
Integration of Associative Tokens into Thematic Hyperspace: A Method for Determining Semantically Significant Clusters in Dynamic Text Streams

 ,
,
Abstract
1. Introduction
1.1. Motivation and Context
- -
- Monitor public opinion: track the dynamics of discussions of certain topics in social media, which allows you to identify changes in public sentiment, anticipate potential crises, and respond to them in a timely manner.
- -
- Analyze market trends: study the dynamics of discussions of products and services in online reviews and forums helps companies understand consumer needs, forecast demand, and adapt their strategies.
- -
- Analyze the dynamics of scientific publications on a specific topic: track the development of scientific thought, identify promising areas of research, and assess the impact of various factors on scientific progress.
1.2. Research Gap in Dynamic Topic Modelling
- Quantify topic salience within a specified time interval on a comparable scale;
- Account for context by evaluating a topic’s activity relative to other topics and to the total volume of documents;
- Filter noise, highlighting statistically significant changes via time-series techniques;
- Remain interpretable, enabling analysts to spot topics that are rising or fading and to act accordingly.
1.3. Conceptual Foundations
- Trend detection: Dynamic analysis allows you to track changes in interest in certain topics over time, identify growing and fading trends, and predict future trends. This is especially important in a rapidly changing information environment, where static “snapshots” of data quickly become outdated.
- Data contextualization: Taking into account the temporal context helps to understand how external events and factors influence topical activity. For example, a sharp surge in interest in a certain topic can be associated with a specific event, news publication, or social action.
- Cause-and-effect analysis: A dynamic approach allows you to explore cause-and-effect relationships between different topics and external factors. For example, you can analyze how changes in one topic affect the dynamics of another, or how external events lead to a change in the topic landscape.
- Forecasting: Analysis of time series of topical signals allows you to build forecast models and predict future changes in topical activity. This can be useful for making strategic decisions in a variety of areas, from marketing and PR to political analysis and risk management.
- Improved visualization: Dynamic data can be effectively visualized using graphs, charts, and other tools, making the analysis results easier to understand and interpret.
- The semantic component (S), reflecting the semantic core of the topic, its conceptual content, and logical connections between elements. This parameter encodes the deep linguistic and cognitive characteristics that determine the essence of the thematic formation.
- Spatial distribution (X), describing the topology of the location of thematic markers in the structure of the text corpus. This aspect takes into account the features of the distribution of lexical units, their mutual location, and frequency characteristics in various segments of the analyzed data array.
- Temporal dynamics (t), recording evolutionary changes in the topic in the time continuum. This parameter is especially important when analyzing news feeds, scientific publications, or other types of data that have a pronounced time structure.
- 2.
- TF-IDF (Term Frequency-Inverse Document Frequency) is an improved version of the frequency approach, which introduces weighting of the significance of terms:
- 3.
- 4.
- Latent semantic analysis (LSA) uses the singular value decomposition (SVD) of the term-document matrix:
- 5.
- Topic modeling (LDA) considers documents as probabilistic mixtures of topics and topics as word distributions:
- Objectively limiting the number of identified topics;
- Increasing the stability of topic models;
- Improving the interpretability of analysis results.
- Limited ability to process dynamic content and new domains;
- Lack of mechanisms for quantitative assessment of semantic noise;
- Inability to objectively determine the optimal number of thematic clusters;
- Dependence on static training samples;
- High computational costs when working with large volumes of data.
- Integrates a complex of token associations into a thematic hyperspace;
- Ensures control of thematic entropy through formalized metrics;
- Allows for objective determination of the maximum number of significant topics;
- Provides a quantitative assessment of the level of information noise;
- Maintains computational efficiency when working with big data.
1.4. Paper Road-Map
2. Materials and Methods
- It models documents as a mixture of topics, and topics as a mixture of words. This approach accounts for uncertainty and can handle noisy data better.
- It scales well to large amounts of data.
- It effectively models the “sparseness” of topics: each topic is described by only a small number of keywords, and each document has strong connections to only a few topics. This makes the results more accurate and plausible.
- 1.
- For each topic , “” is inversely proportional to its uncertainty:—энт is the entropy associated with the distribution of words in topic .
- 2.
- describes the relative contribution of a topic to the overall reduction in uncertainty. The higher the “”, the less uncertainty (entropy) a topic contributes.
- 3.
