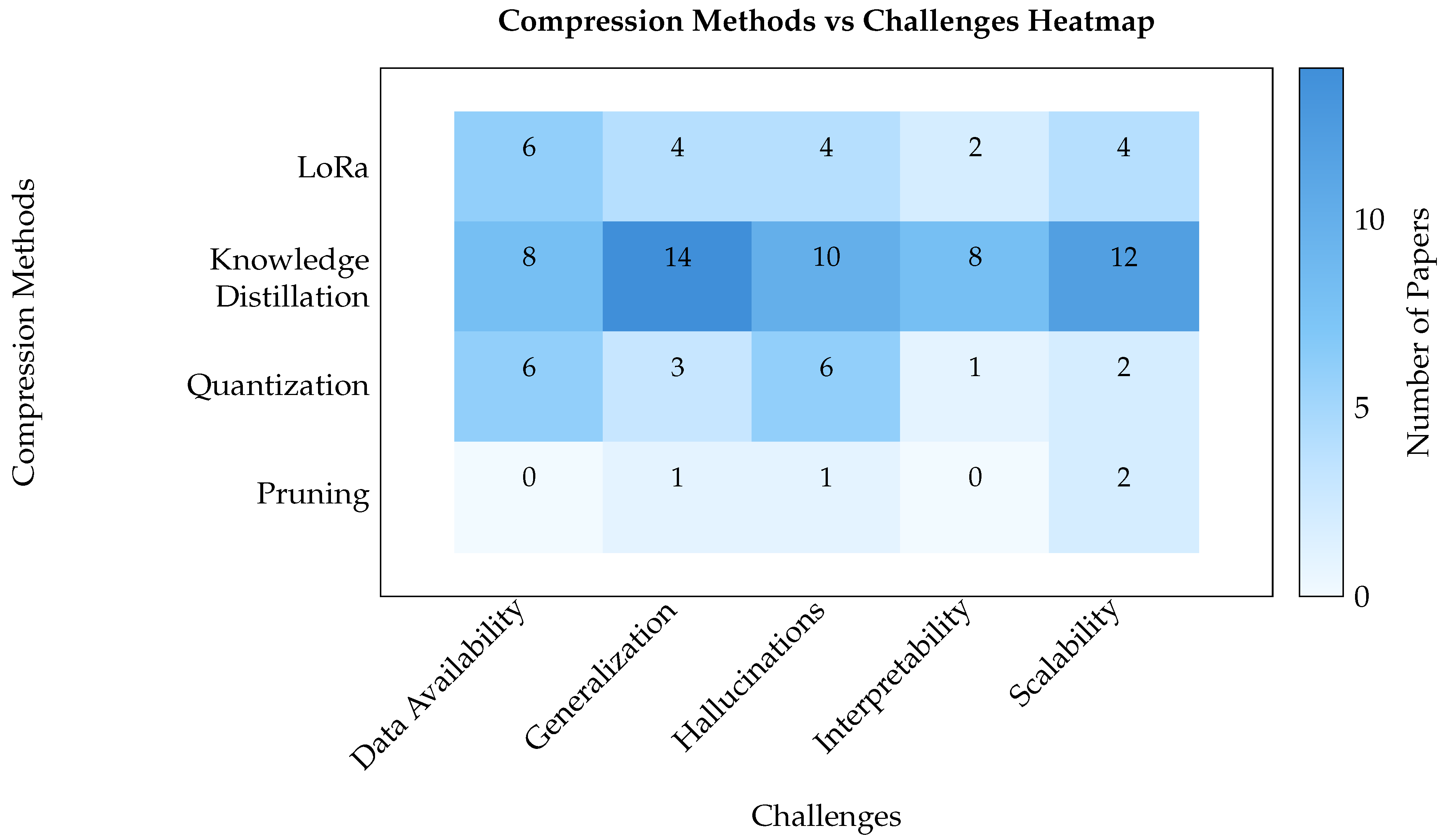

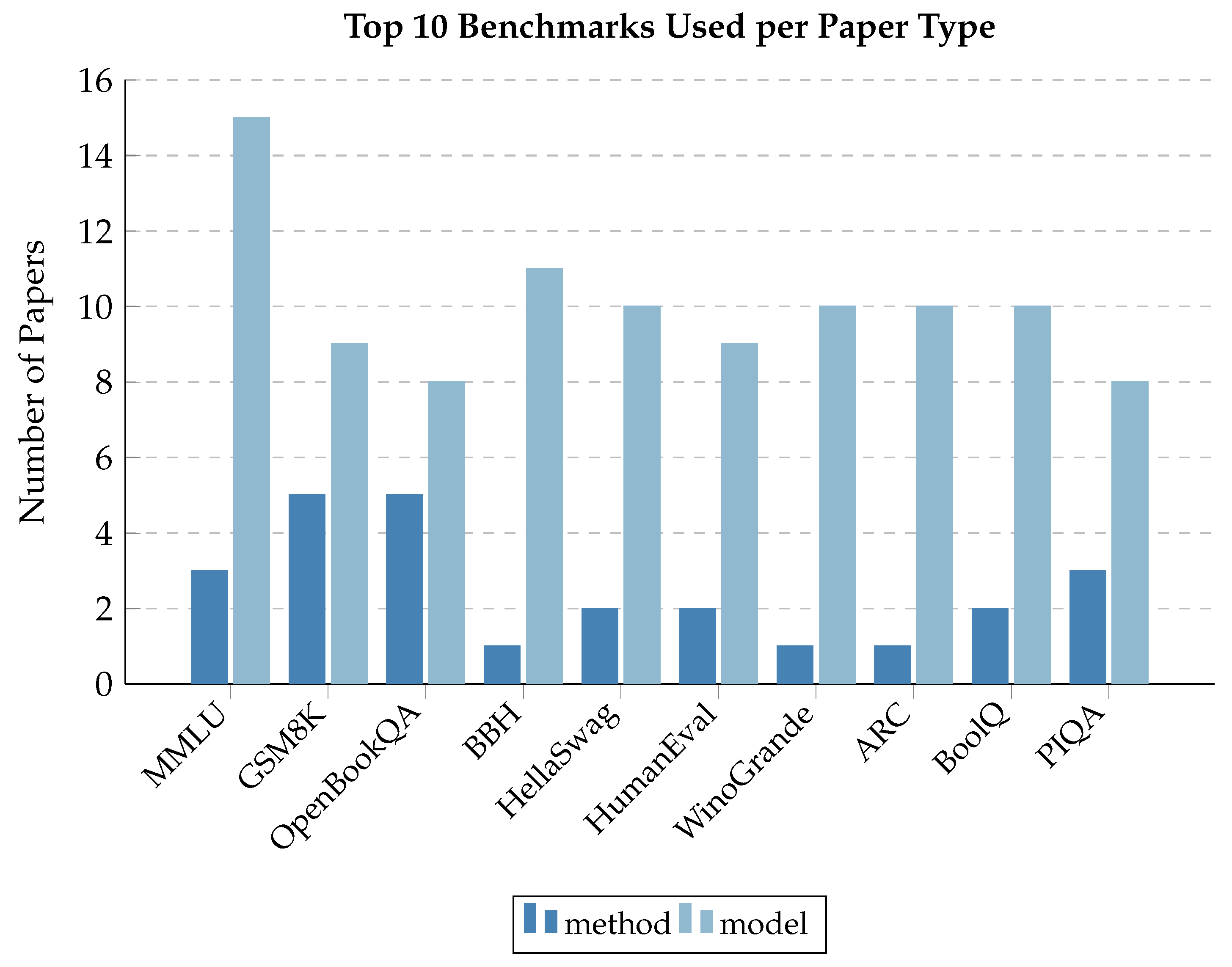

| Feature | SLMs | LLMs |
|---|---|---|
| Parameter Range | from ∼1 M–7B | ≥100B |
| Examples | Mistral 7B, Llama-2 7B | Llama-3.1 450B |
| Performance | Competitive on specific tasks | Emergent capabilities (reasoning, logic) |
| Training Costs | Lower (less energy, fewer resources) | High (energy-intensive, expensive) |
| Inference Speed | Fast; real-time on edge devices | Slower; requires server-class hardware |
| Deployment | Mobile, edge, IoT | Cloud, data center |
| Use Case Fit | Domain-specific fine-tuning | Broad-domain, general-purpose |
| Architecture | Transformer (often decoder-only) | Transformer (decoder-heavy, sometimes mixed) |
| Availability | Many open-source models | Often proprietary or restricted |
| Benchmark | Type of Task |
|---|---|
| BBH | Multistep reasoning |
| MMLU | Multitask language understanding |
| Natural Questions (NQ) | Open-domain question answering |
| SQuADv2 | Reading-comprehension QA |
| GSM8K | Mathematical reasoning |
| MultiArith | Arithmetic reasoning |
| OpenbookQA | Factual QA |
| PIQA | Physical commonsense reasoning |
| SIQA | Social commonsense reasoning |
| ARC | Scientific QA |
| BoolQ | Yes/No question answering |
| Humaneval | Code generation/debugging |
| MATH | Competition-style mathematics |
| MBPP | Code generation (intro) |
| QuAC | Conversational QA |
| TriviaQA | Open-domain trivia QA |
| WinoGrande | Coreference commonsense reasoning |
| SQuAD | Reading-comprehension QA |
| Anthropic Helpful–Harmless | Alignment/safety preference |
| HellaSwag | Commonsense reasoning/NLI |
| COPA | Causal commonsense reasoning |
| Date | Temporal reasoning |
| LAMBADA | Broad-context language modeling |
| RACE | Exam reading-comprehension QA |
| SciQ | Science QA |
| MULTI STS-B | Semantic textual similarity |
| SQuAD-IT | Italian reading-comprehension QA |
| UD Italian ISDT | Dependency parsing |
| WikiNER | Named-entity recognition |
| XGLUE NC | News classification |
| MTEB | Embedding evaluation (mixed tasks) |
| AGIEval | Standardised-exam QA |
| CRASS | Logical reasoning |
| DROP | Discrete numerical reasoning |
| MS-MARCO | Passage retrieval/ranking |
| MT-bench | Multi-turn dialogue evaluation |
| QMSum | Meeting summarisation |
| ToxiGen | Toxic-language detection |
| NDCG@10 | Ranking metric (IR) |
| 2WikiMultiHopQA | Multi-hop QA |
| HotpotQA | Multi-hop QA |
| TydiQA | Multilingual QA |
| CodeSearchNet | Code-to-text retrieval |
| CodeXGLUE | Code understanding/generation (suite) |
| JavaCorpus | Code language-modeling |
| MathQA-Python | Math reasoning with code execution |
| PY150 | Code modeling |
| CommonSenseQA | Commonsense QA |
| NumerSense | Numerical commonsense reasoning |
| QASC | Science QA (abductive) |
| QuaRTz | Qualitative reasoning |
| RiddleSense | Riddle-style commonsense reasoning |
| GeoQuery | Semantic parsing → SQL |
| KaggleDBQA | Text-to-SQL |
| Spider | Text-to-SQL (complex) |
| ML-100K | Recommender systems |
| TAPE | Protein modeling |
| MLPerf Tiny | Edge-device ML performance |
| AlpacaEval | Instruction-following eval |
| ASDiv | Algebraic word problems |
| SVAMP | Algebraic word problems (reasoning) |
| ANLI | Adversarial NLI |
| CQA | Commonsense QA (variant) |
| RAI | Responsible AI |
| E-SNI | Explainable NLI |
| GLUE | General NLU benchmark |
| BLUE | Biomedical NLU benchmark |
| HeadQA | Medical QA (Spanish) |
| MedMCQA | Medical multiple-choice QA |
| MedQA | Medical-exam QA |
| SHP | Helpfulness preference pairs |
| BC5CDR | Biomedical NER |
| CoNLL03 | Named-entity recognition |
| MR | Sentiment analysis |
| SST-2 | Sentiment analysis |
| SUBJ | Subjectivity classification |
| TREC | Question-type classification |
| Math23K | Math word problems |
| BLIMP | Linguistic phenomena probing |
| MSGS | Morphological segmentation |
| WikiSQL | Text-to-SQL |
| StrategyQA | Strategic multi-hop QA |
| QAMPARI | List-type open-domain QA |
| WikiQA | Open-domain QA |
| C4 | Language-model perplexity (pre-train) |
| SNLI | Natural-language inference |
| ROUGE-L | Summarization metric |
| G-Eval | LLM-as-judge eval metric |
| RealToxicity | Toxic-language detection |
| GPQA | Graduate-level physics QA |