- For the joint space , the decrease in the level of reflects the overall decrease in entropy:
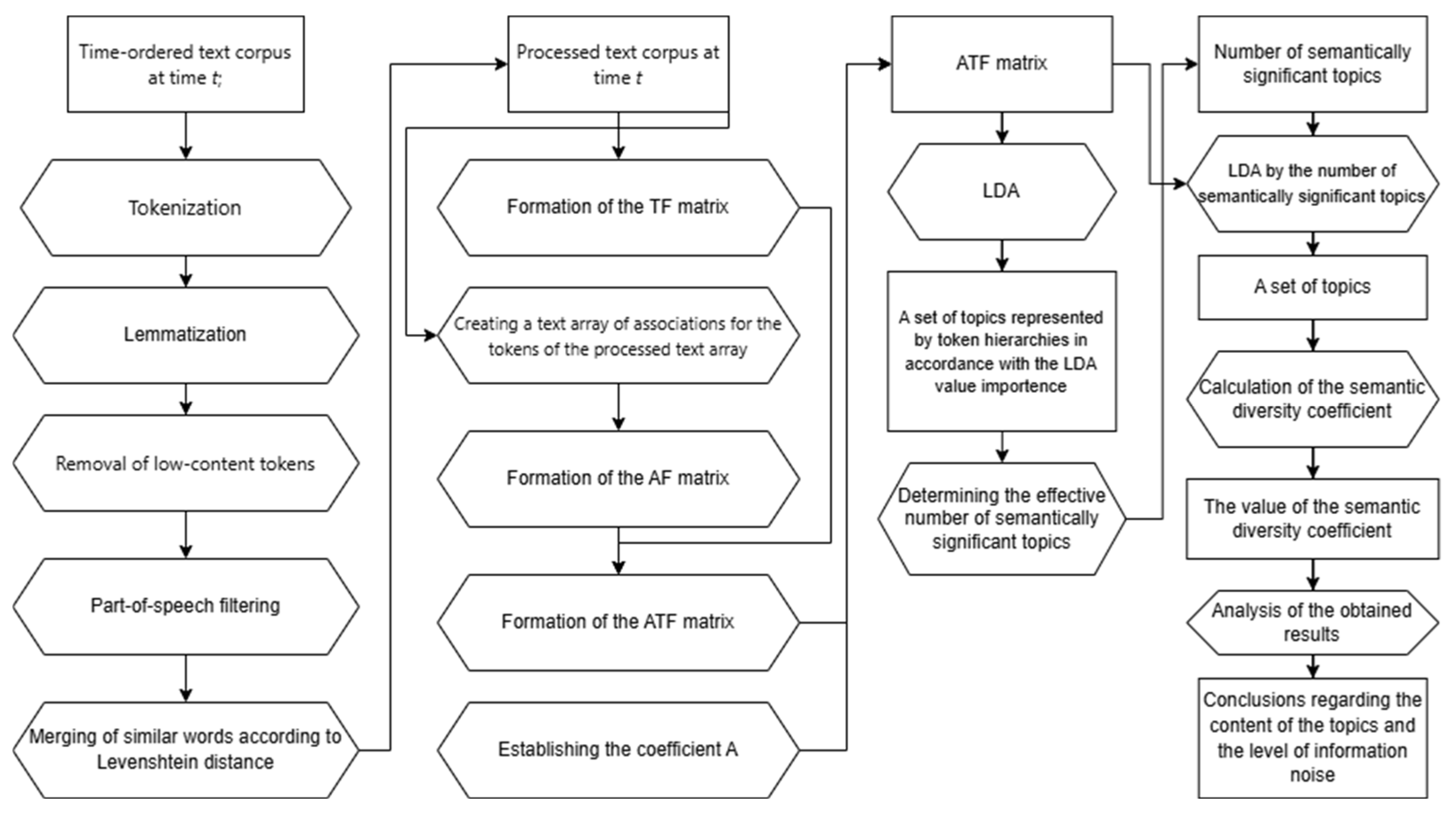
| Algorithm 1. Associative-Token Dynamic Topic Model (ATe-DTM)—step-by-step pseudocode of the proposed method |
| Algorithm 1: Associative-Token Dynamic Topic Model (ATe- DTM) Input: Corpus C = {d1,…,dN}; Yandex Associative Thesaurus Y; time-slice width ∆t; blending weights (α,β) with α+ β=1 Output: Topic-time matrix Ө; thematic-signal series F(T) 1. Pre-processing: tokenise and lemmatise each di; remove stop-words; assign time-stamp ti 2. Build lexical matrix: compute term-frequency matrix Mω,d and document lengths |di|; 3. Extract associative tokens: foreach lemma ω ε V do query γ with ω; keep up to five associates a1, …, ak having confidence c(aj) ≥ 0.30; 4. Construct association matrix A ω’,d; min-max normalise c(aj)→[0, 1] and scale by document length; 5. Blend matrices: M′ ‹– αM + βA; 6. Grid-search (α,β) (optional): evaluate topic-coherence C and semantie-diversity S on a 10% validation set; select (α,β) = arg max (α,β)(C-S) 7. Dynamic topic modelling: apply time-slice LDA to M’ to obtain Өk,t; 8. Compute thematic signal: Fk(t) = KL(Pk,t|| Po); 9. Post-processing: compute entropy reduction ∆H, noise index Z noise, and derive optimal cluster count Koptimal |
- Time-slice acquisition. At every discrete instant t, the documents that have arrived since the previous slice are appended to a time-ordered corpus; this batch is the raw input for all subsequent operations.
- Tokenization. Each document is split into lexical tokens using language-specific rules that handle punctuation, numerals, emojis, and multi-word expressions.
- Lemmatization. Tokens are normalized to their base (lemma) forms with SpaCy’s morphological analyzer (e.g., running → run), thereby reducing sparsity in highly inflected languages.
- Low-content removal. Stop-words, digits, one-letter strings, and tokens whose corpus frequency is <5 are discarded, eliminating elements that carry no topical information.
- Part-of-speech filtering. Only nouns, proper nouns, verbs, and adjectives are retained because they convey the strongest semantic signal for topic modelling.
- String-similarity merging. Residual near-duplicates (e.g., American vs. British spelling) are merged when their Levenshtein distance ≤ 2; the most frequent variant is kept. Steps 2–6 yield the processed text corpus for slice t.
- TF matrix construction (TF). A sparse matrix is built in which each entry stores the term-frequency of token i in document j.
- Association retrieval. For every lemma, the Yandex Associative Thesaurus returns up to five associates whose confidence ≥ 0.30; these form the association text array.
- AF matrix construction (AF). The frequencies of the associates are encoded into a second matrix of identical dimensionality.
- ATF blending. The lexical and associative spaces are fused as with the empirically tuned balance α = 0.7, β = 0.3, which maximises topic coherence on a held-out validation set.
- Topic modelling with LDA. Latent Dirichlet Allocation is applied to the ATF matrix, producing (i) a ranked token hierarchy for every topic and (ii) a topic distribution for each document and time slice.
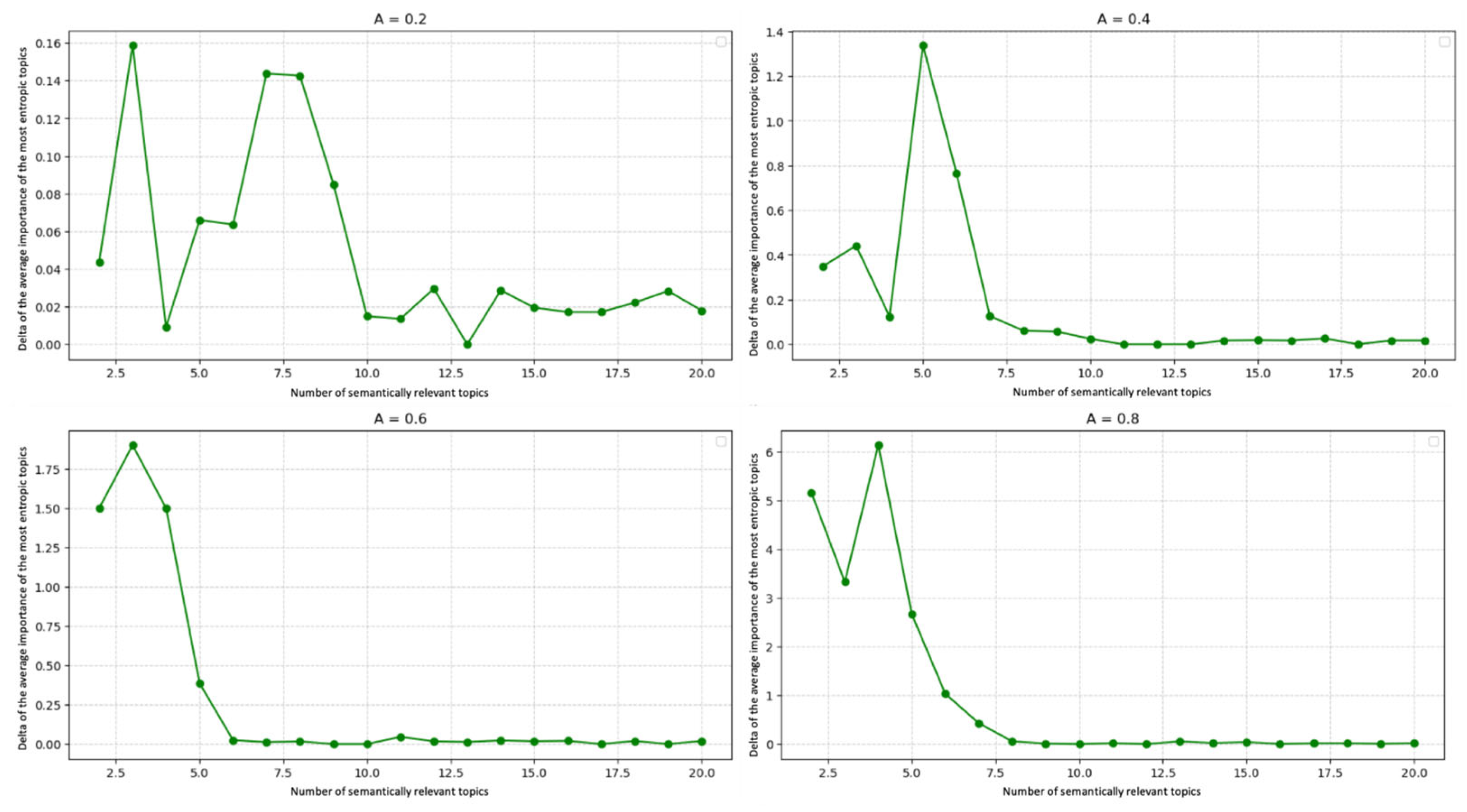
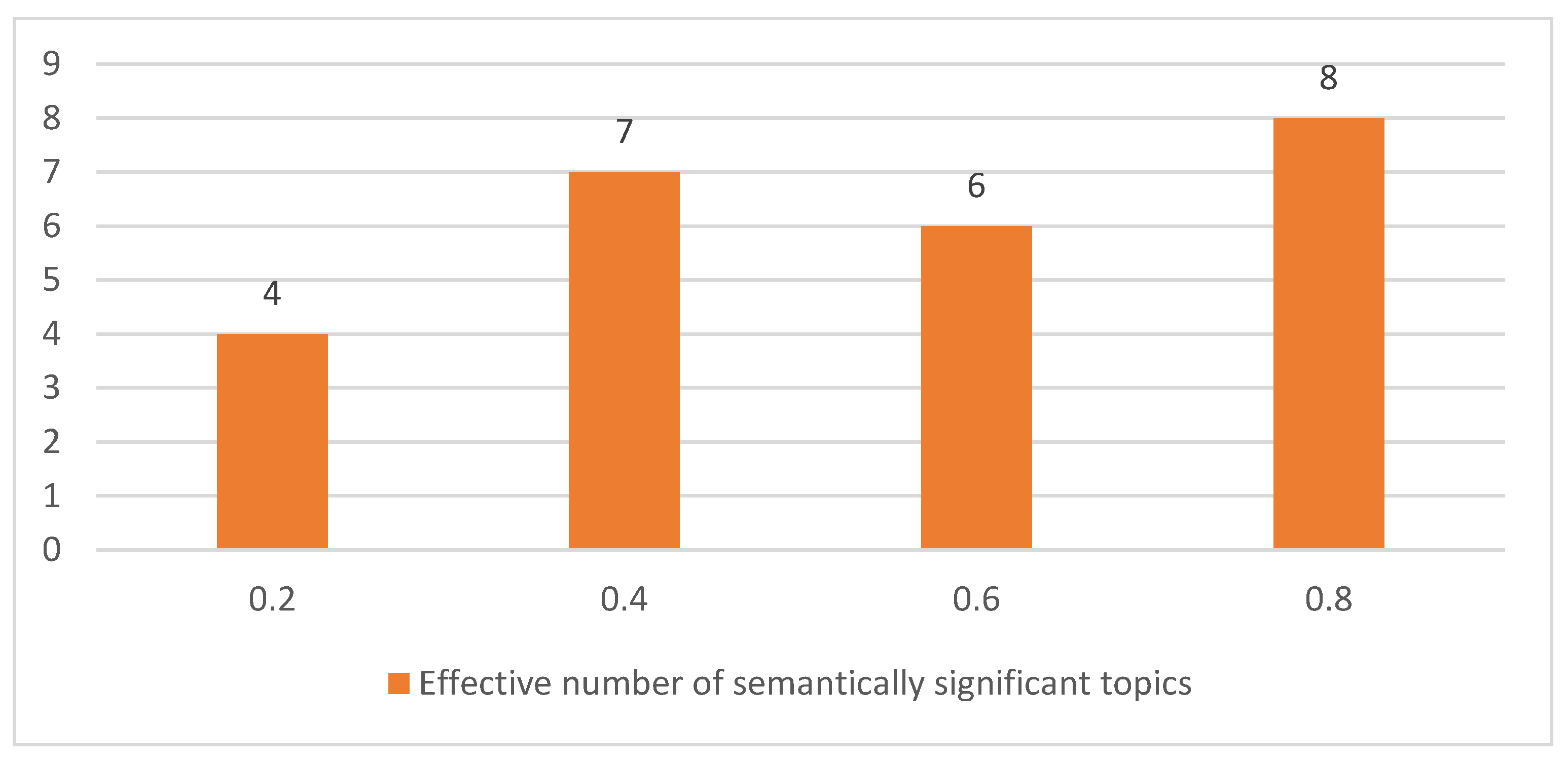