| TruthfulQA | Truthfulness QA |
| AlignBench | Alignment evaluation benchmark |
| Arena-Hard | Hard preference-ranking eval |
| EvalPlus | Code-generation evaluation |
| IFEval | Instruction-following eval |
| LiveCodeBench | Live coding eval |
| MMLU-Pro | Professional-level MMLU |
| MixEval | Mixed-instruction eval |
| NeedleBench | Retrieval “needle-in-haystack” eval |
| Theorem QA | Theorem-proving QA |
| LibriTTS (test) | Speech-synthesis (TTS) test set |
| GYAFC | Style transfer (formal - informal) |
| MAWPS | Math word problems |
| SuperGLUE | Advanced NLU benchmark |
| Audio ASR | Automatic speech recognition |
| AudioCaps | Audio captioning |
| ChartQA | Visual QA (charts) |
| MMBench | Multimodal eval benchmark |
| MMMU | Multimodal multitask understanding |
| ScienceQA | Multimodal science QA |
| COMVE | Commonsense validation |
| E-SNL | Explainable NLI |
| ECQA | Explainable commonsense QA |
| SBIC | Social-bias identification |
| Challenge | Focus Area | Solutions Proposed |
|---|---|---|
| Scalability | Model Size Reduction | Weight pruning (sparsity), Ultra-low-bit quantization (4-bit/2-bit), Hardware-aware calibration |
| Inference Efficiency | Test-Time Scaling (TTS), Iterative decoding, Majority-voting strategies | |
| Knowledge Transfer | Neural-Symbolic Collaborative Distillation, Skill-knowledge decoupling, External knowledge bases | |
| Interpretability | Model Transparency | Cluster-ability loss objectives, Disentangled MoE experts, Non-overlapping experts |
| Decision Explanation | Explanation validation, Transparency, Interpretability, Modularity, Reasoning benchmarks, Human-in-the-loop evaluation | |
| Hallucinations | Evaluation Methods | OnionEval unified framework, DiaHalu dialogue benchmark, Context-influence scoring |
| Truthfulness Training | Teacher–student distillation, “I don’t know” uncertainty prompts, Rationalized training | |
| Generation Control | Knowledge-overshadowing analysis, Contrastive Decoding (CODE), Fact amplification | |
| Generalization | Architecture Design | Mixture-of-Experts, Retrieval-augmented generation, Multi-task instruction tuning |