- Effective topic count selection. LDA is re-run for ; for each K, we compute entropy reduction ΔH and the semantic-diversity coefficient . The elbow where both curves plateau is adopted as the number of semantically significant topics.
- Semantic-diversity coefficient. For the optimal K, we report (average Jaccard overlap of the top 20 tokens across topics) as an objective indicator of information noise.
- Result analysis. The final topic set and their time-series curves are inspected: sharp surges denote emerging issues, while flat or declining curves indicate fading interest.
- Conclusions. From these outputs, the analyst derives (a) the semantic content of each topic, (b) the overall noise level, and (c) actionable insights such as trend forecasts or anomaly alerts.
3. Results
3.1. Dataset Description
3.2. Experimental Pipeline
- Normalization and lemmatization of text material;
- Construction of vector representations of documents;
- Application of the topic modeling algorithm;
- Quantitative assessment of the clustering quality;
- Semantic interpretation of the obtained results.
- International politics: the core of the cluster is formed by the terms “vote”, “voting”, “democrat”, “medvedev”, “congress”, “impeachment”, and “biden”, reflecting the main trends of the world political agenda of the studied period.
- Domestic political processes: the dominant lexemes “russia”, “president”, “usa”, “ukraine”, and “putin” characterize the key areas of domestic and foreign policy.
- Sports topics: the terms “club”, “match”, “team”, and “score” form a compact semantic cluster with a high degree of coherence.
- Economic news: the lexical units “increase”, “asset”, “tax”, and “volume” reflect the main economic trends.
- Emergencies: the cluster with the keywords “earthquake”, “magnitude”, and “shock” demonstrates high thematic integrity.
- Background semantic noise: result, October, data, region, EMERCOM, car, degree, city, and district.
- Background semantic noise: formula, signature, purchase, comparison, guy, model, volume, gas, half, and asset
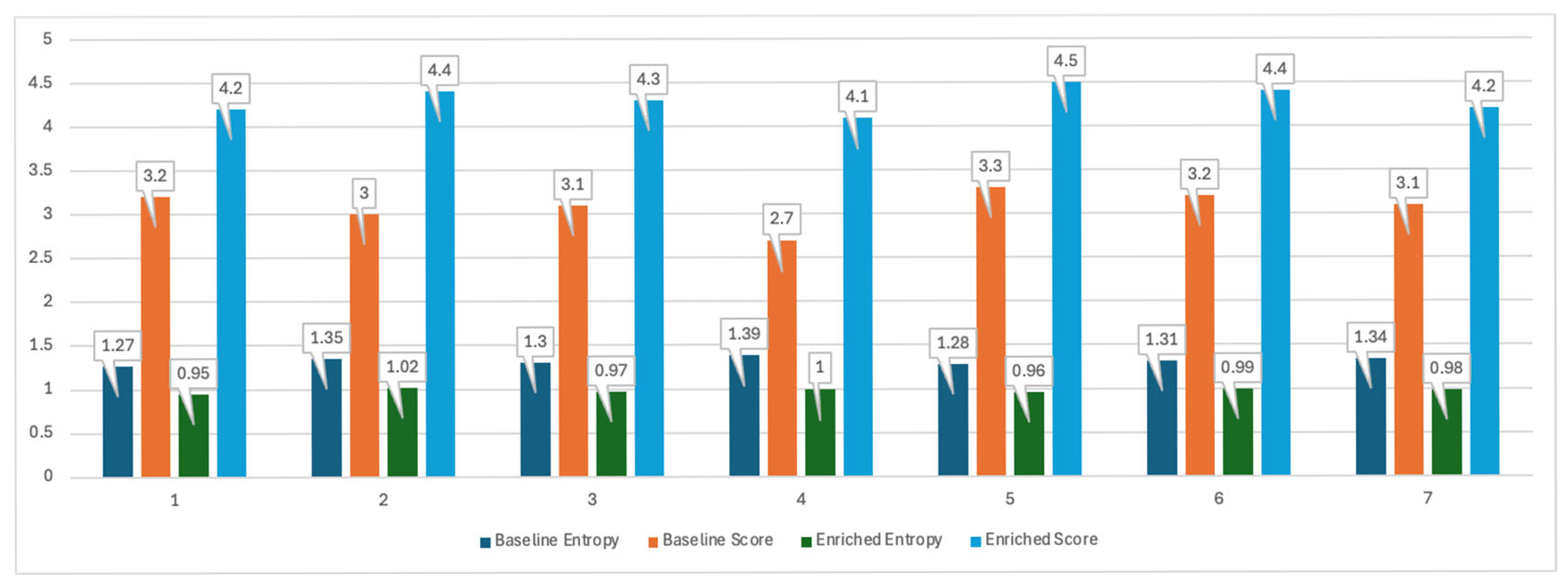
- An increase in the semantic coherence of thematic clusters;
- A decrease in the degree of overlap between different topics;
- An increase in the discriminative ability of the algorithm.
- Entropy reduction, which measures the drop in thematic entropy relative to the raw token stream (larger values are better);
- Semantic-diversity coefficient, which reflects inter-topic lexical overlap (smaller values indicate purer, less noisy clusters).
4. Discussion
- The ability to quantify information noise through a formalized indicator Znoise = ∑z(wj);
- An objective mechanism for determining the optimal number of topics Koptimal = argmin_K(H(T) + Z_noise(K));
- Improved interpretability of results by filtering out noise topics;
- Maintaining the semantic integrity of clusters while reducing entropy.