| Knowledge Distillation | Teacher–student and Chain-of-thought distillation, Orca explanation tuning | |
| Domain Adaptation | Meta-learning, Domain-specific adapters, LoRA-based adaptation | |
| Data Scarcity | Synthetic Data | LLM-generated corpora, Automated quality filtering, Pipeline-driven corpora |
| Low-Resource Learning | Parameter-efficient fine-tuning (PEFT), Cross-lingual transfer, Meta-learning with sparse data | |
| Benchmark Creation | Knowledge-base integration, Linguistic resource enrichment, Low-resource scenarios |
| Technique | Generalization | Data Avail. | Hallucinations | Scalability | Interpretability |
|---|---|---|---|---|---|
| Knowledge Distillation [49,50,51,52,53] | ✓ | ✓ | ✓ | ✓ | |
| LoRA/Adapter Tuning [56,58,59] | ✓ | ✓ | ✓ | ||
| Quantization (8-bit, 4-bit) [54,55,56,60] | ✓ | ||||
| Chain-of-Thought Training [47,65,71] | ✓ | ✓ | ✓ | ||
| Synthetic Data Generation [44,63,73] | ✓ | ||||
| Contrastive Decoding (CODE) [78] | ✓ | ||||
| Pruning/Sparse Models [57] | ✓ | ||||
| Mixture-of-Experts (MoE) [10,85] | ✓ | ✓ | ✓ | ||
| Modular Architectures [84] | ✓ | ||||
| RAI Benchmarks/Rationalized Evaluation [47,60,75] | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corradini, F.; Leonesi, M.; Piangerelli, M. State of the Art and Future Directions of Small Language Models: A Systematic Review. Big Data Cogn. Comput. 2025, 9, 189. https://doi.org/10.3390/bdcc9070189
Corradini F, Leonesi M, Piangerelli M. State of the Art and Future Directions of Small Language Models: A Systematic Review. Big Data and Cognitive Computing. 2025; 9(7):189. https://doi.org/10.3390/bdcc9070189
Chicago/Turabian StyleCorradini, Flavio, Matteo Leonesi, and Marco Piangerelli. 2025. "State of the Art and Future Directions of Small Language Models: A Systematic Review" Big Data and Cognitive Computing 9, no. 7: 189. https://doi.org/10.3390/bdcc9070189
APA StyleCorradini, F., Leonesi, M., & Piangerelli, M. (2025). State of the Art and Future Directions of Small Language Models: A Systematic Review. Big Data and Cognitive Computing, 9(7), 189. https://doi.org/10.3390/bdcc9070189