- Adapting the method to work with multilingual corpora and specialized terminologies;
- Developing dynamic versions of the algorithm for analyzing thematic evolution over time;
- Integration with modern neural network architectures;
- Creating automated systems for adjusting model parameters;
- Studying the possibilities of applying the method to short texts (social media messages).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, S.U.; Namin, A.S. A Survey on Chatbots and Large Language Models: Testing and Evaluation Techniques. Nat. Lang. Process. J. 2025, 10, 100128. [Google Scholar] [CrossRef]
- Garcia, A.V.; Minami, M.; Mejia-Rodríguez, M.; Ortíz-Morales, J.R.; Radice, F. Large Language Models in Orthopedics: An Exploratory Research Trend Analysis and Machine Learning Classification. J. Orthop. 2025, 66, 110–118. [Google Scholar] [CrossRef]
- Shankar, R.; Bundele, A.; Mukhopadhyay, A. A Systematic Review of Natural Language Processing Techniques for Early Detection of Cognitive Impairment. Mayo Clin. Proc. Digit. Health 2025, 3, 100205. [Google Scholar] [CrossRef] [PubMed]
- Manion, F.J.; Du, J.; Wang, D.; He, L.; Lin, B.; Wang, J.; Wang, S.; Eckels, D.; Cervenka, J.; Fiduccia, P.C. Accelerating Evidence Synthesis in Observational Studies: Development of a Living Natural Language Processing–Assisted Intelligent Systematic Literature Review System. JMIR Med. Inform. 2024, 12, e54653. [Google Scholar] [CrossRef] [PubMed]
- Regla, A.I.; Ballera, M.A. An Enhanced Research Productivity Monitoring System for Higher Education Institutions (HEI’s) with Natural Language Processing (NLP). Procedia Comput. Sci. 2023, 230, 316–325. [Google Scholar] [CrossRef]
- Kaczmarek, I.; Iwaniak, A.; Świetlicka, A.; Piwowarczyk, M.; Nadolny, A. A Machine Learning Approach for Integration of Spatial Development Plans Based on Natural Language Processing. Sustain. Cities Soc. 2022, 76, 103479. [Google Scholar] [CrossRef]
- Francia, M.; Gallinucci, E.; Golfarelli, M. Automating Materiality Assessment with a Data-Driven Document-Based Approach. Int. J. Inf. Manag. Data Insights 2025, 5, 100310. [Google Scholar] [CrossRef]
- Maibaum, F.; Kriebel, J.; Foege, J.N. Selecting Textual Analysis Tools to Classify Sustainability Information in Corporate Reporting. Decis. Support Syst. 2024, 183, 114269. [Google Scholar] [CrossRef]
- Schintler, L.A.; McNeely, C.L. Artificial Intelligence, Institutions, and Resilience: Prospects and Provocations for Cities. J. Urban Manag. 2022, 11, 256–268. [Google Scholar] [CrossRef]
- Gepp, A.; Linnenluecke, M.K.; O’neill, T.J.; Smith, T. Big Data Techniques in Auditing Research and Practice: Current Trends and Future Opportunities. J. Account. Lit. 2018, 40, 102–115. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Rosen, R. Life Itself: A Comprehensive Inquiry into the Nature, Origin, and Fabrication of Life; Columbia University Press: New York, NY, USA, 1991; ISBN 0231075642. [Google Scholar]
- Gershenfeld, N. The Physics of Information Technology; Cambridge University Press: Cambridge, UK, 2000; ISBN 0521580447. [Google Scholar]
- Landauer, R. Irreversibility and Heat Generation in the Computing Process. IBM J. Res. Dev. 1961, 5, 183–191. [Google Scholar] [CrossRef]
- Bekenstein, J.D. Black Holes and the Second Law. In Jacob Bekenstein: The Conservative Revolutionary; World Scientific: Singapore, 2020; pp. 303–306. [Google Scholar]
- Ellerman, D. Introduction to Logical Entropy and Its Relationship to Shannon Entropy. arXiv 2021, arXiv:2112.01966. [Google Scholar]
- Xu, P.; Sayyari, Y.; Butt, S.I. Logical Entropy of Information Sources. Entropy 2022, 24, 1174. [Google Scholar] [CrossRef] [PubMed]
- Çengel, Y.A. A Concise Account of Information as Meaning Ascribed to Symbols and Its Association with Conscious Mind. Entropy 2023, 25, 177. [Google Scholar] [CrossRef] [PubMed]
- Manzotti, R. A Deflationary Account of Information in Terms of Probability. Entropy 2025, 27, 514. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhang, T.; Xi, B. Information Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- McKenzie, D.P. Plate Tectonics and Its Relationship to the Evolution of Ideas in the Geological Sciences. Daedalus 1977, 97–124. [Google Scholar]
- Chernavskaya, O.D.; Chernavskii, D.S. Natural-Constructive Approach to Modeling the Cognitive Process. Biophysics 2016, 61, 155–169. [Google Scholar] [CrossRef]
- Munappy, A.R.; Bosch, J.; Olsson, H.H.; Arpteg, A.; Brinne, B. Data Management for Production Quality Deep Learning Models: Challenges and Solutions. J. Syst. Softw. 2022, 191, 111359. [Google Scholar] [CrossRef]
- Nevalainen, P.; Lamberg, J.-A.; Seppälä, J.; Mattila, P. Executive Training as a Turning Point in Strategic Renewal Processes. Long Range Plann. 2025, 58, 102510. [Google Scholar] [CrossRef]
- Li, M.; Liu, Y.; Liu, H. Analysis of the Problem-Solving Strategies in Computer-Based Dynamic Assessment: The Extension and Application of Multilevel Mixture IRT Model. Acta Psychol. Sin. 2020, 52, 528–540. [Google Scholar] [CrossRef]
- Churchill, R.; Singh, L. The Evolution of Topic Modeling. ACM Comput. Surv. 2022, 54, 1–35. [Google Scholar] [CrossRef]
- Vayansky, I.; Kumar, S.A.P. A Review of Topic Modeling Methods. Inf. Syst. 2020, 94, 101582. [Google Scholar] [CrossRef]
- Passalis, N.; Tefas, A. Learning Bag-of-Embedded-Words Representations for Textual Information Retrieval. Pattern Recognit. 2018, 81, 254–267. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Modest-Vocabulary Loop-Closure Detection with Incremental Bag of Tracked Words. Rob. Auton. Syst. 2021, 141, 103782. [Google Scholar] [CrossRef]
- Choi, J.; Lee, S.-W. Improving FastText with Inverse Document Frequency of Subwords. Pattern Recognit. Lett. 2020, 133, 165–172. [Google Scholar] [CrossRef]
- Lakshmi, R.; Baskar, S. Novel Term Weighting Schemes for Document Representation Based on Ranking of Terms and Fuzzy Logic with Semantic Relationship of Terms. Expert Syst. Appl. 2019, 137, 493–503. [Google Scholar] [CrossRef]
- Attieh, J.; Tekli, J. Supervised Term-Category Feature Weighting for Improved Text Classification. Knowl.-Based Syst. 2023, 261, 110215. [Google Scholar] [CrossRef]
- Kim, S.; Park, H.; Lee, J. Word2vec-Based Latent Semantic Analysis (W2V-LSA) for Topic Modeling: A Study on Blockchain Technology Trend Analysis. Expert Syst. Appl. 2020, 152, 113401. [Google Scholar] [CrossRef]
- Sharma, A.; Kumar, S. Ontology-Based Semantic Retrieval of Documents Using Word2vec Model. Data Knowl. Eng. 2023, 144, 102110. [Google Scholar] [CrossRef]
- Rkia, A.; Fatima-Azzahrae, A.; Mehdi, A.; Lily, L. NLP and Topic Modeling with LDA, LSA, and NMF for Monitoring Psychosocial Well-Being in Monthly Surveys. Procedia Comput. Sci. 2024, 251, 398–405. [Google Scholar] [CrossRef]
- Indasari, S.S.; Tjahyanto, A. Decision Support Model in Compiling Owner Estimate for Fmcgs Products from Various Marketplaces with Tf-Idf and Lsa-Based Clustering. Procedia Comput. Sci. 2024, 234, 455–462. [Google Scholar] [CrossRef]
- Zimmermann, J.; Champagne, L.E.; Dickens, J.M.; Hazen, B.T. Approaches to Improve Preprocessing for Latent Dirichlet Allocation Topic Modeling. Decis. Support Syst. 2024, 185, 114310. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic Modeling: Models, Applications, a Survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The Evolution of Sentiment Analysis—A Review of Research Topics, Venues, and Top Cited Papers. Comput. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef]
- Shah, A.; Shah, H.; Bafna, V.; Khandor, C.; Nair, S. Validation and Extraction of Reliable Information through Automated Scraping and Natural Language Inference. Eng. Appl. Artif. Intell. 2025, 147, 110284. [Google Scholar] [CrossRef]
- Ghalyan, I.F.J. Estimation of Ergodicity Limits of Bag-of-Words Modeling for Guaranteed Stochastic Convergence. Pattern Recognit. 2020, 99, 107094. [Google Scholar] [CrossRef]
- Ghalyan, I.F. Capacitive Empirical Risk Function-Based Bag-of-Words and Pattern Classification Processes. Pattern Recognit. 2023, 139, 109482. [Google Scholar] [CrossRef]
- Junior, A.P.C.; Wainer, G.A.; Calixto, W.P. Weighting Construction by Bag-of-Words with Similarity-Learning and Supervised Training for Classification Models in Court Text Documents. Appl. Soft Comput. 2022, 124, 108987. [Google Scholar]
- Al Tawil, A.; Almazaydeh, L.; Qawasmeh, D.; Qawasmeh, B.; Alshinwan, M.; Elleithy, K. Comparative Analysis of Machine Learning Algorithms for Email Phishing Detection Using Tf-Idf, Word2vec, and Bert. Comput. Mater. Contin 2024, 81, 3395. [Google Scholar] [CrossRef]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-Co-Training for Document Classification Using Various Document Representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Shaday, E.N.; Engel, V.J.L.; Heryanto, H. Application of the Bidirectional Long Short-Term Memory Method with Comparison of Word2Vec, GloVe, and FastText for Emotion Classification in Song Lyrics. Procedia Comput. Sci. 2024, 245, 137–146. [Google Scholar] [CrossRef]
- Zhou, J.; Ye, Z.; Zhang, S.; Geng, Z.; Han, N.; Yang, T. Investigating Response Behavior through TF-IDF and Word2vec Text Analysis: A Case Study of PISA 2012 Problem-Solving Process Data. Heliyon 2024, 10, e35945. [Google Scholar] [CrossRef] [PubMed]
- Sagum, R.A.; Clacio, P.A.C.; Cayetano, R.E.R.; Lobrio, A.D.F. Philippine Court Case Summarizer Using Latent Semantic Analysis. Procedia Comput. Sci. 2023, 227, 474–481. [Google Scholar] [CrossRef]
- Bastani, K.; Namavari, H.; Shaffer, J. Latent Dirichlet Allocation (LDA) for Topic Modeling of the CFPB Consumer Complaints. Expert Syst. Appl. 2019, 127, 256–271. [Google Scholar] [CrossRef]
- Bailón-Elvira, J.C.; Cobo, M.J.; Herrera-Viedma, E.; López-Herrera, A.G. Latent Dirichlet Allocation (LDA) for Improving the Topic Modeling of the Official Bulletin of the Spanish State (BOE). Procedia Comput. Sci. 2019, 162, 207–214. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Seo, S.; Seo, D.; Jang, M.; Jeong, J.; Kang, P. Unusual Customer Response Identification and Visualization Based on Text Mining and Anomaly Detection. Expert Syst. Appl. 2020, 144, 113111. [Google Scholar] [CrossRef]
- Agarwal, N.; Sikka, G.; Awasthi, L.K. Enhancing Web Service Clustering Using Length Feature Weight Method for Service Description Document Vector Space Representation. Expert Syst. Appl. 2020, 161, 113682. [Google Scholar] [CrossRef]
- Kaveh, A.; Hamedani, K.B. Improved Arithmetic Optimization Algorithm and Its Application to Discrete Structural Optimization. Structures 2022, 35, 748–764. [Google Scholar] [CrossRef]
- Li, P.; Mao, K.; Xu, Y.; Li, Q.; Zhang, J. Bag-of-Concepts Representation for Document Classification Based on Automatic Knowledge Acquisition from Probabilistic Knowledge Base. Knowl.-Based Syst. 2020, 193, 105436. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Abd Elaziz, M.; Gandomi, A.H. The Arithmetic Optimization Algorithm. Comput. Methods Appl. Mech. Eng. 2021, 376, 113609. [Google Scholar] [CrossRef]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the Space of Topic Coherence Measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 399–408. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Value |
|---|---|
| Source | MK.ru news portal |
| Time span | 19 September–24 October 2019 |
| Language | Russian |
| Documents | 5000 articles |
| Total tokens (clean) | ≈1,280,000 |
| Average tokens per document | 256 |
| Unique lemmas | 12,497 |
| Doc ID | Date (2019) | Headline | Excerpt (≈20 Words) |
|---|---|---|---|
| 7 | 21 September | Putin Discusses Gas Pipeline Project with Merkel | During Saturday’s phone call the leaders reviewed construction progress, environmental permits and possible U.S. sanctions affecting Nord Stream 2. |
| 149 | 25 September | Magnitude-5.5 Quake Strikes Kamchatka | The regional EMERCOM office reported no casualties, although residents felt two strong jolts and some schools were evacuated as a precaution. |
| 234 | 30 September | Zenit Beats CSKA 2-0 in Premier League Derby | Mid-fielder Dzyuba scored twice in the second half, sealing a decisive victory that keeps Zenit top of the domestic table. |
| 378 | 9 October | Impeachment Inquiry Opens First Public Hearing | U.S. lawmakers questioned State Department officials over withheld aid to Ukraine amid heated partisan exchanges broadcast live on national television. |
| 421 | 14 October | Central Bank Cuts Key Rate to 6% | Citing lower inflation expectations and sluggish consumer demand, the regulator trimmed its benchmark rate for the third time this year. |
| Model | ΔH | Sdiv | Znoise |
|---|---|---|---|
| ATe-DTM (ours) | 0.24 | 0.32 | 0.18 |
| DTM | 0.11 | 0.47 | 0.29 |
| DETM | 0.14 | 0.42 | 0.25 |
| BERTopic | 0.13 | 0.39 | 0.24 |
| NMF-TimeSlice | 0.06 | 0.52 | 0.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodionov, D.; Lyamin, B.; Konnikov, E.; Obukhova, E.; Golikov, G.; Polyakov, P. Integration of Associative Tokens into Thematic Hyperspace: A Method for Determining Semantically Significant Clusters in Dynamic Text Streams. Big Data Cogn. Comput. 2025, 9, 197. https://doi.org/10.3390/bdcc9080197
Rodionov D, Lyamin B, Konnikov E, Obukhova E, Golikov G, Polyakov P. Integration of Associative Tokens into Thematic Hyperspace: A Method for Determining Semantically Significant Clusters in Dynamic Text Streams. Big Data and Cognitive Computing. 2025; 9(8):197. https://doi.org/10.3390/bdcc9080197
Chicago/Turabian StyleRodionov, Dmitriy, Boris Lyamin, Evgenii Konnikov, Elena Obukhova, Gleb Golikov, and Prokhor Polyakov. 2025. "Integration of Associative Tokens into Thematic Hyperspace: A Method for Determining Semantically Significant Clusters in Dynamic Text Streams" Big Data and Cognitive Computing 9, no. 8: 197. https://doi.org/10.3390/bdcc9080197
APA StyleRodionov, D., Lyamin, B., Konnikov, E., Obukhova, E., Golikov, G., & Polyakov, P. (2025). Integration of Associative Tokens into Thematic Hyperspace: A Method for Determining Semantically Significant Clusters in Dynamic Text Streams. Big Data and Cognitive Computing, 9(8), 197. https://doi.org/10.3390/bdcc9080197